一種基于非監控學習的數據清洗算法
2016-06-02 05:55:08李景民吉林工商學院長春130062
黑龍江科學 2016年3期
關鍵詞:數據庫
李景民(吉林工商學院,長春130062)
?
一種基于非監控學習的數據清洗算法
李景民
(吉林工商學院,長春130062)
摘要:在數據庫的應用中經常會出現數據的“相似重復記錄”問題,筆者提出一種基于非監控學習的數據清洗算法。這種算法主要采用了基于非監控學習的方法,在學習過程中能夠結合需要增添新的聚類,去除錯誤聚類,進而能夠避免出現死神經元問題,經實驗數據證明可以有效地實體識別。
關鍵詞:非監控學習;數據清洗;數據庫;數據轉換
在現代高等院校科研系統信息化的建設過程中,管理人員發現存在數量龐大的異構系統、海量的資源。面對如此多的不同來源、較為分散和清潔度不夠的信息,科研系統管理人員需要提煉有效信息,以供決策,因而急需信息集成和整合的行之有效的方法。創建數據倉庫的主要目標是提供準確的數據,為數據分析服務,為科研領導的決策提供參考。為了能夠對正確決策提供足夠的支持,需要依據的參考數據應該是可靠的,沒有偏差的,以體現科研的實際情況[1,2]。鑒于以上的環境及需求,ETL技術作為一種工具和手段蓬勃發展起來。ETL主要是指數據抽取、轉換、清洗、加載的過程。ETL是建立數據倉庫非常重要的一個步驟,管理員從數據源中提煉出需要的數據,經過數據轉換及數據清洗過程,最后根據事先確定好的數據倉庫模型,把數據最終加載到數據倉庫中去。
在科研管理系統當中,由于數據倉庫中的數據可能來源于多種不同的數據源,該數據源又可能存在于差異的硬件平臺上,數據庫管理系統也千差萬別,這就導致這些數據在很多方面都是不同的,甚至是相互沖突的,所以控制數據質量成為極為重要的問題。
1 ETL技術中的數據質量控制方法
1.1數據質量問題的類別
在科研管理系統中進行數據ETL過程時,管理者有可能碰到形形色色的數據質量問題,有必要將它們進行分類管理。通過總結該問題的產生究竟是在模式層還是在實例層,進而把數據質量問題進一步劃分成四大類:A.單數據源模式層問題。B.單數據源實例層問題。C.多數據源模式層問題。D.多數據源實例層問題。
如果在模式層次上存在問題,那么在實例層次上會有相應的體現,不好的數據模式設計、定義的完整性約束缺乏、多個數據源之間命名沖突以及結構沖突等,全部都是這類問題。人們可以采用改進模式設計、模式轉化和模式集成的方法解決模式層次上的問題。目前主流的方法是通過相關問題域的專家,采用手工方法來處理此類問題,但是效率低下。
1.2數據質量評估方法
在高校科研系統中,需要解決不同數據質量的異常問題,首要任務是分析產生異常的根源。導致數據異常的因素較多,可能是系統自身的原因,也可能是歷史因素[3]:在不同階段,系統的數據模型可能存在差異;相應的處理過程有所區別;新舊幾套系統模塊處理財務、人事等有關信息時有所區別;老舊系統與新增業務以及管理系統數據在進行集成時的不完備也會產生差異;源系統在數據輸入時沒有對數據進行數據驗證,無法攔截不合格的數據輸入到系統。分析數據質量應該從以上幾個方面進行考量,評估采集到的具體數據源,衡量數據源的質量,進而確定采用的ETL規則。
2 基于非監控學習的數據清洗策略
2.1數據清洗
所謂數據清洗就是在檢測數據集中過程之后出現的錯誤和差異,并通過人工或者自動化工具將其刪除和修正,進而提升數據質量。
在對實例層次的數據進行清洗的過程中,即使通過模式轉化和集成取得了一致模式,在實例層上依舊需要對不一致性進行清除,關鍵是對缺損屬性修正,并進行相應的實體識別。處理缺損屬性時,主要是針對不確定信息的理論,對于不完全數據,需要進行推理和相應的研究,并且提出合適的規則。在實體識別時,對于相同的實體,在不同的數據源的記錄中,有可能標識的主鍵是不同的,這些信息在內容上互為補充,可能存在冗余情況,嚴重時甚至會有互相矛盾的情況。
針對相似重復記錄的處理方式,筆者采用了非監控的學習方法,以此來處理數據集中過程中的實體識別困難。非監控學習是針對海量的、未標記的數據分析的聚類技術。主要目的是提供一系列類,而且要求相同類中數據的特性要保持一致,類別不同的數據要有明顯的、便于區分的差異。
2.2非監控學習算法
這種學習方法主要包括競爭學習和增強式學習兩種方法。筆者在實體識別中總結出采用基于Hebbian假設的一種非監控的學習算法。
由Hebbian的假設,神經元的學習規則能夠用如下的函數進行表示:
表達式中的W為突觸權值向量,X表示輸入樣本向量,ψ()是可微函數,α≥0是遺忘系數。神經元的輸出為:
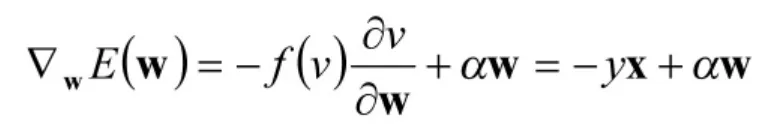
2.3非監控學習算法性能測試
在對非監控學習算法性能進行測試的過程中,設計了兩組數據。其中一組是系數σ=0.05服從高斯分布的測試數據,另外一組是系數σ=0.5測試數據。結果是σ=0.05,數據相對集中,聚類邊界明顯;σ=0.5,數據不集中,聚類邊界不夠清晰。
因為從多數據源當中直接進行對象識別具有非常大的困難,所以我們可以把整個識別過程分成不同的階段來完成。
3 結論
在進行數據清洗操作中,利用非監控學習算法處理在實體識別方面的問題,完成“相似重復記錄”的查詢,可以進一步提高清洗的準確程度。
參考文獻:
[1]Wand Y,Anchoring Wang R Y.Data Quality Dimensions In Ontological Foundations[J].Commun ACM39,1996,(11):86- 95.
[2]Strong Diane M,Lee Yang W,Wang Richard Y.Data Quality In Context[J].Commun ACM40,1997,(05):103- 110.
[3]郭志懋,周傲英(Guo Z.M., Zhou A.Y.).數據質量和數據清洗研究綜述(Research on Data Quality and Data Cleaning:a Survey)[J]軟件學報(Journal of Software),2002,13(11):2076- 2082.
中圖分類號:TP311.13
文獻標志碼:A
文章編號:1674- 8646(2016)02- 0044- 02
收稿日期:2015- 12- 19
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
