一個基于社區相似度分析的物流網絡優化算法
2016-05-14 12:41:40于蕾吳強
現代電子技術 2016年6期
關鍵詞:優化算法
于蕾 吳強
摘 要: 隨著物流網絡的快速擴張,如何在異構系統中交換物品信息已經成為影響物流效率的重要因素,而社交網絡與物流網絡都具有異構的特征,因此將物流網的各個節點看作是社交網絡的社區,利用多關系社交網絡社區挖掘算法來尋找各個異構的物流網絡中固有的社區結構,從而發現物流網中隱藏的規律并進行路徑優化等網絡行為是可行的。通過對4 000例物流數據的對比試驗,得出基于相似度的社區挖掘算法在準確率、算法復雜度和效率上都優于K均值算法和回歸算法。
關鍵詞: 社區挖掘; 物流網絡; 相似度分析; 優化算法
中圖分類號: TN711?34 文獻標識碼: A 文章編號: 1004?373X(2016)06?0045?04
A logistics network optimization algorithm based on community similarity analysis
YU Lei, WU Qiang
(Xian University of Technology, Xian 710048, China)
Abstract: With the rapid expansion of logistics network, how to exchange the information of goods in heterogeneous systems has become an important factor affecting the efficiency of logistics. However, both social network and logistics network have a same heteroid feature: heterogeneity. Therefore, it is entirely feasible to find out the hidden law of logistics network and optimizing route by using the intrinsic community structure of each heteroid logistics network, which is calculated by a community mining algorithm of multi?relation social network. The contrast test result of 4000 logistics data from three different algorithms shows that the community mining algorithm based on similarity is better than K?mean algorithm and regression?based algorithm in accuracy rate, complexity and efficiency.
Keywords: community mining; logistics network; similarity analysis; optimization algorithm
目前,對于物流網絡設計的研究分為三個層次:策略、戰術和運作[1]。策略和戰術研究主要是為供應商解決貨物儲備的決策問題,如倉庫大小和位置、貨物價格和數量以及組織一個高效、低成本的物流網絡。總之,物流網絡的建立和優化,需要考慮四個層次的內容:物流中的選址[2]、對客戶的聚類[3]、配送區域劃分[4]和車輛調度[5]。一些學者將復雜網絡理論應用在物流網上,試圖解決區域選址問題[4]。一些學者利用遺傳算法建立染色體表達式解決車輛調度問題(Vehicle Scheduling Problem,VSP)[6?7]。
