基于動態GMM模型的歌曲歌唱部分檢測
2016-02-13 07:03:21呂蘭蘭
現代計算機 2016年35期
呂蘭蘭
(湖南科技學院電子與信息工程學院軟件工程系,永州425100)
基于動態GMM模型的歌曲歌唱部分檢測
呂蘭蘭
(湖南科技學院電子與信息工程學院軟件工程系,永州425100)
針對人工標注歌聲/純伴奏信號存在的誤差,以及初始訓練的歌唱模型/伴奏模型與測試歌曲之間在音樂風格、樂器等方面的差異,提出建立基于對數似然比的動態GMM模型。在使用初始模型對測試歌曲的每一幀進行分類后,根據似然比選出可信度較高的連續幀數據,對初始模型進行動態更新,使得更新后的模型與測試歌曲之間的差異縮小。實驗結果表明,相對初始模型,使用動態更新后的模型對歌曲的歌唱部分進行檢測,準確率更高。
歌唱部分檢測;高斯混合模型;似然比;動態模型
0 引言
歌曲中的歌唱部分是一首歌曲的精華所在,對于歌曲的檢索和分類有很大幫助。一首歌曲通常由歌手演唱部分和純伴奏部分構成,其中歌手的演唱部分是人聲與伴奏音樂的疊加,純伴奏部分則不含人聲、純粹由伴奏樂器的聲音構成。歌曲中的歌唱部分檢測,指的是在歌曲中定位這兩種信號出現的起始時間和結束時間。通過檢測歌曲的歌唱部分,可以快速挖掘歌曲中與歌曲內容有關的信息。此外,歌曲中的歌唱部分檢測,也可以作為歌詞識別和歌手識別的前端處理。
大量研究表明,現有的歌曲歌唱部分檢測算法大多采用聲學特征參數和概率統計模型分類器相結合的處理方法[1-3]。在語音信號處理中廣泛使用的聲學特征參數很多,常用的聲學特征參數有:梅爾倒譜系數(MFCC,Mel-Frequency Cepstral Coefficients)、感知線性預測系數(PLPC,Perpetual Linear Predict Coefficients)、線性預測倒譜系數(LPCC,Linear Predict Cepstral Coefficients)、短時能量(Short-Term Energy)、過零率(Cross Zero Rate)、基音(Pitch)等。文獻[4]的研究結果表明,MFCC不僅能很好地體現說話人的語音特征,在音樂信號的各種聲學特征參數中,MFCC對音樂信號的特征表現能力也很不錯,而且是最合適的。常用的的分類器包括:隱馬爾科夫模型(HMM)、高斯混合模型(GMM)、支持向量機(SVM)、人工神經網絡(ANN)、決策樹(Decision Tree)、樸素貝葉斯分類器(Naive Bayes)等。研究表明,支持向量機的分類效果最好,但與GMM相差不大,且GMM具有較強的數據描述能力[5-7]。因此,本文嘗試采用MFCC作為聲學特征,使用GMM作為分類器來對歌曲中的歌唱部分和純伴奏部分進行區分。
由于不管采用哪種分類器,都要使用人工標注好的歌聲信號和伴奏信號作為訓練數據,以建立歌唱模型和伴奏模型。因此,人工對歌曲中的歌聲信號和伴奏信號進行標注的精確度極為關鍵,直接影響到所建立的模型的好壞以及識別的準確率。同時,在實際檢測中發現,初始訓練的歌唱模型/伴奏模型與測試歌曲之間在音樂風格、樂器等方面常常存在不小的差異,這對識別的準確率有一定影響。
針對上述問題,本文提出一種歌唱模型和伴奏模型的動態更新算法。使用人工標注好Sing和Non-singing的音頻數據建立初始模型,利用初始模型定位待測歌曲中最有可能是歌唱部分的片段,以及最有可能是伴奏部分的片段,并使用這些數據對初始模型進行動態更新,一方面消除人工標注誤差的影響,另一方面縮小訓練模型與測試歌曲的差異。
1 基于GMM的歌唱部分/伴奏部分檢測
1.1 歌唱模型/伴奏模型的建立
使用人工標注好Singing和Non-singing的歌曲作為訓練數據,對其進行分幀,每一幀提取MFCC特征向量。根據人工標注將這些幀分為歌唱和純伴奏兩類,然后用這些數據分別建立歌唱部分的GMM模型和純伴奏部分的GMM模型,記為λS和λN。
1.2 歌唱部分/伴奏部分的識別
對歌曲的歌唱部分進行檢測時,對其分幀,每一幀提取MFCC特征向量。假設共有T幀,這樣得到一個特征向量序列:{x1,x2,…,xT}。對每一幀的特征向量xt,分別計算其在歌唱部分的GMM模型λS和純伴奏部分的GMM模型λN下的對數似然率,即:logp(xt|λS)和logp(xt|λN),其中t=1,2,…,T。從而得到一組隨時間變化的對數似然比:
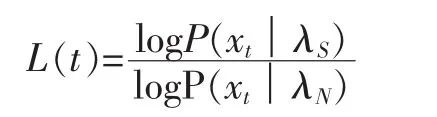
其中t=1,2,…,T。
若L(t)≥0,則將xt識別為歌唱部分,否則將xt識別為伴奏部分。設識別結果為D(t),則有:
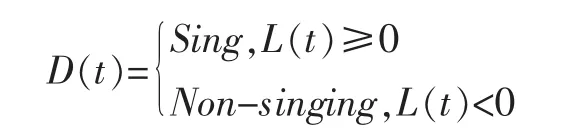
其中,Sing代表歌唱幀,Non-singing代表伴奏幀,t=1,2,…,T。
