基于MapReduce的約束頻繁項(xiàng)集挖掘算法
2015-12-23 01:07:56錢(qián)雪忠
計(jì)算機(jī)工程與設(shè)計(jì) 2015年10期
關(guān)鍵詞:數(shù)據(jù)庫(kù)
施 亮,錢(qián)雪忠
(江南大學(xué) 物聯(lián)網(wǎng)工程學(xué)院,江蘇 無(wú)錫214122)
0 引 言
本文結(jié)合MapReduce[1]云計(jì)算編程模型提出一種基于MapReduce的約束頻繁項(xiàng)集挖掘算法DCFIBMR (discover constrained frequent itemsets based on MapReduce)。該算法可以將一個(gè)完整的挖掘任務(wù)分成若干個(gè)相對(duì)獨(dú)立的子任務(wù),然后通過(guò)Hadoop[2]框架的MapReduce并行編程模型實(shí)現(xiàn)FP-Growth算法的并行化,其原理是DCFIBMR 算法將一個(gè)挖掘任務(wù)分成若干個(gè)相對(duì)獨(dú)立的子任務(wù),然后利用Hadoop框架將子任務(wù)分發(fā)給各個(gè)子節(jié)點(diǎn)進(jìn)行處理,該算法在數(shù)千機(jī)器組成的集群中處理數(shù)據(jù)挖掘,因此DCFIBMR 算法可以有效地處理海量的數(shù)據(jù)挖掘任務(wù)。
1 相關(guān)概念
1.1 約束頻繁項(xiàng)
本文中討論的約束是有項(xiàng)約束,即挖掘包含某些項(xiàng)目(或同時(shí)包含幾個(gè)項(xiàng)目)的頻繁項(xiàng)目集合,設(shè)布爾表達(dá)式B是I上的項(xiàng)約束條件,將B 轉(zhuǎn)換為析取范式 (disjunctive normal form,DNF)的形式,如:B1∨B2∨B3…∨Bn,如果把B寫(xiě)成集合的形式,形如:set-of-B= {B1,B2,B3…Bn},其中集合B中的任意兩個(gè)組成元素均不相等[3]。
1.2 FP-tree的構(gòu)建
在FP-tree[4]中每個(gè)節(jié)點(diǎn)包含有5個(gè)屬性:該節(jié)點(diǎn)的名稱(chēng) (NodeName),該節(jié)點(diǎn)在數(shù)據(jù)庫(kù)中出現(xiàn)的次數(shù) (Node-Count),指向下一個(gè)同名節(jié)點(diǎn)的指針 (NodeSlider),指向該節(jié)點(diǎn)的父節(jié)點(diǎn)的指針 (ParentNode)及該節(jié)點(diǎn)的子節(jié)點(diǎn)所構(gòu)成的節(jié)點(diǎn)集合 (ChildrenNode)。而該頻繁項(xiàng)按計(jì)數(shù)降序排列組成的頭表集合 (HTable)中,每個(gè)元素包含3個(gè)子對(duì)象:頻繁項(xiàng)名稱(chēng)ItemName,頻繁項(xiàng)計(jì)數(shù)ItemCount及指向FP-tree中同名節(jié)點(diǎn)的指針I(yè)temHead。FP-tree[5]的構(gòu)造過(guò)程如下:
