大數據分析平臺
2016-03-24 00:16:48鄭緯民陳文光
中興通訊技術 2016年2期
關鍵詞:大數據
鄭緯民 陳文光
摘要:認為現有以MapReduce/Spark等為代表的大數據處理平臺在解決大數據問題的挑戰問題方面過多考慮了容錯性,忽視了性能。大數據分析系統的一個重要的發展方向就是兼顧性能和容錯性,而圖計算系統在數據模型上較好地考慮了性能和容錯能力的平衡,是未來的重要發展方向。
關鍵詞:大數據;分布與并行處理;并行編程;容錯;可擴展性
Abstract:Existing big data analytic platforms, such as MapReduce and Spark, focus on scalability and fault tolerance at the expense of performance. We discuss the connections between performance and fault tolerance and show they are not mutually exclusive. Distributed graph processing systems are promising because they make a better tradeoff between performance and fault tolerance with mutable data models.
Key words:big data; distributed and parallel processing; parallel programming; fault tolerance; scalability
隨著信息化技術的發展,人類可以產生、收集、存儲越來越多的數據,并利用這些數據進行決策,從而出現了大數據的概念。大數據的定義很多,比較流行的定義是Gartner公司提出的簡稱為3V的屬性,即數據量大(Volume),到達速度快(Velocity)和數據種類多(Variety)。大數據分析利用數據驅動的方法,在科學發現、產品設計、生產與營銷、社會發展等領域具有應用前景。
由于大數據的3V屬性,需要在多臺機器上進行分布與并行處理才能滿足性能要求,因此傳統的關系型數據庫和數據挖掘軟件很難直接應用在大數據的處理分析中。傳統的超級計算技術,雖然具有很強的數據訪問和計算能力,但其使用的MPI編程模型編程較為困難,對容錯和自動負載平衡的支持也有缺陷,主要運行在高成本的高性能計算機系統上,對于主要在數據中心運行的大數據分析不是非常適合。
為了解決大數據的分析處理所面臨的編程困難,負載不平衡和容錯困難的問題,業界發展出了一系列技術,包括分布式文件系統、數據并行編程語言和框架以及領域編程模式來應對這些挑戰。以MapReduce[1]和Spark[2]為代表的大數據分析平臺,是目前較為流行的大數據處理生態環境,得到了產業界的廣泛使用。
但是在文章中,我們通過分析認為:MapReduce和Spark系統將容錯能力作為設計的優先原則,而在系統的處理性能上做了過多的讓步,使得所需的處理資源過多,處理時間很長,這樣反而增加了系統出現故障的幾率。通過進一步分析性能與容錯能力的關系,我們提出了一種性能優先兼顧擴展性的大數據分析系統構建思路,并以一個高性能圖計算系統為例,介紹了如何用這種思路構建大數據分析系統。
1 以MapReduce/Spark為
代表的大數據分析平臺
現有的大數據分析平臺主要基于開源的Hadoop系統,該系統使用Hadoop分布式文件系統(HDFS),通過多個備份的方法保證大量數據的可靠存儲和讀取性能,其上的Hive[3]系統支持數據查詢,Hadoop MapReduce則支持大數據分析程序的開發。
與傳統的并行編程方法MPI[4]相比,MapReduce是近年來并行編程領域的重要進展。盡管Map和Reduce在函數語言中早已被提出,但將其應用于大規模分布并行處理應歸功于Jeff Dean和Ghemewat Sanjay。在MapReduce并行編程模型中,用戶僅需要編寫串行的Map函數體和Reduce函數體,MapReduce框架就可以完成并行的計算,并實現了自動容錯和負載均衡。這對于數據中心中采用的異構服務器、低成本服務器集群是非常重要的。MapReduce開始僅能在使用通用中央處理器(CPU)的分布式系統上運行,但后來被移植到圖形處理器(GPU)和多種加速器上。
MapReduce需要將中間結果保存到磁盤中,從而大大影響了性能,美國加州伯克利大學提出的Spark系統可以看做是基于內存的MapReduce模型,通過將中間結果保存在內存中,大大提高了數據分析程序的性能,類似思路的系統還包括HaLoop[5]和Twister[6]等。
Spark和MapReduce在大數據領域取得了巨大的成功, 已經成為事實上的大數據處理標準。它們與分布式文件系統HDFS、查詢系統Hive都集成在Hadoop系統中,為大數據的存儲、查詢和處理提供了相對完整的解決方案。這一系統也具有完整的開源社區支持和商業公司支持,HortonWorks和Cloudera提供Hadoop的發行版和服務,DataBricks為Spark提供發行版和服務。IBM于2016年宣布將投入10億美元開發Spark。
