基于詞項語義映射的短文本相似度算法
2015-12-23 01:01:20黃賢英張金鵬劉英濤趙明軍
計算機工程與設計 2015年6期
黃賢英,張金鵬,劉英濤,趙明軍
(重慶理工大學 計算機科學與工程學院,重慶400054)
0 引 言
當前短文本相似度[1-6]計算方法主要包括基于詞項比較的方法和基于HowNet語義詞典的方法[7]。因為文本的特征主要是通過詞項來反映,因此采用詞項比較來量化文本之間相似度是一種常用的方法,諸如提取文本之間共有詞項的比例[8]、比較文本之間詞項間的逆序關系[9]、統計詞項詞頻填充文本向量度量余弦相似度[10]。這種詞項比較方法相對適用于長文本,長文本的信息量能夠通過規模較大的詞項數量得到較為全面的反映。對短文本而言,通過數量稀疏的詞項難以全面地體現短文本的含義,因此衍生出基于HowNet語義詞典的方法,如文獻 [11,12]利用HowNet計算詞項相似度實現句子相似度計算,文獻 [13]將句子劃分為主語、謂語等部分,再利用HowNet語義詞典計算各句子成分之間相似度。這種基于語義詞典的方法在一定程度上反映短文本中詞項潛在的語義信息,但是HowNet語義詞典對詞項收錄數量的有限性較為嚴重地制約著詞項相似度的計算,HowNet語義詞典對未在詞典出現的新詞項的處理能力較弱。
本文針對基于詞項比較的方法和基于HowNet語義詞典方法存在的缺陷,分析中文短文本表達時主要依賴名詞、動詞、形容詞和副詞4種詞性,提出將短文本中詞項按詞性進行切分,不同詞性的詞項構建對應的詞性庫,對于某一種詞性,提取待比較的兩個文本中對應的詞性庫進行詞項歸并,構建相應的詞性向量,詞性向量中各個維度上的映射值通過取該維度對應詞項和詞性庫中所有詞項相似度最大值,各個維度上最終權值取映射值與該詞項在詞性庫中映射詞項的詞頻乘積,詞項間相似度計算采用HowNet語義詞典提供的算法,則短文本之間相似度運算轉換為詞性向量之間相似度運算。
1 改進的短文本相似度算法
短文本中詞項較為稀疏,通過數量非常有限的詞項來表現文本實為不易,詞項間的相互組合關系和語義關聯性在短文本表示中顯得尤為重要。短文本中不同詞性的詞項在語義表達時的作用各不相同[14],通過將短文本中詞項按詞性進行切分,并利用HowNet語義詞典完成詞項詞性向量權值映射。
1.1 短文本詞性切分
對于待比較的短文本MiT _A 和MiT _B,分別對MiT _A 和MiT _B進行分詞和詞性標注。詞性標注采用中科院的ICTCLAS工具[15],示例如圖1所示。

圖1 詞性標注
對于詞性標注后的短文本,按名詞、動詞、形容詞和副詞4 種詞性提取詞項并構建對應的詞性庫,短文本MiT _A 的詞性庫表示如式 (1)所示
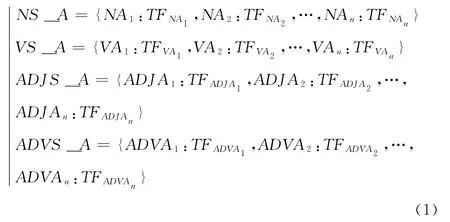
