基于深度卷積神經網絡和二進制哈希學習的圖像檢索方法
2016-08-30 11:57:39彭天強河南工程學院計算機學院鄭州451191河南圖像識別工程技術中心鄭州450001
電子與信息學報 2016年8期
彭天強 栗 芳(河南工程學院計算機學院鄭州451191)(河南圖像識別工程技術中心鄭州450001)
?
基于深度卷積神經網絡和二進制哈希學習的圖像檢索方法
彭天強*①栗芳②①
①(河南工程學院計算機學院鄭州451191)
②(河南圖像識別工程技術中心鄭州450001)
隨著圖像數據的迅猛增長,當前主流的圖像檢索方法采用的視覺特征編碼步驟固定,缺少學習能力,導致其圖像表達能力不強,而且視覺特征維數較高,嚴重制約了其圖像檢索性能。針對這些問題,該文提出一種基于深度卷積神徑網絡學習二進制哈希編碼的方法,用于大規模的圖像檢索。該文的基本思想是在深度學習框架中增加一個哈希層,同時學習圖像特征和哈希函數,且哈希函數滿足獨立性和量化誤差最小的約束。首先,利用卷積神經網絡強大的學習能力挖掘訓練圖像的內在隱含關系,提取圖像深層特征,增強圖像特征的區分性和表達能力。然后,將圖像特征輸入到哈希層,學習哈希函數使得哈希層輸出的二進制哈希碼分類誤差和量化誤差最小,且滿足獨立性約束。最后,給定輸入圖像通過該框架的哈希層得到相應的哈希碼,從而可以在低維漢明空間中完成對大規模圖像數據的有效檢索。在3個常用數據集上的實驗結果表明,利用所提方法得到哈希碼,其圖像檢索性能優于當前主流方法。
圖像檢索;深度卷積神徑網絡;二進制哈希;量化誤差;獨立性
針對大規模數據的檢索問題,哈希技術被廣泛用于計算機視覺、機器學習、信息檢索等相關領域。為了在大規模圖像集中進行快速有效的檢索,哈希技術將圖像的高維特征保持相似性地映射為緊致的二進制哈希碼。由于二進制哈希碼在漢明距離計算上的高效性和存儲空間上的優勢,哈希碼在大規模圖像檢索中非常高效。
位置敏感哈希[4](Locality Sensitive Hashing,LSH)按照其應用可以分為兩類[5]:一類是以一個有效的方式對原始數據進行排序,以加快搜索速度,這種類型的哈希算法稱為“original LSH”;另一類是將高維數據嵌入到Hamm ing空間中,并進行按位操作以找到相似的對象,將這種類型的哈希算法稱為二進制哈希(binary hashing)。二進制哈希方法可以分為無監督的哈希算法、半監督的哈希算法和監督的哈希算法。無監督的哈希方法不考慮數據的監督信息,包括Isotropic hashing[6]、譜哈希[7](SH)、PCA-ITQ[8]等;半監督的哈希方法考慮部分的相似性信息,包括SSH[9];監督的哈希方法利用數據集的標簽信息或者相似性點對信息作為監督信息,包括BRE[10]、監督的核哈希[11](KSH)等。這些哈希算法的目標均是構造出能夠保持數據在原空間中的相似性且能夠生成緊致二進制哈希碼的哈希函數。在譜哈希[7]中給出了度量哈希函數好壞的3個標準:(1)將原始數據空間中相似的對象映射為相似的二進制編碼;(2)需要較少的位數來對整個數據集進行編碼;(3)給定一個新的輸入易求出相應的二進制編碼。其中第(2)個標準的目標要求生成緊致的二進制碼,即不同哈希函數之間應該是獨立的。在PCA-ITQ[8]中在哈希函數構造利用量化誤差最小作為優化目標,最后生成了表達能力很強的二進制哈希碼。
基于深度學習的方法[1214]-在圖像分類、目標檢測等方面都展現了其優越性。從2012年文獻[13]提出的A lexNet模型到2014年文獻[15]提出的NIN(Network In Network)模型和文獻[16]提出的深層VGG模型都成功地驗證了基于深度卷積神經網絡的方法在學習圖像特征表示上的能力。
由于深度卷積神經網絡在特征學習上的優越性以及哈希方法在檢索中計算速度和存儲空間上的優越性,近幾年也出現了深度卷積神經網絡與哈希技術相結合的方法。文獻[17]提出了一種CNNs與哈希方法相結合的算法,該算法分為兩個步驟,第1步首先利用數據的相似性信息構建相似性矩陣,然后得到訓練樣本的近似哈希編碼;第2步將第1步學習得到的哈希碼作為目標利用深度卷積網絡框架學習哈希構造函數,該論文將哈希編碼的學習和特征的提取分為兩個階段,效果不夠好。文獻[18]提出了一種利用深度卷積網絡同時學習特征和哈希函數的算法,它利用圖像三元組作為監督信息,優化目標函數是在最終的變換空間中相似的圖像對之間距離比不相似圖像對的距離近,且有一定的間隔;該論文將三元組作為監督信息,三元組對的挑選質量直接影響著檢索的精度且三元組的挑選需要較大的工作量。文獻[19]也提出了一種利用深度卷積網絡框架同時學習特征和哈希函數的算法,該論文中采用標簽信息作為監督信息,避免了需要挑選三元組的工作量,但是它沒有考慮到將連續值閾值化為二進制碼時產生的量化誤差以及哈希函數之間的獨立性。
結合深度卷積神經網絡和哈希算法的優勢,本文提出了一種基于深度卷積神經網絡學習二進制哈希函數的編碼方法,學習得到的二進制哈希碼可用于大規模的圖像檢索。本文的基本思想是在CNNs框架中引入哈希層,利用圖像標簽信息同時學習圖像特征和哈希函數,且哈希函數需要滿足獨立性和量化誤差最小的約束。本文提出的二進制哈希函數學習算法,考慮哈希函數之間的獨立性和閾值化產生的量化誤差,與其他相關的方法相比,本文有以下特點:
(1)在原有的CNNs框架中,引入哈希層,將哈希層得到的編碼輸入分類器進行分類,將Softmax分類損失作為優化目標之一。
(2)哈希層中包括兩部分,第1部分包括分片層(slice layer)、全連接層、激活層以及合并層(concat layer),將特征映射為連續的編碼,用于生成具有獨立性的哈希函數;第2部分是閾值化層,將連續編碼二值化,得到二值哈希碼,用于計算量化誤差。
(3)在整個框架模型中考慮量化誤差的影響,將連續值閾值化為二進制哈希碼時產生的誤差加入到優化目標中,從而得到表達能力更強的哈希碼。
實驗結果表明,本文提出的二進制哈希學習方法的檢索性能優于現有的方法。
2 本文方法
本文方法的框架圖如圖1所示。該模型接受的輸入為圖像及其相應的標簽信息。該模型主要包括3個部分:(1)卷積子網絡,用于學習圖像的特征表示;(2)哈希層,用于構建獨立的哈希函數得到相應的哈希碼;(3)損失層,包括Softmax分類損失和量化誤差損失。首先,輸入圖像通過卷積子網絡層得到圖像的特征表示;其次,圖像特征經過哈希層得到哈希碼;最后,哈希碼進入損失層,計算損失函數,并優化該損失函數學習得到模型參數。

