文獻知識網絡的節點度變化對領域熱點的影響
2016-03-25 10:58:10,,,,
中華醫學圖書情報雜志 2016年11期
關鍵詞:關聯
,,, ,
文獻是科研工作者獲取科學假設與跟蹤領域進展的重要途徑,從大量文獻集中識別出前沿熱點對科學研究具有重要的理論和實踐意義。科技情報工作的基礎就是要抓住前沿熱點,掌握前沿發展的動態,密切跟蹤研究進展,但前沿熱點的定義并沒有科研人員一致公認的標準[1]。領域熱點存在兩個最主要的特征:一是相關領域近年的文獻集呈現出的熱點主題,二是圍繞熱點主題使未來短期內能形成大量新的研究內容。目前各個學科領域的科研人員提出了很多熱點主題的識別方法,以便領域專家總結未來短期內的研究方向,但研究內容的預測及對預測結果的評價仍是一個開放的問題。
要從已有文獻中獲得新的研究內容,首先需要從文獻集中發現隱含的聯系以形成科學假設。越來越多的文獻挖掘研究嘗試從文獻集構建關聯知識網絡,以便進一步深入地挖掘新的關聯知識[2],而網絡的拓撲特征會在一定程度上影響網絡的演化發展[3]。因此,本文主要基于文獻的知識發現模型,從關聯知識網絡的特征變化預測領域熱點,并通過1種評價預測結果的方法驗證其可預測性。
1 研究設計
基于文獻的知識發現(Literature-based Discovery, LBD)通過潛在的關聯挖掘推斷出新的科學假設。如果有兩類文獻集As和Cs,其中As討論了概念A和概念B之間的關系,而Cs討論了概念C和概念B之間的關系,但是沒有任何文獻討論概念A和概念C的關系,那么A與C之間通過B存在某種關系,這就可能是一個新的科學發現[4-5]。根據文獻知識發現理論模型,如果基于近期文獻集,從概念A能夠推斷出較多的新假設,那么概念A很可能是近期文獻集呈現出的某個熱點主題,能衍生出大量新的研究內容。
1.1 關聯建模
利用圖對關聯知識建模,是目前相關領域最常用的方法。通常一個簡單的無向無權網絡,可記為G=(V ,E),其中集合 V 稱為節點集,V={V1,V2,…,Vn},集合E稱為邊集,E={e1,e2,…,em},任意一條邊對應一個節點的二元組:ex=(Vi,Vj),E是V×V的一個子集。本文將文獻集中的內容相關性轉化為基于關聯信息存在的圖結構數據模型,即根據文獻中的概念實體及其關聯信息,對文獻中所蘊含的知識進行網絡結構化,構建文獻關聯知識網絡。在關聯知識網絡G=(V, E) 中,節點集V 是各種從生物醫學文獻中提取而來的實體的集合,如基因、蛋白質、化合物或疾病等,邊集E 是實體之間的關聯集合。關聯知識網絡把文獻集中的知識以網絡形式表示出來,這既表示出知識之間的聯系,也過濾了冗余知識,為發現對象間的隱含關系提供了方便。本文基于句子共現提取實體關聯[6],用以進行測試分析,基本過程如下。
識別出句子的實體NP(Noun Phrase)及其位置。如果在同一個句子中得到的實體按其在句子中的順序依次為NP1、NP2、NP3,則得到關聯(NP1,NP2),(NP1,NP3),(NP2,NP3)。如文獻標題(PMID: 20856896):β1-syntrophin modulation by miR-222 in mdx mice. 提取得到實體及其位置的列表為:[(β1-syntrophin modulation, 1),(miR-222, 4),(mdx mouse, 6)]