而物流網中普遍存在物流效率低、成本高、大量的異構系統不能順暢交換數據等問題。在物流網中,如何準確獲取物品信息、如何在異構系統中交換物品信息,已經成為近幾年物流網絡研究的熱點。本文提出一種基于相似度的社區挖掘算法,將物流網的各個節點看作是社交網絡(Social Networks)的社區,社區結構可能各不相同,物品是隸屬于不同社區的成員(意味著,不同物流節點的信息組成是異構的)。通過社區挖掘尋找各個異構的物流網絡中固有的社區結構,從而發現物流網中隱藏的規律并進行路徑優化等網絡行為。
1 相關工作
對物流中所涉及到的數據,建立一個適用于物流的地理社會網絡,通過分析和處理,優化物流流程,提高物流效率。物流的產生和發展的原因在于沒有將時間、空間以及人這三者關系結合起來,地理社會網絡可以實現時間、地點與人三者關系的疊加處理[8]。因此,將地理社會網絡與物流信息平臺相結合,關注用戶與系統、用戶與用戶間關系,讓用戶作為系統的一個節點,有效地參與并發布數據;結合地理社會網絡,消除信息之間的孤立等研究具有一定的研究價值和實際意義。
1.1 物流網關系模型
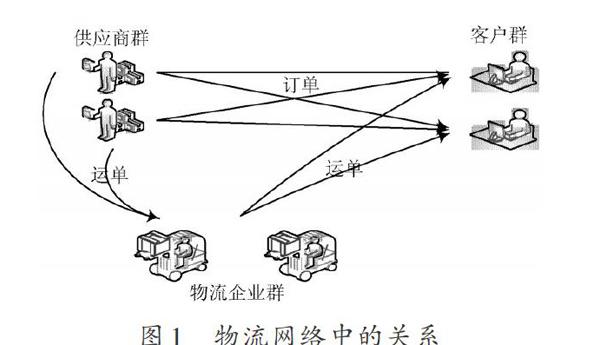
物流關系:一個物流網絡可以用一張圖來表示,如圖1所示。供應商、客戶、物流企業對應圖中的節點,每個節點擁有自己的屬性,包括身份,公司,車隊等;邊代表節點之間的關系,包括買賣關系,合作關系等。用一個無向圖來表示這樣的網絡,Nsocial =(P,C,T),P是代表一組供應商用戶的節點集合;C代表一組客戶用戶的節點集合;T代表物流企業,T包含于P×C的笛卡爾乘積中,是無向圖中的邊的集合。一條邊(p1,c2)屬于T,表示p1,c2這兩個的關系。
對物流網絡進一步抽象,用連通的無向圖G=(V,E)來表示,節點集V表示物流網絡中個體(既可以是供應商也可以是消費者客戶)的集合,V={v_1,v_2,…,v_n},邊集合E表示網絡中供應商或者消費者之間的關系,E={e_1,e_2,…,e_m}。
這樣,物流中的每類關系都可以對應出一個子圖Gj=(Vj,Ej),j=l,2,…,k,k≥2,Vj表示該子圖中供應商的集合;Ej表示子圖中供應商之間關系的集合。在圖G中,邊E上是有標有權重的,供應商之間關系的緊密程度是通過權重來體現的,權值的計算是根據計算供應商之間的標記數目得到的。所以,在構建子圖Gj=(Vj,Ej)所對應的關系矩陣Rj時,需要計算邊上的權值,同樣,通過計算物流網絡中供應商之間的標記數,得到個體邊上的權重,用如下公式進行計算:
[Rjxy=1, x和y具有相同標記0, x和y不具有相同標記]
其中[x,y∈Vj,]表示在物流子圖Gj中存在的兩個供應商x,y,假設x和y具有3個相同的標記,則[Rjxy]為3,是通過這種方式進行計算物流網絡中所有邊上的權值的。對于關系矩陣Rj,j=1,2,…,k,k≥2,通過除以物流網絡中邊上的最大權值作歸一化處理,使得所有的邊上的權重值在范圍[0,1]內。因為Rj是一個對稱矩陣,所以可以采用一個向量表示它。
1.2 物流網絡中的社區
一個社區可以簡單地定義成享有一些共同屬性的一群對象的集合,這個共同屬性就是對象之間的關系。例如,給出一個用戶的一組選擇[P={p1,p2,…,pk}],構建出相應的關系矩陣RP,關系矩陣RP是一個對稱矩陣;然后,找出最能匹配選擇關系向量的已有關系的線性組合,根據得到的關系組合,來挖掘符合用戶需求的社區。
這些關系矩陣具有如下的屬性:
頻率:[f(xj)=xjn],表示社會網絡中供應商[xj]在關系[Rj]中所對應的標記占關系[Rj]中的有對象對應的標記的百分比,其中[xj]表示對象[xj]在關系[Rj]中所對應的標記數;n為關系[Rj]中所有對象對應的標記總和。若[xj]在關系[Rj]所對應標記中出現的次數越多,則[f(xj)]值越大,表示[xj]在關系[Rj]中與其他個體之間的聯系越緊密。