(1)掃描一次事務(wù)數(shù)據(jù)庫(kù)DB,構(gòu)造頻繁項(xiàng)和其支持?jǐn)?shù)組成集合L,將集合L 中不滿足最小支持度的頻繁項(xiàng)刪除并按支持?jǐn)?shù)降序排列,生成支持?jǐn)?shù)降序排列的頻繁項(xiàng)集合F。
(2)構(gòu)造FP-tree樹(shù)的根節(jié)點(diǎn)T,并標(biāo)記為 “NULL”,再次掃描事務(wù)數(shù)據(jù)庫(kù)DB,遍歷每條事務(wù)Trans,并執(zhí)行如下過(guò)程:
1)根據(jù)頻繁項(xiàng)集在F中的順序,對(duì)事務(wù)Trans中頻繁項(xiàng)按其支持?jǐn)?shù)降序排列,構(gòu)造 [p|P]結(jié)構(gòu),其中p是事務(wù)Trans中第一個(gè)項(xiàng),P是剩余項(xiàng)。
2)調(diào)用insert_tree([p|P,T])函數(shù),該函數(shù)執(zhí)行過(guò)程如下:
如果T 存在一個(gè)子節(jié)點(diǎn)N,并滿足N.NodeName,=p.NodeName,那么使節(jié)點(diǎn)N 的計(jì)數(shù)NodeCount加1;否則,創(chuàng)建一個(gè)新的子節(jié)點(diǎn)N,并且設(shè)置節(jié)點(diǎn)N.NodeName=p.NodeName、N.NodeCount=1、p.ParentNode=T。如果P非空,遞歸調(diào)用insert_tree(P,N)。
1.3 MapReduce編程模型
MapReduce是Apache下開(kāi)源云計(jì)算框架Hadoop中一種并行計(jì)算編程模型,利用MapReduce編程模型Hadoop可以并行處理數(shù)據(jù)量巨大的任務(wù),該框架可以極大的簡(jiǎn)化分布式任務(wù)的處理。而MapReduce編程模型主要有Map和Reduce兩個(gè)部分組成,其主要原理是利用一個(gè)輸入鍵值對(duì)集合,通過(guò)處理產(chǎn)生一個(gè)輸出鍵值對(duì)集合[6]。
用戶(hù)需要重寫(xiě)兩個(gè)函數(shù):mapper和reducer,MapReduce首先將數(shù)據(jù)分片輸入到mapper函數(shù)中,根據(jù)指定的處理過(guò)程產(chǎn)生鍵值對(duì)集合并將相同鍵的鍵值對(duì)輸出給同一個(gè)reducer函數(shù)進(jìn)行處理,reducer函數(shù)根據(jù)用戶(hù)的自定義的處理流程處理后將結(jié)果輸出[7]。
2 約束頻繁項(xiàng)集挖掘DCFIBMR算法
給定一個(gè)事務(wù)數(shù)據(jù)庫(kù)、最小支持度及約束規(guī)則B,DCFIBMR 算法需要執(zhí)行兩次MapReduce過(guò)程。
2.1 第一次MapReduce過(guò)程
