基于語料庫的蒙古人名知識庫建設與實踐
2016-01-19 02:52:52通拉嘎李佳正泉州師范學院圖書館福建泉州6000中國科學院計算技術研究所北京0090中國移動北京分公司北京00007
圖書館理論與實踐 2015年2期
關鍵詞:實驗
●通拉嘎,劉 凱,李佳正(.泉州師范學院 圖書館,福建 泉州 6000;.中國科學院計算技術研究所,北京 0090;.中國移動北京分公司,北京 00007)
基于語料庫的蒙古人名知識庫建設與實踐
●通拉嘎1,劉凱2,李佳正3
(1.泉州師范學院圖書館,福建泉州362000;2.中國科學院計算技術研究所,北京100190;3.中國移動北京分公司,北京100007)
[關鍵詞]語料庫;人名;蒙古人名;最大熵;特征選擇;實驗
[摘要]為提取較為完備的蒙古人名特征,以內蒙古大學語料庫及網頁人名句為基礎,采用量化分析的方法,建立普通人名知識庫及兼類人名知識庫,將知識庫歸并為14個特征,進行特征選擇實驗,在直接保留“漢語姓氏映射表”及“漢語人名映射表”等特征集后,鑒于對正確率和召回率的貢獻,去除了地名詞典、地名后綴詞典、機構名后綴詞典等3個特征集,保留了9個作為最大熵模型的特征集,從實驗結果看,予以保留的特征影響并不相同。
1 引言
命名實體往往包含了文章的主要內容,是正確理解文本的基礎。人名等命名實體在文本中有很高的使用頻率,是開放的集合,無法窮舉,在未登錄詞中占有相當大的比例,鄭家恒[1]統計出人名在未登錄詞中的比例是30.24%。人名等命名實體的識別(NER)是信息抽取的子任務,是自然語言處理的基礎工作,是詞法分析與標注的重點及難點之一。要取得更高的正確率,必須解決人名等命名實體的識別問題。人名可以分為普通人名及兼類人名,人名識別的主要難點是兼類人名的識別,因為命名實體之間、人名和普通詞之間存在大量的歧義和沖突。為實現蒙古文人名識別,本文建立了人名知識庫,并對知識庫進行特征選擇實驗,以期尋找出更有利于統計模型的知識。
最大熵模型(ME)是一個通用的機器學習框架,最早由E.T.Jaynes于1957年提出,在自然語言處理方面的應用非常廣泛,已經成功應用于不同的研究領域,如詞法分析、組塊分析、短語識別、詞義消歧、指代消解、文本分類、句子的邊界檢測等,并且表現良好。最大熵的兩個基本任務是特征選擇和參數估計。特征選擇,就是選能表達這個隨機過程的特征集合,使系統的特定指標最優化。特征空間很大,并不是每一個特征都是可靠的,所以選擇特征就是很關鍵的問題,對模型的訓練和使用都十分重要,最大熵通過特征選擇可以減少計算量,降低噪聲,對識別的正確率及解碼的效率都有很大影響。
為提取較為完備的蒙古文人名特征,本文以蒙古文語料庫為基礎,建立了普通人名知識庫及兼類人名知識庫,并以最大熵的統計模型,對人名知識庫中的各類特征進行選擇實驗,從中提取了更為有效的人名特征,為進一步的人名識別工作做好準備。
2 語料庫的應用
語料庫是統計建模的知識來源,是蒙古文人名識別的基礎與前提,用以提取人名前后詞、規則及訓練最大熵模型。
2.1內蒙古大學詞法標注語料庫
26萬詞規模詞法標注語料庫是內蒙古大學蒙學院詞法標注語料庫的局部,一詞一行,切分與標注出詞干及附加成分,格式為蒙古文拉丁形式。語料來源是中小學蒙古語課本共12冊,《內蒙古日報》1988年7月1~3日,《實踐》月刊1988年1~3期,含264000
