網絡輿情分析系統中的支撐技術研究
2015-12-14 01:48:03王君澤方醒杜洪濤
現代情報 2015年8期
王君澤++方醒++杜洪濤


〔摘要〕網絡輿情分析領域已經吸引了研究人員的關注并產生了諸多成果。本文對于近年來網絡輿情分析領域的相關研究進行梳理,同時對現有網絡輿情分析系統的架構進行剖析,對其中的數據采集、數據預處理、數據分析以及輿情展示等部分的支撐技術進行分析,并對網絡輿情分析系統的發展方向進行探討。
〔關鍵詞〕網絡輿情;輿情分析;系統框架
〔摘要〕網絡輿情分析領域已經吸引了研究人員的關注并產生了諸多成果。本文對于近年來網絡輿情分析領域的相關研究進行梳理,同時對現有網絡輿情分析系統的架構進行剖析,對其中的數據采集、數據預處理、數據分析以及輿情展示等部分的支撐技術進行分析,并對網絡輿情分析系統的發展方向進行探討。
〔關鍵詞〕網絡輿情;輿情分析;系統框架
DOI:10.3969/j.issn.1008-0821.2015.08.011
〔中圖分類號〕G2062;TP391〔文獻標識碼〕A〔文章編號〕1008-0821(2015)08-0051-06
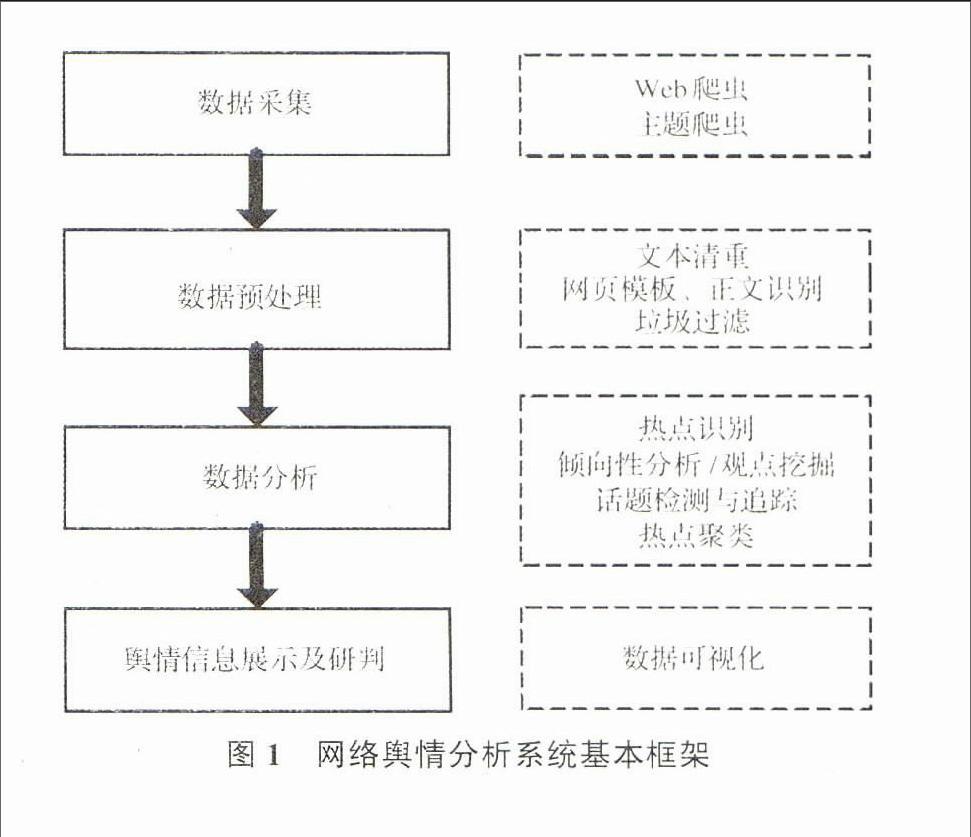
隨著網絡媒體的日益發達和網民數量的不斷增加,互聯網已經成為民意表達的重要空間。為了有效利用互聯網,將其作為政府治國理政、了解社情民意的新平臺,需要及時發現、分析、管理網絡輿情。而網絡輿情分析技術正是解決該問題的關鍵之一。本文對于近年來的網絡輿情分析領域的相關研究進行梳理,同時對現有網絡輿情分析系統的架構(圖1)進行剖析,分析其中的支撐技術,并對網絡輿情分析系統的發展方向進行探討。
1數據采集與數據預處理
11數據采集
數據采集是網絡輿情分析的基礎。該部分的主要功能
是借助Web爬蟲,從互聯網上獲取網頁數據。傳統的通用型Web爬蟲、分布式爬蟲和主題爬蟲等是網絡輿情數據采集的主要技術力量。分布式爬蟲和主題爬蟲技術的應用是網絡信息膨脹的結果。目前網絡信息膨脹,具體表現為信息源激增、信息發布量快速增長、信息內容種類多樣化等。膨脹的網絡信息對網絡數據的采集提出更高的要求。分布式爬蟲可以對數據采集任務進行高效的任務分割,并且可以通過系統規模的動態擴展,保證網頁信息的實時獲取。主題爬蟲[3]能夠選擇性地采集主題相關頁面,以降低帶寬的消耗以及計算和存儲的資源。主題爬蟲的難點在于如何對主題建模、如何判定頁面與主題的相關性以及如何在一個爬蟲系統中容納不同的主題爬蟲等[4]。
12數據預處理
數據預處理是指從網頁文本中抽取對網絡輿情分析有價值的信息,其中主要使用到的技術包括Web數據抽取、網頁相似性識別等。