使用一個(gè)MapReduce任務(wù)來(lái)統(tǒng)計(jì)整個(gè)事務(wù)數(shù)據(jù)庫(kù)中的頻繁項(xiàng)的支持?jǐn)?shù)。每個(gè)mapper實(shí)例處理一個(gè)事務(wù)數(shù)據(jù)庫(kù)的數(shù)據(jù)塊。mapper實(shí)例接收的數(shù)據(jù)是一種鍵值對(duì)的形式,如<key,value=Ti>,其中Ti是事務(wù)數(shù)據(jù)庫(kù) (DB)中的每條記錄,對(duì)于每個(gè)頻繁項(xiàng),mapperper實(shí)例將處理好的數(shù)據(jù)以一種鍵值對(duì)的形式輸出,如<key’=aj,value’=1>。對(duì)于每個(gè)mapperper實(shí)例的輸出,用一個(gè)對(duì)應(yīng)的combiner實(shí)例進(jìn)行局部的整合,將相同鍵的值進(jìn)行求和,通過(guò)此步可有效地減少節(jié)點(diǎn)之間的數(shù)據(jù)通信量。
在所有的mapperper實(shí)例執(zhí)行完畢后,Hadoop框架會(huì)將具有相同鍵的鍵值對(duì)分發(fā)給同一個(gè)reducer實(shí)例進(jìn)行處理,reducer實(shí)例對(duì)具有相同鍵 (key’)的值進(jìn)行求和運(yùn)算,處理結(jié)束后同樣以鍵值對(duì)的形式輸出,如<key’,sum(values’)>[8]。該階段處理完成后可獲得一個(gè)由頻繁項(xiàng)及按支持度降序排列的列表,F(xiàn)。
2.2 第二次MapReduce過(guò)程
首先,在Map階段,事務(wù)數(shù)據(jù)庫(kù)中的數(shù)據(jù)被處理成組內(nèi)依賴(lài)的數(shù)據(jù)塊。然后在Reduce階段每個(gè)reducer實(shí)例根據(jù)獲取到的數(shù)據(jù)塊構(gòu)建子頻繁模式樹(shù) (SubFP-tree),并在構(gòu)建的子頻繁模式樹(shù)上遞歸進(jìn)行頻繁模式的挖掘任務(wù)。在mapper實(shí)例的開(kāi)始階段,它會(huì)加載第一次MapReduce過(guò)程生成的F[9]。在本文的實(shí)現(xiàn)中,F(xiàn)被構(gòu)建成一個(gè)Hash映射表,將其包含的每一項(xiàng)映射到相應(yīng)的組的編號(hào)(group-id)上。
(1)mapper的輸入?yún)?shù)是事務(wù)數(shù)據(jù)庫(kù)中的數(shù)據(jù)切片,每個(gè)數(shù)據(jù)切片以鍵值對(duì),如<key,Value=Ti>,的形式傳遞。對(duì)于每個(gè)Ti,mapper將會(huì)按照如下步驟進(jìn)行:
1)按照F中頻繁項(xiàng)的順序?qū)i進(jìn)行降序排列;
2)對(duì)于Ti中的每一項(xiàng)i,定位該項(xiàng)左邊的項(xiàng)集,記錄為L(zhǎng);
3)輸出一個(gè)鍵值對(duì),形如<key’=group-id,value={Ti[1],Ti[2],…Ti[L-1],Ti[L]},其中g(shù)roup-id為i在F中的下坐標(biāo)。
(2)reducer實(shí)例開(kāi)始執(zhí)行時(shí)同樣會(huì)加載F。在這個(gè)階段,reducer實(shí)例會(huì)接受<key’,Value=DB (group-id)>鍵值對(duì),DB (group-id)包含了同一組內(nèi)的所有事務(wù)數(shù)據(jù)塊[10]。針對(duì)DB (group-id),reducer實(shí)例會(huì)遞歸地構(gòu)建和挖掘子頻繁模式樹(shù) (SubFP-tree)。詳細(xì)描述如下:
