
基于引文分析的古籍文獻影響力評估
2016-04-11 07:53:48馬創新陳小荷
大學圖書館學報 2016年1期
馬創新 陳小荷

摘要 介紹注疏文獻的引用特點,并對注疏文獻的引用情況進行分類。分析注疏文獻引文分析的流程,提出利用學科本體和XML表示的注疏文獻,解決引文分析中的難點。通過對《十三經注疏》中各部注疏文獻之間的耦合分析,以及被引文獻的同被引分析,嘗試對古籍文獻的影響力進行評估。
關鍵詞 古籍文獻 XML 本體 引文分析 評估
分類號 G255.1
DOI 10.16603/j.issn1002—1027.2016.01.002
1引言
中華文化源遠流長,在這漫長的歷史時期,產生了大量古籍文獻。這些著作是中華民族精神文明的結晶,具有重要的文學價值、科學價值和歷史價值。在當今時代,如何科學地評估古籍文獻在中華文化中所處的地位和影響力,成為亟需解決的重大問題。
知識具有傳承性、累積性、擴散性和創新性,任何新知識都不是憑空產生的,都是在前人研究的基礎上創造出來的。文獻作為知識的主要物質載體,它們顯然都不是孤立存在的,而是具有密切聯系的,它們之間的聯系就表現在文獻的相互引用上。因此,文獻的相互引用是知識傳承規律的表現,也是科學活動中普遍存在的一種必然現象。
引文分析就是建立在文獻的引用與被引用關系基礎上,運用數學、統計學和邏輯學等方法,對期刊、論文、專著等研究對象的引用和被引用現象進行計量分析,揭示出研究對象所具有的規律和特征,以及對象之間的關系,從而探尋科學發展的動態規律、評價科學現象和預測領域熱點。
國外很早就在科學史、科學結構和科技管理等研究領域應用引文分析的方法。從二十世紀八十年代起,國內逐漸重視引文分析的研究,并且研制了多個用于科學管理的期刊引文索引數據庫。當前國內外的引文分析在研究范圍方面更加寬廣,并且逐步增加研究深度,探索出了一些新的引文分析方法。
2古籍文獻引文分析的相關研究
對于一般研究者來說,在閱讀和理解古籍文獻時會比較困難,所以對古籍文獻做引文分析的多是文獻學或者語言學的專家,他們的研究目的、關注的重點以及所采用的方法與當代圖書情報學界的引文分析研究有較大區別。
1930年,洪業主持創辦了我國第一個大型索引編纂機構——哈佛燕京學社引得編纂處,致力于編纂古籍索引,出版了《漢學引得叢刊》,共計64種81冊。洪業等人的引得編制因書而異,對于先秦諸子和儒家重要經典,就編為逐字引得;對于考證名物的古籍,編作綜合引得;對于注疏類文獻,則編為引書引得。洪業等人編制的“注疏引書引得”有《春秋經傳注疏引得》、《禮記注疏引書引得》、《周禮引得附注疏引書引得》、《爾雅注疏引書引得》等共計14種。他們編制這些引得的主要目的在于為研究者提供檢索工具和輯佚線索。
