光互連網絡中資源預留的多級光互連仲裁機制*
2016-11-25 06:25:54賴明澈肖立權
國防科技大學學報 2016年5期
翦 杰,賴明澈,肖立權
(國防科技大學 計算機學院, 湖南 長沙 410073)
?
光互連網絡中資源預留的多級光互連仲裁機制*
翦 杰,賴明澈,肖立權
(國防科技大學 計算機學院, 湖南 長沙 410073)
基于資源預留策略提出一種多級光互連仲裁機制,通過將網絡分級實現快速、高效的仲裁。多優先級數據緩存隊列的傳輸節點設計,提供了不同類型流量的差異化傳輸;通過預約式兩級仲裁機制,實現網絡的完全公平與100%的高吞吐率。設計并對快速仲裁通道進行了合理布局,極大地縮短了仲裁延遲。仿真結果表明:采用基于資源預留的分級仲裁策略,在多種流量模式下所有節點均獲得公平的服務。與FeatherWeight相比,分級仲裁策略吞吐率提高17%;與2-pass相比,仲裁延遲減少15%,同時,功耗減少5%。
多級光互連;快速仲裁通道;資源預留
近幾年來的硅基光子集成技術日臻成熟,低延遲、高吞吐率、低功耗的片上硅光網絡成為研究熱點。面向片上光互連結構的大量研究[1-3]表明,片上光互連網絡作為未來“眾核”處理器內部互連實體的趨勢已初現端倪。在以Crossbar交換結構為主的當今主流光互連網絡中,仲裁策略關系到網絡的各種性能,包括通道利用率、功耗、公平性等,因此一直是需要重點解決的問題,現有的仲裁策略[4-5]采用的單一仲裁器進行分布式仲裁,隨著網絡規模和性能的不斷發展,已經不能獲得較好的仲裁效果,在解決網絡公平性、通道利用、可擴展性等方面存在固有缺陷。
受復雜網絡學科中分級網絡的啟發[6],本文給出的光互連網絡中的服務質量(Quality of Service, QoS)支持策略,引入分級仲裁的概念,將網絡進行兩級管理,將仲裁過程分散到兩級仲裁器分別實現,減少了仲裁延遲,同時利用很小的硬件開銷和邏輯復雜度,解決了因節點位置導致的不公平性問題,解決了遠端饑餓矛盾;在仲裁過程中,充分考慮不同應用請求的特點,為不同類型和優先級的請求維護不同的請求隊列,保證了差別化服務的QoS要求,通過節點與一級仲裁、一級仲裁與總仲裁之間的信息交互,保證了網絡資源能夠完全被節點利用,達到100%的吞吐率。
1 支持QoS的分級仲裁結構
1.1 QoS設計規則
隨著片上光網絡的發展,網絡上運行的應用種類和數量越來越多,在不同優先級的網絡報文同時競爭網絡帶寬時,為片上光網絡提供QoS[7]的服務保證,成為新階段光網絡仲裁算法必須解決的一個問題。
但是,針對光互連網絡的現有仲裁策略沒有充分確保網絡有較好的網絡性能(最小帶寬保證、最大延遲保證、公平性等),針對片上光網絡的具體要求,該仲裁結構在保證對QoS支持的同時,令網絡達到最佳性能。QoS的設計規則為:① 公平性。當高優先級隊列還有數據等待傳輸時,低優先級隊列數據被阻塞。②最小帶寬和最大延遲保證。任何節點不能長時間無服務,以保證最小帶寬;任何隊列的數據從請求仲裁到獲得仲裁結果的延遲不能太大,即仲裁延遲不能太大。③位置獨立性。不同節點不因其在網絡布局中的位置不同而影響其獲得服務的概率,以保證整個網絡節點之間的公平性。