Web數據抽取(Web Data Extraction)通過識別網頁文本的html結構抽取出新聞或網帖的標題、正文、發布時間、回復信息等不同的部分。當前在Web數據抽取領域廣泛采用的技術是網頁包裝(Wrapping)[5],其中抽取方法[6]和Wrapper的自動或半自動化生成工具是網頁包裝研究的重點對象。抽取方法主要包括直接解析[7]、HTML結構分析[8-9]和數據建模[10-11]等。此外,新的Web數據抽取數據策略也不斷涌現,如微軟亞洲研究院的Cai等人提出VIPS算法,利用網頁的視覺特征來抽取信息[12]。需要指出的是,Web數據抽取方法的可操作性和實用性受到不同網站排版方式的差異程度和變動頻次等因素的影響。
相似網頁識別也是數據預處理階段的重要技術。相似網頁識別最初應用在網頁消重領域[13-16],即對內容重復的網頁進行識別、處理和合并。在搜索引擎等應用中,網頁消重可以節省網頁數據庫的存儲空間和在網頁數據庫上進行操作的時間的過程。而在網絡輿情分析系統中,該技術主要用于判斷某條新聞或網帖被轉載的次數,同時建立信息的轉載軌跡,進而識別熱點信息,實現對信息的溯源。
輿情數據分析
數據分析是網絡輿情分析系統的核心部分。數據分析的目的是通過跟蹤特定時期內集中反應特定社會熱點問題的網絡輿情信息,掌握輿情產生、變化和衰落的趨勢或規律,深度分析網絡輿情隨時間的發展趨勢情況,進而實現對輿情環境的監測與預警[17]。高質量的數據分析組件需廣泛借鑒自然語言處理領域以及數據挖掘方面的成果,包括情感分析、話題檢測與追蹤、多文本摘要、熱點識別等,以完成輿情的語義識別和知識發現。如網絡輿情的總體概括的描述性信息可以借助情感分析技術在網絡輿情信息文本挖掘的優勢中得到,而網絡輿情熱點、焦點信息的自動發現則有賴于網絡信息的主題檢測和追蹤技術。總的來看,學界對網絡輿情數據分析組件的研究主要集中在以下幾個方面:
21語義分析及數據挖掘
輿情分析的效果在很大程度上依賴于對原始網頁的文本的語義理解能力,其中又涉及中文分詞、詞性標注、指代消解、新詞識別、人名消歧等技術。在中文分詞領域,經過多年的發展,尤其是2003年首屆國際中文分詞評測[18]開展以來,已經取得諸多成果。中國科學院計算技術研究所在多年研究工作積累的基礎上,研制出漢語詞法分析系統ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System),主要功能包括中文分詞、詞性標注等[19]。為提升語義分析的效果,命名實體識別[20]、指代消解[21]、人名消歧[22]等諸多技術往往被綜合使用。
22情感分析及觀點識別
情感分析是數據挖掘和計算機語言學的分支,能夠對各種新聞資源、社會媒體評論和其他用戶生成內容進行提取、分析、處理、歸納和推理[23]。針對網絡文本進行情感分析,有助于輿情分析人員明確網絡傳播者的意圖和傾向。文本情感分析研究早期的工作主要集中在詞語級別的語義傾向計算和文檔級別的文本情感分類方面。如Kim通過分析大量美國大選時的網絡新聞評論,來推斷大部分選民是支持共和黨還是民主黨[24];Lin等人構造“巴以戰爭”評論分析系統來區分某一評論是支持巴方還是支持以方[25]。該領域的快速發展是2006年以來美國標準與技術研究院組織的多次國際性觀點檢索(Opinion Retrieval)評測比賽推動的結果[26-27]。