基于粒子松密度的復雜網絡社團劃分算法
2016-02-27 00:43:04王曉軍
計算機技術與發展 2016年10期
關鍵詞:實驗
姜 斐,王曉軍,許 斌,亓 晉
(1.南京郵電大學 計算機學院、軟件學院,江蘇 南京 210003;2.南京郵電大學 物聯網學院,江蘇 南京 210003)
基于粒子松密度的復雜網絡社團劃分算法
姜 斐1,王曉軍1,許 斌2,亓 晉2
(1.南京郵電大學 計算機學院、軟件學院,江蘇 南京 210003;2.南京郵電大學 物聯網學院,江蘇 南京 210003)
復雜網絡的社團挖掘算法是近幾年數據挖掘領域新興起的一個熱點課題。傳統的智能優化算法雖然在社團挖掘方面有較好的效果,但其執行效率低,適用范圍窄;而已有的啟發式算法雖然在社團挖掘效率方面的優勢比較明顯,但相比于智能優化算法,其普適性仍未得到改善。為綜合提高社團劃分算法的效率,通過對材料科學領域的松密度的概念進行調研,結合復雜網絡的特有屬性,提出一種基于節點松密度的社團挖掘算法。實驗結果表明,相比于其他算法,該算法在時間和精度上都有較為顯著的優勢。
復雜網絡;松密度;社團;挖掘
0 引 言
復雜網絡是對復雜系統的抽象和描述方式,任何包含大量組成單元(或子系統)的復雜系統,當把構成單元抽象成節點、單元之間的相互關系抽象為邊時,都可以當作復雜網絡來研究[1];復雜網絡是研究復雜系統的一種角度和方法,它關注系統中個體相互關聯作用的拓撲結構,是理解復雜系統性質和功能的基礎[2]。因此,在科學發展日趨復雜化的大背景下,網絡社團挖掘算法的研究對分析復雜系統中的復雜網絡拓撲結構、理解其功能、發現其隱含模式、預測其行為具有十分重要的理論意義[3]。
1 網絡社團劃分算法
網絡社團結構是復雜網絡最普遍和最重要的拓撲屬性之一[4],處于相同社團內的節點間相互連接密集、處于相異社團的節點間相互連接稀疏;該特點也是對復雜網絡的社團結構的定義[5]。
