加權社會網絡中的個性化隱私保護算法
2016-02-23 06:28:58陳春玲
計算機技術與發展 2016年8期
陳春玲,熊 晶,陳 琳,余 瀚
(南京郵電大學 計算機學院 軟件學院,江蘇 南京 210003)
加權社會網絡中的個性化隱私保護算法
陳春玲,熊 晶,陳 琳,余 瀚
(南京郵電大學 計算機學院 軟件學院,江蘇 南京 210003)
針對加權社會網絡中存在一部分用戶不需要隱私保護或者需要某種特殊隱私保護的現象,提出了一種基于加權社會網絡數據發布的個性化隱私保護方法。將社會網絡中的隱私保護分為3個等級:不需保護L=0、防止權重包攻擊L=1和防止敏感屬性泄漏L=2。對于L≠0的節點集,通過k-度分組和修改權重包信息對節點進行匿名,使得每個分組滿足權重包k-匿名;在分組過程中,對于存在L=2的分組要求其敏感屬性滿足l-diversity。理論分析和實驗表明:攻擊者不能以大于1/k的概率識別出某節點,且不能以大于1/l的概率推斷出節點的敏感信息。該方法能夠滿足社會網絡中各用戶對隱私保護的要求,同時降低了社會網絡圖的信息損失。
加權社會網絡;隱私保護;個性化;權重包;敏感屬性
1 概 述
前Sun Microsystems的CEO,Scott McNealy曾說過“反正你的隱私為零,那就克服它吧”。當時這句話震驚了很多人。然而,十幾年過去了,事實證明他的說法是正確的。社會網絡中的用戶不斷增多,使得社會網絡在現實生活中已非常普遍,并深刻地影響著人們的日常生活。國外的LinkedIn、Facebook、Twitter,國內的新浪微博、QQ、微信等社交平臺都擁有了龐大的客戶群。用戶通過社會網絡與他人分享個人信息,并接觸到了更多的人,而用戶之間的這種互動與交流必然會產生大量社會網絡數據。分析數據有助于認識網絡的拓撲結構和演化過程、用戶的類別劃分和行為傾向等,但是也會造成用戶敏感信息泄漏,可能導致個人隱私受到威脅。近些年,對于社會網絡的隱私保護研究已經引起了廣泛的關注。
Samarati等[1]提出k-匿名隱私保護模型,但僅針對關系數據,并不適用于現在的社會網絡;Terzi等[2]將節點的度作為攻擊者的背景知識,提出了k-度匿名方法來防止節點再識別攻擊;Zhou等[3]提出的匿名化方法使得對任意節點的鄰域子圖,至少有k-1個節點的鄰域子圖與其同構;Jiao等[4]提出了個性化的社會網絡數據保護方法,允許用戶根據自身要求設置隱私保護程度,同時為了保護節點的敏感屬性(例如疾病、收入)不被泄漏,引入了l-diversity思想[5-7],避免同質性攻擊。上述研究成果都是基于不帶權值的社會網絡,在現實生活中,對邊的權值分析也是具有重要意義的,它可以表示社會網絡中各節點之間的連接關系,如朋友網絡(朋友圈)中的邊權值表示聯系次數,商業交易網絡中的邊權值表示交易次數等。Maria等[8]提出了基于加權社會網絡的k-匿名保護方法,使得攻擊者不能以大于1/k的概率識別出目標節點;Tsai等[9-10]通過修改權值方法,使得任意兩節點之間的最短路徑條數滿足k1≤k≤k2,避免任意兩節點之間的最短路徑泄漏問題;Chen等[11]提出了k-histogram-inverse-l-diversity匿名方法,通過修改節點的權重包信息,使得同一等價類中節點的權重包信息相同;陳可等[12]提出了k-可能路徑匿名模型來保護加權社會網絡中的最短路徑信息泄漏問題;蘭麗輝等[13-14]采用向量來描述加權社會網絡,通過隨機分割和聚類分割兩種方式將加權社會網絡表示為若干個子圖,用向量表示每個子圖,將所有子圖的向量構成的集合作為加權社會網絡的發布模型,但目前還不能很好地應用于社會網絡中。
