低數(shù)據(jù)資源條件下基于結(jié)構(gòu)信息共享的無切分維文文檔識別字符建模
2015-12-13 11:46:56姜志威丁曉青彭良瑞劉長松
電子與信息學(xué)報(bào) 2015年9期
姜志威 丁曉青 彭良瑞 劉長松
1 引言
近年來,基于隱馬爾可夫模型(Hidden Markov Model, HMM)的無切分文檔識別方法逐漸成為主流,通過字符、文本行兩級概率圖模型的框架,能夠有效解決困擾傳統(tǒng)預(yù)切分文檔識別方法的字符切分問題。不過,這種方法要求字符HMM建模有較高的準(zhǔn)確度,并且需要使用大量的樣本進(jìn)行學(xué)習(xí)。對于維吾爾文(簡稱“維文”)文檔而言,在上述兩方面都面臨著較大的困難。首先,維文字符形狀變化有一百多種,并且粘連性和相似性很強(qiáng),會為字符建模帶來很大的困難;其次,盡管現(xiàn)有維文文檔存量很大,但是制作樣本的顯現(xiàn)形式內(nèi)容標(biāo)注卻非常費(fèi)力、耗時(shí)。尤其是在面對一種新字體類型時(shí),很難找到充足且有標(biāo)注的同類樣本來訓(xùn)練新模型。所以,如何解決好低數(shù)據(jù)資源條件下的字符建模問題,實(shí)現(xiàn)利用少量樣本來建立高性能的識別系統(tǒng),對當(dāng)前的無切分維文文檔識別領(lǐng)域具有迫切的需求和重要的意義。
盡管低數(shù)據(jù)資源建模的問題在語音識別領(lǐng)域已經(jīng)有一定的研究成果[1,2],但是在無切分文字識別領(lǐng)域卻剛剛起步。以往的研究工作中,HMM 模型優(yōu)化和低數(shù)據(jù)資源建模通常被作為兩個獨(dú)立的問題進(jìn)行研究。前者可以通過HMM狀態(tài)結(jié)構(gòu)優(yōu)化來提高字符建模的準(zhǔn)確度[3,4],而后者則主要采用HMM自適應(yīng)的方法,通過少量新樣本調(diào)整已有的通用模型來解決[57]-。但是,字符圖像是一種結(jié)構(gòu)性很強(qiáng)的2維信號,字符HMM狀態(tài)是描述其結(jié)構(gòu)的基本單元。所以,即使是在低數(shù)據(jù)資源的條件下,也應(yīng)當(dāng)充分考慮狀態(tài)結(jié)構(gòu)帶來的影響。文獻(xiàn)[8,9]以法文文檔識別為背景,提出將HMM狀態(tài)結(jié)構(gòu)優(yōu)化方法與模型自適應(yīng)方法相結(jié)合,用以提高自適應(yīng)模型對新樣本的識別性能。該方法需要使用少量帶有切分標(biāo)注的樣本進(jìn)行模型自適應(yīng),以及大量無切分標(biāo)注的樣本用于狀態(tài)結(jié)構(gòu)優(yōu)化。然而,在維文文檔識別問題中,適應(yīng)集樣本規(guī)模通常都很小,而且具有粘連性的維文文本行也很難給出明確的切分位置標(biāo)注,所以該方法不能用于改善維文字符建模的問題。
不過,經(jīng)過觀察可以發(fā)現(xiàn),常用維文字體間的差異主要是形狀扭曲風(fēng)格的不同,在整體結(jié)構(gòu)上并沒有像法文字體那樣的劇烈變化。于是,本文提出一種基于結(jié)構(gòu)信息共享的無切分維文文檔識別字符建模方法,通過在自建樣本和實(shí)際樣本上的相關(guān)實(shí)驗(yàn)結(jié)果可以表明,該方法不僅可以提高HMM模型對字符結(jié)構(gòu)的描述能力,還可以有效降低模型自適應(yīng)訓(xùn)練對新樣本的依賴程度,提高識別系統(tǒng)對新樣本類型的識別性能。
2 HMM中的字符結(jié)構(gòu)信息表達(dá)與提取
2.1 基于HMM的無切分文檔識別方法的基本原理
