基于Hadoop的海量數據存儲技術的研究
2016-11-03 08:34:32袁麗娜
中國新通信 2016年19期
袁麗娜
【摘要】 隨著社會信息化程度的不斷提高,傳統的數據存儲技術已經不能滿足需求。本文基于Hadoop平臺,對其海量存儲技術進行了專門研究分析,從海量數據存儲的容錯性、可擴展性和延遲性、實時性、性能等四個方面對目前海量數據存儲技術進行了分析評價。
【關鍵詞】 Hadoop 海量數據處理 分布式存儲技術
引言
隨著社會信息化程度的不斷提高,互聯網應用的多元化及快速發展,傳統的數據存儲技術在處理能力和存儲容量的可擴展性已經不能完全滿足需求。如今大數據時代下的海量數據存儲出現了新的特點:(1)數據規模巨大,且增長快速。(2)訪問并發程度高。(3)數據結構及處理需求的多樣化。在線數據訪問和離線數據分析的應用,對系統可靠性的要求也越來越高。在這種情況下,基于Hadoop的分布式存儲技術應運而生。
一、Hadoop概述
1.1 簡介
隨著海量數據的不斷快速增長,各大公司紛紛對其相關技術進行研究。Google在開發了MapReduce、GFS和BigTable等技術之后,開源組織Apache模仿并發布了開源的Hadoop分布式計算框架和分布式文件系統。
Hadoop是一個開源的分布式計算平臺,其核心是分布式計算框架MapReduce和分布式文件系統HDFS,主要用于處理海量數據,能在大量計算機組成的集群中運行海量數據并進行分布式計算。
1.2 體系結構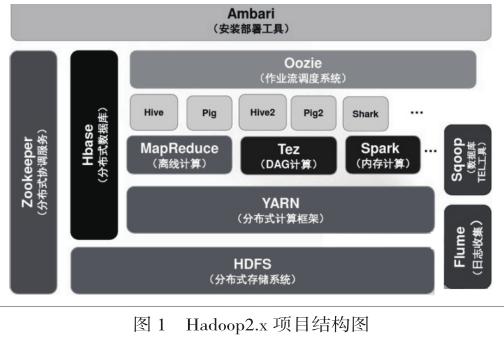
Hadoop主要設計用來在由通用計算設備組成的大型集群上執行分布式應用的框架。經過多年的發展,逐步形成了其應用程序生態系統,以Hadoop2.x版本為例,其族群中包括很多子項目:分布式文件系統HDFS、分布式并行編程模型和程序執行框架MapReduce、資源管理器YARN、配置管理工具Ambari、分布式且按列存儲的數據庫Hbase、數據倉庫Hive、數據流語言和運行環境Pig、數據挖掘Mahout、分布式且可用性高的協調服務ZooKeeper、關系型數據庫同步工具Sqoop、日志收集工具Flume等,其中MapReduce和HDFS最重要,在核心層上提供了更高層的互補性服務。Hadoop2.x的項目結構如圖1所示。
MapReduce是一種簡化并行計算的編程模型,用來解決大規模數據處理的問題。其主要思想是將需要自動分割執行的任務拆解成映射Map和簡化Reduce的方式。Map主要負責把單個任務分解成多個任務,Reduce則負責把分解后的多任務處理結果進行匯總。MapReduce任務由一個JobTracker節點和多個TaskTracker節點控制。JobTracker主要負責和管理TaskTracker,而TaskTracker具體負責這些任務的并行執行。
HDFS分布式文件系統可以和MapReduce編程模型很好地結合,用于存儲海量數據。HDFS采用主從模式的結構,HDFS集群由一個名字節點NameNode和若干個數據節點DataNode所組成。NameNode是主服務器,主要負責管理文件系統的命名空間和客戶端對文件的訪問操作,而DataNode主要負責節點數據的存儲。
YARN是Hadoop 2.x中新引入的資源管理系統,它的引入使得Hadoop不再局限于MapReduce一類計算,而是支持多樣化的計算框架。它由兩類服務組成,分別是ResourceManager和NodeManager。
二、海量數據存儲技術研究
分布式文件系統HDFS是Hadoop的核心技術之一,是基于Hadoop的分布式存儲架構中數據存儲的基礎。Hadoop2. x中HDFS體系結構如圖2所示。
