主題爬蟲的主題相關度算法研究
2016-06-22 09:18:00徐楊王未央上海海事大學信息工程學院上海201306
現代計算機 2016年14期
徐楊,王未央(上海海事大學信息工程學院,上海 201306)
?
主題爬蟲的主題相關度算法研究
徐楊,王未央
(上海海事大學信息工程學院,上海201306)
摘要:
關鍵詞:
0 引言
伴隨著互聯網的發展,網絡資源日益豐富。傳統通用搜索引擎的弊端日益突顯,資源的覆蓋率、搜索結果的準確性和相關性均有所下降,用戶的搜索難度日益增大。于是,垂直搜索引擎應運而生,在近幾年得到了快速的發展,并成為搜索引擎領域的發展的熱點和難點之一。
對于搜索引擎而言,網絡爬蟲是核心模塊。在傳統搜索引擎中,網絡爬蟲將網絡資源不加區分地爬取下來,然后通過以PageRank算法為核心的排序算法對網頁進行打分,并按得分高低排序。而垂直搜索引擎則是針對特定主題的網絡資源進行下載和整合的,具有更專業、更具體,以及更高的主題相關度。主題爬蟲是垂直搜索引擎為用戶提供高相關度檢索結果的核心部分所在。
針對主題爬蟲的主題相關度識別,本文提出一種利用兩步向量空間模型算法的主題相關度識別的方法。第一步空間向量模型算法用于計算當前頁面的主題相關度,第二步空間向量模型算法用于計算當前頁面所包含所有出度鏈接的主題相關度,用于對當前待爬取鏈接進行排序,進一步確定主題相關度的高低,防止主題漂移。經實驗表明,該爬蟲在主題相關的識別的準確度和運行效率均表現良好。
1 相關知識
在傳統主題爬蟲中,主題相關度識別方法主要有基于內容的識別和基于鏈接分析的識別。
基于內容評價的搜索策略主要是根據鏈接頁面內容與主題之間的相似度來評價鏈接價值的高低。主要以向量空間模型為基礎,通過將頁面文檔映射成向量,與主題詞集向量進行余弦值計算,然后將之與人為設定的閾值進行比較,高于閾值表示符合主題相關度,低于閾值則丟棄該頁面。但是這種主題識別策略存在一定的問題,例如一些頁面設置虛假關鍵詞可能會導致相關度計算失真,并且忽略了鏈接在網絡中的相互關系,如果爬蟲繼續爬去頁面就會偏離主題。
而基于鏈接分析的主題爬蟲主要以PageRank算法為基礎,依靠PageRank算法來建立主題相關度模塊。然而PageRank的算法模型是建立在隨機訪問基礎之上的,也就是說用戶瀏覽當前網頁上的任意鏈接都是隨機的,也由此假定所有鏈接被用戶點擊的概率都是相等的。但實際上往往并非如此,頁面上的出鏈并不會被用戶以相等的概率而訪問,除此之外,更重要的是并非所有的出鏈都是符合主題相關度要求的,很容易造成“主題漂移”。因此主題爬蟲的相關度并不能單純依靠PageRank算法,需要引入更多的因子以提高主題爬蟲的相關度,從而更好地改善垂直搜索引擎的發展。
有人提出結合遺傳算法或者蟻群算法,引入網頁的被訪問數、創建時間等因子,但通常這些因子的獲取都需要過程,而且許多參數因子難以獲取,并且遺傳算法的不斷迭代的過程無疑延長了主題爬蟲的抓取數據的過程和爬蟲的執行效率。同時這種結合PageRank算法的主題識別方法要求以Web圖結構為基礎,而在爬取頁面并提取其中的URL后,Web圖也會相應地改變,所以計算量很大,會對爬蟲的速度造成一定的影響,并且在爬蟲爬行過程中,準確地計算出那些從來沒有被訪問過的網頁的PageRank值幾乎是不可能的。
