面向磁盤駐留的類Pregel系統的多級容錯處理機制
2016-11-25 03:24:19畢亞輝姜蘇洋王志剛冷芳玲鮑玉斌于戈錢
計算機研究與發展 2016年11期
畢亞輝姜蘇洋王志剛冷芳玲鮑玉斌于 戈錢 嶺
1(東北大學計算機科學與工程學院 沈陽 110819)2(中國移動(蘇州)軟件技術有限公司 江蘇蘇州 215163)(biyahui1990@163.com)
?
面向磁盤駐留的類Pregel系統的多級容錯處理機制
畢亞輝1姜蘇洋1王志剛1冷芳玲1鮑玉斌1于 戈1錢 嶺2
1(東北大學計算機科學與工程學院 沈陽 110819)2(中國移動(蘇州)軟件技術有限公司 江蘇蘇州 215163)(biyahui1990@163.com)
基于BSP模型的分布式框架已經成為大規模圖高頻迭代處理的有效工具.分布式系統可以通過增加集群節點數量的方式提供彈性的處理能力,但同時也增加了故障發生的概率,因此亟需開發高效的容錯處理機制.現有工作主要是基于檢查點機制展開研究,包括數據備份和故障恢復2部分:前者沒有考慮迭代過程中參與計算的數據規模的動態變化,而是備份所有圖數據,因此引入了冗余數據的寫開銷;后者通常是從遠程存儲節點上讀取備份數據進行故障恢復,而沒有考慮利用本地磁盤數據恢復某些場景下的故障,引入額外的網絡開銷.因此提出了一種多級容錯處理機制,將故障分為計算任務故障和計算節點故障2類,并設計了不同的備份和恢復策略. 備份階段利用了某些應用在迭代計算過程中參與計算的數據規模的動態變化特性,設計了完全備份和寫變化log自適應選擇的策略,可以顯著減少冗余數據的寫開銷.故障恢復階段,對任務故障,利用本地磁盤上保留的圖數據和遠程的消息數據完成恢復;而對節點故障,則利用備份在遠程信息進行恢復.最后,通過在真實數據集上的大量實驗,驗證了提出的多級容錯機制的有效性.
容錯;大規模圖;迭代計算;BSP模型;檢查點
隨著圖數據規模的快速增長和分析復雜性的不斷增加,大量支持大規模圖迭代計算的分布式處理系統被開發[1-3],其中,Giraph[1]和BC-BSP[2]在迭代計算過程中提供了基于磁盤輔助的數據和中間消息存儲.分布式系統可以通過增加計算節點數量的方式提高處理的能力和效率.然而,系統在迭代過程中發生故障的概率與節點規模成正比[4].對于長時間迭代計算的圖處理應用,需要設計高效的容錯處理機制.
目前分布式圖處理系統采取的處理故障方法一般是基于檢查點的方法[2-3].檢查點機制包括數據備份與數據恢復2部分.各個任務周期性地將圖數據和有關信息備份到分布式文件系統(如HDFS)中.當系統發生故障時,各任務從分布式文件系統中讀取檢查點備份的數據和有關信息來完成故障恢復.基于檢查點的方法原理簡單明了,容易實現.然而,現有的基于檢查點的方法存在2方面的不足:
1) 在數據備份時,并沒有區分迭代過程中數據是否發生動態變化,而是將所有的圖數據信息進行備份,因此導致寫檢查點時產生了大量冗余數據的寫操作;
2) 在故障恢復階段,通常是從遠程存儲節點上讀取備份的信息進行故障恢復,而沒有考慮利用本地磁盤數據恢復某些場景下的故障,尤其是在面向磁盤駐留的計算系統中,例如任務故障的情形,使得在某些類型的故障恢復過程中需要遠程讀取檢查點數據,存在“遠程讀”問題,引入了網絡開銷.
針對上述2個問題,本文提出了一種面向磁盤駐留的類Pregel系統的多級容錯處理機制.所謂的多級是針對任務故障和節點故障的數據備份與恢復策略而言的.首先,對于數據備份策略,根據數據備份的位置和規模,可以分為3個級別:第1級別,被處理的圖數據有本地備份和消息數據在HDFS上備份;第2級別,靜態數據(頂點的出度鄰接表,并假設在迭代計算過程中不改變)、動態數據(迭代過程中動態變化,如PageRank的PR值)和消息都備份在HDFS上;第3級別,HDFS上備份有圖的動態數據加日志(log)信息、靜態數據和消息.對應于數據備份的3個級別,故障的恢復也有3個級別:第1級別,讀取本地的數據和HDFS上的消息;第2級別,讀取HDFS上的靜態數據、動態數據和消息;第3級別,讀取HDFS上的靜態數據、啟用log機制(記錄變化的動態數據)后的動態數據和消息.對于任務故障的備份與恢復采用的是第1級別的容錯處理機制,對于節點故障備份與恢復采用的是第2級別和第3級別的容錯處理機制.本文所提出的多級容錯處理機制能夠有效地處理分布式圖處理系統出現的任務故障以及節點故障,該機制適用于采用磁盤輔助的類Pregel系統.
本文的主要貢獻如下:
1) 任務故障的恢復直接讀取本地磁盤的靜態數據與動態數據和HDFS上的消息,避免了加載HDFS上的靜態和動態數據的開銷,加快了任務故障的處理過程.
2) 提出了log機制,當參與計算的圖數據規模小于指定閾值時,使用log方式記錄數據變化而不是全部備份動態數據,以減少備份數據的寫開銷.此外,本文還給出了log啟動閾值設置的理論分析.
3) 在大量的實驗基礎上,對比了傳統的檢查點(checkpoint)機制和本文的多級容錯處理機制,驗證了本文的多級容錯處理機制的有效性.
1 相關工作
設計高效的容錯方案始終是分布式圖處理系統重點解決的問題.因此,已有許多關于分布式(圖)處理系統的容錯機制的研究工作.已有的方法可以分為基于檢查點的方法、基于日志的方法和混合方法3類.
目前大多數知名的分布式圖處理系統如Giraph[1], GraphLab[5], PowerGraph[6], GPS[7], Mizan[8]系統采用的都是基于傳統檢查點的方法;GraphX[9]采用基于日志的方法.Pregel[3]系統中提供了2種容錯機制:1)基本的寫檢查點機制;2)受限的恢復機制,即采用的是一種基于檢查點和日志相結合的混合方法.
Pregel的基于基本寫檢查點機制實現的容錯機制是周期性地備份頂點的狀態和消息以實現容錯.當一個或多個節點發生故障,主節點重新分配這些圖的分區到當前可用的工作節點集合上,這些節點會從最近記錄檢查點的超步S開始重新加載分區狀態.
Pregel提出的另一種受限的容錯恢復機制是一種基于檢查點和基于日志相結合的方法.除了基本的檢查點,工作節點同時將圖數據加載和迭代計算期間從這個節點上分區發出去的消息記錄到日志中,這樣故障恢復就會被限制在丟失的分區上.這種方法的優點是:只重新計算丟失的分區,節省了恢復時的計算資源,同時由于每個工作節點需要恢復的分區很少,減少了恢復的延遲;缺點是對發送出去的消息進行保存會產生一定的存儲開銷,降低了作業正常運行時的效率.本文的恢復機制雖然還是要重新計算所有分區,但通過日志記錄發生變化的動態數據可以減少檢查點的存儲開銷及網絡IO開銷.Pregel的受限恢復機制可以與本文的工作互補.
