基于相關向量機的SPOC成績預測模型構建
2016-06-07 08:32:08馬潔明李池利班建民奚雪峰付保川
蘇州科技大學學報(工程技術版) 2016年1期
馬潔明,李池利,王 儉,班建民,奚雪峰,付保川
(1.蘇州科技學院電子與信息工程學院,江蘇蘇州215009;2.湖北工業大學外國語學院,湖北武漢430068)
?
基于相關向量機的SPOC成績預測模型構建
馬潔明1,李池利2,王儉1,班建民1,奚雪峰1,付保川1
(1.蘇州科技學院電子與信息工程學院,江蘇蘇州215009;2.湖北工業大學外國語學院,湖北武漢430068)
摘要:SPOC是互聯網與傳統校園教學的有機結合。作為信息化教學平臺的一部分,成績預測模型可為學生相關課程成績進行合理預測。針對SPOC學生成績樣本數量小的特點,提出一種基于相關向量機的概率式成績預測方法。結果表明,模型較神經網絡等傳統數據挖掘方法有更精確的預測性能,有助于師生及時了解掌握知識的程度,提高教學質量,為推廣SPOC提供技術支持。
關鍵詞:相關向量機;成績預測;SPOC
在教育全球化和信息化的背景下,MOOC(Massive Open Online Course)概念被廣泛應用到教學實踐中。MOOC是基于課程與教學論及網絡和智能技術發展起來的新興在線課程形式[1]。然而,在當前的信息技術條件下,以脫離實體學校的大規模在線學習還難以完全替代傳統課堂[2]。加州大學伯克利分校的MOOC負責人Armando Fox提出通過網絡教學資源來改變傳統高等教育現狀的一種解決方案—SPOC(Small Private 0nline Course)。SPOC針對小規模、特定人群,采用講座視頻及在線評價等功能作為校園課堂的教學輔助手段,是MOOC與傳統校園教學的有機融合。SPOC不但可有效地彌補MOOC課程缺乏學習氣氛、平均完成率低等缺陷,而且在教學改進中引入數據分析模塊。成績預測是SPOC教學中評價教學質量和學習效果不可或缺的分析模型,其利用數據挖掘的方法,從學生的現有成績和其他相關信息對學生知識掌握程度進行綜合預測,及時預警學習狀況不良的學生,為教學管理部門提供決策支持信息,促進教學質量的提高。
近年來,數據挖掘方法,如BP(Back Propagation)神經網絡[3]、遺傳算法[4]、決策樹[5]等被應用于成績預測。BP神經網絡是一種按誤差逆傳播算法訓練的多層前饋網絡,是目前應用較廣的神經網絡模型。決策樹通過歸納和提煉現有數據所包含的規律,建立預測模型,實現對新數據的預測。這兩種模型往往需要大量數據樣本才能達到較好的預測結果,適用于數據較多的學生成績統計系統。遺傳算法是模擬達爾文生物進化論自然選擇和遺傳學機理的優化計算模型,但迭代過程中容易陷入局部極小點。文章提出基于相關向量機(Relevance Vector Machine,RVM)[6]的成績預測模型,以解決在SPOC課程樣本數量小,常規數據方法難以精確預測的問題。
