基于歷史數據的異常域名檢測算法
2016-11-24 08:29:39袁福祥劉粉林蘆斌鞏道福
通信學報 2016年10期
袁福祥,劉粉林,蘆斌,鞏道福
(1. 解放軍信息工程大學網絡空間安全學院,河南 鄭州 450001;2. 數學工程與先進計算國家重點實驗室,河南 鄭州 450001)
基于歷史數據的異常域名檢測算法
袁福祥1,2,劉粉林1,2,蘆斌1,2,鞏道福1,2
(1. 解放軍信息工程大學網絡空間安全學院,河南 鄭州 450001;2. 數學工程與先進計算國家重點實驗室,河南 鄭州 450001)
提出一種基于域名歷史數據的異常域名檢測算法。該算法基于合法域名與惡意域名歷史數據的統計差異,將域名已生存時間、whois信息變更、whois信息完整度、域名IP變更、同IP地址域名和域名TTL值等作為主要參量,給出了具體的分類特征表示;在此基礎上,構建了用于異常域名檢測的SVM分類器。特征分析和實驗結果表明,算法對未知域名具有較高的檢測正確率,尤其適合對生存時間較長的惡意域名進行檢測。
異常域名;域名歷史數據;特征;檢測
1 引言
近年來,隨著網絡技術的不斷發展,網絡中出現的各種威脅也不斷增加,如惡意軟件[1]、僵尸網絡[2]和木馬[3]等。其中,僵尸網絡和木馬在發動諸如垃圾郵件、網絡釣魚[4]等惡意行為的過程中往往都通過域名系統,即DNS解析域名獲取回連服務器的IP地址,從而隱藏躲避在僵尸代理身后的命令與控制服務器(Camp;C, command-and-control server)[5~8],回連控制端接收控制消息或回傳盜取的數據信息,躲避檢測和封堵,提高自身的頑健性,延長生命周期。由此可見,域名在僵尸網絡及木馬發動攻擊行為的過程中發揮了至關重要的作用,因此,如何對此類攻擊中所使用的域名進行檢測,對于發現并防范僵尸網絡及木馬的傳播具有極為重要的意義。
目前,針對異常域名檢測的研究大致包括基于域名自身特性、域名網絡行為特性的檢測方法等。如文獻[9]主要從域名的字符構成角度,通過分析合法域名與算法產生的惡意域名在字符構成方面的差異,對惡意域名進行檢測,實驗表明,該方法能夠檢測出網絡中出現的算法產生的惡意域名。文獻[10]從域名的注冊信息等特性出發,將輸入的已知惡意域名作為種子,通過種子域名的域名服務器特征和注冊信息特征推測出與該種子可能為同一批的惡意域名,并利用相關的黑名單對推測結果進行驗證,結果表明,73%的推測域名最終出現在黑名單中。文獻[11]基于木馬使用域名進行回連這一事實,對木馬域名進行分析,提取出域名使用時間、訪問域名周期和域名IP地址所屬國家變更等特征,實驗結果表明,該檢測準確率與之前的方法相當。文獻[12]設計了一個域名信譽系統——Notos,該系統使用被動 DNS查詢的數據,分析域名的網絡特征,為已知域名建立模型,并用該模型為新域名計算信譽分數,該檢測方法準確率較高,并能夠在惡意域名被列入黑名單幾周甚至幾個月前檢測出惡意域名。文獻[13]提出了 Kopis檢測系統,該系統通過對頂級域名服務器以及權威域名服務器進行監測獲取數據提取特征,能夠檢測惡意軟件相關的域名,該方法可以從全球的角度對域名的請求、解析等網絡行為進行分析,相比于其他方法監測范圍更廣。文獻[14]提出了Exposure檢測系統,該系統通過對真實的DNS流量數據分析,從DNS應答以及域名構成等方面出發提取特征,該方法能夠對真實網絡中的域名進行高效的檢測。文獻[15]基于域名的長度、域名中存在的特殊字符、域名的被解析次數、被解析時間以及被解析出的IP的變化等來構建特征,該檢測能夠從真實的 DNS數據中檢測出惡意域名。
