大數據環境下基于MapReduce的網絡輿情熱點發現
2015-12-25 14:28:08王書夢吳曉松
軟件 2015年7期
關鍵詞:大數據
王書夢 吳曉松

摘要:大數據環境下的網絡輿情分析更側重于在海量數據的采集、存儲、清洗和文本聚類,因此傳統的僅依據數據統計的輿情分析方法不再適用。文章對大數據網絡輿情分析的相關文獻進行總結研究,歸納出網絡輿情分析的基本流程框架,并闡明了在大數據環境下網絡輿情分析中文本聚類的各個階段如何運用MapReduce進行分布式計算,以此提高網絡輿情分析的準確度與及時性。
關鍵詞:大數據;輿情熱點;MapReduce;文本聚類
中圖分類號:TP391.1
文獻標識碼:A
DOI: 10.3969/j.issn.1003-6970.2015.07.022
0 引言
輿情是一定時期一定范圍內社會民眾對社會現實的主觀反映,是群體性的態度、思想、情緒和要求的綜合表現。大數據時代已經到來,大數據下的網絡輿情分析已經成為當前政府和科研機構研究的熱點問題。2011年,經濟學人發表“Building with big data”指出在數據極度膨脹的時代,要掌握數據分析的能力,成為數據的主人,而不要成為數據的奴隸。
在大數據時代,如何及時的收集、分析處理海量數據,并為決策者提供有用的信息是當前研究的熱點與難點。相較于傳統的輿情分析,大數據環境下的網絡輿情分析更側重于在海量數據的采集、存儲、清洗和文本聚類,因此傳統的僅依據數據統計的輿情分析方法不再適用。
文章對大數據網絡輿情分析的相關文獻進行總結研究,歸納出網絡輿情分析的基本流程框架,并提出了在大數據環境下網絡輿情分析各個階段的解決方案,構建大數據網絡輿情分析的基礎模型,以此提高網絡輿情分析的準確度與及時性。
1 網絡輿情分析發展概述
從已有的輿情分析的相關文獻中不難發現,社會輿情分析大致經歷了以下幾個階段,簡單的社會輿情分析,網絡輿情分析和大數據環境下的網絡輿情分析三個階段。簡單的社會輿情分析主要分析當下熱點事件、政府頒布的法令法規與社會輿情之間的關系。簡單的社會輿情分析主要通過問卷調查取得原始數據進行分析,例如MacLennan等通過抽樣調查的方式研究新西蘭民眾對于酒精政策的態度,Alan等使用蓋洛普世界民意調查數據研究了恐怖襲擊與民眾態度之間的關系。網絡輿情分析伴隨著Facebook、微博、微信、人人、Twitter等社交網絡平臺的興起應用而生,例如著名的Ceron通過分析2012年Twitter上的法國大選時網民的情感取向數據預測大選的結果。大數據環境下的網絡輿情分析是在海量、多樣性網絡數據的背景下利用大數據分析技術進行的網絡輿情分析。
目前大數據時代的數據具有規模性、多樣性、變化快速性特征,首先由于網絡的開放性每天產生大量的信息,其次多媒體的發展使得數據有多種形態比如文本、視頻、圖片、音頻等。基于目前網絡輿情分析的大數據特征,出現了以下幾種網絡輿情分析方法:基于網絡日志數據挖掘的輿情分析、基于社會網絡分析的輿情主體關系發現、網絡輿情熱點分析、關聯不同領域的數據輿情分析。
大數據網絡輿情分析是一個熱點問題,從現有的研究文獻來看,對于大數據網絡輿情分析更多的是體現在大數據輿情分析的機遇與挑戰、以及研究方法的概述與總結上,從技術層面對大數據網絡輿情分析的研究較少。
2 大數據網絡輿情分析技術
2.1 大數據技術
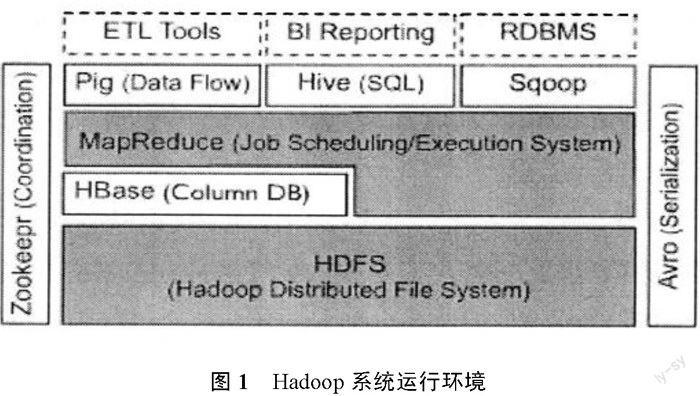
