數據挖掘在獨立學院招生錄取評鑒中應用
2016-05-30 11:13:18舒懿,李棟
長春大學學報 2016年4期
舒 懿, 李 棟
(1.北京理工大學 珠海學院,廣東 珠海 519085 ;2.澳門城市大學,澳門 999078)
?
數據挖掘在獨立學院招生錄取評鑒中應用
舒懿1, 李棟2
(1.北京理工大學 珠海學院,廣東 珠海 519085 ;2.澳門城市大學,澳門 999078)
摘要:云技術、數據挖掘、互聯網+等概念已經滲透到各個行業領域。高校每年招生產生的大量數據也逐漸被學校重視起來重新考量。本研究使用數據挖掘技術決策樹ID3算法和其改進算法C4.5,探究這些數據運用在招生宣傳決策中的可行性和有效性,并尋找錄取新生的信息之間的關聯規則。提出了把數據挖掘技術應用于高校招生工作和高校管理工作的新思想,并建立了高校招生的數據挖掘模型。
關鍵詞:數據挖掘;獨立學院;ID3算法;C4.5算法;招生決策
1研究背景及意義
中國的高等教育過去幾十年飛速發展,迅速從精英教育階段跨入大眾化教育階段。伴隨高等教育改革而新興的獨立本科院校扮演著重要角色。獨立本科院校的招生宣傳工作與公辦高校相比較有著明顯差異。隨著中國人口紅利的逐漸消失,獨立本科院校的招生工作面臨學費高昂、學校名譽較低、招生形式靈活、生源穩定性不佳等特點,招生宣傳工作的好壞直接關系學校的生存與發展。
隨著大數據時代的到來,云技術、數據挖掘、互聯網+等概念已經滲透到各個行業領域。與此同時,高校每年招生產生的大量看似無用的數據也逐漸被學校重視起來重新考量。如何從這些數據中提取潛在價值,使其成為高校招生宣傳工作參考的重要指標,演變為一個迫切的議題。由于現代數據的大、多、繁、冗等特點,如何更有效地、更精準地、更快速地對數據進行分類和挖掘是廣大科研工作者的不懈追求。
在目前獨立本科院校每年給定招生配額的大背景下,如何優化各個省份不同專業的配置,不同專業的招生名額分配,都成為影響學校招生計劃完成率以及新生報到率的重要考量。錄取考生的信息不是進行簡單的圖表化,而應該找尋各個信息之間的關系。因此,把數據挖掘技術應用于獨立本科院校的招生宣傳決策中有著巨大的實用意義。
2研究方法及分析
本研究以廣東省某獨立學院2015年招生錄取數據為研究基礎,選擇決策樹ID3算法進行分類規則的研究,分析錄取學生中不同性別、不同生源地等等因素影響下的新生報到特點;根據數據間的聯系,對于未來新開設的專業,或者新投放的招生地區,通過此算法,來判別某一專業或某一地區未來生源是否充足,亦或某一招生地區是否存在潛在的生源對象,實證宣傳策略的可行性及可靠性,利用數據挖掘算法來實現廣東省獨立本科院校招生宣傳效果的重點研究。在現有的招生宣傳中遵循的一些基本性原則文獻、高校生源競爭的宣傳策略文獻、ID3算法的改進研究、C4.5算法等文獻的基礎上,針對招生宣傳的質量評價以實例數據為基礎,嘗試運用C4.5算法進行定量的評價研究,對改進招生宣傳工作缺少量化指標與依據進行改善。[2][3]