式中:NAi——詞項,TFNAi——該詞項對應的詞頻。式(1)中其它字符含義類似。
短文本中每個詞項都可以與對應的詞性庫中某個維度相對應,短文本MiT_B 的詞性庫表示與MiT_A 類似,詞性與詞性表示字符的對應關系見表1,只列出了本文需要考慮的名詞詞性、動詞詞性、形容詞詞性和副詞詞性。

表1 詞性與詞性字符表示對應
1.2 詞項權值計算
通過對詞性庫中詞項進行歸并,構建詞性向量。以名詞詞性向量為例,名詞詞項向量的表示如式 (2)所示
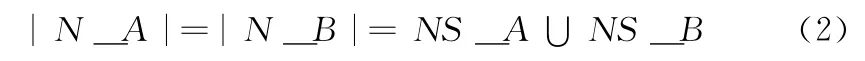
式中:|N_A|、|N_B|——名詞詞性向量N_A,N_B中詞項,不包括詞項權值,通過詞性庫NS_A 和詞性庫NS_B 中詞項歸并后得到,對于名詞詞性向量中各個維度上對應的詞項權值,將詞項向詞性庫映射完成,替代傳統的基于HowNet語義詞典的最佳詞項相似度匹配對發現的方法。
根據TF-IDF算法的定義,詞項在文本中出現的頻率越大,表明該詞項在文本中的重要程度越高[16]。在短文本中,這種理論同樣適用,詞項在短文本中出現次數越多,表明該詞項對文本的表征能力越強。以MiT _A 中名詞詞性向量N _A 為例,對于N_A 中某個詞項NAi,詞項間相似度計算采用文獻 [17]中算法,詞項NAi向名詞詞性庫的映射值如下所示
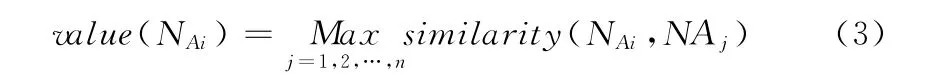
式中:similarity(NAi,NAj)——使用文獻 [17]中算法計算得到的詞項間的相似度,詞項向詞性庫中的映射值取該詞項與詞性庫中所有詞項相似度最大值,NAj表示詞項NAi在詞性庫中的映射詞項,名詞詞性向量N_A 中詞項NAi的最終權值如下所示
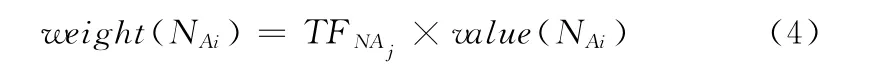
通過構建名詞詞性向量,名詞詞項向量作為整體向詞性庫中進行映射,若名詞詞性向量中詞項在詞性庫中出現,則置映射值為1,若未出現,則映射值為該詞項與詞項庫中所有詞項的最大相似度,待比較文本中詞項都映射到同一向量維度中,本方法集成了基于關鍵詞和基于HowNet語義詞典的優點,既較好地解決了HowNet詞典容量有限的缺陷 (詞項出現與否判斷),又兼顧了詞項間的語義相關性(詞項間語義相似度計算),具體示例見表2。動詞詞性向量、形容詞詞性向量和副詞詞性向量中詞項權值計算與名詞詞性向量中詞項權值計算方法相同。

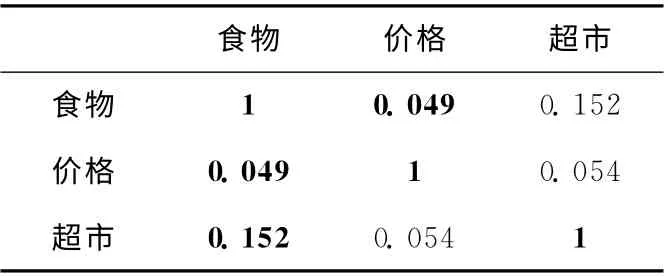
表2 詞項權值映射
1.3 詞性向量相似度計算
詞性向量相似度計算采用經典的余弦相似度[10],本節以名詞詞性向量相似度計算為例,其它詞性向量類似。
在圖2中,表示文本的初始化處理、詞性標注、詞性庫構建、詞性向量構建和詞項權值計算的過程。名詞詞性向量相似度計算如式下所示
