配網(wǎng)工程項(xiàng)目詞庫(kù)創(chuàng)建及分詞探索
2016-05-30 07:21:20張文露譚騫章光東
企業(yè)技術(shù)開(kāi)發(fā)·中旬刊 2016年11期
關(guān)鍵詞:文本挖掘
張文露 譚騫 章光東

摘 要:隨著國(guó)網(wǎng)公司信息系統(tǒng)的完善和業(yè)務(wù)數(shù)據(jù)的積累,公司各業(yè)務(wù)部門開(kāi)展了數(shù)據(jù)探索和分析,以支撐逐年增加投資、擴(kuò)大規(guī)模的配網(wǎng)工程項(xiàng)目建設(shè)工作。但是由于各省市公司的管理模式不同,導(dǎo)致配網(wǎng)工程項(xiàng)目相關(guān)數(shù)據(jù)一致性較差,可用于支撐分析的特征值較少。因此論文基于文本挖掘方法創(chuàng)建符合國(guó)網(wǎng)公司特性的工程詞庫(kù),彌補(bǔ)過(guò)往歷史數(shù)據(jù)的缺失和不完整,使歷史文本數(shù)據(jù)能夠支撐后續(xù)數(shù)據(jù)分析工作。
關(guān)鍵詞:文本挖掘;配網(wǎng)工程;詞庫(kù)創(chuàng)建
中圖分類號(hào):TP391 文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1006-8937(2016)32-0072-02
1 研究背景
配網(wǎng)工程項(xiàng)目具有項(xiàng)目類型眾多、物資使用種類集中的特點(diǎn),隨著國(guó)網(wǎng)信息化系統(tǒng)建設(shè)的逐漸完善,出現(xiàn)聯(lián)合數(shù)據(jù)分析的需求,然而由于各網(wǎng)省公司項(xiàng)目管理水平的差異,配網(wǎng)項(xiàng)目在各網(wǎng)省公司的管理模式不同。
部分省公司按照區(qū)縣對(duì)配網(wǎng)項(xiàng)目進(jìn)行打包管理,部分省公司則按照單體項(xiàng)目進(jìn)行管理。但是從整體來(lái)看,針對(duì)配網(wǎng)工程項(xiàng)目的管理是松散的,直接導(dǎo)致了配網(wǎng)工程項(xiàng)目的可用特征較少,無(wú)法配合其他數(shù)據(jù),以工程項(xiàng)目為對(duì)象進(jìn)行聯(lián)合數(shù)據(jù)分析。但是配網(wǎng)工程項(xiàng)目的命名包含一定規(guī)律,可以通過(guò)文本挖掘的方法從工程項(xiàng)目名稱中提取有效的項(xiàng)目屬性特征,以描述工程建設(shè)性質(zhì)和建設(shè)內(nèi)容。然而目前較為成熟的分詞函數(shù)都依賴于對(duì)應(yīng)的專業(yè)詞庫(kù),即基于一本專業(yè)“詞典”自動(dòng)完成名詞的分解,所以提取配網(wǎng)工程項(xiàng)目特征標(biāo)簽的首要任務(wù)就是構(gòu)建專業(yè)的配網(wǎng)電網(wǎng)詞庫(kù),以支持后期分詞函數(shù)的應(yīng)用,完成對(duì)配網(wǎng)工程項(xiàng)目名稱的分詞。
2 詞庫(kù)構(gòu)建原理
傳統(tǒng)的詞典創(chuàng)建方法通常認(rèn)定出現(xiàn)頻數(shù)超過(guò)某個(gè)閾值的文本片段即為詞典的組成部分,然而并沒(méi)有考慮到該文本片段是否僅為一個(gè)詞還是由多個(gè)詞構(gòu)成的詞組,因此為了克服傳統(tǒng)方法的缺點(diǎn),需要綜合分析自然語(yǔ)言的內(nèi)部凝聚程度和外部自由運(yùn)用程度兩個(gè)方面去構(gòu)建配網(wǎng)專業(yè)詞庫(kù)。其中詞語(yǔ)的內(nèi)部凝聚程度指的是一個(gè)文本片段成詞的概率,凝聚程度越大說(shuō)明該文本片段越可能成為一個(gè)詞即進(jìn)入配網(wǎng)專業(yè)詞庫(kù),如“維修工程”出現(xiàn)的概率為“維修工”出現(xiàn)概率的25倍,這說(shuō)明“維修工程”更可能是一個(gè)具有實(shí)際意義的配網(wǎng)專業(yè)詞匯。
