云環境下軟件錯誤報告自動分類算法改進
2016-05-14 14:30:52黃偉林劼江育娥
計算機應用 2016年5期
關鍵詞:云計算
黃偉 林劼 江育娥


摘要:用戶提交的軟件錯誤報告隨意性大、主觀性強且內容少導致自動分類正確率不高,需要花費大量人工干預時間。隨著互聯網的快速發展用戶提交的錯誤報告數量也不斷增加,如何在海量數據下提高其自動分類的精確度越來越受到關注。通過改進詞頻逆文檔頻率(TFIDF),考慮到詞條在類間和類內出現情況對文本分類的影響,提出一種基于軟件錯誤報告數據集的改進多項式樸素貝葉斯算法,同時在Hadoop平臺下使用MapReduce計算模型實現該算法的分布式版本。實驗結果表明,改進的多項式樸素貝葉斯算法將F1值提高到71%,比原算法提高了27個百分點,同時在海量數據下可以通過拓展節點的方式縮短運行時間,有較好的執行效率。
關鍵詞:多項式樸素貝葉斯;錯誤報告;文本自動分類;詞頻逆文檔頻率;云計算
中圖分類號:TP311 文獻標志碼:A
Abstract:Usersubmitted bug reports are arbitrary and subjective. The accuracy of automatic classification of bug reports is not ideal. Hence it requires many human labors to intervention. With the bug reports database growing bigger and bigger, the problem of improving the accuracy of automatic classification of these reports is becoming urgent. A TFIDF (Term FrequencyInverse Document Freqency) based Naive Bayes (NB) algorithm was proposed. It not only considered the relationship of a term in different classes but also the relationship of a term inside a class. It was also implemented in distributed parallel environment of MapReduce model in Hadoop platform. The experimental results show that the proposed Naive Bayes algorithm improves the performance of F1 measument to 71%, which is 27 percentage points higher than the stateoftheart method. And it is able to deal with massive amounts of data in distributed way by addding computational node to offer shorter running time and has better effective performance.
