基于持續關注度衰減的重要論文預測
2015-12-19 09:16:24張美平尚明生
復雜系統與復雜性科學 2015年3期
張美平,尚明生
(電子科技大學互聯網科學中心,成都611731)
0 引言
如何評價科學家的影響力及論文的內在質量一直都是重要的研究課題[1]。基于總引用次數的評價方法最簡單但存在若干不足,為此Hirsch[2]提出了具有很強魯棒性的H指數。此后,Egghe[3]提出g指數用來解決H 指數存在的一些問題。文獻[4]提出帶權重的PageRank算法對科學家的影響力進行排名。文獻[5]基于數字圖書館的引證數據,以科學家合作網絡為研究對象,從網絡結構特性的角度對科學家進行評價。然而,這些研究大多僅依賴于論文當前的被引次數來評價一篇論文的受歡迎程度和權威性,從而對科學家進行評價,無法處理論文將來可能獲得大量引用的情況。因此,如何對論文的潛在重要性進行預測引起了大量學者的關注,已經提出很多算法,主要包括以下3個方面:
1)基于時間效應的方法。科學論文發表時總是會引用已經發表過的論文,因此論文引用次數是隨時間動態變化的累計增量。Medo等[6]通過分析論文引用隨時間的演化過程和偏好依附過程來挖掘論文的影響力,發現了論文的影響力隨著時間指數遞減的規律。文獻[7]基于引用存在的時間進行加權,為較新的引用賦予較高的權重。Walker等[8]的CiteRank算法優先訪問發表時間較近的論文。
2)基于論文多種信息融合的方法。與一般作者相比,領域權威作者所撰寫的論文更可能吸引同行的關注;被這些作者引用的論文,也更可能被其他人引用;而發表在影響力更高的期刊上的論文,會更有機會被其他工作者引用[9]。基于這些因素,研究者們運用論文的多種信息,如期刊、作者、領域等信息來更全面地預測論文被引變化趨勢。例如,文獻[10]利用論文、作者、期刊信息,為不同的引證邊賦權,提出一種運用于不同期刊的論文和作者的評價指標。文獻[11]利用HITS算法[12]的思想,通過作者-論文關系、論文-論文引用關系以及作者合作關系來動態評價論文的價值以及作者的權威度。此外,文獻[13]通過一個加強的泊松分布概率模型來預測論文被引用的動態特性。
3)時間衰減和多源信息融合集成的方法。論文的時間衰減因素通常也和論文的多源信息在一起被考慮。例如,文獻[14]依據施引論文所在雜志的影響因子以及引用時間,為引用鏈接賦予不同的權值,進而評價論文的價值。文獻[15]提出FutureRank算法,該算法基于HITS算法[12]與PageRank算法[16]考慮了論文的發表時間、作者權威度和論文當前的PageRank值,基于迭代運算預測論文未來的被引次數排名和PageRank值排名,較之前的算法取得了更好的預測準確度。