現實生活中存在一種現象:只有很少一部分人需要較高級別的隱私保護;對于度相對較大的節點集,只有其中很少一部分節點需要進行較高級別的隱私保護[4]。例如,將生活中的公眾人物抽象為一個節點,該節點的鄰居節點會比普通節點多,聚類系數更大,但是相對來說,他們的隱私保護要求更低。在加權社會網絡的隱私保護研究中,每個人對隱私保護的要求不盡相同,而目前的研究并沒有考慮到用戶的這一需求,而是將所有用戶節點都進行同一隱私保護,導致對某些節點的隱私保護過度,同時增加了隱私保護的代價,降低了社會網絡信息的有效性。因此,文中提出一種基于加權社會網絡數據發布的個性化隱私保護算法。
2 相關概念
2.1 加權社會網絡
為了形象地描述社會網絡結構,文中將其抽象成加權圖模型G=(V,E,W,S,L)。其中,V為節點集,表示社會網絡中的用戶;E為邊集,表示社會網絡中的節點關系;W為邊權值集,表示節點關系的緊密程度;S為敏感標簽集,表示社會網絡中的用戶敏感屬性;L為隱私級別集,表示社會網絡中的用戶隱私要求。
圖1為某公司員工交流中心的模型,邊權值表示兩節點一周內聯系的次數,如果兩節點沒有連接,則表示他們本周沒有聯系過。節點的上半部分標識表示員工的薪資,屬于敏感屬性,下半部分標識表示隱私級別,可由節點自身進行設置。例如節點a和b本周聯系了2次,a和d在本周沒有聯系過,且a的薪資為7.5k,隱私級別為1。

圖1 某公司員工交流中心網絡圖
2.2 權重包匿名
權重包:節點的權重包表示與該節點關聯的邊的權值序列,文中將此序列按照逆序排列。圖1中a的權重包為<5,2>,b的權重包為<7,6,5,4,2>。
權重包k-匿名:假設攻擊者已經掌握了某個節點的權重包信息,很容易識別出目標節點。為了避免節點受到此類攻擊,文中采用了權重包k-匿名的思想。通過修改權重包信息,使得每個分組中節點的權重包均一致,這樣攻擊者就不能以大于1/k的概率識別出目標節點[11]。
2.3 敏感屬性匿名
在對節點進行分組時,可能會出現某個分組中的敏感屬性值都一樣的情形。而對于L=2的節點要求進行敏感屬性匿名,使得攻擊者不能獲取敏感屬性。為了滿足用戶的隱私保護要求,文中采用l-diversity思想[11],使得每個分組中的敏感屬性值不同的節點數不小于l,因此攻擊者獲取目標節點的敏感屬性值的概率不會大于1/l。
2.4 隱私級別
用戶根據自身需求設置相應的隱私保護級別,文中將用戶隱私級別L分三個等級:
(1)L=0,表示用戶對隱私保護沒有要求;
(2)L=1,表示用戶希望攻擊者不能通過其權重包識別出自己;
(3)L=2,表示用戶希望攻擊者不能通過其權重包識別出自己,且不能識別出自己的敏感屬性。
2.5 信息損失度loss
社會網絡的信息損失由三部分組成:邊的添加與刪除、節點的添加與刪除以及權值的修改。式(1)表示信息損失度loss的計算方法。
(1)
其中,α+β+γ=1;|Δedge|為添加與刪除的邊總數;|Δnode|為添加與刪除的節點總數;|Δweight|為權值修改的邊總數。
3 加權網絡的個性化隱私保護算法
3.1 分組算法
圖1表示一個原始的社會網絡圖G,現在需要對G進行隱私保護,假設k=3,l=2。匿名算法如下:
(1)將節點(隱私級別L>0)的度按逆序排列,節點v記錄為(v,v.degree,S,L),得到度序列:
P={(b,5,10k,1),(j,5,10k,2),(f,4,6k,1),(h,4,3k,1),(l,3,9k,2),(a,2,7.5k,1),(e,2,3k,1),(c,1,7.5k,1),(d,1,6k,1),(n,1,6k,1)}