在本文中依然采用向量空間模型作為頁面相關度計算的基礎,通過將頁面向量與手工設定的主題關鍵詞集向量的余弦值作為主題相關的大小,與閾值進行比較,而鏈接分析同樣以向量空間模型為基礎,通過計算頁面中所有出度鏈接的主題相關度的余弦值,作為當前頁面的主題相關度的加權系數,對待爬取鏈接進行相關度排序的同時進一步檢測頁面的主題相關度,防止“主題漂移”的產生,避免無關頁面的下載影響爬蟲的執行效率。
2 基于兩步空間向量模型的主題爬蟲策略
2.1主題詞集確立
主題爬蟲在工作前要確定該主題爬蟲的相關主題詞集。主題詞集的確定通常有兩種,一種是人工確定,另一種是通過初始頁面分析所得。本文中采用人工確定主題詞集,并為每個主題詞指定不同的權值。主題詞的個數作為主題向量的維數,而相應的權值則為主題向量的各個分量值。記主題詞集向量為:K={k1,k2,…,kn}(n為主題詞的個數)。
2.2頁面相關度計算
為了確保頁面與主題的相關度,盡可能避免“主題漂移”的發生,必須對頁面進行主題相關度計算,這是主題爬蟲至關重要的一個步驟,所以需要對鏈接所對應的頁面中的文本信息進行提取,以便進行主題相關度的計算。
本文關于頁面主題相關度的判別采用的是基于向量空間模型方法。向量空間模型概念簡單,通過計算頁面特征向量和主題中心向量的余弦距離來表示兩者的相似度,從而對當前頁面的主題相關度進行評價,直觀易懂。在對頁面預處理過程中,大量HTML標簽的存在帶來了一定的麻煩,但卻可以加以利用,從而進一步提高頁面相關度的預測。通常情況下,位于錨文本和標題處的文本信息要比在正文中出現的信息具有更高的重要性。因此,不同位置出現的關鍵詞對頁面信息的描述能力具有一定的差異性。那么,針對關鍵詞出現的不同位置,需要對關鍵增加額外的權重位置權重,這樣可以更好地反映頁面與主題的相關度。關鍵詞詞頻計算公式如下:

其中,wi代表不同位置的權重系數,fi表示關鍵詞在該位置出現的次數。

解決了位置權重問題,就可以通過向量空間模型,將頁面文本數據就轉換成計算機可以處理的結構化數據,頁面和主題詞集之間的相似性問題轉化成兩個向量之間的相似性問題了。計算公式如下:
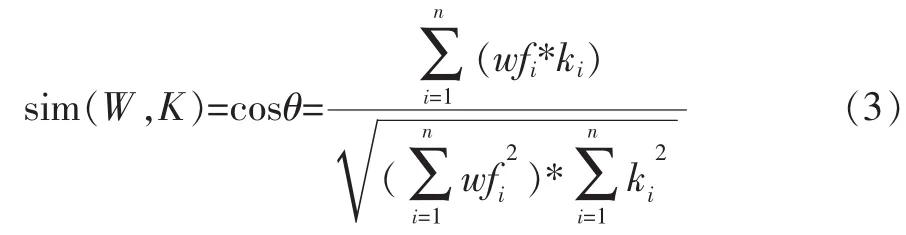
其中wfi表示頁面文本特征項的第i項特征值,ki表示主題詞集特征向量第i項特征值。相似度由向量的余弦值表示,用來衡量兩個個體之間的差異的大小,當余弦值越接近1時,就說明夾角越接近于0度,也就表示兩個向量越相似度越高,這也叫“余弦相似性”。
然而只運用向量空間模型算法對當前頁面進行相關度計算,往往存在一定的問題。例如,頁面中一些無關的友情鏈接的存在,虛假關鍵詞的設置等等都會造成對主題相關度的誤判,從而影響主題爬蟲的前行,偏離主題。此外,在當前頁面爬取完畢后,如何在待爬取隊列中眾多URL中選擇下一個爬取鏈接也是一個至關重要的問題。所以,要同基于鏈接分析的相關性評價結合使用,綜合考慮待分析鏈接之間的相關性。
2.3候選URL優先級排序
對候選URL進行優先級排序決定下一個爬行URL是主題爬蟲需要解決的另一個關鍵問題。在傳統主題爬蟲策略中往往采用基于PageRank算法的策略,通過考查頁面入度去計算鏈接之間的相互關系,對頁面進行“打分”,然后根據相應的評分高低進行優先級排序。但其中存在的一些問題在第1節已經做出相關敘述。