Spark系統[10]將圖數據信息分為動態數據和靜態數據.寫檢查點只記錄動態變化的部分.對于絕大部分真實圖,靜態數據的規模遠大于動態數據,因此這種方式極大減少了寫檢查點的開銷.本文的多級容錯機制借鑒了Spark的這種處理方式,即第2級別.進一步地,對于某些算法,如單源最短路徑(SSSP),迭代過程中僅有部分頂點參與計算,即參與更新計算的動態數據的規模是變化的.針對這種情形,本文提出了第3級容錯方案——寫日志機制(即log機制)來進一步減少IO開銷.此外,Spark對于任務故障和節點故障的恢復都是加載存儲在分布式文件系統的檢查點數據,沒有利用本地磁盤數據.
GraphX[4]采用的是基于日志(血統)的恢復方法,它利用彈性分布式數據集(RDD)加速故障恢復.然而,當一個節點發生故障時,這個節點上的圖數據仍然需要恢復.
文獻[11]則針對傳統檢查點性能低下的問題提出了基于內存緩存的異步檢查點容錯方法.其主要思想是將檢查點臨時緩存在節點的內存中,然后由另一個輔助任務將緩存在內存中的檢查點數據寫到分布式文件系統.但是這種異步的檢查點容錯方法并不適用于類Pregel系統,因為類Pregel系統需要在寫檢查點時進行全局同步才能進入下一個超步.
2 多級容錯處理機制概述
本節首先介紹BC-BSP系統及其現有的檢查點機制,然后介紹本文的備份與恢復框架.
2.1 BC-BSP系統簡介
BC-BSP系統[2]是基于BSP模型的開源大圖迭代處理系統,支持多種數據輸入方式和使用磁盤輔助暫存數據(簡稱磁盤操作),具有良好的容錯控制能力和可伸縮性.圖1給出了BC-BSP的系統結構圖.它包括客戶端(Client)、BSP Controller端、Worker端、Staff端和完成同步協調的ZooKeeper.
客戶端是用戶與BC-BSP系統交互的實體,作業的提交和運行狀態的監控均需要通過客戶端平臺實現.Controller端是BC-BSP系統的中樞控制系統,負責調控整個集群,包括作業調度、故障恢復等.Worker端是工作節點的控制中心,隸屬于Controller端,負責本節點的整體運行調控.Staff端是工作實體,完成具體的工作任務,從邏輯上講,按照用戶提交的作業進行組織,但是在集群中受Worker端的直接管理.全局同步、消息通信和容錯控制,是作業運行過程中的重要環節,需要Controller端、Worker端和Staff端的協同工作來實現.其中的ZooKeeper作為第三方插件,在BC-BSP系統的任務調度模塊、高可用(HA)管理模塊、全局同步模塊以及聚集計算功能的實現中具有重要作用.
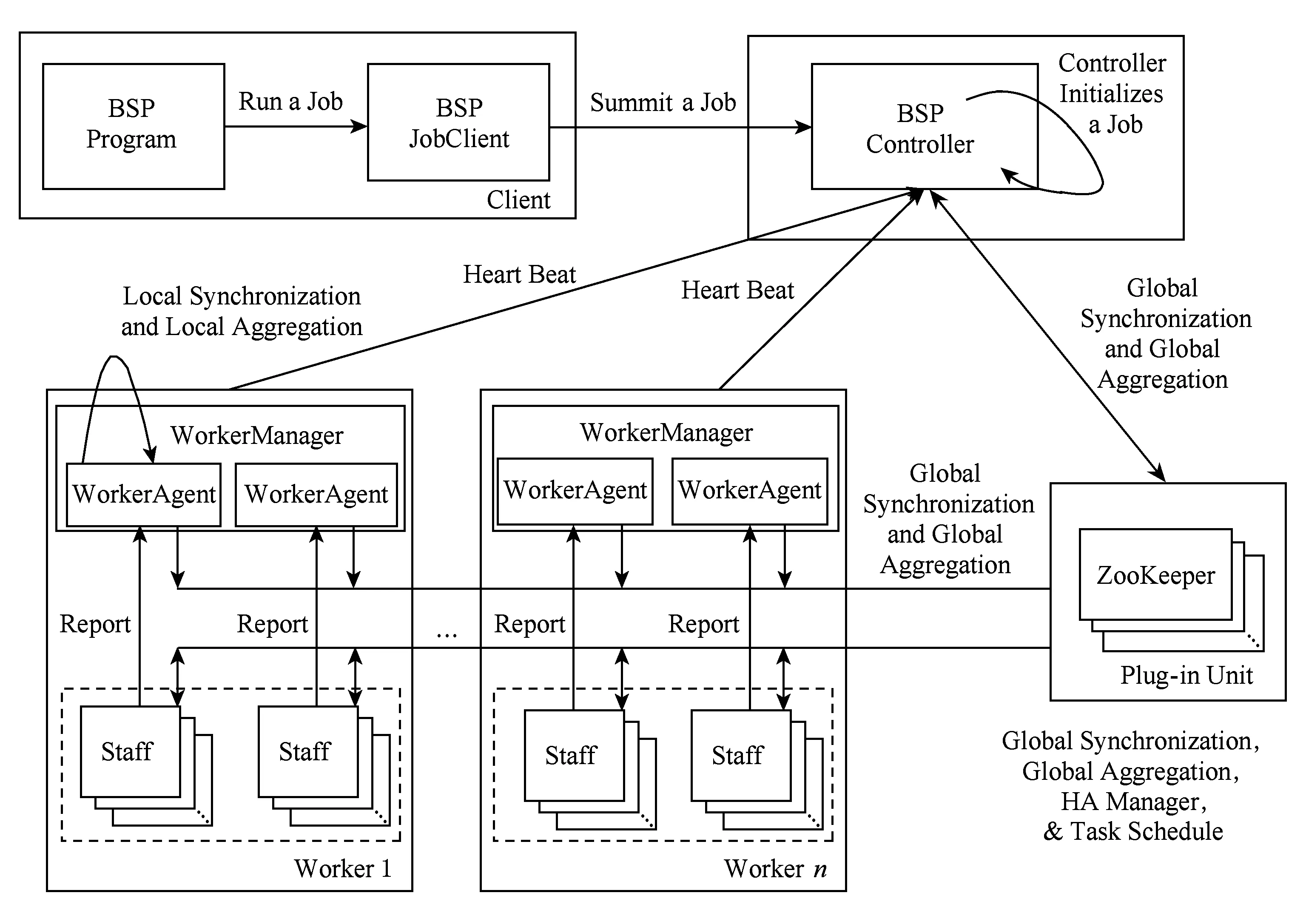
Fig. 1 The system structure of BC-BSP.圖1 BC-BSP系統結構關系圖
鑒于數據量的不斷激增和硬件資源的相對缺乏,BC-BSP系統支持使用磁盤作為迭代計算過程中的輔助存儲介質,暫存圖數據和中間消息數據等,而不是假設所有數據(包括中間的消息數據)都在內存.因此,系統中實現了磁盤緩存模塊,它負責暫存系統計算時內存無法容納的圖數據和消息數據.其基本思路是:對于圖數據,在迭代計算過程中常駐磁盤,在圖處理系統的數據加載階段,每個計算任務從原始數據所在的存儲系統(通常為HDFS或HBase)按照數據分片記錄的位置信息加載數據,數據加載程序每讀取一個頂點的數據,就按照該頂點的ID值,根據系統設定的映射規則,將其寫入到對應節點的磁盤塊中.圖數據在本地磁盤的存儲是按照Hash分桶組織,且每個任務的數據被分成圖頂點(動態數據)、邊(靜態數據)和消息3個部分,每一部分都分為若干個Hash桶存放到本地磁盤上,桶的數量可由用戶自行設定.進入迭代計算階段,每個超步結束后,將動態變化的頂點數據寫回本地磁盤,而不發生變化的靜態數據只在需要處理時才從本地磁盤讀入內存,處理結束后并不需要寫回磁盤,因為它沒有變化.而對消息數據,則盡可能地存儲在內存中,如消息發送時內存緩沖區中的數據量超出用戶設置的緩沖區上限,計算等待發送;在消息接收時,如果所占用緩沖區的大小也超出用戶設置的接收消息緩沖區上限,則接收過程要同步等待數據塊寫入磁盤.
