基于隔離網閘的異構數據庫同步技術研究與實現
2016-04-29 00:44:03崔恒香馮徑馬瑋駿張慶龐琨余堃
軟件工程 2016年2期
崔恒香 馮徑 馬瑋駿 張慶 龐琨 余堃

摘 要:數據同步是分布式環境中維護各節點數據庫數據一致性的一項關鍵技術。本文針對存在物理隔離網閘的應用環境,提出一種基于觸發器的SQL文件級異構數據庫同步方法,該方法適用于企業異構數據庫同步。文中將闡述隔離網閘環境下異構數據庫同步的工作原理,提出同步系統的總體框架,給出變化捕獲、SQL文件生成、文件傳輸、數據更新和故障處理這五個環節的實現細節。最后通過在洪水預報系統中的實際應用,驗證本文方法的高效性及可靠性。
關鍵詞:數據同步;網閘;異構數據庫;觸發器;SQL
中圖分類號:TP302.7 文獻標識碼:A
1 引言(Introduction)
網絡技術的飛速發展和分布式計算的廣泛應用,大大方便了企業的跨地域發展,許多企業通過不斷重組和分散經營來提高效率,形成了分散、異構的環境特點。這些機構在地域上雖然分散,但在管理上相對集中,往往既要有各機構的局部控制和分散管理,又要求各機構之間的信息能靈活交流和共享,能統一管理和使用[1]。所以對于異構數據庫同步技術的研究是十分有必要的。
絕大多數企業并不是把這些地域上分散的應用數據庫通過直接的傳輸通道進行連接,考慮到網絡傳輸的安全性,往往在傳輸通道上添加物理隔離網閘,將兩者隔離,建立單向連接,來保證信息傳遞的安全。網閘對應用的支持主要是通過對應用協議的剝離和重建來完成的,能夠在保證安全的情況下盡可能支持數據交換,如果不安全則斷開,可以解決數據庫保護所需要的完整性,可用性,保密性,可鑒別和防抵賴等特性,因此被廣泛應用在數據庫保護上[2]。目前,在物理隔離網閘的特定網絡環境下,如何有效地解決異構數據庫間的數據同步問題已成為企業數據庫系統應用的重要環節。
本文在物理隔離網閘的環境下,設計出一種效率高、可靠性強的異構數據庫同步方法,實現企業內外網間的數據同步。
2 相關工作(Related work)
2.1 異構數據庫同步的基本方法
數據同步大致可分為存儲系統層同步、操作系統層同步和數據庫系統層同步[3],本文所涉及的是數據庫系統層同步技術的研究。變化捕獲作為數據庫系統層面數據同步的基礎,直接決定了數據庫的更新方式,其方法包括以下幾種:基于觸發器法、基于快照法、基于日志法、基于API法等。
基于觸發器法是在源數據庫為同步對象創建觸發器,當對同步對象進行增刪改等DML命令時,觸發器被喚醒將變化傳播到目標數據庫;基于日志法是通過分析數據庫日志信息來捕獲同步對象的變化序列;基于快照是指數據庫中存儲對象在某一時刻的即時映像,通過為同步對象定義一個快照或采用類似方法將它的當前映像作為更新副本;基于API法是指在應用程序和數據庫之間引入中間件,由它提供一系列API(例如JDBC驅動程序)這些中間件,在完成應用程序對數據庫修改的同時,也把同步對象的變化序列記錄下來從而達到捕獲的目的[4]。
對于不同數據庫而言,數據庫的體系結構、數據類型、所支持的標準都不盡相同,所以上述幾種方法在實際應用中都有或多或少的缺陷。
2.2 數據庫廠商解決異構數據庫同步的方法
目前學術界對于異構數據庫同步的研究并不夠多。相比之下,產業界對異構數據庫同步研究取得了不少技術成果,其中一些已經得到了廣泛應用,詳見表1。
四大數據庫廠商提出的方案均重點關注異構數據源向自身的數據同步,在實現上也采用與DBMS(DataBase Management System)密切結合的技術,并且具有成本高、實現復雜、缺少靈活性等缺點。設計并實現一種新型的靈活性強、成本小且復雜性較低的異構數據庫同步方法十分有必要。
3 基于觸發器的SQL文件級異構數據庫同步方法
(SQL file level heterogeneous database
synchronization method based on trigger)
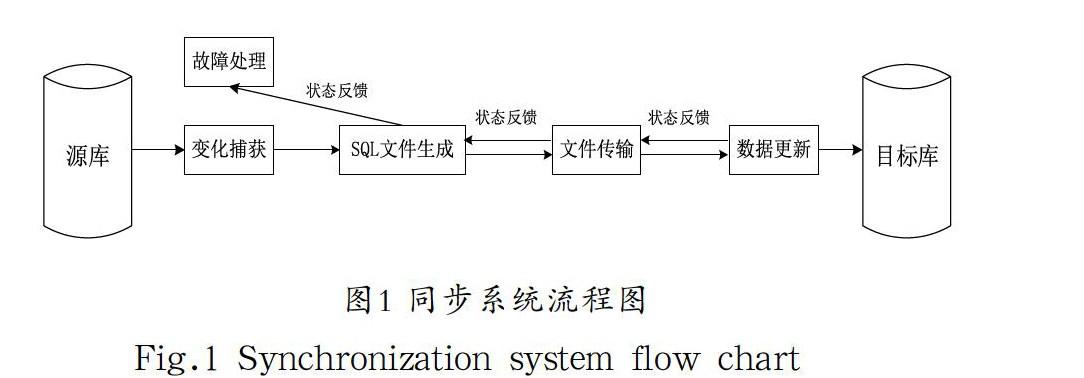