1 基于相關向量機的學生成績預測
RVM是由美國Tipping博士2000年提出的基于稀疏貝葉斯學習理論的算法模型。RVM根據有限的樣本信息,通過事先選擇的核函數(非線性映射),將低維輸入變量映射到一個高維的特征空間,在貝葉斯框架下估計回歸函數映射到高維空間的輸出,在模型的學習能力和復雜度之間尋求最佳折中,因此在回歸和預測領域得到廣泛應用[7,8]。設{xi}Ni=1為給定RVM訓練樣本集,為目標值,RVM的輸出模型如圖1,可數學表達為
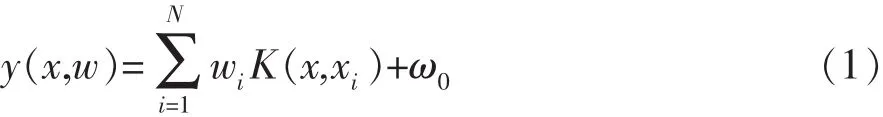
式中,K(x,xi)為核函數,wi為權值,N為樣本數,w是由wi組成的向量。可以合理地假定目標值是彼此獨立的,可用概率來表示帶噪聲的模型

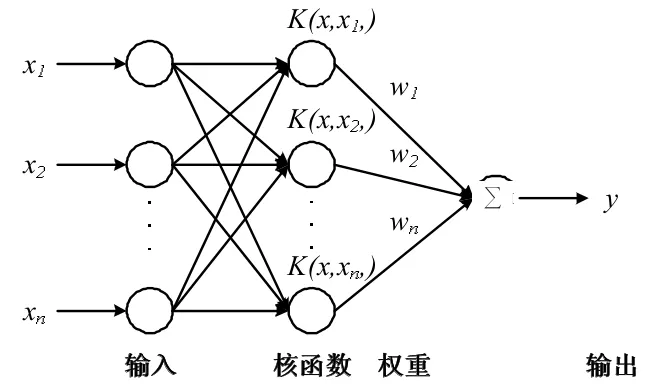
圖1 RVM模型結構
其中,εi為服從Gauss分布N(0,σ2)的噪聲,在已知{xi}Ni=1和σ2條件下,tt的分布如下
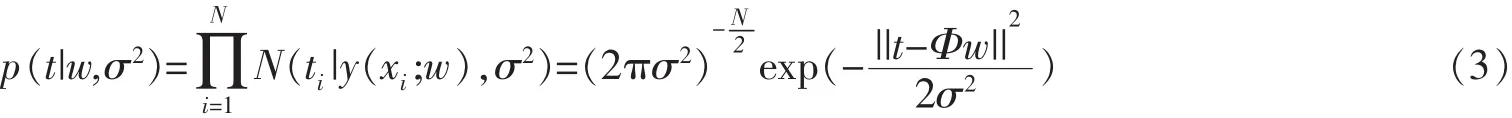
Φ是由xi{代入核函數所得的N×(N+1)矩陣,即
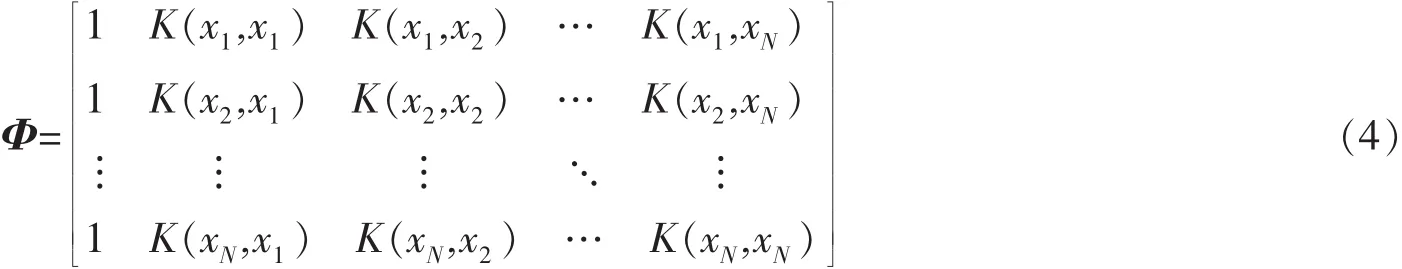
通過最大似然法可求出最優w,但可能導致過度擬合。為避免這種情況,采用稀疏貝葉斯方法對權值賦予先驗條件:w分布于0周圍的高斯分布,可表示為
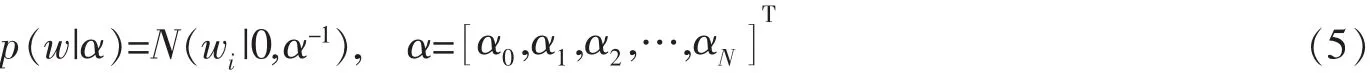
α用于描述每個wi的反向變異。上式表明,每個權值與超參數αi相關,控制著先驗條件的影響程度。未知參數w、α和σ2的先驗概率可表示為P(w,α,σ2|t),根據貝葉斯公式,可寫為其中

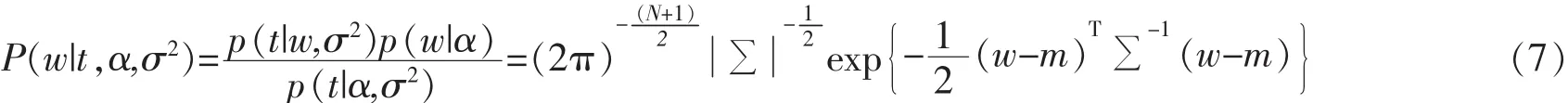
后驗協方差∑=(σ-2ΦTΦ+A)-1,m=σ-2∑ΦTt,A=diag(α0,α1,α2,…,αN)。

后驗概率P(α,σ2|t)不能通過分解求得,因此引入狄拉克函數做近似計算αMP和σ2MP為P(α,σ2|t)的最優解,由于P(α)P(t|α,σ2|)P(α)P(),在一致超先驗條件下,可忽略P(α)和P(σ2),對P(α,σ2|t)的極大極小估計轉化為最大化P(t|α)

其中,P(t|w,σ2)和P(w|α)服從如下分布
胃病是臨床上常見病。胃病與人的生活飲食無規律、心理壓力過大等有較大關系。在胃病患者護理實踐中,心理護理主要從患者心態的調適上,增加治療效果。
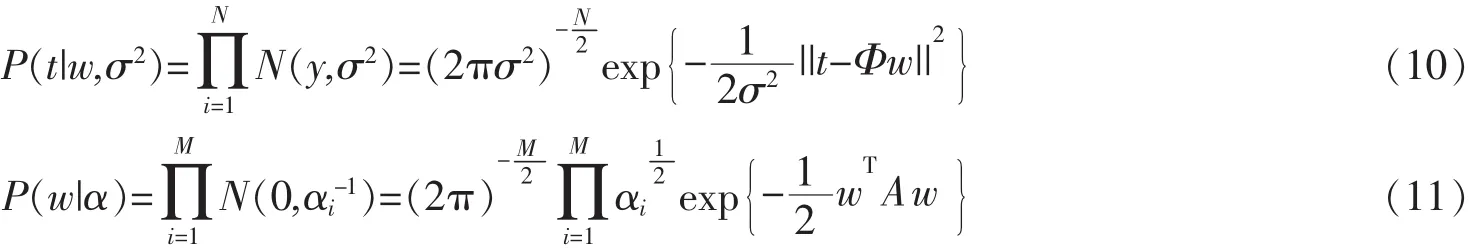