外部自由運(yùn)用度指的是定義該詞語(yǔ)片段與左鄰、右鄰詞語(yǔ)之間的相關(guān)程度,計(jì)算該文本的左鄰字和右鄰字所能夠提供的信息熵,信息熵越大,說(shuō)明該文本可提供的信息量越大,該文本的左右鄰字越豐富,即可以更加自由地運(yùn)用于各個(gè)語(yǔ)言環(huán)境中,如“臺(tái)區(qū)”前后可以添加各類文本片段成詞,然而“變電臺(tái)區(qū)”、“新增臺(tái)區(qū)”、“臺(tái)區(qū)布點(diǎn)”等詞卻僅能夠以單獨(dú)形態(tài)成詞,即更有可能成為真正有區(qū)分度的有實(shí)際意義的配網(wǎng)專業(yè)詞匯。
用p(x)代表詞語(yǔ)的凝聚程度,P(AB)代表該文本片段在整個(gè)文本中出現(xiàn)的概率,P(A),P(B)代表子文本片段在整個(gè)文本中出現(xiàn)的概率,凝聚度公式如下:
如果僅從內(nèi)部凝聚程度考慮,有可能出現(xiàn)找到部分詞的情況,該詞內(nèi)部凝聚程度很高,但并不包含完整的文本片段,如變電、開(kāi)閉等。同樣,如果僅從外部自由程度去考慮,很有可能提取到相當(dāng)多的連接字,該連接字可以很大程度上自由地運(yùn)用于文本環(huán)境中,如的、了等。因此模型首先需要對(duì)輸入文本進(jìn)行預(yù)處理,將一列項(xiàng)目名稱整合成一段緊密相連的文本片段、去掉字母、數(shù)字和特殊符號(hào),將預(yù)處理后的文本按從前至后和從后至前兩個(gè)方向進(jìn)行單字切割,分別生成單字出現(xiàn)字頻表。
然后計(jì)算并逐步檢驗(yàn)可能成詞的文本片段的內(nèi)部凝聚程度和外部自由運(yùn)用程度兩個(gè)指標(biāo),結(jié)合實(shí)際業(yè)務(wù)需求,在程序中設(shè)定合適的內(nèi)部凝聚度閾值和左右信息熵閾值,按照業(yè)務(wù)規(guī)則最終篩選得到既準(zhǔn)確又有現(xiàn)實(shí)意義的配網(wǎng)電網(wǎng)專業(yè)詞庫(kù)字典,比如針對(duì)項(xiàng)目名稱中各省地市公司的地理位置詞語(yǔ),由于缺乏能夠揭示工程建設(shè)性質(zhì)和建設(shè)內(nèi)容的實(shí)際意義,所以即便可以滿足內(nèi)部凝聚程度和外部自由運(yùn)用程度兩個(gè)指標(biāo)的要求,也不能作為最終的詞語(yǔ)進(jìn)入配網(wǎng)電網(wǎng)專業(yè)詞典。
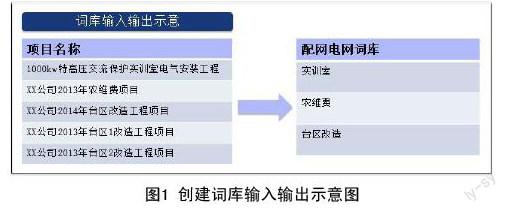
運(yùn)用R語(yǔ)言實(shí)現(xiàn)以上步驟,該階段的輸入數(shù)據(jù)是一列包含配網(wǎng)電網(wǎng)特征關(guān)鍵詞的項(xiàng)目名稱,輸出是一列可能成詞的文本即配網(wǎng)電網(wǎng)專業(yè)詞庫(kù)字典,該輸入輸出的數(shù)量并非一一對(duì)應(yīng)的關(guān)系,如圖1所示。
3 分詞原理
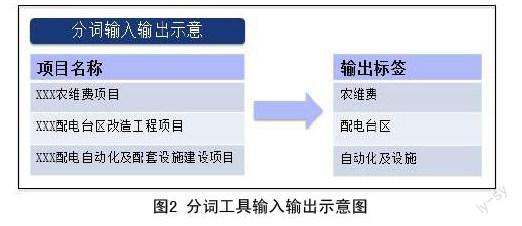