大數據時代的到來對現有的數據處理技術帶來了巨大的挑戰,目前針對大數據的多樣性等特征,在數據存儲和數據處理方面都提出了相應的解決方案。在數據存儲方面,目前網絡輿情分析的數據存儲方法主要還是將獲取的熱點數據直接存儲在傳統的SQLServer、ORACLE、Sybase等數據庫中,大數據的出現導致數據結構多樣性,傳統的結構性數據庫遠不能滿足當下快速多樣的大數據存儲的要求,對此目前出現了三種大數據的存儲技術:針對海量的非結構化數據的分布式文件存儲系統、針對海量半結構化數據存儲的NoSQL數據庫、針對海量結構化數據存儲的分布式并行數據庫。在數據計算處理方面,目前并行處理和云計算是解決大數據計算的比較有效率的方式,Hadoop是當前學術界和企業用來解決大數據存儲和分析的一個主要技術手段,它是Apache開源分布系統的架構基礎,由HDFS、MapReduce和HBase組成,其運行環境如圖1所示。
(l)HDFS(Hadoop分布式文件系統)
HDFS是整個Hadoop體系結構中處于最基礎的地位,分為三個部分:客戶端、主控節點(Namenode)和數據節點(Datanode)。Nanenode是分布式文件系統的管理者,主要負責文件系統的命名空間、集群的配置信息和數據塊的復制信息等,并將文件系統的元數據存儲在內存中;Datanode是文件實際存儲的位置,它將數據塊(Block)信息存儲在本地文件系統中,并且通過周期性的心跳報文將所有數據塊信息發送給Namenode。
(2)MapReduce
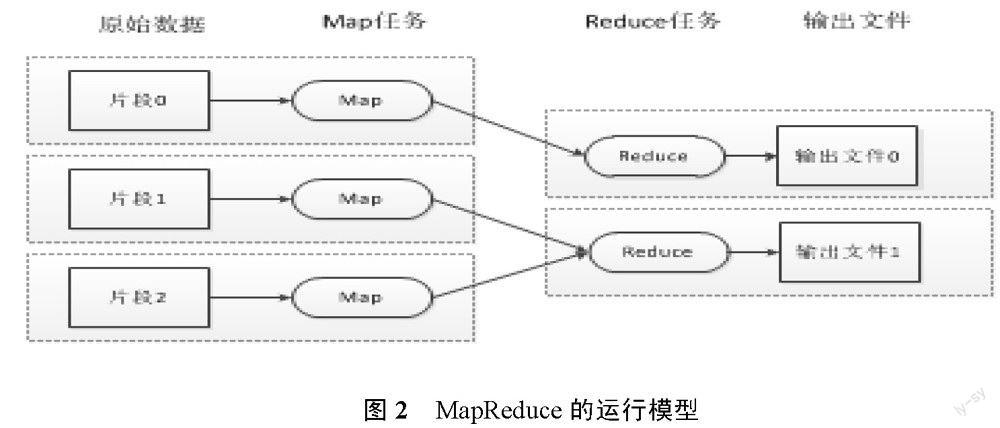
MapReduce分布式計算模型,封裝了并行運算、容錯處理、本地化計算、負載均衡等細節,提供了簡單而強大的接口。通過這個接口,可以把大數據量的計算自動地并發和分布執行,其運行模型如圖2所示。
(3) HBase
HBase即Hadoop Database,是一個構建在HSFS上,面向列的開源分布式數據庫系統,是GoogleBigtable的開源實現。HBase不是關系型數據庫,不支持SQL,HBase提供了一組簡單的API接口,用于存儲和管理數據。
2.2 網絡輿情分析技術
網絡輿情分析主要涉及數據采集、文本分詞、文本向量表示、文本聚類分類幾個方面。
(1)向量空間模型
向量空間模型(VSM)起源于信息檢索,簡單說來VSM是一種將非結構化的文本表示成向量形式的模型,網絡文本用VSM向量空間模型來表示:
v(d)=(t1,w1(t1);…;ti,wi(ti);…tIl,wn(tn))
其中,ti為網絡文本d的關鍵詞,wi(ti)為關鍵詞的權值。
如何確定關鍵詞和關鍵詞的權重是網絡輿情分析是否有效的關鍵因素,文章采用TF.IDF指標來確定網絡文本的關鍵詞和權值。詞頻(TF)指的是某一文檔中給定單詞出現的頻次,規范化的表示一般用給定單詞的頻數除以文檔總的單詞數。IDF是指逆向文件頻率,是一個詞語普遍性的度量,規范性的表示一般由包含此單詞的文檔的數量除以文檔的總數,然后取對數得到。
(2)文本相似度計算
相似度計算方式目前有海明距離(Hamming Distance)、歐幾里得距離(Euclidean Distance)、余弦距離(Cosine Distance),其中文本相似度計算比較常用的是余弦距離,其計算公式1如下
其中,ai、bi是文本A和B的項。余弦距離的取值區間是[0,1],“0”代表兩個文本完全一樣,“1”代表兩個文本完全不相似。
(3)文本聚類算法
文本聚類算法有很多,比較常用的有四種,基于層次的聚類、基于密度的聚類、基于網格的聚類、基于劃分的聚類。文章選用在文本聚類中應用比較多的基于劃分的聚類中的K-Means算法,其流程如表1所示。
3 實驗方案
文章對大數據環境下網絡輿情熱點發現提出了基本的技術路線如圖3所示
3.1 數據采集
網絡信息的采集可以利用網絡爬蟲技術在特定的網站上進行數據收集也可以利用網站的API接口直接對網站的信息進行采集,獲得的網站數據存儲在Hbase中。傳統的基于網絡爬蟲的網頁解析方式抓取速度較慢,在大數據環境下基于某網站API的分布式數據抓取具有更快的速度。
