基于Python的動態網頁評價爬蟲算法
2016-04-29 00:44:03夏火松李保國
軟件工程 2016年2期
夏火松 李保國


摘 要:在大數據獲取中面臨著如何采集動態評論網頁的問題,這篇論文使用靜態網頁信息構造動態鏈接,提出了基于Python的動態網頁評論爬蟲算法。在此基礎上實現了評論收集程序。最后將它與通用爬蟲算法進行比較,證實了該算法具有針對性強、數據采集速度快、易嵌入開發、簡單等優點,為不善于編程的新聞、文學、管理等學科的研究者提供了快速獲取評論信息的方法。
關鍵詞:Python語言;靜態地址;動態鏈接;動態網頁評論;爬蟲算法
中圖分類號:TP312 文獻標識碼:A
1 引言(Introduction)
大數據具有數據體量巨大(Volume)、數據類型繁多(Variety)、價值密度低(Value)、處理速度快(Velocity)的特點。在大數據獲取中面臨的一個數據源問題為:如何獲取大量的動態評論數據?Python是一門獨立的語言,可以直接操作數據庫,便于對大規模數據的操作與分析[1]。而且,由于Python包含結巴分詞等程序包,可以直接進行分詞,適宜于自然語言處理[2]。
現在很多網頁通過Ajax動態請求、異步刷新生成數據[3]。Python由于先天局限,它爬取靜態網頁的方法難于直接提取動態網頁。而爬取動態網頁的方法雖然有很多,但便于新聞學、語言學、管理等學科的研究者應用的方法卻很少。所以這篇論文研究如何用Python語言爬取Ajax動態生成的評論數據。
這篇論文延續前人的方法,通過靜態網址信息構造動態鏈接,并增加了翻頁的部分,把各種商品、新聞、社交網站、TV等動態網頁評論的爬取方法歸結為一套抽象的爬蟲算法流程圖。在此基礎上實現了商品評論收集程序[4]。本文為實時評價數據采集技術的研究提供了新路徑[5]。
2 基于Python的爬蟲算法 (Reptiles algorithms
based on Python)
網絡爬蟲即數據采集程序。主要有搜索引擎網絡爬蟲[6]、基于Agent的網絡爬蟲、遷移的網絡爬蟲、通用網絡爬蟲和聚焦爬蟲等。其中聚焦爬蟲是一種主題網絡爬蟲,它圍繞主題內容采集數據。
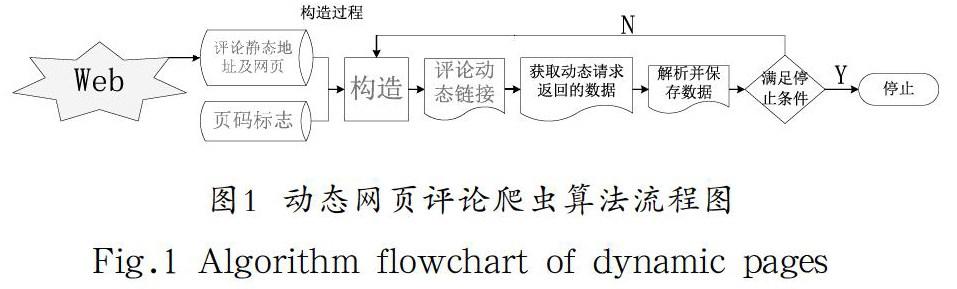
靜態網頁是指不應用程序而直接或間接制作成Html的網頁,每一個頁面都有一個固定的URL地址,這個URL和相應的Html可以通過Python直接獲取。動態網頁一般使用腳本語言(Php、Asp等)將網站內容存于數據庫中,相應URL動態鏈接不可以通過Python獲取。但是動態URL的變化部分一般可以在相關靜態URL及源代碼中尋找,所以這篇論文在前人的基礎上,利用靜態的URL地址和相應的網頁源代碼構造動態鏈接,從而實現了Python直接對動態網頁的爬取。本研究在前人基礎上,通過對各主流商品、新聞、社交網站、TV等動態網頁評論分析,提出了基于Python的動態網頁爬蟲算法流程圖,如圖1所示。
3 相關操作與爬蟲程序(Operation and Reptiles
procedure)
為顧及新聞、管理等的學科的研究者,相關操作比較詳細。工具:使用Chrome瀏覽器的開發人員工具或火狐瀏覽器的Firebug插件,這篇論文以Firebug插件為例[7]。首先安裝火狐瀏覽器,版本為40.0,并裝上Firebug,版本為2.0.13。程序以商品評論為例,具體分五步。
3.1 靜態URL構造動態URL
(1)提取某個商品的靜態URL網址
該文以商品為例,用瀏覽器打開某個商品的頁面,復制地址欄網址如①所示。
http://item.jd.com/492036.html①
(2)提取對應評論頁的靜態URL
a.單擊“商品評價”;b.復制地址欄的網址如②所示。
http://item.jd.com/492036.html#comment②
(3)提取含有評論數據的Ajax動態鏈接
這里總結前人獲取評論動態鏈接的方法如下:a.用火狐瀏覽器在評論頁空白部分,右鍵——使用Firebug查看元素,打開“Firebug工作面板”;b.點擊工具面板上的“網絡”;c.其子菜單默認在“全部”處;d.單擊工作面板左上角的“清除”,以清除已有請求;e.在瀏覽器窗口中,點擊評論第二頁的圖標;f.在“Firebug工作面板”上,右擊"GET p-492036-……"這個動態請求,然后點擊“復制地址”;其中,選定"GET p-492036-……"這個請求的原因為:這個請求的“響應”含有評論數據;g.粘貼這個“第二頁”評論的動態地址如③所示。