(一)ID3算法
ID3算法是對1966年Hunt等學者提出的CLS決策樹概念學習系統基礎上進行改進的,可以稱作是決策樹算法的經典。ID3算法能夠揭示隱藏的模式和關系,通過把最大信息的增益(Gain)的屬性作為節點進行劃分,將所有信息根據節點來構建一顆樹[1-3],例如:對于學校而言,樹的主體就是被錄取的學生讀還是不讀,接著根據生源地、分數、性別等等確定節點進行自上而下枝葉的生長,構建一棵簡潔明了的決策樹。信息增益是期望信息或者信息熵的有效減少量,意味著信息增益(Gain)值越大信息的意義就越大,也可以理解為某種信息的出現率[2,3]。具體計算方法如下:
(1)以決策屬性分類的樣本集信息熵的推導公式: (公式2.1)
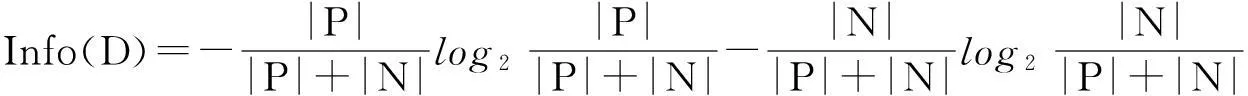
其中E(D)表示信息熵值,將整個樣本集分為P正例集和N反例集,|P|表示P正例集的元素個數,同理|N|表示N反例集的元素個數。
(2)以各個條件屬性劃分樣本集的類別條件熵的推導公式:(公式2.2)
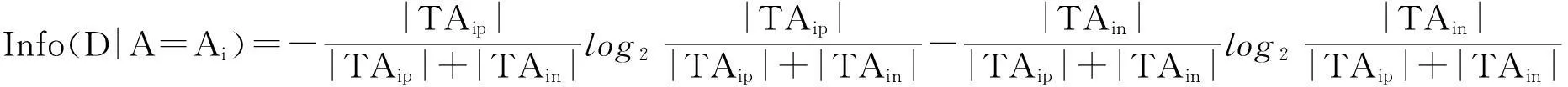
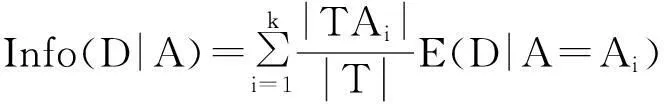
(3)以條件屬性劃分樣本集的信息增益推導公式:
例如:屬性A的信息增益推導公式:
Gain(A)=E(D)-E(D|A) (公式2.4)
本研究以廣東省某獨立學院2015級錄取新生名單,選取20人作為樣本數據集合T(如下表1)
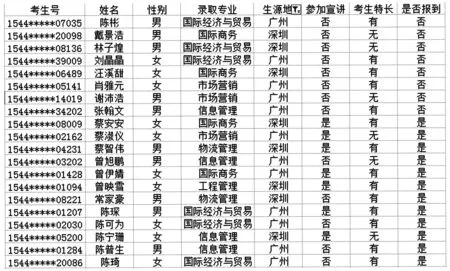
在數據集合中“是否報到”屬于決策屬性,“性別”“生源地”“參加宣講”“考生特長”屬于條件屬性,對以報到為類標記的樣本元組進行統計分析(如下表2)。
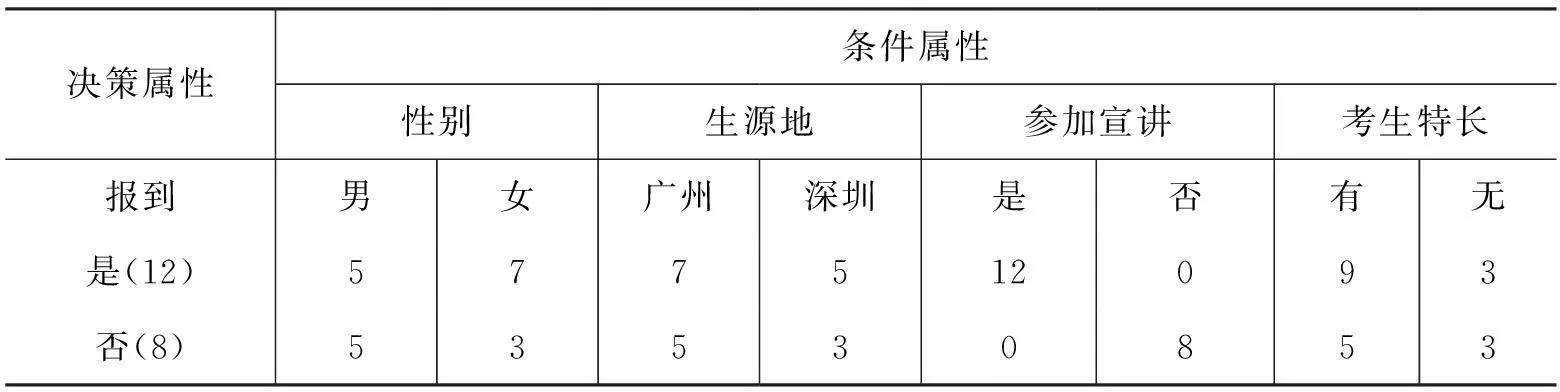
決策屬性條件屬性性別生源地參加宣講考生特長報到男女廣州深圳是否有無是(12)577512093否(8)53530853
(二)接著我們依據以上公式2.1-2.3探究構造決策樹的模型:
(1)計算樣本數據集合T的決策屬性“是否報到”的信息熵:
(2)分別計算四個條件屬性劃分樣本集的條件熵:
4.根據以上結果,運用公式2.4來求取四個屬性的信息增益值分別為:
Gain(性別)=Info(報到)-Info(報到|性別)=0.9716-0.94065=0.03095
Gain(生源地)=Info(報到)-Info(報到|生源地)=0.9716-1.06866=-0.09706
Gain(參加宣講)=Info(報到)-Info(報到|宣講)=0.9716-0=0.9716
Gain(考生特長)=Info(報到)-Info(報到|考生特長)=0.9716-0.96412=0.00748
此時,選取信息增益值進行分類,“參加宣講”的條件屬性的信息增益值為0.9716,在四個條件屬性中具有最強的分類能力,通過ID3算法把信息進行了初步規整,分為參加過宣講的數據和沒有參加過宣講的數據兩部分:
數據集合A=參加過學校宣講會的12名考生
數據集合B=沒有參加過學校宣講會的8名考生
因為“參加宣講”進行信息分類帶來的不確定程度最小。所以,在構建招生信息決策樹時,首先選擇“參加宣講”作為根節點,下一步對數據集合A和B進行以上往復運算分類,從其他三個條件屬性中繼續尋找信息增益值最大的屬性做下一步分類屬性,直到分析完畢,建構一顆完整的決策樹。決策樹如圖1:
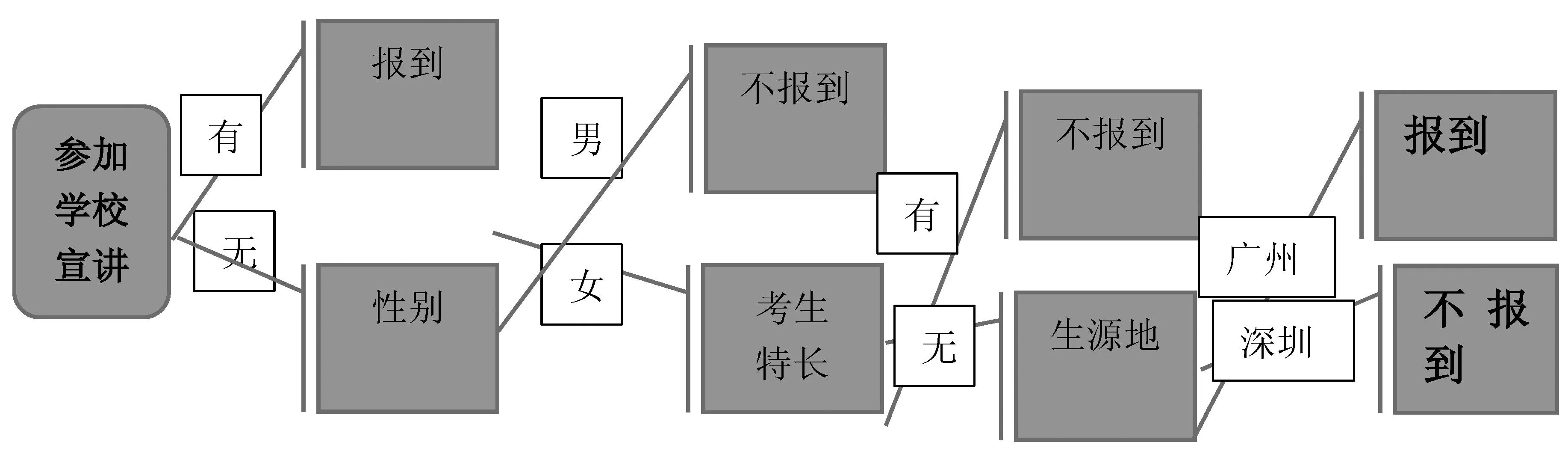
圖1 決策樹
以上分析僅僅選取20個學生信息作為闡述ID3算法,數據雖然真實,但在數量上以及條件屬性關系上略有欠妥之處,另外在實際研究錄取學生是否報到上,高考分數、志愿情況、專業配置、家庭收入、父母教育背景均屬于研究范圍內的條件屬性。而通過ID3算法在構造決策樹時只能對離散型信息進行分類,對連續性數值類型的高考成績無法處理,通過計算信息增益值來確定決策樹的根節點,這樣算法的選擇偏向于取值較多的屬性[1,2],但是這樣的屬性在招生決策時不一定是最優屬性。
(三)C4.5算法
C4.5算法是在ID3算法的基礎上進行的改進,克服ID3算法缺陷提出了新的決策樹構建算法。使得C4.5算法成為2006年以來IEEE數據挖掘國際會議選入數據挖掘十大經典算法[1]。在ID3算法基礎上提出的改進有:
(1)ID3算法實用信息的增益值來衡量信息的屬性標準,而C4.5算法改進為使用信息增益率(Gain Ratio),如此改進可以避免在進行信息屬性選擇時候出現對取值較多屬性的偏向情況。其原理就是求得特定信息增益值與其分裂屬性的信息熵的比值[1][3]。具體公式如下:
其中,A表示屬性,T表示按照屬性A劃分的樣本集,K表示條件屬性A的K個屬性值通過上文引用的例子來解釋C4.5算法的具體運用,樣本集中共有20個樣本,其中14個樣本屬性為有“考生特長”,6個樣本屬性為沒有“考生特長”,上文已經計算了Gain(考生特長)=0.00748,那么屬性“考生特長”的信息增益率計算如下:
Gain(考生特長)=Info(報到)-Info(報到|考生特長)=0.9716-0.96412=0.00748
Gain Ratio(考生特長)=0.00748/0.88129=0.00849
(2)C4.5算法可以處理連續數值型屬性,處理方法按照連續數值屬性進行排序,然后將該屬性劃分若干分割點,對每個分割點的信息增益率進行計算,取信息增益率最大的方案最為最終的分割方案實現連續數值屬性的離散化,選取決策樹的根節點。具體改進方法如下所示:

樣本T1T2T3T4T5T6T7T8T9T10成績511512519520522523524528538540報到是否是是是是是否是否
首先將T1-T10十個屬性值劃分9個分割點,然后分別計算9個分割點的信息增益率,例如第四分割點在T4與T5之間,將屬性劃分為{T1,T2,T3,T4}和{T5,T6,T7,T8,T9,T10}兩部分,