基于HMM的無切分文檔識別方法可以歸納為字符層和文本行層這兩個層級。在字符層面,每種字符都用一個基元HMM模型描述。字符圖像首先被狹長的滑動窗口進(jìn)行分幀處理,得到一連串的觀測序列{Ot: t = 1,2,… , T },它們被認(rèn)為是一個隨機(jī)過程序列{qt:t = 1 ,2,… ,T }的輸出結(jié)果。而其中的 qt都來自于一個有限的集合{sj: j = 1 ,2,…, N },其構(gòu)成元素 sj被稱為HMM的“狀態(tài)”,如圖1所示。觀測與狀態(tài)之間的關(guān)系只能通過條件概率Pr(Ot|qt= sj)進(jìn)行估計(jì),本文采用混合高斯模型(Gaussian Mixture Model, GMM)來描述這一概率,如式(1)所示。其中,Mj為狀態(tài) sj觀測的GMM混合分量數(shù),cjm, μjm和Σjm分別為該GMM中第m個高斯分量的權(quán)重、均值向量和協(xié)方差矩陣。此外,狀態(tài)之間在概率上構(gòu)成一階馬爾科夫鏈,用起始概率πi=Pr(q1= si) 和轉(zhuǎn)移概率 pij= P r(qt= sj|qt-1= si) 共同描述,其中 i, j = 1 ,2,… , N 。
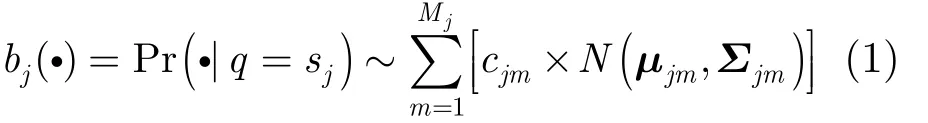
圖 1 基于HMM的字符圖像建模原理示意圖
當(dāng)文本行圖像被用于模型訓(xùn)練時(shí),由于字符模型之間的跳轉(zhuǎn)可以被作為狀態(tài)間的跳轉(zhuǎn)對待,因此不需要字符間的切分標(biāo)注信息,即可更新其包含的各個基元模型的參數(shù),這種訓(xùn)練方法被稱為嵌入式訓(xùn)練。而當(dāng)文本行圖像需要解碼識別時(shí),只要尋找到與該圖像觀測序列對準(zhǔn)匹配最佳的字符基元模型組合,其組合內(nèi)容就是文本行的識別結(jié)果,而模型間的跳轉(zhuǎn)時(shí)刻,就對應(yīng)著文本行圖像中的字符切分位置。
2.2 狀態(tài)的物理意義與字符結(jié)構(gòu)信息的提取
HMM 作為一種概率圖模型,其狀態(tài)的物理意義是對一段圖像觀測序列進(jìn)行有序聚類的結(jié)果,它們在全局上形成概率圖模型的結(jié)構(gòu),用以描述字符的整體結(jié)構(gòu);在局部上實(shí)現(xiàn)概率圖模型的統(tǒng)計(jì)平均,用以描述字符的區(qū)域變化風(fēng)格。為了使每個狀態(tài)都被有效用于描述穩(wěn)定的局部字符結(jié)構(gòu)觀測,避免產(chǎn)生冗余的狀態(tài),狀態(tài)自身需要具有典型性;同時(shí),為了降低狀態(tài)在與觀測序列對準(zhǔn)匹配時(shí)所產(chǎn)生的誤差,保證模型對字符圖像進(jìn)行準(zhǔn)確的編碼和解碼,狀態(tài)之間也需要具有鑒別性。于是,根據(jù)上述兩條性質(zhì),就可以設(shè)計(jì)出相應(yīng)的狀態(tài)優(yōu)化方法,使得HMM 能夠準(zhǔn)確地提取出字符圖像觀測序列中的結(jié)構(gòu)信息。
狀態(tài)的典型性可以采用信息熵的形式估計(jì)狀態(tài)活躍度來評價(jià)[10],如式(2)所示,其中 H ( p ) = -p lg p ,α, β和γ是和為1的歸一化因子。由于描述復(fù)雜字符結(jié)構(gòu)的 HMM 通常采用自底向上的狀態(tài)優(yōu)化算法,即逐步減少狀態(tài)數(shù)量,所以狀態(tài)冗余的模型中會存在信息熵過小的非典型狀態(tài)。于是,可以根據(jù)信息論中的最大熵原理,從模型中將信息熵過小的狀態(tài)去除,即可完成狀態(tài)的典型性優(yōu)化。

狀態(tài)間的鑒別性可以采用分布的KL(Kullback-Leibler)散度來衡量。但由于GMM的KL散度從理論上不具有可計(jì)算的解析形式,這里采用文獻(xiàn)[11]中的方法,先估計(jì)出此距離的一個緊上界,如式(3)所示。其中,f和g為空間中的兩個具有相同高斯分量數(shù)m的GMM 分布,a和b分別為它們的高斯分量權(quán)重;()iβ為兩個GMM高斯分量間的映射關(guān)系,并要求在此映射關(guān)系下,所有高斯分量對之間的距離之和最小。然后,根據(jù)相鄰狀態(tài)間的距離估計(jì)和判斷閾值,就可以確定哪些狀態(tài)需要融合。另外,還要對最終狀態(tài)數(shù)的上、下界限進(jìn)行控制,以便模型能具有更合理的結(jié)構(gòu)[12],并且采用文獻(xiàn)[8]中的方法來融合相似的相鄰狀態(tài)。
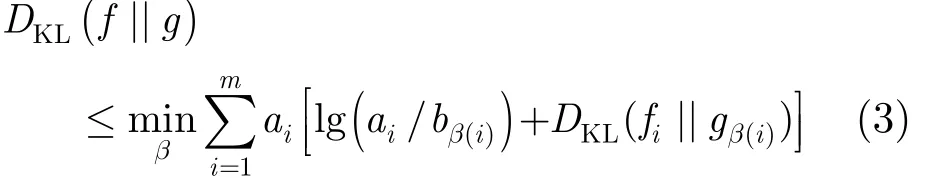