那么,我們不妨考慮一下頁面的出度。因為對于一個頁面而言,出度是明確的。網頁中所包含的出度鏈接,也就是指向其他頁面的鏈接信息,是近幾年研究中比較關注的對象,出度不僅反映頁面之間的相互關系,并且對于判別頁面的內容也具有很重要的作用。但是通過以往的研究表明,通過出度去研究頁面的主題,也具有一些弊端,例如廣告鏈接、版權信息、導航條以及一些無關的友情鏈接或者是一些惡意URL指向都可能造成判斷失真。因此,需要對這些不可靠的噪聲URL進行丟棄處理。
本文提出基于兩步向量空間模型的主題爬蟲策略,也就是在第一步判別頁面的主題相關度后,并不直接對頁面進行保留或丟棄處理,而是進一步判斷該頁面的出度URL頁面的主題相關度來對其進行與主題相關度的加權判斷。
然而存在一個問題,正如上文所述,在實際的情況中,頁面的出度鏈接中可能會對應一些噪音頁面,那么這些噪音頁面給予待分析URL的支持是不可靠的,那么就需要進行過濾。考慮到兩種情況,一種是待分析頁面的出度URL對應頁面集合中,大多數均有較高的主題相關度(此相關度仍用上節所述方法計算),但由少量出度頁面具有極低的相關度或者不相關,那么直接丟棄該出度URL,出度數也做相應的減少。另一種情況是,所有出度URL頁面集合均不具由高相關度,則直接忽略出度對待分析頁面的相關度貢獻。計算公式如下:
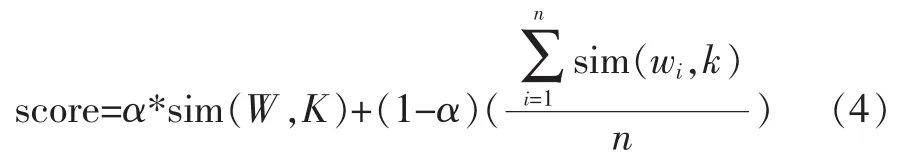
其中α為權重因子,score由頁面主題相關度和頁面出度URL對應頁面相關度兩部分組成,通過對score進行排序,從而選出下一個爬行的URL。舉例如下:
如圖1所示,假設初始URL由3個出度鏈接分別為a,b,c,而這3個候選URL又各自擁有3個出度鏈接。通過VSM計算,各頁面的主題相關度如圖2所示。那么基于傳統向量空間模型策略的主題爬蟲第二步就會去保存頁面a,然后繼續考察a頁面中的出度鏈接。實際情況下這種a,b,c的候選URL排序可能是不合理的,按照本文所提出的策略,需要在對a,b,c三條鏈接排序時,先分別對候選鏈接a,b,c的所有子URL進行主題相關度計算,假設結果如圖2所示,依據頁面出度信息對頁面主題相關度具有一定貢獻的原則,對候選URL進行重新加權計算。按照公式(4)可以計算的到,a的頁面的得分是0.7*0.9+0.3*((0.9+0.8+0.7)/3)=0.87(實驗表明α取值0.7附近時效果較好,故此處α取0.7),同樣,計算可得b,c的得分分別為0.65,0.76。通過公式3.1“打分”后,候選URL排序為a,c,b。
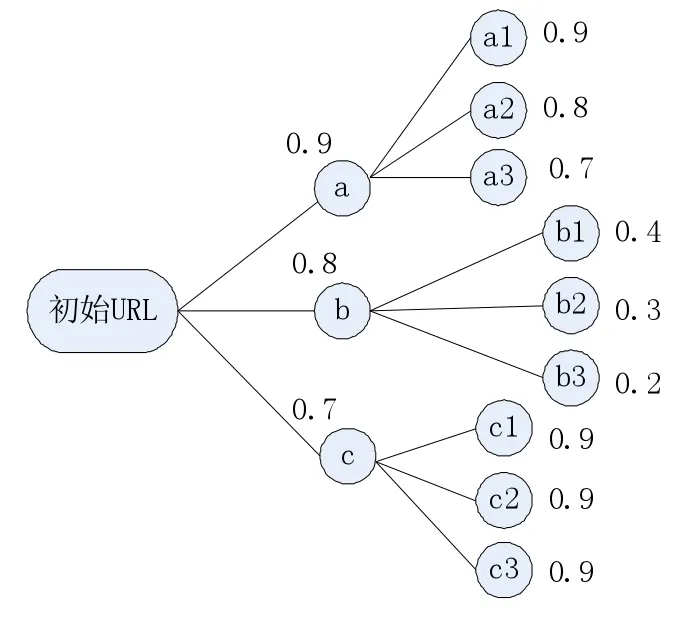
圖1 網頁Web簡圖
通過利用待分析頁面出度URL相關度的分析,進一步確定待分析頁面與主題的相關性程度,在一定程度上克服了頁面惡意關鍵詞的設置。此外,在一定程度上擴大了主題爬蟲的在整個網絡中的搜索范圍,有利于引導主題爬蟲穿越網絡隧道,解決“隧道現象”,提高了主題爬蟲的爬全率和爬準率。
3 實驗結果及分析
3.1評估指標