由于歌唱的發聲以及音樂的產生不是驟然停止或者開始,而是具有一定的延續性和穩定性,因此歌唱幀的附近很有可能還是歌唱幀,伴奏幀的附近很有可能還是伴奏幀。并且,通過分析實驗數據發現,絕大部分的歌曲中的歌唱部分和伴奏部分的持續時長至少在1s以上。根據歌曲信號的這一平穩特性,考慮以基于GMM的識別結果為基礎,對短暫突變的識別結果,使用中值濾波對原始的對數似然比L(t)進行平滑處理,如下所示:其中,h(t)為一個101點的中值濾波器,*為卷積符號,Lsm(t)為使用中值濾波平滑后的處理結果。再將中值濾波結果分為兩類,這樣就得到了幀識別結果Dsm(t),如下所示。
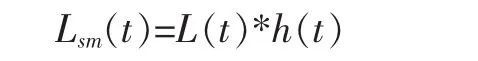
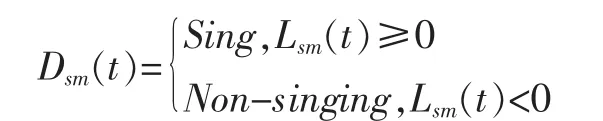
其中,Sing代表歌唱幀,Non-singing代表伴奏幀。
2 歌唱模型/伴奏模型的動態更新算法
由于人工標注歌曲中的歌聲/純伴奏信號時,人的大腦、耳朵和雙手之間存在著一定的延遲,這樣會導致在標注歌聲部分的開始區域或者純伴奏部分的開始區域時出現誤差,使得訓練數據本身存在標注錯誤,從而影響訓練所得到的模型的質量。同時,由于歌曲的風格、種類和流派眾多,所用樂器及其演奏方式、歌手的性別、嗓音及唱腔等都千差萬別,造成初始訓練的模型與某一首特定的待測試歌曲之間存在較大差異,不利于準確地檢測出其中的歌唱部分。為解決上述問題帶來的影響,提出采用一種歌唱模型/伴奏模型的動態更新算法,對初始訓練好的模型進行動態更新,以達到更高的識別準確率。歌唱模型/伴奏模型的動態更新算法如2.1和2.2所示。
2.1 基于對數似然比選擇可靠數據
利用1.2介紹的方法對歌曲信號進行處理,對每一幀特征向量xt計算其在初始訓練的歌唱部分的GMM模型λS和伴奏部分的GMM模型λN下的對數似然比Lsm(t)。使用該組隨時間變化的對數似然比數據Lsm(t)來定位歌曲中最可能是歌唱部分的歌聲片段:

其中,θ是一個動態的判決閾值,只需保證n%的Lsm(t)在此閾值之上。θ具體數值將由實驗決定,此處取20。將檢測到的所有歌聲幀融合在一起作為動態更新歌唱模型的可靠數據。同時,也可通過設置動態的判決閾值θ,保證n%的Lsm(t)在此閾值之下,將檢測到的所有伴奏幀融合在一起作為動態更新伴奏模型的可靠數據。
2.2 基于最大后驗估計動態更新模型
采用基于最大后驗估計(MAP,Maximum a Posterior)的GMM模型自適應算法[8],使用2.1得到的可靠數據對初始的歌唱模型λS和伴奏模型λN進行更新,得到更新后的歌唱模型和伴奏模型,分別記為λS'和λN'。利用1.2介紹的方法,使用更新后的歌唱模型λS'和伴奏模型λN',對待測歌曲的歌唱部分進行檢測。
3 實驗結果及分析
實驗選取了20首中文流行歌曲建立音頻數據庫,為方便處理,預先將歌曲從MP3格式轉換為WAV格式,采樣率為16kHz,量化位數為16。人工對這20首歌曲的歌唱部分和純伴奏部分進行了手工標注。測試方法為留一交叉檢驗(Leave One Out Cross Validation),即:假設測試樣本總容量為L,依次將L-1份數據用作訓練樣本,而將剩下的1份數據作為測試樣本。實驗中采用的幀長為32ms,幀移為16ms,MFCC特征維數為39維,高斯混合數為13。采用基于幀的錯誤率(ER,Error Rate)、漏檢率(MDR,Miss Detection Rate)、錯檢率(FAR,False Alarm Rate)三個指標來評價識別效果,其中漏檢是指歌曲中的歌唱部分未被檢測出來,即被錯誤地識別為伴奏部分,錯檢指的但是歌曲中的伴奏部分被錯誤地檢出,即被錯誤地識別為歌唱部分。錯誤率、漏檢率和錯檢率的計算公式如下:


表1給出了使用初始歌唱/伴奏GMM模型和動態更新后的歌唱/伴奏GMM模型的識別結果。從表1中可以看到,使用動態更新后的GMM模型可以有效地降低平均錯誤率,同時平均漏檢率和平均錯檢率也有所降低。
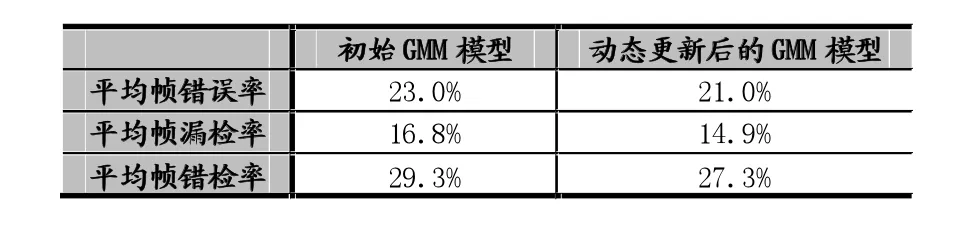
表1 初始GMM模型和動態更新后的GMM模型的識別結果
4 結語
本文采用MFCC作為聲學特征,使用GMM作為分類器,進行歌曲中歌唱部分的檢測研究。針對人工對歌曲中的歌聲信號和伴奏信號進行標注時可能存在的誤差,以及訓練模型與測試歌曲在音樂風格、樂器等方面可能存在的差異,提出基于對數似然比選擇可靠數據、動態更新訓練模型,獲得與待測歌曲在音樂風格、樂器等方面差異較小的訓練模型,同時也使人工標注中的誤差的影響降低。實驗表明,使用動態更新后的訓練模型可以有效地降低幀層次的錯誤率。與此同時,幀層次的漏檢率和錯檢率也得到了有效降低。
[1]B.Lehner,G.Widmer,R.Sonnleitner.On the Reduction of False Positives in Singing Voice Detection.In Proc.of the 2014 IEEE Int. Conf.on Acoustics,Speech,and Signal Processing,ICASSP 2014.IEEE,2014,pp.753-7534.