另外,在實(shí)際的訓(xùn)練中,為了提高模型準(zhǔn)確程度,GMM 高斯分量的產(chǎn)生通常采用自頂向下的方法,即單高斯分布的狀態(tài)交替進(jìn)行參數(shù)更新和高斯分裂,直至達(dá)到預(yù)定的GMM分量數(shù)。因此,上述狀態(tài)優(yōu)化方法可以跟隨GMM的分裂過程進(jìn)行,用于在每一輪參數(shù)優(yōu)化之前,尋找更加準(zhǔn)確合理的模型結(jié)構(gòu)和參數(shù),避免參數(shù)估計(jì)陷入局部極值的風(fēng)險(xiǎn)[13],提高模型對字符結(jié)構(gòu)信息的描述能力。
3 低數(shù)據(jù)資源條件下基于結(jié)構(gòu)信息共享的字符建模方法
3.1 HMM自適應(yīng)與最大后驗(yàn)估計(jì)方法
HMM 自適應(yīng)主要研究模型特化問題,目的是在訓(xùn)練樣本不足條件下,使一個已有的通用模型能更好地適用于單一識別任務(wù)。模型自適應(yīng)的思路主要有兩種,一種是“微調(diào)”通用模型的參數(shù),使其符合適應(yīng)集樣本的統(tǒng)計(jì)特性,如最大后驗(yàn)估計(jì)方法(Maximum A Posteriori, MAP)[5];另一種是假定目標(biāo)模型參數(shù)與通用模型參數(shù)間存在線性變換關(guān)系,通過估計(jì)這個變換的參數(shù),使變換后的模型適用于適應(yīng)集樣本的識別,如最大似然線性回歸方法[6]。由于本文主要工作是研究模型參數(shù)的估計(jì),所以這里只對MAP方法進(jìn)行分析。
MAP方法以最大化 Bayes理論導(dǎo)出的模型后驗(yàn)概率作為計(jì)算準(zhǔn)則。以狀態(tài)的均值向量自適應(yīng)為例,其更新公式如式(4)所示,是一個適應(yīng)集樣本最大似然估計(jì)μMLE與原始模型參數(shù)μori之間的線性插值結(jié)果。其中,τ為預(yù)先給定的學(xué)習(xí)速率,{ Ot:t=1,2,… ,T}為適應(yīng)集中的樣本觀測序列,ψ(t)為樣本觀測幀tO在t時(shí)刻由當(dāng)前待更新狀態(tài)生成的概率,MLEμ的計(jì)算如式(5)所示。
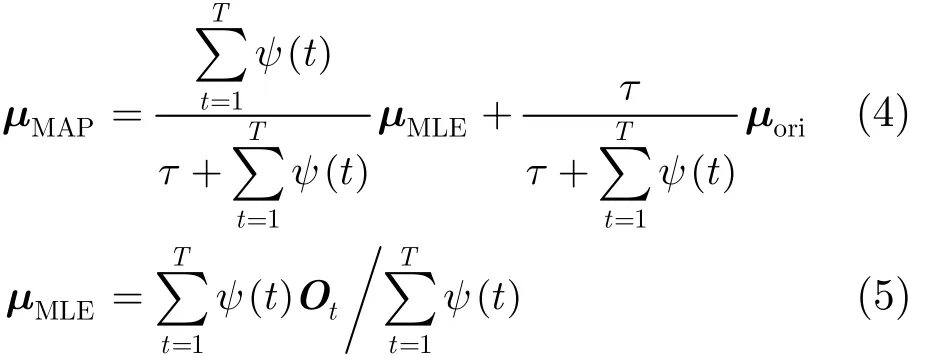
從式(4)中可以看出,如果適應(yīng)集樣本的規(guī)模越大,則自適應(yīng)的結(jié)果MAPμ就會越傾向于適應(yīng)集樣本的最大似然估計(jì)MLEμ;反之,則會傾向于保持原有的通用模型參數(shù)oriμ,相當(dāng)于沒有進(jìn)行參數(shù)調(diào)整。因此,MAP方法雖然具有較好的一致性和漸進(jìn)性,但是在低數(shù)據(jù)資源條件下,對模型的特化性能提高效果十分有限,難以充分利用新樣本中所包含的信息。
3.2 基于結(jié)構(gòu)信息共享的字符建模方法
針對常用維文字體在字符的整體結(jié)構(gòu)上一致性較高、在變化風(fēng)格上差異性較大的特點(diǎn),可以采用先共享通用訓(xùn)練樣本的字符結(jié)構(gòu)信息,向這些樣本“借數(shù)據(jù)”,再利用Bootstrap原理學(xué)習(xí)少量適應(yīng)集樣本字符變化風(fēng)格,向這些樣本“要數(shù)據(jù)”的策略,使得模型最大似然估計(jì)對樣本的依賴性得到降低,這就是本文所提方法的主要思路。該方法的流程框圖如圖2所示,上方的圓邊矩形表示訓(xùn)練所采用的樣本,下方的矩形表示訓(xùn)練所得的HMM模型;另外,中間5個帶編號的箭頭表示流程中的5個操作步驟,其中①②③為準(zhǔn)備步驟,④⑤為新樣本學(xué)習(xí)步驟。下面將會逐一對各個步驟進(jìn)行說明。
為了準(zhǔn)確地向通用樣本“借數(shù)據(jù)”,需要確定字符結(jié)構(gòu)共享的時(shí)機(jī),既要讓模型從通用樣本中充分提取出結(jié)構(gòu)信息,又要避免模型在通用樣本上過度特化(步驟①)。在上一節(jié)所述的字符結(jié)構(gòu)信息提取過程中,由于高斯數(shù)增長的初期,大量冗余狀態(tài)因缺乏典型性或鑒別性而被去除或合并,所以狀態(tài)數(shù)將會驟減,模型狀態(tài)結(jié)構(gòu)也迅速向相應(yīng)字符結(jié)構(gòu)的統(tǒng)計(jì)特性靠近。當(dāng)高斯數(shù)增長到一定程度后,各個狀態(tài)已具有充分的典型性和鑒別性,所以狀態(tài)數(shù)將不再變化,各個狀態(tài)也開始對字符結(jié)構(gòu)的統(tǒng)計(jì)特性進(jìn)行精細(xì)描述,使模型逐步特化于當(dāng)前的訓(xùn)練樣本。因此,字符結(jié)構(gòu)共享時(shí)機(jī)應(yīng)當(dāng)選擇從通用樣本提取字符結(jié)構(gòu)信息的過程中,所有模型的結(jié)構(gòu)變化剛剛趨于穩(wěn)定的時(shí)刻。此時(shí),將會得到一個低高斯數(shù)的基礎(chǔ)模型。