重要性:[I(xj)=Nxj],表示供應商[xj]在整個網絡中的一個重要參數,式中的N表示整個物流網絡中所有物流個體對應的標記總數目,[xj]表示對象[xj]在整個網絡中對應的標記總數。若[xj]對應標記在整個網絡中出現的次數越多,則[I(xj)] 的值就越小。
次序值:[RV(xj)=f(xj)I(xj)],由頻率與重要性的定義可知,若對象[xj]所對應標記總數在社會網絡中出現的次數越多,并且在某一關系中出現次數越多,則對象[xj]的次序值就越大。若以這樣的[xj]作為一組選擇實例,則在網絡中,次序值越大的關系就更可能符合用戶的需求。
綜合次序值:整個網絡中某關系中的次序值。[j=1kRV(xj)]表示用戶選擇[P={p1,p2,…,pk}],在整個網絡某關系中的次序值。
1.3 基于相似度的社區挖掘算法
進行用戶推薦,需要了解客戶的購買行為。可以通過大量的訂單的信息來了解,因為訂單信息一般包含客戶的編號、物品名稱、數量、時間等信息;然后根據不同用戶提取相關數據并調用推薦算法,最后找出1~3個供應商作為結果展現給用戶。
對于兩位用戶,當他們在物流信息平臺上購買物品,選取的物流公司相同,則認為兩位用戶有一定的相似性;假如兩位用戶同時都在物流服務平臺上購買相同的物品并且選取的物流公司也相同,可以認為這兩位用戶在選取物流公司的相似度較高;假如兩位用戶同時都在物流服務平臺上購買相同的物品并且選取的物流公司也相同,而且兩位用戶在同一個區域,認為這兩位用戶在選取物流公司的相似度更高。
在物流社交網絡中,用戶每一次下單行為可以稱作一個購買興趣點(Purchase of interest,PI)。PI庫中都會記錄每一個PI的供應商、物品名稱、發貨地、送貨地、送貨方式(物流公司名稱),即PI=(P,N,O,D,T)。在物流過程中,經常會涉及到訂單,需要對訂單進行定義。這樣,每一個訂單都會有供應商、物品名稱、發貨地、送貨地、物流公司名稱,即Order=(ProviderName,GoodsName,Origin,Destination,LogisticsCompanyName)。n個訂單可以看成[n×5] 的矩陣:
[On×5=O11O12…O15???Oi1Oi2…Oi5????On1On2…On5]
首先,給出一個連通的無向圖G(V,E),|V|=M,代表物流網絡中的有M個物流個體,確切地說是M個供應商;E代表個體之間的關系。并對其對應的關系向量[R1,R2,…,Rn]作標準化處理。
其次,物流社會網絡中物流個體間存在著各種關系,每種關系都可以映射為一個關系圖,因此一個社會網絡映射出多個關系圖,[G1,G2,…,Gn],并根據用戶的選擇信息,由次序值公式:[RV(xj)=f(xj)I(xj)]計算綜合次序值[j=1kRV(xj)],然后重新排序關系,其中N表示關系的種類數目。
最后,選擇次序值高于一定閾值t的關系,在此關系基礎上,調用基于回歸的多關系抽取算法,求出組合系數:[R=a1R1′+a2R2′+…+anRn′],其中[a1,a2,…,an]為對應關系的組合系數,得到一組關系組合[R1′,R2′…,Rn′] ,調用K?means算法,得到K個聚類,即挖掘出k個社區。
該算法偽代碼如下所示:
2 實驗及分析
本實驗使用4 000個訂單數據集進行實驗,把這個數據集看作一個物流網絡,供應商視為網絡中的對象,供應商使用不同的物流公司配送物品視作一種關系,因為10個物流公司,則至多有10種不同關系,那么這個數據集就是一個多關系社會網絡。本實驗就是在其上研究供應商的內在的關系,對供應商社區進行挖掘。
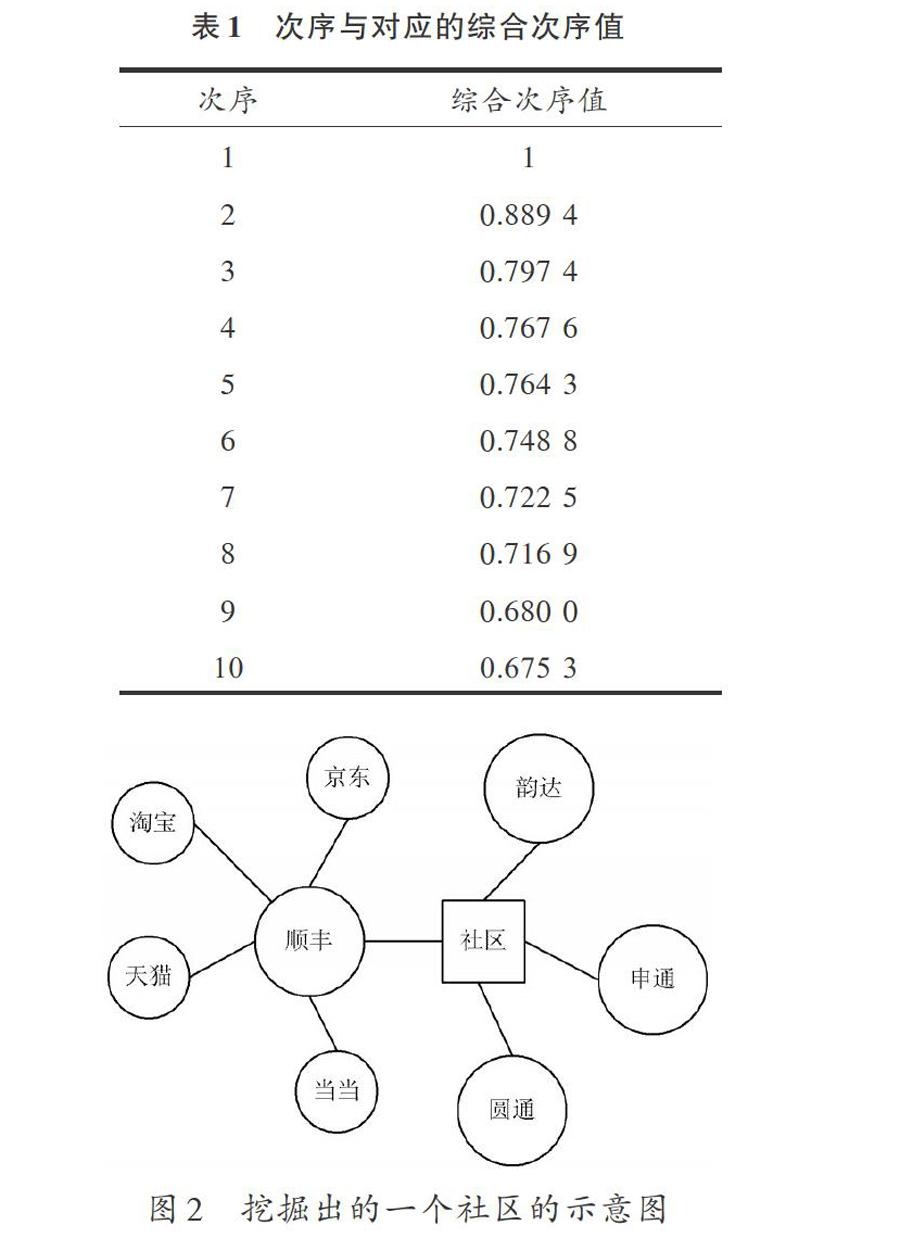
首先構建關系圖,把供應商視為節點,標記數初始值為0,如果有兩個供應商使用同一個物流公司配送物品,則他們的標記數加l,否則不變;然后生成關系圖,每一個物流公司生成一個關系圖,對每個物流公司,將數據相加獲得該物流公司的供應商關系圖。這種關系圖反映了供應商在配送某一類物品時的相似度,相似度越高,說明他們之間的具有共同喜好的可能性越大。一般來說,如果兩個供應商在某一圖中邊的權值較大,就說明他們有著相似或者相同的物品或物流公司,也說明他們的相似度更高。最后,對于每一個關系圖,需要進行歸一化權值,可以采用他們的權值除以整個網絡關系圖中的最大權值的方式來處理,權值結果都在區間[0,l]內。本實驗選取了配送物品較多的物流公司構建了關系圖。所有供應商的綜合次序值的計算結果如表1所示。
