基于校園BBS 的輿情系統爬蟲應用研究
2016-08-17 11:27:56于淑云
長春工程學院學報(自然科學版) 2016年2期
于淑云
(福建船政交通職業技術學院信息工程系,福州350002)
基于校園BBS 的輿情系統爬蟲應用研究
于淑云
(福建船政交通職業技術學院信息工程系,福州350002)
在校園BBS的基礎上研究了網絡爬蟲程序的4個關鍵模塊:頁面抓取、頁面解析、任務調度和去重模塊。探討了HTMLParser和正則表達式在解析頁面時的運用方法。在處理爬取數據時,改進了任務調度算法,提高了爬取速度,并針對校園論壇BBS經關鍵詞搜索的頁面進行了爬取。
爬蟲;關鍵詞;調度算法;輿情
0 引言
隨著因特網應用的日益廣泛,網絡安全問題日益突出。公眾通過網絡表達出來的情緒、態度、意見和要求的集合形成了網絡輿情[1]。對于高校而言,網絡輿情因其主體知識層次高、參與意識強、好奇心重,個性化鮮明等特點,與其他網絡輿情相比,有較強的特殊性,這就給高校網絡輿情管理帶來一定的困難。高校需要及時掌握校園網絡輿情的發展情況。BBS論壇,作為學生最活躍的訊息交流平臺,自然而然地成為校園網絡輿情信息監控的重點。可以在校園BBS論壇上增設爬蟲程序,建立起一個定向于校園的輿情數據收集與提取系統,通過在論壇討論頁面爬取和設置相應熱點關鍵詞來獲取數據,從而實現對校園輿情的監控。目前爬蟲技術已經非常成熟,研究也非常深入,基于論壇帖刷新頻率高,爬取效率低的情況,本文改進了調度算法,提高了爬取效率。
本文使用爬蟲稱為聚焦爬蟲[2],又稱主題爬蟲(或專業爬蟲),是“面向特定主題”的一種網絡爬蟲程序,即在爬取頁面的時候要進行主題篩選,它盡量保證只抓取與主題相關的網頁信息,主要有兩個思路:一是分析已經抓取的頁面的主題相關程度,相關程度較高的入庫,相關程度不高的則不管;二是分析要抓取的URL的相關度,分析當前網頁中的URL,若相關度滿足要求則抓取該URL對應的頁面。由于校園論壇不同的頁面有相似的URL路徑,這就為信息的抓取提供了便利。
1 使用技術
本文使用的Java的開發包HttpClient和HTMLParser[3]。HttpClient是Apache Jakarta Common下的子項目,可以用來提供高效的、最新的、功能豐富的支持HTTP協議的客戶端編程工具包。實現了所有HTTP的方法(GET,POST,PUT,HEAD等),支持自動轉向,支持HTTPS協議,支持代理服務器等。HTMLParser是一個純的Java寫的HTML解析的庫,它不依賴于其他的Java庫文件,主要用于改造或提取HTML。HTMLParser可以根據標簽和標簽屬性的值過濾HTML文檔,也可以根據DOM的組織結構獲取某個元素的父節點或者子節點。
另外,在頁面解析過程中也用到了正則表達式,正則表達式根據正則表達式的值摘取指定內容中需要的內容。與HTMLParser兩者結合起來可以很好地解析出課程論壇數據。
2 校園輿情系統爬蟲架構設計
2.1 爬取流程
本文闡述爬取過程4個部分的內容:頁面抓取模塊、頁面解析模塊、去重模塊、任務調度模塊[4],其中重點闡述了去重模塊和任務調度模塊,爬取流程圖如圖1所示。頁面抓取指根據搜索任務構造URL從服務器端抓取需要的頁面;頁面解析指使用工具分離出抓取的頁面中的有用信息;去重模塊利用去重算法避免抓取和解析重復內容從而提高爬蟲的效率;任務調度模塊負責讀取待處理的任務,并根據調度算法開啟多個線程調用頁面抓取模塊抓取需要的網頁。
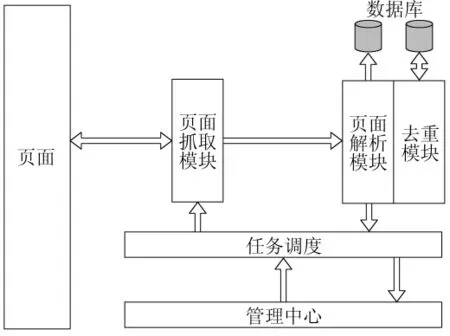
圖1 爬取流程圖
2.2 頁面爬取
爬蟲的基本原理是爬取一個給定的URL指向的頁面。一般的爬蟲程序是從爬取的頁面中解析出頁面中的URL,再爬取這些URL指向的內容,然后再解析出頁面中的URL加入到任務列表中遞歸的爬取[5]。網絡爬蟲采用的主流爬取策略有深度優先爬取策略和廣度優先爬取策略[6],基于校園頁面集中的特點,本文采用的是深度優先爬取策略。搜索爬蟲的URL形式固定,只需要改變URL中傳遞的參數的值即可獲得任務列表。本文爬取的URL路徑的形式為http://jxzy.fjcpc.edu.cn/meol/jpk/course/layout/newpage/index.jsp?courseId=00000。其中courseId是某門課程頁面代碼,默認是實時搜索,即搜索結果按時間排序。