圖 2 低數(shù)據(jù)資源條件下基于結(jié)構(gòu)信息共享的字符建模方法流程圖
為了高效地向適應(yīng)集樣本“要數(shù)據(jù)”,需要生成適應(yīng)集樣本的切分標(biāo)注。這些標(biāo)注信息能夠使文本行圖像樣本轉(zhuǎn)化為字符圖像樣本,幫助模型向新樣本的字符變化風(fēng)格進(jìn)行遷移。對于切分標(biāo)注的生成問題,可以采用 Bootstrap方法來解決[14]。首先,基于前文所得到的低高斯數(shù)基礎(chǔ)模型,用適應(yīng)集樣本直接訓(xùn)練得到一個全高斯數(shù)的輔助模型(步驟②)。然后,用該模型對適應(yīng)集樣本進(jìn)行模型級強(qiáng)制對準(zhǔn)(步驟③),即可獲得這些樣本的切分標(biāo)注信息。
完成上述準(zhǔn)備步驟后,即可采用經(jīng)典的Baum-Welch算法,在逐個模型上進(jìn)行參數(shù)的最大似然估計(jì),完成字符變化風(fēng)格的遷移學(xué)習(xí)(步驟④),其原理如下所述。先來分析該算法中樣本觀測 Ot在t時(shí)刻由狀態(tài) sj生成的概率表達(dá)式,如式(6)所示。其中,αi(t) 和 βi(t ) 分別表示t時(shí)刻觀測處于狀態(tài) sj的前向概率和后向概率。由于式(6)的分母僅用于結(jié)果歸一化,所以在觀測與狀態(tài)進(jìn)行合理對準(zhǔn)匹配的情況下, ψj(t ) 的結(jié)果將主要取決于分子中 bj( Ot) 這一項(xiàng)。如果觀測 Ot服從狀態(tài) sj當(dāng)前的概率分布,則ψj(t)的計(jì)算結(jié)果會趨向于1;反之,則會趨向于0。因此,這個過程相當(dāng)于以基礎(chǔ)模型的狀態(tài)為中心,對適應(yīng)集樣本的觀測序列進(jìn)行有序聚類,并更新模型統(tǒng)計(jì)參數(shù)的過程。又因?yàn)榛A(chǔ)模型中包含了通用樣本的字符結(jié)構(gòu)信息,各個字符模型對應(yīng)的樣本也能夠被切分標(biāo)注進(jìn)行分離,所以步驟④僅使用少量的適應(yīng)集樣本,就可以實(shí)現(xiàn)基礎(chǔ)模型對新樣本字符變化風(fēng)格的遷移學(xué)習(xí),得到一個遷移模型。

最后,按照經(jīng)典的HMM嵌入式訓(xùn)練方法,再對遷移模型交替進(jìn)行多次參數(shù)最大似然估計(jì)和GMM 高斯分裂操作[15],直到模型的高斯數(shù)達(dá)到預(yù)設(shè)值為止(步驟⑤),就可以得到適用于新樣本類型的全高斯數(shù)最終模型。由于在前一個步驟中,得到的遷移模型已經(jīng)偏向于適應(yīng)集樣本,因此這里可以直接使用無切分標(biāo)注的適應(yīng)集樣本進(jìn)行模型嵌入式訓(xùn)練。
4 實(shí)驗(yàn)與結(jié)果分析
本文實(shí)驗(yàn)主要使用劍橋大學(xué)公開的 HTK[16]工具包完成,其它原創(chuàng)性工作通過C代碼實(shí)現(xiàn),并由Perl腳本控制執(zhí)行流程。實(shí)驗(yàn)中,基于文獻(xiàn)中已有的28維特征提取方法[17],通過一階幀間差分?jǐn)U展獲得56維特征向量,并采用直線型HMM進(jìn)行建模。結(jié)果評價(jià)方面,利用系統(tǒng)識別性能間接衡量各模型準(zhǔn)確度的思路,采用 HTK中相對嚴(yán)格的字符識別準(zhǔn)確率ACC作為評價(jià)指標(biāo)。該指標(biāo)通過動態(tài)規(guī)劃算法對齊識別結(jié)果與真值內(nèi)容,然后計(jì)算正確識別字符數(shù)量與插入錯誤數(shù)量之差,占全部真值字符數(shù)量的百分比,并且ACC指標(biāo)也等價(jià)于常用的美國國家標(biāo)準(zhǔn)與技術(shù)研究院所提出的詞識別錯誤率WER指標(biāo),因?yàn)槎咧秃愣?。