何希淳在其1966年的碩士論文《禮記正義引佚書考》中,考證《禮記正義》引書中已經亡佚文獻的作者生平、各書內容和前人輯存情況。葉程義在其1969年的碩士論文《<禮記正義>引書考》中,列舉了《禮記正義》的引書種類,并且按照禮類、書類、易類、詩類等進行歸類,把《禮記正義》引書的方式歸納為工5種,引書作用歸納為“申鄭注”、“申經義”、“證鄭注”、“證經義”、“存異說”等5種。王忠林的碩士論文《周易正義引書考》介紹了《周易正義》引書的種類、作用和方式,考證每種書的作者和流傳情況,并且列出具體引書加以疏證。
班吉慶對劉寶楠的《論語正義》中引用《說文解字》闡述經義時的訓詁特點進行了歸納和總結。馬萃澤輯錄了《五經正義》孔穎達疏中引用《說文解字》的全部引文內容,把引用體例歸納為全引、節引和敘引三類,并且把所輯錄的引文內容與通行大徐本《說文》進行比對,考證其中存有差異的條目。安敏統計了孔穎達的《左傳正義》的引書情況,將引書按經、史、子、集分類,統計出引書的書名和引用次數,分析了《左傳正義》的引書形式和注疏重點。
綜觀上述古籍文獻的引文分析研究,我們發現這些研究基本上都深入到引文內容層面進行統計、溯源、歸類和比較,具有一定的研究深度。但是,當前古籍文獻的引文研究總體上聚焦在微觀層面的考證與辨析,沒有明確地從技術角度人手做引文耦合及共被引分析,很少有利用引文分析探索科學史以及揭示科學結構等方面的宏觀研究。
筆者以某一類古籍——“注疏文獻”為研究對象,借助學科本體和結構化表示的注疏文獻,通過引文分析,探索注疏文獻中文獻引用的規律和特點,從宏觀層面挖掘引文分析在探索科學史和評估古籍文獻影響力方面的價值。
3注疏文獻的文獻引用特點和分類
對比當代的論文和圖書等文獻的引用情況,我們認為,注疏文獻的文獻引用有三個特點:
(1)古籍文獻是封閉性的信息資源。所謂封閉性資源,是指信息規模有限,不再隨時間而增加,處于靜止狀態的信息資源。因為古籍文獻的封閉性,它們的引文耦合、同被引等數據都已經固定不變,不像當代的期刊文獻具備開放性,引文分析的各項數據還在不斷變化之中。
(2)引用方式都是內容引用,沒有列出參考文獻。古籍文獻并沒有在文獻末尾列出參考文獻的慣例,其所引用的文獻種類和引用次數只能到施引文獻的內容中查找和統計。
(3)施引文獻和被引文獻都是圖書,而沒有論文。古代沒有定期出版的刊物,還沒有出現論文這種記錄學術成果、并且能夠快捷地提供給讀者閱讀的知識載體,所引用的文獻都是書籍。
我們考察了《十三經注疏》的引用情況,對十三部注疏文獻中的引用情況進行了綜合、比較、分析和歸納,按照兩個標準對注疏文獻的文獻引用情況進行分類。
(1)根據所引用對象的類型,可以把引用情況分為“典籍引用”和“其他引用”兩大類。注疏文獻中的典籍引用是指引用《論語》、《莊子》、《史記》、《漢書》、《說文》、《方言》等文獻。除了引用典籍外,注疏文獻中還大量引用訓詁學家的看法和說解,這些說解沒有按照原創作者的不同分別輯錄成書,而是散錄在多部注疏文獻中。此外,還大量引用了散傳的詩歌曲詞等。
(2)根據引用方式,可以把引用情況分為“標明出處的引用”和“未標明出處的引用”。在注疏文獻中,大部分引用都是標明了出處的,只有少部分沒有標明。