2.2 BC-BSP現有的容錯機制
BC-BSP當前版本的數據備份就是對作業本地計算的中間結果按照一定的頻率(比如每隔k個超步)記錄檢查點.分布式文件系統中記錄的檢查點由3部分信息組成:1)原始的圖數據信息,該部分數據在作業完成之前一直存在;2)每次以增量方式(即只記錄頂點動態數據而不記錄頂點的出邊信息)記錄的檢查點信息;3)各個分區收到的、在下個超步處理的消息.為了節省存儲資源,當新的檢查點記錄成功之后則刪除歷史檢查點.數據恢復即從分布式文件系統加載最后記錄的檢查點信息,加載時要同時讀取原始圖數據信息和最近的增量檢查點信息,以及備份的消息這樣才能還原到最近檢查點記錄時圖處理作業繼續運行的上下文狀態.BC-BSP系統寫檢查點的流程如圖2所示.我們稱這種容錯機制為“增量檢查點”機制.
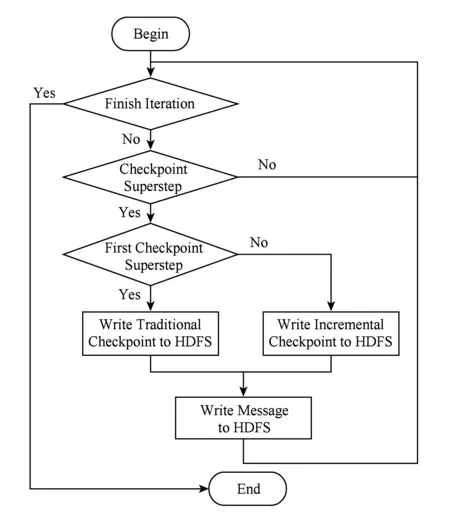
Fig. 2 The flowchart of write checkpoint.圖2 寫檢查點流程圖
BC-BSP系統對故障的檢測是通過心跳機制完成的.當主節點在一定的時間內沒有收到工作節點的心跳信息,就把該節點標記為故障節點.
2.3 多級容錯機制的備份與恢復框架
系統運行過程中各個任務加載分區數據到該任務本地的磁盤上,動態數據每個迭代步都寫回本地磁盤,靜態數據在每次迭代計算中是只讀的.進入迭代計算階段,如果沒有發生故障,無論動態數據或是靜態數據的訪問都是針對本地磁盤的.迭代過程中,系統按照配置文件中設置的檢查點頻率周期性地記錄檢查點.在增量檢查點機制中,除了第1次寫檢查點時需要記錄完整的圖數據(包括頂點Id、value值和出邊)之外,其后的每個檢查點只需記錄圖的動態數據(頂點Id與value值)即可.若計算過程中存在節點間交互,則這種交互的信息都以消息的形式備份到HDFS上.故障恢復時會讀取檢查點及備份的消息進行恢復.但是,通過對某些應用的運行特征進行觀察,我們發現圖的動態部分也不是全部變化的,例如在單源最短路徑計算中每次參與計算的點很少.因此,當動態數據變化的規模小于一定閾值時,啟用log機制來記錄變化的動態數據,這樣需要備份的數據量就小于完整的動態數據部分.這里的關鍵是閾值的確定問題,3.1節將詳細討論.多級容錯機制備份算法如算法1所示.
算法1.computeFramework().
輸入:log機制啟用標志logFlag.
① Whileflag=true /*flag:本地循環計算標志*/
② For each vertexv
③compute();
④ IflogFlag=true
⑤ 將v放到c中;/*c:值發生變化的頂集合*/
⑥ End If
⑦ End For
⑧ 將動態數據寫回本地磁盤文件;
⑨ IfcommandType.equals(“CHECKPOINT”)
/*commandType:超步命令類型*/
⑩ 將消息寫到HDFS;







當故障發生時,針對不同的故障類型采取不同的恢復策略.故障恢復過程的框架見算法2所示.
算法2.FaultRecovery(faultType).
輸入:故障類型faultType.
① IffaultType.equals(“任務故障”)
② 加載本地靜態和動態數據及HDFS上的消息;
③ElseIflogFlag=true/*logFlag:log啟用的標志*/
④ 從HDFS加載檢查點數據、日志和消息;
⑤ Else
⑥ 從HDFS加載檢查點數據和消息;
⑦ End If
對于任務故障,系統直接在本地重啟故障的任務,各個任務(包括重啟的恢復任務)直接利用本地保存的圖數據以及遠程的消息數據恢復到最近的檢查點,因為圖數據在本地有完整的信息,且任務故障不會造成本地的數據不可用(除了極少數文件損壞的情況外).這就避免了加載HDFS上的檢查點圖數據,從一定程度上加快了任務恢復的過程.而對于節點故障,系統首先利用故障恢復調度機制對在這個節點上的所有任務進行遷移操作,因為節點發生故障就不能再使用存儲在本地的圖數據進行恢復了.此時,如果發生故障的任務沒有啟用log機制,那么遷移后的任務通過讀取HDFS上的靜態數據、動態數據和消息進行恢復;如故障任務啟用了log機制,通過讀取HDFS上的靜態數據、log機制記錄的動態數據和消息進行恢復.
3 多級容錯機制的數據備份策略
寫檢查點是常用的容錯數據備份機制:按照一定的頻率或超步間隔將各個任務處理的數據和頂點所收到的消息寫入分布式存儲介質(如HDFS).因為假設內存不足,系統所處理的數據常駐磁盤,需要時才加載到內存,所以各任務處理的數據每個超步結束后都保存到本地磁盤,靜態部分常駐磁盤,動態變化部分每個超步都寫回本地磁盤.