假設傳輸節點有3種不同優先級的數據,它們分別存儲在3個不同優先級的隊列P1,P2,P3中(優先級P1>P2>P3)。為保證公平性,高優先級隊列的請求獲得滿足之后,低優先級隊列的請求才會被滿足,這一點在仲裁器中實現;為保證節點的最小帶寬(用Bm表示),仲裁控制器會監測整個節點獲得的服務情況,當服務很少,使得節點帶寬達到Bm時,仲裁控制器向操作系統發送中斷請求,減少節點的數據產生;為保證數據的最大傳輸延遲(用D表示),節點維護一個特殊請求隊列P0,其優先級大于所有普通隊列,仲裁控制器會記錄每個隊列頭報文的等待延遲,如果達到D,則將普通隊列的頭報文遷移到特殊隊列P0中以保證在下一個仲裁周期,數據能立即發送出去。
1.2 多優先級QoS兩級仲裁器結構
基于上述QoS的設計規則,為滿足QoS的公平性、最大延遲保證、最小帶寬保證的支持,設計了兩級仲裁機制。通過一級仲裁器將整個網絡分成多個子網,每個子網通過一個一級仲裁器進行仲裁,所有的子網信息集中到總仲裁器;通過總仲裁器控制一級仲裁器,仲裁機制的總結構如圖1所示。
在節點內部,節點控制邏輯維護4個不同等級的等待隊列(P1,P2,P3,P0),不同類型的數據分別進入不同的等待隊列,其中特殊請求進入隊列P0。每個隊列的實際請求情況用向量q表示,同時,總仲裁的仲裁結果會分發到每個節點,節點收到的仲裁結果用向量g表示。為提供QoS支持,節點控制邏輯除了分別維護每個隊列的請求信息,還要維護提供最小帶寬和最大延遲保證的特殊請求信息。最大延遲保證的特殊請求信息由低等級隊列在長時間未獲得服務時發出,節點收到此信息后,會將發送此特殊信息的隊列頭報文遷移到特殊隊列P0;最小帶寬保證的特殊請求信息由節點所有隊列長時間未獲得服務時發出,此時,節點控制器向軟件發送中斷請求,請求軟件減少流量請求。

圖1 分級仲裁結構Fig.1 Architecture of hierarchical arbitration
節點在向仲裁器請求資源時,綜合考慮每個隊列的實時請求情況和收到的仲裁結果,無論是隊列的實際請求q、收到的仲裁結果g,還是最終節點向一級仲裁器提供的請求信息r,均為一個四維向量。一級仲裁器管理由8個節點組成的子網,它收集8個節點發送過來的請求信息r,進行處理后,將請求信息發送到總仲裁器,并接收總仲裁器的仲裁結果,利用此結果對子網絡進行仲裁,再將仲裁結果分發到每個節點。總仲裁器是通道資源的實際仲裁者,與8個一級仲裁器進行數據交互,根據8個一級仲裁器發送過來的請求信息,總仲裁器進行資源分配,并將分配結果分發給每個一級仲裁器。總仲裁器從8個一級仲裁器收到的是8個四維請求信息,總仲裁器進行仲裁時,特殊請求的優先級最高,接下來分別是P1,P2,P3,資源分配的原則是先完全滿足高優先級的請求,同一優先級的不同請求,按照Max_Min的原則進行分配。其仲裁的一般過程為:首先,利用Max_Min原則將資源分配給最高優先級的請求,如果資源還有多余,則以同樣的原則分配給下一優先級的請求,直到所有資源被分配完。
2 資源預留的快速仲裁策略
2.1 仲裁策略設計
上述兩級仲裁結構解決了QoS支持問題,但基于上述思路實現的仲裁策略,存在吞吐率不高、仲裁延遲過長的問題。現提出一種基于資源預留的仲裁策略,根據網絡的實時請求信息,針對性地仲裁預留資源,使得吞吐率能達到100%;同時,簡化仲裁信息量,提高仲裁信息的交換速度,減少仲裁延遲。高效的光網絡仲裁策略一般采用預留[8]的方式進行通道資源的分配。仲裁策略首先利用仲裁通道向節點發送預約令牌,請求通道的節點獲得令牌,即獲得對令牌所代表資源的預約。節點從請求獲得令牌到實際獲得資源之間的時間間隔,稱之為預留周期,它與網絡的節點數目正相關。