使用HttpClient開發包中的Get方法就可以爬取構造的URL指向的內容,其中URL參數就是程序構造好的URL,程序運行之后返回的頁面的內容可以把它寫入到文件中保存下來留待以后解析,也可以直接交給頁面解析模塊解析之后直接把數據入庫。
2.3 頁面解析
頁面解析使用的工具主要是HTMLParser開發包和正則表達式。HTMLParser可以根據標簽和標簽屬性的值過濾HTML文檔,也可以根據DOM的組織結構獲取某個元素的父節點或者子節點。正則表達式則根據正則表達的值摘取指定內容中需要的內容。由于動態網頁都是服務器動態生成然后返回至客戶端的,因此返回的內容必然有一定的固定格式,只要找到了這一規律就可以利用程序批量的解析,校園論壇討論就是典型的動態網站。
如圖2所示,經過分析,發現所有的討論回復內容都包含在<div id="body"><p>…</p></div>標簽中,而且這個標簽中的文本就是用戶話題的內容,這樣可以使用HTMLParser提取這組標簽里面的文本,這個文本即是需要的話題內容信息。對于剩下的幾條信息可以選擇通過正則表達式來提取。

圖2 校園論壇前端代碼片段
2.4 去重模塊
去重模塊是對程序的優化,雖然爬到重復的用戶數據在入庫的時候,數據庫會因為主鍵的約束拒絕添加沖突的內容,但是這樣會大大降低程序的效率。由于用戶發表言論都是按時間排序,因此我們可以選用爬過的討論發布時間中的最大值作為標準來作為判斷該頁是否已經爬過的依據。為了提高效率,可以單獨建立一個表存儲爬過的最早時間。本文用時間作為判斷是否已爬的參數,并單獨建立了一個表存儲這些參數。
程序在每接到一個任務時,先搜索第一頁,然后解析第一頁的討論內容,解析出該討論的發布時間后搜索去重數據庫,如果沒有該條記錄,則記錄時間為0,如果有則記錄這個時間值,更新該條記錄的值為解析出來的時間[7]。如果數據庫中的值大于等于該頁某討論的時間,則表示該討論之后的內容以及該頁以后的內容已經爬過了,該關鍵詞后面的搜索頁面就不用爬取了,如果數據庫中的值小于第一條討論的時間,則把該頁的所有討論都入庫,并爬取下一頁,然后循環執行。
這一算法理想的情況可以避免爬取已經爬過的內容,但是現實情況中,論壇討論的搜索結果在實時更新,平均幾秒鐘就會更新,然而程序不可能在幾秒的時間內爬完沒爬過的數據,這樣就存在以下的情況:先爬第n頁,過幾秒爬第n+1頁時,由于討論內容的更新,第n+1頁中包含了之前爬的第n頁的討論內容,導致重復爬取。為了盡可能解決上面提到的問題,本程序選擇多線程的方法提高爬蟲的速度,爭取針對一個關鍵詞開多個線程同時把多個頁面爬取下來,這樣就可以避免上一段提到的論壇討論更新,導致重復爬取的問題。關鍵程序如下,其中dbdate是讀取的數據庫中的時間值,time是搜索到的發表討論的時間,page是爬取的頁數,i是每頁中用戶順序號。


2.5 任務調度模塊
2.5.1 并行爬取策略
任務調度模塊讀取管理中心配置的待處理任務文件,按照調度算法調用頁面爬取模塊爬取相關的頁面,任務調度模塊決定了爬蟲程序面臨多個任務時的爬取方式,對爬蟲程序的效率有很重要的影響。
使用多線程爬取頁面是必要的。首先,如果待處理的任務中的關鍵詞很多,那么就必須使用多線程的方式提高爬蟲程序的速度,否則就不能爬取關鍵詞對應的所有課程內容。其次,在去重模塊中也提到,如果爬蟲速度太慢那么就會出現即使爬取的是不同的頁面,也有可能出現重復爬取的問題,重復爬取不僅耗費了程序運行時間,更重要的是在這段時間內論壇帖在逐漸從搜索頁面中清除,如果不能及時爬取下來就再也搜索不到了。
本程序的調度算法的核心思想是根據賬號數目確定開啟的線程的個數,保證線程開啟后就可以分配到確定的本線程獨有的賬號,無需和其他線程競爭,與其他線程是獨立的,運行完之后直接結束線程。
