多源信息融合研究綜述
2015-12-06 07:50:34余肖生田智星
重慶理工大學學報(自然科學) 2015年12期
余肖生,田智星,余 梅,2
(1.三峽大學計算機與信息學院,湖北宜昌 443002;2.武漢大學信息管理學院,武漢 430072)
目前,全球信息量以每年30%的速度增長,且這個速度還將上升[1]。大數據已成為各行業發展面臨的“新常態”[2]。隨著網絡技術的發展,越來越多的互聯網或企業內部網的可用數據源通過網絡連接,通過一個一致的接口訪問這些信息源的所有需求已成為信息融合領域研究的背后推動力量[3],而信息源中的數據呈現出異構性、分布性、自治性等特點[1]。在大數據環境下,如何高效地進行信息融合已成為信息資源有效利用的主要瓶頸。國內外學者在信息資源融合方面進行了有效的探索,并取得了一定的研究進展。本文從信息融合架構、信息融合模型、信息融合方法、信息融合技術、信息融合層次等5個方面對信息融合領域進行總結和分析,指出該領域研究的主要特點和趨勢,以期對信息融合領域的研究發展提供一些借鑒和啟示。
1 相關研究
信息融合是為綜合信息系統的用戶提供多個數據源的統一視圖的過程[4]。從數據的來源看,既有來自傳感器的流媒體數據,也有來自互聯網的半結構化或非結構化數據,還有來自各類數據庫的結構化數據。本文主要針對結構化數據的融合架構、模型、方法、技術等進行綜述。
1.1 信息融合架構
目前的信息融合基本架構主要有2種,即虛擬化架構和物化架構。在虛擬化架構中,一個數據融合系統可以形式化地定義為一個三元組〈G,S,M〉,其中G是全局或中介模式,S是異構源模式集合,M是源和全局模式之間查詢的映射[5-6]。在虛擬化環境中,數據存在于單獨的數據源中。虛擬層是一個屬于所有數據來源的虛擬模式。當系統收到虛擬層定義的用戶查詢時,先判定將被查詢的相關數據源,然后根據不同的數據源將查詢分解成不同的子查詢。子查詢由合適的數據源執行,再將各數據源響應的結果進行適當的結合后返回用戶[7]。這種架構的優點在于返回給用戶的數據總是當前最新數據。然而,最大的挑戰是如何定義每個數據源和虛擬層之間的映射[8]。虛擬化架構的設計和實現有2個主要策略,即全局視圖(GAV)和本地視圖(LAV)。GAV是將各本地數據源的局部視圖映射到全局視圖,即全局模式被描述為源模式上的一組視圖,如圖1所示[9-10]。用戶查詢直接作用于定義在數據源模式上的全局視圖。GAV的優點是查詢效率較高,缺點是用這種方法構建出來的映射關系的可擴展性較差,不適合數據源存在動態變化的情況。LAV是將全局視圖映射到各數據源上的本地局部視圖,即各數據源模式被描述為全局模式上的視圖,如圖2所示。當用戶提交某個查詢時,中介系統通過整合不同的數據源視圖決定如何應答查詢。這種方法可看作利用視圖回答查詢。該方法的優點是映射關系的可擴展性好,適合于信息源變化比較大的情況,缺點是可能會造成“信息遺失”、信息查詢效率低。考慮到LAV和GAV固有的局限,很多研究者試圖創造一種包含兩者優勢、同時可克服兩者劣勢的“混合”方法,即GLAV[11]。
在物化架構中,將數據在全局層面進行實體化通常應用于數據倉庫,且沒有任何非結構化信息。該架構面臨的挑戰是一系列實體化視角的選定,另一問題是增量視圖的維護。當底層數據源發生改變時,需要一個有效的方式維持實體化視圖。數據倉庫方法合并來自多個源數據的數據庫,數據必須經過抽取、轉換、加載(ETL)才能進入數據倉庫。數據倉庫在解決數據融合問題的同時,也存在自身的問題。數據倉庫的主要難點是維護數據倉庫和底層數據源之間的同步。一般地,有2種主要方法用于解決該問題:①周期性地重建整個數據倉庫;②檢測來源的變化,然后相應地更新[7]。
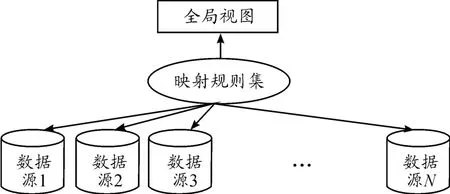
圖1 GAV
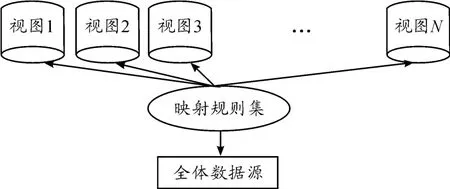
圖2 LAV
1.2 信息融合模型