4注疏文獻引文分析的流程、難點和解決方法
4.1注疏文獻引文分析的流程
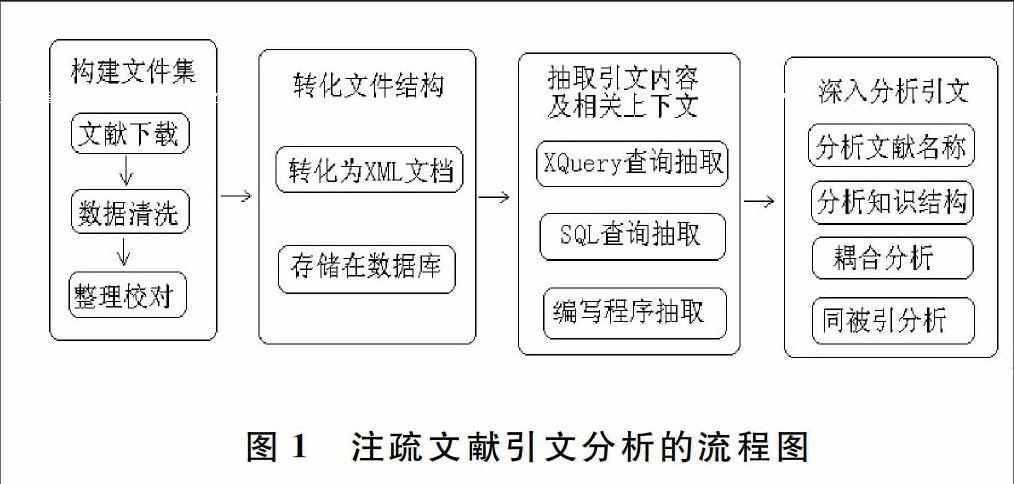
注疏文獻的引文分析,實質上就是對注疏文獻的引用內容、以及相關上下文進行分析。注疏文獻引文分析的具體流程如圖1所示,它主要包括四個步驟:
(1)構建文獻集。構建文獻集是進行引文分析的前提,主要包括文獻下載、數據清洗和整理校對等工作。文獻在下載和清洗之后,要進行相應地整理,包括修改文件名和合并文件等。另外,還要利用紙質古籍善本對文獻做人工校對,以此來保證文獻集具有可靠的質量。
(2)轉化文件結構。轉化文件結構是進行引文分析的基礎,主要是把文獻由非結構化或半結構化轉化為結構化,以便于進行文本分析和知識挖掘。當前主流的結構化文件存儲方式是使用數據庫,或者以XML格式存儲。由于XML技術能夠把文獻內容與表示結構信息的標簽分離開來,不會影響文獻在閱讀方面的連續性,并且文獻內容獨立于顯示方式,針對同一文獻內容可以定義多種顯示方式,所以XML比數據庫更適合存儲結構化的文獻資料。
(3)抽取引文內容及相關上下文。這一步是進行引文分析的關鍵環節。在把文獻由非結構化或半結構化轉化為結構化表示后,如果文獻是存儲在關系型數據庫中,能夠使用SQL查詢和抽取引文內容及相關上下文。如果文獻存儲為XML格式,可以利用XQuery檢索和抽取,也可以自編程序實施抽取,編寫程序前,首先要對文獻中引文上下文的形式特征進行分析和總結,根據其區別特征編寫抽取規則。
(4)深入分析引文。這一環節是進行引文分析的核心和重點,主要包括①區分各個引文內容是屬于哪部文獻,由于所引文獻名稱的具體寫法存在多種方式,所以很難直接區分;②對所引文獻按照不同的分類標準進行歸類,以此來探索施引文獻的知識結構;③對施引文獻和被引文獻進行文獻耦合分析、同被引分析,探索它們之間的相互關系、共同特點和區別特征。
4.2注疏文獻引文分析的主要難點
主要難點有以下兩個方面:
(1)把注疏文獻由普通文本轉化為結構化的XML文檔時,需要分析各部注疏文獻的行文結構和內部知識單元,定義的XML架構要能夠適應于所有的注疏文獻,并且充分地表示出重要的知識,具有高度的結構化和模塊性。另外,需要轉化的文獻規模很大,如果完全使用人工方式轉化,成本會很高。
在抽取引文內容及其上下文時,首先要分析表示注疏文獻知識結構的XML架構,總結文獻中引文上下文的形式特征,然后根據區別特征定義規則進行抽取測試,并且分析抽取結果,改進抽取規則。要循環此流程,直至達到最佳的抽取效果。
(2)注疏文獻中所引文獻的名稱存在多種寫法,比如:《爾雅》、《釋言》、《漢書。天文志》、《大雅·抑篇》、《詩.小雅.出車》等。還存在書名的異名同指現象,比如常稱《周易》為《易》或《易經》、稱《尚書》為《書》等。只有解決這個問題,才能正確區分出各個引文內容究竟是屬于哪部文獻。
4.3解決方法
4.3.1把注疏文獻轉化為結構化XML格式,以便于抽取引文內容
