在多態陣列處理器上實現統一渲染架構
2016-02-23 06:28:56韓俊剛
計算機技術與發展 2016年8期
郭 丹,韓俊剛
(西安郵電大學 計算機學院,陜西 西安 710121)
在多態陣列處理器上實現統一渲染架構
郭 丹,韓俊剛
(西安郵電大學 計算機學院,陜西 西安 710121)
多態陣列處理器是一種將成千上萬的單處理核集成于一塊芯片的新型并行處理器,其具有多種并行計算模式。針對傳統的分離式圖形渲染管線產生負載不均衡的問題,以業界提出的統一渲染思想為指導,充分利用多態陣列處理器的多種并行計算模式,設計并實現了一種基于多態陣列處理器的統一渲染架構。該設計將多態陣列處理器的單處理核作為統一渲染架構中的流處理器,同時設計緩沖區對象、緩存機制、分配器、重定序等相關機制配合流處理器工作,以此達到對圖形頂點數據和像素數據統一渲染的目的。最后在實現的統一渲染架構中對基本的3D模型數據進行了仿真。結果表明,設計的統一渲染架構很好地實現了頂點著色和像素著色的負載平衡,并且在數據處理方面實現了較高的數據并行性。
統一渲染;多態陣列處理器;著色器;分配器
0 引 言
進入可編程時代的GPU可以對頂點處理單元和像素處理單元兩個部分進行編程。在頂點處理單元和像素處理單元上運行的程序分別稱為頂點著色器(vertex shader)和像素著色器(pixel shader)[1]。微軟DirectX10發布之前,GPU采用將頂點處理單元和像素處理單元分開的分離式渲染架構[2],當圖形流水線采用分離式渲染架構時,會產生負載不均衡的現象[3]。在DirectX10時代圖形界引入了統一渲染架構[4],即在統一渲染架構中,不再有頂點處理單元和像素處理單元之分,取而代之的是支持通用計算[5]的流處理器陣列。流處理器不區分所處理的數據,對于頂點和像素的處理也只是當作普通的數據處理,因此,統一渲染架構下的GPU具備了進行通用計算的基礎。
文中研究了統一渲染架構在多態同構陣列處理器(Polymorphic Array Architecture for Graphics,PAAG)[6]上的實現方法。
1 多態同構陣列處理器
PAAG由若干個基本處理簇和特定功能單元組成,16個簡單處理器單元(Processing Element,PE)按4×4的二維陣列組成一個簇。每個簇中包含一個簇控制器、一個全局共享存儲、四個行控制器和四個列控制器。簇控制器可以向列控制器和行控制器發送指令或者信號,然后這些指令或信號被行控制器或列控制器通過路由器發送至PE。相反的路程可以是PE的執行狀態向簇控制器的反饋。最小的處理器單元PE包含一個算術邏輯單元、一個路由器、一個PE控制器、一個本地數據存儲器、一個本地指令存儲器和四個與相鄰處理器共享的共享存儲器。
PE可單獨執行程序,相互之間互不影響,也可以是相鄰的幾個PE或者一組指定的PE協作執行一段程序。同屬于一個簇的PE都可以從全局共享存儲里存取數據。相鄰PE之間通過本地共享存儲器進行數據通信,不相鄰的PE可以通過路由器進行數據通信。
PAAG中的行(列)控制器可同時向屬于同一行(列)的PE發送同一條指令來實現單指令多數據操作,而多指令多數據操作在PAAG中則體現為行(列)控制器向所屬行(列)的PE發送不同的指令。在PE內部,同一時刻可包含八個線程,并且這八個線程或獨立或協作工作。通過結合PAAG的數據級并行、操作級并行以及線程級并行等多種計算模式來充分挖掘程序中的并行性[7]。
2 統一渲染架構下的圖形流水線
