基于云計算的柑橘市場信息預測平臺構建研究*
2016-10-14 07:03:00黃曉英
中國農業信息 2016年14期
王 聰,黃曉英
(浙江農林大學暨陽學院,紹興 311800)
基于云計算的柑橘市場信息預測平臺構建研究*
王 聰,黃曉英
(浙江農林大學暨陽學院,紹興 311800)
文章設計了一種基于Hadoop的柑橘市場信息預測平臺,根據往年的柑橘產量、柑橘消費量、進出口量、庫存量等,通過Apriori算法在云計算平臺Hadoop下實現對影響柑橘價格的各類影響因素和柑橘市場信息之間的關聯分析,根據得出的關聯性和置信度預測柑橘價格和產量,以此構建柑橘市場信息預測平臺,對柑橘價格和產量進行預測。
云計算 數據挖掘 Hadoop 柑橘
目前,中國柑橘生產面積已躍居世界第一,柑橘產業已經成為中國農業生產的重要力量,在發展的過程中,也面臨一系列問題。由于柑橘產量與需求的不平衡,使得柑橘的銷售和增收困難,柑橘價格長期劇烈的波動,使得柑橘種植商的利潤波動大,當柑橘生產量遠遠大于供應量時,就會出現柑橘滯銷、價格低廉,相反就會出現供不應求的情況。如果通過數據挖掘技術,分析柑橘市場每年的供求關系,提前知曉柑橘未來供需缺口的變化,能夠為柑橘生產、消費、進出口制定相應對策提供依據的同時,保證柑橘市場的供需平衡,具有重要的意義。
1 數據挖掘與云計算
隨著數據量不斷的劇增,傳統的數據挖掘算法和分析工具在面臨海量數據時,出現挖掘效率低的問題,由于已有的數據挖掘大多基于傳統的單機模式,無法高效的處理海量數據。同時,擴展已有的挖掘體系,會造成人力物力成本上升,很多中小企業無法承擔如此高昂的成本,而且,數據挖掘成本高,效率低。
云計算的出現,給數據挖掘帶來新的方向。基于云計算的數據挖掘,具有在計算能力、存儲能力、可靠性、價格低等優點,迅速地得到廣泛應用。云計算挖掘平臺可以分為3層,包括數據挖掘云服務層、數據挖掘分析層和云計算支持平臺。云服務層通過網絡連接,為云用戶提供云資源例如挖掘算法服務、數據預處理服務、數據服務、調度服務等;數據挖掘能力層包括數據并行處理、調度引擎等;云計算支持平臺提供分布式存儲和計算能力,為數據挖掘提供物理支持。如圖1所示。
2 基于Hadoop的柑橘市場信息預測平臺設計
2.1 系統設計目標
目前,市場上柑橘種類繁多,柑橘數據來源收受域約束,分布比較分散。同時,這些數據具有時效性,在移動互聯網和各種物聯網的發展下,柑橘的數據量劇增,如果采用傳統數據挖掘體系,無法很好地完成挖掘功能。因此,文章采用基于云計算的Hadoop下的云計算方式進行平臺設計。
該系統設計基于云計算的市場信息預測平臺要滿足以下需求。
(1)存儲具有可擴展性。在存儲層,存儲節點具有可擴展性,由于柑橘數據來源多樣,且很多異構數據。因此,該文采用非關系型數據庫系統的存儲模式存儲數據,存儲方式采用分布式,便于靈活地進行系統擴容和系統伸縮。
(2)集成化、可定制的數據挖掘能力。用戶可以根據實際添加所需要的算法,因此系統實現了可定制的數據挖掘能力。
(3)友好的用戶展示界面。能夠直觀地顯示數據挖掘結果,用戶可以輕而易舉地理解挖掘的含義。
因此,該設計基于云計算的柑橘市場信息預測平臺,具有可靠、高效、性能好、可擴展的特點。
2.2 設計思路及方案
文章設計了基于Hadoop的柑橘市場信息預測平臺,利用Hadoop的強大計算能力和存儲能力,達到以上系統設計目標。
其設計思路是:利用Hadoop的特性,將數據挖掘中需要大的計算能力的算法擴展到Hadoop集群的各個節點上,利用并行計算能力進行數據挖掘工作,提高挖掘效率。采用分層設計思想,存儲層使用HDFS存儲文件和數據,通過Map Reduce計算模型來執行海量數據挖掘。
根據設計思路和云計算數據挖掘模型,通過分層設計思想,自頂向下的調用下層結構,最頂層是用戶和系統的交互層;中間層是業務處理層,提供基礎計算框架和業務邏輯處理;最底層為存儲層,提供分布式存儲。
