基于決策樹技術的倉儲企業綜合競爭力評估研究
2016-05-31 08:55:00孟強
物流科技 2016年5期
孟強
摘 要:文章運用SQL Server 2008商務智能平臺和決策樹分析技術,通過構建決策樹挖掘模型,對倉儲企業的綜合競爭力進行了科學的、準確的、合理的評估分析,實現了認知規則的提取和知識的發現,具有一定的理論和現實意義。
關鍵詞:決策樹;倉儲企業;評估;SQL Server 2008
中圖分類號:F253 文獻標識碼:A
Ahstract: The use of SQL Server 2008 business intelligence
platform and decision tree analysis technology, by constructing a decision tree mining model, comprehensive competitiveness of enterprise logistics were analyzed and the scientific, accurate and reasonable assessment. The cognitive rules extraction and knowledge discovery have certain theoretical and practical significance.
Key words: decision tree; storage enterprise; evaluation; SQL Server 2008
倉儲業是物流業的重要組成部分,也是第三產業中的獨立行業,近10年來,我國經濟持續穩定高速增長,電子商務迅猛發展,促使物流業的規模不斷擴大,傳統物流企業逐步轉型,現代物流發展的生態環境日益優化,物流基礎設施和信息化建設進度加快,現代物流服務體系已逐漸形成,倉儲物流配送服務的能力和水平得到了顯著的提高,現代物流業已成為現代服務業的重要支撐。然而,與西方發達國家相比,我國倉儲業的發展還不夠成熟,存在著許多不足,需要進一步加強和完善現代倉儲物流體系的構建,并對倉儲物流企業進行綜合評估和考察,促使倉儲物流企業競爭、創新和發展,不斷提升倉儲物流企業的服務質量和綜合競爭力,以更好地適應現代倉儲業的發展。
1 SQL Server 2008 BI平臺概述
Business Intelligence Development Studio,即微軟公司SQL Server 2008商業智能平臺,被用于創建和使用數據挖掘模型,通過對該平臺中數據挖掘算法和工具的使用,進而為企業提供有價值的、高效的、可靠的商務智能決策方案。
SQL Server 2008系統結構主要包括4個部分,即數據庫引擎、分析服務(Analysis Services)、報表服務(Reporting Services)和集成服務(Integration Services)。在用BI平臺進行數據挖掘時,主要使用的是Analysis Services,它不僅能夠被用來進行多維數據分析,還能創建數據挖掘結構和模型,并且提供了9種比較常用的數據挖掘技術(Microsoft Naive Bayes、關聯規則、聚類分析、決策樹、邏輯回歸、神經網絡、時序、線性回歸、順序分析和聚類分析),除此之外用戶還能自定義算法。
2 決策樹簡介
數據挖掘的本質就是知識發現的過程,它是從海量的數據中提取有價值的、對人們有用的信息和知識[1],而決策樹是數據挖掘技術中常用的一種,在分類和預測中運用比較廣泛,該技術就是通過分析已知類別訓練集,挖掘并發現分類規則,再對未知數據的類別進行分析預測,從而給決策者提供參考[2-3]。