近年來該領域的研究者開始將精力放到獲得更細粒度結果的研究方向上如細粒度的觀點挖掘、情感分類器的領域移植和情感摘要等[28-29]。部分研究人員嘗試對用戶的觀點進行分解或摘要[30-31],并提出Opinosis等基于圖的觀點摘要技術[32]和OPINIONCLOUD等觀點摘要和可視化技術[33]。全局序列模型(Global Sequence Model)、條件隨機場(Conditional Random Fields)等技術也被用于識別用戶情感[34-36]。endprint
情感分析技術功能的實現和優化依賴于情感詞語料庫的完備性。情感詞是指帶有情感傾向性的詞語。Turney提出從大規模語料中,利用一個詞與具有強烈正面傾向的種子詞集合中詞語的互信息,減去這個詞與具有強烈負面傾向的種子詞集合中詞語的互信息,計算這個詞語的情感傾向性[37]。通過類似上述的詞語情感傾向性識別策略,可以構建情感詞語料庫。目前文本情感語料庫的建設方面,已有的語料庫包括Pang語料庫[38]、Whissell語料庫[39]、Berardinelli電影評論語料庫[40]等。而有關中文情感詞匯方面的資源較少,基本采用人工的方法獲取。陳建美等人借助現有的詞典和語義網絡構建的將情感分為7大類20小類情感詞匯本體,共收錄17 156個情感詞匯[41];臺灣大學的研究人員的工作主要在于簡體中文情感極性詞典NTUSD的構建[42],知網(Hownet)則發布“情感分析用詞語集”[43]。此外,網絡輿情分析領域的特定需求對情感分析提出更高的要求,如對文本中蘊含的思想傾向進行分析(左派/右派),以掌握網民的思想流派等,其作為全新的課題,目前尚未看到公開的成果。
23話題探測與追蹤
話題檢測與跟蹤(Topic Detection and Tracking,TDT)是面向多語言文本和語音形式的新聞報道,完成報道邊界自動識別、鎖定和收集突發性新聞話題、跟蹤話題發展以及跨語言檢測與跟蹤等相關任務[44]。與EDT不同,TDT檢測與跟蹤的對象從特定時間和地點發生的事件擴展為具備更多相關性外延的話題,相應的理論與應用研究也同時從傳統對于事件的識別跨越到包含突發事件及其后續相關報道的話題檢測與跟蹤[45]。TDT的任務以及評測體系是由美國國防高級研究計劃局(DARPA)、馬薩諸塞大學(University of Massachusetts)、卡耐基-梅隆大學(Carnegie Mellon University)和Dragon Systems公司聯合制定和設計完成的。話題檢測與跟蹤技術有助于輿情分析人員把握輿情的源頭和演化脈絡,為研究如何完成新聞報道中自動收集、識別和鎖定特定話題、跟蹤話題發展等相關任務,美國國防高級研究計劃局等組織舉辦多次TDT評測比賽并取得一定的成果[46]。而針對網絡輿情事件的突發性,研究人員還利用話題檢測與跟蹤技術來探測新聞中的突發熱點事件[47]。
24熱點話題識別