Kangchan Lee等[12-13]根據互聯網信息資源融合需求,提出了基于XML的中介框架(XMF)模型。它采用中介器-封裝器體系結構,使用XML描述信息資源和映射規則,為最終用戶提供一個融合的基礎信息來源;王寧[14]以E-R-P信息管理模型為基礎,提出了以實體管理、關系管理、問題管理以及元數據管理為核心組件的信息資源整合平臺;黃萃[15]以電子政務信息流程為基礎,構建了基于門戶網站的電子政務信息資源整合機制模型;Ananthanarayanan等[16]為跨多個非結構化的數據源提供了一個數據驅動的相似性發現方法,以便被發現的信息能與現有結構化信息的模式融合,從而允許同時在結構化和文本數據上查詢;文獻[17]提出了基于本體的信息融合模型[17];Brzykcy[18]在 SIXP2P 系統中提出了基于XML數據的語義融合模型;Kim等[19]提出了模型驅動的數據融合(MDDI)模型,通過分離數據和元數據降低了數據融合的復雜性,從而有效地解決了數據整合的問題;張玉濤等[20]提出了基于主題圖的電子政務信息資源整合模型,并對模型在Metamorphosis主題圖環境中的處理流程和實際實施進行了初步的探討;羅賢春等[21]提出了基于共享目錄的電子政務信息資源整合模型。
1.3 信息融合方法
基于中介器的方法[22]:該方法是被許多融合框架采用的最著名的方法之一。它提出了中介器的使用,一個系統負責把一個單一模式上形成的用戶查詢重新表述成底層數據源在本地模式上的查詢。這些數據源包含實際的數據,而全局模式提供了底層數據源的一個協調、融合、虛擬的視圖。映射可以通過采用GAV或LAV來完成。當融合的數據源是已知和穩定時,宜采用GAV;而融合的數據源是大規模和臨時時,宜采用LAV。
基于本體的方法[23-25]:語義(數據融合的一個重要組件)的普及為基于本體的方法做了鋪墊。協調跨多個概念的異構模式中本體的使用已經被語義網研究社區廣泛關注。該方法以數據對象為基本元素,利用數據對象和領域本體之間的映射關系來表達數據對象的語義,使用嵌套關系模型來表達數據對象的模式信息,通過把一個網格節點中集成的所有數據對象作為下一個節點的數據對象來實現數據資源由粗到細的融合。
基于導航的方法:也被稱為基于鏈接的方法[26]。它基于這樣一個事實:網絡上越來越多的數據源要求用戶手動瀏覽一些網頁,以獲取所需的信息。純導航融合消除了數據的關系建模,在這個模型中,數據源被定義為網頁、它們之間的聯系和具體入口點的集合。另外,還包括一些附加信息,如內容、路徑約束和強制輸入參數。在深網絡的信息融合中,這種方法被認為是至關重要的[27],它需要抽取隱藏在 Web查詢接口后的數據。然而,維持以一定速度變化的網絡資源之間的關系是一項艱巨的任務,在當前網絡環境下,這種方法被認為不可行。
聯邦數據庫方法[28]:開發的前提是回答查詢所需的信息直接來自數據源。因此,查詢結果發布時,其總是關于數據源的最新的內容。更重要的是,數據庫聯邦方法更易適應應用程序要求用戶能夠強加自己的本體到分布式自治信息源的數據上的情形。當數據源是自治的,并需要支持多個本體時,聯邦方法是首選。然而,當查詢頻率遠高于底層數據源的變化頻率時,這種方法是失敗的。
基于數據倉庫的方法[29]:該方法的基礎是傳統的數據倉庫技術。來自異構的分布式信息源的數據映射到一個共同的結構并存儲在一個集中的位置。為了確保數據倉庫中的信息能反映單個數據源的當前內容,有必要定期更新數據倉庫。
1.4 信息融合技術
信息融合主要涉及沖突解決、數據合并等技術。數據沖突主要有2種類型:不確定性和矛盾。不確定性是所有用來描述現實世界實體的相同屬性的一個非空值和一個或多個空值之間的沖突。不確定性由于缺少信息(例如在一個數據源中的空值或數據源中完全缺失的屬性)而引起。矛盾用來描述相同實體的同一屬性的兩個或兩個以上的不同的非空值之間的沖突。矛盾是現實世界實體的相同屬性由不同數據源提供了不同的值而引起的。解決數據沖突的策略主要有沖突忽略策略、沖突避免策略、沖突解決策略[3]。數據合并技術主要有連接、并等關系運算符。然而,它們不能很好地處理數據合并。因此,產生了為完成數據融合而特別設計的操作符,例如匹配連接(match join)[30]、完全析取(full disjunction)[31-32]。另外,還有模式匹配和模式映射等相關技術。
1.5 信息融合層次