報到考生成績≦S4≧S4是(7)34否(3)12
因此我們可以求得決策屬性“報到”的信息熵:
以屬性“考生成績”劃分的“報到”的條件熵:
Gain(考生成績)=Info(到)-Info(到|考生成績)=0.8813-0.8755=0.0058
由公式計算屬性“學生成績”的信息熵:
由公式計算屬性“學生成績”的信息增益率:
Gain Ratio(考生成績)=0.0058/0.9709=0.1282
通過分別計算9個分割點的信息增益率,取最大信息增益率的分割點就可以將“考生成績”屬性進行離散化,進而進行根節點的劃分和決策樹的構建。
3發現及結論
綜合前期對該獨立學院2015年錄取學生做出的問卷調查,部分信息結合C4.5決策樹構建方法,做出詳細分析,針對招生宣傳工作茲提出以下發現和結論:
(1)獲得C4.5決策樹模型,以及對于影響決策樹分類的變量,從影響程度高低排列分別為:參加宣講會、性別、成績、高考類型、年齡、宣傳登記、所在地區,其中是否接受學校宣傳對報到影響程度較大,而宣傳登記的影響程度大于考生所在地區的影響程度。
(2)提前確定報考院校考生錄取率較高。研究發現考生在高三及高考填報志愿期間選擇目標學校的占79%,特別在高考填報志愿期間選擇目標學校的占39%。在志愿填報時,有明確目標的,自己心中有數占40.39%,比較茫然和查閱資料再定的占57%。而在高三期間確定報考志愿的考生報到率同比高考填報志愿期間高出7.8個百分點。
(3)考生關注“校園環境”,“教學、師資”宣傳大有空間。數據顯示2015級新生選擇本學校最主要的原因是“校園環境”(68.16%),其后依次是 “學校的社會聲譽”(32.94%)和“專業特色”(32.79%)等。但在不同省份學生的關切點略有差異,因此對于招生宣傳工作人員應該有策略講方法的針對不同省份考生的關切點進行重點宣傳。
(4)多媒體成為考生獲取信息的主渠道。研究發現在參與調研的4597名廣東考生中有將近88%的新生都未看到過學校招生簡章,2015級學生獲知我校信息的來源最主要的渠道是當地招生報考目錄(63.27%)、學校招生簡章和海報(26.44%)親戚朋友推薦(22.46%)。另外,部分學生通過報刊網站、微信、貼吧等獲悉我校信息。2015級學生以學校招生指南作為我校信息渠道同比2014級學生高出17個百分點。我校新生報到的人數中有77%新生沒有參加我校在各地舉行的高考招生咨詢會,而只有23%新生參加了招生咨詢會,參與情況較2014年略微提升。另外,值得我們注意的是,在參加過我校招生咨詢會的同學中,有854人接近65%的學生認為參加招生咨詢會對報考有直接影響。
(5)專業信息獲取渠道較為狹窄。2015級新生對“專業的培養目標和就業范圍”普遍有所了解,63.23%的考生通過學校網站獲取報考專業信息,通過招生宣傳人員了解專業情況的考生占比5.76%。此外,學生對于學校優勢學科及專業情況不甚了解,在參加招生咨詢會過程中工作人員對考生的問題解答滿意度直接影響考生報考學校的意愿。