這樣,利用本地的靜態數據、動態數據和HDFS上備份的消息就可以完成任務故障的恢復.
3.1 log機制及其啟用條件
在現有的增量備份策略中,是將動態部分數據全備份到遠程,但實際上有些應用每次迭代計算,甚至在寫檢查點間隔期間,并不會更新分區上所有的狀態或者值,因此為了減少寫入檢查點的冗余數據,當頂點值發生變化的比例低于一定的閾值時,就開啟log機制.所謂的log機制就是在迭代過程中只有一小部分頂點的值發生改變時,記錄這些發生改變的頂點的信息.log機制的實現可以有2種方式:作業級的實現和任務級的實現.作業級的實現就是當作業滿足開啟log機制的條件時,對這個作業的所有任務都啟用log機制;任務級實現是針對某個任務而言的,如某個任務滿足啟用log機制的條件,對這個任務本身啟用log機制.log機制的作業級實現的優點是:當啟用log機制時能夠加快整個作業的運行速度,降低存儲開銷;而任務級實現的優點是:啟用log機制的任務能夠加快該任務本身的運行,減少存儲開銷,更加靈活,當所有任務都開啟log機制時也能加快作業的運行.本文的log機制是在任務級實現的,以任務為單位開啟log機制.采用任務級的log機制,雖然作業的整體運行時間要受到沒有開啟log機制的任務運行時間的影響,但是對于啟用log機制的任務大大減少了檢查點寫入HDFS的數據量,減少了存儲開銷.而當所有的任務都開啟log機制時,作業的整體運行時間也會得到很大的改善.
如果開啟了log機制,那么在2個檢查點之間,每個超步都要將變化的日志寫到遠程,或者暫存在本地.這樣的話,如果這些超步累計記錄的信息大于全部動態數據(本部分增量寫只寫這么多),那么記日志就沒有優勢可言了.對于頂點值發生變化的比例閾值,本文選取為檢查點頻率(記為c)的倒數,即1/c,此時滿足式(1):
(1)
其中,P(Si)為第i超步某任務頂點值發生變化的比例,Si為第i個超步.此時開啟log機制能夠保證在2個檢查點之間所記錄的頂點不會大于原來檢查點所記錄的頂點規模.另外對每個任務設置一個log機制的標志位,用于判斷該任務的log機制是否開啟.對于log機制開啟條件的判斷,本文采用了一種預測式的判斷,如圖3所示.

Fig. 3 The decision of enabling log mechanism.圖3 log機制啟用判定
對提交的作業從S1開始(S0為任務的初始化超步,不進行記錄)對2個檢查點之間的每一個超步內頂點值變化的頂點比例進行收集,設Sk為第1個檢查點的超步數,一個任務在S1,S2,…,Sk滿足式(2):
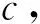
(2)
其中,P(Si)為第i步某任務頂點值變化的比例,那么該任務將會在Sk+1步開啟log機制,該任務的log機制標志位置為true,否則從Sk+1開始重新收集變化的頂點比例.開啟log機制后,從Sk+1繼續開始記錄每個超步內變化頂點最新的value值,到S2k時將這些頂點的變化記錄到HDFS的一個文件中,這就是log機制記錄的log文件.系統在S2k,S3k,S4k…不再記錄完整的圖頂點信息,而是記錄這些log信息,log的存儲規模遠小于所有頂點值的存儲規模.
3.2 log文件生成及優化
log機制開啟后,如果頂點在參與計算之后其值發生改變,那么該頂點的信息將會被暫時記錄在內存中.每記錄一個頂點之前首先要查找內存中是否存在該頂點,如不存在直接記錄,否則記錄頂點的最新的值.在寫檢查點時,內存中的所有記錄將會以log文件記錄到HDFS.
開啟log機制后,每到一個檢查點就會記錄一個log文件.因此,當一個作業運行的超步數比較多時,就會在HDFS上產生很多log文件,這些log文件會影響節點故障的恢復.為了避免在發生節點故障時合并大量的log文件,任務每產生n個log文件(n可由配置文件讀入)就會啟動一個線程在后臺合并log文件,從而減少發生節點故障時要合并的log文件的數量.后臺的線程獨立于作業的執行,因此不會影響作業運行時間.
當大部分的頂點都發生變化時,啟用log機制的開銷過大,此時檢查點記錄的數據量不會有明顯減少,反而會因log文件的合并增大節點故障的恢復開銷,這時就不適合啟用log機制.采用這種策略,在啟用log機制之后只備份發生變化的動態數據,明顯減少了檢查點備份的數據.而在發生節點故障后也能根據log信息、動態數據、靜態數據及消息進行恢復.
開啟log機制對作業運行的收益為
(3)
其中,p為系統發生節點故障的概率,則1-p為系統正常運行至結束或發生任務故障恢復的概率;BenefitN為啟用log機制相比于沒有啟用log機制的作業正常運行至結束或發生任務故障恢復的收益;BenefitR為啟用log機制相比于沒有啟用log機制的作業進行節點故障恢復的收益.BenefitN和BenefitR可分別由式(4)和式(5)表示:
(4)
(5)
式(4)中,slog為第1次記錄log文件的超步數,(s-slog)/c+1為總共記錄的log文件的個數,CostWc k為記錄一次檢查點的代價,CostW(i)log為第i次記錄log的代價.
式(5)中,sf表示發生節點故障的超步數,則(sf-slog)/c為故障任務需要讀取的log文件的數量;CostR(i)log為讀取第i個log文件的代價.
為簡化問題,我們忽略在內存中記錄變化的頂點信息的開銷及后臺進程對log文件的合并.由式(4)和式(5)可以看出,開啟log機制獲得的收益和檢查點頻率、發生節點故障的超步數有密切的關系.檢查點頻率設置得越小,發生節點故障的超步數越小,開啟log機制相對于BC-BSP的增量檢查點獲得的收益可能越大.
4 多級容錯機制的故障恢復策略
4.1 任務故障的恢復
任務運行過程中,會因為運行環境的影響,例如出現異常、文件讀寫錯誤等,導致任務不能正常運行.這種任務故障一般不會造成本地數據的損壞(極少數的任務故障由文件的磁盤故障引起,造成文件損壞,本文忽略此種情況),所以系統對于任務故障的恢復策略是直接在原來的節點上重新啟動故障任務,所有任務加載檢查點進行故障恢復.
根據本文提出的多級容錯處理機制的第1級容錯處理機制的數據備份策略,本地磁盤保存了任務故障恢復所需的靜態數據和動態數據.因此,故障任務可以直接加載本地保存的靜態數據和檢查點時刻的動態數據以及HDFS上備份的消息,回滾到距離故障超步最近的檢查點進行故障恢復.本文的第1級容錯處理機制避免了加載HDFS保存的靜態數據和動態數據,直接利用本地磁盤保存的靜態數據和動態數據進行恢復,加快了任務故障恢復時加載檢查點所需的時間,同時也減輕了網絡傳輸的壓力.