進一步得到關聯:(β1-syntrophin modulation, miR-222 ),(β1-syntrophin modulation , mdx mouse),( miR-222, mdx mouse)
將兩個實體首次共現的時間(年份),作為關系的T屬性。
1.2 熱點建模
給定關聯知識網絡G=(V,E),對于任意節點v∈V,定義其節點度的增長率為:
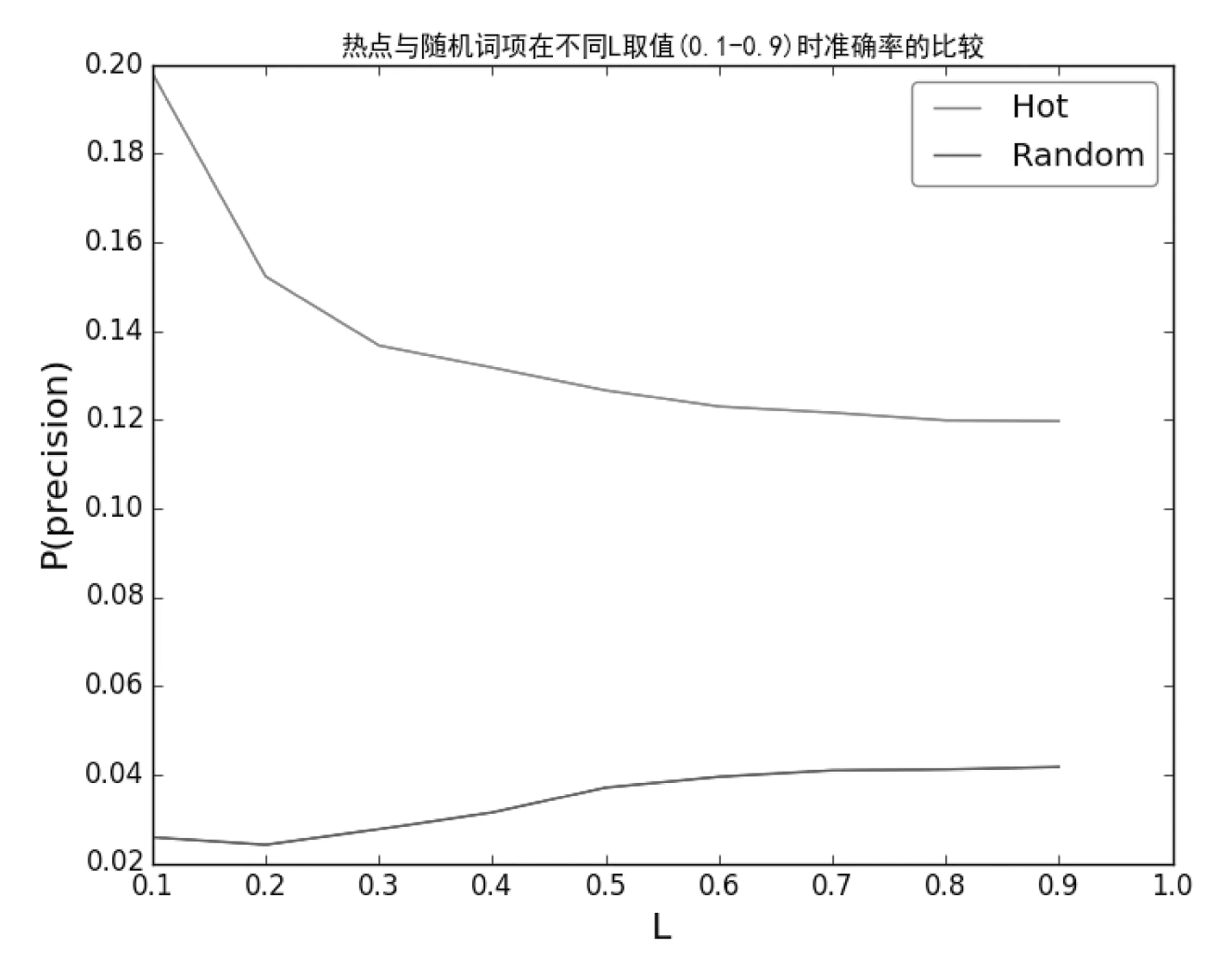
其中dT為T時節點的度,即T時節點的所有關聯數量,且T1 綜合來看,筆者更傾向于第一種浪形的劃分。因為從時間和大周期結構的角度來看,時間不支持走一輪完整的12345浪了。 文獻知識發現的實施主要包括3個重要部分,分別是概念實體A、B和C的識別、關聯的抽取以及間接關聯的相關度計算,用戶輸入概念A,計算A-B-C之間的關聯強度獲得按關聯強度由大到小的有序列表[7]。對于一個文獻知識發現系統來說,返回的候選結果的數量比較大時,排在前面的結果通常是用戶最關心的。因此,給定每一個A-B-C間接關聯,計算其(A-B-C)的一個分值SAC,利用SAC對所有候選結果集從大到小排序之后,在有序的結果列表中,確保排序靠前的多是全局關聯強度較好的結果,即只關注于分值最高的前L條關系鏈(A-B-C)的準確度P(Precision),P越大效果越好。 1.3.1 準確率P的計算 給定測試文獻數據集,將文獻數據集按時間分成訓練集Ttrain和測試集Ttest,分別建立訓練網絡G1=(N1,E1)和測試網絡G2=(N2,E2)。從N1中隨機選擇m個詞作為種子詞項集A,其中A取訓練網絡與測試網絡中共同擁有的詞項,即A∈N1∩N2。 在訓練網絡G1中,以種子集A中的節點為起點提取其間接節點,得到間接節點集C,計算所有關系鏈(A-Btrain-C)的一個分值SAC,對結果集C按SAC值從大到小排序,取有序結果集CSorted中前L個詞項,得到CSorted_TopL={c1,c2,…cL}。 在測試網絡G2中,以種子節點集A中的節點為起點提取其直接關聯節點,得到關聯節點集Btest。 計算有序結果集CSorted前L個詞項集CSorted_TopL的準確率P: 其中CSorted_TopL∩Btest指CSorted_TopL和Btest的交集,即共同擁有的詞項,|CSorted_TopL∩Btest|為交集的節點數量,|Btest|指Btest集的節點數量。 為了驗證熱點的可預測性,在Ttrain時期的訓練集篩選近3年關聯增長率最大的前N個詞項作為熱點詞項集Ahot,同時隨機選取N個詞項作為隨機詞項集Arandom,分別作為種子詞項集,基于Ttest時期的測試集,計算與比較兩種情況下的準確率Phot與Prandom。如果Phot顯著大于Prandom,說明Ahot詞項一定程度上表達了短期內的熱點主題,如圖1所示。 圖1 利用熱點詞項與隨機詞項預測新關聯的 1.3.3 A-B-C間接關聯SAC的計算 目前已有多種指標用于評價A-B-C三者之間的關聯性[8]。