詞(包含標點符號)。[2]有3522個人名句可以提取人名的前后詞規則,但由于標注格式問題,提取到的是2570個人名句。
2.2網頁蒙古人名句
自建的5千人名句用作最大熵模型訓練,共5773句。人名句從蒙科立編碼的中國蒙古語新聞網、人民網(蒙古文版)、蒙古文化網等9個網站人工抓取。網站選取原則為統一的蒙科立編碼,句子選取原則為人名句,盡量為兼類人名句。從上述網站上抓取人名句,以蒙科立轉拉丁的編碼轉換工具轉換為內蒙古大學拉丁格式,并著重對人名及前后兩詞進行校對。
2.3測試集的選取
訓練及測試所用的句子共為8343句,共11583個人名。封閉測試集是訓練集的子集,開放測試集與訓練集不存在包含與被包含關系。使用的訓練集、測試集的各項數據如表1。
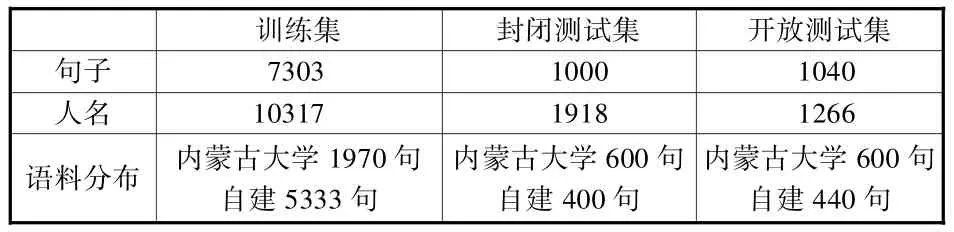
表1 訓練集、測試集數據統計表
3 人名知識庫的建立
3.1普通人名知識庫的構建
蒙古文語料庫規模偏小,形態變化眾多,建設相關的知識庫,以此提取人名識別的各類特征,保證識別的指導性。相對于中文人名識別中較為常見的姓氏、名字用字概率信息的使用,蒙古文人名識別更加側重運用形態特征及上下文信息。因此,構建的普通人名知識庫包括以下10個知識庫:姓氏辭典(漢語姓氏、蒙古姓氏),漢語姓氏拉丁映射表,梵、藏、滿人名詞典,地名詞典,人名指示詞庫(左邊界詞典、右邊界詞典、有距離邊界詞典),機構名后綴詞典,蒙古族普通人名詞典,漢語名拉丁映射表,著名人物詞典,地名后綴詞典。
(1)姓氏詞典。中文文本中的姓氏根據是否可以獨立成詞,分為絕對封閉的姓氏、相對封閉的姓氏、開放姓氏等。[3]蒙古文本中的姓氏很多是絕對封閉姓氏,與其他詞無法構詞,也不易獨立成詞,所以,蒙古文本中姓氏是識別人名的重要知識來源,收集的姓氏包括漢語姓氏及蒙古姓氏。①蒙古姓氏詞典。以曹納木的《蒙古族姓氏集》[4]列舉的蒙古族姓氏1133個為基礎,輔之拉丁轉寫,建立了蒙古族蒙古姓氏詞典,如“ANGCIN安、ABAHANAR安”等。②漢語姓氏詞典。蒙古族漢語姓氏庫的建立以曹納木的《蒙古族姓氏集》為數據基礎,漢語姓氏共419個,除去重復姓氏9個,共包含蒙古族漢語姓氏410個,輔之拉丁轉寫,如“B0V包薄寶保鮑暴爆”、BI鼻畢、DONG東冬董棟”。漢語姓氏詞典的建立以《姓氏人名用字分析統計》[5]為依據,共有734個姓氏,按拉丁轉寫順序重新排序錄入,如“SI郗奚席溪司思郗習洗喜”等。不過漢語姓氏在語料庫中與其他詞發生兼類的現象較難排除,所以,在實際實驗中,僅選取了蒙古姓氏詞典為特征。
(2)人名詞典。人名詞典對有效識別人名很有意義,有助于提高系統的執行速度及效率,建立人名詞典是必要的。不過蒙古文網站有很多不同的編碼格式,無法直接像漢語人名一樣從浩瀚網絡抓取,因而本文的人名詞典建立只能以學生名為主,輔之語料庫人名及某刊物作者名的搜集;蒙古國人名與中國蒙古族人名相比也有其不同分布特點,因而也收集了一定的蒙古國人名,這些人名被整理歸入“普通人名詞典”。