4.2 節點故障的恢復
節點故障一般是由分布式系統中的物理機宕機或網絡原因導致.這種故障一般會造成故障節點不可用.系統對于節點故障的處理流程是:首先利用故障恢復調度機制對在這個節點上所有的任務進行遷移操作,因為節點發生故障就不能再使用該節點進行本地恢復,故障任務將會被遷移到正常的節點上重啟;然后加載檢查點進行恢復.遷移到其他節點的任務由于缺少該任務以前的本地的動態數據與靜態數據,因此系統通過讀取HDFS記錄的靜態數據與動態數據及消息進行節點故障的恢復.
如果故障任務沒有開啟log機制,可以利用第2級容錯處理機制(即BC-BSP的增量檢查點機制)恢復策略,加載檢查點上的靜態數據、動態數據及消息進行故障恢復.如果故障任務開啟log機制,根據第3級容錯處理機制的恢復策略,需要加載檢查點記錄的靜態數據、動態數據、log文件及消息進行節點故障恢復.第2級容錯處理機制已在2.2節詳細介紹,這里不再贅述.
第3級容錯處理機制的恢復策略具體為:按照log文件生成的先后順序,首先讀取最晚生成的log文件的每一條記錄到內存中;然后依次讀取較早生成的log文件,較早記錄的log文件中的頂點ID如在內存中已記錄就無需再記錄,而較早記錄的log文件中的頂點在內存中不存在時便記錄此頂點信息.掃描完所有的log文件之后,再讀取記錄有全圖信息的檢查點記錄(可能存在增量檢查點,也可能只存在第1個檢查點記錄),將內存中的記錄與檢查點按照上述方法再次合并,最終生成故障發生前最近的檢查點時刻的完整動態數據.該策略完整描述如算法3所示.
算法3.readLogCheckPoint(s,ck).
輸入:記錄第1個log文件的超步數s、檢查點頻率ck;
輸出:圖數據對象graphData.
① /*讀取未合并log文件集合*/
② For each log filelfrinNr/*Nr:未合并log文件集合*/
③Foreach頂點vinlfr
④ 將v放入c /*c:值發生變化的頂點集合*/
⑤ End For
⑥ End For
⑦ /*讀取已合并log文件集*/
⑧ For each log filelfminNm/*Nm:已合并log文件集合*/
⑨Foreach頂點vinlfm
⑩If不存在v


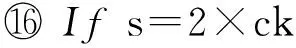
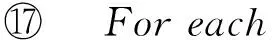









5 實驗結果與分析
5.1 數據集與實驗設置
本文使用2個真實圖數據集進行實驗,包括Wiki[12]和USA-Road[13],具體描述如表1所示.測試使用的應用包括計算圖的連通分量(CC)和單源最短路徑(SSSP).

Table 1 Description of Real-World Graphs
本文在BC-BSP系統上實現了多級容錯處理機制.本文實驗的對比分析包括:第1級容錯處理機制與BC-BSP的增量檢查點機制的對比,即任務故障恢復時加載HDFS與加載本地數據的對比;不同寫檢查點頻率下開啟log機制與關閉log機制的作業運行時間、寫檢查點IO開銷(不包括消息)的對比;第3級容錯處理機制與BC-BSP增量檢查點的對比,不同寫檢查點頻率下節點故障的恢復;頂點值變化比例的閾值對作業運行的影響.第2級容錯處理機制即為原BC-BSP系統節點故障的恢復機制.實驗所用集群由15個節點構成,且由1臺Gigabit以太網交換機連接,每個計算節點配置酷睿i3-2100雙核處理器、8 GB內存、1TB的7200RPM硬盤.每個節點最大任務槽數設為2,測試時啟動10個任務,多余的節點是為了發生節點故障時有可用的節點進行故障遷移.節點的心跳間隔設為1 s,心跳超時時間設為3 s.測試的參數為檢查點頻率和故障超步數,測試的指標為作業運行時間和寫檢查點IO開銷.
5.2 任務故障恢復
我們在2個真實數據集上使用SSSP和CC測試了BC-BSP增量檢查點機制加載HDFS與多級容錯處理機制的第1級容錯處理機制加載本地磁盤進行任務故障恢復的時間.這里我們設置檢查點頻率為6,運行至第8步發生任務故障,共運行10個超步.
圖4為不同的應用分別在BC-BSP的增量檢查點機制與本文的多級容錯機制的第1級容錯機制下進行任務故障恢復的運行時間,圖5統計了平均每個任務在進行任務故障恢復時加載檢查點所花費的時間.

Fig. 4 The recovery time of task failure.圖4 任務故障恢復時間
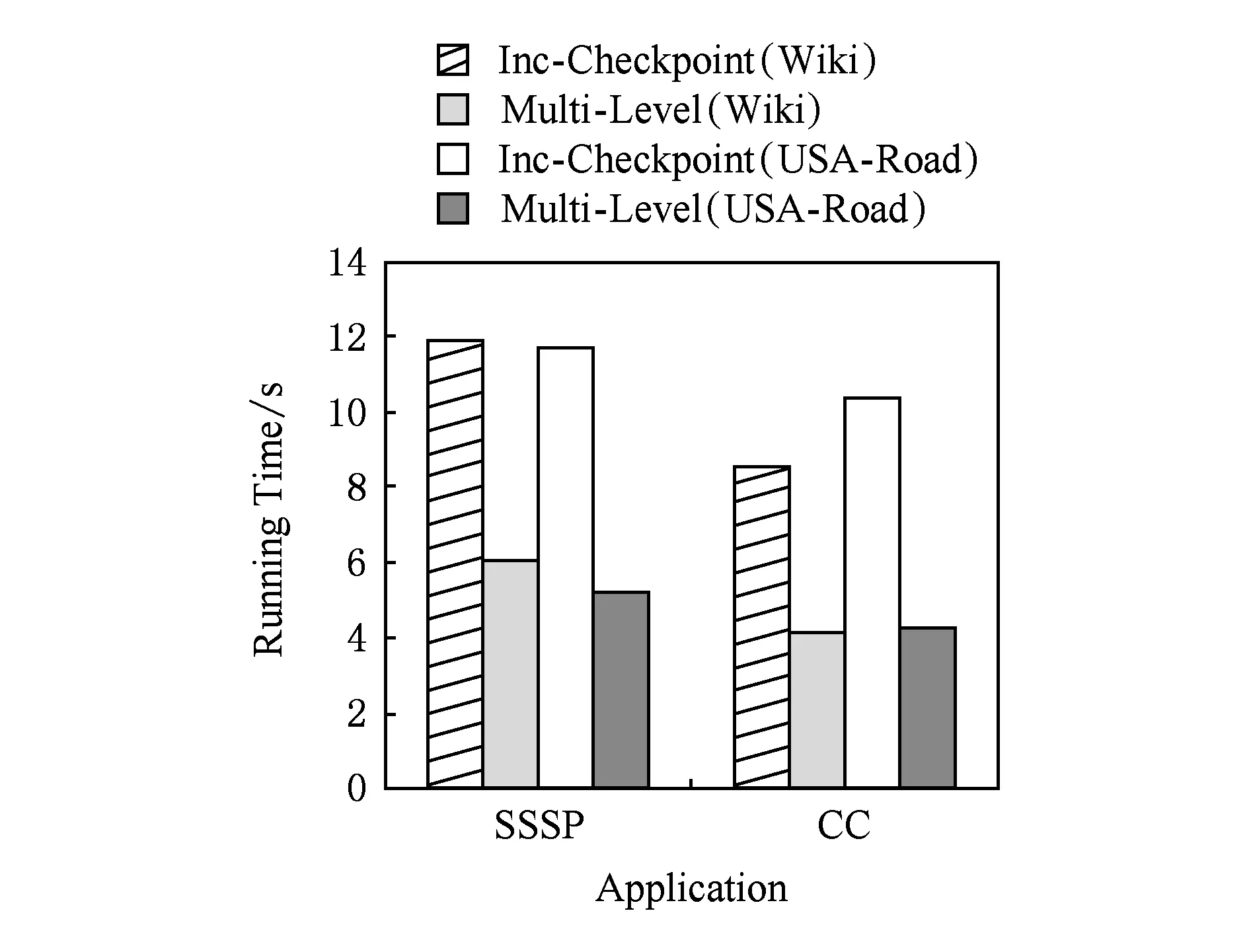
Fig. 5 The checkpoint time of task failure recovery.圖5 任務故障恢復加載檢查點時間
綜合圖4和圖5的實驗結果可以發現,對于不同應用(SSSP和CC),加載本地數據的時間比加載HDFS的時間快了1倍多,作業恢復運行的總時間也有所改善.此外,由于加載本地數據不需要網絡傳輸,因此也降低了網絡傳輸的開銷.本節的實驗證明了本文多級容錯處理機制的第1級容錯處理機制的高效性.
