油氣生產大數據挖掘系統的研究及應用
2016-10-13 21:25:19檀朝東張恒汝馬永忠楊兵王輝萍
數碼設計 2016年1期
檀朝東,張恒汝,馬永忠,楊兵,王輝萍
?
油氣生產大數據挖掘系統的研究及應用
檀朝東1*,張恒汝2,馬永忠3,楊兵3,王輝萍1
(1.中國石油大學(北京)石油工程學院,北京昌平,102249;2. 西南石油大學計算機科學學院,成都610500;3.中石油華北油田采油五廠,河北辛集,052360)
隨著智能油田建設的不斷推進,油氣生產數據呈爆炸式增長。由于其數據結構復雜,形式多樣,以及數據深度分析需求的增長,為挖掘工作帶來了機遇與挑戰。本文采用數據融合技術,搭建復雜油氣生產過程的大數據挖掘平臺,根據特定的挖掘目標,建立專題數據庫,快速定制相應數據挖掘算法和石油工程業務模型,形成適應用戶需求的數據挖掘應用系統,實現油氣生產智能化診斷、預測、優化及輔助決策。
智能油田;大數據;灰色關聯;聚類分析;時序預測
引言
隨著數字油田的快速發展,油田生產過程的自動化和信息化程度不斷提高,產生了采油與地面工程的生產、作業等多個類型的海量數據。其年增長速度從MB級迅速發展到TB、PB、EB、ZB級,形成“數據量的急劇膨脹”和“數據深度分析需求的增長”這兩大趨勢。油氣生產是一個復雜的過程,包括了采油、采氣、注水及油氣集輸等諸多環節。油氣生產中積累的數據具有如下特點[1]:(1)數據量巨大、高維且有較強的耦合性。油氣生產中數據采集頻繁、采集密度大,且存在重復冗余數據,系統眾多參數間相互影響,共同作用其行為狀態;(2)油氣生產系統具有不穩定性,且采集數據因工業噪聲易受污染;(3)動態性與數據類型的多樣性。油氣生產中油氣井產量、注水量、油壓,溫度、設備狀態等參數都隨時間不斷變化,并包括邏輯型、數值型等多類型數據;(4)多時標性與不完整性。不同參數采集頻率不同,數據粒度不同,且數據記錄的不同步可能出現數據丟失;(5)多模態性,油氣生產系統中存在正常工作狀態,也存在故障的工況。這些特性使得傳統的數據庫系統架構難以支撐挖掘任務,傳統的模型和算法,比如聯機事務處理(OLAP)無法充分、有效地挖掘數據中隱藏的有價值信息。因此,有必要研究面向大數據的油氣生產數據挖掘系統,實現油氣生產智能化診斷、預測和優化,提高決策能力,降低油氣生產成本。海量數據。
1 油氣生產大數據挖掘系統的技術研究
傳統的數據挖掘技術及其體系架構在應對海量數據時已經出現了不少問題,特別是挖掘效率的問題。基于小數據的挖掘算法或基于數據庫、數據倉庫的挖掘技術及并行挖掘已經很難高效地完成海量數據的分析處理。傳統的體系架構基本是在以單個算法為整體模塊,用戶只能使用已有的算法或重新編寫算法完成本專業獨特的業務。“大數據”出現后,需求將不再完全由業務部門明確提出,更多將由技術、模型、經驗等綜合驅動[2]。同時,從基礎設施架構到分析應用,“大數據”的處理方式和技術發生改變,需要對所有與數據生成、傳遞、處理有關的系統進行重新規劃和布局,需要對原有的數據架構、數據標準、接口規范等重新設計和統一,需要對企業內外部數據環境進行全面分析,經整體綜合考慮后,制定數據模型、架構和解決方案,最終形成“以數據驅動決策”的全新信息化頂層架構。
1.1 基本思路