http://club.jd.com/productpage/p-492036-s-0-t-3-p-1.html?callback=fetchJSON_comment98vv216③
通過動態網址③就可以得到第2頁的評論。獲取動態鏈接的操作如圖2所示。
動態網址③含有一些時間戳等無用部分,可以進行適當的簡化。簡化方法為:將網址③粘貼到瀏覽器地址欄,在保證網頁結果保留JSON格式信息的前提下,按照分隔符逐個刪除,直到最簡,如④所示。
http://club.jd.com/productpage/p-492036-s-0-t-3-p-1.html④
(4)提取存儲評論數據的另一頁的Ajax動態鏈接
操作和3.1的第3節相同,但是,在其中的第5部分,應該點擊評論的第三頁。最后得到第三頁評論的動態網址,并簡化如⑤所示。
http://club.jd.com/productpage/p-492036-s-0-t-3-p-2.html⑤
(5)提取另外一個商品的已簡化的Ajax動態鏈接如⑥所示
http://club.jd.com/productpage/p-1298665-s-0-t-3-p-1.html⑥
(6)根據靜態網頁信息構造Ajax動態鏈接
分析④⑤⑥動態網址的變化部分,找出組成結構如⑦所示
http://club.jd.com/productpage/p-+商品ID+-s-0-t-3-p-+頁碼標識+.html⑦
“商品ID”唯一標識了這個商品,“頁碼標識”表示不同的頁碼。在Ajax動態鏈接的組成結構中,對于變化部分,一般可以在靜態網址①②以及由①②所得到網頁的源代碼中尋找,其中獲取源代碼方法:網頁空白處右鍵單擊——查看網頁源代碼。而對于這個網站,“商品ID”可以由靜態網址①得到,“頁碼標識”一般為1…N的自然數。這樣就可以由商品的靜態網址及網頁數據構造出評論的動態鏈接,從而爬取評論信息。
一般在一種網站中,不同商品對應的評論頁動態網址⑦的格式是相同的。所以可以選擇某一個商品的動態評論網址,設置為標準動態網址(comment_Norm),為方便起見,這篇論文把網址④設置為comment_Norm。這樣,對于任意一種商品,把comment_Norm的商品ID置換為本商品的ID,就可以得到這個商品的動態網址;置換頁數,可以得到2…N頁的動態網址(commentsUrl),因為第1頁的動態網址不易獲取,所以從第2頁開始爬取。
3.2 獲取該Ajax請求返回的Json數據
用requests的get/post方法(或urllib、urllib2、beautifuSoup等)發送請求并接收數據:content=requests.get(comments_Url).content。用正則表達式提取標準數據:content='{'+re.findall(r"{(.+)}",content)[0]+'}'。然后轉換為Json庫函數可以處理的字典格式:dict=json.loads(content,"gbk"),其中“gbk”為這個網頁的數據編碼方式,Python默認編碼方式為“Ascii”,當網站編碼方式也為“Ascii”時,直接用json.loads(content)。
3.3 解析Json數據并保存結果
(1)解析Json數據
使用Python IDE即PyCharm解析Json數據,PyCharm版本4.0.5,python版本2.7.10。操作為:a.在dict=json.loads(content,"gbk")這句設置斷點;b.點擊“Debug/綠色甲蟲”圖標;c.點擊“Step Over”;d.在“Variables”中右擊“dict”變量;e.左鍵單擊“add to watches”;f.在“Watches”窗口中點擊“dict”變量前的三角符號,就得到了dict的樹狀結構。操作如圖3所示。