4思考及建議
(1)全面更新線上宣傳端口,發揮宣傳正面效果。
以上結果顯示,學校的官方網站是獨立類本科院校獲取專業信息,了解學校情況的主要網絡傳播媒介。從資源的投入產出比來看,學校官網是一種不需耗用額外費用的自有電子媒體,獨立本科院校要善用此媒介,使其發揮具備詳細、便捷、快速、準確的為考生提供報考參考咨詢的功能。除此之外,可以增加考生與校方互動功能,以利于來年招生傳銷和決策,強化效果與無形。
(2)靈活調整宣傳方式,準確選擇宣傳時機。
研究發現學校可以在宣傳招生期間,對于不同省份縣市靈活選擇招生宣講會的時間、地點、對象,學校招生海報等宣傳資料根據宣傳需要動態增減并且宜采取進校進班全面鋪開的形式進行張貼宣傳,對于招生宣傳工作時機趕早不趕晚,并與下一級教育機構保持長期穩定的合作關系,以提高我校知名度和聲譽,促進招生。
(3)突出宣傳學校優勢,提升宣傳人員專業素養。
研究結果發現,錄取學生中參加招生咨詢會考生報到率高于未參加招生咨詢會考生,現場宣傳人員左右考生選擇就讀院校之意向。因此,對于參加各類招生宣傳工作人員,宜經過專業訓練,將學校硬件、軟件、學科、師資之優勢規整總結,便于解答。期望使咨詢學生家長留下良好影響,杜絕派公差、輪值方式派出不適任人員[2]。
我國高等教育已經步入改革的關鍵時期,長期以來積累的眾多數據應該為學校招生決策提供參考,通過數據挖掘技術的應用,可以促進教育和改革的良性發展。中國的高考招生制度具有非常強的計劃性和政策性。因此,本研究通過一個小的數據集闡釋了ID3算法和C4.5算法在招生決策中的具體應用,具有一定現實意義。具體實踐不一定對所有地區的獨立學院均適用,后續可以進步一探討相關改進方法的運用,將理論研究付之于實際,產研結合,通過開發建立高校的招生錄取分析系統為高校個體提供更精準有效的招生決策服務。
參考文獻:
[1]姚亞夫,邢留濤.決策樹C4.5連續屬性分割閾值算法改進及其應用[J],中南大學學報(自然科學版),2011,42,(12):3772-3776.
[2]楊學兵,張俊.決策樹算法及其核心技術[J],計算機技術與發展,2007(1):44-46.
[3]劉玉文,數據挖掘在高校招生中的研究與應用[D].上海:上海師范大學,2008.
[4]朱巍,譚峰.高校局域網考試系統設計[J].黑龍江八一農墾大學學報,2013(2):81-83.
責任編輯:程艷艷
Application of Data Mining in Enrollment Assessment in Independent Colleges
SHU Yi1, LI Dong2
(1.Zhuhai School, Beijing Institute of Technology, Zhuhai 519085, China;2.City University of Macau, Macau 999078, China)