1)首先設(shè)置前綴項(xiàng)prefix=F[group-id];
2)掃描一次DB(group-id),產(chǎn)生由頻繁項(xiàng)按支持?jǐn)?shù)降序排列的頭表subHTable;
3)再次掃描DB(group-id)構(gòu)建局部子頻繁模式樹(shù)subFPtree;
4)判斷由prefix和subHTable中的各個(gè)頻繁項(xiàng)構(gòu)成的項(xiàng)集是否滿足約束規(guī)則B,如果滿足則輸出該頻繁項(xiàng);
5)遍歷subHTable集合,對(duì)于集合中的每個(gè)頻繁項(xiàng)p,從subFPtree中找到含有p的路徑,并構(gòu)造p的條件模式基集合。然后將prefix=prefix+p.NodeName,p的條件模式基集合,約束規(guī)則B 及F 作為輸入?yún)?shù)從步驟2)開(kāi)始迭代執(zhí)行。
算法的具體執(zhí)行過(guò)程如下:
輸入:事務(wù)數(shù)據(jù)庫(kù)DB,最小支持度minsup,約束規(guī)則B;
第一次MapReduce:


第二次MapReduce:

3 DCFIBMR 算法實(shí)例講解
為了對(duì)DCFIBMR 算法的詳細(xì)挖掘流程進(jìn)行講解,設(shè)事務(wù)數(shù)據(jù)庫(kù)DB,其數(shù)據(jù)見(jiàn)表1,約束規(guī)則為B=(f∧c∧p)∨ (b∧i)及最小支持度為30%,從該事物數(shù)據(jù)庫(kù)DB中挖掘出滿足約束條件B的所有頻繁項(xiàng)目集合。
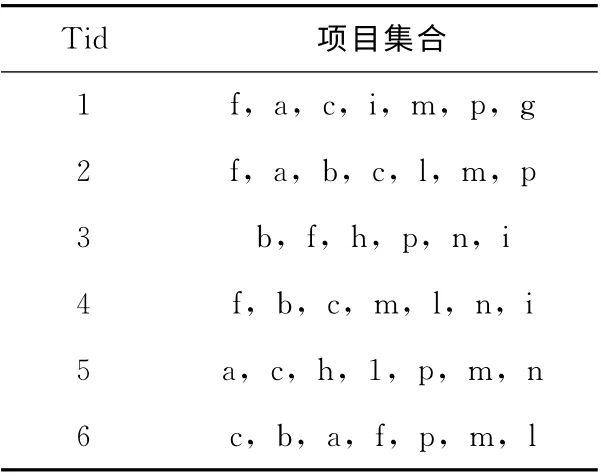
表1 事務(wù)數(shù)據(jù)庫(kù)D
首先,執(zhí)行一次MapReduce統(tǒng)計(jì)事務(wù)數(shù)據(jù)庫(kù)中的所有頻繁項(xiàng)及其出現(xiàn)的次數(shù),產(chǎn)生形如L= [{f:5},{c:5},{p:5},{m:5},{b:4},{a:4},{n:3},{h:2},{i:3}, {l:4}, {g:1}],從中剔除支持?jǐn)?shù)小于1.8 (6×30%)的頻繁項(xiàng),可以看出g出現(xiàn)次數(shù)小于1.8,將其從L中刪除。然后對(duì)L按照支持?jǐn)?shù)降序排列,組成F集合,F(xiàn)=[f,c,p,m,b,a,l,n,i,h]。
再執(zhí)行一次MapReduce,在本次執(zhí)行中將事務(wù)數(shù)據(jù)庫(kù)D,約束規(guī)則B,最小支持度30%及F集合作為輸入,通過(guò)相關(guān)的挖掘處理,輸出滿足要求的頻繁項(xiàng)集合。
Map階段:
本階段主要是對(duì)事務(wù)數(shù)據(jù)庫(kù)D 的分組及數(shù)據(jù)的分發(fā),以便于后續(xù)的并行計(jì)算。以D 中第一行Tid-1為例,首先對(duì)Tid-1中的項(xiàng)集按照頻繁項(xiàng)在F中的位置進(jìn)行降序排序,并刪除F中沒(méi)有的項(xiàng)集,得到T={f,c,p,m,a,i}。然后對(duì)T 進(jìn)行分組,形式如:{{f,c,p,m,a}|i}、{{f,c,p,m}|a}、{{f,c,p}|m}、{{f,c}|p}、{{f}|c(diǎn)}。在F中i的下標(biāo)為8,則將 {{f,c,p,m,a}|i}放入第8組中,并輸出:output<8, {f,c,p,m,a}>的鍵值對(duì),其中8為組編號(hào),{f,c,p,m,a}為i的條件模式基,其余幾項(xiàng)的分組同理i。