幾乎所有的已知的社團聚類算法都直接或間接地應用了社團的這一特點進行計算[6]。在已知的應用到此領域的智能優化算法中,MODPSO(多目標粒子群算法)是效果比較好的一個,該算法將復雜網絡的模塊密度D的概念[7]進一步分解為RA和RC并將其作為算法的兩個優化目標[8]。
在MODPSO算法的核心的局部搜索部分,根據某一節點的鄰居節點的所占社團的比例進行該節點的社團歸屬劃分。該算法的實驗結果表明,局部搜索這一應用使得算法的效率有了顯著的提升;從社團定義的角度對其進行分析不難看出,對于一個社團內的某個節點的鄰居節點在同一社團的比例明顯要大于在不同社團的比例;同時在模塊密度的公式中也可以看到對網絡社團定義的間接應用。
(1)
(2)
D=RA-RC
(3)
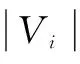
MODPSO算法通過局部搜索不斷優化RA和RC,使得RA不斷增大,RC不斷減小,最終得出網絡聚類結果。模塊密度能夠很好地反映網絡社團聚類情況的優劣程度,文中算法也會用到這一指標對實驗結果進行評測。實驗數據顯示,MODPSO算法對于部分網絡聚類精度高,但該算法也同樣具有智能優化算法的普遍缺陷—效率低[9]。
與智能優化算法相比,啟發式算法在效率方面則有較大的優勢[10]。啟發式算法根據網絡的節點與節點之間的內在聯系(如度、介數及聚類系數)等,對節點進行聚少成多的社團構造[11]。不同的網絡指標應用到聚類算法中有不同的優缺點:基于節點度的聚類算法,簡單直觀,便于計算,但忽略了網絡的整體特性,結果不夠準確;基于中介數的聚類算法按節點的流量分析節點的重要性,可以反映網絡的動態特性,但算法復雜度過高,執行效率低;基于特征向量的聚類算法考慮到了鄰居節點的重要性,但僅僅將各個節點進行簡單的線性疊加,過于簡化實際情況。