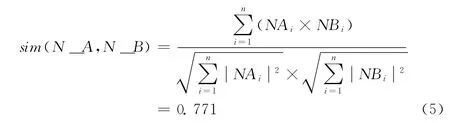

圖2 名詞詞性向量相似度計算
1.4 文本相似度計算
文本之間的相似度運算由名詞詞性向量相似度、動詞詞性向量相似度、形容詞詞性向量相似度和副詞詞性向量相似度4部分組成,計算方法如下所示
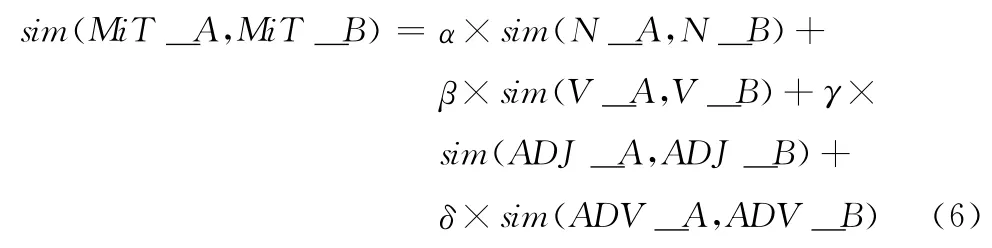
根據不同詞性的詞項在文本中重要程度不盡相同,在文本相似度計算時,為不同的詞性向量賦予不同的權值定義,由于待比較的文本處于時刻變化中,因此相應詞性向量的內容也在不斷變化,示例如圖3所示。
在圖3中,count(N_A)表示MiT _A 中名詞詞性向量中詞項數目,其它表示含義類似。示例1 中,名詞詞性向量中詞項的數目遠大于動詞詞性向量中詞項的數目,此時,名詞詞性向量因賦予較大的權值系數,而在示例2中,名詞詞性向量中詞項數目卻遠小于動詞詞性向量詞項數目,若仍按照示例1中所取權值系數固定分配,難免會造成在相似度計算時的局部不均勻性。
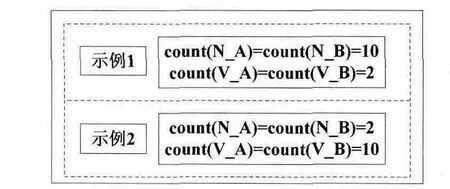
圖3 名詞詞性向量內容變化
詞性向量的權值系數并非固定不變而應當隨著待比較句子對的變化而變化,對詞性向量的權值進行動態定義,取決于當前詞性向量中詞項的數目與所有詞性向量詞項總和的比值,如下所示
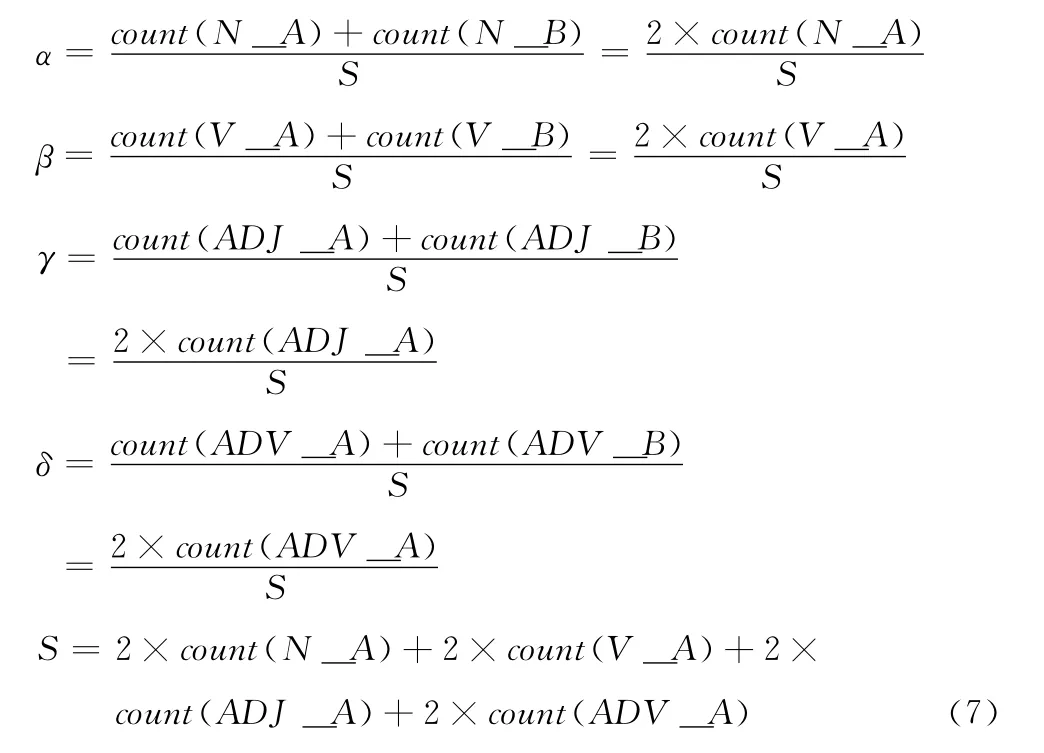
2 實驗與分析
本文的實驗數據來源于重慶理工大學計算機科學與工程學院的院長信箱數據,院長信箱主要用于本學院學生和學院進行教學和日常管理的一個簡易FAQ (frequently asked questions)系統平臺,該平臺的實驗數據可在“http://cs.cqut.edu.cn/DeanMail/MailList.aspx”網址處獲得,數據格式見表3。
本實驗選取時間段為 “2010/4/9-2013/9/11”共5992條記錄,提取表3中提問內容和回復內容項作為實驗時的短文本相似度比較實驗數據集。
2.1 實驗結果
本文采用余弦相似度算法 (similarity cosine algorithm,SCA)、關鍵詞重疊算法(similarity overlap algorithm,SOA)、基于語義詞典的算法 (similarity library algorithm,SLA)和本文算法 (similarity semantic algorithm,SSA)分別計算給定實驗數據集中短文本之間的相似度。