結合開放圖形庫(Open Graphics Library,OpenGL)圖形流水線[8]和統一渲染架構思想,同時加入OpenGL緩沖區對象[9]機制,文中提出了統一渲染架構下的圖形渲染流水線,見圖1。
數據緩沖區(Buffer Object,BO)作為GPU頂點數據的來源,PAAG的一個簇用作流處理器陣列,每一個PE對應一個流處理器,同時為實現統一渲染的目標,在這個簇的內部設計了頂點緩存(Vertex Cache,VC)、像素緩存(Pixel Cache,PC)和分配器(Dispatcher)。經過PE處理后的數據寫入重定序模塊(Reorder Buffer,RB),由RB根據數據類別決定數據的去向。
3 統一渲染架構在PAAG上的具體實現
3.1 Buffer Object的設計
BO是一個獨立于CPU和GPU的存儲區域[9],由于它向GPU傳輸數據的方式為直接內存訪問(Direct Memory Access,DMA),所以它的出現代替了CPU向GPU傳輸數據這種費時的過程。文中對來自CPU端應用程序的頂點信息進行提取和整合,然后將其存儲在BO中,每一個頂點數據包含有頂點的四類屬性共16個標量(坐標、顏色、紋理、法向量)。對每個需要生成的圖形,其頂點數據存入BO,CPU端只保留其頂點索引數組。
3.2 Vertex Cache和Pixel Cache的設計
在PAAG簇的全局共享存儲里設置VC和PC,分別存儲來自BO的頂點數據和來自光柵化模塊的像素數據。這樣設置的原因有兩個:
(1)現代圖形處理器中通常都設有VC[10],以減輕頂點讀取時的帶寬要求。
(2)PC作為PE像素數據的來源,不僅可以存儲光柵化模塊產生的大量像素數據,而且和VC一起配合后面所提到的Dispatcher對PE進行數據的分發。在分發的過程中Dispatcher對PC和VC一視同仁,使得每個PE不僅有可能得到頂點數據,也可能得到像素數據,以此達到統一渲染的目的。
受硬件影響,VC的容量不可能無限大,故文中在進行頂點傳輸時進行了優化,以此來減少頂點復用[11]導致的重復傳輸浪費。如圖2所示,經過傳輸,在VC中的頂點數據順序不同于在BO中,重新排列的頂點數據意味著VC的命中率提高,進而提高了渲染速度。

圖2 Buffer Object到Vertex Cache的數據流通示意圖
頂點傳輸優化算法的偽代碼如下:
char Buffer[MAX];/*緩沖區*/
char Vertex_cache[size];/*頂點緩存*/
/*int Indices[len];頂點索引*/
/*int Flag[num];標記此頂點是否已經存在于緩存中*/
void Read_from_buffer(int Indices[], int Flag[])
{
int j=0;
int current_indices=0;
for(int i=0;i { current_indices=Indices[i]; /*如果此頂點已經存在于緩存中,那么循環繼續*/ if(Flag[current_indices]!=0) continue; /*如果此頂點不存在于緩存中,那么就將此頂點數據從緩沖區復制到緩存中*/ else Copy_data(Buffer[current_indices], Cache[j++]); Flag[current_indices]+=1; } } 3.3 分配器的設計 3.3.1 地址存儲 Dispatcher包含四個存儲地址的隊列,分別存儲當前PC和VC里所有數據的地址以及一個標記此數據屬于哪個Cache的標志位(下面統稱為地址),存儲序列如圖3所示(圖中Address Queue中的p0表示地址而不是數據)。