M為x的維度,將式(10)與(11)代入(9),簡化整理后得
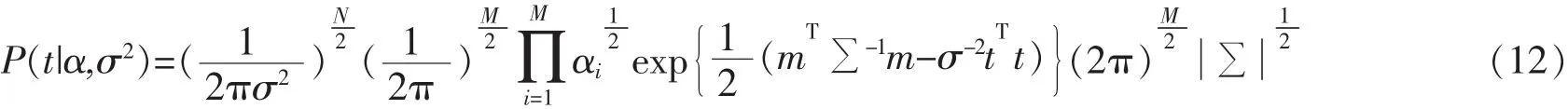

其中,∑ii為后驗權協方差矩陣的第i個對角元素。由于不能直接求得m,可以反復迭代估計αi和σ2的值以實現相關向量學習。
1.2算法實現
文章以RVM進行學生成績的仿真估計與預測。算法的學生成績輸入為xi{,xi可為包括D維成績的向量,綜合成績的預測值為輸出。由于成績的評價方式多樣,在執行算法前往往對數據進行歸一化處理。RVM通過在w上定義受超參數控制的高斯先驗概率,利用自相關判定理論來移除不相關的點,得到稀疏化模型,與支持向量機(Support Vector Machine,SVM)相比,不但適合小樣本預測,而且減少了核函數計算量,具體見以下算法:
Algorithm 1基于相關向量機的成績預測
Input:學生現有成績x=[x0,x1,x2,…xN]T
Output:學生綜合成績預測值t=[t0,t1,t2,…tN]T1:數據歸一化處理
2:選擇和σ2起始值
3:while αi>αmindo
4:計算m=σ2∑ΦTt和∑=(A+σ2ΦTΦ)-1
5:根據公式(13)和(15)更新α、σ2
6:end while
7:預測成績t=mTΦ(x')
2 實驗驗證
SPOC課程往往通過離線調查、在線測試等方式采集學生成績。為評價RVM的預測效果,選用24個學生在某課程中取得的教師評價數據,包括課堂的考勤、作業成績、期末考試成績。同時通過自評互評的方式,了解學生對課堂考勤、作業成績、課程難度及對課程的興趣,見表1。
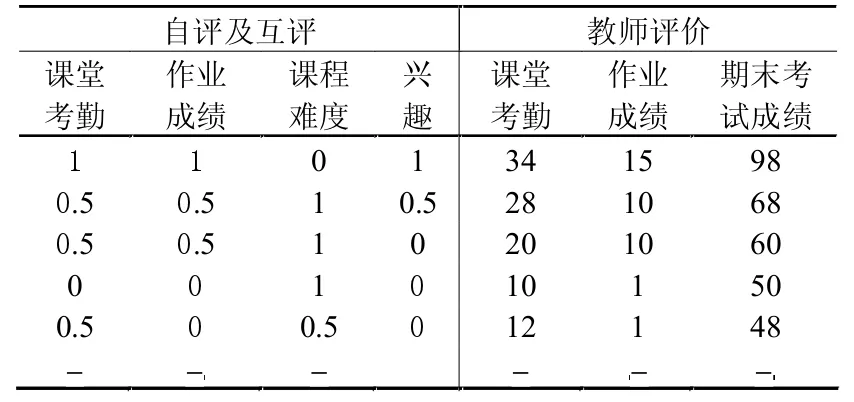
表1 原始輸入數據
設教師對課堂考勤、作業成績以及學生自評及互評成績為預測模型的輸入。表1中,學生自評及互評成績通過數據標準化處理,課堂考勤及作業成績分為0,0.5,1三個等級,分別表示優、中、差。同理,課程難度與學生對課程感興趣程度也分為0,0.5,1三個層次,分別表示程度的高、中、低。設期末考試為需要預測的結果,采用RVM、SVM(懲罰參數c=362.049和核函數參數g=0.016)、BP神經網絡(雙隱含層,每層節點數為5)和隨機森林對表1中的數據進行預測。圖2比較了四個模型的預測能力,模型的預測結果越精確,則其與實際成績的比值與斜線y=x越接近。不難發現,SVM、BP神經網絡和隨機森林在[20,40]和[80,100]兩個區間內有較大的誤差,RVM預測成績與實際成績的比值較接近于1。為量化各模型的預測能力,可采用擬合優度(決定系數)對預測結果進行評價。經過仿真計算,RVM、SVM、BP神經網絡的擬合優度分別為0.984 9,0.933 5,0.890 8,0.942 2,證實了RVM在小樣本數量情況下表現出最好的預測能力。