上述方法大多存在計算復雜或精確度不高的問題,本文通過對APS和arXiv兩個典型數據集的實證研究,發現論文未來引用數和論文的持續關注度密切相關,結合論文引用隨時間指數衰減的特性,設計了基于持續關注度衰減的重要論文預測方法。該方法具有預測準確率高,且復雜度低的特點。
1 基于持續關注度衰減的重要論文預測
對科學引文網絡的分析需建立在真實數據的研究上。為此,以兩個典型的引文網絡數據arXiv數據集和APS數據集為研究對象做實證分析和算法研究。其中,arXiv數據集取自arXiv中的高能物理理論引文網絡數據集,包含了1992年~2003年發表的所有高能物理論文。APS數據集取自美國物理學會出版的物理評論系列期刊的引用數據集。該數據集論文時間跨度為1893年-2009年,包含了APS系列所有期刊論文的引用關系數據。由于其各期刊的起始時間和數量等因素差別較大,在后續討論中,僅選取其中異質性較低的PRA、PRB、PRC、PRD和PRL期刊的相互引用關系數據進行實驗,簡稱為APS數據集。經過預處理后,兩個數據集的基本信息表如表1所示。

表1 數據集基本信息表Tab.1 Information of the two data sets
1.1 論文的持續關注度
論文發表以后,會有后續論文對其進行引用。這些引用行為反映出科研工作群體對某篇論文的關注程度,可以用論文的引用次數來刻畫論文的被關注度。一般而言,論文存在時間越長,被其他工作者關注到的機會就更多[17-18]。因為即使兩篇論文質量相當,發表時間長的論文通常會比近期發表的論文獲得更多的引用,也即被關注度越大。這樣,論文的被關注度是受到時間因素的影響的。為消除這種時間因素帶來的影響,本文提出論文持續關注度的概念,用來預測論文未來的被引用情況。論文的持續關注度定義為

其中,S為示論文獲得的持續關注度,cc為論文當前獲得的總被引用次數,tc為當前時間,tp為論文的發表時間,均以年為單位計算。
通過對APS和arXiv引文數據的實證分析發現,與論文當前總被引用次數相比,論文持續關注度更能體現論文未來的被引潛力。圖1a給出了arXiv數據集中論文2000年前的持續關注度與2000年后的持續關注度之間的相關性;圖1b顯示了相同情況下論文當前總被引次數與未來被引次數之間的相關性。可以看到,相比于圖1b,圖1a中的點更集中在對角線周圍,也就是相關度更高。事實上,持續關注度的相關系數為0.77,而總被引次數的相關系數為0.62,也就是說,論文的持續關注度更能刻畫論文未來的引用情況。對APS數據集的分析(見圖2),得到類似的結論,前者的相關系數為0.52,后者為0.38。