對于主題網絡爬蟲性能的衡量,查全率和查準率是常用判斷指標。它們可以定量化的考查主題爬蟲的“過濾能力”,即判斷頁面“保留”還是“丟棄”的能力。但是,進一步分析,就會發現查全率的計算具有一定的困難。眾所周知,在整個網絡中的主題資源數量幾乎是不可知的,那我們也就無從知曉檢漏的頁面數量。通過其它方式計算查全率又具有一定的不準確性,所以本文經不針對查全率進行計算。然而相當于查全率,查準率則要相對容易計算,查準率是指在已提取頁面中與主題相關的頁面數占所提取頁面總數的比例。除此之外,時間維度也是判斷爬蟲性能的另一個至關重要的標準,從這個角度考慮,引入另一個考查標準,就是爬蟲在不同時間所能爬蟲到的相關頁面數量。
綜上所述,本文將采用查準率和不同時間點的執行情況作為主題爬蟲進行考查標準。
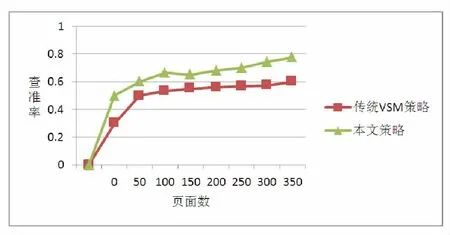
圖2 查準率結果比較
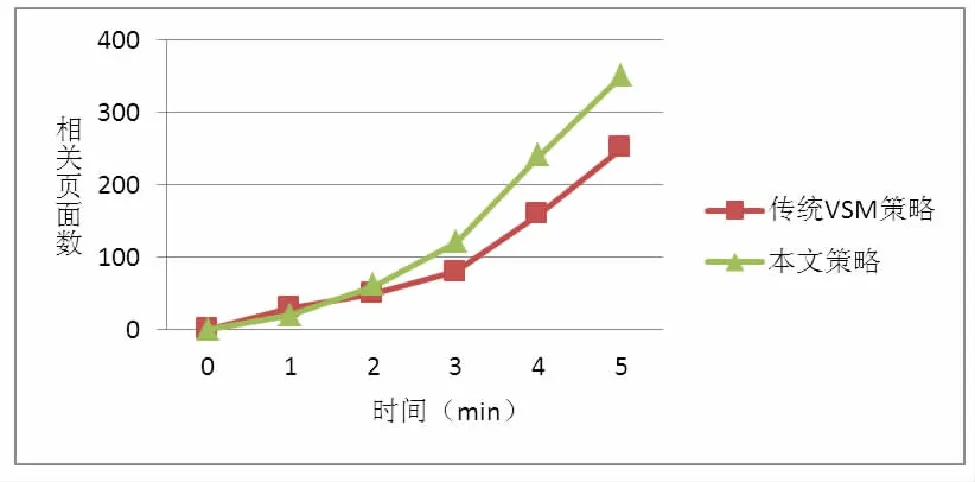
圖3 時間維度結果比較
3.2實驗結果分析
依據上節所述評估標準,將本文所提策略爬蟲與傳統VSM策略爬蟲進行比較,以驗證本文所提策略的可行性。實驗以搜狐體育(http://sports.sohu.com)為初始URL入口,爬取與“中國足球”相關的頁面。取關鍵詞集:國足,亞冠,世預賽,足球,中超。搜索策略采用傳統基于VSM策略和本文所提策略,結果如下:
(1)從查準率的角度來看,在爬取了不同數量頁面的對比中可以發現本文改進策略的普遍高于傳統VSM的爬蟲策略。
(2)從時間的角度來看,在剛開始是基于本文策略的爬蟲爬取的相關頁面要略少,但隨著時間的推移,優勢會逐漸顯現。這是因為本文的策略在計算復雜度上開銷稍大,在短時間內雖然爬取頁面的相關度比例要高,但是總數會略少,所以在開始的時間節點比較時,會有略微的劣勢,但隨著爬取時間的不斷增加,優勢會逐漸明顯。
4 結語
本文提出了基于兩步向量空間模型的主題爬蟲策略。同時考慮了待爬取頁面的主題相關度以及待爬取頁面所包含的URL的主題相關度,通過對多一步的頁面相關度分析可以減小惡意URL對主題相關度的“貢獻”,同時也有利于解決當前頁面低于主題相關度閾值,但經過子URL后進入一個高主題相關度的頁面的“隧道現象”,防止相關頁面的丟失。實驗表明,此方法在主題相關度識別方面具有可行性,實驗結果較好。但是關于閾值的設定以及關鍵詞集的設置都將直接影響到主題爬蟲的執行。因為單純提高閾值,會造成一些頁面訪問不到;降低閾值,又會抓取大量不相關頁面,主題詞集的設置也直接影響到主題相關度的計算,應該提升到語義本體的層面。所以,這也將是下一步研究的重點。
參考文獻:
[1]劉建明,郝志峰.垂直搜索引擎中的主題爬蟲技術研究[D].廣東:廣東工業大學,2013.
[2]高琪,張永平.PageRank算法中主題漂移的研究[J].微計算機信息,2010.
[3]劉國靖,康麗等.基于遺傳算法的主題爬蟲策略[J].計算機應用,2007.
[4]張翔,周明全等.基于PageRank與Bagging的主題爬蟲研究[J].計算機工程與設計,2010,31(14).
[5]黃正德,張文燚等.主題爬蟲關鍵技術研究[D].哈爾濱:哈爾濱工程大學,2013.
Research on Subject Relevance Algorithm of Theme Crawler