Key words:Naive Bayes of polynomials; bug report; text automatic classification; Term FrequencyInverse Document Frequency (TFIDF); cloud computing
0 引言
隨著大數據時代的到來,海量數據的處理速度越來越受到重視,傳統的單機處理已經呈現出其弊端,如何在大量的數據情況下提高處理速度受到廣泛的關注。Hadoop作為一個分布式的框架,其在超大數據集下的表現令人滿意。開源軟件的錯誤報告隨著版本的更新收到用戶越來越多的反饋,如何在短時間內將用戶的反饋分門別類更快地進行修復已經成為各企業提升自我軟件競爭力的重點。用戶提交軟件錯誤報告有著很大的隨意性,即使事先給出類別也無法保證用戶能夠正確地選對,因此將錯誤報告進行自動分類能夠節省時間并提高效率。目前對于軟件錯誤報告的分析主要集中在錯誤報告的質量、錯誤報告的最優化、錯誤報告的分類和錯誤報告的修復,機器學習算法和信息檢索技術已經被廣泛應用到其中[1]; 然而對于軟件錯誤報告自動分類改進方法的結果卻不理想[2]。Shokripour等[3]提出的基于時間算法的精確度可以提高到45.52%。Shokripour等[4]提出僅采用名詞和時間元數據的詞條權重的方法可以將準確度提高到49%。Alenezi等[5]通過詞條選擇的方法將F1值提高到38.2%。Shokripour等[6]提出基于位置的錯誤報告加權方法使得準確度提高到50%左右;黃小亮等[7]提出的潛在Dirichlet分配(Latent Dirichlet Allocation, LDA)的軟件缺陷分派方法,將準確度提高到37.54%。業界對此也進行大量的研究,比如基于馬爾可夫鏈的方法[8]、基于詞匯知識模型的方法 [9]和Shokripour等[10]提出的信息提取的方法。以上提到的這些研究,都是為了提高軟件錯誤報告自動分類的精確度。
文本自動分類的算法多種多樣,樸素貝葉斯算法以其簡單高效的特點受到青睞,在其基礎上的改進算法也層出不窮,比如,李文進等[11]提出的基于改進樸素貝葉斯的區間不確定性數據分類方法,翟軍昌等[12]提出的基于增益比對特征詞的樸素貝葉斯改進算法,羅凌等[13]提出的基于樹增強型貝葉斯網絡(Tree Augmented Bayes Network,TAN)的改進等。在大數據環境下實現文本自動分類算法更加有意義,比如張紅蕊等[14]提出的基于關聯規則和置信度的樸素貝葉斯算法,衛潔等[15]在云環境下實現別人改進的樸素貝葉斯算法。盡管如此,對于軟件錯誤報告的自動分類研究結果仍然不理想,同時在大數據環境下對其的關注也較少。本文在Hadoop框架下實現多項式樸素貝葉斯算法并對其進行改進,經過實驗驗證了其在時間和精度上均有較好表現。
2 云環境下的改進算法實現
在Hadoop平臺下使用MapReduce計算模型來實現改進的多項式樸素貝葉斯算法。MapReduce模型主要采用對數據“分而治之”的方法,定義Map和Reduce兩個抽象的編程接口,用鍵值對(key,value)來表示數據。首先是各個Map節點對數據進行并行計算,將中間結果輸出到各個Reduce節點,最后匯總所有Reduce節點的結果,以鍵值對的形式輸出結果。改進算法的實現主要分訓練和測試兩個階段,訓練階段采用四個MapReduce,測試階段采用一個MapReduce。
2.1 訓練階段
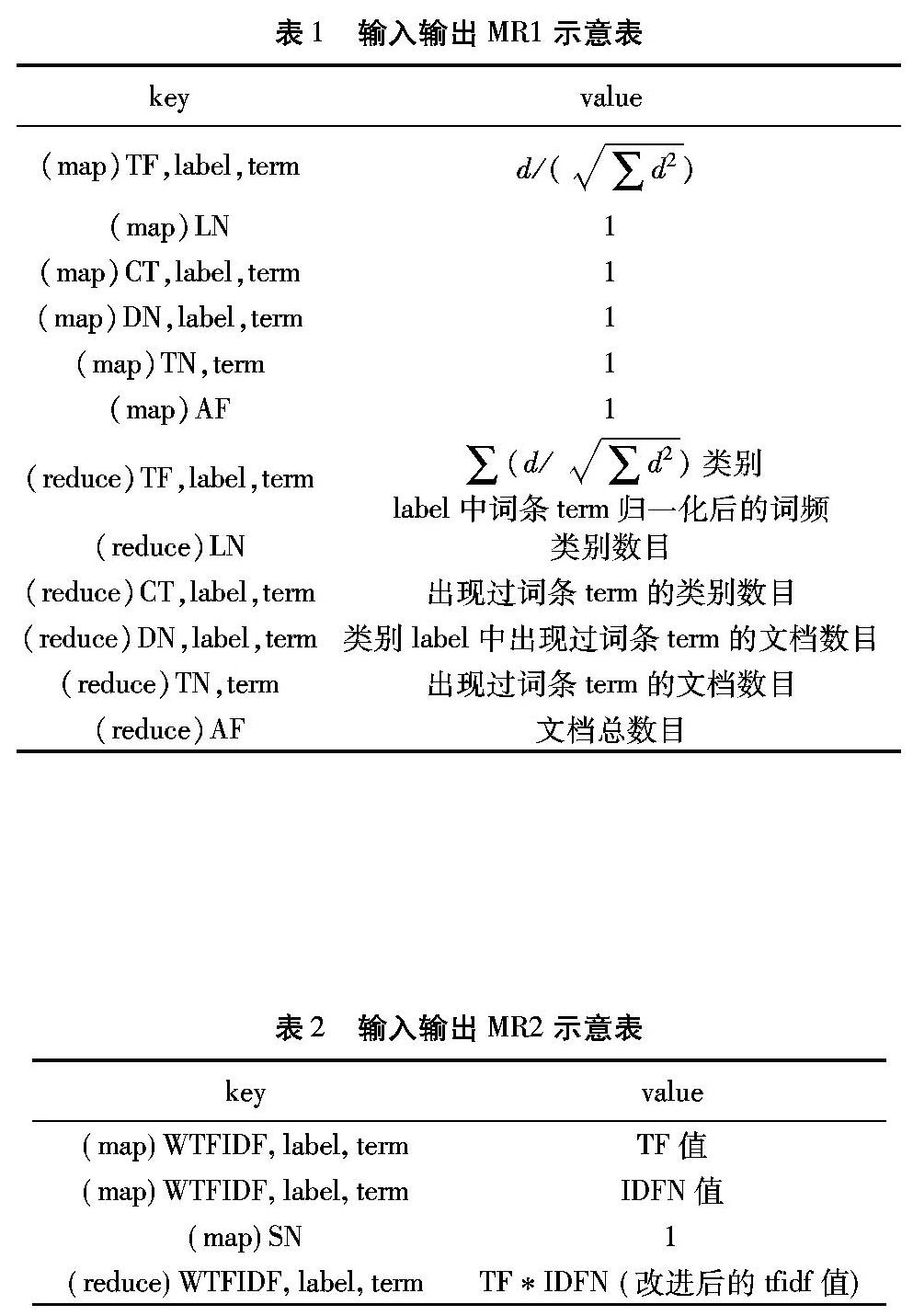