當選擇淘寶、京東、天貓,閾值t為10時,綜合次序值對應的是表1中的第4,9,10次序;抽取的關系組合系數分別為:
[R=0.736R1′+0.265R2′+0.182R3′+0.139R4′+0.092R5′+ 0.061R6′+0.043R7′+0.021R8′+0.019R9′+0.006R10′]
由上式可以看出,當選擇淘寶、京東和天貓這幾個供應商和物流公司[R1′](順豐)的關系最密切,換言之,淘寶、京東和天貓與順豐的業務合作比較多。最終,通過聚類,得到一個社區,該社區如圖2所示。
從圖2中可以看出,這個社區中的供應商有一個共同的特點,那就是他們的客戶主要是個人,而不是企業。他們使用的物流公司大都是一些快遞公司。因為這些快遞公司的費用較低,速度快等特點,淘寶是最典型的例子。進而得到一個供應商和客戶的關系,該社區的供應商大多數業務是面向個人用戶的。
同樣的,當用戶選擇當當、TCL、索尼,閾值t為10時,綜合次序值對應的是表1中的第1,2,3次序;抽取的關系組合系數分別為:
[R=0.636R1′+0.565R2′+0.532R3′+0.458R4′+0.394R5′+ 0.138R6′+0.119R7′+0.095R8′+0.062R9′+0.027R10′]
由上式可以看出,當選擇當當、TCL和索尼這幾個供應商和物流公司[R1′](順豐)[R2′](中國外運(集團)總公司)[R3′] (EMS)[R4′] (中遠國際貨運有限公司)[R5′](德邦物流)的關系比較密切;最終,通過聚類,得到2個社區,如圖3所示。從圖3中可以看出,社區1中的供應商的共同特點是他們的客戶主要是個人。他們使用的物流公司大都是一些快遞公司,使用最多的是順豐快遞和EMS。此社區中的供應商大多數業務是面向個人用戶的。社區2中的供應商的共同特點是他們的客戶主要是企業。他們使用的物流公司大都是一些貨運代理公司,如中國外運(集團)總公司、中遠國際貨運有限公司、德邦物流等。此社區中的供應商大多數業務是面向企業用戶的。
3 結 語
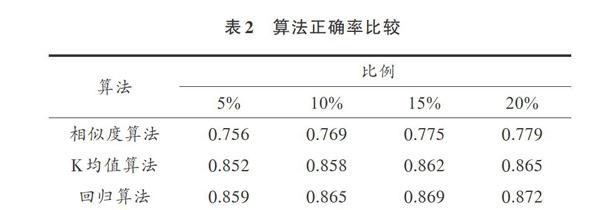
傳統K均值數據挖掘算法的好處是不需要進行關系選擇和抽取,但是其結果會隨著選取實例比率的不同在一個而上下浮動。針對實驗中的4 000個訂單數據,分別使用K均值算法[9]、回歸算法[10]和相似度挖掘算法在選擇實例的比例為5%,10%,15%和20%下得出的挖掘正確率如表2所示。
表2 算法正確率比較
經過實驗驗證,在關系數恒定的情況下,相似度算法的正確率會隨著用戶選定實例比率的提高而提高,且明顯要好于傳統K均值挖掘算法,略微高于基于線性回歸的多關系抽取算法。
參考文獻
[1] SHANKAR L B, BASAVARAJAPPA S, CHEN J C H, et al. Location and allocation decisions for multi?echelon supply chain network: a multi?objective evolutionary approach [J]. Expert systems with applications, 2013, 40: 551?562.
[2] WANG Y, MA X L, WANG Y H, et al. Location optimization of multiple distribution centers under fuzzy environment [J]. Journal of Zhejiang University (Science A), 2012, 13(10): 782?798.