縱觀現有的異常域名檢測方法都各有所長,且有各自適用的范圍。相對而言,基于域名網絡行為分析的檢測方法(如文獻[13]),其檢測正確率較高,且適用范圍較廣,但該類方法需要從頂級域名服務器、權威域名服務器或者遞歸解析域名服務器獲取大量的域名解析數據。然而,無論是頂級域名服務器、權威域名服務器還是遞歸解析域名服務器,其流量數據都很難獲取。本文基于域名的自身特性及網絡行為特性相關的歷史數據,根據合法域名與惡意域名whois、解析IP變更及TTL等信息存在的差異,提出了一種惡意域名檢測算法,該算法通過對域名的whois信息、域名解析的IP變更信息、同IP地址域名數量以及域名的TTL值這些數據的統計分析,量化出用于分類的四維特征,使用已知的合法域名與惡意域名作為訓練數據集,并對 SVM(support vector machine)[16]分類器進行訓練,使用訓練好的分類器對測試域名集合進行檢測。特征分析與實驗表明,算法在能獲取到一定量的歷史數據條件下,能夠有效識別出具有一定生存時間的可疑域名,尤其對域名生存期較長的異常域名具有更高的可靠性。同時,本文所使用的數據較易獲取,且處理數據量也較小。
2 域名相關數據分析與分類特征具體表示
大量的域名歷史數據表明,惡意域名與合法域名在whois信息變更、域名whois信息完整度、IP變更、同 IP域名數量和TTL等方面表現出不同的性態,并且這種差異與域名的生存時間密切相關。本節將基于這種差異特性,首先給出相關數據對分類貢獻的分析,然后給出分類特征的具體表示。
2.1 域名相關數據分析
域名的 whois信息更新次數、whois信息完整度、IP變更、同IP域名數量、域名的TTL值等可以通過相關的域名信息網站及查詢工具獲得,這些數據對惡意域名與合法域名而言,會隨域名生存時間的增長而表現出某種穩定的性態,這種穩定的性態對異常域名的檢測有著不同的貢獻,下面將給出這些數據的具體分析。
1) 域名whois信息更新次數。whois是一個用來查詢域名是否已經被注冊,以及已注冊域名的詳細信息的數據庫,這些信息包括域名的注冊組織、域名的注冊商以及注冊時間、更新時間等。為保證域名的可用性,注冊商或域名持有者可以對域名的相關注冊信息加以更新。一般而言,合法域名經常被用戶查詢,為保證域名更好地服務于用戶,域名持有者會對域名的whois信息及時更新,其whois信息更新次數往往較多;而惡意域名僅僅為惡意攻擊服務,攻擊者往往并不關心域名的whois信息,大部分惡意域名持有者并不需要及時更新whois信息,其whois信息更新次數往往較少。此外,域名的whois信息更新次數與域名已生存時間存在著相應的關系,就統計意義而言,生存時間越長惡意域名與合法域名在whois信息更新次數上的區別將會越明顯。圖 1給出了 2類域名共 2000個樣本的whois信息更新次數隨域名已生存時間變化的樣本具體分布情況,分布結果表明,隨著生存時間的增長,合法域名whois信息更新次數較多,更新速率較快,而大部分惡意域名whois信息更新次數幾乎不變,二者有較為明顯的差異。

圖1whois信息更新次數隨域名已生存時間變化的域名分布
2) 域名whois信息完整度。域名持有者在注冊某個域名時,往往會提供相關的域名信息。合法域名為了能夠提高域名知名度,方便用戶查詢域名信息、了解域名,在注冊時一般會盡可能地將信息填寫完整。而惡意域名為了掩蓋其惡意目的,在注冊域名時往往將很多信息隨意填寫,如注冊人、聯系方式等相關信息,甚至盡可能地減少填寫這些信息。大量統計發現,域名whois信息在完整的情況下總條數約為52。對2000個域名樣本進行統計,統計結果如表1和表2所示。結果表明:92.47%的合法域名其whois信息條數在30條之上,90.85%的惡意域名其 whois信息條數在 20條之下;有 9條whois信息是合法域名和惡意域名共有的,且擁有這9條信息的域名數量在合法域名和惡意域名中分別占99.52%和98.85%。
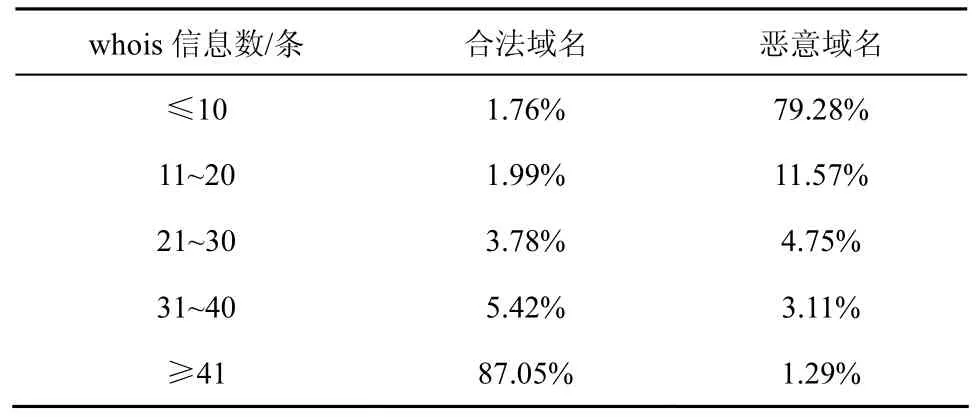
表1域名樣本whois信息完整度統計
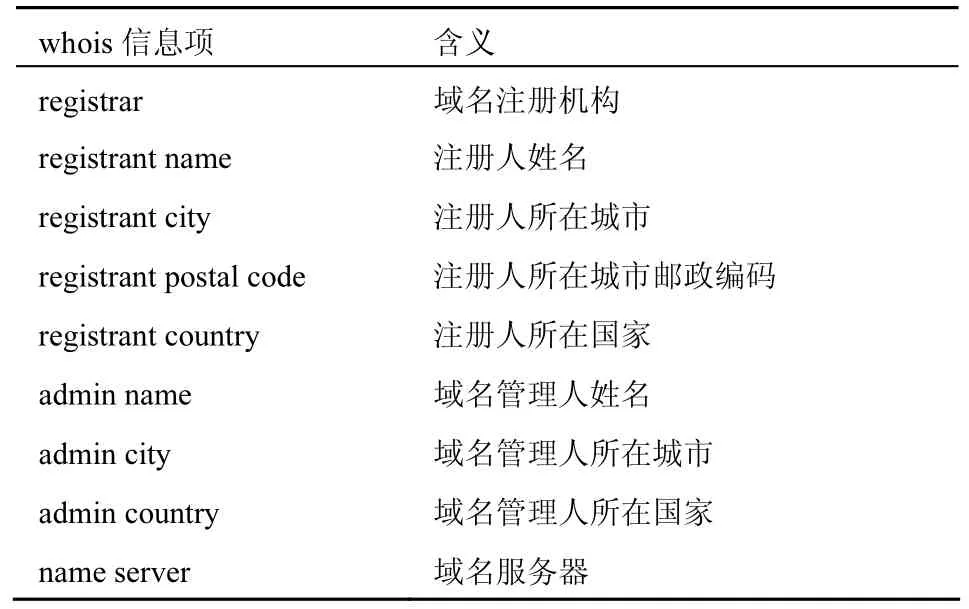
表2合法、惡意域名共有的whois信息項及其含義
顯然,合法域名與惡意域名相比,域名 whois信息完整度方面有著明顯的差異,這種差異對二者的分類應有幫助。