Abstract:The concepts of cloud technology, data mining and Internet+ have been penetrated into various industries. A large number of data generated from enrollment each year are gradually being taken and reconsidered by colleges. The study uses data mining techniques decision tree ID3 algorithm and its improved C4.5 algorithm to explore the feasibility and effectiveness of these data in the application of enrollment propaganda decisions and to seek for the rules of association between information among enrolled students, presenting the ideas of applying data mining technology to college enrollment and management and establishing data mining models of college enrollment.
Keywords:data mining; independent college; ID3 algorithm; C4.5 algorithm; enrollment decision
中圖分類號:TP311
文獻標志碼:A
文章編號:1009-3907(2016)04-0022-06
作者簡介:舒懿(1982-),女,安徽旌德人,碩士,助理研究員,主要從事招生政策、高等教育管理方面研究;李棟(1988-),男,山東煙臺人,講師,博士研究生,主要從事教育管理、成人教育、思政教育方面研究。
基金項目:2015年廣東省教育統計科學研究計劃項目(14TJ0015)
收稿日期:2015-10-28
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
留學生(2016年6期)2016-07-25 17:55:29
信息通信技術(2015年6期)2015-12-26 01:16:46
小朋友·聰明學堂(2014年7期)2015-01-15 12:07:06
中外會展(2014年4期)2014-11-27 07:46:46
電子設計工程(2014年18期)2014-02-27 12:00:13
中學生英語·外語教學與研究(2008年2期)2008-02-18 01:52:44
祝您健康(1987年3期)1987-12-30 09:52:32