訓練階段的輸入為一個預處理過的文件,每行均代表一個文件,第一個詞條為文檔所屬類別名稱,之后為特征屬性,以空格為間隔符。例如第1行為c、w1、w2w3、w4,c表示所屬類別,w表示分詞后的詞條。如表1所示,Map函數中主要進行詞頻的計算以及其他基本數據的計算,在Reduce中進行合并統計,并將結果輸出到相應文件中。在Reduce輸出過程中,利用setOutputFormat方法設置輸出格式,將每個key得到的結果輸出到單獨文件中去,以供后續計算。
經過4個MapReduce之后,訓練階段完成。在測試階段即可進行預測新文本所屬的類別。
2.2 測試階段
測試階段的輸入文件為測試文件,文件的格式和訓練階段的格式一致。先對每一行所代表的文檔進行詞頻統計。對于每一個類cj,計算每個詞條wt的tf*lg P(wt|cj)值并進行累加,其所屬類別為 c=arg maxcj∈C P(cj|di),在Map階段將判斷結果和原始類別進行比較,相符不相符作出相應輸出,Reduce階段對Map階段的結果進行累加。
3 實驗及結果分析
3.1 實驗數據與環境
本文的實驗數據來自開源軟件Eclipse 官網中2001—2013年用戶提交的部分錯誤報告,涉及到Tools、 Modeling、 Technology、 SOA等11 個類別,總共包含大概50000份錯誤報告。由于每個類別的錯誤報告份數不同,考慮到樣本的均勻性,在抽取樣本時保證每個類別的樣本份數一致,約為3000份每類別,處理過程中遇到個別類別總數不足3000份的,采取放回繼續抽取的隨機方式獲得。首先處理下載的Eclipse 錯誤報告數據,留下錯誤報告的類別和錯誤報告的內容描述2個屬性。利用R語言的TM(TextMining)包對錯誤報告的內容描述進行預處理。將其錯誤報告的內容描述小寫化、去空格、去數字、去停用詞、詞干化、進行分詞。采用10×10交叉驗證方法。每一次打散數據,任意選擇70%數據為訓練數據,余下的30%為驗證數據。訓練數據(70%)被用來建模,余下的數據(30%) 被用來匹配此模型以驗證模型的有效性,記錄下相應的性能指標(精確度、召回率和F1值)。此訓練和驗證過程重復進行10 次,對性能指標取平均值作為每次的計算結果。本文采用分布式集群,每臺電腦配置一致,均為32位計算機,centos6.4系統,2GB內存,Hadoop版本為2.2.0,Java版本1.7。搭建的集群為1個NameNode,6個DataNode。在運行過程中,所有參數均為默認值,暫時沒有進行優化。
3.2 評價指標
實驗評價標準主要有精確率P(precision)、召回率R(recall)和F1值,如表5所示,A表示屬于某類別的文本且預測結果也是屬于某類別的,D表示不屬于某類別的文本預測結果為屬于某類別,C表示屬于某類別的文本預測結果顯示不屬于某類別。依據表5,幾個評估指標的計算公式如式(8)~(10)。F1值綜合了精確率和召回率,能總體地反映出整體的指標,因而本文主要采用F1值來評估算法在不同類別上的分類性能。
3.3 實驗結果與分析
采用交叉驗證方法,將結果取平均值得到F1結果對比表,第2列為采用原始TFIDF算法的多項式樸素貝葉斯方法[15]得到的結果,第3列為本文改進TFIDF算法后的多項式樸素貝葉斯算法得到的結果,因為類別較多,所以僅列出前幾個類別,最后一行為所有類別的平均值。從數據可以看出,改進算法在各個小類別上的F1值均有相當幅度的提高,而且在所有類別的平均值上,改進的算法比原算法提高了27%,提高了原來結果的61%。而在精確度上(未在表中標出),由原始算法的44%提高到改進算法的69%。由此可見改進的算法使得軟件錯誤報告的自動分類結果得到了改善,同時使得海量數據在單機情況下的內存不足瓶頸得以解決。由于業界并沒有將改進的算法應用于軟件錯誤數據集上,基于數據集的特殊性,因而無法直觀比較結果,但是可以對比最近業界在eclipse軟件錯誤報告數據集上做的實驗,最好的結果也是將精確度提高到50%左右[6],可見本文的改進算法對比業界相關研究的結果具有一定的優勢。