(2)將節點分組,選取前k個節點為當前組,如果在該組中有L=2的節點,且不滿足l-diversity,則將下一節點加入到當前組中,直到滿足l-diversity,得到分組C1=(b,j,f)。

(4)重復步驟3,直到待分組的節點數小于等于k,得到分組C3=(e,c,d),C4=(n)。
(5)分組結束后,判斷最后一個分組是否滿足分組要求。如果不滿足,則與前一分組進行合并,將C3與C4合并,得到C3=(e,c,d,n)。
故圖1的分組為C1C2C3。
3.2 圖匿名算法
對節點進行分組后,需要對圖進行匿名,使得攻擊者不能識別出目標節點。為了防止攻擊者通過權重包識別出目標節點,要求每個分組滿足權重包k-匿名特性。
(1)分組后,每個分組首先要求節點度相同,這樣才可以達到權重包相同。故對于Δd≠0的節點需要進行k-度匿名,使得每一組的節點度都相同。對分組中的各節點進行k-度匿名會出現兩種情況:
①對于Δd>0的節點集N1,優先選擇在N1中的兩個節點之間添加噪聲邊(不存在邊關聯),權值為0。如果|N1|=1或者N1節點集中的任意兩節點都存在邊,則添加噪聲節點,此時噪聲節點的敏感屬性值與該節點相同,隱私級別L=0,噪聲邊權重為0。
②對于Δd<0的節點集N2,優先選擇刪除N2中的兩個節點之間的關聯邊。如果依然存在Δd<0的節點,則刪除其與隱私級別L=0的節點之間的關聯邊。如果不存在這樣的邊,則刪除其中一條邊,并將該邊關聯的另一節點連接到噪聲節點上,權值不變。
(2)權重包的匿名:對于每個分組,根據各邊權重出現的頻率,選取前n個值作為該分組的權重包標準,n=avg(Ci)。修改每個節點的權重包,使得分組中的各節點權重包一致,盡量不改變原來的權值。C1的權重包為<6,5,4,3,2>,C2的權重包為<5,4,3,2>,C3的權重包為<5>。由于每條邊關聯了兩個節點,導致修改某個邊的權值后,在匿名其關聯的另外一個節點權重包時,需要再次修改邊的權值。為了解決這個問題,采取泛化的方法,保存多次修改后的邊權值。例如,匿名節點b的權重時,將邊eab的權值改為2,而在匿名節點a的權值時,需要將eab的權值改為3,故將eab的權值修改為<2,3>,即eab的權值可能為2,也可能為3。
圖2為G的發布圖G*。粗實線表示修改了權值的邊或添加的噪聲邊,虛線為匿名過程中已刪除的邊,細實線表示原始邊,節點o為添加的噪聲節點。
3.3 算法分析
假設攻擊者掌握了目標節點的權重包信息,在發布的社會網絡圖中,存在兩種情況:第一,在權重包匿名過程中,權重包的信息被修改過,使得在發布的社會網絡圖中不存在這樣的權重包,這樣攻擊者就識別不出目標節點,例如圖2中的節點b;第二,在權重包匿名過程中,要求同一個分組中每個節點的權重包一致,這樣攻擊者不能以大于1/k的概率識別出目標節點。在分組過程中,如果存在某個節點的隱私級別L=2,則要求該組中敏感屬性值不同的節點個數大于等于l,因此,攻擊者也不能以大于1/l的概率推測出目標節點的敏感屬性值。綜上所述,該算法是有效的。
由于在生成節點分組的過程中需要遍歷每個節點,故時間復雜度為O(n)。分組結束后,對于L≠0的節點,需要進行k-度匿名。在對Δd≠0的節點集匿名過程中,需要刪除和增加邊,而找到最優解的策略則需要遍歷該節點集,因此進行節點k-度匿名的時間復雜度為O(n2)。例如現在需要使Δd>0的節點集滿足k-度匿名,則需要遍歷Δd>0節點集,判斷是否存在這樣的兩個節點,不存在邊的連接。在對權重包的匿名過程中,需要將節點的權重包修改為所在分組的標準權重包,而選擇權重包的標準需要的時間復雜度為O(n)。因此,總的時間復雜度為O(n2)。