基于觸發器的SQL文件級異構數據庫同步方法的基本思想就是為源數據庫創建觸發器,當源庫數據發生變化時,觸發器在變更表中通過SQL語句的重組記錄目標庫能夠直接執行的SQL語句,然后將SQL語句定時導出到文件,并通過網閘將文件傳輸到目標端,目標庫定時執行SQL文件將源庫中的變更數據更新到目標庫,同時在生成SQL文件、文件傳輸以及數據更新等步驟執行完后將結果狀態向源數據庫端反饋,針對同步過程中出現的不同失敗狀態采取不同措施,以實現整個數據同步過程的故障定位與恢復。
3.1 異構數據庫同步設計方案
整個系統由變化捕獲、SQL文件生成、文件傳輸、數據更新和故障處理五個功能模塊組成。變化捕獲模塊負責以SQL語句記錄變化,SQL文件生成模塊把SQL語句定時導出到數據文件,文件傳輸模塊負責將SQL文件傳輸到目標端,數據更新模塊負責把傳送過來的數據更新到目標數據庫,故障處理模塊將根據各個模塊的狀態反饋,對同步流程中出現的故障點實施針對性的補救措施。下面將對系統主要模塊的實現方法進行詳細闡述,同步系統流程設計如圖1所示。
3.2 各模塊具體設計
3.2.1 基于觸發器的變化捕獲
變化捕獲是捕獲源表的變化序列的過程。觸發器法和日志法是最基本的變化捕獲的方法,目前流行的商用數據庫都提供觸發器機制或日志分析工具。而本文需要在捕獲變化的同時重寫目標庫能執行的SQL語句并記錄下來,因此本方法將采用觸發器法,能夠在觸發器程序塊中編寫重組SQL語句的程序。
基于Oracle觸發器重組SQL語句的基本原理:
Oracle觸發器機制中使用了兩個特殊的臨時駐留內存的關鍵字:New和Old。New用于存儲INSERT和UPDATE操作所影響的行的副本;Old用于存儲DELETE和UPDATE操作所影響的行的副本。當執行INSERT操作時,新建記錄被同時添加到觸發器表和New中;當執行DELETE操作時,記錄從觸發器所在表中刪除,并傳輸到Old中;當執行UPDATE操作時,舊記錄被移到Old中,新紀錄被添加到New和觸發器表中。因此通過獲得Old和New中行的副本再進行重組便能夠得到目標庫可直接執行的SQL語句。
3.2.2 SQL文件生成的方法
上文通過觸發器捕獲變化并將重組后的SQL語句記錄在變更表中,那么只要通過建立操作系統層的定時任務程序對數據庫建立連接按規則獲得變更表中的SQL語句輸出到數據文件,即完成了SQL文件的生成。
基于Oracle的sql*plus工具生成SQL文件的基本原理:
sql*plus是與Oracle進行交互的客戶端工具,通過Spool命令將數據導出到SQL文件是它的主要功能之一,可以通過編寫批處理程序(Windows平臺)登錄sql*plus并執行帶有輸出控制設置的Spool命令的ctl文件,再通過操作系統自帶的定時任務功能定時執行bat文件就可以實現SQL文件的定時導出。
3.2.3 文件傳輸及數據更新
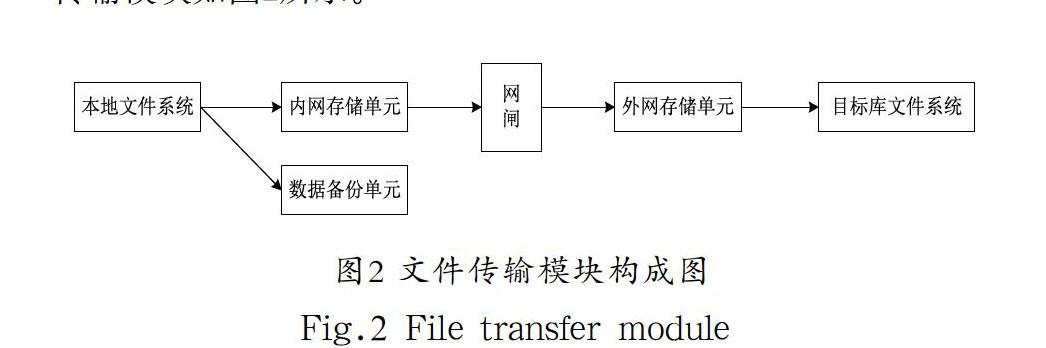
文件傳輸模塊主要包括源庫端、網閘和目標庫端,源庫端定時將生成的SQL數據文件從導出文件目錄移動到網閘的內網存儲單元,同時復制一份存放到數據備份單元,并且在任務執行失敗的情況下向故障處理模塊發送類型為failure的消息文件(用于故障處理模塊進行故障分析);網閘定時將內網存儲單元的SQL文件轉移到外網存儲單元;目標庫端定時將外網存儲單元的SQL文件移到目標庫文件系統,并且在任務執行失敗的情況下向故障處理單元發送類型為failure的消息文件,文件傳輸模塊如圖2所示。
圖2 文件傳輸模塊構成圖
Fig.2 File transfer module
目標庫端同樣創建定時任務,由于目標庫文件系統所存放的就是目標庫可直接執行的SQL文件,通過定時執行SQL文件即能完成數據的同步更新。并且在任務執行失敗時向故障處理單元發送類型為failure的消息文件;同步成功則發送類型為success的消息文件。
3.2.4 基于預先配置策略的故障處理