2.3 系統模塊功能
數據管理框架。數據管理層建立在Hadoop下的HDFS文件系統之上,提供并行數據訪問和高效、可擴展的存儲服務。當系統存儲能力不足時,可以在不影響已有數據情況下,添加新的存儲節點。通過多副本存儲機制保障數據安全,即使有節點出現存儲失效,通過副本機制將失效節點數據轉移到其他節點。
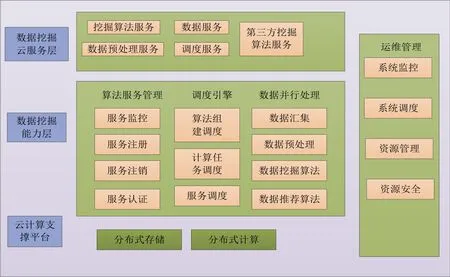
圖1 基于云計算的數據挖掘
基礎計算框架。Map Reduce為系統的基礎計算框架,它可以隱藏底層設計細節,通過簡單的對外接口,實現各種并行計算能力,并且具有很好的擴展性和伸縮性,可以根據實際需求增加或者刪除節點。
算法管理。用戶通過算法管理模塊查看系統提供的算法,并且可以上傳自己設計的算法,實現可定制化的數據挖掘能力。
頁面展示。通過友好的方式展示數據挖掘結果。
數據加載塊。由于數據種類繁多,且來源不同,數據加載模塊將來源各異的數據在數據集管理模塊中進行注冊,然后存儲到HDFS文件系統。
數據挖掘算法模塊。提供各種并行挖掘算法,是基于算法管理模塊的擴展。
數據挖掘。是系統的核心模塊,通過調用業務層的Map Reduce計算框架,提供高效的數據挖掘服務。
3 基于Hadoop的柑橘市場信息預測平臺構建
3.1 Hadoop平臺搭建
平臺采用B/S架構,前臺采用JSP作為開發語言;后臺選擇java語言,采用Tomcat服務器;數據存儲采用MySQL和Hadoop的HDFS;Hadoop采用4臺PC機器作為數據節點。所有機器配置:4臺HP刀片服務器組成一個內部往來,建立一個 4個節點的Hadoop集群。其中 1個節點作為 Master,其余3 個節點作為 Slave,各個節點通過100M網卡進行數據訪問。Master節點服務器CPU:Inter(R)Xeon(R)E5620 2.4GHz 4*4核,Memory:6GB,Disk:500G*8。Salve節 點 服 務 器 CPU:Inter (R)Xeon(TM)3.00GHZ 4核,Memory:1GB,Disk: 146.8G*2。每臺服務器上安裝OS:64 bit CentOS6.2,Hadoop 版本1.0.3和Eclipse版本4.3.1。Hadoop默認參數配置Block為64M,備份數為3。
3.2 預測模型構建
文章采用關聯規則分析中的Apriori算法,對柑橘價格和產量進行分析和預測,主要通過Apriori算法,找出影響柑橘價格和產量之間的置信度,通過置信度構建柑橘市場分析模型,以置信度計算柑橘市場信息。
基于Apriori算法的柑橘市場價格預測模型,如圖3.1所示。整個柑橘價格是建立在2005~2015年的柑橘價格指數、生產量指數、世界柑橘價格指數等基層上,通過我國《中國統計年鑒》發布的數據,導入這10年的柑橘指數作為預測模型基礎。利用這些數據構建數據挖掘模型,利用Apriori算法對這些數據進行挖掘分析,得到各種因素對柑橘價格和產量之間的置信度,然后通過計算模型,實現對柑橘價格和產量的預測(圖2)。
3.3 Hadoop數據預處理
影響柑橘市場的數據主要有柑橘產量、柑橘消費量、進出口量、庫存量等,文章主要通過這些數據,構建柑橘市場預測模型。由于庫存量沒有統計數據,因此,文章不考慮柑橘的庫存量對市場影響。
(1)柑橘產量。柑橘產量數據來源于《中國統計年鑒》。
(2)柑橘消費量,數據來源于《中國農村統計年鑒》,根據家庭人均水果消費量,計算出柑橘中國國內消費數據。
(3)柑橘出口量,數據來源于聯合國貿易數據庫。
(4)國民消費價格指數,國家統計局獲取。