網絡輿情熱點話題是網絡輿情深度分析模式和判據中的重要因素,也是社情民意的重要體現[48]。正確識別熱點話題對話題識別和趨勢預測具有重大影響。目前對熱點話題的識別方法可以分為詞頻分析方法、基于詞網絡關系的共詞分析方法、基于詞頻變化率的突發監測方法、基于短語差異的分析方法等[49-50]。Kleinberg提出突發監測算法[51],以重點關注那些相對增長率突然增長的詞,并認為話題的報道數量不是平滑增長,而是在不同水平之間躍遷,這種在一段時間內突然增長的詞即可能為熱點話題的表征詞;Zheng等人利用Aging Theory對BBS中的熱點話題進行識別,可以快速挖掘任意時間段內的熱點話題[52]。
25分類和聚類
文本分類和主題聚類技術也是網絡輿情分析中的主要手段。文本自動分類是在預定義的分類體系下,根據文本的特征(詞條或短語),將給定文本分配到一個或多個特定類別的過程。文本自動分類技術在信息過濾情報處理數字圖書館等領域已經有著廣泛應用。然而,互聯網文本數據以指數級增長并呈現出各種新特點,這給文本自動分類技術帶來了巨大挑戰,如短文本分類、多語言文本分類管理、數據集偏斜、多層分類、標注瓶頸等問題[53]。主題聚類主要通過對文本、查詢式等聚類對象進行基于機器學習的主題分析。將聚類對象轉換為基于主題的表示形式,以達到降低特征空間維度的目的,然后以主題表示為基礎進行對象的聚類分析,最后得到基于主題的聚類結果描述[54]。主題聚類可以對聚類特征進行主題或語義控制,對聚類對象進行維度約簡并對聚類的結果進行基于主題的描述。利用主題聚類技術,還可以對屬于同一個話題的所有信息進行聚類,以完成新話題的監測,為TDT算法提供支持。
3輿情信息展示及研判平臺
31輿情信息展示
信息可視化是指非空間數據的可視化。Card等將信息可視化定義為:“使用計算機支持、交互性的視覺表示法,對抽象數據進行表示,以增強認知”[55]。信息可視化是使用直觀的方式展現原始數據間的復雜關系、潛在信息以及發展趨勢。其目的是為更好地利用信息資源[56]。當前,輿情信息展示的常用形式主要有標簽云和關鍵詞關聯網絡模型。
標簽云是一套相關的標簽以及與此相應的權重,用以表示特定內容的標簽,并按照內容中的涉及的信息的重要性,確定標簽字體的醒目程度,以凸顯內容中的重要信息。下面以對“中國政府工作報告”的分析為例介紹,從圖2中可以看出,政府工作報告的重點在“社會主義”、“改革開放”、“市場”、“經濟”、“人民”、“教育”、“生產”等方面。利用標簽云這類信息可視化手段,可以直觀的掌握相應信息內容的重點。關鍵詞關聯網絡模型(圖3)也是輿情信息展示的重要手段。通過利用文本信息可視化模型,構建基于新聞文本內容構建專題新聞文本集的關鍵詞關聯網絡模型,能夠直觀展示事件動態發展變化過程、各主體的主要行為及其之間的關系以及人們關注點的變化,有利于分析人員快速了解事件動態。
圖2基于“中國政府工作報告”分析結果的標簽云圖3基于“朝鮮”相關信息的關鍵詞關聯網絡