注疏文獻的傳統知識表示方法是面向人的理解的,使用計算機難以對其做檢索和分析。而XML是表示結構化數據的行業標準,是萬維網聯盟定義的一種元數據,也是可以用來創建標記語言的元語言。近些年來,XML被廣泛應用于古籍知識表示研究中。
XML沒有預先定義的標記系統,允許開發者根據需要定義自己的標記系統。在使用XML標注語料時,標注者可以根據需要設計標記體系,詳盡地標注出語料中的信息。當語料規模不斷擴充,或者應用逐步深入時,XML能夠適應需求的變化,很方便地擴展標記系統。為了能夠使所定義的XML架構與表示對象的知識結構基本一致,我們從注疏文獻的外部關聯事物、內部體例結構和知識結構三個方面,對注疏文獻的典型代表——《十三經注疏》做全面分析。在此基礎上,設計了表示注疏文獻的XML架構。這個XML架構簡潔而又清晰,表現出了注疏文獻的核心知識結構,能夠根據需要進行擴展,具有較強的可擴展性。
把注疏文獻由普通格式的文獻轉化為符合XML架構規范的XML文檔的過程,也就是把它們的知識結構由半結構化轉變為結構化的過程。要實現這種知識結構的轉化,有多種方法可供選擇,比如:手工方法、自動化方法、半自動方法等。我們在實施這項轉化工作時,采用計算語言學方法,充分利用注疏文獻的半結構化特征,依據人工制訂的規則,編寫程序實現注疏文獻的半自動轉化,提高了知識結構轉化的工作效率。圖2是用XML表示《論語集注》的樣例。
注疏文獻原本是半結構化的,現在由于轉化成了結構化的XML格式,在原文中添加了有意義的標簽信息,這就使得注疏文獻更加便利于利用計算機進行分析和處理。在此基礎上,能夠開展多方面的研究。例如:設計更加智能、具有更高查準率的檢索系統,實現多種類型、復雜條件的檢索;在注疏引文與其經典原文的知識點之間自動設置錨點和鏈接,實現古籍文獻的超文本閱讀;等等。
4.3.2利用訓詁學本體解決文獻名稱的異名同指問題
對于標明出處的文獻引用,在所引文獻名稱的具體寫法上,存在著多種方式。古代的劉炫做了總結,他認為“夫子敘經,申述先王之道。《詩》、《書》之語,事有當其義者,則引而證之,示言不虛發也。七章不引者,或事義相違,或文勢自足,則不引也。五經唯《傳》引《詩》,而《禮》則雜引,《詩》、《書》及《易》并意及則引。若泛指,則云‘《詩》曰、‘《詩》云;若指四始之名,即云《國風》、《大雅》、《小雅》、《魯頌》、《商頌》;若指篇名,即言‘《勺》曰、‘《武》曰;皆隨所便而引之,無定例也。”我們分析了《十三經注疏》的文獻引用情況,歸納出注疏文獻在標明所引用文獻名稱時的六種常用寫法:
(1)給出文獻名稱,如《方言》、《爾雅》、《左傳》、《莊子》等,即劉炫所說的泛指。
(2)給出章節名稱,如《釋言》、《釋詁》、《大雅》、《泰誓》、《大宗伯》等,即劉炫所說的指四始之名。
(3)給出篇名,如《關雎》、《勺》、《武》、《多方》等。
(4)給出“文獻名稱+章節名稱”或者“文獻名稱十篇名”,如《爾雅·釋天》、《漢書·天文志》、《周禮·司服》、《周禮·司勛》、《史記·弟子傳》、《史記·世家》、《禮記·少儀》、《詩·大雅》、《詩·唐風》等。