也可以使用一般瀏覽器的“FeHelper”插件解析Json數據,“FeHelper”插件版本v7.5。操作:把3.1的第3節的第6部分的“Response/響應”復制粘貼到FeHelper的“Json串格式化”的窗口中,單擊格式化。也可以直接用Firebug插件,操作:在在3.1的第3節的第6部分,點擊含有評論數據的響應——單擊“JSON”按鈕。在“JSON”內,即為Json數據的樹狀結構,如圖2所示。
(2)尋找評論路徑
dict['comments'][j]['content']即為評論,j為0-9自然數。
(3)保存結果
用easy_install或者是pip安裝相應python包,以及安裝對應的數據庫軟件。結果可以保存到mysql[8]、csv、excel、mongodb等數據庫中。
3.4 停止條件
一般通過評論總頁數判斷,可以直接看有多少頁(京東商城、國美在線等);或則用評論總數除以每頁個數得到總頁碼(天貓網、淘寶網、當當網、亞馬遜卓越網、蘇寧易購等)。或通過判斷動態鏈接請求的返回值是否為空作為停止條件。
3.5 程序及結果
最后構造程序如圖4所示。
3.6 特殊情況
(1)自動獲取停止爬取的標志
一般需要從含有評論數據的動態網頁或其他動態網頁中尋找相關數據。a.通過評論總頁數:例如淘寶網,dict['maxPage']即為總頁數。b.通過評論總數:例如京東商城的dict['productCommentSummary']['commentCount']為評論總個數,再除以每頁的個數,即得到總頁數。c.通過停止標志:例如騰訊TV、騰訊新聞。它們的停止標志為dict['data']['hasnext'],該值如果為false,則應停止爬取。
(2)頁碼標志符不是自然數
標志符一般需要從相關動態網頁中尋找。例如騰訊新聞、TV。首先選取某個新聞,提取第一頁已簡化的動態評論網址如⑧所示,提取第二頁的如⑨所示,動態網址的結構見⑩。
http://coral.qq.com/article/1267477591/comment?commentid=0&reqnum=10⑧
http://coral.qq.com/article/1267477591/comment?commentid=6081308797779398298&reqnum=20⑨
http://coral.qq.com/article/+新聞ID+/comment?commentid=+pageID+&reqnum=+rNUM⑩
“新聞ID”從評論頁靜態網址中提取;第1頁評論動態網頁的“rNUM”為10,第2…N頁的“rNUM”為20;第1頁的“pageID”為固定值“0”,其他頁的“pageID”從前一頁的動態網頁中找,其中pageID=dict['last']。以此類推,這樣就可以得到第1…N頁的動態網址了。
其中第一頁動態網址的獲取方法為:進入評論頁,打開“Firebug工作面板”,單擊“清除”,然后刷新頁面,在請求中逐個尋找。存儲評論的請求一般包含在“網絡”子菜單的JavaScript或XHR中,可以直接在這里找。
(3)遵守robot協議
在爬取數據的過程中,應嚴格遵守網絡協議規定,經測試,6秒對服務器發起一次請求較為合適。用time.sleep(6)來控制速度。
(4)應對防爬蟲方法
a.表頭信息:對于一些網站需要表頭信息,程序為:content=requests.get(comments_Url,headers=header).content。其中的comments_Url為存儲評論信息的動態網址。Header為表頭信息,獲取方法為:在3.1的第3節的第6部分點擊任意一個請求—頭信息—請求頭信息—“User-Agent”。b.cookie:對于一些需要登錄信息的網站,例如新浪/騰訊微博、twitter、QQ空間、Facebook、朋友網、人人網、網頁版微信/來往等,需要Cookie信息。程序為:content=requests.get(comments_Url,cookies=cook).content。Cookie的獲取方法為:先用瀏覽器登錄賬號,在3.1的第3節的第6部分點擊含有評論信息的請求—頭信息—請求頭信息—Cookie。c.Form Data(表單數據):例如鳳凰新聞、TV評論,由評論頁動態網址并不能得到評論數據,還得加入Form Data,而且通過更改表單數據中'p'的值來翻頁。程序如下:
comments_Url='http://comment.ifeng.com/get?job=1&order=DESC&orderBy=create_time&format=json&pagesize=20'
data={'p':'1','docurl':'http://news.ifeng.com/a/20151121/46335318_0.shtml'}
content=requests.post(comments_Url,data=data).content
data為表單數據的信息。獲取方法為:在3.1的第3節的第6部分點擊含有評論信息的請求—Post—參數。
(5)其他
環球新聞用content=re.findall(r"comment_list\((.+)\);",content)[0]語句提取標準Json數據。新浪、騰訊等網站,評論不分頁顯示,“加載更多/加載更多評論”按鈕相當于第2…N頁。優酷TV,動態鏈接返回Html。用正則表達式提取評論信息。對評論部分的字符串(例如:comment="\u559c\u6b22\u59ae"),用comment=comment.decode("unicode-escape")進行反編碼后得到對應漢字。
4 對比分析(Comparative analysis)
該研究把本文所設計的爬蟲與目前應用廣泛的通用爬蟲比較:通用爬蟲以集搜客和網絡神采為例。網絡神采通用性最強(采集瀏覽器看到的),采集內容范圍廣(支持登錄、跨層、POST、腳本、動態網頁),但需要設置許多參數;基于Python的動態網頁評論爬蟲專門針對評論,而且爬取過程不依賴于瀏覽器,因此其效率比集搜客和網絡神采快些。在復雜度方面,網絡神采考慮的因素比較全面,所以比評論爬蟲算法復雜得多;而集搜客,基本不用編寫程序,甚至直接使用現成的采集規則。網絡神采擴展性強(支持存儲過程、插件、二次開發),集搜客可以導入excel,而Python可操作各種DB。三種爬蟲對比分析詳見表2。
5 結論(Conclusion)
研究在前人的基礎上,設計了基于Python的商品、新聞、社交網站、TV評論聚焦爬蟲算法。以此為基礎,實現了商品評論的收集程序。基于Python的評論爬蟲具有一定的高效性、通用性、實時性,所以可以作為實時商品、新聞、社交網站、TV評論采集算法;這種算法基于自然語言處理能力強的Python語言,利于對評論文本的后續分析以及相應爬蟲軟件[9]的開發。而且這種爬蟲比較簡單,可以被計算機基礎弱的評論挖掘研究者使用。
參考文獻(References)
[1] 彭磊,李先國.大數據量Excel數據導入系統的設計與實現[J].
計算機應用技術,2014(14):57-59.
[2] 吳宏洲.分詞技術的研究與應用——一種抽取新詞的簡便方
法[J].軟件工程師,2015,18(12):64-68.
[3] 王佳.支持Ajax技術的主題網絡爬蟲系統研究與實現[D].北
京:北京交通大學,2011:22-27.
[4] 方美玉,鄭小林,陳德人.商品評論聚焦爬蟲算法設計與實現
[J].吉林大學學報(工學版),2012(S1):377-381.
[5] 陳國良.基于商品評論信息的特征挖掘[J].福建電腦,2015(05):
106-107.
[6] 劉典型.基于概念聚類的Web數據挖掘搜索引擎的設計與實
現[J].軟件工程師,2015,18(5):18-20.
[7] Winterto1990.python爬取ajax動態生成的數據以抓取淘寶
評論為例子[EB/OL].[2015-08-26]http://www.th7.cn/web/
ajax/201508/117293.shtml.
[8] 陳瀟.SQL Server2008數據庫存儲過程的應用[J].軟件工程師.
2015,18(6):18-19.
[9] 劉正春.基于Carbide.C++的Symbian OS軟件開發[J].電腦與
電信,2009(01):47-49.
作者簡介:
夏火松(1964-),男,博士,教授.研究領域:決策支持系統.
李保國(1990-),男,研究生.研究領域:信息管理.