4.1 實(shí)驗(yàn)相關(guān)數(shù)據(jù)集介紹
本文實(shí)驗(yàn)共需要兩類數(shù)據(jù)樣本,一類是規(guī)模較大、包含多種類型的通用集樣本,用于訓(xùn)練和測試通用模型,以及提取字符結(jié)構(gòu)信息;另一類是規(guī)模較小、類型單一的適應(yīng)集樣本,用于訓(xùn)練和測試專用模型。
通用集樣本方面,由于目前維文識別文獻(xiàn)中主要采用的傳統(tǒng)預(yù)切分識別方法,都是以單字符圖像樣本數(shù)據(jù)庫為主,所以尚無統(tǒng)一的標(biāo)準(zhǔn)維吾爾文文檔樣本數(shù)據(jù)庫。為此,本文專門制作了 THOCRUy360數(shù)據(jù)庫,其內(nèi)容來源于《塔里木》雜志社的官方網(wǎng)站[18]。選取的維文語料被整理為360頁文檔,用激光打印機(jī)印刷成ALKATIP的Basma, Kitab,Journal, Tor和UKIJ的Tuzb這5種常用字體,如圖3的前5行所示,并根據(jù)維文文檔字號偏小的特點(diǎn),選擇10號字印刷。然后,再用掃描儀以300 dpi的分辨率進(jìn)行掃描,經(jīng)過閾值化和行切分處理后,每種字體就可以得到 7887張文本行圖像,包含264583個字符。

圖3 本文實(shí)驗(yàn)所用的維文文本行樣本字體類型示例
適應(yīng)集樣本方面,直接使用真實(shí)的《中共中央關(guān)于制定國民經(jīng)濟(jì)和社會發(fā)展第十二個五年規(guī)劃的建議》(維文版)書籍掃描圖像作為樣本,如圖 3的最后一行所示,并請維文專家給出相應(yīng)的內(nèi)容標(biāo)注。從圖中可以看出,實(shí)際書籍所采用的字體與通用集中的5種字體均不相同,主要體現(xiàn)在文本行圖像的質(zhì)量、字符連接緊湊度、筆畫寬度、孔狀結(jié)構(gòu)尺度、某些字符形狀等多個方面。該樣本集包括 42頁文檔,采用與通用集樣本相同的閾值化和行切分方法。按照文獻(xiàn)[8]中的建議,僅選取正文的字體類型,而不考慮標(biāo)題等極少的特殊字體。于是,最終的適應(yīng)集樣本共包含1075個文本行圖像、55363個字符。
另外,本文實(shí)驗(yàn)樣本數(shù)據(jù)覆蓋維文字母105種、數(shù)字10種、各類標(biāo)點(diǎn)符號14種,共129種字符基元。
4.2 通用樣本的字符結(jié)構(gòu)信息驗(yàn)證實(shí)驗(yàn)
本小節(jié)實(shí)驗(yàn)在通用集樣本上進(jìn)行,需要將5種字體的文本行樣本在內(nèi)容相同的前提下,隨機(jī)按照70%(5523行,185349字符),15%(1182行,39622字符),15%(1182行,39612字符)的比例進(jìn)行劃分,分別作為訓(xùn)練集、驗(yàn)證集和測試集。
為了形象地說明字符結(jié)構(gòu)信息提取原理,這里以單字體Basma識別系統(tǒng)下維文字符“NG”圖像為例,將其觀測序列進(jìn)行狀態(tài)強(qiáng)制對準(zhǔn),并在對應(yīng)的圖像中標(biāo)記出狀態(tài)跳轉(zhuǎn)的位置,展示當(dāng)前模型的狀態(tài)分配情況。模型的起始狀態(tài)數(shù)被設(shè)置為15,均為單高斯模型。由于狀態(tài)數(shù)量冗余,所以經(jīng)過初始化后,狀態(tài)分配十分零碎。不過,每個狀態(tài)都被用于描述一種明確的字符局部結(jié)構(gòu),如圖 4(a)。經(jīng)過狀態(tài)典型性優(yōu)化后,描述字符中間尖端部分的3個狀態(tài)會被去除,僅留下必要的典型狀態(tài),如圖4(b)。隨后,狀態(tài)鑒別性優(yōu)化將模型精簡為10個狀態(tài),它們彼此之間都具有明顯的差異性,如圖 4(c)。隨著混合高斯數(shù)的增長,模型狀態(tài)數(shù)也會進(jìn)一步減小直至穩(wěn)定。再經(jīng)過嵌入式訓(xùn)練,最終模型的狀態(tài)分配如圖 4(d)所示。可見,HMM 狀態(tài)中所包含的結(jié)構(gòu)信息,既對應(yīng)著2維字符圖像所具有的局部結(jié)構(gòu),也符合狀態(tài)是觀測聚類的物理意義。