隨著網絡規模的擴大,一級仲裁需要直接管理的節點數迅速增加,預留周期,即網絡的仲裁延遲也迅速擴大。因此,提出針對光網絡基于預留的兩級仲裁策略,為減小單個仲裁器的復雜度以及整個網絡的仲裁延遲,兩級仲裁策略將網絡的仲裁分散到多個不同的仲裁器上,從而極大縮短了仲裁延遲。仲裁策略所調度的通道使用權的最小單位,稱之為傳輸槽(transmit slot),分級仲裁策略實際上就是對仲裁時刻后續多個傳輸槽的調度,稱之為傳輸堆(transmit bund),其大小與預留周期一致。如圖2所示,當前傳輸堆資源的仲裁結果,會用于下一個仲裁周期的資源調度。每個傳輸堆的仲裁過程分為7個階段:①所有節點將自身的隊列請求信息發往一級仲裁器;②一級仲裁器將收到的請求信息進行綜合,得到子網請求信息;③一級仲裁器將子網請求信息發往總仲裁器;④總仲裁器進行仲裁;⑤總仲裁的仲裁結果分發到一級仲裁器;⑥一級仲裁器進行仲裁;⑦一級仲裁器的仲裁結果分發到每個節點,節點利用此結果調度下一個傳輸堆的數據傳輸。

圖2 基于資源預留的兩級仲裁Fig.2 Two level based on resource reservation
以實際網絡狀況為例,說明分級仲裁機制的工作原理。為簡化描述,設定網絡只含2個一級仲裁器,每個一級仲裁器管理的子網包含3個節點,每個傳輸堆由8個傳輸槽組成。時空圖如圖3所示。矩形內的數字分別代表4個隊列的請求量或令牌量。在每個傳輸堆的第1傳輸槽,節點根據每個隊列的等待信息q,結合從一級仲裁器得到的上一傳輸堆的仲裁結果g,計算出本傳輸堆向一級仲裁器發送的請求信息r(r=q-g);子網內所有節點將各自的r值發送給一級仲裁耗時1個傳輸槽,因此,在第2傳輸槽,一級仲裁器進入up狀態,它對收集到的所有請求信息進行處理,得到子網請求信息(1,1,3,3) 和 (2,3,3,4);在第3傳輸槽,子網請求信息由一級仲裁器傳向總仲裁器,總仲裁器獲得所有的請求信息;在第4傳輸槽,總仲裁器將傳輸堆內的資源,以傳輸槽為單位,按照優先級順序,依次進行Max_Min仲裁;在第5傳輸槽,總仲裁器將仲裁結果(1,1,1,0) 和 (2,3,0,0)分別傳輸至2個一級仲裁器;在第6傳輸槽,一級仲裁器利用總仲裁器的仲裁結果,用與總仲裁器一樣的原則將獲得的時間槽資源仲裁給每個節點;在第7傳輸槽,節點獲得了仲裁結果,并按照仲裁結果,獲得對下一個傳輸堆內傳輸槽的預約;在第8傳輸槽,節點統計每個請求隊列的長度,為下一個傳輸堆資源的預約仲裁做準備。后續仲裁將重復上述過程,而第9~16傳輸槽的數據傳輸利用第6傳輸槽得到的仲裁結果。

圖3 仲裁時空圖Fig.3 Time diagram of arbitration scheme
觀察上述過程發現,在兩級仲裁過程中,在每個傳輸堆的最開始時刻,節點處的隊列等待信息向仲裁器發送之前,來自總仲裁器的當前傳輸堆的仲裁結果在上一傳輸堆末(第6傳輸槽)就已經分發到了每個節點處。因此,節點向仲裁器發送的請求是將實際請求信息減去仲裁結果后得到(r=q-g),這就保證了在下一傳輸堆開始后,實際所有隊列的長度不會小于請求資源數量,因此,也保證了仲裁器仲裁給每個隊列的資源最終肯定能夠被完全利用,即保證了網絡的吞吐率能夠達到100%。
