基于聚類(lèi)的非中心化工作流的適應(yīng)性切片方法
2015-12-23 01:07:44梁繼偉尹智剛
計(jì)算機(jī)工程與設(shè)計(jì) 2015年10期
葉 鑫,李 佳,梁繼偉,尹智剛
(大連理工大學(xué) 信息與決策技術(shù)研究所,遼寧 大連116024)
0 引 言
非中心化工作流如何進(jìn)行切片,以實(shí)現(xiàn)工作流片段在多個(gè)服務(wù)器間的調(diào)度問(wèn)題已成為理論研究與實(shí)踐中的熱點(diǎn)問(wèn)題[1]。非中心化的工作流根據(jù)其特點(diǎn)主要可分為計(jì)算和數(shù)據(jù)密集型[2-5]和實(shí)例密集型[6-9]兩類(lèi)。區(qū)別于計(jì)算和數(shù)據(jù)密集型工作流,實(shí)例密集型工作流的最大特點(diǎn)是實(shí)例中活動(dòng)所需的計(jì)算能力較低、數(shù)據(jù)量較小,但存在大量需要運(yùn)行的工作流實(shí)例,對(duì)響應(yīng)時(shí)間和執(zhí)行效率提出了嚴(yán)峻的挑戰(zhàn)。文獻(xiàn) [10]指出該類(lèi)工作流廣泛存在于連鎖經(jīng)營(yíng)、在線(xiàn)零售、電子政務(wù)和醫(yī)療保險(xiǎn)等行業(yè)中,由大量分散在不同服務(wù)器上的服務(wù)集之間復(fù)雜的交互來(lái)組成,最終將被數(shù)以萬(wàn)計(jì)的工作流實(shí)例來(lái)實(shí)現(xiàn)。
當(dāng)前,一些學(xué)者為提升非中心化工作流的響應(yīng)時(shí)間和執(zhí)行效率,提出了相應(yīng)工作流的切片方法,主要可以分為靜態(tài)和動(dòng)態(tài)的工作流切片方法兩類(lèi)。
靜態(tài)工作流切片方法是在設(shè)計(jì)時(shí)而非工作流執(zhí)行時(shí)進(jìn)行切片的[11,12],雖然可相對(duì)提高工作流執(zhí)行效率,但是由于其主觀性較強(qiáng),而且沒(méi)有考慮工作流的執(zhí)行環(huán)境,因此無(wú)法根據(jù)執(zhí)行環(huán)境的改變做出動(dòng)態(tài)調(diào)整,而動(dòng)態(tài)工作流切片方法可彌補(bǔ)這些不足[7,13]。如文獻(xiàn) [13]提出一種基于流程挖掘的工作流分布方法,該方法根據(jù)流程日志,利用apriori算法挖據(jù)工作流中最相關(guān)的活動(dòng),并將這些活動(dòng)封裝在同一個(gè)代理上去執(zhí)行;文獻(xiàn) [14]提到了另外一種針對(duì)客戶(hù)行為的工作流中頻繁路徑的挖據(jù)方法-GSP算法,以提升挖據(jù)效率;文獻(xiàn) [8]在文獻(xiàn) [13]的基礎(chǔ)之上提出了HIPD (分層智能流程非中心化)方法,該方法將工作流的頻繁路徑挖掘和流程樹(shù)分層結(jié)合起來(lái)進(jìn)行工作流片段的切分,最后將頻繁交互的活動(dòng)封裝為一個(gè)工作流片段,并分配在相同的代理中執(zhí)行,從而減少活動(dòng)間的通信時(shí)間,并使得工作流切片更具靈活性,以適應(yīng)工作流執(zhí)行環(huán)境的變化。