基于數據場的復雜網絡聚類算法是一種典型的啟發式聚類算法[12],在算法中首次將勢場和互信息的概念融合應用到復雜網絡聚類問題。首先,將節點的互信息作為衡量節點重要性的指標,根據節點互信息的大小劃分出網絡社團的核心節點;然后,通過計算每個非核心節點與核心節點的勢值判斷節點的社團歸屬。該算法執行效率較高,但其具有一定的局限性,只能對部分網絡具有較好的聚類結果。
文中通過對大量網絡數據集的拓撲結構進行調研,提出一種基于度和粒子松密度的粒子社團聚類算法;根據節點的度數劃分核心節點很容易忽略網絡的整體特性,而網絡松密度的概念則可以較好地彌補這一缺陷。將節點按照度大小進行降序排列,序列的第一個節點選為第一個粒子社團的核心節點;然后依次計算每個節點與核心節點的松密度,根據松密度的大小判斷該節點是否為新的粒子社團的核心節點。
2 粒子社團聚類算法
文中算法將網絡中的每個節點形象化為微粒,則根據網絡社團的定義,連接緊密的微粒聚集在一起形成粒子社團。
2.1 粒子松密度
粒子松密度的概念來自于微粒學中的松密度的定義。在微粒學中,松密度指的是包括顆粒內外孔及顆粒間空隙的松散顆粒堆積體的平均密度。用處于自然堆積狀態的未經振實的顆粒物料的總質量除以堆積物總體積求得,公式如下:
bulk=m/V
(4)
在粒子社團運算中,用節點數代替堆積物質量m,節點之間的連接數代替堆積物的體積V,則網絡總體的粒子松密度B為:
(5)
其中,Nnode表示網絡中總的節點數;Nedge表示網絡中總的邊數。
任意兩個節點的粒子松密度Bij為:
(6)
其中,Aij表示網絡的鄰接矩陣中i行j列的值;di和dj表示節點i和j的度;δ(i,j)表示節點i和j鄰居節點的重復個數。
2.2 算法流程
考慮到節點的度值較大的點對網絡中部分社團的劃分的影響比較大,因此文中算法根據節點的度值計算該節點是否為某一社團的核心節點。首先,設定度值最大的節點為第一個社團的核心節點;然后,按節點度值的降序次序依次根據如下條件判斷每個節點是否為核心節點:
(7)
若滿足式(7),則節點j不是新社團的核心節點,將其加入到核心節點為i的社團中;否則節點j為新社團的核心節點。式中λ的取值為節點j對核心節點i的影響度,根據實驗數據表明,λ的取值與網絡整體的粒子松密度密切相關,在實驗分析部分會對其進行詳細描述。