據此可知該技術的實施一般分為模型訓練和應用兩個步驟[4],該方法具有以下幾個優點:方法簡單,計算量較小;容易挖掘和發現有價值的規則;連續和離散字段均能適用;能夠明顯直觀地顯現出各字段的重要性程度。然而也存在一些不足,比如對連續字段和時間順序這樣的字段需要進一步轉化處理,類別太多會增加錯誤決策的概率等。
3 數據挖掘的ETL過程
3.1 數據的獲取和導入
根據挖掘和分析的需要,文章隨機從物流產業大數據平臺[5]中抽取全國倉儲物流企業相關數據集,該樣本數據集合共有400條記錄,每條記錄主要選取了10個相關屬性,其屬性名稱分別為Comp_ID(企業ID)、Comp_Name(企業名稱)、Comp_Prop(企業性質)、Region(所屬區域)、Address(企業地址)、Cont_Way(聯系方式)、Asset(TTY)(企業資產(萬元))、Income(TTY)(企業經營收入(萬元))、Comp_Numb(企業員工數)和Comp_Eval_Result(企業評估結果)。通過Excel對所需數據進行初步的匯集和整理,再運用SQL server 2008 Management Studio所提供的數據導入功能,進行數據的導入并創建Basic_Info(基本信息)表,儲存在事先已創建好的名為倉儲物流企業綜合競爭力評估系統數據庫中。
3.2 數據的清洗和轉換
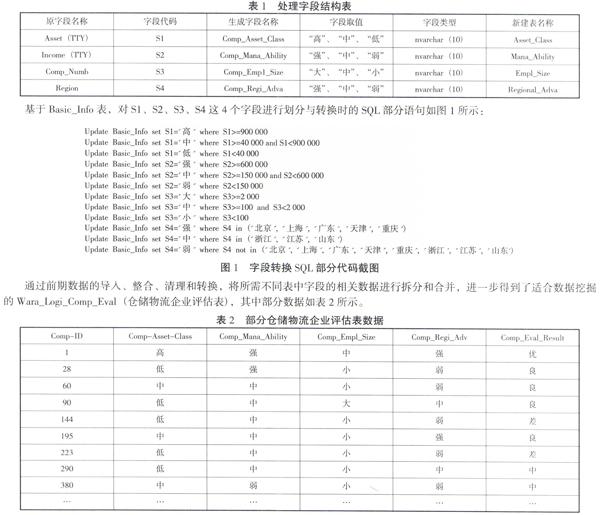
在隨機抽取的400條數據中,數據可能并不是非常完整,不能被直接用來進行數據分析,需要根據分析需求對數據本身做進一步的處理,也就是所謂的查缺補漏工作。如果某條記錄超過3個屬性值為空,則放棄錄入該條數據。為了能夠更好地對倉儲物流企業的綜合競爭力進行評估,需要對相關數據進行轉換,基于Basic_Info表,需要對Asset(TTY)、Income(TTY)、Comp_Numb和Region字段的數據進行離散化處理轉換,也就是把待處理字段的每個取值用“字符串”的形式進行處理轉換[6],然后把各字段轉換后的值存儲在數據庫中,其轉換處理字段的具體結構如表1所示。文章將Asset(TTY)(企業資產(萬元))按照“高”、“中”、“低”3個級別進行劃分、轉換并生成Comp_Asset_Class(企業資產級別)字段,基于此創建Asset_Class(資產級別表);將Income(TTY)(企業經營收入(萬元))按照“強”、“中”、“弱”3個級別進行劃分、轉換并生成Comp_Mana_Ability(企業經營能力)字段,基于此創建Mana_Ability(經營能力表);將Comp_Numb(企業員工數)按照“大”、“中”、“小”3個級別進行劃分、轉換并生成Comp_Empl_Size(企業員工規模)字段,基于此創建Empl_Size(員工規模表);將Region(所屬區域)按照“強”、“中”、“弱”3個級別進行劃分、轉換并生成Comp_Regi_Adva(企業區域優勢)字段,基于此創建Regional_Adva(區域優勢表)。
基于Basic_Info表,對S1、S2、S3、S4這4個字段進行劃分與轉換時的SQL部分語句如圖1所示:
通過前期數據的導入、整合、清理和轉換,將所需不同表中字段的相關數據進行拆分和合并,進一步得到了適合數據挖掘的Wara_Logi_Comp_Eval(倉儲物流企業評估表),其中部分數據如表2所示。
4 決策樹挖掘模型的創建及準確性驗證
4.1 挖掘結構和模型的構建
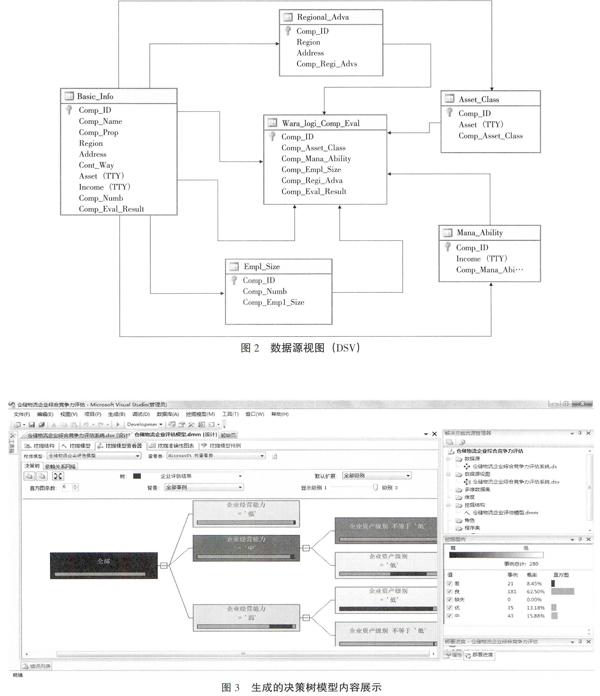
啟動BI Dev Studio,在開發環境中新建名為“倉儲物流企業綜合競爭力評估”的Analysis Services項目,以及定義項目保存位置信息和解決方案名稱,然后創建數據源和數據源視圖(DSV),最終所建DSV如圖2所示。