接下來,本文基于Hadoop的海量數據存儲技術,從容錯性、可擴展性和延遲性、實時性以及性能這4個方面對海量數據存儲技術進行研究分析。
2.1海量數據存儲的容錯性
目前海量數據存儲系統中,為獲取較高可靠性,通常使用完全的數據復制技術和磁盤冗余陣列技術(RAID)兩種冗余容錯方法。RAID 技術在傳統關系數據庫及文件系統中應用比較廣發,但不太適用于NoSQL數據庫及分布式文件系統。
Hadoop使用HDFS存儲海量數據。文件通常被分割成多個塊進行存儲,每個塊至少被復制成三個副本存儲在各個數據節點中。HDFS可以部署在大量廉價的硬件上,因此一個或多個節點失效的可能性很大,所以HDFS在設計時采用了多種機制來保障其高容錯性,但有些也存在著一些問題。
1、HDFS中NameNode
NameNode是HDFS集群中的主節點,也是中心節點,它的可靠性直接關系到整個集群的可靠性。對于不同版本的Hadoop對此也有不同的處理機制。Hadoop1中只有一個NameNode節點,所以存在單節點故障問題,而在Hadoop2.x中通過HA策略大致解決了NameNode的單點問題。即存在兩個NameNode,一個是狀態為活動的 active namenode,另一個是狀態為停止的standy namenode,兩者可以進行切換,但是有且只有一個屬于活動狀態。目前,Hadoop 2.x中提供了兩種HA方案,一種是基于NFS共享存儲的方案。此方案中,NFS作為active namenode和standy namenode之間數據共享的存儲,但若active namenode 或者standy namenode中有一個和nfs之間發生網絡故障,將會造成數據同步不一致。另一種是基于Paxos算法的方案Quorum Journal Manager(QJM),它的基本原理就是用2N+1臺JournalNode存儲EditLog,每次寫數據操作有大多數(>=N+1)返回成功時即認為該次寫成功,數據即不會丟失,可以實現namenode單點故障自動切換。
2、HDFS數據塊副本機制
HDFS中一個文件由多個數據塊組成,每個數據塊包含多個副本,副本的數量可以通過參數設置。副本是一種能夠提高數據訪問效率和容錯性能的技術。Hadoop在數據存儲方面可以自動將數據保存到不同機架的多個副本中,在數據計算方面也可以自動將失敗的任務重新分配到其他的節點上。Hadoop2.x版本對于數據副本存放磁盤選擇策略有兩種方式,一種是低版本中的磁盤目錄輪詢方式,另外一種是選擇可用空間足夠多的磁盤方式。
3、HDFS心跳機制
HDFS中的NameNode通過心跳機制掌握整個集群的工作狀態。DataNode通過周期性向NameNode發送心跳信息,即NameNode通過DataNode的心跳信息來獲知DataNode的存在、其上的磁盤容量、已用剩余空間和負載等信息。
2.2海量數據存儲的可擴展性和延遲性
可擴展性和延遲性是分布式文件系統評判性能的兩個重要指標。Hadoop 的HDFS 分布式文件系統的設計主要用于處理大文件,以流式方式訪問數據,一次寫入,多次讀寫。對于HDFS,讀取整個數據集要比讀取一條記錄更加高效。所以HDFS不合適處理處理小文件,即大小小于HDFS塊大小的文件。這樣的小文件會給Hadoop的擴展性和性能帶來嚴重問題。因為并行的I /O 接口并不支持小文件的處理,所以讀寫延遲時間比較長,且主節點很難在云存儲系統中進行擴展。因此,文獻[1]提出了一種基于混合索引的HDFS小文件存儲策略,采用應用分類器分類標記小文件,在存儲節點根據小文件大小建立不同的塊內索引,用以提高小文件訪問效率。文獻[2]提出一種基于多維列索引的小文件管理方案,且提出了小文件合并方案。文獻[3]提出了一種面向低延遲的內存HDFS數據存儲策略,提出了基于HDFS的內存分布式文件系統架構Mem-HDFS,且利用集群數據節點的內存和磁盤存儲數據,并提出一種并行讀取算法,該算法能較好降低讀取訪問延遲。