Reduce階段:
在Map階段,事務(wù)數(shù)據(jù)庫(kù)被進(jìn)行了分組及輸出,而在Reduce階段,會(huì)接收到被分到同一組內(nèi)的數(shù)據(jù)集合,形如<group-id,Values>,其中g(shù)roup-id為組的編號(hào),Values為同一組內(nèi)的數(shù)據(jù)集合;以頻繁項(xiàng)i為例,將會(huì)獲取到group-id=8,Values= ({f,c,p,m,a},{f,p,b,n},{f,c,m,b,l,n})。設(shè)定DB (8)= [{f,c,p,m,a},{f,p,b,n},{f,c,m,b,l,n}]。那么基于該局部數(shù)據(jù)庫(kù)構(gòu)建subFPtree,可構(gòu)建出如圖1 所示的頭表subHTable及子頻繁模式樹(shù)subFPtree。
設(shè)置前綴項(xiàng)prefix=F [8]=i,并判斷由subHTable中的各個(gè)頻繁項(xiàng)和prefix 組成的項(xiàng)集pattern= {{i,f},{i,c},{i,p},{i,m},{i,b},{i,n}}是否滿足約束規(guī)則B,從中可以看到頻繁集 {i,b}滿足要求。因此將{i,b}輸出。
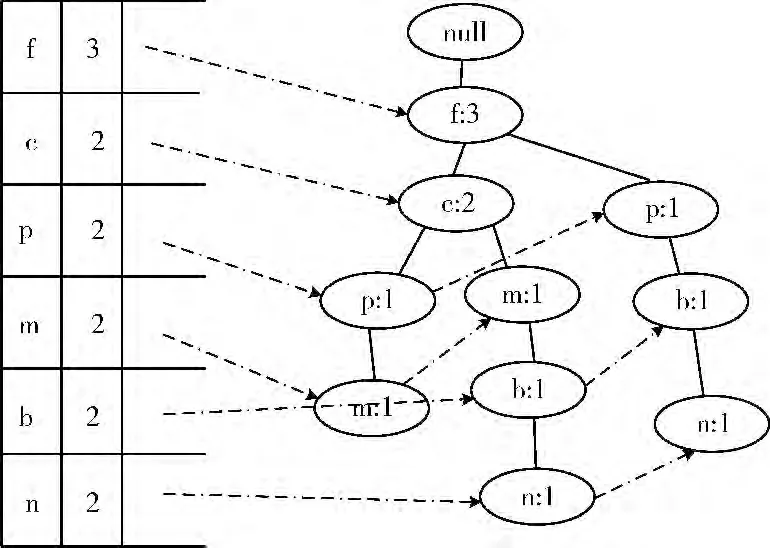
圖1 頭表及子頻繁模式樹(shù)
然后遍歷subHTable,在本例中對(duì)于頻繁項(xiàng)n,從sub-FPtree中可以找到以n為前綴的條件模式基集合cbase-n={{f,c,m,b},{f,p,b}},然后設(shè)置prefix=prefix+n,在集合cbase-n上建立頭表及頻繁模式樹(shù),挖掘過(guò)程同理i。最終,通過(guò)上述執(zhí)行步驟可挖掘出滿足約束規(guī)則B 的所有頻繁項(xiàng)集。
4 算法性能比較與分析
Direct*算法[11]是一種串行的基于頻繁模式樹(shù)的約束頻繁項(xiàng)集挖掘算法,在本次實(shí)驗(yàn)中將DCFIBMR 算法與Direct*算法進(jìn)行比較,可以得出如下結(jié)論:
(1)Direct*算法主要是基于Apriori思想,即不斷地由頻繁K 項(xiàng)集產(chǎn)生K+1候選項(xiàng)集,因此在算法執(zhí)行期間會(huì)產(chǎn)生大量的候選項(xiàng)集,并需要多次掃描數(shù)據(jù)庫(kù)[11],而DCFIBMR 算法在執(zhí)行過(guò)程中僅需要掃描兩次數(shù)據(jù)庫(kù),因此算法的執(zhí)行效率有顯著的提升。