4 實 驗
4.1 實驗環境
實驗在Windows 7操作系統上進行,CPU2.0 GHz,內存2 GB,編程工具使用Visual C++ 6.0。實驗數據集來自微信(http://weixin.qq.com/),包含500個節點的網絡圖,1 482條邊,節點平均度為5.928,各節點的隱私保護級別(0~2)由程序隨機產生,各節點的敏感屬性值由程序隨機產生。
4.2 實驗結果分析
算法考慮了現實情況,避免對不需要進行隱私保護的節點進行匿名,在滿足用戶的隱私要求下,減小了開銷,降低了數據的損失。分組是關鍵,在進行分組時考慮節點滿足k-匿名的同時,判斷當前分組是否存在要求敏感屬性值滿足l-多樣性的節點。k值越大,用戶的隱私保護程度就越高,造成的信息損失也會越大,執行時間越長;l值越大,攻擊者獲取目標節點的敏感屬性值概率越小;社會網絡中節點的隱私級別分布比例,也會對社會網絡的信息損失和執行時間產生重要影響。通過修改參數k和l,以及社會網絡的隱私級別分布,從時間和信息損失兩個方面對實驗結果進行分析。
圖3和圖4分別表示了隱私級別分布比例,以及k值對算法的執行時間和信息損失度產生的影響,l=3,X∶Y∶Z表示隱私級別為L=0、L=1和L=2的節點分布比例。
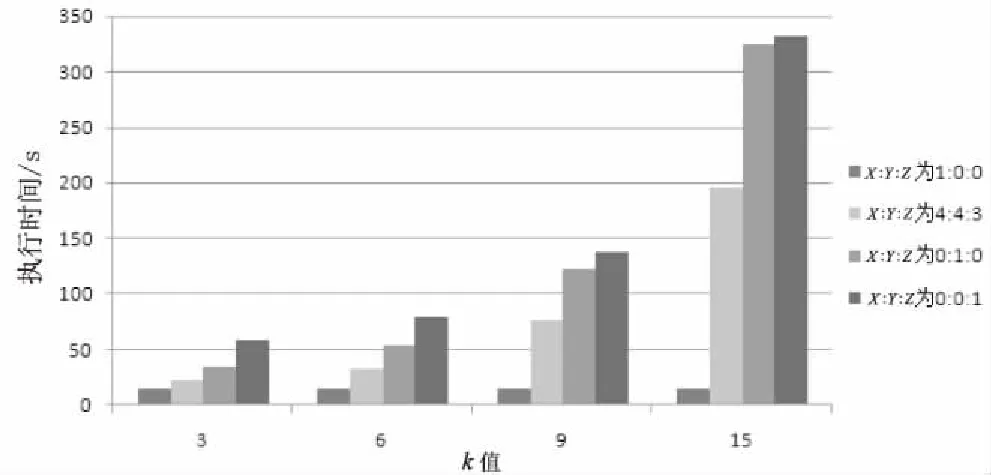
圖3 執行時間比較

圖4 信息損失度比較
當分布比例為1∶0∶0時,所有的節點均不要求進行隱私保護,因此k值的改變對執行時間和信息損失沒有影響,且信息損失度為0。隨著k值的增大,當分布比例為4∶3∶3,0∶1∶0以及0∶0∶1時,執行時間和信息損失不斷增大。當k遠大于l時,分布比例為0∶1∶0和0∶0∶1的執行時間和信息損失趨于相等。一般k值越大,分布比例為4∶4∶3的優勢越能得到體現。
圖5表示的是算法執行時間隨l值的變化規律,其中k=6,隱私級別分布比例為4∶3∶3。隨著l值的增大,執行時間不斷增長,且增長比率也隨之增大。當l遠小于k時,l值對執行時間的影響不明顯;當l接近k時,l對執行時間的影響則比較明顯。
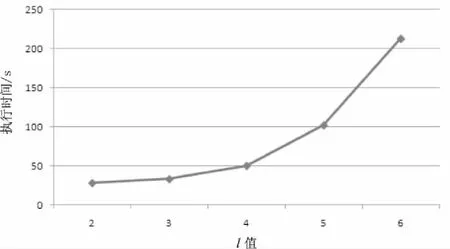
圖5 執行時間
5 結束語
對于加權社會網絡的隱私保護方法還處在不斷研究中。文中提出了一種基于加權社會網絡的個性化隱私保護方法,先除去不需要進行保護的節點,再將社會網絡按照節點度分組,要求每個分組中的節點滿足k-度匿名;對于存在L=2的節點所在分組,要求此分組滿足l-多樣性;分組結束后,對每個分組根據各邊權重出現的頻率,確定該分組的權重包標準;通過修改邊的權值實現節點的權重包k-匿名,而對于需要重復修改權值的邊,通過泛化方法保留每次修改后的權值。實驗結果表明,算法在滿足用戶的隱私保護要求的前提下,降低了對社會網絡結構信息的破壞。但在處理敏感屬性滿足l-多樣性的過程中只考慮單一敏感屬性,并且對引入的噪聲節點未進行匿名處理,以后還需針對上述問題不斷完善。
[1]SamaratiP,SweeneyL.Generalizingdatatoprovideanonymitywhendisclosinginformation[C]//ProceedingsoftheseventeenthACMSIGACT-SIGMOD-SIGARTsymposiumonprinciplesofdatabasesystems.[s.l.]:ACM,1998.