本文選擇常用的絕對詞頻(Absolute Word Frequency,AWF)來計算A-B-C之間的潛在關聯性SAC,以輔助計算與比較準確率Phot與Prandom,具體如下。 SAC=min(w(A,B),w(B,C)) 其中,w(A,B)與w(B,C)分別為A與B、B與C的共現次數。 以關鍵詞“miRNA or MicroRNA”從PubMed中檢索得到51 118條結果,取標題數據,將數據集按時間分成訓練集和測試集,分別建立訓練網絡G1=(N1,E1)和測試網絡G2=(N2,E2)。以2012年為分開點,2013-2015年的文獻數據作為Ttest測試集,2010-2012年作為訓練集Ttrain。從訓練集中隨機選取50個關鍵詞作為種子詞項Arandom,同時給定T2=2012,T1=2010,從訓練集中選取50個近3年增長率最大的節點作為熱點節點Ahot。 取 L=0.1,0.2,0.3,…,1,即取有序結果集Csorted前10%、20%、10%、20%、30%、40%、50%、60%、70%、80%、90%、100%的詞項時,計算熱點詞項與隨機詞項的準確率P的結果如圖2所示。 圖2 L=0.1,0.2,… ,1.0時熱點詞項與隨機 進一步取靠前的區間,取 L=0.01,0.02,0.03,…,0.1,即取有序結果集Csorted前1%、2%、3%、4%、5%、6%、7%、8%、9%、10%的詞項時,計算準確率P的結果如圖3所示。 圖3 L=0.01,0.02,…,0.1時熱點詞項與隨機詞項的準確率P的比較 綜合圖2、圖3的測試結果可以發現,基于文獻知識發現模型,對結果集進行關聯置優排序,利用熱點詞項計算得到的準確率Phot顯著高于由隨機詞項獲得的準確率Prandom。這一方面說通過篩選節點度增長率大的詞項,可以獲得更多的新關聯,即度增長率大的節點在短期內能衍生出較多的新研究內容;另一方面說明,能夠在未來短期內形成的大量新關聯都與節點度快速增長的詞項密切相關。因此,節點度快速增長的詞項在一定程度上能夠表達相關領域近期的熱點主題,即文獻知識網絡的節點度變化對領域熱點具有一定的預測作用。 面對大數據時代知識獲取的需求與挑戰,基于文獻的知識發現研究對完成從文獻到知識的轉化具有重要作用,已成為醫學情報分析與輔助科研的一種重要理論與方法。基于文獻的知識發現是一個啟發式的過程,如何保證在已有的文獻集中,篩選出更多更有效的潛在關聯,仍是該領域研究的熱點問題之一。 本文基于文獻知識發現模型,探討了文獻知識網絡中節點度變化對近期熱點的預測性,測試實驗顯示度增長率大的節點在未來形成新關聯的準確率顯著大于一般節點,表明節點度變化對領域熱點具有一定預測性。在實際科研過程中,不同時期、不同領域都存在相應的熱點內容,準確地識別領域前沿熱點是進行情報跟蹤的基礎。如果在文獻知識發現具體實施過程中的種子概念實體取自于熱點主題,可以顯著提升知識發現準確率和篩選效率,輔助科研人員獲得更多的科學假設。1.3 評價方法

2 數據實驗
2.1 數據準備
2.2 結果與討論

3 總結
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