文章采用了基于Mapreduce的文本采集技術對網站信息進行采集,將普通的網頁爬蟲系統部署在hadoop平臺上,文本采集由主節點和若干分節點組成,主節點作為爬蟲系統的NameNode和Jobtracker,負責文件管理及任務調度;分節點作為DataNode和TaskTracker,負責存儲文件及運行任務。Jobtracker作為主節點負責分發任務給各分節點,在Map階段分節點TaskTracker通過網站API進行信息抓取,抓取的數據分布存儲在各個DataNode中。
3.2 數據預處理
數據的預處理主要是對原始數據的清洗、抽取元數據,對于網絡的文本信息預處理主要是文本的分詞、去停用詞(主要是一些標點、單字和一些沒有具體意義的詞,如:的、了等重復出現的詞)、文本的特征向量提取、詞頻統計、文本的模型化表示等操作。
文章采用基于MapReduce的文本預處理技術,MapReduce以函數的方式提供了Map和Reduce操作來進行分布式計算,利用一個輸入key/value集合來產生一個輸出的key/value集合。在文本預處理過程中,Map函數主要完成文本的分詞,將輸入的文本進行中文分詞,形成詞語序列(X1、x2、x3、x4……、Xn)將文本用key/value的形式表示,輸出的形式為:(xl、1),(x2、1),(x3、1),……,(xn、1),當所有的Map任務完成后,由主程序將Map函數的輸出作為Reduce函數的輸入即Reduce函數的輸人為(k,[vl、v2、……、vn]),其中(k,V1),(k,v2)……,,(k,vn)Map函數輸出結果中鍵為k的key/value值,如表2所示Map處理過程。
Reduce函數需要計算出特定某個詞的IDF值,通過IDF的計算公式 可知需要知道文本數據大小和詞語在文本中出現的頻率,此時Map輸出的Value值為詞語的頻率,N在文本預處理時可以直接計算得到,經過Reduce計算過后可得到詞語的IDF值,將之與Value中的TF值相乘可得到詞語的TF.IDF值,將其存儲在HBase中的TF.IDF表中。
對于每個文檔,保留排列在前面的10個TF.IDF值,識別其對應的主題,以向量空間模型(VSM)表示,行表示主題數,列表示文檔數,通過VSM與單位列向量的乘積統計出每個主題所包含的文檔數,從而發現網絡輿情熱點。以上的主題識別和VSM矩陣向量的乘法,同樣可以通過Map和Reduce分布式計算得到,在此就不再贅述。
4 實驗結果
文章的實驗環境總共有四臺主機,其中每臺機器搭載CORE 15雙核處理器,1G內存,500G硬盤,選擇其中一臺主機作為master節點,剩余3臺作為slaves節點,配置Hadoop,配置Linux和Eclipse。文章通過新浪微博的網站API收集了170萬條數據,利用上述數據分析方法,對數據進行分析處理得到的分析結果如表3所示:
實驗結果與2014年新浪微博熱點話題分析報告里的結果有很大程度上的相似,說明了并行分析的準確性,而實驗用時比起傳統的分析方法節約了很多時間。
5 結論與展望
隨著互聯網的快速發展,每天都會產生巨大的網絡數據,如何快速有效的分析處理數據而不是讓數據成為災難,是在大數據環境下迫切需要解決的問題,在海量的網絡數據中快速的獲得準確的輿情信息是當前研究的熱點和重點。文章結合網絡輿情熱點發現的基本理論方法和大數據處理技術,提出了在大數據環境下分布式輿情分析的解決方案,重點對網絡輿情分析中數據的分布式預處理做了詳述,最后利用K-means聚類算法進行網絡輿情熱點發現。
當然文章還存在很多不足,只是對網絡輿情分析的基本過程使用了分布式的處理方法,關于輿情分析過程中的情感傾向分析以及語義分析并未進行研究。
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