進一步,本文用持續關注度對論文的未來引用進行預測。圖3給出了僅用持續關注度排名來預測論文未來的被引次數排名的實驗結果:對前50篇論文,在arXiv數據集上精確率可達0.38,在APS數據集上為0.4。作為對比,如果用當前總被引次數來預測論文的未來排名,arXiv數據集上精確率僅為0.3,APS數據集為0.26。

圖1 arXiv中論文2000年前和2000年后的持續關注度的相關度和被引總數的相關度Fig.1 Relevance of the sustained attention and the total citations before 2000and after 2000in arXiv dataset
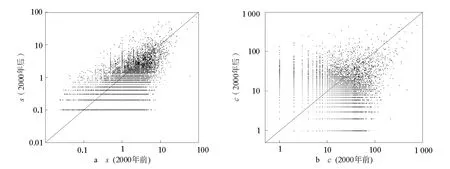
圖2 APS中論文2000年前和2000年后的持續關注度的相關度和被引總數的相關度Fig.2 Relevance of the sustained attention and the total citations before 2000and after 2000in APS dataset
1.2 論文的時間衰減效應
論文引用受時間衰減效應的影響已被大量學者的實證研究所證實[6-8]。通常情況下,一項研究成果問世之后,會受到很多同行工作者的關注,但隨著時間的推移,新的研究成果會涵蓋、完善甚至完全代替已有的研究成果,人們將會更關注這些新的研究成果。除非是開創性工作的論文或者非常經典的文獻,才會在經過很多年后依然被大量引用。事實上,我們對arXiv和APS引證數據集的實證研究也支持這一結論。
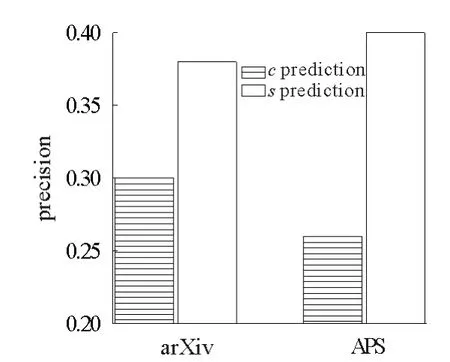
圖3 基于持續關注度和總被引數在預測論文未來引用排名的精確率比較Fig.3 Comparision of the predicted precision based on sustained attention and total citations
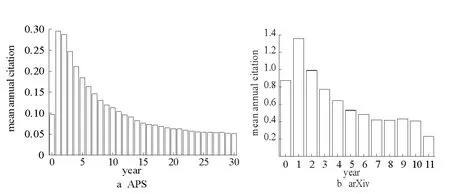
圖4 論文引用次數隨時間變化圖Fig.4 The citation vary over time
圖4給出了論文平均引用次數隨時間的變化情況,其中橫坐標是論文被引用的時間間隔,縱坐標是對應時間的論文平均被引次數。圖4a是APS數據集上1958年到1988年發表的論文在30年內的平均被引次數。可以看到,論文平均被引次數是隨時間呈負指數規律衰減的。圖4b給出了arXiv數據集上的所有論文引用數據的分析。由于arXiv數據集論文時間從1992年到2003年,時間跨度較短,我們統計了其11年的平均引用次數,得到了類似的結論。
1.3 基于持續關注度衰減的論文價值預測算法
通過前面的分析發現,論文的持續關注度體現了論文未來的被引潛力,與此同時,論文引用又呈現明顯的時間衰減特性,因此,我們考慮將上面兩個因素結合起來對論文未來被引情況進行預測。