將以上數據存儲到預測模型的數據倉庫中,在單機模式下Apriori算法執行效率低,因此,采用云平臺方法,通過Hadoop實現Apriori算法。在計算過程中,首先將這些數據處理成Html格式存儲到Hadoop中,使用MapReduce對柑橘價格影響因素數據進行提取,之后將Apriori算法預測模型與Hadoop云計算框架關聯。
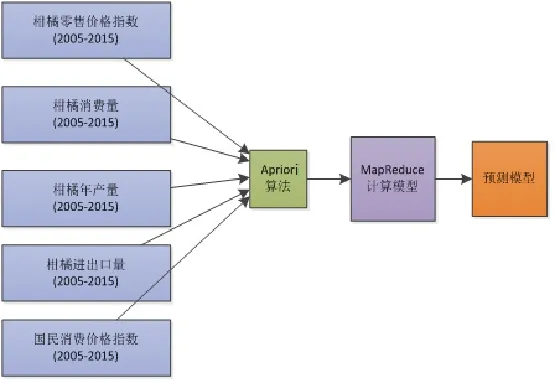
圖2 柑橘市場預測模型
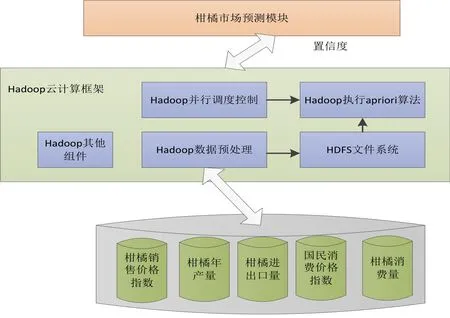
圖3 基于Hadoop的柑橘市場預測模型
4 基于Hadoop的柑橘市場信息預測
經過數據預處理之后,結合Hadoop云計算框架,設計基于Hadoop云計算處理的柑橘市場預測模型,如圖4.1所示,將Hadoop云計算框架部署在Linux虛擬機上,通過Hadoop框架構建整個預測系統,然后設計Hadoop并行Apriori處理任務,將Apriori算法挖掘任務分成多個并行任務,分布到各個計算節點進行處理。同時,通過預處理模塊,從柑橘市場預測數據系統中,導入柑橘產量、柑橘消費量、進出口量、庫存量、居民消費指數到HDFS文件系統中,為Hadoop執行Apriori算法提供數據支持,最大限度地提高Apriori算法的執行效率,最后通過Apriori算法得到各個影響因素,對糧食價格和年產量的置信度,交給柑橘市場預測模塊,進行計算,得到柑橘年產量和價格預測值(圖3)。
以上述模型為依托,從而搭建基于Hadoop的柑橘市場信息預測平臺。
[1] 陳康,鄭緯民.云計算系統實例與研究現狀.軟件學報,2009,20(5):1337~1348
[2] 陳全,鄧倩妮.云計算及其關鍵技術.計算機應用,2009,29(9):2562~2567
[3] 張建勛,古志民,鄭超.云計算研究進展綜述.計算機應用研究,2010,27(2):429~433
[4] 何勁,祁春節.中國柑橘生產成本和市場價格變動的實證研究.浙江柑橘,2009,26(1):2~7
[5] 汪曉銀.中國柑橘市場預警研究.華中農業大學,2013
[6] Witten,Frank I H.Data Mining.Practical Machine Learning Tools & Techniques with Java Implementations,2011,13(4):95~97
[7] 劉永平,郭小波,胡坤倫.采用云計算對糧食價格進行分析和預測.現代食品,2015,(21)
[8] Azuaje F. Witten IH,Frank E: Data Mining: Practical Machine Learning Tools and Techniques. Biomedical Engineering Online,2006,5(1):1~2
[9] 孫吉紅,彭林,鄒秋霞.基于云計算平臺的智能預測模型研究.農業網絡信息,2014,(1):43~46
[10] 徐懿瑾.基于數據挖掘的移動中高端用戶流失預警分析.上海交通大學,2010
[11] Han J,Kamber M. Data Mining: Concepts and Techniques. Data Mining Concepts Models Methods & Algorithms Second Edition,2000,5(4):1~18
[12] 李佳鍞.基于云計算和數據挖掘技術的中小企業風險預測模型研究.廈門大學,2012
[13] Chen M S,Han J,Yu P S. Data Mining: An Overview from a Database Perspective. IEEE Transactions on Knowledge & Data Engineering,1996,8(6):866~883