32網絡輿情指標體系的建設
網絡輿情指標體系是網絡輿情研判的重要參考依據。網絡輿情指標體系可以用于衡量和評價網絡輿情熱度,通過權重計算能夠明確各個指標影響力大小,從而明確輿情漲落的深層次影響原因,為政府輿情控制、引導和預案制定提供理論依據[57]。針對輿情指標體系的研究已經產生諸多成果。如李雯靜等人根據網絡輿情的特點,從指標設計、分類、構建等方面,在網絡輿情信息匯集、分析、預警的工作流程中,按照主題將信息分門別類,統計、計算出若干指標值,對輿情進行橫向、縱向的監測和評估,篩選出有價值的信息,幫助輿情工作者對輿情突發事件進行研判及態勢預測[58];王青等人對現有網絡輿情監測指標體系進行整理與歸納,通過E-R模型系統分析主題輿情的屬性特征,構建更為科學系統的網絡輿情監測與預警指標體系。該指標體系從輿情熱度、輿情強度、輿情傾度、輿情生長度4個維度詮釋主題輿情的傳播范圍及程度、輿情主題內容強度、主題輿情生長規律及狀態、輿情受眾意見分布等網絡輿情監測與預警要素[59];曾潤喜利用層次分析法構建了警源、警兆、警情三類因素和現象的網絡輿情突發事件預警指標體系,并對影響這一指標體系的因素和現象進行排序,確定影響權重[60]。綜合來看,已有的網絡輿情指標體系不同程度上存在部分指標缺乏深度,部分指標難以評估,指標體系不完整以及對受眾的傾向關注不夠等問題[61]。endprint
4發展趨勢
網絡輿情參與者的行為建模將成為網絡輿情分析系統的重要關注點,以識別目前的意見領袖、網絡推手等特殊的輿情參與者。目前隨有研究者嘗試建立意見領袖識別模型和網絡推手識別模型[62-63],但僅從某些側面構建模型,而未有較為通用的模型,同時也未于輿情分析系統深度的結合,進而模型的實用性。
網絡輿情預測技術已得到研究者的關注,未來可能與輿情分析軟件進一步結合。如曾祥平等[64]、Naruse建立情感激勵模型來模擬回復量的變化情況,對于預測起到一定的借鑒作用[65]。Zeng等提出了一種基于隱馬爾科夫的網絡輿情預測模型,但是不能對網絡輿情突發事件進行預測[66]。在此基礎上,有學者充分嫩考慮到網絡輿情具有突現性,以突現計算的觀點將發帖人抽象成Agent[67]。因此,網絡輿情預測技術的不斷成熟將大大提高其在輿情分析系統中的實用性。
輿情預警功能的優化也是未來輿情分析系統研究的重點。網絡輿情監管功能的實現有賴于各類敏感事件和輿情預警技術與輿情地圖、輿情預判和決策分析模擬系統、輿情隱患庫和預案庫等的有效結合。目前在預警防控平臺方面已有一些研究成果。如文獻[68]構建SD因果關系模型,研究了非常規突發事件應急決策系統各子系統間反饋機制和相互耦合機制以及應急決策動態調整機理;文獻[69]在平行系統基本思想的基礎上,采用多智能體技術構建人工社會以實現模擬仿真的方法,以作為社會問題模擬仿真研究的重要途徑。但相關的研究成果如何與輿情分析系統相結合,也是亟須解決的問題。
參考文獻
王國華,曾潤喜,方付建.解碼網絡輿情[M].武漢:華中科技大學出版社,2011.