沿用文獻[8]和[15]中刻畫時間衰減效應的指數函數:

其中,x為論文發表時間距離當前時間的年數,ρ為刻畫時間衰減程度的參數,其值越大則刻畫時間衰減因素權重越大,反之越小。
科學論文發表時,往往會基于不同的引證動機引用相關參考文獻。針對這些引用行為,從微觀角度同等對待每一條邊,僅基于時間為它們賦權則會有失偏頗;但是如果從宏觀角度將一篇論文某個時間周期的被引次數作為研究對象,就能降低相應的預測誤差。因此,與之前研究對每條引用連邊基于時間賦權不同,本文基于時間段為論文的持續關注度賦予不同的權重,進而預測論文未來的被引次數。具體計算公式為

其中,cf為論文未來引用的預測值,tc為當前時間,tp為論文發表時間,ct為該年的被引次數。
2 實驗及結果分析
為了驗證算法的預測效果,通過arXiv和APS兩個典型的引文數據集對算法進行評估。參考算法是目前預測效果最好的FutureRank算法[15],從算法對參數的敏感度、算法排名預測的準確率和全局的spearman秩相關系數值等3個方面進行對比。
2.1 實驗數據和設置
在算法驗證過程中,將ArXiv數據集分為兩部分:2000年以前的引用數據和2000年以后的引用數據,第1部分為訓練數據,第2部分為測試數據。算法的目的是預測論文未來的被引次數和PageRank值排名。其中,被引次數反映論文的流行度,PageRank值反映出論文的權威值[15]。APS數據劃分方式類似arXiv數據集,以2000年為分界點劃分數據集。兩個數據集經過劃分之后,基本信息如表2。
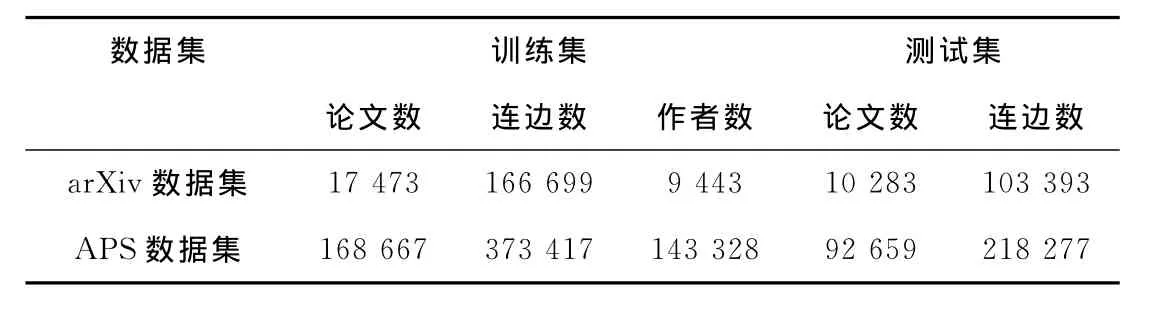
表2 實驗數據劃分信息表Tab.2 The training data and the test data
2.2 評價指標
2.2.1 精確率
精確率反映算法預測的準確性,定義為
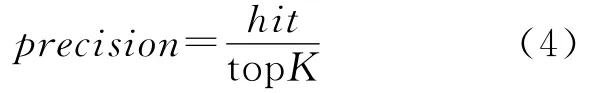
其中,hit=|預測排名topk∩真實排名topk|,精確率用來檢驗算法對排名靠前的論文的預測準確度。
2.2.2 spearman秩相關系數
計算算法預測的論文未來引用排名、PageRank值排名與論文未來實際排名的全局相關程度。假設測試集中的論文xi,yi按從大到小的順序排列,記x’i,y’i為xi,yi根據預測算法計算獲得的排名,則Spearman秩相關系數的計算即為秩次之間的Pearson的線性相關系數:
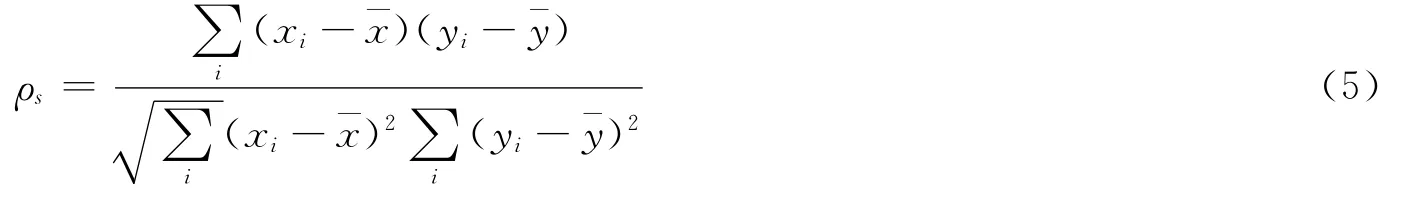
2.3 實驗結果及分析
2.3.1 參數敏感性分析