下面,本文將比較幾個識別系統(tǒng)在5種字體測試集上的性能,它們分別是5種字體樣本分別直接訓(xùn)練得到的“單字體基線系統(tǒng)”,5種字體樣本混合后直接訓(xùn)練得到的“多字體基線系統(tǒng)”,以及采用本文基于字符結(jié)構(gòu)信息的模型優(yōu)化方法所得到“單字體優(yōu)化系統(tǒng)”和“多字體優(yōu)化系統(tǒng)”,相關(guān)測試結(jié)果如表1所示。
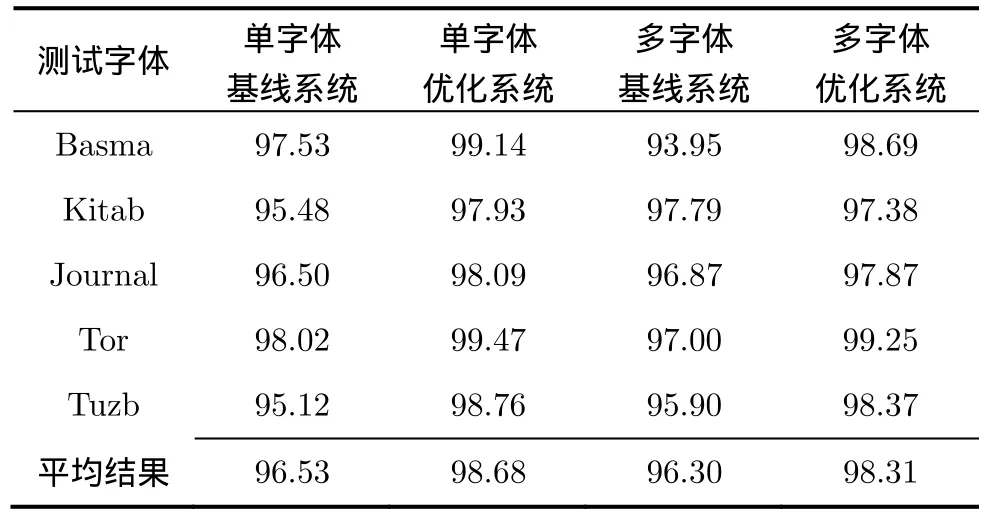
表 1 不同識別系統(tǒng)在通用樣本測試集上的識別準(zhǔn)確率評價(jià)結(jié)果(%)
對于兩個基線識別系統(tǒng),它們均采用狀態(tài)數(shù)一致的HMM建立基元模型,并通過在驗(yàn)證集上的系統(tǒng)識別性能來選擇最佳的狀態(tài)數(shù)。通過結(jié)果比較可以看出,前者使用單一類型的訓(xùn)練樣本能保證穩(wěn)定的識別性能,但是未經(jīng)優(yōu)化的HMM模型結(jié)構(gòu)會使其對字符的描述能力受到限制;而后者雖然出現(xiàn)模型偏離個別字體的情況,如Basma, Tor,但在其他字體上的識別性能卻會出現(xiàn)反超,如Kitab, Journal,Tuzb,這說明不同字體間確實(shí)存在某種可以被共享的信息,但直接混合多字體樣本的方法是不能有效利用這種信息的。
對于兩個優(yōu)化識別系統(tǒng),它們均采用了本文方法對模型結(jié)構(gòu)和參數(shù)進(jìn)行聯(lián)合優(yōu)化。由于多字體優(yōu)化系統(tǒng)能夠共享5種字體之間的共性字符結(jié)構(gòu),提高字符模型在多字體樣本融合中的準(zhǔn)確性,因而其識別性能要優(yōu)于多字體基線系統(tǒng),甚至是單字體基線系統(tǒng)。這不僅說明了多字體樣本之間所共享的正是共性的字符結(jié)構(gòu)信息,也驗(yàn)證了本文提取字符結(jié)構(gòu)信息方法的有效性。另外,單字體優(yōu)化系統(tǒng)表現(xiàn)出了最好的識別性能,這也說明在訓(xùn)練樣本充足的情況下,還是應(yīng)當(dāng)優(yōu)先考慮建立單字體的專用識別系統(tǒng)。

圖4 單字體識別系統(tǒng)中維文字符“NG”在不同模型下的狀態(tài)強(qiáng)制對準(zhǔn)結(jié)果
此外,為了更加直觀地說明不同字體之間共享字符結(jié)構(gòu)信息的效果,下面再次以維文字符“NG”為例,在多字體基線系統(tǒng)和優(yōu)化系統(tǒng)下,分別對 5種字體的該字符圖像進(jìn)行狀態(tài)強(qiáng)制對準(zhǔn)。可以看出,在基線系統(tǒng)中,狀態(tài)與觀測的對準(zhǔn)匹配關(guān)系相對雜亂,而且冗余程度較高,如圖 5(a)所示。而在優(yōu)化系統(tǒng)中,雖然不同字體的圖像觀測存在變化風(fēng)格上的差異,但各個狀態(tài)都能對準(zhǔn)匹配到相似的字符結(jié)構(gòu)上,如圖5(b)所示。因此,本文方法的“借數(shù)據(jù)”思路能為HMM自適應(yīng)訓(xùn)練,提供更加豐富且穩(wěn)健的字符結(jié)構(gòu)先驗(yàn)知識。
4.3 低數(shù)據(jù)資源條件下的字符建模實(shí)驗(yàn)
本小節(jié)實(shí)驗(yàn)需要將適應(yīng)集樣本劃分為 4個子集,~分別對應(yīng)書籍1~10頁(253行,~13116字符),1120頁(266行,13594字符),2130頁(257行,13321字符),31~42頁(299行,15332字符)的內(nèi)容。4.3.1不同樣本規(guī)模下字符建模方法對比實(shí)驗(yàn) 為了研究低資源樣本對字符建模方法的影響,從前3個子集中選取1個、2個和3個子集,它們的規(guī)模分別約為通用模型訓(xùn)練集的1/14, 1/7, 1/5。其中,隨機(jī)抽取90%的文本行樣本作為訓(xùn)練集,剩下的10%作為驗(yàn)證集。然后,將4號子集作為測試集,用于比較不同識別系統(tǒng)的性能,實(shí)驗(yàn)結(jié)果如表2所示。