運(yùn)用R語(yǔ)言中的結(jié)巴(jiebaR)工具包,利用其支持的最大概率法(Maximum Probability),隱式馬爾科夫模型(Hidden Markov Model),索引模型(Query Segment),混合模型(Mix Segment)共四種分詞模式的功能,首先引入并應(yīng)用已經(jīng)創(chuàng)建完成的配網(wǎng)專業(yè)詞典,替換掉結(jié)巴(jiebaR)工具包中的默認(rèn)詞典,接下來(lái)讀取項(xiàng)目名稱數(shù)據(jù)集進(jìn)行分詞。該階段的輸入數(shù)據(jù)是一列包含配網(wǎng)電網(wǎng)特征關(guān)鍵詞的文本,輸出是對(duì)應(yīng)項(xiàng)目名稱的一系列標(biāo)簽,如圖2所示。
基于已創(chuàng)建的配網(wǎng)專業(yè)詞典,可以將復(fù)雜的項(xiàng)目名稱拆分成為幾個(gè)關(guān)鍵詞的堆疊,并且根據(jù)需求,配置個(gè)性化選擇規(guī)則,例如選擇幾個(gè)關(guān)鍵詞中出現(xiàn)頻率最高的關(guān)鍵詞作為標(biāo)簽形成初步標(biāo)簽。由于分詞會(huì)輸出較多標(biāo)簽,為了防止標(biāo)簽冗雜,工程特征指示不清晰,本文通過(guò)聚類分析發(fā)現(xiàn)并聚合具有相似物資領(lǐng)用特征的項(xiàng)目群,隨后結(jié)合業(yè)務(wù)理解對(duì)這些項(xiàng)目群進(jìn)行命名,即完成了標(biāo)簽的合并和刪減。此過(guò)程使用K-Means聚類方法作為無(wú)監(jiān)督式的機(jī)器學(xué)習(xí)方法,在未知樣本類別的情況下,通過(guò)計(jì)算樣本彼此間的歐式距離或余弦距離來(lái)估計(jì)樣本所屬類別。
K-Means是一種自下而上的聚類算法,是典型的基于距離的聚類算法,采用距離作為相似性的評(píng)價(jià)指標(biāo),即認(rèn)為兩個(gè)對(duì)象的距離越近,其相似度就越大。該算法認(rèn)為簇是由距離相近的若干對(duì)象組成的,因此希望最終得到緊湊的簇。該算法接受參數(shù)k,首先將事先輸入的n個(gè)數(shù)據(jù)對(duì)象隨機(jī)分成k個(gè)簇,為使同一類中的對(duì)象相似程度較高,不同類中的對(duì)象相似程度較低。具體計(jì)算步驟如下:
①隨機(jī)選定k個(gè)中心作為起點(diǎn);
②將每個(gè)數(shù)據(jù)點(diǎn)歸類到離它最近的中心點(diǎn)所代表的簇中;
④重復(fù)步驟②~③,直到滿足收斂要求,即該k個(gè)中心點(diǎn)不再變化。
結(jié)合業(yè)務(wù)理解給定k=44,即給定44個(gè)具有不同項(xiàng)目工程建設(shè)內(nèi)容和建設(shè)性質(zhì)的項(xiàng)目群,通過(guò)聚類分析的方法,輸入對(duì)應(yīng)于各個(gè)項(xiàng)目名稱的不同物料小類的領(lǐng)料數(shù)據(jù)和下達(dá)預(yù)算金額,最終輸出得到44個(gè)項(xiàng)目群的序號(hào)標(biāo)簽,隨后結(jié)合業(yè)務(wù)理解,根據(jù)項(xiàng)目工程實(shí)際特征,對(duì)這44個(gè)項(xiàng)目群分別進(jìn)行命名即分別貼標(biāo)簽,對(duì)貼好的標(biāo)簽進(jìn)行人工調(diào)整,保留其中能用自然語(yǔ)言表達(dá)的并且具有現(xiàn)實(shí)意義的標(biāo)簽名稱,作為提取構(gòu)建的新的工程項(xiàng)目特征,完成配網(wǎng)工程項(xiàng)目特征屬性的提取和標(biāo)記,使得即便不同省份對(duì)配網(wǎng)項(xiàng)目的管理水平不一致,也可以使用同一維度標(biāo)尺進(jìn)行衡量,便于后續(xù)與其他數(shù)據(jù)聯(lián)合開(kāi)展關(guān)聯(lián)分析。