2.2 快速仲裁通道布局
兩級仲裁的主要優勢在于能快速收集節點的請求信息,經過仲裁之后又能快速將仲裁結果分發到每個節點。基于通用的Corona[3]光互連結構,設計了一種能夠實現上述目標的快速仲裁通道(Fast Arbitration Channel,FAC),其物理布局如圖4所示。

圖4 快速仲裁通道布局Fig.4 Layout of FAC
快速仲裁通道充分考慮Corona結構的特點,利用兩類光導快速收集和分發仲裁數據:S型光導與數據光導平行,而垂直光導則用于連接所有仲裁器。兩類光導都包含上行和下行2組,每個節點的請求信息由40 bit組成,其中包含4個優先級隊列的目的地址(8 bit)和請求量(2 bit)。FAC包含8條40波段的波分多路復用S型光導(4條上行和4條下行),每個S型光導花費4傳輸周期發送請求信息至一級仲裁器,當一級仲裁器收到所有的請求信息并進行計算之后,它將子網請求信息通過垂直光導發送至總仲裁器,快速仲裁通道利用包含的8條64波段的垂直光導在2傳輸周期內完成子網請求信息的收集和總仲裁器仲裁結果的分發。整個仲裁過程需要16個傳輸周期。
3 仿真結果
采用哥倫比亞大學的PhoenixSim模擬器模擬多寫單讀(Multi-Write-Single-Read, MWSR)光Crossbar分級仲裁網絡,實現四種仲裁機制:Baseline(Corona)[3],FeatherWeight[9],2-pass token stream[4]以及Hierarchical arbitration。兩種流量模型分別是均勻流量和自相似流量,用以模擬真實網絡流量。目的節點分為自然隨機和熱點兩種。系統頻率為5 GHz,網絡規模為64節點,數據包大小統一為64 Bytes,隊列深度大小為8,采用隨機分配多隊列(Dynamic Allocate Multi Queue, DAMQ)技術,光鏈路傳輸率為10 Gbps/link。光器件的物理參數來自文獻[10]。
圖5展示了在不同流量模型下,仲裁策略在公平性方面的仿真結果。圖5(a)和圖5(b)分別展示了節點0在通道負載飽和情形下,每個節點獲得的帶寬。對于源節點的注入率設置,兩圖有差異:圖5(a)在均勻流量模型下,一半節點(節點16~48)具有低注入率0.01,其余一半具有高注入率0.1。圖5(b)在自相似流量模型下,所有節點均具有高注入率0.1。仿真結果表明,在兩種情形下,Baseline只有開始的幾個節點獲得了服務,其余節點均餓死,2-pass策略第一輪里給每個節點分配資源,在第二輪則收集第一輪未被使用的資源,按位置順序分配給有需求的節點,沒有完全解決公平問題,開始的節點獲得了較多服務。FeatherWeight通過歷史信息和當前請求來節制高請求節點的流量。因此,其高請求節點獲得流量大致相等,而低請求節點基本可以被滿足。但是,當網絡流量為自相似的突發流量時,此算法對流量變化反應不及時,導致不公平性依然存在。Hierarchical arbitration 利用集中式預留策略,在所有情形下,都獲得了完全公平。

(a) 均勻流量(a) Uniform random