算法的具體執行步驟如下:
Step1:對網絡中的節點進行度值的降序排列,得到節點序列S。
Step2:從序列S取出第一個節點作為網絡中的第一個社團的核心節點,將該節點加入到核心節點序列C中。
Step3:依次取出序列S中的第二個節點,根據式(7)計算該節點與序列C中的節點是否滿足構成核心節點的條件;若滿足則將該節點加入序列C,若不滿足則將該節點加入到對應的核心節點所在社團。
Step4:重復Step3,依次遍歷序列S中的所有節點。
在算法核心步驟Step2和Step3的執行過程中分別會對網絡節點進行一次遍歷,算法的時間復雜度為O(n2)。
3 仿真實驗與分析
文中算法運行的硬件環境為Inter(R)Core(TM)i5-4200UCPU,1.60GHz,4GB內存。軟件環境為微軟Windows8.1操作系統,jdk1.7,Eclipse軟件開發環境,采用Java語言進行實現。
實驗數據的驗證采用國際通用的NormalizedMutualInformation(NMI)指標進行實際劃分結果與文中算法劃分結果的對比[13],該指標的值表示兩個向量的相似度,其取值范圍為(0,1)。文中用其作為實驗結果的社團號向量與真實社團號向量的相似度,若NMI=1,則兩向量完全相同;反之則完全不同。在對比過程中輸入兩個向量A和B,向量的第i位表示第i個節點所歸屬的類。
NMI(A,B)的計算公式如下:
其中,CA(CB)表示向量A(B)中的社團個數;C為向量A與向量B組成的混合矩陣,Cij表示向量B的第g個社團與向量B的第j個社團所共有的元素個數,Ci.(C.j)表示在矩陣C的第i行(j列)中所有元素之和;N為網絡中的節點個數。