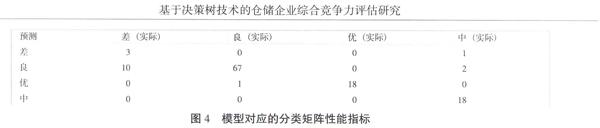
然后按照數據挖掘向導的提示,逐步構建挖掘結構和挖掘模型,在創建的過程中,需要重視測試集的創建,即指定要為模型測試保留的事例數,一般需要指定測試數據百分比和測試數據集中的最大事例數,通常指定測試數據百分比為30%。本文隨機抽取120個作為測試集,用來測試和檢驗模型,剩余280個作為訓練集,用來生成規則。最后將所創建的數據挖掘結構和模型都命名為“倉儲物流企業評估模型”。該挖掘模型成功部署處理之后,就可以查看所創建的挖掘結構、挖掘模型、挖掘模型查看器、挖掘準確性圖表和挖掘模型預測相關的各種信息,通過挖掘模型查看器可以查看所生成的決策樹如圖3所示。
4.2 模型的準確性驗證
4.2.1 分類矩陣
分類矩陣(Classification Matrix)也稱無秩序矩陣,它能夠精確地顯示該算法測試的結果正確的次數,并且顯示錯誤的預測是什么。本文所創建的決策樹挖掘模型選取對應的測試集共400*30%=120個事例來對所生成的挖掘模型進行測試并將測試結果以分類矩陣的形式加以表示,如圖4所示。
根據分類矩陣所顯示的內容可知,本模型預測的結果為:真“差”事例數目為3,假“差”事例數目為1;真“良”事例數目為67,假“良”事例數目為12;真“優”事例數目為18,假“優”事例數目為1;真“中”事例數目為18,假“中”事例數目為0[7]。綜上所述,可求出本模型在測試集上的平均分類評估的準確率為:(3+67+18+18)/(3+1+10+67+2+1+18+18)
≈88.33%,該結果表明模型具有較強的可靠性。
4.2.2 挖掘提升圖
提升圖是按照測試數據集中可預測列的已知值來繪制從該測試數據集進行預測查詢的結果,并同時展示理想模型、隨機模型和所建模型的結果。本文測試數據集中共有120個事例,可以得到企業評估結果(可預測字段)分別為“優”、“良”、“中”和“差”不同條件下的模型所對應的提升圖,文章僅給出企業評估結果為“良”條件下模型所對應的提升圖(如圖5所示)及其相應的挖掘圖例(如圖6所示)。
從提升圖(圖5)明顯可以看出,紅色曲線不斷向綠色曲線靠攏,也就是所構建模型的提升曲線十分靠近理想模型的提升曲線,此外由挖掘圖例(圖6)可知分數為0.99,非常接近1,所以該模型性能非常好,且具有較高的預測準確率。
4.2.3 綜合競爭力評估依賴關系
通過挖掘模型查看器進行模型挖掘,查看倉儲物流企業綜合競爭力評估主要強依賴關系如圖7所示,在Wara_Logi_Comp_Eval(倉儲物流企業評估表)中,若干字段包括Comp_Mana_Ability(企業經營能力)、Comp_Asset_Class(企業資產級別)、Comp_Empl_Size(企業員工規模)和Comp_Regi_Adva(企業區域優勢),對倉儲物流企業綜合競爭力評估影響最大的是企業經營能力,其次是企業資產級別,對于較弱的依賴關系圖中并沒有顯示出來,這是由于微軟SQL Server 2008所提供的決策算法不同造成的,然而主要結論是一致的,那就是倉儲物流企業綜合競爭力評估主要依賴于企業經營能力和企業資產級別這兩個因素。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
物流技術與應用(2019年8期)2019-09-04 03:29:56
汽車觀察(2018年12期)2018-12-26 01:05:44
電力與能源(2017年6期)2017-05-14 06:19:37
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
現代企業(2015年2期)2015-02-28 18:45:09