在表4中,分別選取Top_N 條數據的相似度平均值,SCA 算法、SOA 算法和SLA 算法的相似度平均值分別保持在0.09-0.11、0.08-0.09 和0.20-0.21,而本文算法(SSA)的相似度平均值明顯高于前3個算法,基本保持在0.37-0.39附近,SCA 算法和SOA 算法的相似度值平均值相對較低,SLA 算法的相似度平均值介于本文算法和SCA算法、SOA 算法之間。
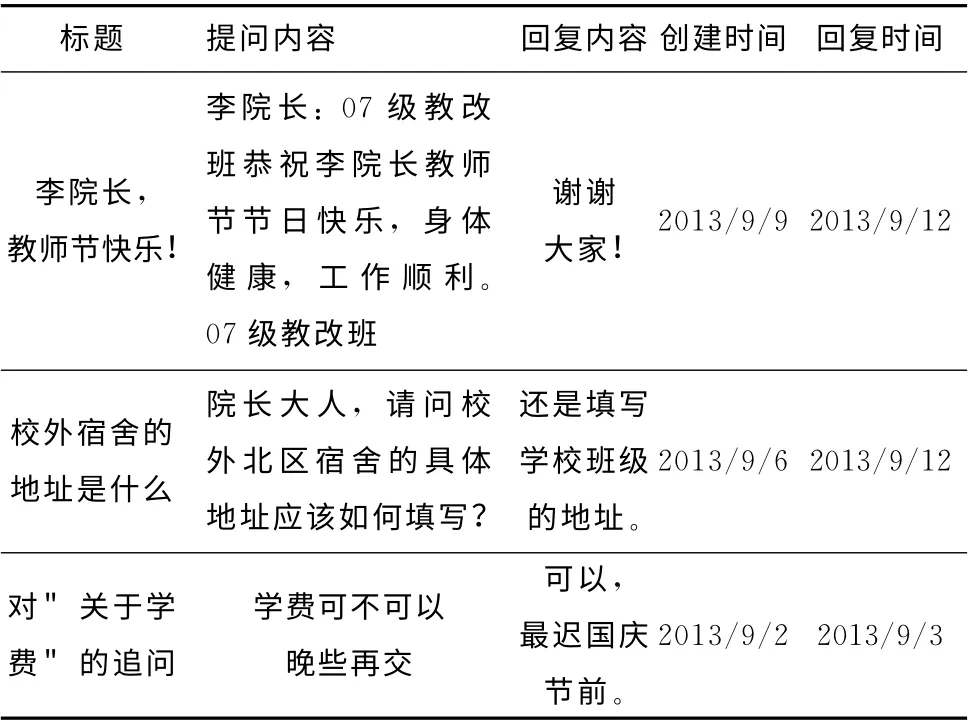
表3 院長信箱數據格式
在表5中,分別比較SCA 算法、SOA 算法、SLA 算法和本文算法在不同的相似度閾值下的準確率,準確率計算方式為:相似度閾值內句子對數目/數據集中句子對總數。
通過圖2中4種算法的對比圖可以發現,SCA 算法和SOA 算法在相似度閾值很小的情況下,最終的相似度運算準確率仍然偏低,而此時SLA 算法和SSA 算法的性能卻明顯高于前兩種算法,準確率都保持在非常高的水平,可以看出,在相似度閾值在0.05 以內時,SLA 算法和SSA 算法的準確率都能夠保持在90%以上且SLA 算法優于SSA算法。相似度閾值在0.15時,SLA 算法的性能出現了較大幅度的降低,SSA 算法在相似度閾值為0.19時準確率首次超過SLA 算法。當相似度閾值在0.30 時,SSA 算法的性能出現了大幅度的降低,但是此時卻明顯優于前3種算法。因此,SSA 算法從整體上來看要優于SLA 算法,數據的分布較為平均,且整體的相似度計算時的準確性也優于前3種,這一點也可以通過表4中相似度平均值數據得到驗證,而SLA 算法隨著相似度閾值的遞增會出現非常明顯的遞減。
SCA、SOA、SLA 和SSA 在不同相似度閾值下準確率如圖4所示。

表4 SCA、SOA、SLA 和SSA 在TopN 條數據下相似度平均值

表5 SCA、SOA、SLA和SSA在不同相似度閾值下準確率
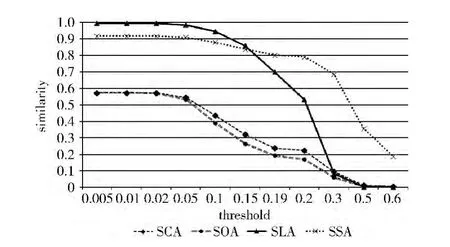
圖4 SCA、SOA、SLA和SSA在不同相似度閾值下準確率
2.2 實驗分析
本實驗主要針對余弦相似度算法、關鍵詞重疊算法、語義詞典算法和本文算法在相似度計算時性能進行分析,從實驗數據本身出發,數據中問答句子對基本上采用的是比較隨意的表述方式,在具體的關聯性方面顯得并非十分匹配,因此句子對之間的相似度總保持在較低的水平,這一點可在表4數據中得到反映。
從理論上來說,余弦相似度算法和關鍵詞重疊算法是完全基于關鍵詞是否在文本出現而進行定義的,這在很大程度上制約了運算時的準確性,須知中文在表達時的差異性和多樣性,相異的關鍵詞也可以表達相近甚至相同的含義,語義詞典算法和本文算法正是考慮了關鍵詞之間的相互關聯性,因此,語義詞典算法和本文算法應當在性能上要優于余弦相似度算法和關鍵詞重疊算法,這一點通過實驗中相似度平均值和不同閾值下的準確率得到驗證,語義詞典算法沒有考慮關鍵詞的詞性信息,收錄的關鍵詞數量也非常有限,因此,語義詞典算法在相似度平均值上要低于本文算法,雖然語義詞典算法在閾值較低的情況下準確率會優于本文算法,這正說明了語義詞典算法計算的短文本之間相似度值偏低,在相似度閾值數值設置較低時,較多的句子對被判定為相似,從而很好的佐證了語義詞典算法相似度計算的準確性不高。