文中對人造數據集及具有代表性的部分公共數據集如海豚網絡(dolphinnetworks)[14]、書局網絡(polbooksnetworks)[15]、空手道俱樂部網絡(karatenetworks)等[16]進行了對比測試。通過對實驗結果的分析證明文中算法相對其他算法而言具有良好的劃分效果和較高的執行效率。
3.1 人工網絡數據集實驗分析
人工網絡數據集是由人工生成的嚴格符合網絡社團定義的網絡數據集,該數據集包含50個節點、808條邊,該數據集的粒子松密度值為0.062。
按照網絡社團劃分的標準,該數據集共有5個社團,通過文中算法對其運算得出的社團聚類結果與原始聚類結果相同,該網絡的拓撲結構如圖1所示。
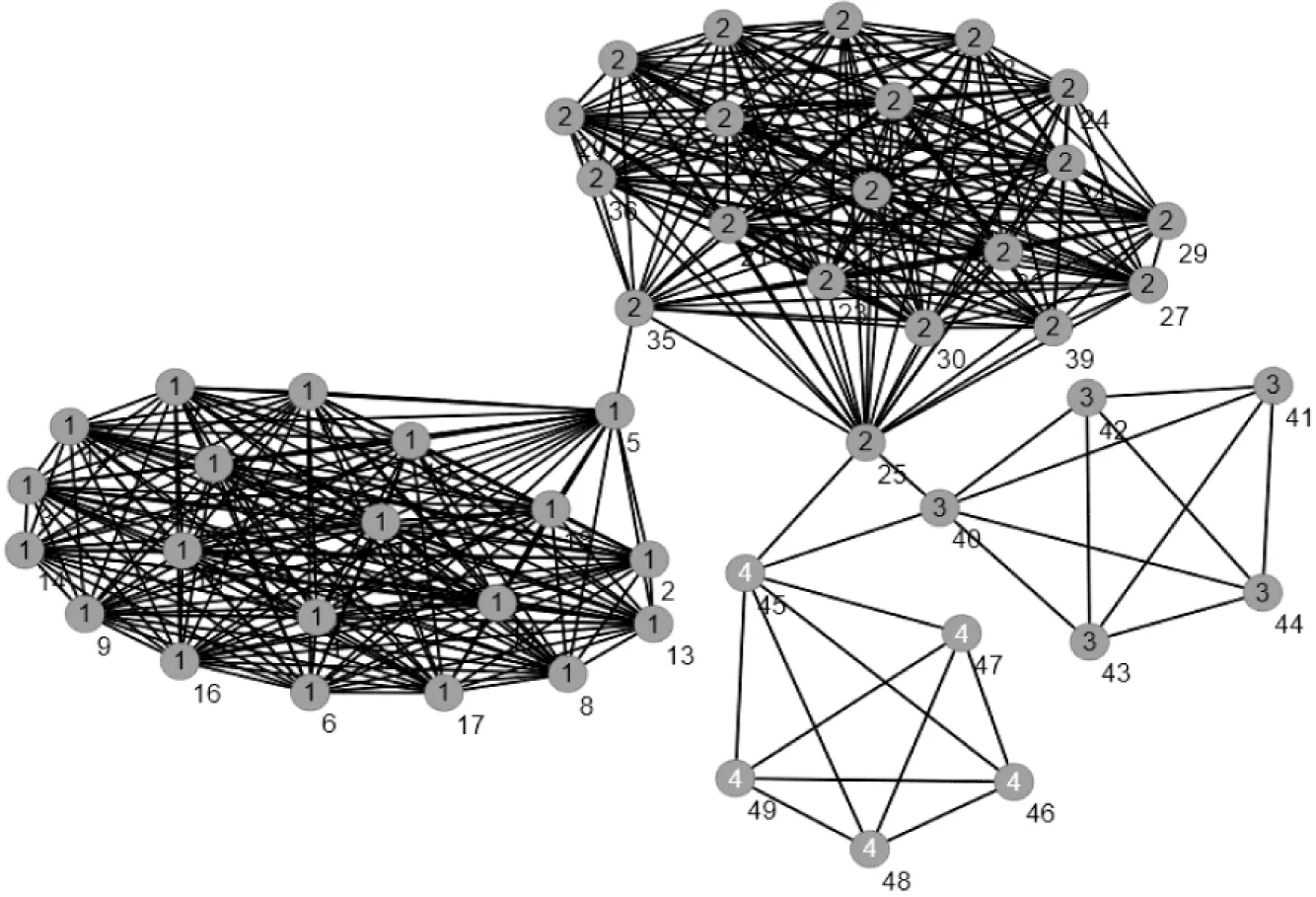
圖1 人工數據集網絡拓撲圖
實驗數據的NMI值為1表明文中算法的社團聚類結果與原始結果相同。實驗分別對λ取值0.1~0.9,這9個取值中對應該結果的λ的取值為0.1和0.2,其他取值對應的NMI值均為0.887。
3.2 海豚網絡實驗數據分析
該數據集由Lusseau等在新西蘭對62只寬吻海豚的生活習性進行了長時間的觀察得出,根據研究發現這些海豚的交往呈現出特定的模式,并構造了包含有62個節點的海豚網絡。如果某兩只海豚經常一起頻繁活動,那么網絡中相應的兩個節點之間就會有一條邊存在。該數據集含有159條邊,其粒子松密度值為0.39。該數據集的實際社團結構有一定主觀因素,共有兩個社團。當λ取0.4時,文中算法對其的聚類結果與真實結果相符。取不同λ對應實驗結果的最優解比例如圖2所示。當λ取值在網絡整體的粒子松密度附近時,實驗結果與原始聚類結果之間的差異將逐漸變小。其網絡的拓撲結構如圖3所示。
3.3 書局網絡實驗數據分析
書局網絡數據集包含105個節點,節點之間連接的邊數有159條,網絡的粒子松密度值為0.39。