BC-BSP進入迭代計算階段,每個超步結束后將動態變化的頂點數據寫回本地磁盤,不發生變化的靜態數據只在需要處理時再從本地磁盤讀入內存,而在處理結束時并不寫回磁盤,因為它沒有變化.任務故障的恢復只需額外備份檢查點寫到磁盤上的動態數據,所以存儲代價為一步的動態數據的大小.經實驗測得,對于2種應用在USA-Road數據集上,每臺機器的存儲代價均為21 MB,而Wiki數據集的存儲代價均為每臺機器5MB.因此,存儲代價很低.
5.3 log機制對正常運行的作業的影響
在2個真實數據集上,使用SSSP測試了log機制,以證明開啟log機制能夠加速作業正常運行.
圖6給出了SSSP在數據集Wiki和USA-Road上以不同的檢查點頻率正常運行40個超步時,BC-BSP的增量檢查點機制與log機制的運行時間的對比.
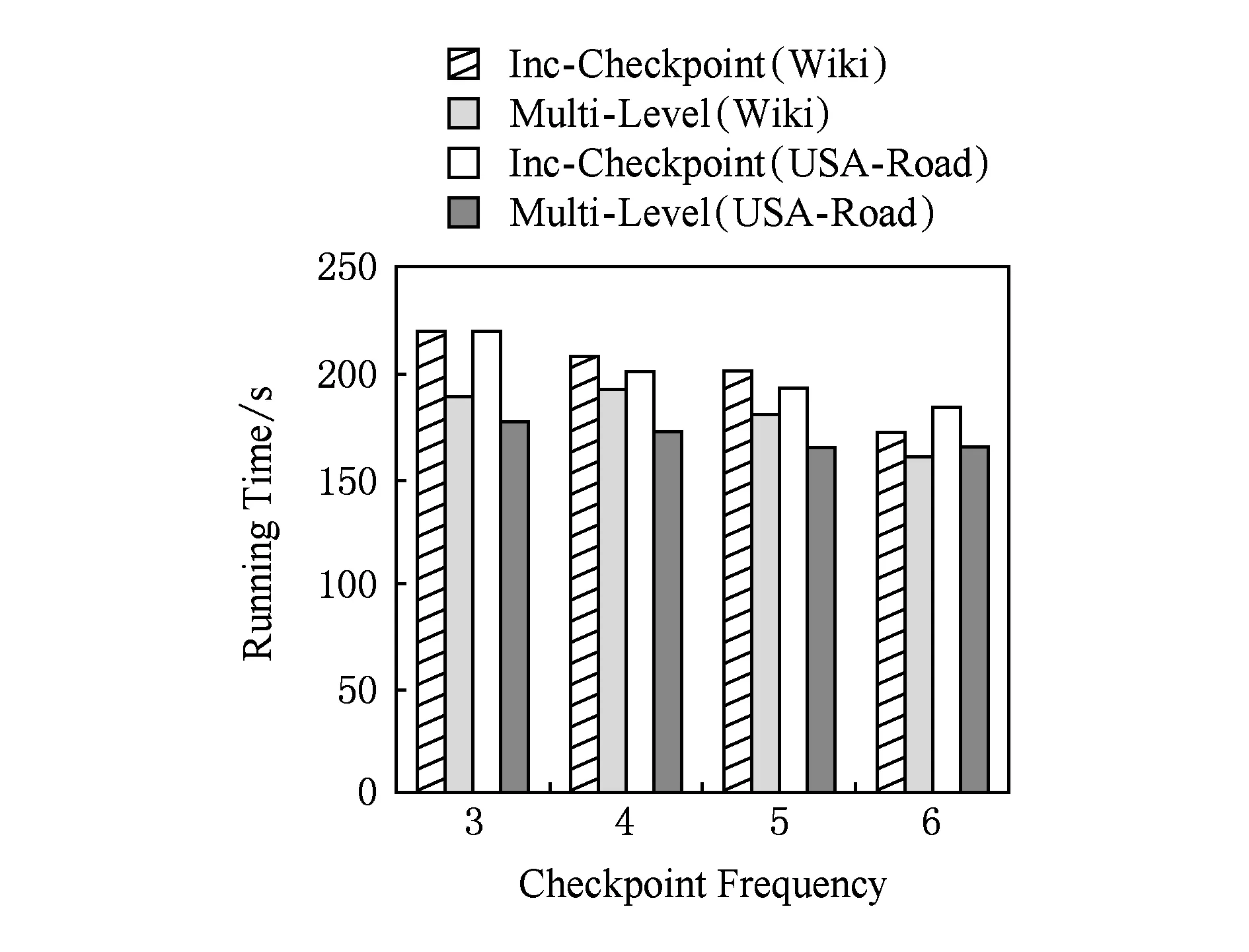
Fig. 6 Running time of job against the checkpoint frequency.圖6 不同檢查點頻率作業運行時間
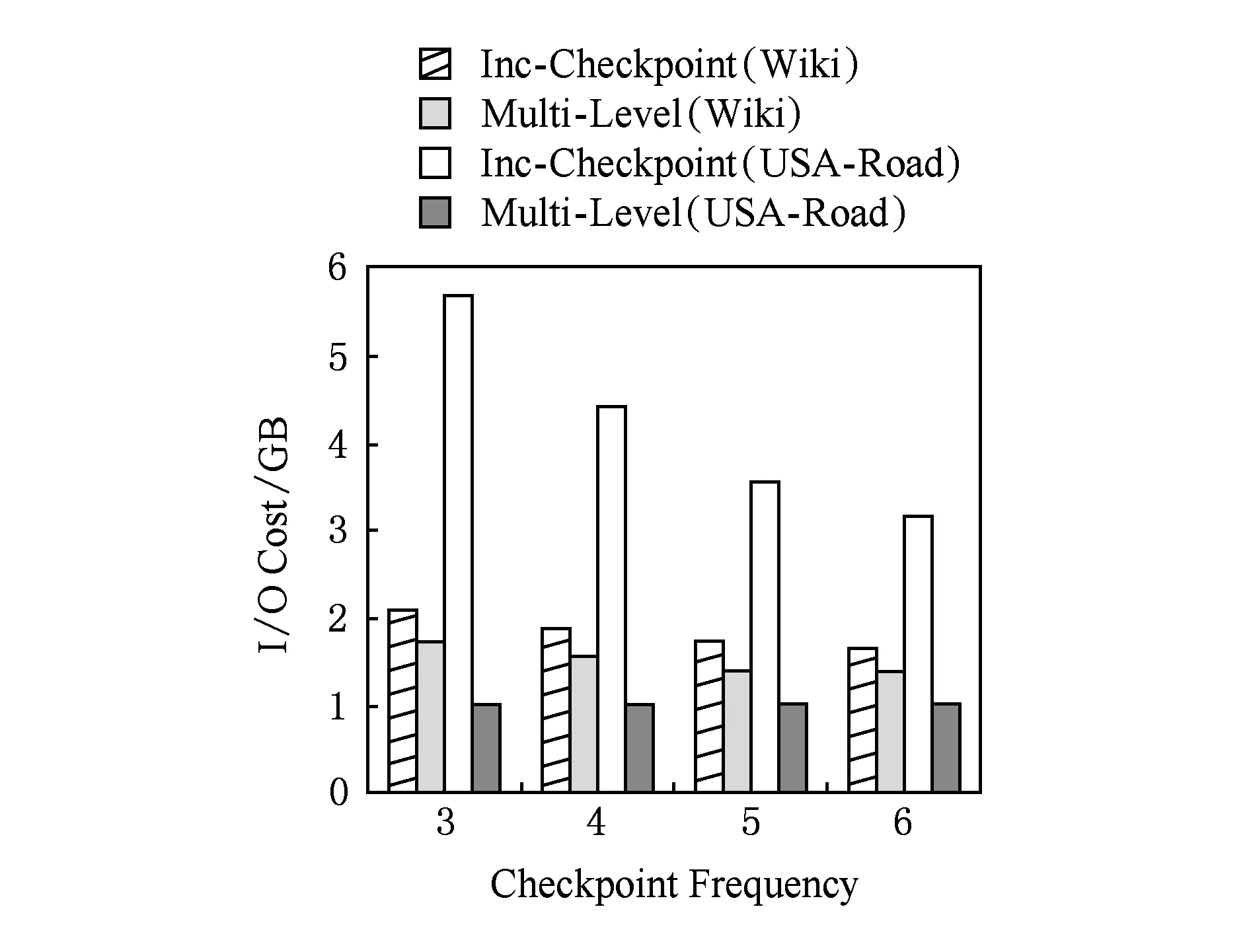
Fig. 7 IO cost of backup against the checkpoint frequency.圖7 不同檢查點頻率下備份的IO開銷
由圖6可以看出,開啟log機制后的作業運行時間明顯減少,而寫檢查點頻率設置越小,log機制對于作業正常運行時間的收益越大.因為,開啟log機制的任務在寫檢查點時備份的數據量比BC-BSP的增量檢查點機制要少得多,在記錄多個檢查點后,log機制明顯地縮短了作業正常運行的時間.