XU Yang,WANG Wei-yang
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
Abstract:
The core issue of the theme crawler is the discrimination of the topic.In the process of crawling,the fast and accurate identification of the topic relevance of crawling pages is the key to decide the strategy of the search strategy.Proposed method of two step vector space model is used to identify themes.And compared two-step vector space model strategy with traditional one-step vector space model strategy.Experimental results show that the two step vector space strategy in to identify topic relevance and efficiency have better performance,also has a certain improvement on the“tunnel phenomenon”.
Keywords:
主題爬蟲核心問題是主題的相關性判別問題。如何在爬取過程中,快速、準確地判別爬取頁面的主題相關度,是決定主題爬蟲搜索策略好壞的關鍵所在。提出利用兩步向量空間模型計算的方法進行主題識別,并將基于兩步向量空間模型的主題爬蟲與傳統基于一步向量空間模型的主題爬蟲進行比較,實驗表明基于兩步向量空間的主題爬蟲在主題相關度判別和執行效率方面都有較好的表現,同時對“隧道現象”也有一定的改善。
搜索引擎;網絡爬蟲;主題相關度;向量空間模型
文章編號:1007-1423(2016)14-0048-05
DOI:10.3969/j.issn.1007-1423.2016.14.010
作者簡介:
徐楊(1989-),男,安徽合肥人,在讀碩士研究生,研究方向為軟件開發方法與軟件項目管理
王未央(1963-),女,江蘇常熟人,副教授,研究方向為數據處理與挖掘
收稿日期:2016-04-06修稿日期:2016-05-10
Search Engine;Web Crawler;Theme Relevance;Vector Space Model
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
保健醫苑(2022年1期)2022-08-30 08:39:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
光學精密工程(2016年6期)2016-11-07 09:07:19
時代英語·高三(2014年5期)2014-08-26 02:49:51