3) 域名IP變更。域名在注冊時會綁定IP地址,合法域名會根據解析 IP是否可以提供正常的服務來決定是否需要更換IP地址,從而保證某一IP出現問題后使用更換后的IP仍然能夠提供服務,提高了服務的可用性。一般而言,合法域名的IP地址更換,總在一個IP數量有限的IP池內更換IP[17],其更換IP地址的個數是有限的,且隨著生存時間的增長,IP變更的個數(使用過的IP個數)遠小于變更次數。而惡意域名由于遭到檢測及封堵,攻擊者需要經常更換域名對應的IP地址,且每次IP變更幾乎都將域名映射到一個新的 IP地址,因此,其IP變更的個數與變更次數都會增加。圖2和圖3給出了2000個域名樣本的IP變更個數、變更次數隨域名已生存時間變化的樣本分布情況,結果表明:隨著域名生存時間增長,合法域名與惡意域名的IP變更個數與次數都會增加,但合法域名與惡意域名相比,其IP變更個數與次數的增長要緩慢。
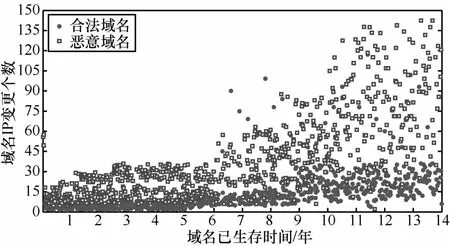
圖2IP變更個數隨域名已生存時間變化的域名分布
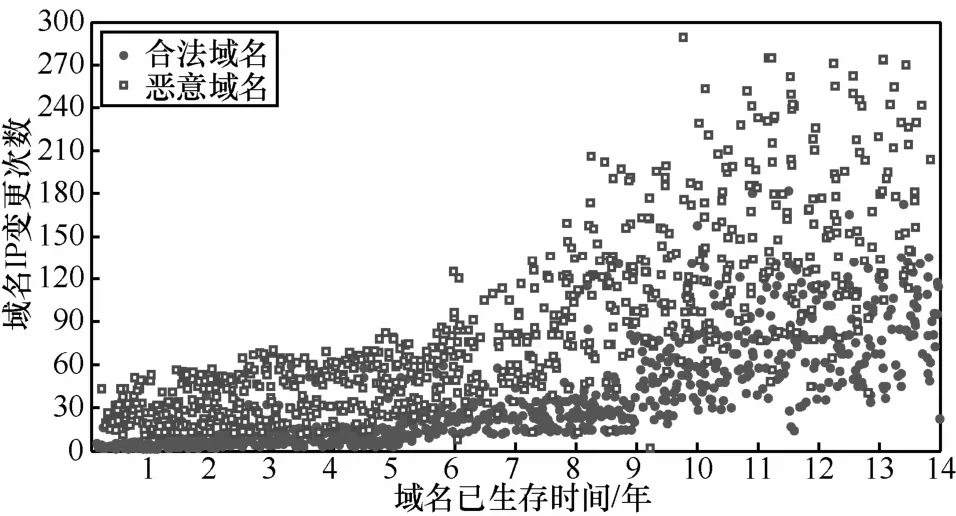
圖3IP變更次數隨域名已生存時間變化的域名分布
4) 同IP地址域名數量。同IP地址域名,即與某個確定的域名共享其解析IP地址的域名。由于同一臺服務器可能同時為多個域名提供服務,所以會出現多個域名共享同一個IP地址的現象。合法域名其目的是為互聯網用戶提供網絡服務,考慮到服務質量問題,同一臺服務器一般不會同時為大量的域名提供服務,因此,與合法域名同IP地址的域名數量往往較少。而惡意域名其真正目的是用于攻擊者發動攻擊,并不是為用戶提供服務,為了躲避檢測和封堵,攻擊者往往會將大量域名注冊到同一IP地址。統計2000個域名樣本同IP域名數量結果發現,同IP域名數量小于50個的合法域名占域名樣本總數的79.20%,大于50個的合法域名僅占 20.80%,而惡意域名同 IP域名數量大于50個的為93.37%,小于50個的僅為6.63%。圖4所示為這2000個域名樣本的同IP域名數量分布情況,對同IP域名數量大于100個的統一視為定值100。由圖4可知,絕大多數惡意域名樣本其同IP域名數量大于等于100個,幾乎所有合法域名樣本其同 IP域名數量小于100個。
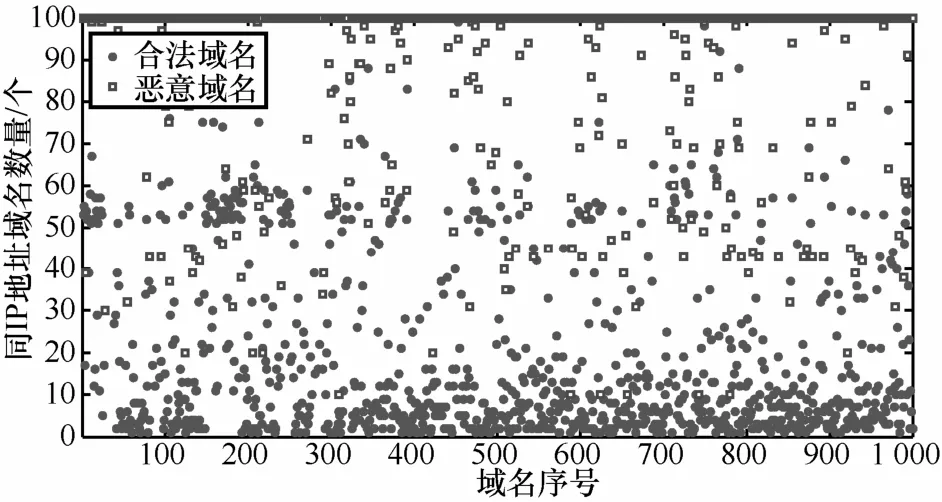
圖4同IP地址域名數量的域名分布
5) 域名 TTL值。域名 TTL是指域名服務器將域名解析記錄作為緩存保留的最長時間,以秒為單位。合法域名解析對應IP地址往往在一個固定的IP池內,為提供較為穩定的服務,TTL值往往設置較大,通常被設置為1~5天[14]。惡意域名由于遭到封堵,域名解析對應IP地址經常變化,且每次變化往往映射到一個新的 IP地址,所以其TTL值往往較小。統計2000個域名樣本得出,有23%以上的合法域名將其TTL值設為86400 s即1天,64%以上的合法域名其TTL值設置大于1000 s,而惡意域名中幾乎有40%其TTL值設置小于300 s,小于1000 s的更是占總量的75%以上。
通過上述分析可以得出,合法域名與惡意域名在whois信息更新次數、whois信息完整度、IP變更個數及次數、同IP地址域名數量、TTL值方面差異明顯,且隨著域名已生存時間的增長,二者在whois信息更新次數、IP變更個數及次數方面差異變得更加顯著,具體信息及其變化如表 3所示。

表3各類信息變化趨勢
2.2 分類特征具體表示
通過對合法域名與惡意域名的上述信息隨域名生存時間變化趨勢的分析,本文將域名 whois信息更新次數作為一維特征,其余三維特征表示如下。
2.2.1 域名IP變更個數與次數的比值
由 2.1節的統計分析表明,隨著域名生存時間的增長,域名IP變更個數與次數都有所增長,但合法域名 IP變更個數相對固定,惡意域名 IP變更個數卻逐漸增長。從這種變化趨勢來看,合法域名 IP變更個數與變更次數之比會隨域名生存時間的增長而不斷減小;而惡意域名該比值會隨域名生存時間的增長而不斷增大,且該比值將逐漸趨于1。為此,這種變化趨勢使將域名IP變更個數與次數之比作為一維特征更有利于異常域名的檢測。記域名IP變更的個數為IPCN,IP變更的次數為 IPCT,則域名 IP變更個數與次數之比可表示為:
本節仍用2000個合法域名與惡意域名作為樣本,圖5顯示了域名IP變更個數與次數之比隨域名生存時間增長的變化情況,其中,縱軸為特征值。由圖2、圖3和圖5可知,隨著域名生存時間的增長,使用域名IP變更個數與次數之比的分類效果要遠好于使用域名 IP變更個數和次數的分類效果,且確實存在隨生存時間的增長分類效果越好的趨勢。
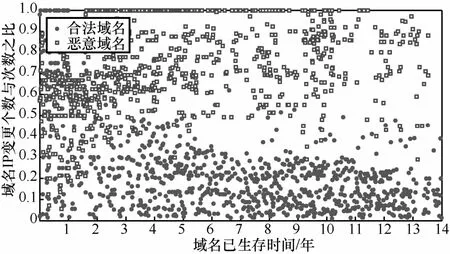
圖5IP變更個數與次數比隨域名已生存時間變化的域名分布
2.2.2 域名同IP域名數量與其whois信息完整度總和的比值
由2.1節的分析可知,合法域名為了保證網絡服務質量,往往不會與大量的域名共享同一個IP;而惡意域名會僅僅為達到某種單一的目的而出現大量域名共享IP地址的情況,如僵尸網絡中會將大量的域名關聯到同一個IP地址。此外,大部分合法域名的whois信息都較為完整,而大量的惡意域名其whois信息完整度都較低。從域名的同IP域名數量與相應的同IP域名whois信息完整度之和的比值來看,如果同IP的域名均為合法域名,該比值較小,而如果同IP的域名均為惡意域名,則該比值往往較大。因此,本文將域名同IP地址域名數量與其相應whois信息完整度總和的比值作為一維特征。下面給出該一維特征的一種具體表示方法并驗證其分類效果。
記域名M的第n(1≤n≤N )條whois信息為i(n),其值用v(i(n))表示。如果i(n)在域名M的whois信息中存在,則置v(i(n))為1;否則置v(i(n))為0。
由2.1節的分析可知,域名whois信息在完整的情況下總條數約為52條,故取N=52;由表2可知,在大量的合法域名與惡意域名 whois信息中,有 9條信息項是共有的,顯然共有項對分類的貢獻要小于非共有項,故可對域名 whois信息的每一項加以賦權。記共有的9條whois信息項構成的集合為I,域名的第n條whois信息項i(n)的權值為W(i(n)),則

其中,a<b。
設域名的whois信息完整度為WCR,則對于域名M,其whois信息完整度可表示為

設與域名M同IP的域名為M1,M2,M3,…, MK,則域名M同IP域名數量與其whois信息完整度總和的比值可表示為
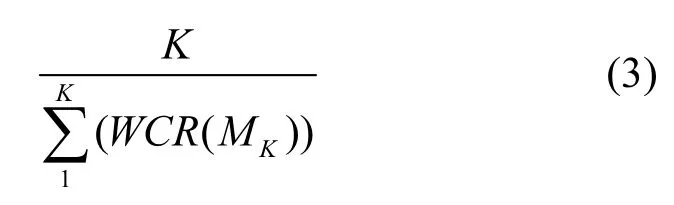
仍采用上述2000個域名為樣本,圖6顯示了同IP域名數量與其whois信息完整度總和的比值的域名分布(實驗中有大量的比值大于0.5,本文將大于0.5的比值統一視為定值0.5)。驗證過程中,置式(1)的參數a=0.1,b=0.9。由圖4和圖6可知,基于式(3)的這維特征能夠更好地區分合法域名與惡意域名。但由于約6.7%的合法域名與其同IP的域名中存在部分惡意域名,約3.9%的惡意域名與其共享IP的域名中存在大量合法域名,所以導致合法域名與惡意域名基于該特征的特征值出現部分交叉。

圖6同IP域名數量與其whois信息完整度總和的比值特征的域名分布
2.2.3 基于域名IP變更速率與TTL的二元函數值
由2.1節關于域名IP變更個數和變更次數的分析可知,合法域名IP總是在一個數量有限的IP池內變更,而惡意域名的IP變更數量是逐漸增加的,因而就統計而言,合法域名IP變更速率會隨域名生存時間的增長而減小,而惡意域名對應的IP地址經常變化,且每次變化幾乎都映射到新的IP地址,因而其 IP變更速率并不具有合法域名那樣明顯的特性。此外,從域名提供服務的角度而言,合法域名為提供穩定的公共服務,便于用戶訪問,其解析記錄在 DNS服務器中緩存的時間比較固定,即域名的TTL值設置固定(統計上該值設置一般較大);而惡意域名只是為攻擊者達到某種惡意的目的,為避免相關的檢測和封堵,其域名所對應的IP地址需要經常變更,這就使域名的解析記錄在 DNS服務器中的緩存時間較短,即TTL值設置往往較小。就合法域名與惡意域名二者的特性而言,域名IP變更的速率與TTL值的設置會呈現一定程度的負相關性。為此,本節將用基于域名IP變更速率與TTL值的二元相關函數的函數值作為特征來刻畫這種負相關性。