4 研究結(jié)論
首先通過(guò)計(jì)算自然語(yǔ)言的內(nèi)部凝聚程度和外部自由運(yùn)用程度兩個(gè)指標(biāo)可以幫助從冗雜的文本片段中篩選出符合閾值篩選條件的詞語(yǔ),創(chuàng)建出符合國(guó)網(wǎng)公司自身業(yè)務(wù)特點(diǎn)的專業(yè)配網(wǎng)電網(wǎng)詞典,接下來(lái)結(jié)合文本挖掘工具即可較為簡(jiǎn)單地根據(jù)個(gè)性化選擇規(guī)則對(duì)項(xiàng)目名稱實(shí)現(xiàn)匹配、分詞,提取配網(wǎng)工程項(xiàng)目的特征值,以描述項(xiàng)目特征、建設(shè)內(nèi)容、工程屬性等。另一方面,通過(guò)聚類方法可以減少提取特征值的數(shù)量,使具有相同工程建設(shè)性質(zhì)和建設(shè)內(nèi)容的項(xiàng)目合并成一個(gè)項(xiàng)目群,并基于業(yè)務(wù)理解為44個(gè)項(xiàng)目群分別命名,因此該分詞結(jié)果更為標(biāo)準(zhǔn)清晰,同時(shí)也簡(jiǎn)化了分類維度,有利于支撐后續(xù)與其他數(shù)據(jù)之間的聯(lián)合分析。
參考文獻(xiàn):
[1] 鄧建,李夕兵,古德生.結(jié)構(gòu)可靠性分析的多項(xiàng)式數(shù)值逼近法[J].計(jì)算力 學(xué)學(xué)報(bào),2002(11):26-30.
[2] 李慶陽(yáng),王能超,李大義.數(shù)值分析[M].武漢:華中工學(xué)院出版社,1982.
[3] 王淑云,方保镕,王如云.數(shù)值分析方法[M].南京:河海大學(xué)出版社,1996.
[4] I.Babuska,W.C.Rheinbold.Error estimates of adaptive finite element
computations[J].SLAM Journal of Numerical Analysis,1978(4):
736-737.
[5] B.Moller,M.Beer,W.Graf,etal.Fuzzy finite element method and its
application[M].Trends in computational structural mechanics,2001:
529-538.
[6] 劉信恩,肖世富,莫軍.用于不確定性分析的高斯過(guò)程響應(yīng)面模型的設(shè) 計(jì)點(diǎn)選擇方法[J].計(jì)算機(jī)輔助工程,2011,20(1):101-105.
猜你喜歡
科技資訊(2017年5期)2017-04-12 15:18:52
電腦知識(shí)與技術(shù)(2016年33期)2017-03-21 08:13:37
商情(2016年32期)2017-03-04 00:27:28
軟件導(dǎo)刊(2016年12期)2017-01-21 15:55:21
電子技術(shù)與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國(guó)遠(yuǎn)程教育(2016年9期)2016-11-19 12:26:00
中國(guó)中醫(yī)藥圖書情報(bào)(2016年4期)2016-10-20 23:35:25
湖南師范大學(xué)學(xué)報(bào)·自然科學(xué)版(2016年3期)2016-06-25 06:47:25
語(yǔ)文教學(xué)之友(2016年5期)2016-06-15 12:15:44