綜上所述,動(dòng)態(tài)的工作流切片方法為本文的研究提供了良好的基礎(chǔ)與借鑒,但還主要存在以下問(wèn)題:①部分方法主要考慮了活動(dòng)的執(zhí)行頻次,忽視了活動(dòng)間的依賴(lài)關(guān)系;②考慮因素不全面,缺少對(duì)工作流活動(dòng)間的通信量的關(guān)注;③不能很好適應(yīng)工作流的執(zhí)行環(huán)境。這些問(wèn)題的存在將會(huì)影響到工作流執(zhí)行的響應(yīng)時(shí)間和吞吐量。因此,本文針對(duì)這些問(wèn)題的改進(jìn)進(jìn)行研究,旨在減少工作流的響應(yīng)時(shí)間,提高工作流的執(zhí)行效率。
1 基于層次聚類(lèi)法的非中心化工作流的切片方法
為減少實(shí)例密集型非中心化工作流的響應(yīng)時(shí)間并提升其執(zhí)行效率,應(yīng)在綜合考慮活動(dòng)執(zhí)行頻次等因素的前提下,盡可能的將通信頻繁且通信量大的活動(dòng)分配在同一臺(tái)服務(wù)器上執(zhí)行,亦即將這些活動(dòng)劃分到一個(gè)工作流片段中。而聚類(lèi)分析是數(shù)據(jù)挖掘中的一種數(shù)據(jù)劃分或分組處理的重要手段和方法。如果將通信頻繁且通信量大的活動(dòng)看作為相似,則可將聚類(lèi)分析中的類(lèi)別看作為工作流片段。因此,可應(yīng)用聚類(lèi)分析對(duì)工作流進(jìn)行切片,但須對(duì)其類(lèi)間距離的定義進(jìn)行修訂。另外,由于執(zhí)行環(huán)境的不確定性等因素,因此借鑒凝聚層次聚類(lèi)法的思路對(duì)工作流進(jìn)行切片,以提高切片結(jié)果對(duì)執(zhí)行環(huán)境的適應(yīng)性。
1.1 基本定義
基于BPMN 規(guī)范,一個(gè)工作流模型可被抽象為一個(gè)有向無(wú)環(huán)圖 (DAG)。圖中的節(jié)點(diǎn)可分為活動(dòng)和網(wǎng)關(guān)兩類(lèi)。相關(guān)的基本定義如下。
定義1 活動(dòng) (或任務(wù))。活動(dòng)是工作流中的最基本的元素,也是工作流切片的基本單元,令ai表示工作流中的第i個(gè)活動(dòng),則A={ai|i=1,2…,n}表示工作流中所有活動(dòng)的集合。
定義2 工作流片段 (或類(lèi))。工作流片段表示切片過(guò)程中所產(chǎn)生的活動(dòng)集合,亦可看作為聚類(lèi)分析中的類(lèi)。令ci表示第i 個(gè)工作流片段,則ciA。特別的,當(dāng)某工作流片段只包含1 個(gè)活動(dòng)時(shí),該工作流片段等價(jià)與活動(dòng)。令clusterk= {ci|i=1,2…,l},k=1,2…m 表示第k次聚類(lèi)時(shí)的所有工作流片段的集合。
定義3 活動(dòng)間的偏序關(guān)系與工作流片段間的偏序關(guān)系。其中,如果在DAG 圖中存在一條從ai指向aj的路,且除ai和aj外,路上無(wú)其它節(jié)點(diǎn)或只包含網(wǎng)關(guān)類(lèi)型的節(jié)點(diǎn),則稱(chēng)ai和aj之間存在偏序關(guān)系<ai,aj>。類(lèi)似的,如果工作流片段ci中的活動(dòng)和工作流片段cj中的活動(dòng)存在偏序關(guān)系,則ci和cj之間存在偏序關(guān)系<ci,cj>。