(5)給出“文獻名稱+章節名稱+篇名”,如《詩·邶風·雄雉》、《詩·小雅·出車》、《詩·大雅。皇矣》、《周易·既濟·象辭》、《周易·遁卦·象辭》等。
(6)給出“章節名稱斗篇名”,如《大雅·抑篇》、《小雅·蓼莪》、《小雅·隰桑》、《乾卦·文言》、《夏官·司弓矢》、《地官·遂人職》、《衛風·碩人》等。
另外,注疏文獻中在標明所引用文獻名稱時,經常出現異名同指現象,比如常稱《周易》為《易》或《易經》、稱《尚書》為《書》、稱《詩經》為《詩》、稱《春秋左氏傳》為《左傳》或<<左氏傳》、稱<<春秋公羊傳》為《公羊》等等。
注疏文獻在給出所引用文獻名稱時的六種常用寫法中,第一、四、五種名稱寫法都含有文獻名稱,而第二、三、六種寫法只有章節名稱或篇名,卻沒有文獻名稱。除此之外,還存在文獻名稱的異名同指問題。
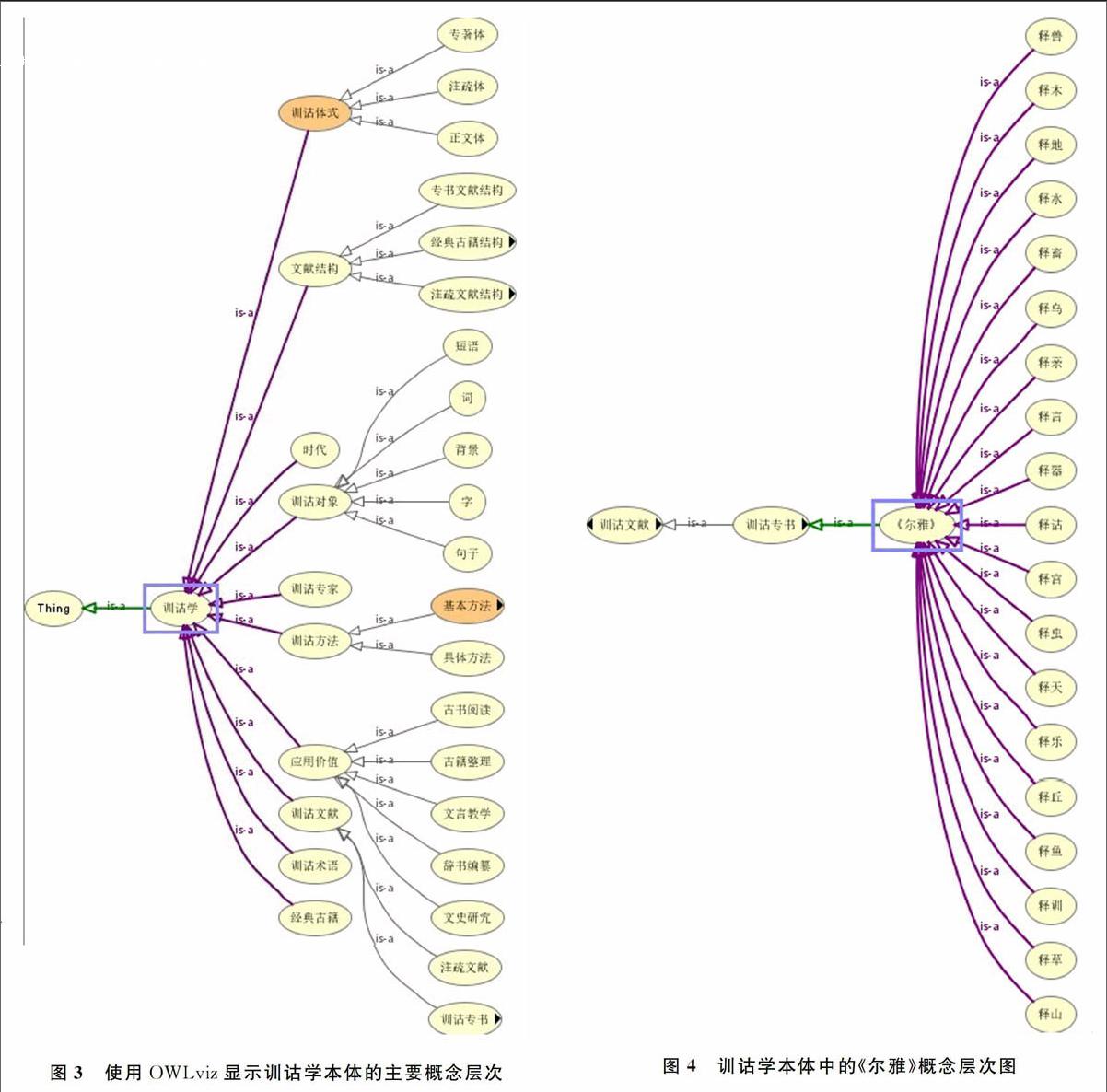
對于這些問題,我們使用“古籍文獻名稱知識庫”來解決,該知識庫不需要重新構建,它存在于“訓詁學本體”中。為了用形式化方式表示訓詁學領域的知識體系,利用本體思想重新檢查和審視傳統的訓詁學知識體系,構建了“訓詁學本體知識庫”,它包含10個頂層概念、25個一級子概念、216個二級子概念以及眾多的下級概念。使用Protege4.2編輯器,對訓詁學本體進行編輯,生成OWL文件保存。圖3就是使用Protege的圖形插件OWLviz顯示的訓詁學本體的主要概念層次。
在訓詁學本體的“經典古籍”和“訓詁文獻”兩個頂層概念下,列出多部古籍文獻的名稱,以及各部古籍的章節名稱和篇名。圖4的是訓詁學本體中的《爾雅》概念層次圖。
在做注疏文獻的文獻引用自動分析時,如果發現使用書名號括起來的字符串,當不能確定它是指哪部文獻時,甚至不能確定它是文獻名、章節名,還是篇名時,就到“訓詁學本體”的“經典古籍”和“訓詁文獻”兩個頂層概念下進行檢索和分析,以確定它究竟指的是哪部文獻或者屬于哪部文獻。
5利用引文分析評估古籍文獻的知識結構和影響力
《十三經注疏》包含了十三部注疏文獻,所引用的文獻種類極多,引用次數龐大,引用情況復雜。在注疏文獻的各種引用類型中,“其他引用”所引用的內容主要是訓詁學家說解,以及散傳的詩歌曲詞等。“典籍引用”所引用內容的來源復雜,包括多種類型的文獻。“未標明出處的引用”所引用的內容一般字數較少,或者只是含義引用,而非原文引用,引用者在很大程度上對原文作了改寫。“標明出處的引用”所引用的內容一般是原文引用,并且引用字數較多。所以,“標明出處的典籍引用”是注疏文獻中的主要引用類型。
我們編寫程序分析結構化表示的《十三經注疏》。為了能夠在有限條件下得到較為精確的結果,我們的實驗沒有對《十三經注疏》中所有的引用情況做窮盡式統計,只統計和分析“標明出處的典籍引用”,對于僅僅提及而沒引用其內容的典籍也不做分析。