設域名M已生存時間為T,則M已生存時間內的IP變更速率IPCR可表示為。其中,IPCN在2.2.1節中已提到。
設域名M的TTL值為ttl,域名M的IP變更速率與TTL值的二元相關函數記為f(IPCR,ttl),根據域名IP變更速率與TTL值的關系,本文將這種二元關系表示為

隨著生成時間的增長,合法域名該函數值將會減小,而惡意域名該函數值將增大,通過基于域名IP變更速率與TTL的二元函數能夠較好地區分合法域名與惡意域名。部分大型合法網站為了提高網站可用性及服務質量,使用內容分發網絡(CDN,content delivery network)或輪轉 DNS(rrDNS,round robin DNS)技術,其域名TTL值設置可能較小,但生存時間內IP變更速率較小,與惡意域名的IP變更速率依然有較大差異,因此,基于域名IP變更速率與TTL的二元函數值仍然能夠將這類合法域名與惡意域名區分開。
仍采用上述2000個域名為樣本,圖7顯示了基于域名IP變更速率與TTL的二元函數值為特征的域名分布(部分惡意域名的特征值遠大于0.1,為便于觀察,實驗中將大于 0.1的特征值統一視為0.1)。從圖7可知,通過域名IP變更的速率與TTL值呈現出的負相關性,可以良好地刻畫合法域名與惡意域名之間的差異。

圖7基于域名IP變更速率與TTL的二元函數值隨域名已生存時間變化的域名分布
3 檢測算法
本文提出的異常域名檢測算法的主要思想是通過域名信息網站獲取域名相關的各類歷史數據信息,從中收集合法域名與惡意域名在域名 whois信息更新次數、whois信息完整度、域名解析對應的IP變更、同IP地址域名數量、域名的TTL值方面的統計差異,構建域名whois信息更新次數、域名 IP變更個數與次數之比、同 IP域名數量與其whois信息完整度總和的比值、基于域名IP變更速率與TTL的二元函數值這些四維分類特征,如表4所示。

表4特征集合
具體檢測算法如下。
1) 通過篩選后的合法域名與惡意域名構造域名樣本集合S。
2) 對?M∈S,獲取域名M的歷史數據Dhistory,對Dhistory進行分析,提取特征構造域名M的特征向量FM(F1, F2, F3, F4)。
3) 設FM∈F,F為所有域名樣本的特征向量構成的集合。將特征向量集F分為訓練集Ftrain與測試集Ftest,并使用Ftrain訓練分類器,得出已訓練好的分類器模型(Model)。
4) 使用測試集Ftest對Model進行測試,得出檢測結果。
4 實驗設計及結果
為了驗證本文所設計的惡意域名檢測算法對生存時間較長的惡意域名良好的檢測效果,以及與現有一些檢測方法的比較,本文設計2組實驗,其中,4.1節為驗證性實驗,4.2節為對比性實驗。
4.1 本文檢測算法檢測效果驗證
4.1.1 域名樣本來源與構造
該組實驗中,合法域名通過網站Domains5注1注1:Domains5. http://www.domains5.cn/。獲取。該網站提供有Alexa排名的域名,并按域名排序列出,從該網站上共獲得合法域名樣本4773個。
惡意域名主要通過Malwr注2注2:Malwr. https://malwr.com/。注3:McAfee. http://www.siteadvisor.com/sites/。注4:Robtex. https://www.robtex.com/。注5:Domaintools. http://www.domaintools.com/。網站獲取。為了進一步確定網站上提供的惡意域名的性質,通過McAfee注3注2:Malwr. https://malwr.com/。注3:McAfee. http://www.siteadvisor.com/sites/。注4:Robtex. https://www.robtex.com/。注5:Domaintools. http://www.domaintools.com/。對其進行進一步的篩選。McAfee網站提供對域名性質的判別,能夠識別出域名是否與惡意行為相關,并且較為精確。根據McAfee的驗證結果篩選后,獲得惡意域名樣本2318個。