信息融合是在幾個層次上完成對多源信息的處理過程,其中每一層次都表示不同級別的信息抽象。信息融合的結果包括較低層次上的狀態和身份估計,以及較高層次上的整個戰術態勢估計[33]。曹建君[34]將信息融合劃分為原始數據融合或像元級融合(pixel based)、目標級或特征級融合(feature based)以及決策級融合(decision leve1)3個層次。Hu Jiaqi[35]把信息融合劃分為數據層融合、特征層融合、相似度層融合和決策層融合4個層次。
2 發展趨勢
2.1 物理化:信息融合的新趨勢
從研究現狀看,信息融合的架構主要有虛擬化和物化2種。物理化已成為互聯網發展的新趨勢[36]。基于數據倉庫的信息融合方法根據決策需求抽取來自不同數據源中的相關數據,將其轉換成數據倉庫中數據的統一格式,并儲存在一個集中的位置。大數據環境下,這一信息融合的物理化方法已經逐步成為信息融合的主流方法。
2.2 大數據:信息融合的新常態
目前,中國移動互聯網用戶數已經超過5億,流量幾乎每年翻番。大數據、物聯網等技術和應用從概念上的討論變成了現實[37]。為了準確獲取用戶行為習慣,需要從這些大數據中融合與用戶行為相關的數據,并加以處理、分析。大數據已成為信息資源融合的新常態。
2.3 全自動化:信息融合的新挑戰
現有信息融合的步驟較多,且通常非常復雜,整個融合過程的每一步都需要大量的人工干預。同時,信息融合過程非常脆弱,如果融合對象中的某一個數據源的結構發生變化,則整個融合過程需要重新設計。因此,現有方法效率較低,錯誤也不可避免。實現人工可控、系統自主的全自動化的信息融合已經成為用戶的新期待,也是信息融合領域發展的新挑戰。
[1]XIN LUNA DONG,FELI NAUMANN.Data fusion-resolving data conflicts for integration[C]//VLDB 2009.France:[s.n.],2009,1654-1655.
[2]JORGE A.LOPEZ.Data Integration:2013’s Top 3 Trends[EB/OL].[2015-02-12].http://tdwi.org/Articles/2013/01/08/Data-Integration-2013-Top-Trends.aspx?Page=2.
[3]BLEIHOLDER J,NAUMANN F.Data fusion[J].ACM CSUR,2008(1):1-41.
[4]BLEIHOLDER J,SZOTT S,HERSCHEL M.Subsumption and Complementation as Data Fusion Operators[C]//EDBT 2010.Switzerland:[s.n.],2010:513-524.
[5]LENZERINI M.Data integration:a theoretical perspective[C]//PODS 2002.USA:[s.n.],2002:233-246.
[6]XU L,EMBLEY D W.Combining the Best Globa-as-View and Local-as-View for Data Integration[C]//ISTA 2004.[S.L.]:[s.n.],2004:123-135.
[7]BENNETT T A,BAYRAK C.Bridging The Data Integration Gap:From Theory to Implementation[J].ACM SIGSOFT Software Engineering Notes,2011(3):1-8.
[8]MOHANIA M,BHIDE M.New Trends in Information Integration[C]//ICUIMC2008.Korea:[s.n.],2008:74-81.
[9]AMIT P S,JAMES A L.Federated Database Systems for Managing Distributed,Heterogeneous,and Autonomous Databases[J].ACM Computing Surveys,1990(3):183-236.
[10]ALON Y H,RAJARAMAN A,JOANN J O.Data Integration:The Teenage Years[J].VLDB,2006:9-16.