(2)Direct*算法是一種典型的單任務(wù)執(zhí)行的算法,即一次只能執(zhí)行一個(gè)任務(wù),因此在處理海量數(shù)據(jù)挖掘任務(wù)時(shí),用戶(hù)需要等待很長(zhǎng)時(shí)間才會(huì)看到結(jié)果,而DCFIBMR 算法的主要優(yōu)勢(shì)在于可以將一個(gè)任務(wù)分成多個(gè)相對(duì)獨(dú)立的子任務(wù)在多臺(tái)計(jì)算機(jī)中進(jìn)行處理,因此可顯著降低用戶(hù)等待的時(shí)間。
為了進(jìn)一步驗(yàn)證本文算法的有效性,實(shí)驗(yàn)設(shè)計(jì)如下:
實(shí)驗(yàn)環(huán)境是4臺(tái)機(jī)器組成的集群,其中一臺(tái)作為主節(jié)點(diǎn),其余機(jī)器作為子節(jié)點(diǎn)。4 臺(tái)機(jī)器具有相同的硬件及軟件配置,每臺(tái)機(jī)器有兩個(gè)2.4GHz Intel處理器和360G 內(nèi)存,Ubuntu13.10系統(tǒng),Jdk1.7,以及0.20.2 版本的Hadoop,數(shù)據(jù)集是由IBM 的數(shù)據(jù)模擬生成器[12]所生成,數(shù)據(jù)集含有2113個(gè)數(shù)據(jù)項(xiàng),事務(wù)平均長(zhǎng)度64,事務(wù)最長(zhǎng)73。
圖2給出了在不同最小支持度 (40%,30%,20%,10%,5%,3%,1%)下隨機(jī)選擇幾個(gè)頻繁項(xiàng)組成約束條件B時(shí),Direct*算法與DCFIBMR 算法的執(zhí)行效率對(duì)比。從圖中的數(shù)據(jù)對(duì)比可知,在約束條件B 相同的條件下DC-FIBMR 算法的執(zhí)行效率遠(yuǎn)遠(yuǎn)高于Direct*算法,且隨著支持度的變小,DCFIBMR 算法相對(duì)于Direct*算法的效率顯著提升,因此該實(shí)驗(yàn)驗(yàn)證了DCFIBMR 算法的有效性。
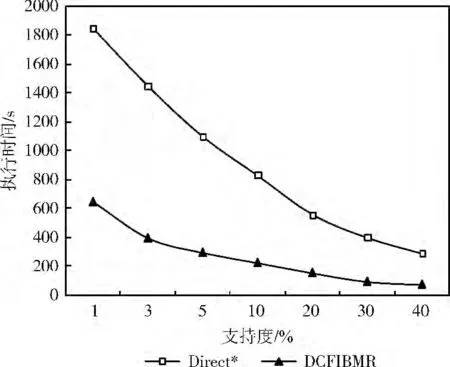
圖2 兩種算法在不同支持度下的執(zhí)行時(shí)間對(duì)比
5 結(jié)束語(yǔ)
從海量的數(shù)據(jù)中挖掘出滿足用戶(hù)指定約束條件的頻繁項(xiàng)集,使用傳統(tǒng)的串行算法是很難完成的任務(wù)。針對(duì)此類(lèi)問(wèn)題并結(jié)合目前流行的開(kāi)源框架MapReduce,提出一種并行的約束頻繁項(xiàng)集挖掘算法DCFIBMR,該算法由用戶(hù)來(lái)指定約束規(guī)則,利用MapReduce框架將一個(gè)完整任務(wù)拆分為若干個(gè)相對(duì)獨(dú)立的子任務(wù),由這些子任務(wù)根據(jù)約束規(guī)則從待處理的數(shù)據(jù)中挖掘出符合要求的頻繁項(xiàng)集,將從各個(gè)子任務(wù)中處理的結(jié)果進(jìn)行匯總整合,得到最終的處理結(jié)果。通過(guò)理論分析及實(shí)驗(yàn)驗(yàn)證了DCFIBMR 算法的有效性。
[1]Hai Duong,Tin Truong,Bac Le.An efficient algorithm for mining frequent itemsets with single constraint[J].Advanced Computational Methods for Knowledge Engineering,2013,479:367-378.