對本文算法中唯一的刻畫時間衰減程度的參數ρ,研究其不同取值對算法精度的影響。實驗中,不失一般性,topK取值為50(事實上,在實驗過程中發現,topK取其他值會得到同樣的結論)。
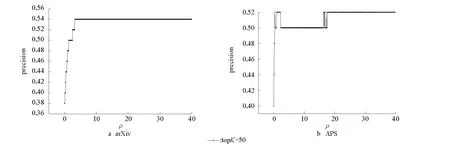
圖5 算法預測精度和參數的關系Fig.5 The precision varies over the parameter
圖5給出了在兩個不同的數據集上,參數ρ的不同取值對算法效果的影響。ρ從0取值到40,取值越大,則刻畫時間衰減因素的權重越大,反之越小。當ρ取0時,算法退化成僅用論文持續關注度進行預測,即不考慮時間衰減效應。在arXiv數據上,ρ取值在0到4時,算法效果逐漸提升,考慮時間效應確實大大提高算法預測精確率。此后,算法一直保持最優值,對算法參數不再敏感(見圖5a);在APS數據集上,ρ取值在0到1時,算法精度逐漸提高。取值大于1后,算法一直保持較高精度。在兩個不同的數據集上,算法對參數ρ在一定取值后就不再敏感,表現大體一致。需要說明的是,算法對ρ取值的不敏感不代表時間效應因素的不重要,因為曲線前期精確率有一個逐漸提升過程。
2.3.2 算法預測準確性比較
2.3.2.1 不同topK 下的算法精確率
進一步驗證算法在不同topK下的預測效果:固定ρ取值最優的情況下,變化topK計算算法精確率,比較本文算法與FutureRank算法[4]、Neman[19-20]提到的用z-score預測論文流行度的算法(僅用來預測論文的被引次數,不預測論文的PageRank值)的預測效果。
如圖6a所示,在APS數據集上,對基于持續關注度衰減算法(s-decay)取在topK為50時精確率最高的參數兩組ρ=2.2和ρ=25,對于FutureRank算法,也取topK 為50時精確率最高的參數兩組,futurerank_1(α=0.09,β=0.25,γ=0.66),futurerank_2(α=0.12,β=0,γ=0.88)。其中,α為論文當前的PageRank值的權重值,β為作者權威值的權重值,γ為時間效應權重值。由于訓練集有將近20萬篇論文,所以圖中topK取值為1~500。可以看到:z-score的預測結果最差,而基于持續關注度衰減算法在前70名精確率略微高于FutureRank算法,70名后遠優于FutureRank算法;基于持續關注度衰減算法在不同參數下,表現幾乎一樣,FutureRank算法不同參數表現差異比較大。PageRank值預測(見圖6b)中,前170名中兩種算法差別不大,但170名后,本文算法開始優于FutureRank算法,當topK取值為170到500時,基于持續關注度衰減算法已經遠優于FutureRank算法。
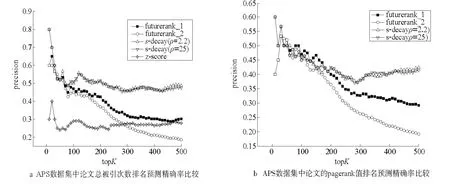