4.1.2 特征獲取
對于獲取到的域名樣本,通過 Robtex注4注2:Malwr. https://malwr.com/。注3:McAfee. http://www.siteadvisor.com/sites/。注4:Robtex. https://www.robtex.com/。注5:Domaintools. http://www.domaintools.com/。、Domaintools注5注2:Malwr. https://malwr.com/。注3:McAfee. http://www.siteadvisor.com/sites/。注4:Robtex. https://www.robtex.com/。注5:Domaintools. http://www.domaintools.com/。網站及whois、nslookup命令獲取用于生成各維特征的域名歷史數據信息。通過對Domaintools網站數據統計獲得域名的創建時間、域名whois信息更新次數、域名IP變更個數及IP變更次數;通過Robtex網站數據統計獲取與某個域名樣本具有相同 IP地址的域名及其數量,并通過whois命令獲取同 IP域名的 whois信息;通過nslookup命令查詢并獲取每個域名樣本的TTL值。在獲取到各類數據信息后,將信息按照本文所述方式進行組合進而得到各維特征。
4.1.3 實驗及結果分析
本文檢測算法中所使用的特征與域名的已生存時間有較大的相關性,域名已生存時間越長,分類效果應越好。為了驗證本文算法的該特點,本節將域名樣本集合按已生存時間的長短進行劃分,構建相應的訓練集和測試集,分類器運用SVM分類器。
根據域名已生存時間對樣本集合進行劃分。其中,S1表示所有已生存時間為0~3年的域名樣本集;S2表示所有已生存時間為3~6年的域名樣本集;S3表示所有已生存時間為6~9年的域名樣本集;S4表示所有已生存時間為 9~12年的域名樣本集;S5表示所有已生存時間為 12年以上的域名樣本集。表示 Sr中的域名構成的集合;表示Sr中另外的域名構成的集合(r=1, 2, 3, 4)。實驗中用第x年至第y年的樣本構成訓練集(如x=0,y=3),分別用第x年后的樣本與第y年后的樣本作為測試集,依據上述樣本劃分,實驗可分為4個小組。具體實驗數據如表5所示。
由于域名樣本的特征向量中分量值出現過大或過小的現象,如whois信息更新次數相對于其他3個分量值較大,而這些奇異分量可能引起訓練時間增加,并可能引起網絡無法收斂,因此需要對訓練數據與測試數據進行歸一化處理,本節中將訓練集與測試集的特征向量分量均歸一化到[0,1]。實驗結果如表6所示。其中,分類正確率、漏報率、虛警率計算如下,分類正確率:,漏報率:,虛警率:,其中,X表示測試集中合法域名數量,Y表示測試集中惡意域名數量,TT表示被正確分類的合法域名數量,FF表示被正確分類的惡意域名數量,FT表示被錯誤分類的合法域名數量,TF表示被錯誤分類的惡意域名數量。
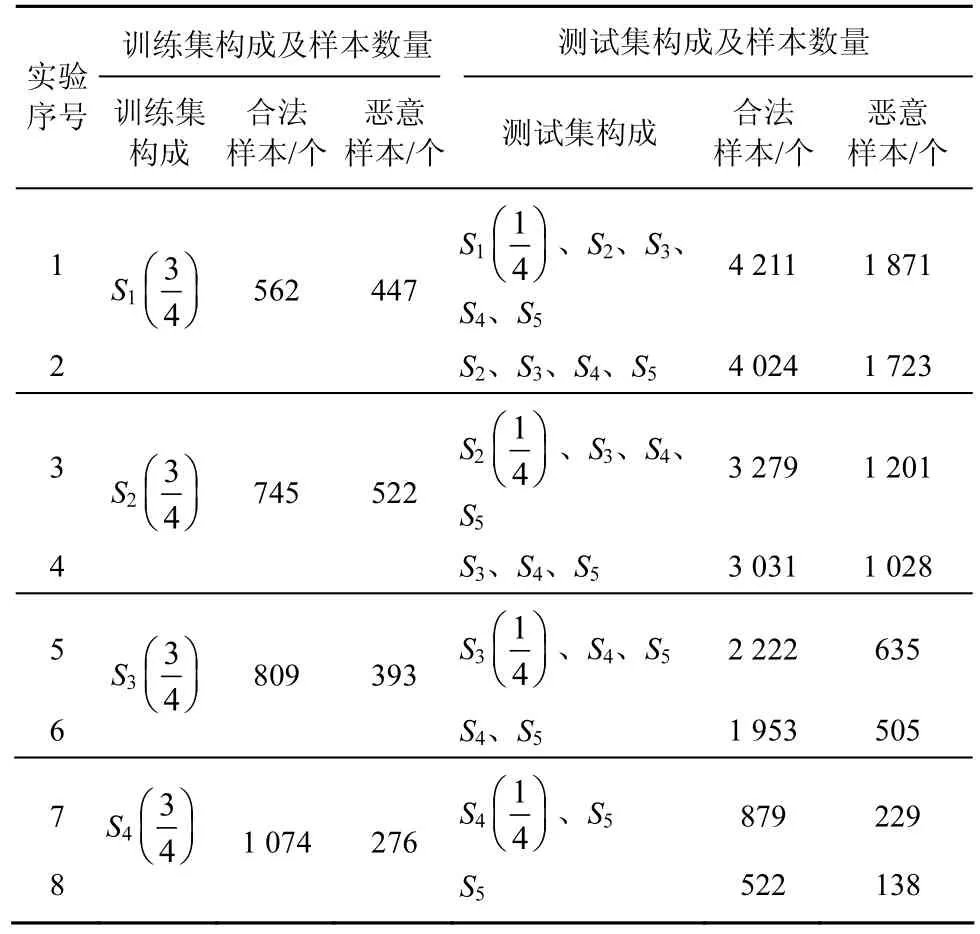
表5訓練集、測試集構造

表6分類結果
由表6可知,實驗2、實驗4、實驗6、實驗8中的分類效果要好于實驗1、實驗3、實驗5、實驗7中的分類效果;從實驗1~實驗8,分類正確率不斷提高,漏報率與虛警率不斷下降。這一結果驗證了本文算法的理論分析與算法特點。此外,分析上述8個實驗測試集的數據可發現如下4類異常域名樣本。
A類:域名whois信息更新次數與已生存時間相關性不強,不足以區分惡意域名與合法域名,導致不同程度的漏報與虛警。