14世紀至17世紀,蒙古族十分盛行以梵、藏、滿文字為人名,這些正逐漸退出蒙古族人名歷史舞臺的名字,可用列舉的方法予以識別,本文建立了有“YVNDVN(云敦)、SURUNG(蘇榮)”等582個詞條的“梵、藏、滿人名詞典”。著名人物名在文本中出現頻率較高,文章還建立了包括“TEMUJIN(鐵木真)、SONG=GING=LING(宋慶齡)”等244個名字的“著名人物詞典”。
(3)漢語姓氏、人名拉丁映射表。漢語名在蒙古文本中占有很高比例,所以,漢語人名知識庫的建立也是研究的重點之一。然而,人名是無法窮舉的命名實體,研究者在姓氏與人名詞典的基礎上,提煉出漢語姓氏拉丁映射表、漢語名拉丁映射表,以姓氏及人名的搭配爭取識別更多的漢語人名。
漢語姓氏拉丁映射表即以“漢族漢語姓氏詞典”為基礎,將其轉寫為蒙古文拉丁形式,如“BU卜補布步佈、LU盧蘆魯陸鹿逯路”等;共有301詞條;漢語人名拉丁映射表即以漢語人名為基礎,將人名歸結為不同拉丁轉寫形式。聲調對拉丁轉寫并無影響,因而,將聲調不同、拼音相同的漢語人名用詞,如“楊、洋、陽、揚”都轉寫為“YANG”,共含記錄190條。
(4)指示詞庫的建立。指示詞指在人名句中出現頻率較高,與人名有語義或語法聯系,對人名的存在與識別有指示作用的詞。蒙古文人名的指示詞有親屬稱謂詞、人體詞、稱謂詞、職務詞、職稱詞、特定行
為動詞等。文章將指示詞分為左邊界詞、右邊界詞、有距離邊界詞,將其作為最大熵模型的上下文邊界特征。人名左邊界詞分別為稱謂詞、親屬稱謂詞、職務詞、職業詞、部分的形容詞、數詞;人名右邊界詞分別為稱謂詞、親屬稱謂詞、人體詞、職務詞、職業詞、部分連詞、副詞、形容詞、語氣詞;特定行為動詞與人名距離較遠,被稱為有距離邊界詞。具體的數據量見表2。
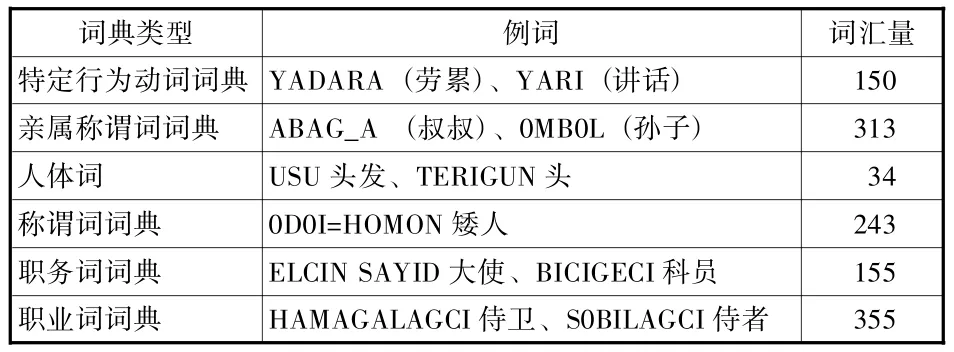
表2 指示詞庫詞匯量統計
(5)地名詞典。蒙古族歷來注重人與自然的和諧共處,崇尚以山川、河流、國名、城市為人名,喜歡以地名作人名,如“H0RCIN(科爾沁)、ENEDHEG(印度)”都是人名、地名的兼類詞。地名對人名有一定的指示作用,鑒于地名對人名識別的重要性,本文建立了“地名詞典”,包括“$ANDUiNG(山東)、ALA$A(阿拉善)”等中外地名詞共558個。
(6)地名后綴詞典及機構名后綴詞典。地名后綴詞典及機構名后綴詞典有助于識別地名及機構名,進而有利于確定人名的位置。本文建立了包括“YEHE ASAR(大樓)”等130個詞的“地名后綴詞典”,包括“ARIHIN MVHVLAG(酒館)、0RD0N(殿、宮)”等83個詞的“機構名后綴詞典”。
3.2兼類人名知識庫的建立
兼類人名指一個詞兼屬人名及其他詞類。如“BOHE”(布赫),既是人名,也是普通名詞及形容詞。筆者隨機統計了中央民族大學蒙古語言文學系1953~1997級,2004~2011級蒙古族907個學生人名。其中,可以充當兼類人名的詞共有205個,占人名總數的22.60%。從上述數據可以看出,兼類人名在人名當中有相當高的比例。兼類人名不僅出現頻率較高,而且較難識別,為識別兼類人名,需要建立專門的兼類人名知識庫。