圖6 APS數據集的算法精確率比較Fig.6 Comparision of the precision in APS data set
由于arXiv數據的訓練集中只有將近2萬篇論文,所以圖中topK取值從1取到50。基于持續關注度衰減算法在arXiv數據集上ρ大于4后未出現波動情況(2.3.1節),所以只選取ρ=10這一組值,而FutureRank算法參數仍選擇兩組,futurerank_1(α=0.16,β=0.05,γ=0.79),futurerank_2(α=0.17,β=0,γ=0.83)。從圖7a可以看出,z-socre預測效果最差,基于持續關注度衰減算法在不同的topK下均優于FutureRank算法,尤其在20名之后遠優于FutureRank算法。圖7b顯示基于持續關注度衰減算法對論文PageRank值的預測相比于Future-Rank算法同樣能獲得更高的準確率。
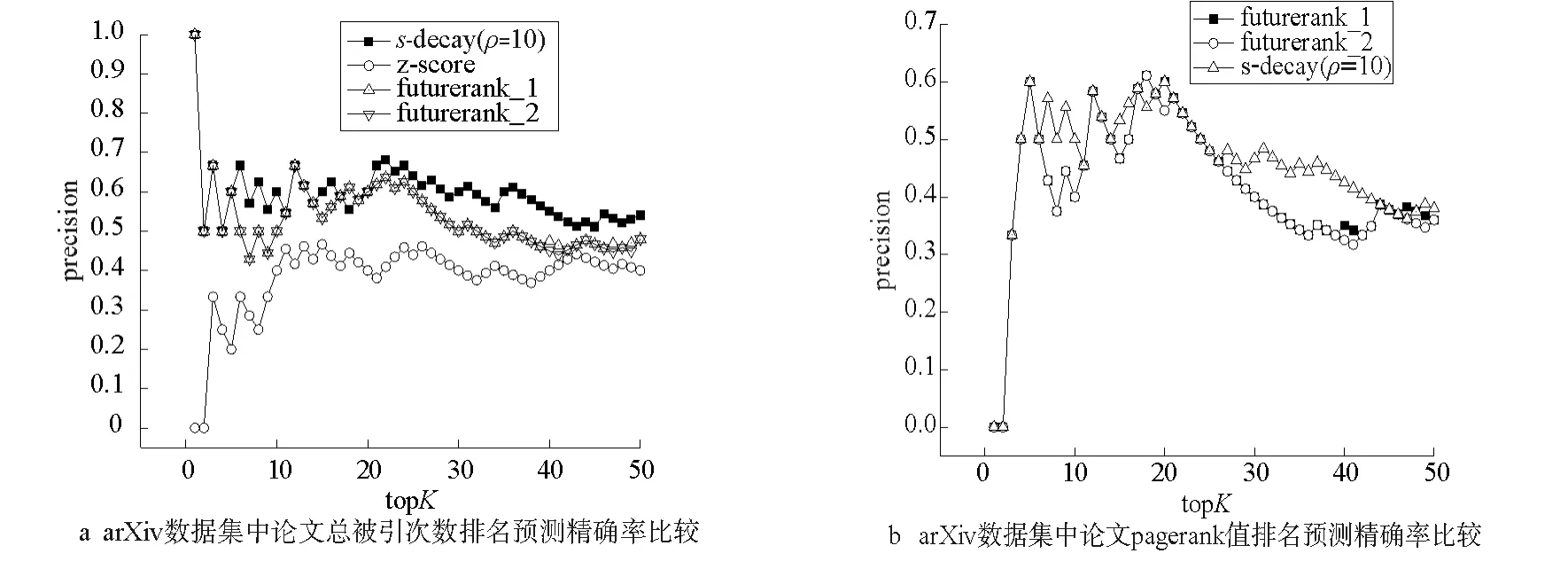
圖7 arXiv數據集的算法精確率比較Fig.7 Comparision of the precision in arXiv data set
2.3.2.2 spearman秩相關系數比較
為了驗證算法的全局排序效果,對比算法對所有論文的預測排名與其未來的真實排名的spearman秩相關系數。實驗結果如圖8所示,可以看出,兩個數據集上的實驗結果顯示的結論一致:對于未來被引次數的排名預測,基于持續關注度衰減算法要遠優于FutureRank算法,對于未來PageRank值的預測,基于持續關注度衰減算法要稍遜于FutureRank算法,但這種優勢不是很明顯。而且前面的分析已經發現,對于預測較靠前(APS數據前500名,arXiv數據前50名)的論文的情況下(見2.3.2.1節),基于持續關注度衰減算法預測未來PageRank值排序的準確率要優于FutureRank算法。這種差異性出現的根本原因是基于持續關注度衰減算法本身是基于論文的引用次數計算的,而FutureRank算法是基于論文的PageRank值計算的。
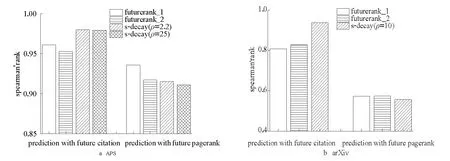
圖8 算法spearman秩相關系數比較Fig.8 Comparision of the spearman’s rank correlation
表3和表4分別給出了基于持續關注度衰減算法在兩個數據集上得到的前20篇論文(表中第1列)與真實排名比較情況。從表3可以看到比較顯著的是編號為“199908142”的論文,2000年之前它的排名為222,未來的排名躍居為第2,而算法能將它預測進前20。此外,論文“199905111”之前為81名,2000年之后排名第6,算法較準確地預測出其潛在價值。