以油氣生產物聯網系統中的PLC/DCS/FCS/CIPS采集積累的動態數據、油井的基礎數據、化驗、試驗、人工記錄日志、解釋成果數據為數據源[3-4],進行數據預處理,以解決數據的不完整性、噪聲及重復、冗余問題等提高數據質量;之后通過集成的數據挖掘系統運用各種數據挖掘新算法進行知識、規則提取,狀態辨識及模式的建立;并以油氣生產領域的管理、操作、監督人員熟悉的方式可視化,對所獲取的知識、規則及模式進行評估檢驗,確定其可信度;應用發掘的有用知識、規則及模式對油氣生產系統實施監控、診斷、優化或豐富知識庫。數據挖掘的過程并非一次就能成功或結束,而是一個不斷的、反復的過程,從而逐漸獲得有用的新知識[4]。
1.2 油氣生產挖掘系統的平臺架構
為進行復雜工業過程中的數據挖掘,在遵循數據挖掘一般方法的基礎上,詳細分析了油氣生產大數據特點,并結合工藝上的要求進行算法的設計與實現。油氣生產涉及采油、注水、集輸等多個工藝流程,雖然這些工藝的數據形式,分析所用的關鍵指標都存在一定的差異,但數據挖掘的思路基本采用經典的幾種方案。
分析某個工藝過程的工作狀態時,從油田的勘探、鉆井、錄井、試采、試氣、井下作業、油氣集輸等多個數據源中抽取所需數據,對數據進行預處理工作,建立相應的專題數據庫,根據特定的挖掘目標,配置相應數據挖掘算法和石油工程業務模型,快速定制成油氣生產領域不同目標下的數據挖掘應用系統,如圖1所示。
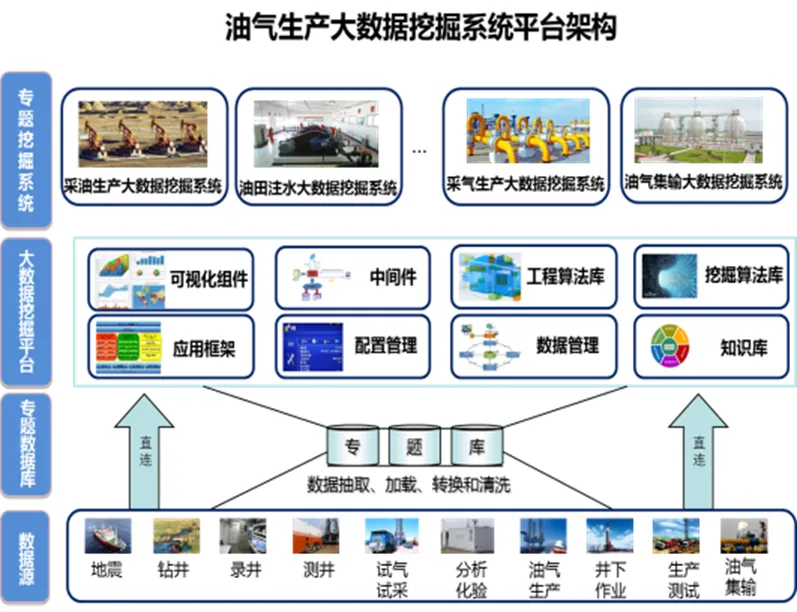
圖1 油氣生產大數據挖掘平臺架構
通過不斷的迭代,以及專家的參與,最終獲得符合需求的新知識。
1.3 高效的數據管理
由于油氣生產的數據來源多樣,數據管理支持多種數據類型管理(oracle數據庫、Sql Server數據庫、excel文件等),實現數據自動抽取、自動計算、自動過濾等。其次,各數據源間可能出現數據冗余、重復,相同數據定義不一致、數據錯誤等情況,因此將所需數據從多個數據源中抽取出來,并進行數據預處理,集中到數據挖掘庫中。
數據的預處理工作主要包括數據清洗、數據集成、數據轉換及數據歸約等操作。通過數據清洗,如缺失值處理、消除數據噪聲、數據不一致處理,保證了數據的完整性、連貫性和正確性。通過數據集成,合并多數據源的數據庫、數據立方體或一般文件,存放到一個一致的數據存儲中。數據轉換則用于將數據變換或統一成適合于挖掘的形式。當處理大型數據集時,還需要對數據進行約簡[5],以節約存儲空間,提高挖掘效率和挖掘質量。
1.4 統計分析與數據可視化
利用統計學和概率論的原理對關系中各屬性進行分析,找出參數之間的關系。將油氣生產系統中的多維多元數據以泡狀圖、餅狀圖、散點圖、立體圖、網格圖、儀表盤等多種形式展示出來,分析參數之間的定性關系。
在此基礎上,運用統計分析方法對生產數據進行定量分析。趨中分析法能夠發現生產系統中參數的一般水平和總體趨勢;離中分析法能夠反映所選數據體的離散程度,反映數據選取的代表性;回歸分析通過具體的函數表達式反映參數之間的相互關系。
1.5 工程算法
工程算法庫實現了對整個油氣生產流程中普遍涉及的重要參數的整理和計算,庫中包括流體物性計算、多相流計算、摩阻計算、熱效率計算、能量守恒、系統節點分析等方法。工程算法庫的建立為不同油氣生產領域中關鍵指標參數提供了計算、分析的方法[6-9]。