雖然實驗數據集相對比較粗糙,但是在同等程度下,可以粗略的認為提問內容項和回復內容項具有一定的關聯性 (問題-答案)。故從整體來說,本文算法要優于語義詞典算法,這可以通過相似度平均值較高,相似度閾值增大時相似度準確率均優于前3種算法加以印證。
3 結束語
本文針對基于詞項比較的相似度算法和基于HowNet語義詞典最佳詞項相似度匹配對發現的相似度算法存在的缺陷,提出一種結合詞項詞頻和詞項語義維度映射的新方法,這種方法既考慮了詞項在文本中詞頻特性,從而避免了因該詞項未被HowNet收錄而出現計算誤差,又兼顧了詞項之間的語義關聯性,實驗部分也很好的佐證了本文算法穩定性較好,相似度平均值均優于另外3種算法,相似度準確率也較高且保持在較為穩定的水平。
[1]HOU Yongshuai,ZHANG Yaoyun,WANG Xiaolong,et al.Recognition and retrieval of time-sensitive question in Chinese QA system [J].Journal of Computer Research and Development,2013,50 (12):2612-2620 (in Chinese). [侯永帥,張耀允,王曉龍,等.中文問答系統中時間敏感問句的識別和檢索 [J].計算機研究與發展,2013,50 (12):2612-2620.]
[2]JIANG Changjin,PENG Hong,MA Qianli,et al.Study on question parsing of restricted-domain Chinese question answering system [J].Computer Engineering and Design,2010,31(11):2589-2592 (in Chinese).[蔣昌金,彭宏,馬千里,等.受限領域中文問答系統問句分析研究 [J].計算機工程與設計,2010,31 (11):2589-2592.]
[3]Rasim M Alguliev,Ramiz M Aliguliyev,Makrufa S Hajirahimova.Maximum coverage and minimum redundant text summarization model [J].Expert Systems with Applications,2011,38 (12):14514-14522.