[2]B.Lehner,R.Sonnleitner,G.Widmer.Towards Light-Weight,Real-Time-Capable Singing Voice Detection.in Proc.of ISMIR,2013.
[3]H.Lukashevich,M.Gruhne,C.Dittmar.Effective Singing Voice Detection in Popular Music Using Arma ltering.in Proc.of DAFx-07,Bordeaux,France,2007.
[4]M.Rocamora and P.Herrera.Comparing Audio Descriptors for Singing Voice Detection in Music Audio Files.in Proc.of Brazilian Symposium on Computer Music,11th.San Pablo,Brazil,volume 26,page 27-30,2007.
[5]Ramona M,Richard B,David G.Vocal Detection in Music with Support Vector Machines[J].Proc of ICASSP,2008:1885-1888.
[6]王天江,陳剛,劉芳.一種按節拍動態分幀的歌曲有歌唱部分檢測新方法[J].小型微型計算機系統,2009,30(8):1561-1564.
[7]石自強,李海峰,孫佳音.基于SVM的流行音樂中人聲的識別[J].計算機工程與應用,2008,44(25):126-128.
[8]閔葆貽,賀光輝.基于UBM-MAP的說話人識別系統研究[EB/OL].北京:中國科技論文在線[2014-03-07].http://www.paper.edu. cn/download/downpaper/201403-204.
作者簡介:
呂蘭蘭(1980-),女,湖南永州人,講師,碩士,研究方向為語音及音頻信號處理
Singing Voice Detection in Songs Based on Dynamic GMM Models
LV Lan-lan
Proposes a dynamic GMM model based on likelihood ratio,in order to deal with the occasional errors in manual annotation of songs,and the differences between initial training models and the tested song in music style,instruments,etc.By use of initial training models,the tested song is classified frame by frame to either singing or non-singing.According to the logarithm of likelihood ratio,the high reliable frames are searched out.The initial training models then are dynamically updated based such frames,which narrows the gap between updated models and the tested song.The experimental results show that relative to the initial training model,using dynamic updated model to detect the singing voice in a song can get higher accuracy.
Singing Voice Detection;Gaussian Mixture Models;Likelihood Ratio;Dynamic Model
1007-1423(2016)35-0029-04
10.3969/j.issn.1007-1423.2016.35.006
2016-10-20
2016-12-01
永州市科技計劃指導性項目(2011)流行歌曲歌詞實時智能提取技術研究
(Department of Software Engineering,College of Electronic and Information Engineering,Hunan University of Science and Engineering,Yongzhou 425100)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:25:42
光學精密工程(2016年6期)2016-11-07 09:07:19