圖1 本文卷積神經網絡的框架圖
2.1卷積子網絡
卷積子網絡層用于學習圖像的特征表示,輸入圖像通過該卷積子網絡層可以得到圖像的特征表示。
本文采用具有深度為16的VGG[16]模型結構作為基本架構。卷積子網絡中包含5個大卷積層、5個池化層和兩個全連接層。前2個大卷積層中分別包含了兩個核大小為3×3,步幅為1的卷積層;后3個大卷積層分別包含了兩個核大小為3×3,步幅為1的卷積層和一個核大小為1×1,步幅為1的卷積層。在使用該卷積子網絡模型時需要根據圖像大小,調整相應的卷積層的輸出個數。對于圖像大小為32×32的小圖,本文的卷積子網絡配置見表1。
2.2哈希層和優化目標
LSH[20]中給出了保持內積相似性的哈希函數的定義:給定特征構造q個m維隨機向量構成矩陣個哈希函數產生的哈希碼為
在本文中,哈希層是由分片層、各子塊的全連接層、各子塊的激活層、合并層和閾值化層組成。其中,分片層、各子塊的全連接層、各子塊的激活層和合并層用于構造相互獨立的哈希函數;閾值化層將連續值編碼二值化,用于計算量化誤差。
從卷積子網絡的第2個全連接層得到圖像特征x之后,將它傳入哈希層。首先,進入哈希層的分片層,對圖像特征x進行分片,假設圖像特征x的維數為m,需要生成哈希碼的長度為q,則需要將圖像特征分為q片,記為中包含的特征維數為/m q(這里最好m為q的倍數,可以通過控制卷積子網絡第2個全連接層的輸出單元數確定圖像特征的維數)。