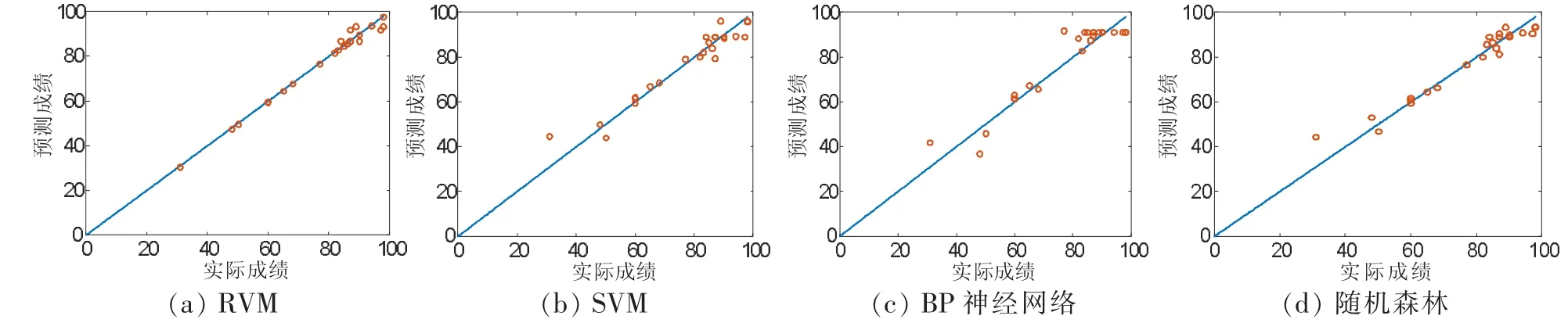
圖2 不同模型預測結果比較
3 結語
文章面向SPOC課程提出了一種基于RVM的學生成績預測模型。根據實例,提出的模型擬合優度較SVM和隨機森林提高了約5%,較BP神經網絡提高了近10%,說明了RVM模型在小樣本數量概率式預測中有更好的精度和有效性。該模型方便教師實時掌握學生學習狀況,同時也可為相關學生提供預警作用,為SPOC課程的推廣提供了依據和數據基礎,有較好的應用價值。
參考文獻:
[1]康葉欽.在線教育的“后MOOC時代”——SPOC解析[J].清華大學教育研究,2014,35(1):85-93.
[2]鄭奇,楊竹筠.SPOC:結合高校教學的融合創新[J].物理與工程,2014,24(1):15-18.
[3]鄒麗娜,丁茜.基于BP算法的成績預測模型[J].沈陽師范大學學報,2011,29(2):226-229.
[4]羅永國.基于改進的遺傳算法的學生成績預測模型[J].科技通報,2012,28(10):223-225.
[5]商俊燕,陸兵,柏倩然.決策樹C4.5算法在學生成績分析中的應用[J].微型電腦應用,2015,31(4):43-52.
[6] DEH W.Time series prediction for machining errors using support vector regression [C]//Pro of the 1st International Conference of Intelligent Networks and Intelligent Systems,2008:27-30.
[7] YUAN J,YU T,WANG K S,et al.Adaptive spherical gaussian kernel for fast relevance vector machine regression [C]//Proc of the 7th World Congress on Intelligent Contrnl and Automation,2008:2071-2078.
[8] SHEN Y,LIU G H,LIU H.Classification method of power quality disturbances based on RVM [C]//Proc of the 8th World Congress on Intelligent Control and Automation,2010:6130-6135.
[9]黃芳.基于數據挖掘的決策樹技術在成績分析中的應用研究[D].山東:山東大學,2009:1-47.
(責任編輯:盧文君)