[11]XU L,EMBLEY D W.Combining the Best Globa-as-View and Local-as-View for Data Integration[C]//ISTA 2004.[S.L.]:[s.n.],2004:123-135.
[12]KANGCHAN L,JAE HONG M,KISHIK P,et al.A Design and Implementation of XML-Based Mediation Framework(XMF)for Integration of Internet Information Resources[C]//HICSS 2002.USA:[s.n.],2002:202.
[13]SEONG-JOON Y,KANGCHAN L,KYUCHUL L.An XML-Based Mediation Framework for Seamless Access to Heterogeneous Internet Resources[C]//ICOIN 2003.Korea:[s.n.],2003:396-405.
[14]王寧.電子政務中信息資源整合的建模方法與應用研究[D].大連:大連理工大學,2005.
[15]黃萃.基于門戶網站的電子政務信息資源整合機制研究[D].武漢:武漢大學,2005.
[16]ANANTHANARAYANAN R,BALAKRISHNAN S.Unstructured information integration through data-driven similarity discovery[C]//IJCAI 2009.USA:[s.n.],2009:1-6.
[17]馬小軍,李廣建.基于本體的數字資源整合方法與技術[J].情報科學,2010(10):1541-1546.
[18]BRZYKCY G.Data Integration in a System with Agents’Models[C]//KES-AMSTA 2008.Korea:[s.n.],2008:162-171.
[19]KIM H,YING ZHANG,SAMIA OUSSENA,et al.A Case Study on Model Driven Data Integration for Data Centric Software Development[C]//DSMM2009.USA:[s.n.],2009:1-5.
[20]張玉濤,夏立新.基于主題圖的電子政務信息資源整合模型研究[J].情報雜志,2009(7):161-165.
[21]羅賢春,文庭孝,張新宇.電子政務信息資源共享與社會化服務研究[M].北京:人民出版社,2012.
[22]LIU L,PU C,LEE Y.An Adaptive Approach to Query Mediation AcrossHeterogeneousInformation Sources[C]//CoopIS 1996.Belgium:[s.n.],1996:144-156.
[23]NOY N F.Semantic Integration:A Survey Of Ontology-Based Approaches[J].SIGMOD Record,2004(4):65-70.
[24]DOERR M,HUNTER J,LAGOZE C.Towards a Core Ontology for Information Integration[J].Journal of Digital Information,2003(1):1-22.
[25]劉波,齊德昱,林偉偉,等.基于本體的語義數據融合方法[J].華南理工大學學報:自然科學版,2009(1):96-101.
[26]FRIEDMAN M,LEVY A Y,MILLSTEIN T D.Navigational Plans For Data Integration[C]//AAAI/IAAI 1999.USA:[s.n.],1999:67-73.
[27]HE B,PATEL M,CHANG C C,et al.Accessing the Deep Web:A Survey[J].Communications of The ACMCACM,2007(5):94-101.
[28]SHETH A P,LARSON J A.Federated Database Systems for Managing Distributed,Heterogeneous,and Autonomous Databases[J].ACM Computing Survey,1990(3):183-236.
[29]FLORESCU D,LEVY A,MENDELZON A.Database techniques for the world-wide web:A survey[J].SIGMOD Record,1998(3):59-74.
[30]YAN L L,?ZSU M T.Conflict tolerant queries in AURORA[J].IEEE Computer Society,1999(1):279.
[31]COHEN S,FADIDA I,KANZA Y,et al.Full disjunctions:Polynomial-delay iterators in action[C]//VLDB2006.Korea:[s.n.],2006:739-750.
[32]COHEN S,SAGIV Y.An incremental algorithm for computing ranked full disjunctions[C]//PODS 2005.USA:[s.n.],2005:98-107.
[33]化柏林.多源信息融合方法研究[J].多源信息融合方法研究,2013(11):16-19.
[34]曹建君,李景相,蔡喜琴,等.基于信息融合理論的省情信息融合研究[J].遙感技術與應用,2006(4):368-371.
[35]HU Jiaqi.DATA FUSION:A FIRST STEP IN DECISION FORMATICS[D].Troy:Rensselaer Polytechnic Institute,2008.
[36]張亞勤.互聯網物理化已經成為新趨勢[N].人民日報,2015-01-08(19).
[37]鄔賀銓.移動互聯網已進入“大智移云”時代[N].人民日報,2015-01-23(20).
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