B類:惡意域名IP變更個數與次數之比隨域名已生存時間增加、合法域名IP變更個數與次數之比隨域名已生存時間減少的規律不明顯。
C類:同IP的域名中存在合法域名與惡意域名共享IP的現象,導致部分域名樣本出現異常。
D類:隨著域名已生存時間的增長,合法域名應呈現的域名IP變更速率與TTL值負相關性不明顯,惡意域名并不存在這種負相關性。
表7給出了使用多類測試集對基于不同訓練集所構分類器進行測試時,分類結果中出現的各類異常域名樣本及其數量統計。
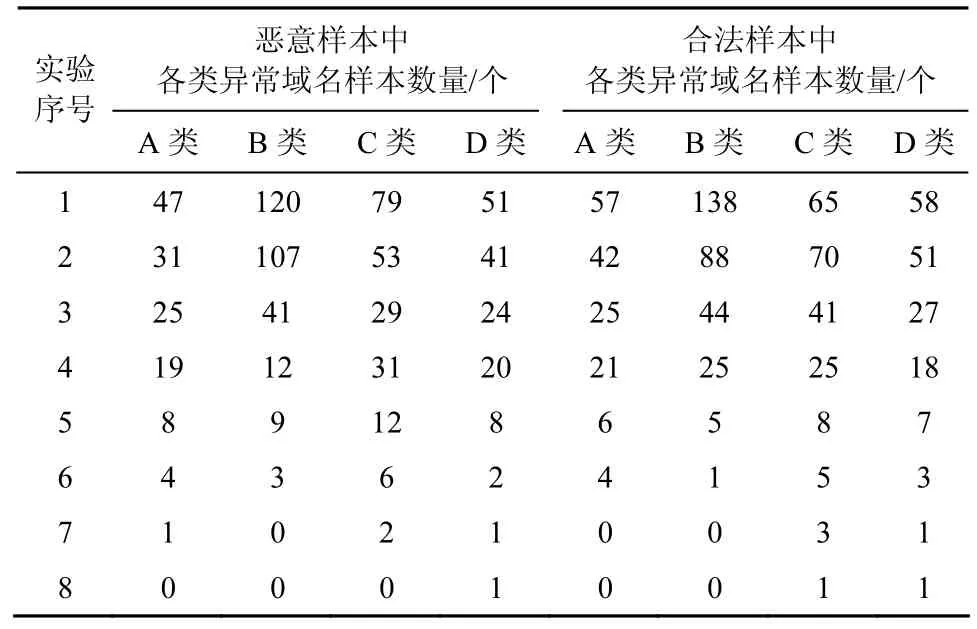
表7測試集惡意、合法樣本中各類異常域名樣本數量統計
就表7的統計結果而言,異常域名樣本盡管與特征的表示相關,但就統計趨勢而言,隨著域名已生存時間的增長,域名樣本集合中引起漏報及虛警的各類異常域名樣本數量在不斷下降,因而本檢測算法對于生存時間較長的惡意域名檢測更為可靠。
4.2 同類相關工作對比
本節主要介紹本文檢測算法與文獻[11]、文獻[14]檢測方法的對比。樣本取文獻[11]、文獻[14]中的同源樣本,合法域名樣本為Alexa排名靠前的域名,惡意域名樣本均取自malwaredomains注6注6:http://mirror2.malwaredomains.com/files/justdomains。網站。取2000個合法域名樣本,從malwaredomains網站取2000個惡意域名樣本,通過這2類共4000個域名樣本構造測試集,并將測試集按生存時間如 4.1.3節所述方式進行劃分,得到域名樣本集 S1'~S5'。使用劃分后的測試集對4.1.3節中實驗1~實驗8對應訓練好的分類器進行測試,得出分類結果。其中,由于文獻[11]、文獻[14]中的檢測方法未對域名樣本集合按生存時間劃分,而是對測試樣本集合總體進行的分類,因此,在對比分類結果時,將本文檢測算法對不同生存期的域名樣本集的分類結果分別與這2種方法對測試樣本集合總體的分類結果相比較。表8給出了實驗9~實驗16中具體的測試集合構造與相應的3種檢測方法的分類正確率。
由表8可以看出,本文檢測算法對其他來源的惡意域名的檢測效果也較好,并且依然對生存時間較長的域名擁有更高的分類正確率。由實驗9~實驗12的分類結果可以得出,域名生存時間短時,本文檢測算法的檢測效果不如文獻[11,14]中檢測方法所獲得的檢測效果;由實驗13~實驗16的分類結果可以得出,隨著域名生存時間的增長,本文檢測算法的檢測效果與文獻[11]中檢測方法的檢測效果相當;由實驗15和實驗16的分類結果可以得出,當域名生存時間更長時,本文檢測算法的檢測效果與文獻[14]中檢測方法的檢測效果相當。表6和表8的分類結果說明相比于其他檢測方法,本文檢測算法對生存時間較長的惡意域名的檢測能力較強,這也進一步驗證了本文檢測算法針對長期生存的惡意域名檢測的優勢及可靠性。

表83種檢測方法對相同來源的域名樣本分類結果對比
5 結束語
本文給出了一種對異常域名進行檢測的算法,該檢測算法通過對各類域名信息網站提供的域名網絡歷史數據的分析,生成特征,利用機器學習進而對可疑域名進行檢測。本文算法的主要貢獻是在獲取到域名歷史數據的情況下,對長期活躍在網絡中的惡意域名具有較為可靠的檢測準確率,并且隨著域名生存時間的增長,其檢測效果尤為明顯。算法對生存時間較長的可疑惡意域名的發現能力,為發現那些尚未檢測到且長期存在的可疑惡意域名提供了一種新的方法,這是本文工作的一個特色,也是與其他工作的一個重要不同。此外,本文工作可離線進行,不需要通過對頂級域名服務器或者權威域名服務器、本地域名服務器的監測獲取 DNS流量等數據,數據獲取容易、計算量小。
[1]ROSSOW C, DIETRICH C, BOS H. Detection of intrusions and malware, and vulnerability assessment[M]. Berlin: Springer, 2013.