定義4 活動(dòng)間的依賴(lài)概率。基于工作流的結(jié)構(gòu)和歷史日志數(shù)據(jù),如果ai和aj之間存在偏序關(guān)系<ai,aj>,則paiaj表示ai和aj之間的依賴(lài)概率,即ai被執(zhí)行后aj被執(zhí)行的概率,其計(jì)算公式如式 (1)所示

式中:countai、countaj——工作流歷史日志信息中ai、aj的執(zhí)行次數(shù)合計(jì)。
定義5 活動(dòng)的預(yù)計(jì)執(zhí)行頻次。若令fai表示活動(dòng)ai的預(yù)計(jì)執(zhí)行頻次,給定時(shí)間段內(nèi)工作流實(shí)例的數(shù)量記為instanceNumber,則工作流中第一個(gè)活動(dòng) (即初始活動(dòng))的預(yù)計(jì)執(zhí)行頻次fa1=instanceNumber,其余活動(dòng)的預(yù)計(jì)執(zhí)行頻次的計(jì)算公式如式 (2)所示,并可通過(guò)遍歷DAG 圖計(jì)算得到

定義6 活動(dòng)間的依賴(lài)頻次。令faiaj表示活動(dòng)ai和aj之間的依賴(lài)頻次,即ai被執(zhí)行后aj被執(zhí)行的頻次,其計(jì)算公式如式 (3)所示

定義7 活動(dòng)間的距離和類(lèi)間的距離。若令commaiaj表示活動(dòng)ai和aj之間的通信量,daiaj表示活動(dòng)ai和aj之間的距離,則daiaj可由式 (4)計(jì)算得到。即活動(dòng)ai和aj之間的依賴(lài)頻次越大,通信量越大,則二者之間的距離越小
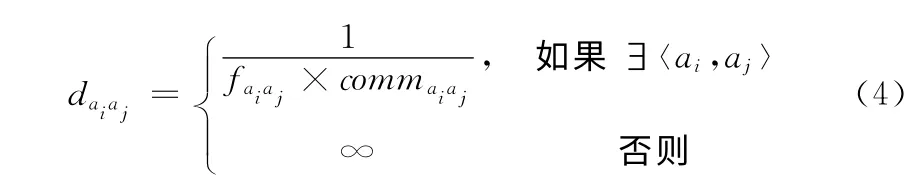
若令dcicj表示類(lèi)ci到cj之間的距離,可由式 (5)計(jì)算得到。若令Dcicj表示類(lèi)ci和cj之間的距離,則可由式(6)計(jì)算得到
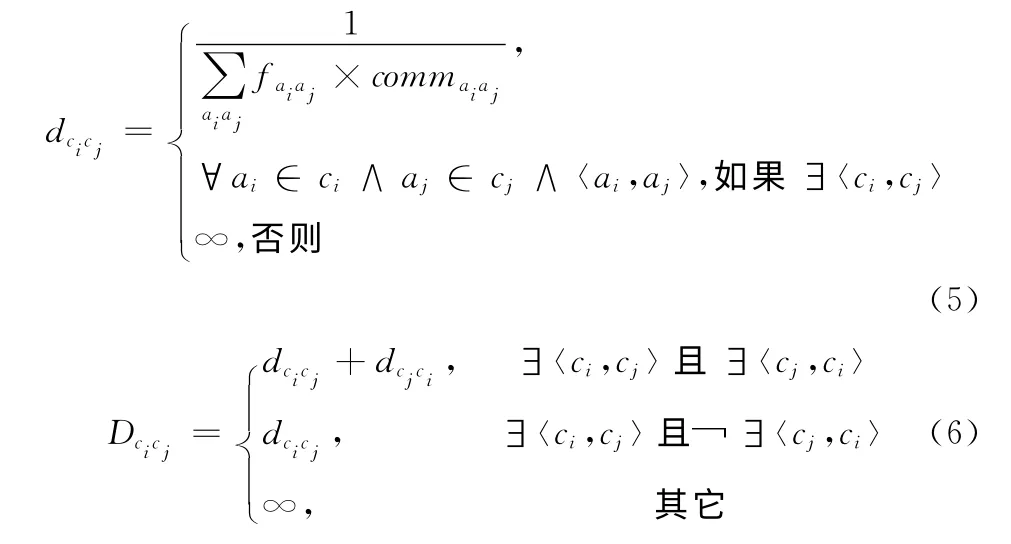
1.2 基于聚類(lèi)的工作流切片算法
基于聚類(lèi)的工作流切片算法如下:
輸入:DAG,instanceNumber,Paiaj,comaiaj
輸出:每次聚類(lèi)的最小距離min(diatance)和相應(yīng)的聚類(lèi)結(jié)果clusterk

首先基于工作流的歷史日志信息,根據(jù)式 (1)計(jì)算得到活動(dòng)間的依賴(lài)概率,并基于工作流執(zhí)行環(huán)境如instanceNumber等信息,執(zhí)行上述算法。該算法的主要步驟解釋如下:
步驟1 數(shù)據(jù)預(yù)處理。根據(jù)給定時(shí)間段內(nèi)的工作流實(shí)例數(shù)量instanceNumber與式 (2)計(jì)算每個(gè)活動(dòng)的預(yù)計(jì)執(zhí)行頻次,根據(jù)式 (3)計(jì)算活動(dòng)間的依賴(lài)頻次。
步驟2 聚類(lèi)初始化。令每個(gè)活動(dòng)自成一類(lèi),初始化clusterk且k=1。
步驟3 根據(jù)式 (5)和式 (6)計(jì)算clusterk中兩兩類(lèi)間距離,找出類(lèi)間距離的最小值,然后將類(lèi)間距離最小的類(lèi)聚合在同一個(gè)類(lèi)中,k遞增,更新clusterk后執(zhí)行步驟4。
步驟4 判斷所有活動(dòng)是否在同一個(gè)類(lèi)中,如是,則聚類(lèi) (即切片)過(guò)程結(jié)束;否則,執(zhí)行步驟3。
1.3 算例