該網絡數據集實際社團的結構如圖4所示。從該拓撲結構中可以明顯觀察出其并不完全符合網絡社團的定義:1號社團中的大部分節點都與其他社團連接緊密。按照該社團結構計算的模塊密度D的值為2.019。根據文中算法聚類過后的數據集如圖5所示,算法對原數據集的社團進行了部分修正,將1號社團中的部分節點重新進行聚類,當取值為0.4時,對應的模塊密度值最大,為4.054。從拓撲結構和數據上進行比較,結果表明文中算法的聚類結果明顯優于實際的聚類結果。
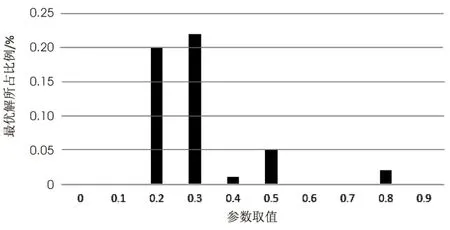
圖2 不同λ取值對海豚網聚類的影響
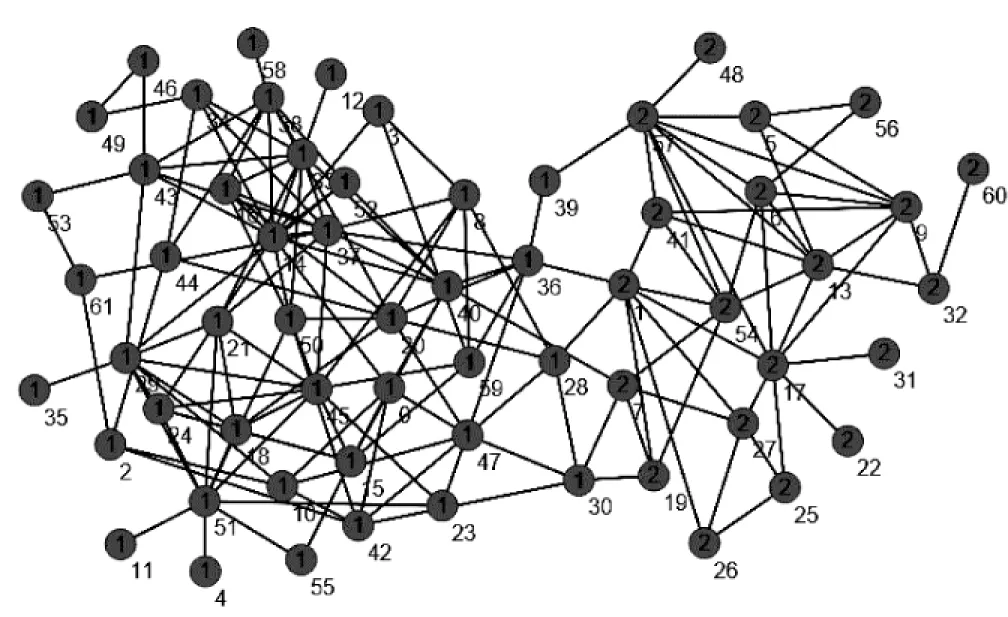
圖3 海豚網絡拓撲圖
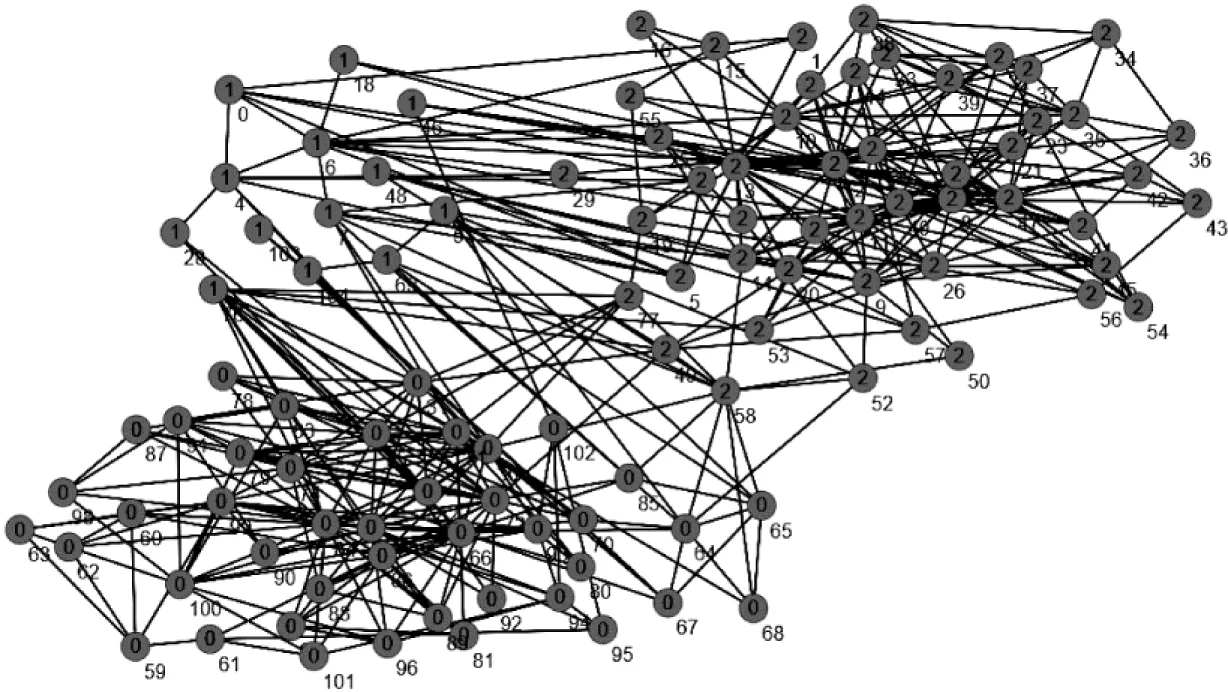
圖4 書局實際社團聚類拓撲圖
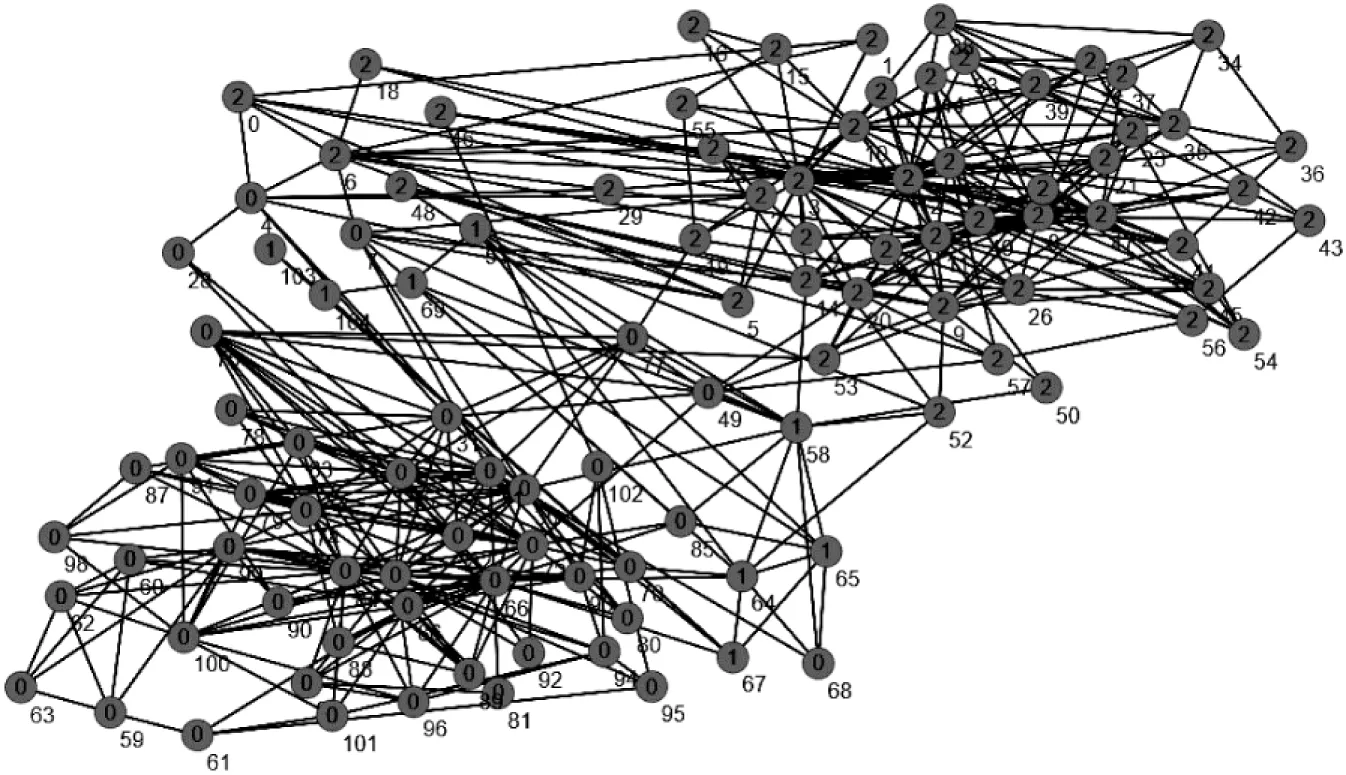
圖5 文中算法對數據網絡聚類拓撲圖
3.4 空手道俱樂部網絡數據集測試
空手道俱樂部數據集包含34個節點,節點之間連接的邊數為78,網絡的粒子松密度值為0.436。網絡數據集的拓撲結構如圖6所示。當取值為0.1~0.4時,NMI=1得出的聚類結果與實際聚類結果相符;取值為0.5~0.9時,NMI值為0.454與真實結果有偏差。
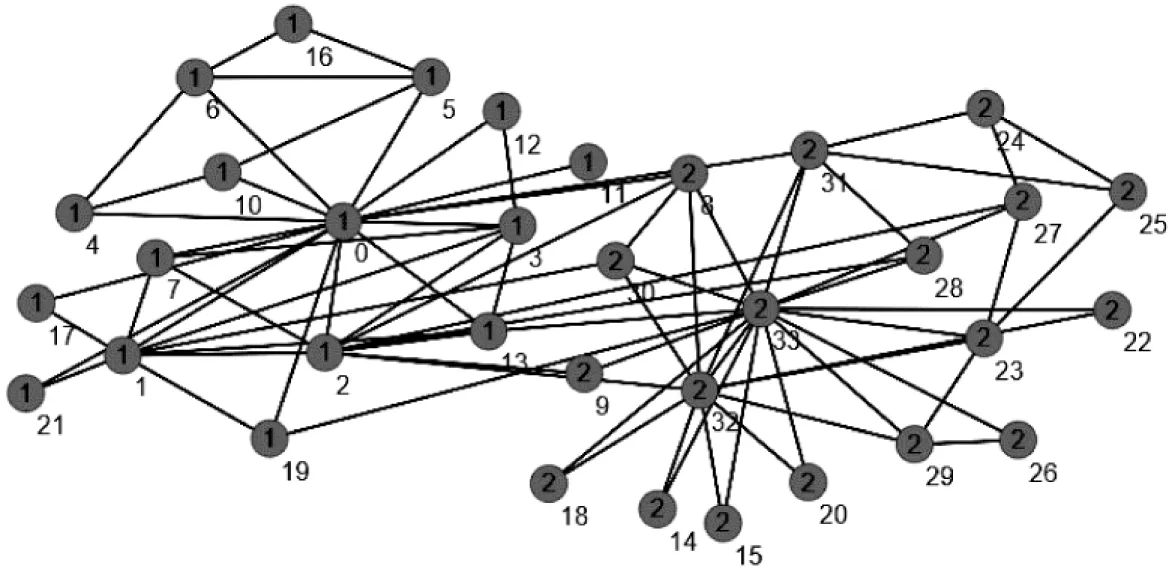
圖6 空手道俱樂部網絡拓撲圖
3.5 小 結
通過對各個數據集的實驗數據分析可以判斷,λ的取值對于文中算法的聚類效果具有較大影響。邊數比較密集的網絡中,其網絡的粒子松密度則偏小,因此合并節點i和j時,需要將Bij的值適當調大。λ的意義即是針對稀疏度不同的網絡來調整節點之間合并的條件。文中算法經過實驗數據測試得出λ與網絡整體的粒子松密度有著直接聯系,同時,實驗結果表明,文中算法對于符合社團基本定義的網絡可以給出準確的聚類結果。
4 結束語