[3] MIRANDA P A, GARRIDO R A, CERONI J A. E?work based collaborative optimization approach for strategic network design problem [J]. Computer & industrial engineering, 2009, 57(1): 3?13.
[4] IYOOB I M, KUTANOGLU E. Inventory sharing in integrated network design and inventory optimization with low?demand parts [J]. European journal of operational research, 2013, 224: 497?506.
[5] CHOPRA S, MEINDL P. Supply Chain management: strategy, planning and operation [M]. 3rd ed. [S.l.]: Pearson Prentice Hall, 2007.
[6] KO H J, EVANS G W. A genetic algorithm?based heuristic for the dynamic integrated forward/reverse logistics network for 3PLs [J]. Computers & operations research, 2007, 34: 346?366.
[7] KANNAN G, SASIKUMAR P, DEVIKA K. A genetic algorithm approach for solving a closed loop supply chain model: A case of battery recycling [J]. Applied mathematical modelling, 2010, 34: 655?670.
[8] 肖智清.基于SOA的物流信息系統集成平臺LESB的研究與實現[D].吉林:吉林大學,2012.
[9] GAZI V P, KAYIS E. Comparing clustering techniques for real microarray data [C]// 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. [S.l.]: IEEE, 2012: 788?791.
[10] YAN Chunlei, SHI Shumin, HUANG Heyan, et al. A method for network topic attention forecast based on feature words [C]// 2013 International Conference on Asian Language Processing. [S.l.]: IALP, 2013: 211?214.
猜你喜歡
課程教育研究·新教師教學(2016年6期)2017-04-10 00:22:41
數字技術與應用(2017年2期)2017-04-08 09:30:10
電子技術與軟件工程(2017年4期)2017-03-27 13:49:48
湖南師范大學學報·自然科學版(2017年1期)2017-03-14 16:08:34
科技與創新(2017年1期)2017-02-16 19:36:23
科技創新導報(2016年21期)2016-12-17 13:07:48
計算機時代(2016年7期)2016-07-15 16:12:30
現代經濟信息(2016年4期)2016-06-20 18:29:48
科技與創新(2016年7期)2016-04-20 09:17:04
科技傳播(2016年3期)2016-03-25 00:23:31