以圖1 所示的工作流為例,說(shuō)明并驗(yàn)證算法。其中,活動(dòng)間的關(guān)系包括:a1與a2、a2與a3構(gòu)成順序關(guān)系,a3與a4、a5、a6之間為Xor-split關(guān)系,a4、a5、a6與a7之間為Xor-join關(guān)系。假設(shè)從工作流的歷史日志信息中計(jì)算得到活動(dòng)間的依賴(lài)概率,如圖1中各邊上的權(quán)數(shù)所示。
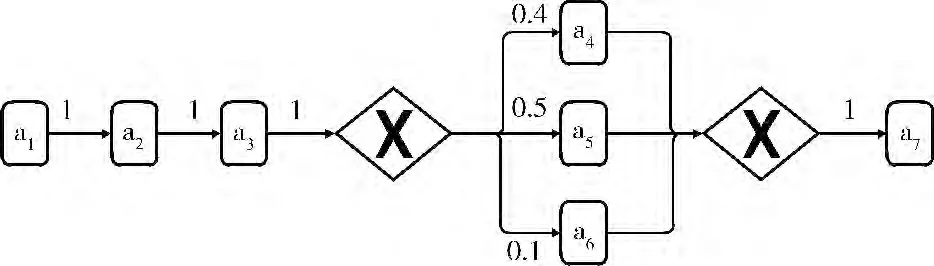
圖1 工作流
另假設(shè)已知即將要到達(dá)的工作流實(shí)例數(shù)目為10000,各活動(dòng)間的通信量見(jiàn)表1。具體的切片過(guò)程如下:
步驟1 基于活動(dòng)間的依賴(lài)概率、式(2)和式(3),可計(jì)算活動(dòng)間的依賴(lài)頻次見(jiàn)表1,如:fa1a2=fa1×pa1a2=10000。
步驟2 初始化:令k=1,則cluster1= {ci|i=1,2,…7}。其中,c1= {a1},c2= {a2},c3= {a3},c4={a4},c5= {a5},c6= {a6},c7= {a7}。
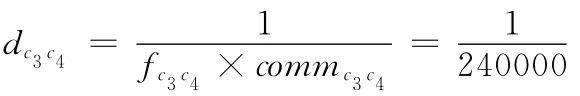
步驟4 重復(fù)步驟3直至所有活動(dòng)都聚合在一個(gè)類(lèi)中。

表1 活動(dòng)間的依賴(lài)頻次和通信量
最終的切片結(jié)果見(jiàn)表2。
2 模擬實(shí)驗(yàn)與分析
2.1 實(shí)驗(yàn)設(shè)計(jì)
為了體現(xiàn)切片方法的適應(yīng)性,考慮了工作流執(zhí)行環(huán)境的兩個(gè)維度:①單位時(shí)間內(nèi)實(shí)例的到達(dá)數(shù)目;②可執(zhí)行資源 (服務(wù)器)的數(shù)目。由于篇幅有限,設(shè)計(jì)了2 組實(shí)驗(yàn),見(jiàn)表3。其中,每一組實(shí)驗(yàn)均考慮HIPD 方法和本文所提出的方法,實(shí)驗(yàn)所使用的工作流如圖1所示。
為了便于和HIPD 方法比較,效果指標(biāo)包括響應(yīng)時(shí)間和吞吐量。文獻(xiàn) [8]中定義的響應(yīng)時(shí)間是指從第一個(gè)工作流實(shí)例到達(dá)直到最后一個(gè)工作流實(shí)例獲得響應(yīng)的時(shí)間;吞吐量是指單位時(shí)間內(nèi),已執(zhí)行結(jié)束的工作流實(shí)例數(shù)目占所請(qǐng)求執(zhí)行的工作流實(shí)例數(shù)目的百分比。

表2 聚類(lèi)過(guò)程與結(jié)果
表3 分組實(shí)驗(yàn)設(shè)計(jì)
另外,在所有的實(shí)驗(yàn)中,為使方法對(duì)比效果更加明顯,假定每個(gè)服務(wù)器的執(zhí)行能力相同,每個(gè)活動(dòng)在服務(wù)器上的執(zhí)行時(shí)間為0.005s,同一時(shí)間一個(gè)服務(wù)器只能執(zhí)行一個(gè)活動(dòng),且單位時(shí)間內(nèi)工作流實(shí)例均勻到達(dá),服務(wù)器之間的網(wǎng)絡(luò)帶寬為10Mb/s,則根據(jù)相應(yīng)公式可得活動(dòng)間的通信時(shí)間見(jiàn)表4。

表4 活動(dòng)間通信時(shí)間