圖7給出了SSSP在數據集Wiki和USA-Road上以不同的檢查點頻率正常運行40個超步時,BC-BSP的增量檢查點機制與log機制的備份IO開銷對比.由圖7可以看出,啟用log機制后備份的IO開銷比BC-BSP的增量檢查點機制的要小,特別是對USA-Road這種平均出度比較小的數據集效果更加顯著.這是因為SSSP在USA-Road啟用log機制的超步比在Wiki上早很多,因此SSSP在USA-Road上的IO收益要遠高于在Wiki上的IO收益,在時間上的收益也高于Wiki.本節從時間和備份的IO開銷的角度來對比BC-BSP的增量檢查點機制與log機制,實驗結果論證了本文的log機制提高了作業正常運行的效率.
5.4 log機制對節點故障恢復的影響
我們在2個真實數據集使用SSSP測試了log機制對于節點故障恢復的影響,為了說明故障超步數和檢查點頻率對節點故障恢復的影響,我們在Wiki數據集上進行了測試.
圖8和圖9分別給出了以不同的檢查點頻率在第17步與第33步制造節點故障時運行40個超步log機制對于節點故障恢復時間的影響.
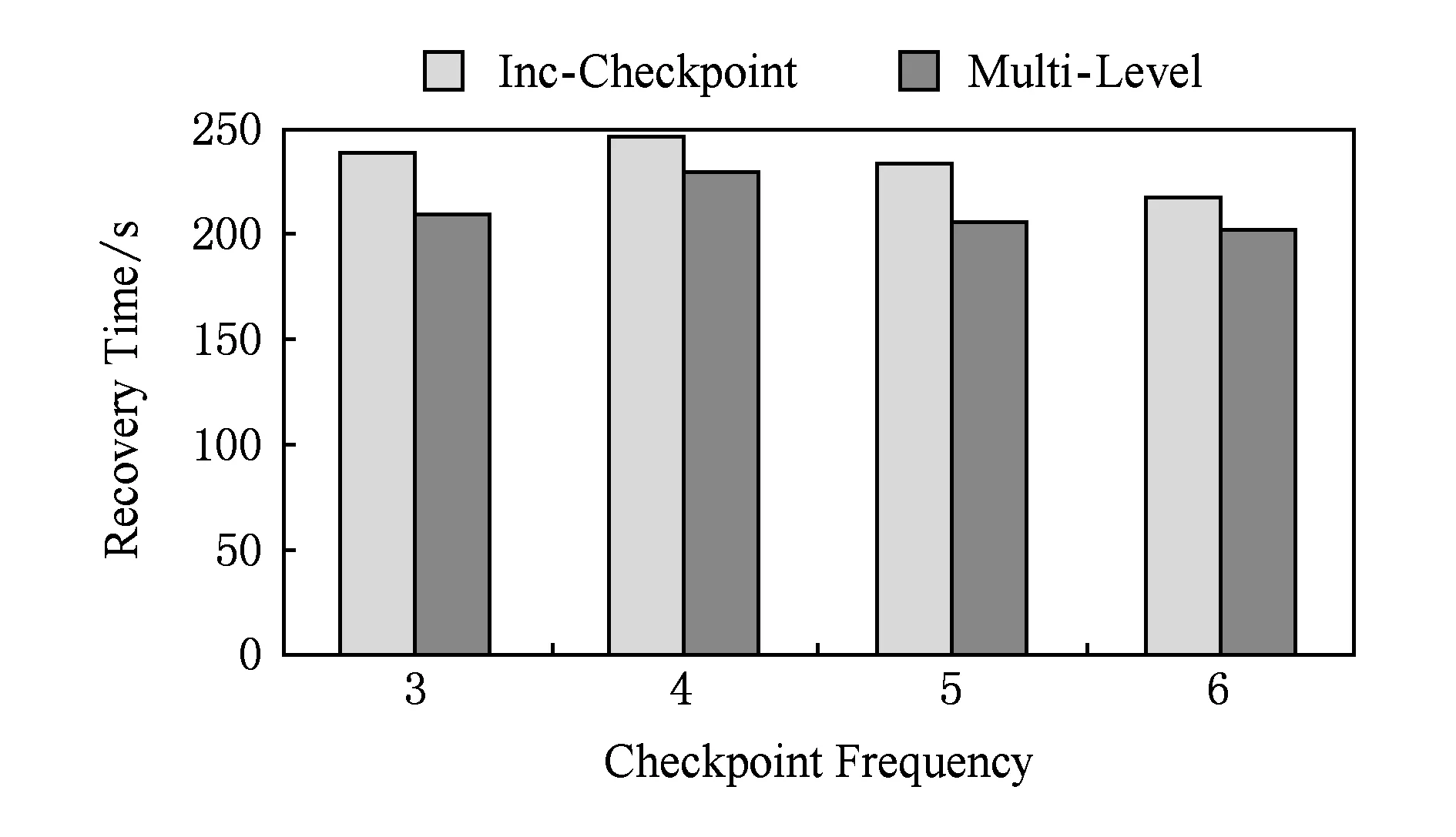
Fig. 8 Recovery time of job against the checkpoint frequency.圖8 不同檢查點頻率作業恢復時間