若PC為空,PE會優先存儲頂點地址;若PC不為空,PE會優先存儲像素地址,在存儲完像素地址后轉而存儲頂點地址。 圖3 地址存儲序列示意圖 3.3.2 分發地址 存儲地址完成后,Dispatcher要分發地址到各組PE(文中對PE按列分組)。四個地址隊列分別對應四組PE。由于四個隊列發放過程是相互獨立的,因此提高了數據并行性。 3.3.3 收集信號 分發地址之前,Dispatcher通過檢測列控制器中的信號signal來判斷本組PE是否可以進行分發。當signal為0時,本組PE可以分發;當signal大于0時,本組PE不可以分發。每分發一次地址,Dispatcher將signal的值加1,所以當本組PE全部獲得地址,對應的列控制器中的signal應變為4。 3.4 流處理器陣列中PE的設計 PE作為流處理器的原型,其內部程序可由程序員寫入。依據分配器分發的地址,PE從Cache中獲得數據并進行處理。PE不僅可以進行通用計算,而且PE的內部會根據附著在地址中的標志位識別出此數據來自哪一個Cache,所以不同的數據在PE中會得到相應的處理,處理后的結果連同標志位寫入RB,同時將所在組的signal減1。所以,當每組PE把結果都寫入到RB后,對應組的signal應該變為0,這也意味著本組PE可以進行下一次的地址分發了。 3.5 重定序模塊設計 RB包含一塊存儲區域,放置在PAAG簇全局共享存儲中,可以存放16個頂點(編號0~15,對應16個PE),同時包含狀態變量State來指示此區域是否已經寫滿數據。因為PE產生結果的順序有先后之分和類別之分,所以此區域可以用來對PE產生的結果進行同步和分類[12]。當通過State判斷出RB滿時就會觸發對該存儲區域的刷新,如果是頂點數據,進入下一級圖元裝配模塊(Primitive Assemble),如果是像素數據,寫入幀緩沖區(Framebuffer),刷新完畢后重置State變量。考慮到PE內部進行通用計算所用的時鐘數不會相差太多,故這里等候RB存滿的時間不會對整體性能造成很大影響。 3.6 統一渲染整體架構 統一渲染的整體架構圖如圖4所示。 圖4 統一渲染架構在PAAG上實現的整體架構圖 (1)針對基本3D模型的頂點數據,計算了VC的平均緩存失效率(Average Cache Miss Ratio,ACMR)[13-14],見表1。ACMR越低,表明Cache的命中率越高。實驗所設置的VC的大小為可以存放16個頂點。 (2)針對基本3D模型,通過統計程序在運行時頂點處理所需時鐘數(Clock_V)、像素處理所需時鐘數(Clock_P)以及整體渲染所需時鐘數(Clock_T)進行性能分析。用Clock_O表示其他模塊所需要的時鐘數,于是有: Clock_V+Clock_P+Clock_O=Clock_T 當等式成立,表明PE實現滿載,負載達到基本平衡。在這里忽略了Clock_O,所以只要Clock_V和Clock_P之和接近于Clock_T即可,見表2。 表1 經過頂點傳輸算法優化后VC的ACMR值 表2 頂點處理和像素處理時鐘個數統計表 結合PAAG豐富靈活的并行計算模式和統一渲染思想,文中設計了一種對頂點和像素能統一高效著色的架構。實驗數據說明了該架構對渲染性能有一定提升,并且能解決GPU負載不均衡的問題。如何在該架構上進行優化和擴展,將在未來工作中繼續研究。 [1] 田緒紅,陳茂資,田金梅.DirectX發展及相關GPU通用計算技術綜述[J].