2.2 工作流切片與服務(wù)器分配
針對(duì)圖1所示的工作流,基于本文所提出的切片方法所得到的切片結(jié)果如1.3 節(jié)中的表2 所示。為了便于與HIPD 方法比較,令min_support=4000,則基于HIPD 對(duì)圖1所示的工作流的切片結(jié)果見(jiàn)表5。

表5 基于HIPD 的工作流算例的切片結(jié)果
在模擬實(shí)驗(yàn)進(jìn)行之前,仍需基于切片結(jié)果,將工作流片段分配到相應(yīng)的服務(wù)器上。針對(duì)基于HIPD 所得到的切片結(jié)果,利用文獻(xiàn) [8]中所使用的Round Robin算法將工作流片段分配到相應(yīng)的服務(wù)器上。針對(duì)基于本文所提出的切片方法所得到的切片結(jié)果,在進(jìn)行服務(wù)器的分配時(shí),盡可能地將在后續(xù)聚類(lèi)步驟中先被聚合的工作流片段分配在同一個(gè)服務(wù)器上,并同時(shí)考慮服務(wù)器的負(fù)載均衡等因素。例如,將表2中k=2時(shí)所得聚類(lèi)結(jié)果分配在2臺(tái)服務(wù)器上時(shí),因?yàn)槭紫?{a3}和 {a4}被聚合在一個(gè)類(lèi)中,所以將片段 {a3,a4}分配在同一臺(tái)服務(wù)器上。然后針對(duì)剩余的工作流片段 {a1}、{a2}、{a5}、{a6}、{a7},考慮k=3時(shí){a2}、{a3}和 {a4}被聚合在一個(gè)類(lèi)中,所以將 {a2}和{a3,a4}分配在同一臺(tái)服務(wù)器上。進(jìn)一步的,考慮到服務(wù)器的負(fù)載均衡因素,將剩余的 {a1}、{a5}、{a6}、{a7}分配在另一臺(tái)服務(wù)器上。這種分配方式既考慮了活動(dòng)間的通信時(shí)間和偏序關(guān)系,也同時(shí)考慮了服務(wù)器的負(fù)載均衡。針對(duì)兩組實(shí)驗(yàn)的工作流片段的分配結(jié)果,見(jiàn)表6和表7。

表6 實(shí)驗(yàn)組一的工作流片段分配

表7 實(shí)驗(yàn)組二的工作流片段分配
2.3 實(shí)驗(yàn)執(zhí)行與結(jié)果分析
實(shí)驗(yàn)的軟件環(huán)境為AnyLogic Professional 7.0.0。Any-Logic是一款應(yīng)用廣泛的,對(duì)離散,連續(xù)和混合系統(tǒng)建模和仿真的工具[15],圖1 所示的工作流在AnyLogic流程模型庫(kù)中建模結(jié)果界面如圖2所示。
實(shí)驗(yàn)結(jié)果如圖3、圖4所示。
基于以上兩組實(shí)驗(yàn)結(jié)果,從以下幾個(gè)方面進(jìn)行比較分析:
(1)本文所提出的切片方法在響應(yīng)時(shí)間和吞吐量?jī)煞矫婢鶅?yōu)于HIPD 方法。
(2)當(dāng)服務(wù)器數(shù)目為2時(shí),由圖3 可以看出,本文提出的切片方法明顯優(yōu)于HIPD 方法。并且當(dāng)單位時(shí)間內(nèi)工作流實(shí)例到達(dá)數(shù)目為600時(shí),聚類(lèi)2-6-2 (基于本文所提出的切片方法的最優(yōu)方案)的響應(yīng)時(shí)間為9.79s,相比于HIPD2-7-2 (基于HIPD 方法的最優(yōu)方案)的響應(yīng)時(shí)間13.77s,減少了31%。由此可見(jiàn),在工作流切片時(shí),考慮活動(dòng)間的通信量比不考慮活動(dòng)間的通信量更能減少工作流執(zhí)行的響應(yīng)時(shí)間。