而在 APS數據集上(見表4),比較顯著的是論文10.1103/PhysRevLett.77.3865,10.1103/PhysRevB.54.11169,10.1103/PhysRevB.37.785,10.1103/PhysRevLett.80.149和論文10.1103/PhysRevB.37.785,這類論文在2000年以前排名比較靠后,但是未來排名靠前,屬于潛在價值比較大的文獻,算法能較準確地將其挖掘出來。
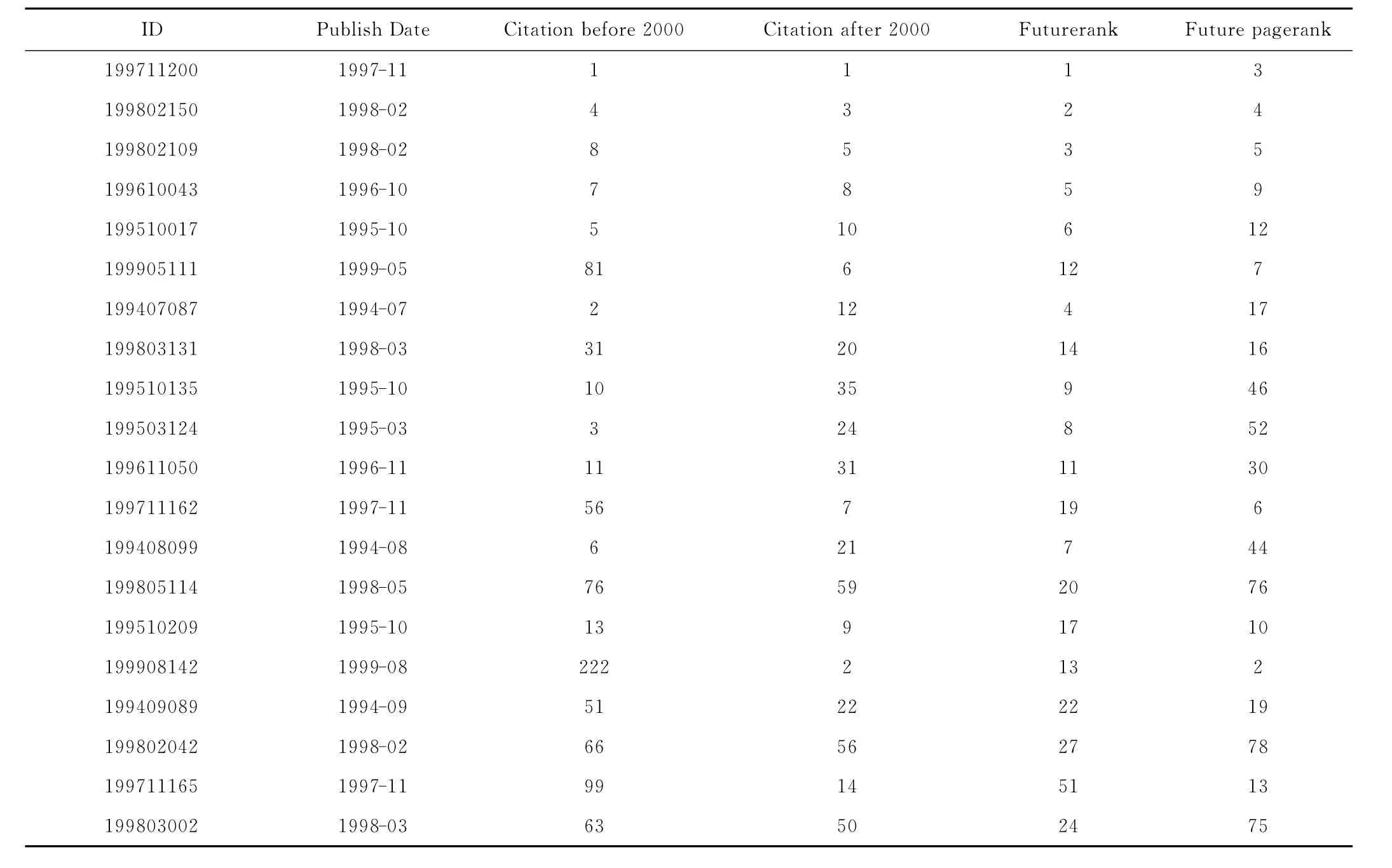
表3 arXiv數據集預測排名前20位與真實排名比較Tab.3 Comparison of the predicted rank and the real rank of the Top20for arXiv data set

表4 APS預測前20名與真實排名比較Tab.4 Comparison of the predicted rank and the real rank of the Top20for APS data set
3 總結和討論
本文提出一種基于持續關注度衰減的重要論文預測算法(s-decay),該方法的優點有:1)預測準確性較高。對于預測排名靠前的論文未來被引情況,本文算法精確率高于FutureRank算法以及z-score值預測算法,只是預測PageRank值排序的全局相關度要稍遜于FutureRank算法;2)本文算法僅含有一個時間參數,且對參數不敏感;3)本文算法不需要處理作者等文本信息,僅僅依據論文隨時間變化的關注度進行論文價值預測,對數據要求低,計算復雜度較低,適用于大規模數據集的處理;4)本文算法在兩個不同的數據集上表現效果也較穩定。
本文綜合考慮論文被引趨勢呈現負指數衰減的特性和論文持續關注度蘊含論文被引潛力的特性,提出基于持續關注度衰減的算法。該算法能較好地預測論文的未來被引排名,但由于算法通過論文過去一段時間的被引用情況來判斷其是否具有繼續被關注的潛力,所以論文必須有被引用的記錄,才能加以判斷。對一些剛剛發表的論文,由于沒有引用鏈接或者過少,對其的預測準確性會大大降低。為此我們猜想是否可將論文所發表的期刊信息,論文所屬的研究領域等因素來預測論文未來的被引情況。此外,被引文獻來自于多個領域,從屬多個類型的論文和引文領域單一,類型單一的論文相比,在未來受到的關注將會更多,被引用潛力也相對更大,論文引文的“多樣性”也可作為研究論文潛在價值的重要依據。
[1] Wang D,Song C,Barabási A L.Quantifying long-term scientific impact[J].Science,2013,342(6154):127-132.