Paolo B.,Bruno C.,Massimo S.et al.UbiCrawler:a scalable fully distributed Web crawler[J].Software:Practice and Experience,2004,34(8):711-726.
[3]Soumen C.,Martin B.,Byron D.Focused crawling:a new approach to topic-specific Web resource discovery[J].Computer Networks,1999,31(16):1623-1640.
[4]白鶴,湯迪斌,王勁林.分布式多主題網絡爬蟲系統的研究與實現[J].計算機工程,2009,35(19):13-16.
[5]Laender F.,Ribeiro B.,Silva A.et al.A brief survey of Web data extraction tools[C].ACM SIGMOD Record,2002,31(2):84-93.
[6]Eikvil L.Information Extraction from World Wide Web——A Survey[R].1999.
[7]Wang J.and Lochovsky F.Data-rich section extraction from HTML pages[C].Proc of the 3rd Intl.Conf.on Web Information System Engineering,2002:2313-2322.
[8]Myllymaki J.Effective Web Data Extraction with Standard XML Technologies[J].Computer Networks,2002,39(5):634-644.
[9]Sahuguet A.and Azavant F.Looking at the Web through XML glasses[C].Proc of the 4th Intl.Conf.on Cooperative Information System,1999:148-159.
[10]Snoussi H.,Magini L.and Nie J.Toward an Ontology-based Web Data Extraction[C].Proc of Intl.Conf.on Business Agents and the Semantic Web,2002.
[11]Embley D.,Campbell Y.,Liddle S.et al.A conceptual-Modeling Approach to Extracting Data from the Web[C].Proc.of the 17th Intl.Conf.on Conceptual Modeling,1998.
[12]Cai D.,Yu S.,Wen J.et al.VIPS:a vision based page segmentation algorithm[R],2007.
[13]Fetterly D.,Manasse M.and Najork M.On the evolution of clusters of near-duplicate web pages[J].Journal of Web Engineering archive,2003,2(4):228-246.
[14]Henzinger M.Finding near-duplicate web pages:a large-scale evaluation of algorithms[C].Proc.of the 29th Intl.Conf.on Research and development in information retrieval,2006:284-291.endprint
[15]Manku GS.,Jain A.,Sarma AD..Detecting Near-Duplicates for Web Crawling[C].Proceedings of the 16th International Conference on World Wide Web,2007:141-150.
[16]Li W,Liu J,Wang C.Web document duplicate removal algorithm based on key word sequences[C].Natural Language Processing and Knowledge Engineering,2005:511-516.
[17]黃曉斌,趙超.文本挖掘在網絡輿情信息分析中的應用[J].情報科學,2009,27(1):94-99.
[18]Sproat R.and Emerson T.The First International Chinese Word Segmentation Bakeoff[C].Proc.of the 2nd SIGHAN Workshop on Chinese Language Processing,2003:133-143.
[19]Zhang H.,Yu H.,Xiong D.et al.HHMM-based Chinese lexical analyzer ICTCLAS[C].Proc.of the 2nd SIGHAN workshop on Chinese language processing,2003:184-187.
[20]Florian R.,Ittycheriah A.,Jing H.et al.Named entity recognition through classifier combination[C].Proc.of the 7th Intl.Conf.on Natural language learning at HLT-NAACL,2003:168-171.
[21]Impedovo S,Ottaviano L.,and Occhinegro S.Optical character recognition-a survey[J].International Journal of Pattern Recognition and Artificial Intelligence,1991,5(1-2):1-24.
[22]Gideon S.and David Y.Unsupervised personal name disambiguation[J].Proc.of the 7th Conf.on Natural language learning at HLT-NAACL,2003:33-40.
[23]Kim S.and Hovy E.Detemining the sentiment of opinions[C].Proc of the 20th Intl.Conf.on Computational Linguistics,2004:1367-1373.