2 大數據分析平臺性能的
重要性
盡管以Spark/MapReduce為代表的大數據分析平臺已經得到了廣泛應用,然而,其性能方面的問題也日益暴露出來。一些研究表明:對一些大數據分析問題來說,使用Spark在幾十臺機器上的性能甚至不如在某些優化過的程序在單機上的性能,例如對Twitter數據集來說,Spark在128個處理器核上需要857 s,而優化良好的單線程程序完成同樣的處理功能僅需要300 s的時間[7],即在中小規模數據集上Spark的性能功耗比比單線程程序要差2個數量級,甚至在絕對處理時間上也比單線程程序要慢。
Spark/MapReduce的性能問題,根源在于其設計理念上陷入了一個誤區:即以容錯能力為優先的設計目標,忽視了處理性能。例如,MapReduce和Spark都采用只讀數據集的概念,這一方面大大方便了系統進行容錯,但也使得系統在處理相當一部分應用時,性能會受到嚴重影響。例如,對于廣泛使用的廣度優先圖搜索問題,需要記錄哪些結點被訪問過,這個數據集如果是只讀的,就只能在每次遍歷迭代時生成新的數據集,這會大大增加所需的內存復制操作和內存容量需求,使得性能大大下降。
而實際上處理性能的提高,對提高系統的容錯能力也是有正面意義的。一個數據分析任務的總執行時間,可以按如式(1)估算(為描述方便,公式中略有簡化):
總執行時間 = 無故障執行時間①+無故障時容錯機制開銷②+故障發生概率*無故障執行時間*單次故障恢復時間③ (1)
Spark的設計主要對②進行優化,即通過只讀數據集簡化無故障容錯機制的開銷,卻大大增加了①的無故障執行時間,而③實際是與①正相關的,即相同機器數,執行時間越長,出故障的概率越大,所需故障恢復時間也就越長。
從上面的分析可以看出:Spark的設計理念,即使對容錯本身來說,也很難說是合理的,因為如果性能損失太大,無故障執行時間增加太多,會使得在②減少的開銷被③抵消甚至超越[8]。
因此,我們認為:大數據分析系統的一個重要的發展方向就是兼顧性能和容錯性。我們需要進一步在編程模型和框架上開展研究,在保持自動負載平衡和一定容錯能力的基礎上,提供優化的系統性能。
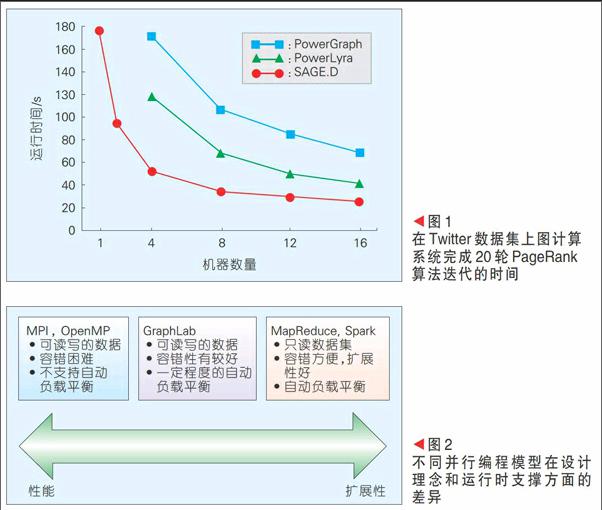
以Pregel[9]和GraphLab[10]等的圖計算編程框架是這一類工作的代表,這些編程模型主要提供了基于圖結點(vertex)的編程抽象,并沿著圖的邊進行通信,與Map-Reduce相比,這類圖編程框架在處理圖數據(如社交網絡、航運網絡和生物網絡等)時比Map-Reduce/Spark的表達更加自然,所獲得的性能也要好得多。這方面的工作引起了全球研究者和工業界的廣泛關注,這些工作針對圖計算中的負載不均衡、隨機訪問多、同步和異步等問題提出了解決方案。PowerGraph[11]和PowerLyra[12]系統是在GraphLab上改進后的圖計算系統,其性能比GraphLab又有顯著提高。GridGraph[13]提出了利用二維混洗的數據結構對圖計算進行優化,可以有效減少圖計算中的隨機內存訪問,提高處理性能。基于GirdGraph的分布式圖計算系統SAGE.D其性能比PowerLyra進一步又提高了1倍左右。如圖1所示:SAGE.D可以在16臺機器上以30 s的時間內完成Twitter數據集的20次PageRank迭代,性能比Spark提高了接近30倍。
我們可以看到:在某些分析任務上,基于圖計算系統的性能比基于Spark的分析系統快1~2個數量級。這意味著基于圖計算系統在執行期間內發生錯誤的機會僅為Spark的1/10以下,從而不僅在執行性能方面,在容錯能力方面也優于Spark。
3 大數據問題展望
未來的大數據問題會呈現兩種趨勢:
(1)具有較小上限的大數據問題。以社交網絡的分析問題為例,目前Facebook有約10億活躍用戶,用戶之間的關注關系大約有1 000億個,大約需要幾個TB的內存容量。社交網絡的結點是用戶,地球上只有幾十億人口,社交網絡的分析問題其上限就是將全部人口數作為網絡結點。
隨著摩爾定律的持續作用,我們今天已經可以很容易地買到內容容量為TB量級的服務器,今后可望達到幾十甚至數百TB。不斷增長的硬件能力與較小上限的大數據問題相遇的結果,就是把今天的大數據問題變為明天的小數據問題,把今天需要數十、數百服務器解決的問題變為今后只需要幾臺甚至單臺服務器就可以解決的問題。
針對這類應用,顯然性能優化的大數據分析處理平臺能夠獲得更好的性價比。
(2)具有較大上限的大數據問題。高性能計算中的很多問題規模具有非常大的上限,例如氣候模擬,需要將空間分成網格、時間分片,顯然空間上和時間上的進一步細分都會導致計算量和存儲量的大幅度增加,人類已有的計算能力還遠遠無法滿足高精度氣候模擬的要求。針對這類應用,性能優化的大數據分析處理平臺能夠通過減少運行時間,提高系統的處理效率和處理規模。圖2展示了不同并行編程模型在設計理念和運行時支撐方面的差異。
綜上所述,現有以Spark為代表的大數據處理平臺在解決大數據問題的挑戰問題方面過多考慮了容錯性,忽視了性能。我們認為圖計算系統在數據模型上較好地考慮了性能和容錯能力的平衡,是未來的重要發展方向。
參考文獻