對于復雜網絡進行社團劃分的算法種類繁多,皆是優缺點兼有。文中算法結合度值和粒子松密度的概念逐步對網絡節點進行聚類。通過對實驗數據的分析得出,不同網絡的社團結構與網絡整體的稀疏程度有著密切的聯系:稀疏的網絡社團內的節點連接也比較稀疏,但相比社團之間的連接要緊密;稠密的網絡社團之間的連接比較稠密,但相對比社團內的連接仍然稀疏。文中算法能準確地利用網絡整體的稀疏度來對網絡進行聚類分析。實驗結果表明,文中算法可按網絡社團聚類的基本原理給出較優的社團結構,效率較高。
[1]LiuH,CaoM,WuCW.Couplingstrengthallocationforsynchronizationincomplexnetworksusingspectralgraphtheory[J].IEEETransactionsonCircuitsandSystemsI:RegularPapers,2014,61:1520-1530.
[2]KangS,BaderDA.Largescalecomplexnetworkanalysisusingthehybridcombinationofamapreduceclusterandahighlymultithreadedsystem[C]//Procof2010IEEEinternationalsymposiumonparallelanddistributedprocessing,workshopsandPhdforum.Atlanta,GA,UnitedStates:IEEE,2010.
[3]PeiT,ZhangH,LiZ,etal.Surveyofcommunitystructuresegmentationincomplexnetworks[J].JournalofSoftware,2014,9(1):89-93.
[4]NewmanMEJ.Thestructureofscientificcollaborationnetworks[J].ProceedingsoftheNationalAcademyofSciencesoftheUnitedStatesofAmerica,2001,98:404-409.