計算機工程與設計,2009,30(23):5432-5436. [2] 韓俊剛,劉有耀,張 曉.圖形處理器的歷史現狀和發展趨勢[J].西安郵電學院學報,2011,16(3):61-64. [3] 林一松,唐玉華,唐 滔.GPGPU技術研究與發展[J].計算機工程與科學,2011,33(10):85-92. [4] VISA.大一統的時代——統一渲染架構引領未來[J].電腦迷,2007(11):32-33. [5] 戴長江,張尤賽.基于圖形處理器的通用計算技術的研究[J].現代電子技術,2013,36(4):157-161. [6] 黃虎才.多態陣列處理器的并行計算研究[D].西安:西安郵電大學,2014. [7] 楊 柳,劉鐵英.GPU架構下的并行計算[J].吉林大學學報:信息科學版,2012,30(6):629-632. [8] 王蘭美,趙繼成,秦華東.OpenGL及其在VC++下的開發應用[J].武漢大學學報:工學版,2006,39(4):62-65. [9] Kilgard M J.Modern OpenGL usage:using vertex buffer objects well[C]//Proc of ACM SIGGRAPH Asia Courses.[s.l.]:[s.n.],2008. [10] Yu C H,Chung K,Kim D,et al.An energy-efficient mobile vertex processor with multithread expanded VLIW architecture and vertex caches[J].IEEE Journal of Solid-State Circuits,2007,42(10):2257-2269. [11] Barczak J D,Nehab D F,Sander P V.Fast triangle reordering for vertex locality and reduced overdraw:US,US8379019B2[P].2013. [12] 韓俊剛,姚 靜,李 濤,等.多態并行機上的3D圖形渲染[J].西安郵電大學學報,2015,20(2):1-6. [13] 陳思遠,史廣順,王慶人.通過三角形Strip衍生實現三維模型數據的渲染優化[J].計算機輔助設計與圖形學學報,2009,21(8):1155-1163. [14] Lin G,Yu P Y.An improved vertex caching scheme for 3D mesh rendering[J].IEEE Transactions on Visualization & Computer Graphics,2006,12(4):640-648. Implementation of an Unified Rendering Architecture on Polymorphism Array Processor GUO Dan,HAN Jun-gang (School of Computer and Technology,Xi’an University of Posts and Telecommunications,Xi’an 710121,China) Polymorphism array processor is a kind of new parallel processor which integrates hundreds or thousands of single nuclear on one chip.It has