多相流的計算有助于了解多相流體在油井及管道中的流型、溫度及壓力變化,對集輸管線、井筒的摩阻進行計算。能夠了解并分析各管段的能量損失,發現某些摩阻值異常大的管段的位置并及時采取應對措施。系統節點分析按油氣生產的工藝流程分為一定數量的子系統,對某一節點分別進行上下子系統的分析,再將兩端結合在一起求解節點,保證油氣生產的協調性和高效性。
1.6 油氣生產系統的診斷與預警模型
針對油氣生產的整個過程,運用多種挖掘算法如灰色關聯[10]、聚類分析[11]、因素分析[12]、主成分分析、時序分析[13]、BP神經網絡[14]等進行分析,找尋蘊藏在數據背后的生產規律,發現生產中容易忽視的問題,為后期生產措施的調整提供指導。
灰色關聯分析法能夠分析系統內部參數之間的聯系,聚類分析能夠對油氣生產的大量數據記錄進行分組,分析各組數據內部的相似性和每組數據總體的相異性。運用以上方法對生產過程,設備狀態的當前數據進行在線挖掘分析,發現系統的異常工況。時間序列分析方法能夠針對油氣生產的關鍵指標,基于其大量的歷史數據,預測該指標的未來走勢,當指標值超出預設值時觸發報警機制,確保工作人員及時發現生產中的故障并進行搶修,保證生產安全。
1.7 構建油氣生產參數優化模型
利用挖掘算法對油氣生產參數進行優化,在滿足必要的約束條件下,改變生產過程的工藝參數,建立與經濟效益有關的目標函數,并使其達到極值。在生產優化實施中,對大量生產數據進行挖掘找到目標與工藝參數的模型關系。利用BP神經網絡、粒子遺傳挖掘,找到系統效率、能耗與工藝參數的模型關系。分析諸多變量作用下的能耗變化規律,幫助工藝人員弄清影響的主次因素,提出相應的對策,進一步調整工藝參數,進行運行和安全控制,為實現生產過程操作最優化提供指導。
1.8 基于知識庫的智能控制
油氣生產過程對象已變為一個十分復雜的系統,產生了更為困難的過程控制問題以及對高性能控制器的要求。例如,抽油機井的柔性變速驅動系統,通過建立油層滲流、抽油機變速運行的運動學及動力學模型和機-桿運動動力學耦合模型,考慮慣性載荷對抽油機的運行動力特性影響,及懸點載荷中的振動載荷和慣性載荷的變化規律,獲得油井供排協調的沖次和懸點最優速度分布曲線,并優化計算得到曲柄最優速度運行曲線,從而建立機采裝置柔性優化運行控制策略,實現柔性控制[15]。該系統結構復雜,計算量大,應用經典的控制方法難以勝任,通常必須有知識庫作為支持,而知識的獲取是關鍵。數據挖掘技術可以將提取的潛在模式、規則評估檢驗后歸入知識庫,使得高等控制充分發揮作用,提高油氣生產過程的控制水平。
2 油氣生產大數據挖掘系統應用
油氣生產大數據挖掘系統在采油、注水、集輸等專業子系統中進行了應用[6-9]。
2.1 以“百米噸液耗電量”為目標的采油工程挖掘
在應用[9]中,以“百米噸液耗電量”為分析目標,利用灰色關聯分析方法,將參與分析的因素對分析目標的影響程度進行排序,得到主要影響因素,從而采取針對性措施。采用因素評價方法,對泵效、地面效率、井下效率、抽油機平衡率等指標進行評價,可以幫助用戶了解評價指標的好壞,根據評價結果,對相關工藝采取措施。利用聚類分析方法,以百米噸液耗電量、系統效率、動液面等為分析參數進行聚類分析,根據聚類分析的結果,以百米噸液耗電量低的一組油井的動液面和系統效率為參考指標,對相關參數進行調節,達到降低百米噸液耗電量的目的。利用時序分析方法,預測關鍵指標未來一段時間內的變化情況,通過設置指標上下限,可對其進行預警,從而輔助油田現場生產管理。利用BP神經網絡方法,對沖次、平衡指數、泵效、操作參數等進行優化,得到百米噸液耗電量最小的運行參數。