[4]Pawan Goyal,Laxmidhar Behera,Thomas Martin McGinnity.A context-based word indexing model for document summariza-tion [J].IEEE Transactions on Knowledge and Data Engineering,2013,25 (8):1693-1705.
[5]Chu Fong,Masrah Azrifah Azmi Murad,Shyamala C Doraisamy,et al.Measuring sentence similarity from both the perspectives of commonalities and differences[C]//Proceeding of the 22nd International Conference on Tools with Artificial Intelligence,2010.
[6]Ahmed Hamza Osman,Naomie Salim,Mohammed Salem Binwahlan.An improved plagiarism detection scheme based on semantic role labeling [J].Applied Soft Computing,2012,12(5):1493-1502.
[7]HUA Xiuli,ZHU Qiaoming,LI Peifeng.Chinese text similarity method research by combining semantic analysis with statistics [J].Application Research of Computers,2012,29(3):833-836 (in Chinese).[華秀麗,朱巧明,李培峰.語義分析與詞頻統計相結合的中文文本相似度量方法研究 [J].計算機應用研究,2012,29 (3):833-836.]
[8]Sergio Jimenez,Claudia Becerra,Alexander Gelbukh.A parameterized similarity function for text comparison [C]//First Joint Conference on Lexical and Computational Semantics,2012.
[9]ZHOU Faguo,YANG Bingru.New method for sentence similarity computing and its application in question answering system[J].Computer Engineering and Applications,2008,44 (1):165-178 (in Chinese).[周法國,楊炳儒.句子相似度計算新方法及在問答系統中的應用 [J].計算機工程與應用,2008,44 (1):165-178.]
[10]WU Quan’e,XIONG Hailing.Method for sentence similarity computation by integrating multi-features[J].Computer Systems and Applications,2010,19 (11):110-114 (in Chinese).[吳全娥,熊海靈.一種綜合多特征的句子相似度計算方法 [J].計算機系統應用,2010,19 (11):110-114.]
[11]ZHONG Maosheng,LIU Hui,ZOU Jian.The inter-sentence semantic relevancy degree calculation using the quantified correlation of words[J].Journal of Shandong University(Engineering Science),2010,40 (5):105-111 (in Chinese).[鐘茂生,劉慧,鄒箭.基于詞語量化相關關系的句際相關度計算 [J]. 山東大學學報(工學版),2010,40 (5):105-111.]
[12]CHENG Chuanpeng,WU Zhigang.A method of sentence similarity computing based on HowNet[J].Computer Engineering and Science,2012,34 (2):172-175 (in Chinese).[程傳鵬,吳志剛.一種基于知網的句子相似度計算方法[J].計算機工程與科學,2012,34 (2):172-175.]
[13]ZHENG Cheng,XIA Qingsong,SUN Changnian.Sentence similarity calculation based on composition [J].Computer Technology and Development,2012,22 (12):101-104 (in Chinese).[鄭誠,夏青松,孫昌年.一種基于成分的句子相似度計算[J].計算機技術與發展,2012,22 (12):101-104.]
[14]WU Quan’e.Chinese sentences similarity computation and its application in question-answering system [D].Chongqing:Southwest University,2011(in Chinese).[吳全娥.漢語句子相似度計算及其在自動問答系統中的應用[D].重慶:西南大學,2011]
[15]ICTCLAS [EB/OL].http://www.nlpir.org/download/ICTCLAS2012-SDK-0101.rar/,2001-2009.
[16]HUANG Chenghui,YIN Jian,HOU Fang.A text similarity measurement combing word semantic information with TF-IDF method [J].Chinese Journal of Computers,2011,34 (5):856-864 (in Chinese).[黃承慧,印鑒,侯昉.一種結合詞項語義信息和TF-IDF方法的文本相似度量方法 [J].計算機學報,2011,34 (5):856-864.]
[17]GE Bin,LI Fangfang,GUO Silu,et al.Word’s semantic similarity computation method based on HowNet[J].Application Research of Computers,2010,27 (9):3329-3333 (in Chinese).[葛斌,李芳芳,郭絲路,等.基于知網的詞匯語義相似度計算方法研究 [J].計算機應用研究,2010,27(9):3329-3333.]
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
當代修辭學(2011年6期)2011-01-29 02:49:50