經研究發現,現有的對分布式文件系統處理海量小文件中所遇到的瓶頸問題,其改進大致包括以下兩種方式,第一種方式是通過建立索引的方式,把小文件合并成大文件;第二種方式是建立緩存機制,從而減少文件訪問次數。
2.3海量數據存儲的實時性
Hadoop 最初被設計為解決大量數據離線情況下批量計算的問題,是為了處理大型數據集分析任務的,是為了達到高的數據吞吐量,因此,需要延遲性作為代價。對于大多數反饋時間要求不是特別高的應用,比如離線統計分析、機器學習、推薦引擎的計算等,都可以采用Hadoop進行離線分析的方式。基于Hadoop 的分布式文件系統能夠很好地完成海量數據存儲的要求,但還是缺乏了實時文件獲取的考慮。因此,海量數據存儲的實時性還有待提高,目前主要通過和傳統關系型數據庫相結合,實現其實時性。文獻[4]提出了一種自定義的內存處理引擎,通過把基于Hadoop 的分析平臺和數據流處理引擎進行結合,實現海量數據環境下實時處理數據的構想。
2.4海量數據存儲的性能
HDFS在選擇數據存放節點時,并沒有考慮到集群中各數據節點的性能、網絡狀況和存儲空間的差異性,從而很容易造成集群整體負載不均衡,數據節點的資源不能合理利用等。因此,文獻[5]提出了確定環境下多階段多目標CMM決策模型,此模型以內存、CPU和磁盤的剩余負載能力作為決策條件,以負載均衡效果、數據傳輸代價和負載遷移代價作為決策目標,根據決策節點間的影響關系來構建有向無環圖,通過多個決策階段的決策及計算方案效果來確定最優均衡方案。
三、結束語
本文針對最新Hadoop框架下的海量數據存儲技術,分別從海量存儲技術的容錯性、可擴展性和延遲性、實時性及性能等四個方面進行了深入的研究,分析概括了目前Hadoop的分布式文件系統在存儲海量數據時所遇到的一些問題及挑戰,并對現有的存儲改進方式進行了綜述。
在海量數據存儲的容錯方面,目前Hadoop2.x最新版本的HA策略已經解決了NameNode的單點問題,但新引入的YARN同樣存在單點故障及性能問題,對于HDFS如何能更高效更好地動態分配數據塊副本機制,相關文獻提出了多目標優化的局部最佳副本分布策略,提出了基于范德蒙碼的HDFS分散式動態副本存儲優化策略;在海量數據的可擴展性和延遲性方面,主要是小文件的存儲策略問題,相關文獻主要提出采用索引方式將小文件合并為大文件進行讀取,通過緩沖機制減少訪問次數;海量數據存儲的實時性方面,目前主要通過和傳統關系型數據庫相結合,通過緩存機制實現實時讀取;在海量數據存儲的性能方面,主要是負載均衡問題,相關文獻主要提出通過采集數據節點的各方面負載,通過計算成本來選擇最優數據節點存儲[9]。
目前,基于Hadoop的海量存儲技術在如何高效存儲及讀取小文件,如何實現數據的實時分析,數據節點的負載均衡問題等方面依舊是將來研究的熱點。
參 考 文 獻
[1]王海榮等. 基于Hadoop的海量數據存儲系統設計[J].科技通報,2014.30(9):127-130
[2]尹穎等. HDFS中高效存儲小文件的方法[J]. 計算機工程與設計,2015.36(2):406-409
[3]英昌甜等. 一種面向低延遲的內存HDFS數據存儲策略[J]. 微電子學與計算機,2014.31(11):160-166
[4]張柄虹等. 空間高效的分布式數據存儲方案[J].計算機應用研究,2015.32(5):1508-1511
[5]盧美蓮等. 基于CMM模型的HDFS負載均衡策略[J]. 北京郵電大學學報,2014.37(5):20-25