假如任務中有n個關鍵字,那么爬蟲程序需要爬取n*30個頁面才能爬完資源平臺中需要的所有頁面,目前有m個用戶賬號,那么從第一個關鍵字的第一個頁面開始至第n個關鍵字的第30頁為止,把這n*30個頁面分成若干份,每份m個頁面。首先是第一份,啟動m個子線程,每個線程分得一個賬號并且爬取一個頁面,之后調度線程再同爬取第一份一樣爬取下一份頁面,直到爬完為止。
2.5.2 調度優化算法
以上的任務調度模塊實現了基本的多關鍵詞的調度方法,但是經過現實運行測試發現,對于一個新添加的關鍵詞而言,第一次爬取該關鍵詞的30個頁面,這30個頁面的內容都為有效內容,這說明每次爬取都是有效的。爬完一輪之后,循環爬取第二輪發現抓取的30頁中往往只有前1~3頁左右是新更新的,有時第二輪只能爬取3條新的信息,還不足一頁,其他的都是已經爬過的,因而后面的頁面盡管都爬了下來但是并沒有為數據庫增添多少信息,爬取這些頁面是毫無意義的,為此需要設計一個算法,利用上一次爬取的頁面情況決定本次爬取多少頁,這可以大大調高程序的效率[7]。
以一個關鍵詞為例說明改進的任務調度算法,初始狀態設定爬取30頁,首先程序開啟30個線程分別爬取這30頁,爬取的過程中每個線程均可將解析出的數據與去重數據庫中的數據比較,判斷該頁是不是已經爬取過了。所有的頁都爬完之后,我們選取已經爬取過的頁的最小值,比如10~30頁經過判斷都已經爬取過了,那么取值為10,取的這個數字10就是下一輪爬取時該關鍵字應該爬取的頁數。新的一輪爬取開始,這個關鍵詞就只需爬取前10頁。這時會出現兩種情況:第一,如果發現這10頁中都沒有已經爬取的頁,那么說明10頁之后還有新的內容而我們漏掉了,說明爬取的頁數少了,下次爬取時就需要適當的增加爬取的頁數的個數,本算法設定如果出現這種情況,下次爬取的搜索頁的個數在這次的基礎上加5,如果增加之后超過30則爬取30頁;第二,如果這10頁中還有已經爬取的頁,比如說是第9頁,那么下一輪爬取時該關鍵詞只爬取前9頁的內容。
要實現以上算法,需要設計相應的數據結構,而且由于本爬蟲程序采取多線程并行爬取,可能出現多個線程同時操作一個字段的情況,所以還需要考慮各線程之間同步的問題。首先,每個關鍵詞對應一個結構體,該結構體中包含4條數據,分別是關鍵詞、上一輪爬取時已經爬取過的頁面的最小值、本輪應該爬取的頁面的個數、上輪爬取的關鍵詞對應的最新課程討論的時間。
關鍵詞只是在爬取之前初始化的時候設置或者任務有變動的時候添加或刪除,在爬取過程中無需改動。已經爬取過的頁面的最小值是通過與關鍵詞各個頁面搜索結果進行比較,然后取最小值得到的,在線程爬取的過程中需要修改。每個線程爬取一頁之后,解析判斷該頁面是否已經被爬取過了,如果是則比較該頁面號和結構體中第二個字段的值,如果頁面號小于該值,則修改結構體中字段值為頁面號的值,這樣經過每個線程的修改,該關鍵字的所有頁面的爬取線程結束之后,結構體第二個字段的值即為已經爬取過的頁面的最小值。修改這個變量的方法需要做同步,每次只能有一個線程使用該方法修改這一數值,如果一個線程需要調用該方法而該方法被另一線程占用時,就需要等待,直到方法無線程占用再去執行,這可以通過Java中提供的synchronized關鍵字使用Java的同步機制來實現這一功能。應該爬取的頁面的個數是在開始新的一輪爬取的時候需要修改的,修改之后的數值就是在本輪爬取時該關鍵詞應該爬取的頁面個數,這個字段的值取決于上次爬取過程中對第二個字段的修改結果,第二個字段的值如果為30(爬取之前初始化值為30)說明沒有修改過,也就是說上次爬取的所有頁面沒有已爬的課程內容,后續的頁面可能還有未爬取的,出現這一現象的原因就是該關鍵字相關的課程內容更新的頻率增高,因此,下次爬取時需要在上次爬取的頁面的個數的基礎上加一個值,經過試驗加5較為合適,也就是說在這種情況下,程序把第三個字段的值在之前的基礎上加5,如果加5之后超過30,則取30;第二個字段的值如果為小于30的值說明該值在上次爬取過程中修改過了,說明在上次爬取的過程中該頁面之后的所有頁面都已經爬取過了,原因就是該關鍵詞相關的課程內容更新的頻率降低,我們程序的下次就可以少爬一些頁面,所以程序把結構體的第三個字段設置為第二個字段的值。每次爬完之后都要設置該字段的值以指導下一次爬取。