Students’grade prediction model using relevance vector machine
MA Jieming1,LI Chili2,WANG Jian2,BAN Jianming2,XI Xuefeng1,FU Baochuan1
(1.School of Electronic and Information Engineering,SUST,Suzhou 215009,China; 2.School of Foreign Languages,Hubei University of Technology,Wuhan 430068,China)
Abstract:Small Private Online Course(SPOC)combines E-learning and traditional campus teaching.As a module of digital teaching platforms, the grade prediction model is capable of predicting a reasonable grade for students in a course.Since SPOC is featured with its small sample size, a probabilistic grade prediction model is proposed based on Relevance Vector Machine(RVM).Compared with the data mining methods like neural networks, simulation results show that the RVM exhibits more accurate prediction performance, helping teachers and students to keep abreast of the degree of mastery of knowledge, improve teaching quality, and provid technical supports for the promotion of SPOC.
Key words:relevance vector machine; grade prediction; SPOC
中圖分類號:TM311
文獻標識碼:A
文章編號:1672-0679(2016)01-0077-04
[收稿日期]2015-09-14
[基金項目]江蘇省教改重點項目(2013JSJG063);江蘇省高校自然科學基金項目(15KJB480002)
[作者簡介]馬潔明(1984-),男,江蘇蘇州人,講師,博士,從事人工智能及其應用方面的研究。