[2]Mohammad El-h(huán)ajj,Osmar R Zaiane.Parallel leap:Largescale maximal pattern mining in a distributed environment[C]//12th International Conference on Parallel and Distributed Systems,2006:230-232.
[3]HUA Hongjuan,ZHANG Jian,CHEN Shaohua.Miningalgorithm for constrained maximum frequent itemsets based on frequent pattern tree [J].Computer Engineering,2011,37(9):78-80 (in Chinese).[花紅娟,張健,陳少華.基于頻繁模式樹(shù)的約束最大頻繁項(xiàng)集挖掘算法 [J].計(jì)算機(jī)工程,2011,37 (9):78-80.]
[4]XU Xiaoyong,PAN Yu,LING Chen.Energy saving and scheduling resources under the cloud computing environment[J].Journal of Computer Applications,2012,32 (7):421-426 (in Chinese).[徐驍勇,潘郁,凌晨.云計(jì)算環(huán)境下資源的節(jié)能調(diào)度 [J].計(jì)算機(jī)應(yīng)用,2012,32 (7):421-426.]
[5]LI Tao,XIAO Nanfeng.Suitable large data sets of weighted frequent itemsets mining algorithm [J].Computer Engineering and Design,2014,35 (6):2114-2118 (in Chinese).[李濤,肖南峰.適用大數(shù)據(jù)集的帶權(quán)頻繁項(xiàng)集挖掘算法 [J].計(jì)算機(jī)工程與設(shè)計(jì),2014,35 (6):2114-2118.]
[6]Yang C,Yen C,Tan C,et al.Osprey:Implementing Map-Reducer-style fault tolerance in a shared-nothing distributed database[C]//International Conference on Data Engineering,2010:657-668.
[7]Dean J,Ghemawat S.MapReduce:A flexible data processing tool[J].Commun ACM,2011,53 (1):72-77.
[8]LIU Yi,ZHANG Kan.Workflow task assignmen strategy based on load balance and experiential value [J].Computer Engineering,2009,35 (21):232-234 (in Chinese). [劉怡,張戡.基于負(fù)載平衡和經(jīng)驗(yàn)值的工作流任務(wù)分配策略 [J].計(jì)算機(jī)工程,2009,35 (21):232-234.]
[9]LV Xueji,LI Longshu.Research on the algorithm of MapRe-duce FP-Growth [J].Computer Technology and Development,2012 (11):123-126 (in Chinese). [呂雪驥,李龍澍.FPGrowth算法MapReduce 化研究 [J].計(jì)算機(jī)技術(shù)與發(fā)展,2012 (11):123-126.]
[10]ZUO Liyun,ZUO Lifeng.Cloud computing scheduling optimization algorithm based on reservation category [J].Computer Engineering and Design,2012,33 (4):1357-1361 (in Chinese).[左利云,左利鋒.云計(jì)算中基于預(yù)先分類(lèi)的調(diào)度優(yōu)化算法[J].計(jì)算機(jī)工程與設(shè)計(jì),2012,33 (4):1357-1361.]
[11]LI Yingjie.New item constraint method for mining frequent itemsets[J].Computer Engineering and Applications,2009,45 (3):161-164 (in Chinese). [李英杰.項(xiàng)約束頻繁項(xiàng)集挖掘的新方法 [J].計(jì)算機(jī)工程與應(yīng)用,2009,45 (3):161-164.]
[12]IBM.IBM quest synthetic data generation code [EB/OL].http://www.almaden.ibm.com/,2009.
猜你喜歡
財(cái)經(jīng)(2017年15期)2017-07-03 22:40:49
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版)(2017年1期)2017-02-27 13:41:08
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
財(cái)經(jīng)(2015年3期)2015-06-09 17:41:31
財(cái)經(jīng)(2014年21期)2014-08-18 01:50:18
財(cái)經(jīng)(2014年6期)2014-03-12 08:28:19
財(cái)經(jīng)(2013年6期)2013-04-29 17:59:30