表1 小圖的卷積子網絡配置

其中,W∈R dim(x(i))×1i為第i個全連接層的權重矩陣。
每個子塊分別進入激活層,激活層使用雙正切激活函數將每個子塊輸出的1維數值映射為值域在[1,1]-之間的數值,表示為

然后進入合并層,合并層主要是將q個子塊的1維輸出合并為一個q維向量,表示為

合并層的輸出即為哈希函數輸出值的近似值,為連續的編碼值。
最后進入閾值化層,閾值化層主要是將合并層得到值域在[1,1]-之間的q維連續值編碼進行量化,量化為1-和1,表示為

本文中深度卷積神經網絡框架的優化目標結構圖如圖2所示。損失層函數包括Softmax分類器損失和量化誤差損失。激活層得到的編碼進入Softm ax分類器進行分類,在這個過程中產生Softm ax分類誤差損失,記為slL。另一方面,考慮到哈希碼為離散值,需要加入將連續值二值化為離散值時帶來的誤差,在目標損失函數中,加入合并層輸出的連續值編碼與閾值化層輸出的哈希碼之間的誤差損失,即量化誤差損失,表示為

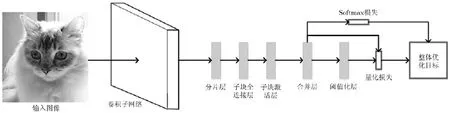
圖2 本文卷積神經網絡的優化目標結構圖

圖3 哈希碼生成流程圖
結合Softm ax分類器的損失函數和量化誤差損失,得到該框架的整體損失函數:

其中,λ為權重因子,決定著量化損失所占的重要性。
2.3哈希碼的生成
在利用本文卷積神經網絡的框架訓練之后,給定一張圖像作為輸入,通過該網絡框架可以得到q位二進制哈希碼。生成流程如圖3所示,給定輸入圖像,首先經過卷積子網絡層,然后經過哈希層,哈希層中的最后一層為閾值層,直接輸出了二進制哈希碼。
3 實驗設置與性能評價
3.1實驗設置
為驗證本文方法的有效性,在以下3個圖像集上對本文方法進行了評估。MNIST數據集[21],該數據集是包括了70000張28×28的灰度圖像,手寫數字從0到9共10個類別。CIFAR-10數據集[22],包括了60000張32×32的彩色圖像,其類別包括飛機、卡車等10類。NUS-W IDE數據集[23],包括了將近270000張圖像,每張圖像具有一個或者多個標簽。借鑒文獻[24]的使用方式,僅使用21個常用類,常用類中每一類中至少包括5000張圖像。另外在訓練時我們統一將圖像大小重設置為256×256。
將本文的方法的檢索性能與其它的哈希方法做比較,包括非監督的哈希方法ITQ[8],監督的哈希方法KSH[11],以及深度學習與哈希技術相結合的哈希方法CNNH[17],改進CNNH[18],DCNNH[19]。
在MNIST和CIFAR-10數據集中,每一類選擇1000張圖像構成包含10000圖像的測試集。對于無監督的哈希方法,其余的數據作為訓練集。對于監督的哈希方法,每類選擇出500張,組成包括5000張圖像的訓練集。在NUS-W IDE數據集中,隨機從每一類中選擇出100張圖像組成2100張圖像的測試圖像集。對于無監督的哈希方法,其余的數據作為訓練集。對于有監督的哈希方法,每類選擇出500張,組成包括10500張圖像的訓練集。
對于深度學習與哈希計算相結合的算法,直接使用圖像作為輸入。而其余的方法,數據集MNIST和CIFAR-10采用512維的Gist特征表示圖像;NUS-W IDE圖像使用500維的bag-of-words向量表示圖像。
為了評估圖像檢索性能并與已有方法作比較,本文采用MAP、查準-查全率(Precision-Recall,P-R)曲線、漢明距離小于2的準確率曲線以及檢索返回top-k近鄰域的準確率曲線這4個參數進行評估。其中,查準率是指查詢結果中正確結果所占的比例,查全率是指查詢結果中正確結果占全部正確結果的比例;P-R曲線是指按照漢明距離從小到大的排序,所有測試圖像的平均查全率和平均查準率的曲線圖。MAP是指P-R曲線所包圍的面積。漢明距離小于2的準確率是指在與查詢圖像的漢明距離小于2的圖像中正確結果所占的比例。top-k近鄰域的準確率是指與查詢圖像距離最小的k張圖像中正確結果所占的比例。
本文的訓練過程基于開源Caffe實現的。在所有實驗中,量化損失的權重因子λ取值為0.2。
3.2實驗性能分析
表2中給出在MNIST數據集上,本文方法和已有方法MAP值的比較結果。從表2中可以看出,本文算法的MAP值遠遠高于傳統特征與哈希方法相結合的算法(KSH,ITQ),因為本文利用深度卷積網絡同時學習特征表示和哈希函數,大大提高了圖像的表示能力。與其它的深度卷積網絡與哈希技術相結合的方法相比,本文算法的MAP值最高,與CNNH算法和改進CNNH算法相比,本文算法采用了標簽信息作為監督信息且考慮了量化誤差,得到了表示能力更強的哈希碼;與DCNNH算法相比,本文算法架構中考慮了量化誤差和哈希函數之間的獨立性,得到了更具有圖像表示能力的哈希碼,使得它在檢索中MAP值較高。
表3給出在CIFAR-10數據集上,本文方法和已有方法MAP值的比較結果。從表3中可以看出,本文算法的MAP值遠遠高于傳統特征與哈希方法相結合的算法(如KSH),提高了50%;與現有的深度卷積網絡與哈希技術相結合的方法相比,由于本文算法同時考慮了量化誤差和哈希函數之間的獨立性,且采用了標簽信息作為監督信息,本文算法的MAP值最高。特別地,比改進CNNH算法的MAP值提高了27%左右。