many parallel computing model.For the problem of uneven load produced by the traditional separate graphics rendering pipeline,guided by the ideology of unified rendering by industry,making full use of varieties of parallel computing model of polymorphism array processor,an unified rendering architecture based on the polymorphism array processor is designed and implemented.It takes single nuclear of polymorphism array processor as a stream processor of unified rendering architecture,and designs the buffer object,cache mechanisms,dispatcher,reorder mechanism and so on to cooperate the works of stream processor,achieving the purpose of rendering the vertex data and pixel data in unified manner.Finally on this unified rendering architecture,the data of the basic 3D model is tested.The experimental results show that the unified rendering architecture designed has realized the load balancing between vertex shader and pixel shader,and achieved the higher parallelism in the aspect of data processing . unified rendering;polymorphism array processor;shaders;dispatcher 2015-11-06 2016-03-04 時間:2016-06-22 國家自然科學基金重大項目(61136002);西安郵電大學研究生創新基金(CXL2014-28) 郭 丹(1991-),女,碩士研究生,研究方向為并行計算與圖形學;韓俊剛,教授,研究方向為軟件和硬件的形式化驗證、圖形處理器和新型計算機體系結構研究。 http://www.cnki.net/kcms/detail/61.1450.TP.20160622.0845.050.html TP302 A 1673-629X(2016)08-0039-04 10.3969/j.issn.1673-629X.2016.08.008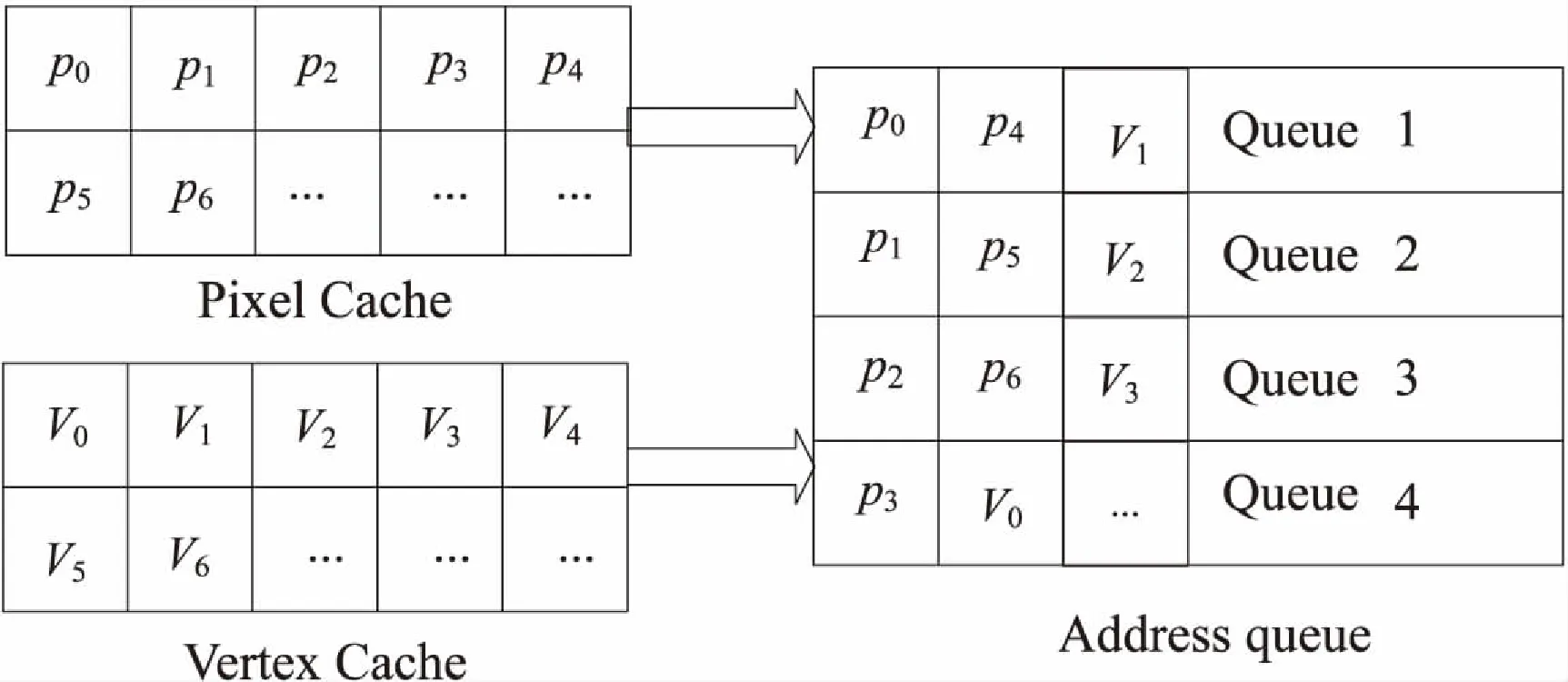
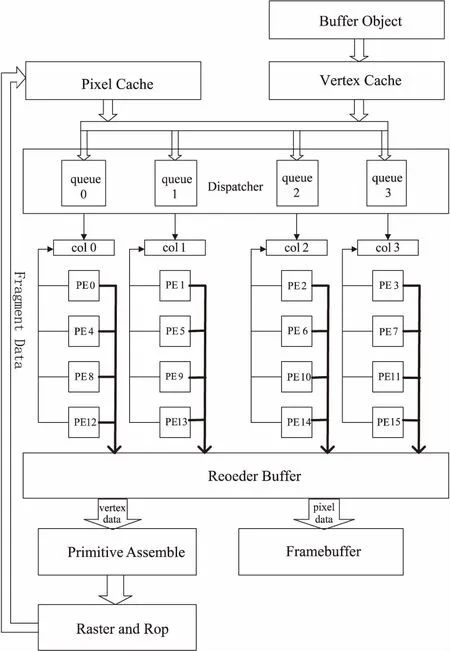
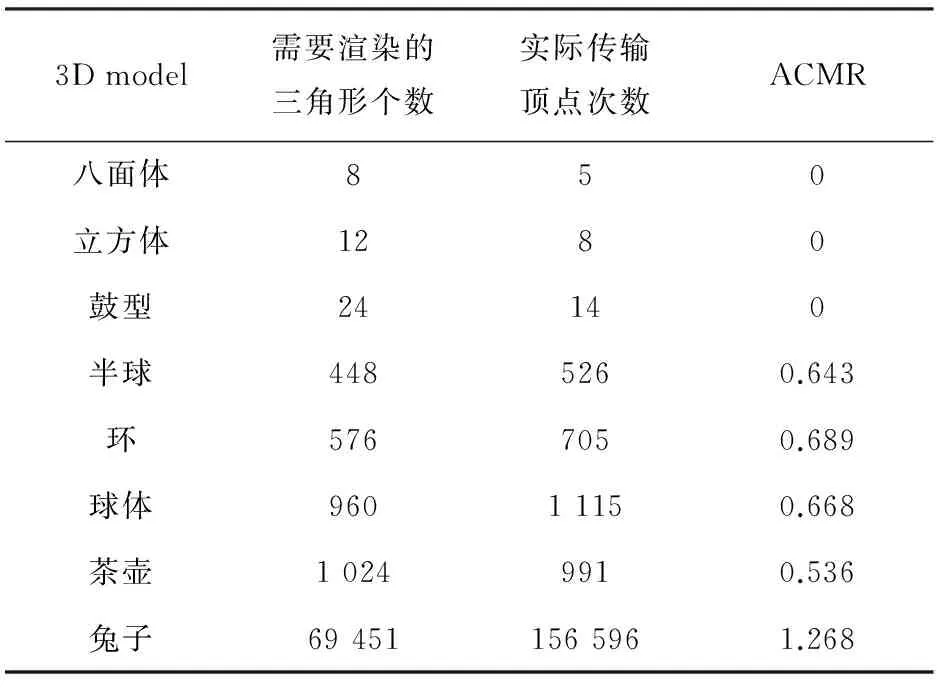
4 實驗結果驗證及分析

5 結束語