[5]LiZ,ZhangS,WangRS,etal.Quantitativefunctionforcommunitydetection[J].PhysicalReviewE,2008,77:036109.
[6]YangB,LiuDY,LiuJ,etal.Complexnetworkclusteringalgorithms[J].JournalofSoftware,2009,20(1):54-66.
[7]GongMG,CaiQ,ChenXW,etal.Complexnetworkclusteringbymultiobjectivediscreteparticleswarmoptimizationbasedondecomposition[J].IEEETransactionsonEvolutionaryComputation,2014,18(1):82-97.
[8]LeskovecJ,LangKJ,MahoneyM.Empiricalcomparisonofalgorithmsfornetworkcommunitydetection[C]//Procof19thinternationalworldwidewebconference.Raleigh,NC,UnitedStates:[s.n.],2010:631-640.
[9]TongC,NiuJW,DaiB,etal.Complexnetworksclusteringalgorithmbasedonthecoreinfluenceofthenodes[C]//Procof2012IEEE31stinternationalperformancecomputingandcommunicationsconference.[s.l.]:IEEE,2012:185-186.
[10]LiuX,LiD,WangS,etal.EffectivealgorithmfordetectingcommunitystructureincomplexnetworksbasedonGAandclustering[C]//Procof7thinternationalconferenceoncomputationalscience.Beijing,China:[s.n.],2007:657-664.
[11]TongC,NiuJW,DaiB,etal.Anovelcomplexnetworksclusteringalgorithmbasedonthecoreinfluenceofnodes[J].ScientificWorldJournal,2014,2014:801854.
[12]LiuYH,JinJZ,ZhangY,etal.Anewclusteringalgorithmbasedondatafieldincomplexnetworks[J].JournalofSupercomputing,2014,67(3):723-737.
[13]DanonL,Díaz-GuileraA,DuchJ,etal.Comparingcommunitystructureidentification[J].JournalofStatisticalMechanicsTheory&Experiment,2005,2005:P09008.
[14]LusseauD,SchneiderK,BoisseauOJ,etal.Thebottlenosedolphincommunityofdoubtfulsoundfeaturesalargeproportionoflong-lastingassociations[J].BehavioralEcology&Sociobiology,2003,54:396-405.
[15]NewmanME.Findingcommunitystructureinnetworksusingtheeigenvectorsofmatricies[J].PhysicalReviewE,2006,74:036104.
[16]GirvanM,NewmanMEJ.Communitystructureinsocialandbiologicalnetworks[J].ProceedingsoftheNationalAcademyofSciencesoftheUnitedStatesofAmerica,2002,99:7821-7826.
Community Clustering Algorithm in Complex Networks Based on Bulk Density
JIANG Fei1,WANG Xiao-jun1,XU Bin2,QI Jin2
(1.School of Computer Science and Technology,School of Software,NJUPT,Nanjing 210003,China;2.School of Internet of Things,NJUPT,Nanjing 210003,China)
The association clustering algorithm of complex networks is a new emerging hot topic in the field of data mining.Traditional intelligent optimization algorithm has better effect in clustering,but it has low execution efficiency and narrow application scope.Although some heuristic algorithm has obvious advantages of clustering efficiency,but compared with the intelligent optimization algorithm,universality still has not be improved.To improve the efficiency of community division algorithm,through the research of the concept of bulk density in the field of materials science,puts forward a kind of association clustering algorithm based on bulk density.The experiment shows that the algorithm proposed has obvious advantage in time and precision compared with other algorithms.
complex networks;bulk density;community;clustering
2015-11-23
2016-03-04
時間:2016-09-19
國家自然科學基金資助項目(61401225);中國博士后科學基金資助項目(2015M571790)
姜 斐(1992-),男,碩士研究生,研究方向為數據挖掘;王曉軍,副研究員,碩士生導師,研究方向為分布計算技術與應用。
http://www.cnki.net/kcms/detail/61.1450.TP.20160919.0839.004.html
TP301.6
A
1673-629X(2016)10-0060-04
10.3969/j.issn.1673-629X.2016.10.013
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