[1] DEAN, JEFFREY, SANJAY G. MapReduce: Simplified Data Processing on Large Clusters [J]. Communications of the ACM, 2008, 51(1): 107-113. DOI: 10.1145/1327452.1327492
[2] ZAHARIA M, CHOWDHURY M, DAS T, et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing[C]// Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation. USA: USENIX Association, 2012:15-28
[3] THUSOO A, SARMA S J, JAIN N, et al. Hive: A Warehousing Solution over a Map-Reduce Framework [J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1626-1629. DOI: 10.14778/1687553.1687609
[4] GROPP W, LUSK E, DOSS N, et al. "A High-Performance, Portable Implementation of the MPI Message Passing Interface Standard [J]. Parallel Computing, 1996, 22(6): 789-828. DOI: 10.1016/0167-8191(96)00024-5
[5] BU Y, HOWE B, BALAZINSKA M, et al. HaLoop: Efficient Iterative Data Processing on Large Clusters [J]. Proceedings of the VLDB Endowment, 2010, 3(1): 285-296. DOI: 10.14778/1920841.1920881
[6] EKANAYAKE, JALIYA. Twister: A Runtime for Iterative Mapreduce [C]//Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing. USA: ACM, 2010: 810-818
[7] FRANK M, MICHAEL I, MURRAY D G. Scalability! But at what COST [C]//5th Workshop on Hot Topics in Operating Systems (HotOS XV). USA: USENIX Association, 2015
[8] KWAK, HAEWOON. What is Twitter, A Social Network or A News Media? [C]/Proceedings of the 19th International Conference on World Wide Web. USA: ACM, 2010: 591-600
[9] MALEWICZ, GRZEGORZ. Pregel: A System for Large-Scale Graph[C]// Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data. USA: ACM, 2010: 135-146
[10] LOW, YU C. Distributed GraphLab: A Framework for Machine Learning and Data Mining in the Cloud [J].Proceedings of the VLDB Endowment, 2012, 5(8): 716-727
[11] GONZALEZ, Joseph E. PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs [J]. OSDI, 2012, 12(1): 23-27
[12] CHEN R. Powerlyra: Differentiated Graph Computation and Partitioning on Skewed Graphs[C]//Proceedings of the Tenth European Conference on Computer Systems. USA: ACM, 2015: 1-15
[13] ZHU X, HAN W, CHEN W. GridGraph: Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning[C]//Proceedings of the Usenix Annual Technical. USA: ASM, 2015: 375-386
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