通過對岔105井的百米噸液耗電影響因素進行灰色關聯分析,結果表明:沖次與百米噸液耗電關系最密切,其次是平均有功功率,沖程的影響比較低。如表1所示。
表1 百米噸液耗電灰色關聯分析結果

影響因素沖次有效功率地面效率功率因數最小載荷最大載荷關聯度泵效沖程 關聯度0.720.550.520.480.480.440.420.410.34
2.2 以降低“注水單耗”作為目標的注水系統挖掘
在應用中,以“注水單耗”為分析目標,繪制注水井配注完成率與井口壓力宏觀控制圖,可對當前注水井的生產工況進行監測及分析。利用灰色關聯分析方法,將參與分析的因素對分析目標的影響因程度進行排序,得到主要影響因素,從而對降低注水單耗采取針對性措施。利用因素評價方法,對注水泵效率、注水系統效率、管網效率、注水單耗等指標進行評價,根據評價結果,對相關環節采取措施。利用聚類分析方法,以油壓、滲透率、注水量為分析參數進行分析,對參數異常的井進行措施作業及重點關注,例如趙一聯注水站水井自動聚類成3類,見表2所示,其中,油壓高、滲透率低、注水量一般的井需要進行措施作業,降低注入壓力;油壓一般、滲透率一般、注水量大的井需要進行重點關注,查看是否發生水竄。應用基于粒子群算法(PSO)和遺傳算法(GA)的神經網絡方法,對注水泵機組參數、管網高低壓、單井注水參數、注水系統技術經濟指標等進行參數優化,獲得合理的運行參數。
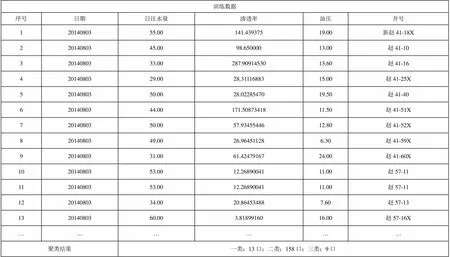
表2 趙一聯注水站水井聚類分析結果
3 結語
基于復雜的油氣生產工藝流程及采集的數據的特點,研究了油氣生產系統大數據挖掘平臺的架構體系,快速定制針對不同挖掘目標的油氣生產大數據挖掘系統。該系統可以油氣生產海量的多維、多源數據為基礎,建立特定挖掘應用的專題數據倉庫,采用了灰色關聯分析、聚類分析與神經網絡等方法形成挖掘模型,對油氣生產系統進行診斷、分析和優化,可以實現:1)發現油氣生產過程各個指標的異常情況;2)油氣田各個生產要素之間的關聯關系;3)預測油氣水井生產指標變化趨勢和增產增注措施效果;4)預測工藝流程的安全性和工況效率指標;5)生產設備壽命預測和維修預警;6)科學地對油氣生產活動和成本控制提出預警和優化等。系統可以滿足不同的用戶需求實現專題挖掘個性化定制。
[1] 羅印升,李人厚等. 復雜工業過程中數據挖掘模型研究[J].信息與控制.2003, 32(1):35-31.
[2] 檀朝東,陳見成,劉志海等,大數據挖掘技術在石油工程的應用前景展望[J].中國石油和化工,2015,1:49-51
[3] TAN C D, WANG H Y, REN G S,et al. The technology research of intelligent production engineering system for oil gas, ICRSM–SEPTEMBER 2013:152-156
[4] 關成堯,檀朝東,田春華等. 基于物聯網的抽油機井系統效率實時計算技術研究.石油地質與工程[J]. 2013, 1, 27(1): 134-136.