表2 在數據集MNIST上按漢明距離排序的MA P值對比

表3 在數據集CIFAR-10上按漢明距離排序的MAP值對比

表4 在數據集NUS-W IDE上top-5000近鄰域的MAP值對比
表4給出在NUS-W IDE數據集上,本文方法和已有方法MAP值的比較結果。從表4中可以看出。本文算法的MAP值比傳統特征+KSH的MAP值提高了將近20%;與現有的深度卷積網絡與哈希技術相結合的方法相比,本文算法比改進CNNH算法的MAP值高了6%左右,比DCNNH算法的MAP值提高了2%左右,主要是因為本文算法同時加入了量化誤差和哈希函數的獨立性的約束,得到了表示能力更強的哈希碼。
圖4~圖6給出了在3個數據集上,在其它檢索性能(不同位數下漢明距離小于2的正確率、P-R曲線、不同位數下top-k的檢索正確率)上的比較結果。從這3個圖中可以看出,本文的方法的檢索性能均優于現有的其它方法。
3.3加入獨立性和量化損失的性能對比
為了驗證本文提出的框架的有效性,將本文算法與未加入分片層、閾值層和量化損失的算法(即未做任何約束,不考慮哈希函數間的獨立性和量化誤差)、以及在本算法的基礎上未加入閾值層和量化損失的算法(即僅考慮哈希函數間的獨立性,不考慮量化誤差)分別做比較。不考慮哈希函數間的獨立性和量化誤差的算法框架見圖7所示,在給定圖像生成哈希碼時,圖像經過該框架僅得到了值域在[-1,1]之間的編碼,需要對得到的編碼進行二值化生成二進制哈希碼,該算法框架類似于文獻[19]提出的算法。僅包含獨立性不包含量化損失的算法框架見圖8所示,在該框架中也需要對該框架的輸出編碼也需要進行二值化生成二進制哈希碼,該算法框架類似于改進CNNH[18]的框架,但在改進CNNH[18]中采用圖像三元組損失函數,且不考慮量化損失。

圖4 在數據集MNIST上結果對比

圖5 在數據集CIFAR10上結果對比

圖6 在數據集NUS-W IDE上結果對比

圖7 未加入分片層、閾值層和量化損失的算法框架

圖8 僅增加哈希函數間的獨立性,未加入量化損失的算法框架
表5~表7給出了3種算法在3個數據集上的MAP對比結果。從這3個表可以看出:僅加入獨立性的算法比未做任何約束的算法的檢索MAP值提高了1%~2%;而本文算法包括獨立性和量化損失約束,比僅有獨立性約束的算法的MAP值又提高了1%左右。在數據集MNIST上,雖然本文算法僅比未閾值化算法的MAP提高0.5%左右,但本文算法24位的哈希碼的檢索MAP值高于未做任何約束算法的48位的哈希碼檢索MAP值,從而在大規模圖像檢索中可以用更短的哈希碼來表示圖像但能達到與較長哈希碼相當的檢索精度。在數據集CIFAR-10上,本文算法24位的哈希碼的檢索精度已經超過了未做任何約束算法的48位哈希碼;在數據集NUS-W IDE上,本文算法12位的哈希碼的檢索精度也高于了未做任何約束算法的48位哈希碼。從以上對比中可以看出,利用本文算法可以用較短的哈希碼表示圖像,且達到其他算法用較長的哈希碼的檢索精度。用較短的哈希碼表示圖像,使得在大規模圖像檢索中圖像集占用的存儲空間更少,距離計算速度更快,提高了圖像檢索在時間、空間上的性能,但同時保持了相應的檢索精度。