[24]Kim M.and Hovy E.Crystal:Analyzing Predictive Opinions on the Web[C].Proc.of the Joint Conf.on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2007:1056-1064.
[25]Lin H.,Wilson T.,and Wiebe J.Which Side Are You On?Identifying perspectives at the document and sentence levels[C].Proc.of the Conf.on Natural Language Learning,2006:109-116.
[26]Macdonald C.,Ounis I.,and Soboroff I.Overview of the TREC 2007 Blog Track[C].In TREC 2007 Working Notes,2007:31-43.
[27]Xu X.,Tan S.,Liu Y.et al.Find Me Opinion Sources in Blogosphere:A Unified Framework for Opinionated Blog Feed Retrieval[C].Proc.of the Conf.on Web Search and Data Mining,2012:583-592.
[28]Thelwall M.,Buckley K.,and Paltoglou G.Sentiment Strength Detection for the Social Web[J].Journal of the American Society for Information Science and Technology,2012,63(1):163-173.
[29]Wilson T,Wiebe J,and Hoffmann P.Recognizing contextual polarity in phrase-level sentiment analysis[C].Proc.of Conf.on Human Language Technologies and Empirical Methods in Natural Language Processing,2005:347-354.endprint
[30]Lu Y.,Zhai C.,and Sundaresan N.Rated aspect summarization of short comments[C].Proc.of the 18th Intl.Conf.on World Wide Web,2009:131-140.
[31]Leung C.,Chan S.,Chung F.et al.A probabilistic rating inference framework for mining user preferences from reviews[J].World Wide Web,2011,14(2):187-215.
[32]Ganesan K.,Zhai C.,and Han J.Opinosis:A graph-based approach to abstractive summarization of highly redundant opinions[C].Proc.of the 23rd Intl.Conf.on Computational Linguistics,2010:340-348.
[33]Potthast M.and Becker S.Opinion summarization of web comments[C].Proc.of the 32nd European Conference on IR Research,2010:668-669.
[34]Choi Y.,Cardie C.,Riloff E.et al.Identifying sources of opinions with conditional random fields and extraction patterns[C].Proc.of Human Language Technology Conference and Conference on Empirical Methods in Natural Language,2005:355-362.
[35]Cui H.,Mittal V.,and Datar M.Comparative experiments on sentiment classification for online product reviews[C].Proc.of the 21st National Conference on Artificial Intelligence,2006:1265-1270.
[36]Mao Y.and Lebanon G.Isotonic conditional random fields and local sentiment flow[J].Advances in Neural Information Processing Systems,2007,(19):961-968.
[37]Peter T.Measuring praise and criticism:Inference of semantic orientation from association[J].ACM Transcation on Information Systems,2003,21(4):315-346.
[38]http:∥www.cs.cornell.edu/People/pabo/movie-review-data[DB/OL].
[39]Athanaselis T.,Bakamidis S.,and Dologlou I.Recognising verbal content of emotionally coloured speech[C].Proc of 14th Intl.Conf.on European Signal Processing Conference,2006.
[40]http:∥www.reelviews.net/[DB/OL].
[41]陳建美,林鴻飛,楊志豪.基于語法的情感詞匯自動獲取[J].智能系統學報,2009,4(2):100-106.
[42]Ku L.and Chen H.Mining Opinions from the Web:Beyond Relevance Retrieval[J].Journal of American Society for Information Science and Technology,2006,58(12):1838-1850.
[43]情感分析用詞語集[EB/OL].http:∥www.keenage.com/html/c-index.html.
[44]James A.,Jaime C.,George D.et al.Topic Detection and Tracking Pilot Study Final Report[C].Proc.of the Broadcast News Transcription and Understanding Workshop,1998.
[45]洪宇,張宇,劉挺,等.話題檢測與跟蹤的評測及研究綜述[J].中文信息學報,2007,21(6):71-87.