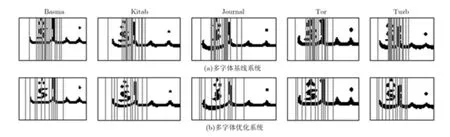
圖5 5種字體的維文字符“NG”在不同模型下的狀態(tài)強(qiáng)制對準(zhǔn)結(jié)果
第1, 2列結(jié)果來自于新字體的基線系統(tǒng)和優(yōu)化系統(tǒng),它們只利用適應(yīng)集中的新樣本來訓(xùn)練新模型。由于樣本規(guī)模很小,所以性能都不是很高。但經(jīng)過字符結(jié)構(gòu)優(yōu)化的系統(tǒng),其識別性能要明顯優(yōu)于基線系統(tǒng)。第3, 4列結(jié)果來自于上一小節(jié)中多字體的基線系統(tǒng)和優(yōu)化系統(tǒng)。由于它們并沒有使用新字體的樣本訓(xùn)練過,所以其識別性能降低至80%左右。第5, 6列結(jié)果對應(yīng)的系統(tǒng),是用MAP方法對兩個多字體系統(tǒng)進(jìn)行自適應(yīng)訓(xùn)練所得到的。由于優(yōu)化系統(tǒng)的模型能更準(zhǔn)確地描述字符結(jié)構(gòu),所以自適應(yīng)優(yōu)化系統(tǒng)的識別性能也要高于自適應(yīng)基線系統(tǒng)4%~5%。而第7列結(jié)果來自于本文方法所得到的系統(tǒng),其識別性能在3種設(shè)置下均超過90%,高于采用MAP方法自適應(yīng)所得到的兩個系統(tǒng),再次說明字符結(jié)構(gòu)信息對于字符建模的重要作用。
4.3.2 模型遷移學(xué)習(xí)性能交叉驗(yàn)證實(shí)驗(yàn) 為了更加準(zhǔn)確地評估上述幾種識別系統(tǒng)的性能,這里對表 2中第3種數(shù)據(jù)集設(shè)置進(jìn)行交叉驗(yàn)證實(shí)驗(yàn),即輪流將4個子集中的1個作為測試集,其余3個子集則用于訓(xùn)練和驗(yàn)證,實(shí)驗(yàn)結(jié)果如表3所示。

表 2 不同樣本規(guī)模下各系統(tǒng)對適應(yīng)集測試樣本的識別準(zhǔn)確率評價(jià)結(jié)果(%)

表 3 各系統(tǒng)對適應(yīng)集測試樣本的識別準(zhǔn)確率交叉驗(yàn)證結(jié)果(%)
通過橫向比較可以看出,本文方法所得系統(tǒng)的識別性能最高,在測試集上的平均識別準(zhǔn)確率為95.05%,能夠?qū)崿F(xiàn)對新字體類型的高性能識別。同時(shí),相比于新字體優(yōu)化系統(tǒng)、自適應(yīng)優(yōu)化系統(tǒng),它在平均識別準(zhǔn)確率上也有 1.55%和 6.24%的提高,即識別錯誤率相對降低 23.85%和 55.76%,證明了本文方法的有效性。
5 結(jié)束語
低數(shù)據(jù)資源條件下的字符建模問題,是當(dāng)前無切分文檔識別領(lǐng)域中的一個重要研究方向,與實(shí)際應(yīng)用中的樣本規(guī)模限制密切相關(guān)。因此,本文提出了一種向相對穩(wěn)定的字符結(jié)構(gòu)“借數(shù)據(jù)”、向低資源樣本的切分標(biāo)注估計(jì)結(jié)果“要數(shù)據(jù)”的方法。通過對自制樣本和實(shí)際書籍樣本的識別測試實(shí)驗(yàn)可以說明,該方法能夠有效解決低數(shù)據(jù)資源條件下,維文字符建模所存在的關(guān)鍵問題,對提高無切分維文文檔識別系統(tǒng)在新樣本類型的適用性上具有重要意義。同時(shí),我們后續(xù)也會嘗試將該方法應(yīng)用于其他民族文字的識別任務(wù)中。
[1] 錢彥旻. 低數(shù)據(jù)資源條件下的語音識別技術(shù)新方法研究[D].[博士論文], 清華大學(xué), 2012: 67-85.Qian Yan-min. Study on new speech recognition technology under low data resource conditions[D]. [Ph.D. dissertation],Tsinghua University, 2012: 67-85.