[2] Hirsch J E.An index to quantify an individual's scientific research output[J].Proceedings of the National academy of Sciences of the United States of America,2005,102(46):16569-16572.
[3] Egghe L.Theory and practise of the g-index[J].Scientometrics,2006,69(1):131-152.
[4] Ding Y,Yan E,Frazho A,et al.PageRank for ranking authors in co-citation networks[J].Journal of the American Society for Information Science and Technology,2009,60(11):2229-2243.
[5] Liu X,Bollen J,Nelson M L,et al.Co-authorship networks in the digital library research community[J].Information Processing & Management,2005,41(6):1462-1480.
[6] Medo M,Cimini G,Gualdi S.Temporal effects in the growth of networks[J].Physical Review Letters,2011,107(23):238701.
[7] Berberich K,Vazirgiannis M,Weikum G.Time-aware authority ranking[J].Internet Mathematics,2005,2(3):301-332.
[8] Walker D,Xie H,Yan K K,et al.Ranking scientific publications using a model of network traffic[J].Journal of Statistical Mechanics:Theory and Experiment,2007,2007(06):P06010.
[9]Zhou Y B,LüL,Li M.Quantifying the influence of scientists and their publications:distinguishing between prestige and popularity[J].New Journal of Physics,2012,14(3):033033.
[10]Yan E,Ding Y,Sugimoto C R.P-Rank:an indicator measuring prestige in heterogeneous scholarly networks[J].Journal of the American Society for Information Science and Technology,2011,62(3):467-477.
[11]Zhou D,Orshanskiy S A,Zha H,et al.Co-ranking authors and documents in a heterogeneous network[J].IEEE International Conference on Data Mining,2007,739-744.
[12]Kleinberg J M.Authoritative sources in a hyperlinked environment[J].Journal of the ACM (JACM),1999,46(5):604-632.
[13]Shen H,Wang D,Song C,et al.Modeling and predicting popularity dynamics via reinforced poisson processes[J].Eprint arXiv,2014:arXiv:1401.0778.
[14]Yan E,Ding Y.Weighted citation:an indicator of an article's prestige[J].Journal of the American Society for Information Science and Technology,2010,61(8):1635-1643.
[15]Sayyadi H,Getoor L.FutureRank:ranking scientific articles by predicting their future pagerank[J].Proc of Siam International Conference on Data Mining,2009:533-544.
[16]Page L,Brin S,Motwani R,et al.The pageRank citation ranking:bringing order to the web[J].Lecture Notes in Engineering,1998,9(1):1-14.
[17]Radicchi F,Fortunato S,Vespignani A.Citation networks[J].Understanding Complex Systems,2012:233-257.
[18]Wu Z X,Holme P.Modeling scientific-citation patterns and other triangle-rich acyclic networks[J].Physicl Review E,2009,80(3):037101.
[19]Newman M E J.Prediction of highly cited papers[J].Earophysics Letters,2014,105(2):28002-28007.
[20]Newman M E J.The first-mover advantage in scientific publication[J].Europhysics Letters,2009,86(6):68001.