以往的兼類詞識別方法較多使用詞語的詞性信息,詞性信息對兼類人名的識別有重要的輔助作用,但鑒于蒙古文現有的切分與詞性標注系統在命名實體識別上較為薄弱,如果運用詞性信息識別人名,會出現將人名詞誤切分或標注為更小顆粒的情況,導致歧義或誤差,因而在本研究中未使用兼類人名的詞性信息。
兼類人名詞典的建立依賴于內蒙古大學語料庫、5千網頁人名句及蒙古人名詞典,從上述數據中提取到未重復兼類人名共968個。蒙古人名中復合人名占很大比例,因而,只依靠人名詞典而不考慮人名的復合情況是不完整的。為此還建立了蒙古人名詞干詞典,包含“YEHE(耶和)”等1336個可以充當人名的蒙古人名詞干詞典,用以識別任何與詞典中的詞復合產生的蒙古人名。具體應用中發現“兼類人名詞典”及“蒙古人名詞干詞典”有大部分的重合,因而,將其合并為“兼類人名詞典”。
兼類詞搭配詞典指列舉兼類人名的固定搭配詞,遇到兼類人名,以兼類詞搭配詞典進行匹配,這對兼類人名詞的判斷起著重要的輔助作用。基于內蒙古大學語料庫及德·青格樂圖的《現代蒙古語固定短語語法信息詞典詳解》[6]收集了2383個兼類詞搭配詞,以兼類人名為中心,提取前后2位的搭配詞,制作成excel表格,每行為一條兼類信息。
4 最大熵特征選擇實驗
4.1實施方案
最大熵模型的關鍵在于如何用特定的任務為模型選取特征集合。特征可以分為基本特征和語言學特征,語言學特征包括上下文特征、詞典特征等知識。
在最大熵模型中使用的特征集={地名詞典,蒙古族蒙古姓氏詞典,著名人物詞典,地名后綴詞典,機構名后綴詞典,漢語姓氏映射表,漢語人名映射表,有距離邊界詞典,左邊界詞詞典,右邊界詞詞典,梵藏滿人名詞典,兼類人名詞典,蒙古人名詞典,兼類搭配詞典},共包含14個特征。雖然最大熵可以不用設定規則的優先集來避免規則的沖突,但是所使用的特征集中哪些特征是有效的,哪些特征有副作用。為驗證特征集中各個特征的效果,設計了以下方案。
(1)令特征集=簡單上下文特征集,在特征集的基礎上訓練最大熵模型,然后進行測試。
(2)在原始的簡單上下文特征集的基礎上,逐次加入某一項新特征,在新特征集的基礎上訓練最大熵模型,然后進行測試,參考開放測試的結果,如果某特征集導致正確率和召回率都下降,說明該特征是無效特征,予以去除;如果正確率和召回率都有一定提升,表明該特征的有效性,則保留該特征,直至每個特征集都實驗過。需要指出的是,鑒于漢語人名在語
料庫中出現較多,形式與蒙古人名又有較大區別,漢語姓氏映射表與漢語人名拉丁映射表能覆蓋大多數人名,因此,本文直接選取“漢語姓氏映射表”、“漢語人名映射表”為最大熵的特征,未經過特征選取的步驟。
4.2特征選擇實驗
在制定具體實施方案后,以最大熵計算了簡單上下文特征集的正確率及召回率,以此為基礎,逐步加入各語言學特征,進行特征選擇實驗,實驗結果如表3所示。
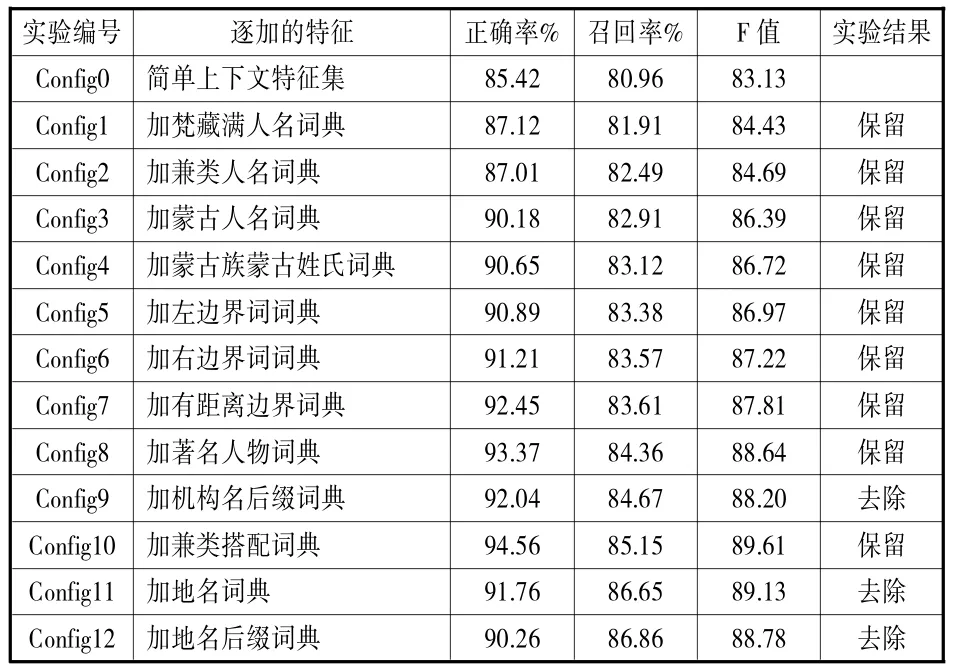
表3 特征選擇實驗
建立地名詞典、地名后綴詞典是因為人名與地名兼類的現象在蒙古文中出現較多,語料庫中地名對人名有一定的指稱作用,因而,希望以此來排除與地名的兼類現象,但能滿足這些特征的情況還是較少,而且地名及地名后綴與人名的距離有時過遠,運用這些特征后不僅正確率和召回率都有一定程度下降,也影響了系統的運行速度。因而,經過考慮,本文去除了上述兩個特征。機構名后綴特征的建立也是因為機構名對人名有一定的指稱作用,機構名后也有出現人名的現象,但在特征選擇中通過實驗發現,機構名特征的運用未能使正確率、召回率有提升,反而有了較為明顯的下降。因而,經過考慮,本文去除了機構名后綴特征。經過上述實驗,去除了機構名后綴詞典、地名后綴詞典、地名詞典等3個特征,保留了9個特征集作為最大熵統計模型的特征集。