[14] Romero C,Ventura S,Garc í a E. Data mining in course management systems: Moodle case study and tutorial. Computers & Education,2008,51(1):368~384
[15] White T. Hadoop : the definitive guide. O’reilly Media Inc Gravenstein Highway North,2010,215(11):1 ~ 4
[16] O’Driscoll A,Daugelaite J,Sleator R D. ‘Big data’,Hadoop and cloud computing in genomics. Journal of Biomedical Informatics,2013,46(5):774~781
[17] Borthakur D,Gray J,Sarma J S,et al. Apache hadoop goes realtime at Facebook// Proceedings of the 2011 ACM SIGMOD International Conference on Management of data. ACM,2011:1071~1080
[18] Dean J,Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters.. In Proceedings of Operating Systems Design and Implementation OSDI,2004,51(1):107~113
[19] Dean B J. et al .MapReduce:Simplifieddataprocessing on large clusters. Osdi’,2010,51(1):107~113
[20] 覃雄派,王會舉,杜小勇,等.大數據分析——RDBMS與MapReduce的競爭與共生. 軟件學報,2012,23(1):32~45
[21] 孫廣中,肖鋒,熊曦. MapReduce模型的調度及容錯機制研究. 微電子學與計算機,2007,24(9):178~180
[22] 孫廣中,肖鋒,熊曦. MapReduce模型的調度及容錯機制研究.全國開放式分布與并行計算機學術會議,2007:178~180
[23] 萬至臻.基于MapReduce模型的并行計算平臺的設計與實現.浙江大學,2008
[24] 陳艷金. MapReduce模型在Hadoop平臺下實現作業調度算法的研究和改進.華南理工大學,2011
[25] 鐘曉,馬少平,等.數據挖掘綜述.模式識別與人工智能,2001,14(1):48~55
[26] 程苗.基于云計算的Web數據挖掘.計算機科學,2011,(Z1):146~149
[27] 王鄂,李銘.云計算下的海量數據挖掘研究.現代計算機:專業版,2009,(11):22~25
[28] 紀俊.一種基于云計算的數據挖掘平臺架構設計與實現.青島大學,2009
[29] 李軍華.云計算及若干數據挖掘算法的MapReduce化研究.電子科技大學,2010
[30] 賀瑤,王文慶,薛飛.基于云計算的海量數據挖掘研究.微機發展,2013,(2):69~72
教育部人文社科基金項目(12YJA870008);浙江農林大學暨陽學院大學生科技創新項目(TMKC1442)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電力與能源(2017年6期)2017-05-14 06:19:37
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