表5 數據集MNIST上按漢明距離排序的MAP值對比

表6 數據集CIFAR-10上按漢明距離排序的M AP值對比

表7 數據集NUS-W IDE上top-5000近鄰域的MAP值對比
4 結束語
本文提出了一種基于深度卷積神經網絡學習二進制哈希的方法,適用于大規模圖像檢索。在本文提出的框架中,采用類別信息作為監督信息,而不使用三元圖像組作為監督信息,大大降低了人工標記量。另外,在整個框架模型中加入哈希函數獨立性的限制,并考慮量化誤差的影響,將連續值閾值化為哈希碼時產生的誤差加入到損失函數中,從而構造出了更好的哈希函數,得到了更具有圖像表達能力的哈希碼。與其他現有方法相比,本文算法的檢索精度最優。
[1]LOWE D G.Distinctive image features from scale-invariant keypoints[J].In ternational Journal ofCom puter V ision,2004,60(2):91-110.
[2]DALAL N and TRIGGSB.Histogram s of oriented gradients for human detection[C].Com puter Vision and Pattern Recognition,San Diego,CA,USA,2005:886-893.
[3]KRIZHEVSKY A,SUTSKEVER I,and H INTON G E. ImageNet classification w ith deep convolutional neural networks[C].Advances in Neural Information Processing System s,South Lake Tahoe,Nevada,US,2012:1097-1105.
[4]DATAR M,IMMORLICA N,INDYK P,et al.Locality sensitive hashing schem e based on p-stable distribu tions[C]. Proceedings of the ACM Sym posium on Com putational Geometry,New York,USA,2004:253-262.
[5]ZHANG Lei,ZHANG Yongdong,ZHANG Dongm ing,et al. Distribution-aware locality sensitive hashing[C].19th International Conference on Multimedia Modeling,Huangshan,China,2013:395-406.
[6]KONG W eihao and LI W ujun.Isotrop ic hash ing[C]. Advances in Neural Information Processing System s,South Lake Tahoe,Nevada,US,2012:1646-1654.
[7]WEISS Y,TORRALBA A,and FERGUS R.Spectral hashing[C].Advances in Neural Information Processing System s,Vancouver,Canada,2009:1753-1760.
[8]GONG Yunchao,LAZEBN IK S,GORDO A,et al.Iterative quantization:a p rocrustean approach to learning binary codes for large-scale image retrieval[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,35(12): 2916-2929.
[9]WANG Jun,KUM AR S,and CHANG Sh ih fu. Sem i-Supervised hashing for large scale search[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(12):2393-2406.
[10]KULIS B and DARRELL T.Learning to hash w ith binary reconstructive embeddings[C].Advances in Neural Inform ation Processing System s,Vancouver,Canada,2009: 1042-1052.
[11]LIUWei,WANG Jun,JIRongrong,etal.Supervised hashing w ith kernels[C].Com puter Vision and Pattern Recognition,Providence,RI,2012:2074-2081.
[12]GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate ob ject detection and semantic segm entation[C].Com puter Vision and Pattern Recogn ition,Ohio,Columbus,2014:580-587.
[13]OQUAB M,BOTTOU L,LAPTEV I,et al.Learning and transferring m id-level image representations using convolutional neural networks[C].Com puter Vision and Pattern Recogn ition,Ohio,Colum bus,2014:1717-1724.
[14]RAZAVIAN A,AZIZPOUR H,SULLIVAN J,et al.CNN features off-the-shelf:an astounding baseline for recognition[C].Com puter Vision and Pattern Recognition,Ohio,Colum bus,2014:806-813.
[15]LIN M in,CHEN Qiang,and YAN Shuicheng.Network in network[OL].http://arxiv.org/abs/1312.4400,2013.
[16]SIMONYAN K and ZISSERMAN A.Very deep convolutionalnetworks for large-scale image recognition[OL]. http://arxiv.org/abs/1409.1556,2014.
[17]XIA Rongkai,PAN Yan,LAI Hanjiang,et al.Supervised hashing for image retrieval via image representation learning[C].Proceedings of the AAAI Con ference on Artificial Intelligence,Québec,Canada,2014:2156-2162.
[18]LAIHanjiang,PAN Yan,LIU Ye,et al.Simultaneous feature learning and hash cod ing w ith deep neural networks[C]. Com puter Vision and Pattern Recognition,Boston,MA,USA,2015:3270-3278.
[19]LIN K,YANG H F,HSIAO J H,et al.Deep learning of binary hash codes for fast im age retrieval[C].Proceed ings of the IEEE Conference on Computer Vision and Pattern Recognition,Boston,MA,USA,2015:27-35.