[2]LiuK,TerziE.Towardsidentityanonymizationongraphs[C]//ProceedingsofACMSIGMODinternationalconferenceonmanagementofdata.Vancouver:ACM,2008:93-106.
[3]ZhouB,PeiJ.Preservingprivacyinsocialnetworksagainstneighborhoodattacks[C]//ProcofIEEEinternationalconferenceondataengineering.[s.l.]:IEEEComputerSociety,2008:506-515.
[4]JiaoJ,LiuP,LiX.Apersonalizedprivacypreservingmethodforpublishingsocialnetworkdata[M]//Theoryandapplicationsofmodelsofcomputation.[s.l.]:SpringerInternationalPublishing,2014:141-157.
[5]ZhouB,PeiJ.Thek-anonymityandl-diversityapproachesforprivacypreservationinsocialnetworksagainstneighborhoodattacks[J].Knowledge&InformationSystems,2011,28(1):47-77.
[6]TripathyBK,SishodiaMS,JainS,etal.Privacyandanonymizationinsocialnetworks[M]//Socialnetworking.[s.l.]:SpringerInternationalPublishing,2014.
[7]SongY,KarrasP,XiaoQ,etal.Sensitivelabelprivacyprotectiononsocialnetworkdata[M]//Scientificandstatisticaldatabasemanagement.Berlin:Springer,2012:562-571.
[8]SkarkalaME,MaragoudakisM,GritzalisS,etal.Privacypreservationbyk-anonymizationofweightedsocialnetworks[C]//Proceedingsofthe2012internationalconferenceonadvancesinsocialnetworksanalysisandmining.[s.l.]:IEEEComputerSociety,2012:423-428.
[9]TsaiYC,WangSL,HongTP,etal.[K1,K2]-anonymizationofshortestpaths[C]//Procofinternationalconferenceonadvancesinmobilecomputing&multimedia.[s.l.]:ACM,2014:317-321.
[10]TsaiYC,WangSL,HongTP,etal.Extending[K1,K2]anonymizationofshortestpathsforsocialnetworks[M]//Multidisciplinarysocialnetworksresearch.Berlin:Springer,2015:187-199.
[11]ChenKe,ZhangHongyi,WangBin,etal.Protectingsensitivelabelsinweightedsocialnetworks[C]//Procofwebinformationsystemandapplicationconference.[s.l.]:IEEE,2013:221-226.
[12] 陳 可,劉向宇,王 斌,等.防止路徑攻擊的加權社會網絡匿名化技術[J].計算機科學與探索,2013,7(11):961-972.
[13] 蘭麗輝,鞠時光.基于向量相似的權重社會網絡隱私保護[J].電子學報,2015,43(8):1568-1574.
[14] 蘭麗輝,鞠時光.基于差分隱私的權重社會網絡隱私保護[J].通信學報,2015,36(9):145-159.
Personalized Privacy Preservation Algorithm in Weighted Social Networks
CHEN Chun-ling,XIONG Jing,CHEN Lin,YU Han
(School of Computer Science & Technology,School of Software,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
There is a phenomenon that some users do not need privacy protections or they need special privacy protections in social networks,so a personalized privacy protection method to meet these requirements is proposed based on weighted social network.The privacy protection is divided into three levels:without protection (L=0),preventingtheweightbagsattack(L=1),andpreventingthesensitiveattributesdisclosure(L=2).FornodeswithL≠0,k-degreegroupingandweightbagmodifyingisusedtotheanonymousnodes,whichmakeseachgroupmeetsthekanonymityofweightbag.Intheprocessofgrouping,thegroupwithL=2hastoensurel-diversityforsensitiveattributes.Theoreticalanalysisandexperimentsshowthatattackerscan’tidentifyanodewiththeprobabilityover1/kandinfernode’ssensitiveattributewiththeprobabilityover1/l.Themethodsatisfiestheuser’srequirementsinweightedsocialnetwork,andtheinformationlossisreduced.
weighted social network;privacy preservation;personalization;weight bag;sensitive attributes
2015-11-18
2016-03-03
時間:2016-08-01
國家自然科學基金資助項目(11501302)
陳春玲(1961-),男,教授,碩士,CCF會員,從事軟件技術及其在通信中的應用、網絡信息安全等方面的教學和科研工作;熊 晶(1991-),女,碩士研究生,研究方向為信息安全與隱私保護。
http://www.cnki.net/kcms/detail/61.1450.TP.20160801.0842.018.html
TP
A
1673-629X(2016)08-0088-05
10.3969/j.issn.1673-629X.2016.08.019
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