5.1文獻引用的總體情況和文獻特點分析
《十三經注疏》中共有65045次提及文獻名稱、圖畫名稱、舞蹈名稱和樂曲名稱等可以用書名號標注的名稱,其中《周易正義》提及1565次;《尚書正義》提及3839次;《毛詩正義》提及13574次;《周禮注疏》提及8809次;《儀禮注疏》提及6363次;《禮記正義》提及11460次;《春秋左傳正義》提及8528次;《春秋公羊傳注疏》提及1951次;《春秋穀梁傳注疏》提及1373次;《論語注疏》提及1255次;《孟子注疏》提及1467次;《孝經注疏》提及836次;《爾雅注疏》提及4025次。
我們對《十三經注疏》中“標明出處的典籍引用”情況做了統計,結果顯示:引用文獻總次數為27403次,被引文獻達400多種。其中,被引次數排在前10位的文獻是《禮記》、《周禮》、《詩經》、《爾雅》、《儀禮》、《尚書》、《周易》、《左傳》、《說文》、《史記》。在這10部被引次數較多的文獻中,除了十三經中的八部經書之外,還有一部訓詁專書《說文》和一部史書《史記》名列其中,這說明了《說文》和《史記》分別在訓詁專書和史書中的重要地位。
通過分析表1中各部注疏文獻所引用的文獻類型,我們能夠對各部注疏文獻所具有的知識結構特點有一個基本的了解。
《十三經注疏》各部注疏文獻引用文獻次數和種數如表2所示。《禮記正義>>引用的文獻次數最多,達到5070次,同時它也是引用的文獻種數最多的文獻,引用了182種文獻。《春秋穀梁傳注疏》引用文獻次數最少,只引用265次;而《周易正義》引用的文獻種類最少,只有24部。
各部注疏文獻引用文獻次數和種數的多少,除了與其自身的篇幅大小有關之外,還與其各自的訓詁特點有關。各部注疏文獻在引用文獻的類型、次數和種數等方面差別很大,通過分析它們的文獻引用情況,可以基本判斷出它們在訓詁方式上的特點。接下來,以《春秋經》的三部注疏文獻為例加以說明。
《春秋左傳正義》引用文獻次數和種數都比較多,并且大量引用《說文》的釋義,《說文》在其所引用的133種文獻中,按引用次數排在第八位,由此可以看出《春秋左傳正義》注重對詞語意義的解釋,它通過解釋詞義來疏通句義和文意。相對而言,《春秋穀梁傳注疏》引用史書的次數比較多,《史記》和《世本》在其所引用的50種文獻中,按引用次數分別排名第九位和第十位,由此可見《春秋穀梁傳注疏>>更偏重于介紹歷史事件背景。《春秋公羊傳注疏》引用文獻61種,共引用文獻383次,在引用次數較多的前十種文獻中,既沒有史書也沒有字書,它的訓詁特點是重視闡述句義。
5.2文獻的耦合情況和知識結構相似度分析
我們分析了《十三經注疏》中各部文獻之間的耦合情況,使用傳統的耦合強度計算方法計算注疏文獻之間的耦合強度,即:兩部文獻A與B之間的耦合強度就是它們引用相同文獻的數量,如果A與B同時引用了m種文獻,那么A、B之間的耦合強度就定為m。由此可見,耦合強度的高低,取決于施引文獻之間引用相同文獻的數量。反之,文獻之間的耦合強度越高,說明它們引用的相同文獻越多,在知識結構上的相同之處也越多。