圖2 基于AnyLogic的圖1所示的工作流算例的建模界面
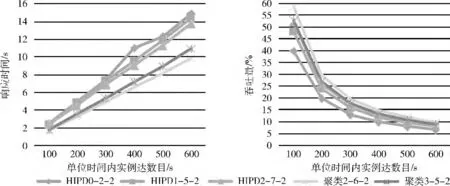
圖3 實(shí)驗(yàn)組一的實(shí)驗(yàn)結(jié)果
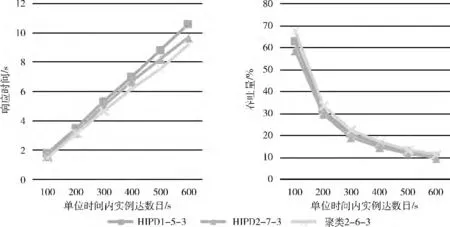
圖4 實(shí)驗(yàn)組二的實(shí)驗(yàn)結(jié)果
(3)當(dāng)服務(wù)器數(shù)目增加時(shí),由圖3和圖4可以看出,本文所提出的切片方法和HIPD 方法在響應(yīng)時(shí)間上均減少,在吞吐量上均提高。這是因?yàn)楫?dāng)服務(wù)器數(shù)目增加時(shí),提高了工作流執(zhí)行的并發(fā)性,減少了等待時(shí)間。但是本文所提出的切片方法在響應(yīng)時(shí)間和吞吐量方面的改善程度均優(yōu)于HIPD。
(4)縱觀所有實(shí)驗(yàn),隨著單位時(shí)間內(nèi)工作流實(shí)例數(shù)目的增加,本文提出的方法較之HIPD 方法在響應(yīng)時(shí)間方面的優(yōu)勢(shì)越來(lái)越大,由此可以說(shuō)明當(dāng)實(shí)例數(shù)目越多時(shí),通信量越大,本文提出的方法較HIPD 更能較少通信時(shí)間,從而減少響應(yīng)時(shí)間。
綜上,本文所提出的方法更能適應(yīng)工作流執(zhí)行環(huán)境。
3 結(jié)束語(yǔ)
本文針對(duì)當(dāng)前非中心化工作流的切片方法中存在的問(wèn)題,提出一種基于聚類(lèi)的非中心化工作流的適應(yīng)性切片方法。該方法是對(duì)經(jīng)典的凝聚層次聚類(lèi)法的改進(jìn),雖然思路上與經(jīng)典方法相似,但是在類(lèi)間距離的計(jì)算上區(qū)別于傳統(tǒng)聚類(lèi)方法。而且,該方法不僅考慮了工作流中活動(dòng)間的偏序關(guān)系與依賴(lài)頻次,還充分考慮了活動(dòng)間的通信量與通信時(shí)間。通過(guò)模擬實(shí)驗(yàn),與當(dāng)前最好的動(dòng)態(tài)流程切片方法HIPD 相比,所提出的方法在不同的工作流執(zhí)行環(huán)境下,響應(yīng)時(shí)間與吞吐量均有不同程度的優(yōu)勢(shì),且更能適應(yīng)工作流執(zhí)行環(huán)境的動(dòng)態(tài)變化。
該方法尚有不足,如切片結(jié)果與服務(wù)器的分配方面,尚未形成完整的方法體系;又如實(shí)驗(yàn)時(shí)做了若干假設(shè),不能完全體現(xiàn)實(shí)際工作流執(zhí)行環(huán)境的各種場(chǎng)景等。上述局限性將有待在未來(lái)的研究工作進(jìn)一步完善。
[1]WANG Wenli.Event-based distributed workflow technology in cloud environment[D].Harbin:Harbin Institute of Technology,2013 (in Chinese).[王文莉.云環(huán)境下基于事件的分布式工作流技術(shù) [D].哈爾濱:哈爾濱工業(yè)大學(xué),2013.]