同時本文還對并行算法的性能進行測試,分別在兩個節點的集群和6個節點的集群上對2GB,4GB,…,10GB數據集進行測試,分別計算其運行時間。而在單機運行時,一旦數據量足夠大,則會出現內存不足的情況而導致程序無法繼續執行,因而并行計算解決了大數據下單機運行的內存瓶頸。從圖1中可以看出,隨著數據集大小的增加,其運行時間趨于緩和,可見數據量越大越適合并行分布式改進的算法。同時隨著節點的增加,運行時間縮短,可見可以通過增加節點進一步的縮短運行時間。
4 結語
本文對多項式樸素貝葉斯算法進行了改進,在軟件錯誤報告集上進行自動分類,結果表明其在F1值指標上相對原有算法有了較大的提高。同時在大數據環境下實現改進的算法,表明在海量數據前其運行時間縮短同時效率提高,使得原來在單機上的串行計算得以并行實現。改進的算法除了適合于開源軟件錯誤報告的自動分類,也適合于大型企業收集客戶信息,通信運行商對客戶投訴和建議的自動分類以及其他需要人工提交文本描述、隨意性比較強的數據的自動分類。
參考文獻:
[1]ZHANG J, WANG X Y, HAO D, et al. A survey on bugreport analysis[J]. Science China Information Sciences, 2015, 58(2):1-24.
[2]STRATE J D, LAPLANTE P A. A literature review of research in software defect reporting[J]. IEEE Transactions on Reliability,2013, 62(2): 444-454.
[3]SHOKRIPOUR R, ANVIK J, KASIRUN Z M, et al. A timebased approach to automatic bug report assignment[J]. Journal of Systems & Software, 2015,102:109-122.
[4]SHOKRIPOUR R, ANVIK J, KASIRUN Z M, et al. Improving automatic bug assignment using timemetadata in termweighting[J]. IET Software, 2014, 8(6):269-278.
[5]ALENEZI M, MAGEL K, BANITAAN S. Efficient bug triaging using text mining[J]. Journal of Software, 2013, 8(9):2185-2190.
[6]SHOKRIPOUR R, ANVIK J, KASIRUN Z M, et al. Why so complicated? Simple term filtering and weighting for locationbased bug report assignment recommendation[C]// Proceedings of the 10th International Workshop on Mining Software Repositories. Piscataway, NJ: IEEE, 2013: 2-11.