源庫端根據總結的歷史經驗配置不同failure狀態故障類型的應對措施,故障處理模塊通過讀取同步系統各模塊實時反饋的同步狀態消息文件,根據不同的failure狀態故障類型實施相應的應對的措施,使得故障點恢復運行保證同步系統的正常運行,從而提高數據同步系統的穩定性和可靠性。
4 實際實現與應用(Practical implementation and
application)
實際應用中考慮到現有的軟硬件環境,實現工作主要放在從源端Oracle到目標端Sql Server數據庫業務數據表的數據同步。并根據同步系統各模塊以及主要工作創新點闡述實現與應用。
4.1 變化捕獲的實現
一般的觸發器內部不能夠對INSERT、DELETE、UPDATE分別觸發。由于使用觸發器是為了變化捕獲的高效和靈活,如果為每張表分別建立INSERT、DELETE、UPDATE三個觸發器,這無疑會對數據庫系統的查詢速度、性能帶來影響。因此必須減少觸發器的數量。
4.1.1 優化后的觸發器編寫
解決方法是在源表上只創建一個包含INSERT、DELETE、UPDATE操作的觸發器,本文將觸發器開頭設計為:
觸發器程序內部通過獲取關鍵字Old和New中的行數據副本來判斷具體是INSERT、DELETE還是UPDATE操作。
4.1.2 基于觸發器重組SQL語句解決數據庫異構的問題
因為UPDATE操作原理上就等于一個DELETE操作加上INSERT操作順序執行的,因此通過UPDATE操作來說明會更全面,本文SQL語句重組流程如下:
Step1:Old.colname字符獲取觸發器表UPDATE之前(將被update影響)行的列值;New.colname字符獲取觸發器表UPDATE之后行的列值。
Step2:通過CONCAT函數拼接Delete語句。
Step3:接Insert語句,由于Insert操作涉及表每列值的插入,因此我們必須考慮源庫表中每列與目標異構庫表的數據類型差異以及存在的表結構差異(表結構差異與具體企業業務相關聯)。
本文列舉了數字、字符串、時間等常用數據類型,在Oracle中存儲類型分別為number、varchar2、date;對應SQL Server中為int、varchar、datetime;并且兩表的表結構存在差異:目標端用單個id列存儲源端id、num兩列的連接值。詳見表2和表3。
Part1:解決數據類型的差異,Oracle到SQL Server需把date類型時間轉換成datetime類型:通過將date類型數據轉換為字符串,再將字符串拼接到Cast函數中,其中Cast函數是SQL Server的類型轉換函數。
Part2:解決數據庫表結構的差異,本文主要解決表字段合并操作,因此需要將源端的id和num字段按照順序拼接在一起進行存儲來完成字段值的連接。
Step4:將拼接好的Delete、Insert語句記錄到變更表中,詳見表4。
變更表temptable中sql字段存儲的便是重組后的SQL語句,并且記錄了操作類型和變更時間便于根據不同的策略取得相應的數據。
4.2 SQL文件生成的實現
SQL文件生成主要步驟:配置操作系統定時任務,任務執行對象為bat文件;編寫包含登錄sql*plus且執行Spool命令的bat文件:Path1\sqlplus username/password Path2\filename.ctl,其中,Path1為sql*plus的路徑;Path2為ctl文件的路徑;ctl文件分為輸出控制設置和Spool導出語句兩部分:
Part1:輸出控制設置部分:例如設置每行的長度、腳本中命令執行結果是否顯示、標準輸出每行的拖尾空格是否去除等等設置。
Part2:Spool導出語句部分如下
Spool filepath/filename.sql
//導出SQL文件名稱及位置
Select colname From tablename Where_statement
//導出的內容為查詢結果