[2]Wan Cong,Wang Cuirong,Pei Jianxun.A QoS-awared scientific workflow scheduling schema in cloud computing [C]//IEEE International Conference on Information Science and Technology,2012:634-639.
[3]Tram Truong Huu,Guilherme Koslovski,F(xiàn)abienne Anhalt,et al.Joint elastic cloud and virtual network framework for application performance-cost optimization [J].Journal of Grid Computing,2011,9 (1):27-47.
[4]Eun-Kyu Byun,Yang-Suk Kee,Jin-Soo Kim,et al.BTS:Resource capacity estimate for time-targeted science workflows[J].Journal of Parallel and Distributed Computing,2011,71(6):848-862.
[5]Simon Ostermann,Radu Prodan.Impact of variable priced cloud resources on scientific workflow scheduling [G].LNCS 7484:Euro-Par 2012Parallel Processing,2012:350-362.
[6]LI Wenhao.The study on instance-intensive workflow schedule in algorithms in community cloud [D].Jinan:Shandong University,2010 (in Chinese).[李文浩.面向社區(qū)云的實(shí)例密集型工作流調(diào)度方法研究 [D].濟(jì)南:山東大學(xué),2010.]
[7]Liu K,Jin H,Chen J,et al.A compromised-time-cost scheduling algorithm in SwinDeW-C for instance-intensive cost-constrained workflows on a cloud computing platform [J].International Journal of High Performance Computing Applications,2010,24 (4):445-456.
[8]Faramarz Safi Esfahani,Masrah Azrifah Azmi Murad,Md Nasir B Sulaimanb,et al.Adaptable decentralized service oriented architecture[J].Journal of Systems and Software,2011,84(10):1591-1617.
[9]YANG Chengwei,MENG Xiangxu.Research on issues of dynamic process optimization scheduling under cloud computing environment [D].Jinan:Shandong University,2012 (in Chinese).[楊成偉,孟祥旭.云計(jì)算環(huán)境下動(dòng)態(tài)流程優(yōu)化調(diào)度問(wèn)題研究 [D].濟(jì)南:山東大學(xué),2012.]
[10]Li G,Muthusamy V,Jacobsen HA.A distributed service oriented architecture for business process execution [J].ACM Transactions on the Web,2010,4 (1):1-33.
[11]Muthusamy V,Jacobsen HA,Chau T,et al.SLA-driven business process management in SOA [C]//Conference of the Center for Advanced Studies on Collaborative Research,2009:86-100.
[12]Daniel Wutke,F(xiàn)rank Leymann,Daniel Martin.A method for partitioning BPEL processes for decentralized execution [C]//Erster Zentraleurop ischer Workshop,2009:109-114.
[13]Faramarz Safi Esfahani,Masrah Azrifah Azmi Murad,Md Nasir Sulaiman,et al.Using process mining to business process distribution [C]//ACM Symposium on Applied Computing,2009:2140-2145.
[14]Alex Seret,Seppe KLM vanden Broucke,Bart Baesens,et al.A dynamic understanding of customer behavior processes based on clustering and sequence mining [J].Expert Systems with Applications,2014,41 (10):4648-4657.
[15]Zhang Debin.Teaching case:Implementation of discrete event simulation using anylogic[C]//Proceedings of International Symposium on Modeling and Simulation of Complex Management Systems,2013:98-101.
猜你喜歡
少先隊(duì)活動(dòng)(2022年5期)2022-06-06 03:45:04
家庭科學(xué)·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
少先隊(duì)活動(dòng)(2021年1期)2021-03-29 05:26:36
快樂(lè)語(yǔ)文(2020年30期)2021-01-14 01:05:38
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
海峽姐妹(2018年3期)2018-05-09 08:20:40
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