[2]MAHMOUD M, NIR M, MATRAWY A. A survey on botnet architectures, detection and defences[J]. International Journal of Network Security, 2015, 17(3): 272-289.
[3]PU Y, CHEN X, CUI X, et al. Data stolen trojan detection based on network behaviors[J]. Procedia Computer Science, 2013, 17: 828-835.
[4]NIRMAL K, JANET B, KUMAR R. Phishing-the threat that still exists[C]//International Conference on Computing and Communications Technologies(ICCCT). IEEE, 2015: 139-143.
[5]CHEN C M, CHENG S T, CHOU J H. Detection of fast-flux domains[J].Journal of Advances in Computer Networks, 2013, 1(2): 148-152.
[6]VANIA J, MENIYA A, JETHVA H B. A review on botnet and detection technique[J]. International Journal of Computer Trends and Technology, 2013, 4(1): 23-29.
[7]KHATTAK S, RAMAY N R, KHAN K R, et al. A taxonomy of botnet behavior, detection and defense[J]. Communications Surveys amp; Tutorials, IEEE, 2014, 16(2): 898-924.
[8]GARCíA S, UHLí? V, REHAK M. Identifying and modeling botnet Camp;C behaviors[C]//The 1st International Workshop on Agents and CyberSecurity. ACM, 2014.
[9]YADAV S, REDDY A K K, REDDY A L, et al. Detecting algorithmically generated malicious domain names[C]//The 10th ACM SIGCOMM Conference on Internet Measurement. Melbourne, Australia,2010: 48-61.
[10]FELEGYHAZI M, KREIBICH C, PAXSON V. On the potential of proactive domain blacklisting[C]//The 3rd USENIX Conference on Large-Scale Exploits and Emergent Threats: Botnets, Spyware, Worms,and More. San Jose, CA, USA, 2010.
[11]劉愛江, 黃長慧, 胡光俊. 基于改進神經網絡算法的木馬控制域名檢測方法[J]. 電信科學, 2014, 30(7): 39-42.LIU A J, HUANG C H, HU G J, Detection method of trojan's control domain based on improved neural network algorithm[J]. Telecommunications Science, 2014, 30(7): 39-42.
[12]ANTONAKAKIS M, PERDISCI R, DAGON D, et al. Building a dynamic reputation system for DNS[C]//USENIX Security Symposium. Washington, DC, USA, 2010: 273-290.
[13]ANTONAKAKIS M, PERDISCI R, LEE W, et al. Detecting malware domains at the upper DNS hierarchy[C]//USENIX Security Symposium. San Francisco, CA, USA, 2011: 23-46.
[14]BILGE L, SEN S, BALZAROTTI D, et al. Exposure: a passive DNS analysis service to detect and report malicious domains[J]. ACM Transactions on Information and System Security (TISSEC), 2014,16(4): 14-41.
[15]周勇林, 由林麟, 張永錚. 基于命名及解析行為特征的異常域名檢測方法[J]. 計算機工程與應用, 2011, 47(20): 50-52.ZHOU Y L, YOU L L, ZHANG Y Z. Anomaly domain name detection method based on characteristics of name and resolution behavior[J].Computer Engineering and Applications, 2011, 47(20): 50-52.
[16]LENG Y, XU X, QI G. Combining active learning and semi-supervised learning to construct SVM classifier[J]. Knowledge-Based Systems,2013, 44: 121-131.
[17]YU B, SMITH L, THREEFOOT M. Machine learning and data mining in pattern recognition[M]. Berlin: Springer, 2014.
Anomaly domains detection algorithm based on historical data
YUAN Fu-xiang1,2, LIU Fen-lin1,2, LU Bin1,2, GONG Dao-fu1,2
(1. School of Cyberspace Security, PLA Information Engineering University, Zhengzhou 450001, China;2. State Key Laboratory of Mathematical Engineering and Advanced Computing, Zhengzhou 450001, China)
An anomaly domains detection algorithm was proposed based on domains’ historical data. Based on statistical differences in historical data of legitimate domains and malicious domains, the proposed algorithm used domains’ lifetime, changes of whois information, whois information integrity, IP changes, domains that share same IP, TTL value,etc, as main parameters and concrete representations of features for classification were given. And on this basis the proposed algorithm constructed SVM classifier for detecting anomaly domains. Features analysis and experimental results show that the algorithm obtains high detection accuracy to unknown domains, especially suitable for detecting long lived malicious domains.
anomaly domain, domain historical data, feature, detection
s:The National Natural Science Foundation of China (No.61379151, No.61272489, No.61302159, No.61401512),The Excellent Youth Foundation of Henan Province of China (No.144100510001)
TP309
A
10.11959/j.issn.1000-436x.2016208
2015-12-21;
2016-09-12
國家自然科學基金資助項目(No.61379151, No.61272489, No.61302159, No.61401512);河南省杰出青年基金資助項目(No.144100510001)

袁福祥(1991-),男,山東濟寧人,解放軍信息工程大學碩士生,主要研究方向為網絡信息處理。

劉粉林(1964-),男,江蘇溧陽人,解放軍信息工程大學教授、博士生導師,主要研究方向為網絡信息安全、信息隱藏與檢測。
蘆斌(1982-),男,山西靈石人,解放軍信息工程大學講師,主要研究方向為數字水印、軟件工程。
鞏道福(1984-),男,山東淄博人,解放軍信息工程大學講師,主要研究方向為數字水印、網絡信息安全。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