從實驗結果看,各個保留的特征對識別結果的影響并不相同,具體表現在:有些特征的貢獻僅是單方面的,如“兼類人名詞典”雖然使召回率有所提升,但正確率卻出現了下降;各個特征對結果影響的大小也不相同,如“梵藏滿人名詞典”及“蒙古人名詞典”對正確率和召回率的影響比較明顯,而“蒙古族蒙古姓氏詞典”的影響并不十分明顯。
蒙古文人名識別遇到很多難題,主要表現在:人名是開放集合,無法窮舉,蒙古人名兼類現象較為嚴重,越普通的詞,成為人名的現象也越普遍,給人名識別帶來很大困難。蒙古文深加工語料庫規模比起中英文規模尚小,本文使用的語料庫規模僅有30萬詞,必定影響了統計模型的規則提取與自動學習。但是,本文的創新和貢獻主要體現在:首次建立了蒙古文人名識別語料庫,與內蒙古大學的語料庫一同訓練數學模型,測試自動識別的結果,有效補充了語料庫缺乏帶來的缺憾;首次建立了蒙古文普通人名知識庫及兼類人名知識庫,對人名及其他命名實體的識別有重要意義;知識庫整理為14個特征,進行了特征選擇實驗,更科學地鑒定了知識庫的有效性及針對性;在以傳統的規則為主的研究基礎上,將最大熵的數學模型成功應用于蒙古文命名實體的識別當中,是統計模型應用于蒙古文命名實體研究的較早成果。
[參考文獻]
[1]鄭家恒.智能信息處理——漢語語料庫加工技術及應用[M].北京:科學出版社,2010:41.
[2]牧仁高娃.蒙古語語料庫標注及相關對策研究[D].內蒙古:內蒙古大學,2008:41.
[3]喬永波.規則與統計相結合的中文命名實體識別[D].山東:山東大學,2007:8.
[4]曹納木.蒙古族姓氏集[M].呼和浩特:內蒙古人民出版社,2007:1-256.
[5]中國社會科學院語言文字應用研究所整理研究室編.姓氏人名用字分析統計[M].北京:語文出版社,1991:747-757.
[6]德·青格樂圖.現代蒙古語固定短語語法信息詞典詳解[M].呼和浩特:內蒙古教育出版社,2005:31-188.
[收稿日期]2014-08-28 [責任編輯]菊秋芳
[作者簡介]通拉嘎(1976-),女,內蒙古科爾沁右翼中旗人,中央民族大學博士,泉州師范學院圖書館館員,中國社科院閩南文化研究基地成員,研究方向:計算語言學、方言及情報學;劉凱(1987-),男,福建龍巖人,中科院計算所博士畢業,研究方向:機器翻譯及自然語言處理;李佳正(1988-),女,中科院計算所碩士畢業,研究方向:機器翻譯。
[基金項目]本文系國家自然科學基金重點項目“跨語言社會輿情分析基礎理論與關鍵技術”(項目編號:61331013)的系列成果之一。
[文章編號]1005-8214(2014)12-0109-04
[文獻標志碼]A
[中圖分類號]TP391.1;G250.74
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