3 運行效果分析
3.1 測試環境(表1)

表1 測試環境配置表
3.2 信息抓取
在具體爬取時,設置數據結構的4個字段為keyword,lastresult,pagenum,date,這4個字段的意義和操作在上面已經做了詳細的說明,設置爬取的關鍵字為:“3.15”,如圖3所示。

圖3 抓取結果
4 結語
本文完成了爬蟲的基本功能之后,為了提高爬蟲的工作效率,又研究了任務調度優化算法。通過本次測試,程序在實際環境中運行穩定正常,爬蟲程序的理論效率和實際運行效率基本相符,調度優化算法提高了程序效率。
[1]閆育周.我國高校網絡輿情管理機制研究[J].西安電子科技大學學報:社會科學版,2013(4):113-117.
[2]周立柱,林玲.聚焦爬蟲技術研究綜述[J].計算機應用,2005,9(25):1965-1969.
[3]汪濤,樊孝忠.鏈接分析對主題爬蟲的改進計算機應用[J].計算機應用,2004(12):174-176.
[4]張亮.基于HTMLParser和HttpClient的網絡爬蟲原理與實現[J].電腦編程技巧與維護,2011(20):94.
[5]杜長燕,李祥龍.基于WEB的網絡爬蟲的設計[J].無線互聯科技,2015,3:49-50.
[6]成功,李小正,趙全軍.一種網絡爬蟲系統中URL去重方法的研究[J].中國新技術新產品,2014(12):23.
[7]林海霞,司海峰,張微微.基于Java技術的主題網絡爬蟲的研究與實現[J].技術交流,2009(2):56-58.
The Applied Study on Purpose Web Crawler in Public Opinion System Based on Campus BBS
YU Shu-yun
(Department of Informational Engineering,Fujian Chuanzheng Communication College,Fuzhou350002,China)
This paper researches the four key web crawler program modules on the basis of the campus BBS.They are climbing up the pages,parsing the pages,tasking schedulings and eliminating duplicate datas.It discusses the use of regular expressions and HTMLParser method when parsing the pages.In dealing with crawl data,the task scheduling algorithm has been improved and the speed of crawl has been raised.As well the campus BBS pages through keywords has been crawled.
purpose web crawler;key word;scheduling algorithm;public opinion
TP391
A
1009-8984(2016)02-0095-04
10.3969/j.issn.1009-8984.2016.02.024
2016-03-21
福建省教育廳A類項目(JA15661)
于淑云(1981-),女(漢),山東,講師主要研究網絡應用系統開發。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
政治與法律(2014年11期)2014-03-01 02:20:40
電腦愛好者(2011年11期)2011-06-22 08:20:18