(b) 自相似(b) Self-similar圖5 不同流量模式下的帶寬Fig.5 Achieved bandwidth under
通過模擬4種仲裁策略在不同的流量模型和源節點與目的節點選擇方式情形下網絡獲得的吞吐率和平均報文延遲來衡量仲裁策略的性能。在圖6中,(a)、(b)兩圖給出了在均勻流量下的吞吐率,圖6(a)顯示,在熱點模式下,所有節點發送報文至目的節點0,所有的仲裁策略獲得1/N的吞吐率;圖6(b)顯示,在自然隨機選擇策略下,所有的仲裁策略獲得100%的吞吐率。分級仲裁策略在延遲上較2-pass有15%的提高。圖6(c)、圖6(d)顯示在自相似流量模型下,2-pass和Baseline在兩種源目的節點選擇機制下都能獲得100%的吞吐率,說明基于時間片的仲裁機制能獲得理想化的吞吐率。分級仲裁根據實時請求進行集中仲裁,因此也能獲得100%的吞吐率。而FeatherWeight損失了約20%的吞吐率,這是因為FeatherWeight不能及時根據流量變化調整資源分配,存在帶寬浪費。圖6(e)、圖6(f)展示了分級仲裁網絡和數據網絡的功耗。從圖6(e)中可以發現,相比于數據網絡,仲裁網絡的功耗幾乎可忽略不計,這是由于與數據網絡相比,仲裁網絡的光導數目少,光導長度短。同時,如圖6(f)所示,與其他幾種仲裁策略相比,分級仲裁的功耗很小,比2-pass仲裁功耗減少了80%。

(a) 熱點(均勻流量)(a) Hotspot (uniform random)
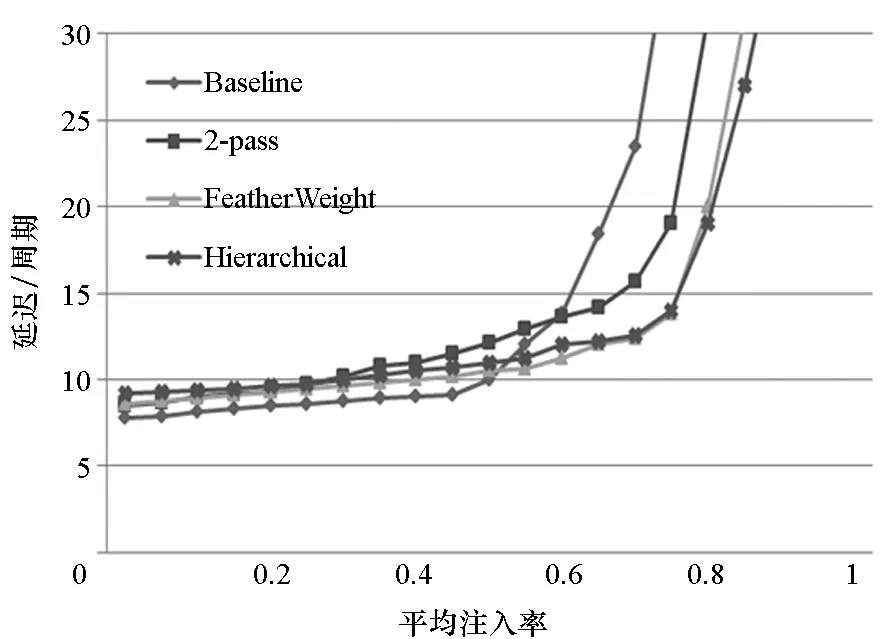
(b) 自然隨機(均勻流量)(b) Uniform(uniform random)

(c) 熱點(自相似)(c) Hotspot(self-similar)

(d) 自然隨機(自相似)(d) Uniform(self-similar)
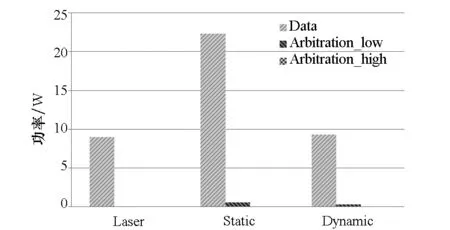
(e) Hierarchical與數據網絡對比(e) Hierarchical vs. data network

(f) Hierarchical與其他仲裁對比(f) Hierarchical vs. other arbitrations圖6 不同注入流量模型下的吞吐率和功耗Fig.6 Throughput and power consumption under different traffic patterns
4 結論
本文提出了一種分級快速光互連仲裁機制。通過具有多優先級數據緩存隊列的傳輸節點設計,實現了數據傳輸差異化服務;利用請求驅動的預約式兩級仲裁機制,實現網絡的完全公平,和100%吞吐率;對設計的快速仲裁通道進行了合理布局,使得仲裁延遲縮短了15%,整個仲裁機制的功耗只占總功耗的5%。
References)
[1] Calhoun D, Wen K, Zhu X, et al.Dynamic reconfiguration of silicon photonic circuit switched interconnection networks[C]//Proceedings of IEEE High Performance Extreme Computing Conference, 2014.