[5] MIN F, HE H P, QIAN Y Y, et al, Test-cost-sensitive attribute reduction, Information Sciences, 2011, 181(22), 4928-4942.
[6] TAN C D, Patrick Bangert, Bailiang Liu,et al. Increase of oil production yield in shallow-water offshore oil wells in the dagang oilfield via machine learning. World Oil,November 2010, 37-40.
[7] 劉萍,檀朝東, 劉暢.基于灰色關聯分析法的SAGD新井組注采參數的優選.中國石油與化工[J]. 2014, 12, 52~55.
[8] 檀朝東,曾霞光等.利用最小二乘法對抽油機井示功圖自動分類及故障診斷.數據采集與處理[J].2010,12,第25卷.
[9] 李鑫,耿玉廣等. 以噸液百米舉升耗電量為目標的大數據分析應用. 石油鉆采工藝[J].2015,4: 48-52.
[10] 劉思峰,蔡華,楊英杰,曹穎.灰色關聯分析模型研究進展[J].系統工程理論與實踐. 2013(08).
[11] GUO G D, CHEN S and CHEN L F. Soft subspace clustering with an improved feature weight self-adjustment mechanism. International Journal of Machine Learning and Cybernetics, 2012, 3(1): 39-49.
[12] 李洪興.因素空間與模糊決策[J]. 北京師范大學學報(自然科學版). 1994(01).
[13] Adrian Letchford, Junbin Gao and ZHENG L H. Filtering financial time series by least squares. International Journal of Machine Learning and Cybernetics, 2013, 4(2): 149-154.
[14] GAN Q T. Synchronization of competitive neural networks with different time scales and time-varying delay based on delay partitioning approach. International Journal of Machine Learning and Cybernetics, 2013, 4(4): 327-337.
[15] 姜民政, 王慧等. 變速驅動抽油機井運行參數變化規律研究[J].石油礦場機械.2010, 39( 10) : 4- 7.
Research and Application of Big Data MiningSystem for Oil-gas Production
TAN Chaodong1, ZHANG Hengru2, MA Yongzhong3, YANG Bin3, WANG Huiping1
(1.College of Petroleum Engineering, China University of Petroleum, Beijing 102249, China; 2. School of Computer Science, Southwest Petroleum University, Chengdu 610500, China 3.NO.5 Oil Production Company of Huabei Oilfield, PetroChina, Xinji 052360, China )
With the development of the intelligent oil field (IOF), the data volume increases dramatically. These data have complex structures and diverse forms. Urgent requirement of data analysis in this field has introduced more opportunities and challenges of the data mining task. In this paper, we discuss a data mining platform for petroleum and gas big data through data fusion. According to user specified objectives, thematic databases are constructed, data mining algorithms are designed, and petroleum engineering models are built. In this way, a data mining application is implemented for the intelligent diagnosis, prediction, optimization and computer aided decision for the oil and gas field.
intelligent oil field; big data; grey relation; clustering; time-series analysis
1672-9129(2016)01-0053-04
TE3
A
2016-04-27;
2016-06-29。
檀朝東(1968-),男,安徽望江,副研究員,博士,主要研究方向:石油工程、物聯網教學及科研;張恒汝(1975-),男,四川廣安,副教授,碩士,主要研究方向:機器學習、代價敏感粗糙集、推薦系統;馬永忠,男,高級工程師,主要研究方向:采油工程技術研究及應用;楊兵,男,高級工程師,主要研究方向:油氣田開發信息化系統開發及應用;王輝萍,女,江蘇東臺,碩士研究生在讀,主要研究方向:油氣開采技術。
(*通信作者電子郵箱 tantcd@126.com)
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小學科學(學生版)(2020年10期)2020-10-28 07:52:12
中國化肥信息(2020年7期)2020-03-19 01:54:02
電子制作(2018年18期)2018-11-14 01:48:24
中國軍轉民(2017年6期)2018-01-31 02:22:28
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
信息通信技術(2015年6期)2015-12-26 01:16:46
機械制造文摘(焊接分冊)(2014年5期)2014-03-20 13:57:44