[46]He Q.,Chang K.,Lim EP.et al.Keep It Simple with Time:a Re-examination of Probabilistic Topic Detection Models[J].IEEE Transactions Pattern Analysis and Machine Intelligence,2010,32(10):1795-1808.endprint
[47]Li H.and Wei J.Netnews Bursty Hot Topic Detection Based on Bursty Features[C].Proc.of the Conf.on E-Business and E-Government,2010:1437-1440.
[48]謝海光,陳中潤.互聯網內容及輿情深度分析模式[J].中國青年政治學院學報,2006(3):95-100.
[49]魏曉俊.基于科技文獻中詞語的科技發展監測方法研究[J].情報雜志,2007,(3):34-39.
[50]Sun Q.,Wang Q.,and Qiao H.The Algorithm of Short Message Hot Topic Detection Based on Feature[J].Information Technology Journal,2009,8(2):236-240.
[51]Kleinberg J.Bursty and hierarchical structure in streams[J].Data Mining and Knowledge Discovery,2003,7(4):373-397.
[52]Zheng D.and Li F.Hot Topic Detection on BBS Using Aging Theory[J].Web Information Systems and Mining,2009:129-138.
[53]龐觀松,蔣盛益.文本自動分類技術研究綜述[J].情報理論與實踐,2012,35(2):123-128.
[54]許鑫,章成志.互聯網輿情分析及應用研究[J].情報科學,2008,26(8):1194-1200.
[55]Robertson G.,Card S,and Mackinlay J.The cognitive core processor for interactive user interfaces[C].Proc.of the ACM SIGGRAPH Symposium on User Interface Soft ware and Technology,1989:10-18.
[56]劉凱.信息可視化概念的深入探討[J].情報雜志,2004,(12):20-21.
[57]張一文,齊佳音,方濱興,等.非常規突發事件網絡輿情熱度評價指標體系構建[J].情報雜志,2010,(11):71-75,117.
[58]李雯靜,許鑫,陳正權.網絡輿情指標體系設計與分析[J].情報科學,2009,(7):986-991.
[59]王青,成穎,巢乃鵬.網絡輿情監測及預警指標體系構建研究[J].圖書情報工作,2011,(8):54-57,111.
[60]曾潤喜.網絡輿情突發事件預警指標體系構建[J].情報理論與實踐,2010,(1):77-80.
[61]王青,成穎,巢乃鵬.網絡輿情監測及預警指標體系研究綜述[J].情報科學,2011,(7):1104-1108.
[62]王君澤,王雅蕾,禹航,等.微博客意見領袖識別模型研究[J].新聞與傳播研究,2011,(6):81-88.
[63]李綱,甘停,寇廣增.基于文本情感分類的網絡推手識別[J].圖書情報工作,2010,54(8):77-80.
[64]曾祥平,方勇,袁媛,等.基于個體自動機的網絡輿論激勵模型[J].計算機應用,2007,27(11):2686-2688.
[65]Naruse K.Lognormal distribution of BBS article and its social and generative mechanism[C].Proc.of Intel.Conf.on Web intelligence,2006:103-112.
[66]Zeng X.,Zhang S.and Wu C.Predictive model for internet public opinion[C].Proc.of Conf.on fuzzy systems and knowledge discovery,2007.
[67]吳渝,楊濤,肖開洲.BBS突發輿情分析及基于小世界網絡的預測模型[J].重慶郵電大學學報:自然科學版,2011,(6):350-354.
[68]韓傳峰,王興廣,孔靜靜.非常規突發事件應急決策系統動態作用機理[J].軟科學,2009,(8):50-53.
[69]王飛躍,邱曉剛,曾大軍,等.基于平行系統的非常規突發事件計算實驗平臺研究[J].復雜系統與復雜性科學,2010,(12):1-10.
(本文責任編輯:孫國雷)endprint