[2] Morris R W, Kodi A K, Louri A, et al. Three-dimensional stacked nanophotonic network-on-chip architecture with minimal reconfiguration [J]. IEEE Transactions on Computers, 2014, 63(1): 243-255.
[3] Vantrease D, Schreiber R, Monchiero M, et al.Corona: system implications of emerging nanophotonic technology[C]//Proceedings of the 35th Annual International Symposium on Computer Architecture, 2008: 153-164.
[4] Yan P, Kim J, Memik G.FlexiShare: channel sharing for an energy-efficient nanophotonic crossbar [C]//Proceedings of IEEE International Symposium on High Performance Computer Architecture, 2010: 1-12.
[5] Vantrease D, Binkert N, Schreiber R, et al.Light speed arbitration and flow control for nanophotonic interconnects[C]// Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, 2009: 304-315.
[6] Clauset A, Moore C, Newman M E J. Hierarchical structure and the prediction of missing links in networks[J]. Nature, 2008, 453(7191): 98-101.
[7] Lee J W, Ng M C, Asanovi K. Globally synchronized frames for guaranteed quality-of-service in on-chip networks[J]. Journal of Parallel & Distributed Computing, 2012, 72(11): 1401-1411.
[8] Peh L S, Dally W J. Flit-reservation flow control[C]//Proceedings of International Symposium on High-Performance Computer Architecture, 2000: 73-84.
[9] Pan Y, Kim J, Memik G. FeatherWeight: low-cost optical arbitration with QoS support[C]// Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, 2011: 105-116.
[10] Vantrease D M. Optical tokens in many-core processors[D].USA: University of Wisconsin-Madison, 2010.
Multi-level arbitration in optical network-on-chip based on resource reservation
JIAN Jie, LAI Mingche, XIAO Liquan
(College of Computer, National University of Defense Technology, Changsha 410073, China)
A multi-level arbitration based on resource reservation in optical network-on-chip was proposed. The fast and high efficiency arbitration scheme divided the network into multi-stages. With the design of multi priority queues in every node, arbiters provided differential transmissions for different kinds of flows. The arbiter also presented the transmit bund resource reservation scheme to fairly reserve time slots for all nodes, thus achieving the throughput of 100%. The fast arbitration channels were proposed and designed to degrade the arbitration period, and the packet transmitting delay was reduced. The simulation results show that, with the multi-level arbitration based on resource reservation, all nodes are allocated with almost equal service under various patterns. This scheme improves throughput by 17% when compared with FeatherWeight under the self-similar traffic pattern, and eliminats arbitration delay by 15% to 2-pass arbitration, incurring total power overhead by 5%.
multi-level optical network-on-chip; fast arbitration channel; resource reservation
10.11887/j.cn.201605007
http://journal.nudt.edu.cn
2015-11-25
國家863計劃資助項目(2015AA015302);國家重點基礎研究發展計劃資助項目(2012CB933504);國家自然科學基金資助項目(61572509)
翦杰(1987—),男,湖南常德人,博士研究生,E-mail:jianj06@mails.tsinghua.edu.cn;肖立權(通信作者),男,研究員,博士,博士生導師,E-mail:xiaoliquan@nudt.edu.cn
TN95
A
1001-2486(2016)05-039-06
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
數學大世界(2018年1期)2018-04-12 05:39:14
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
中外會展(2014年4期)2014-11-27 07:46:46
時代英語·高三(2014年5期)2014-08-26 02:49:51