[2] 錢彥旻, 劉加. 低數(shù)據(jù)資源條件下基于優(yōu)化的數(shù)據(jù)選擇策略的無監(jiān)督語音識別聲學(xué)建模[J]. 清華大學(xué)學(xué)報(bào)(自然科學(xué)版),2013, 53(7): 1001-1004.Qian Yan-min and Liu Jia. Optimized data selection strategy based unsupervised acoustic modeling for low data resource speech recognition[J]. Journal of Tsinghua University(Science and Technology), 2013, 53(7): 1001-1004.
[3] Gunter S and Bunke H. Optimizing the number of states,training iterations and Gaussians in an HMM-based handwritten word recognizer[C]. 7th International Conference on Document Analysis and Recognition (ICDAR), Edinburgh,Scotland, UK, 2003: 472-476.
[4] Geiger J, Schenk J, Wallhoff F, et al.. Optimizing the number of states for HMM-based on-line handwritten whiteboard recognition[C]. 12th International Conference on Frontiers in Handwriting Recognition (ICFHR), Kolkata, India, 2010:107-112.
[5] Qing H, Chan C, and Chin-Hui L. Bayesian learning of the SCHMM parameters for speech recognition[C]. IEEE 19th International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Adelaide, USA, 1994, I: 221-224.
[6] Leggetter C J and Woodland P C. Maximum likelihood linear regression for speaker adaptation of continuous density hidden Markov models[J]. Computer Speech & Language,1995, 9(2): 171-185.
[7] 劉杰. 序列模型中的遷移學(xué)習(xí)研究[D]. [博士論文], 南開大學(xué)計(jì)算機(jī)與控制工程學(xué)院, 2008: 66-89.Liu Jie. Research on transfer learning on sequence model[D].[Ph.D. dissertation], Nankai University, 2008: 66-89.
[8] Ait-Mohand K, Paquet T, and Ragot N. Combining structure and parameter adaptation of HMMs for printed text recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(9): 1716-1732.
[9] Ait-Mohand K, Paquet T, Ragot N, et al.. Structure adaptation of HMM applied to OCR[C]. 20th International Conference on Pattern Recognition (ICPR), Istanbul, Turkey,2010: 2877-2880.
[10] Jiang Zhi-wei, Ding Xiao-qing, Peng Liang-rui, et al..Analyzing the information entropy of states to optimize the number of states in an HMM-based off-line handwritten Arabic word recognizer[C]. 21st International Conference on Pattern Recognition, Tsukuba, Japan, 2012: 697-700.
[11] 王歡良, 韓紀(jì)慶, 鄭鐵然. 高斯混合分布之間K-L散度的近似計(jì)算[J]. 自動化學(xué)報(bào), 2008, 34(5): 529-534.Wang Huan-liang, Han Ji-qing, and Zheng Tie-ran.Approximation of Kullback-Leibler divergence between two Gaussian mixture distributions[J]. Acta Automatica Sinica,2008, 34(5): 529-534.
[12] Bicego M, Murino V, and Figueiredo M A T. A sequential pruning strategy for the selection of the number of states in hidden Markov models[J]. Pattern Recognition Letters, 2003,24(9): 1395-1407.
[13] Seymore K, McCallum A, and Rosenfeld R. Learning hidden Markov model structure for information extraction[C].AAAI-99 Workshop on Machine Learning for Information Extraction, Orlando, USA, 1999: 37-42.
[14] Jiang Zhi-wei, Ding Xiao-qing, Peng Liang-rui, et al..Modified bootstrap approach with state number optimization for hidden Markov model estimation in small-size printed Arabic text-line recognition[C]. 10th International Conference on Machine Learning and Data Mining in Pattern Recognition, St. Petersburg, Russia, 2014: 437-441.
[15] Young S, Evermann G, Gales M, et al.. The HTK Book (for HTK Version 3.4)[M]. Cambridge, UK, Cambridge University Engineering Department, 2009: 97-147.
[16] Cambridge University Engineering Department. Hidden Markov Model Toolkit (HTK)[OL]. http://htk.eng.cam.ac.uk/.2014.
[17] Al-Hajj M R, Likforman-Sulem L, and Mokbel C. Combining slanted-frame classifiers for improved HMM-based Arabic handwriting recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(7): 1165-1177.
[18] Official website of magazine “Tarim”[OL]. http://www.tarimweb.com/index.html. 2014.
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中華詩詞(2019年7期)2019-11-25 01:43:04
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