在表3中,列出了在《十三經注疏》中各部文獻之間的引文耦合矩陣。可以看出,在《十三經注疏》中,耦合強度最高的兩部文獻是《周禮注疏》和《禮記正義》,它們之間的耦合強度是97;而耦合強度最低的兩部文獻是《周易正義》和《孝經注疏》,它們之間的耦合強度是13。《十三經注疏》中各部文獻之間的平均耦合強度是44.5。
經過分析,我們發現“耦合強度”與“知識結構的相似度”之間確有著正相關。《十三經注疏》中每部注疏文獻都有兩位或兩位以上的注疏人,比如:《周易正義》是王弼、韓康伯注、孔穎達等正義;《禮記正義》是鄭玄注、孔穎達等人疏。我們發現在這十三部注疏文獻中,當兩部文獻有一個相同的注疏人時,這兩部文獻的耦合強度就會相對較高。以《周禮注疏》為例,與《周禮注疏》之間耦合強度最高的文獻是《禮記正義》,我們發現這兩部文獻引用的文獻種數都比較多,并且都是由鄭玄作注;《孟子注疏》共引用文獻59種,它與《周禮注疏》的耦合強度是34,《儀禮注疏》共引用文獻57種,與《孟子注疏》引用文獻種數相差不大,但它與《周禮注疏》的耦合強度就達到52,原因就在于《儀禮注疏》與《周禮注疏》這兩部文獻有著兩個相同的注疏人,都是由鄭玄注、賈公彥疏。
5.3文獻的同被引情況和學術地位分析
對《十三經注疏》中“標明出處的典籍引用”情況做統計,結果顯示:被引次數排在前25位被引文獻是:《禮記》、《周禮》、《詩經》、《爾雅》、《儀禮》、《尚書》、《周易》、《左傳》、《說文》、《史記》、《論語》、《釋例》、《公羊傳》、《漢書》、《春秋》、《穀梁傳》、《世本>>、《孝經》、《方言》、《孟子》、《白虎通》、《廣雅》、《國語》、《韓詩》、《字林》。
在十三部注疏文獻中都被引用了的文獻有10部,它們是:《禮記》、《周禮》、《詩經》、《爾雅》、《儀禮》、《尚書》、《周易》、《左傳》、《說文》、《論語》。這十部文獻的被引用次數也很多,在《十三經注疏》中共被引用了20261次,這十部文獻均排在按照被引次數排名的前11位被引文獻中。
把被引文獻按照經、史、子、集等進行分類,我們發現在史書類文獻中被引次數排在前四位的是:《史記》、《漢書》、《世本》和《國語》,可見這四部史書在訓詁研究中有著重要價值。在小學類工具書中被引次數排在前四位的文獻是:《說文》、《方言》、《廣雅》和《字林》,由此可以看出,這四部訓詁專書在中國訓詁學研究中具有重要作用和地位。
6總結
利用結構化的注疏文獻和訓詁學本體解決了引文分析研究中的兩個主要難點,順利完成了引文分析,總結出《十三經注疏》中文獻引用的總體情況,探討了注疏文獻之間的引文耦合情況,并且論述了文獻的同被引情況。
引文分析能夠揭示古籍文獻的知識結構特點,估測古籍文獻之間在知識結構方面的相似程度,評估被引文獻在其所屬類別文獻中的地位。將傳統人文學科與當代信息科學、文獻計量學結合起來,不僅傳承了古籍文獻研究的歷史成果,而且產生了一些新的研究思路和方法,能夠為古籍文獻的同類研究提供參考借鑒。