[20]GIONIS A,INDYK P,and MOTWANIR.Sim ilarity search in high dimensions via hashing[C].Proceedings of the International Con ference on Very Large Data Bases,Edinburgh,Scotland,UK,1999:518-529.
[21]LECUN Y,CORTES C,and BURGES CJC.The MNIST database of handw ritten digits[OL].http://yann.lecun. com/exdb/mn ist,2012.
[22]KRIZHEVSKY A and H INTON G.Learning mu ltip le layers of features from tiny images[R].Technical Report,University of Toronto,2009.
[23]CHUA TatSeng,TANG Jinhui,HONG Richang,et al. NUS-W IDE:A real-world W eb im age database from national university of singapore[C].Proceedings of the ACM International Conference on Image and Video Retrieval,Greece,2009:48.
[24]LIU W ei,WANG Jun,Kumar San jiv,et al.Hashing w ith graphs[C].Proceedings of the 28th International Con ference on Machine Learning,Bellevue,Washington,USA,2011:1-8.
彭天強:男,1978年生,博士,副教授,主要研究方向為多媒體信息處理及模式識別.
栗芳:女,1986年生,碩士,研究方向為圖像檢索與分類.
Image Retrieval Based on Deep Convolutional Neural Networks and Binary Hashing Learning
PENG Tianqiang①LIFang②①(Departm ent ofComputer Science and Engineering,Henan Institute ofEngineering,Zhengzhou 451191,China)
②(Henan Image Recognition Engineering Center,Zhengzhou 450001,China)
W ith the increasing am ount of im age data,the im age retrievalm ethods have several d raw backs,such as the low exp ression ability of visual feature,high dimension of feature,low p recision of image retrievaland so on.To solve these prob lem s,a learningmethod ofbinary hashing based on deep convolutional neuralnetworks isp roposed,which can be used for large-scale image retrieval.The basic idea is to add a hash layer into the deep learning framework and to learn simu ltaneously image features and hash functions should satisfy independence and quantization errorm inim ized.First,convolutional neuralnetwork is emp loyed to learn the intrinsic im plications of training images so as to imp rove the distinguish ability and exp ression ability of visual feature.Second,the visual feature is putted into the hash layer,in which hash functions are learned.And the learned hash functions shou ld satisfy the classification error and quantization errorm inim ized and the independence constraint.Finally,an input image is given,hash codes are generated by the output of the hash layer of the p roposed framework and large scale im age retrieval can be accom p lished in low-dim ensional hamm ing space.Experim ental resu lts on the th ree benchmark datasets show that the binary hash codes generated by the p roposed m ethod has superior perform ance gains over other state-of-the-art hashing methods.
Image retrieval;Deep convolutional neural networks;Binary hashing;Quantization error;Independence
1 引言
隨著大數據時代的到來,互聯網圖像資源迅猛增長,如何對大規模圖像資源進行快速有效的檢索以滿足用戶需求亟待解決。圖像檢索技術由早期的基于文本的圖像檢索(Text-Based Im age Retrieval,TBIR)逐漸發展為基于內容的圖像檢索(Content-Based Im age Retrieval,CBIR),CBIR通過提取圖像視覺底層特征來實現圖像內容表達。視覺底層特征包括基于梯度的圖像局部特征描述子,如SIFT[1](Scale-Invariant Feature Transform),HOG[2](Histogram of Orientated G radients)等。與人工設計的特征相比,深度卷積神經網絡(Convolutional Neural Networks,CNNs)更能夠獲得圖像的內在特征,且在目標檢測、圖像分類和圖像分割等方面都表現出了良好的性能。利用深度CNNs學習圖像特征,文獻[3]首先提出了一個提取圖像特征的框架,且在ImageNet數據集上取得了不錯的效果。
The National Natural Science Foundation of China(61301232)
TP391.4
A
1009-5896(2016)08-2068-08
10.11999/JEIT 151346
2015-12-01;改回日期:2016-04-29;網絡出版:2016-06-24
彭天強p tq_drum boy@163.com
國家自然科學基金(61301232)
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