根據條件查詢結果按設置導出到文件。4.1中將重組后的SQL語句記錄在表temptable的sql字段,因此此處直接對sql字段內容查詢便實現了源表數據變更對應SQL的導出。
Spool命令的優化:一方面,在導出SQL語句的同時添加刪除已導出數據的delete語句,實時刪除臨時變更表冗余的數據,減少對系統資源的過多占用,達到優化性能的效果;另一方面,Spool導出命令中通過獲取臨時變更表最新記錄時間MaxInsertTime,在取數據的select語句和刪除數據的delete語句where條件中均添加變更時間小于等于MaxInsertTime的條件,在導出MaxInsertTime時間點之前的數據同時刪除的也保持一致,這樣做的好處相比直接select、delete表的所有數據,避免了在取完數據后刪除數據之前剛好有數據插入表中所帶來的數據誤刪。
4.3 SQL文件的傳輸與執行以及相關的故障處理
SQL文件的傳輸模塊主要靠物理隔離網閘進行源端到目標端的搬運,以及移動文件和生成反饋狀態文件的程序。目標端SQL文件執行模塊同樣是配置定時任務來完成,本文目標端為SQL Server庫,那么通過定時任務打開cmd.exe執行語句:osql-S127.0.0.1-Usa-Psa-ipath\filename.sql便可完成數據的更新,其中osql為SQL Server的命令行工具,-i表示要執行SQL文件路徑。
當同步過程中某模塊出現故障時會向故障處理模塊發送消息文件,故障處理模塊通過讀取文件中故障類型,根據故障類型從策略表獲取應對策略,并向發生故障的模塊發送應對策略指令使其實施相應的措施恢復運行,從而提高數據同步系統的穩定性和可靠性。策略表預先配置,詳見表5。
4.4 實際應用
本文的“基于觸發器的SQL文件級同步法”已經成功地應用于某地區洪水預報系統中。該系統包括內、外兩個網絡,內網是一個水流量信息采集系統;外網是一個B/S架構洪水預報信息系統,提供洪水預報的計算處理與查詢。由于內、外網兩個應用系統的數據分別放置于不同的數據庫上,因此為了保持內、外網兩個數據庫的一致性,須將內網的數據及時地同步到外網,并且需要考慮數據傳輸的安全性,這就是一個典型的基于網閘的異構數據庫間數據同步的問題。
運行結果表明,隨著記錄數的增長,“基于觸發器的SQL文件級同步法”的時間復雜度呈線性增長,空間復雜度主要為內存消耗,基本上保持常量,因而總體性能比較理想,并且相對于原先系統采用的“基于API的傳統輪詢同步法”,效率提高明顯,可靠性、穩定性都得到了保障。
5 結論(Conclusion)
本文針對物理網絡隔離的應用環境,提出了一種“基于觸發器的SQL文件級同步法”適合于企業數據同步。該方法運用觸發器對源數據庫變化進行捕獲,并轉換成目標庫可直接執行的SQL語句記錄下來且定時導出到數據文件,通過執行數據文件更新目標數據庫,從而達到數據同步。該方法具有適應異構系統、效率高、可靠性強、穩定性佳的特點。
參考文獻(References)
[1] 鄭海明.基于SQL還原法的異構數據庫同步技術的研究與實
現[J].計算機時代,2008(10):15-18.
[2] 張暉,歐陽慎.基于oracle的跨網閘數據同步方案研究[R].鄭州
鐵路局“十百千”人才培育助推工程論文集,會議時間:2011.
[3] 王新偉.基于Oracle數據庫的邏輯數據同步技術在實踐中的
應用研究[J].電子技術與軟件工程,2015(08):195-198.
[4] 張大朋,陳馳,徐震.異構數據庫復制技術的研究與實現[J].中
國科學院研究生院學報,2012(01):101-108.
作者簡介:
崔恒香(1987-),男,碩士,學生.研究領域:信息與系統
集成.
馮 徑(1962-),女,博士,教授.研究領域:系統集成與
應用.
馬瑋駿(1980-),男,博士,講師.研究領域:系統集成與
應用.
張 慶(1978-),男,本科,工程師.研究領域:信息工程.
龐 琨(1980-),男,碩士,工程師.研究領域:信息與系統
集成.
余 堃(1983-),男,碩士,工程師.研究領域:信息與系統
集成.