[7]黃小亮, 郁抒思, 關佶紅. 基于 LDA 主題模型的軟件缺陷分派方法[J]. 計算機工程, 2011, 37(21): 46-48.(HUANG X L,YU S S,GUAN J H. Software bug triage method based on LDA topic model[J]. Computer Engineering, 2011, 37(21): 46-48).
[8]JEONG G, KIM S, ZIMMERMANN T. Improving bug triage with bug tossing graphs[C]// Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering. New York: ACM, 2009: 111-120.
[9]MATTER D, KUHN A, NIERSTRASZ O. Assigning bug reports using a vocabularybased expertise model of developers[C]// Proceedings of the 6th IEEE International Working Conference on Mining Software Repositories. Piscataway, NJ: IEEE, 2009: 131-140.
[10]SHOKRIPOUR R, KASIRUN Z M, ZAMANI S, et al. Automatic bug assignment using information extraction methods[C]// Proceedings of the 2012 International Conference on Computer Science Applications and Technologies. Piscataway, NJ: IEEE, 2012: 144-149.
[11]李文進, 熊小峰, 毛伊敏. 基于改進樸素貝葉斯的區間不確定性數據分類方法[J]. 計算機應用, 2014, 34(11):3268-3272.(LI W J,XIONG X F,MAO Y M. Classification method for interval uncertain data based on improved naive Bayes[J]. Journal of Computer Applications, 2014, 34(11):3268-3272.)
[12]翟軍昌, 秦玉平, 車偉偉. 垃圾郵件過濾中信息增益的改進研究[J]. 計算機科學, 2014, 41(6):214-216.(ZHAI J C,QIN Y P,CHE W W. Improvement of information gain in spam filtering[J]. Computer Science, 2014, 41(6):214-216.)
[13]羅凌, 楊有, 馬燕. 基于TAN貝葉斯網絡的學習風格檢測研究[J]. 計算機工程與應用, 2015,51(6):48-54.(LUO L, YANG Y, MA Y. Research on detecting learning style based on TAN Bayesian network[J]. Computer Engineering and Applications, 2015,51(6):48-54.)
[14]張紅蕊, 張永, 于靜雯. 云計算環境下基于樸素貝葉斯的數據分類[J]. 計算機應用與軟件, 2015, 32(3):27-30.(ZHANG H R,ZHANG Y,YU J W. Data classification based on naive Bayes in cloud computing environment[J]. Computer Applications and Software, 2015, 32(3):27-30.)
[15]衛潔, 石洪波, 冀素琴. 基于Hadoop的分布式樸素貝葉斯文本分類[J]. 計算機系統應用, 2012, 21(2):210-213.(WEI J,SHI H B,JI S Q. Distributed naive Bayes text classification using Hadoop[J]. Computer Systems and Applications, 2012, 21(2):210-213.)
[16]MCCALLUM A, NIGAM K. A comparison of event models for naive Bayes text classification[C]// Proceedings of the 25th International Symposium on Computer and Information Sciences. Berlin: Springer, 1998:41-48.
[17]JIANG S, SAYYADSHIRABAD J, MATWIN S. Large scale text classification using semisupervised multinomial naive Bayes[C]// Proceedings of the 28th International Conference on Machine Learning. Bellevue, WA: ICML, 2011: 97-104.
[18]SALTON G, BUCKLEY C. Termweighting approaches in automatic text retrieval[J]. Information Processing & Management, 1988, 24(5): 513-523.
猜你喜歡
數字技術與應用(2016年9期)2016-11-09 22:56:18
數字技術與應用(2016年9期)2016-11-09 00:07:05
知音勵志·社科版(2016年8期)2016-11-05 04:28:47
電腦知識與技術(2016年21期)2016-10-18 23:34:52
電腦知識與技術(2016年21期)2016-10-18 23:24:44
電腦知識與技術(2016年21期)2016-10-18 22:11:15
科技視界(2016年22期)2016-10-18 14:33:46
中國新通信(2016年16期)2016-10-18 10:49:17
大學教育(2016年9期)2016-10-09 08:54:03
科技視界(2016年20期)2016-09-29 13:34:06