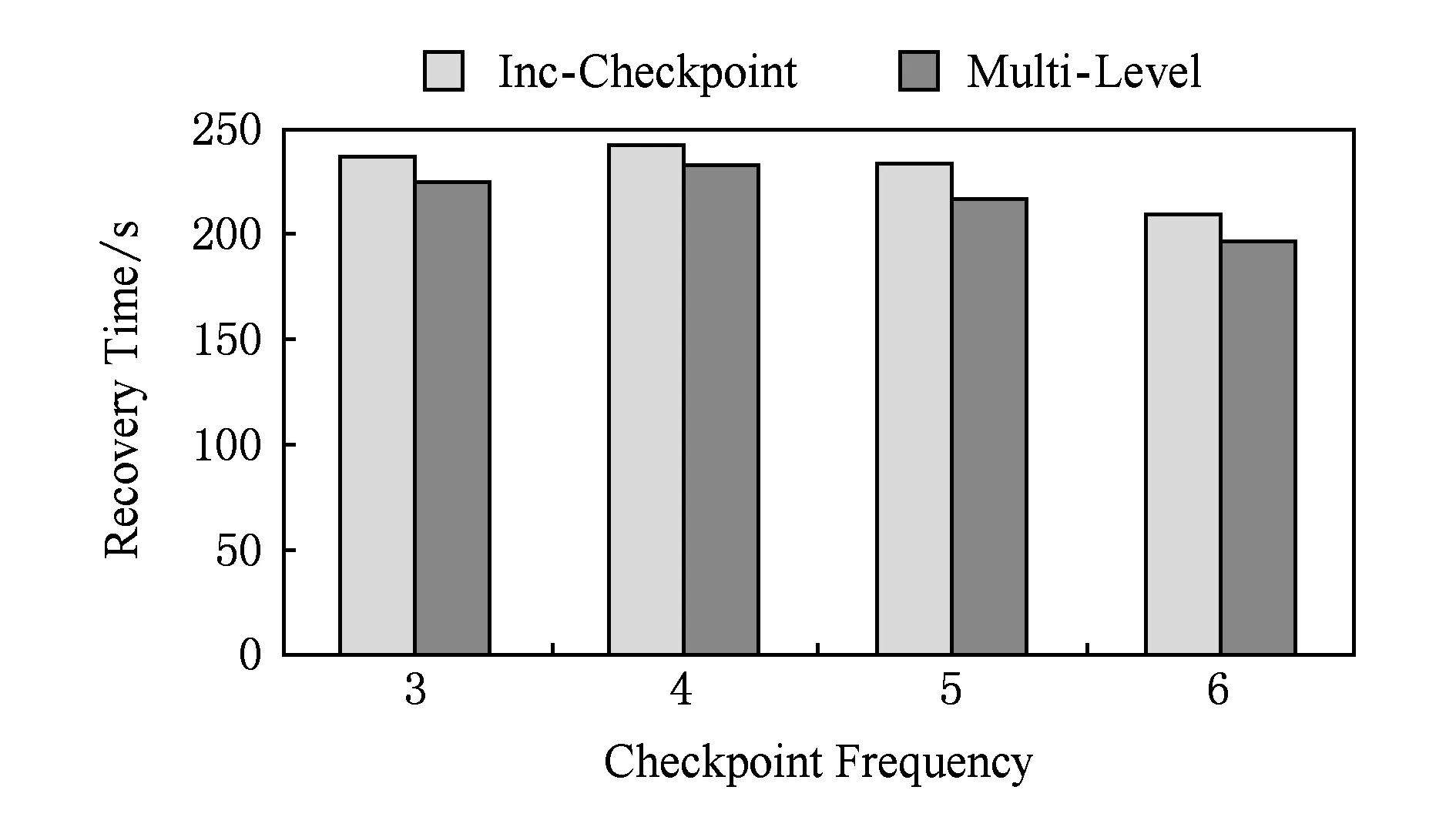
Fig. 9 Recovery time of job against the checkpoint frequency.圖9 不同檢查點頻率作業恢復時間
對比圖8和圖9可以發現,故障步數越大,恢復時需要讀取的log文件內容可能越多,合并log所花費的時間開銷也有所增大,但是恢復的總時間仍小于沒有開啟log機制的總時間.這是因為,在啟用log機制的情況下,寫檢查點的時間開銷減少了,節省的時間足以抵消讀取log文件所花費的時間.因此開啟log機制在一定程度上加速了節點故障的恢復過程.本節實驗說明第3級容錯處理機制加速了節點故障的恢復.
5.5 log啟動閾值對log機制的影響
我們使用SSSP和CC在Wiki上測試不同的log啟動閾值對于log機制的影響,以驗證3.1節理論分析.本節實驗中,閾值的定義為值發生變化的頂點占所有頂點的比例,而檢查點頻率設置為5,運行40個超步.
圖10和圖11分別給出了在不同閾值下作業的運行時間與備份的IO開銷.該閾值的選取要對作業運行時間和寫檢查點的IO開銷優化相對多.因為閾值選取過大可能會造成在內存中記錄的log信息過多,從而導致內存開銷過大;圖11可以看出,閾值選取為10%時,啟用log機制比較晚,導致備份的IO開銷比較大.通過權衡作業的運行時間和寫檢率的倒數)是比較合適的.當閾值為20%時,寫檢查點的IO相對較小,作業的運行時間也和其他3種閾值下的作業運行時間相當.這說明了3.1節中對這個閾值的推導是正確的.
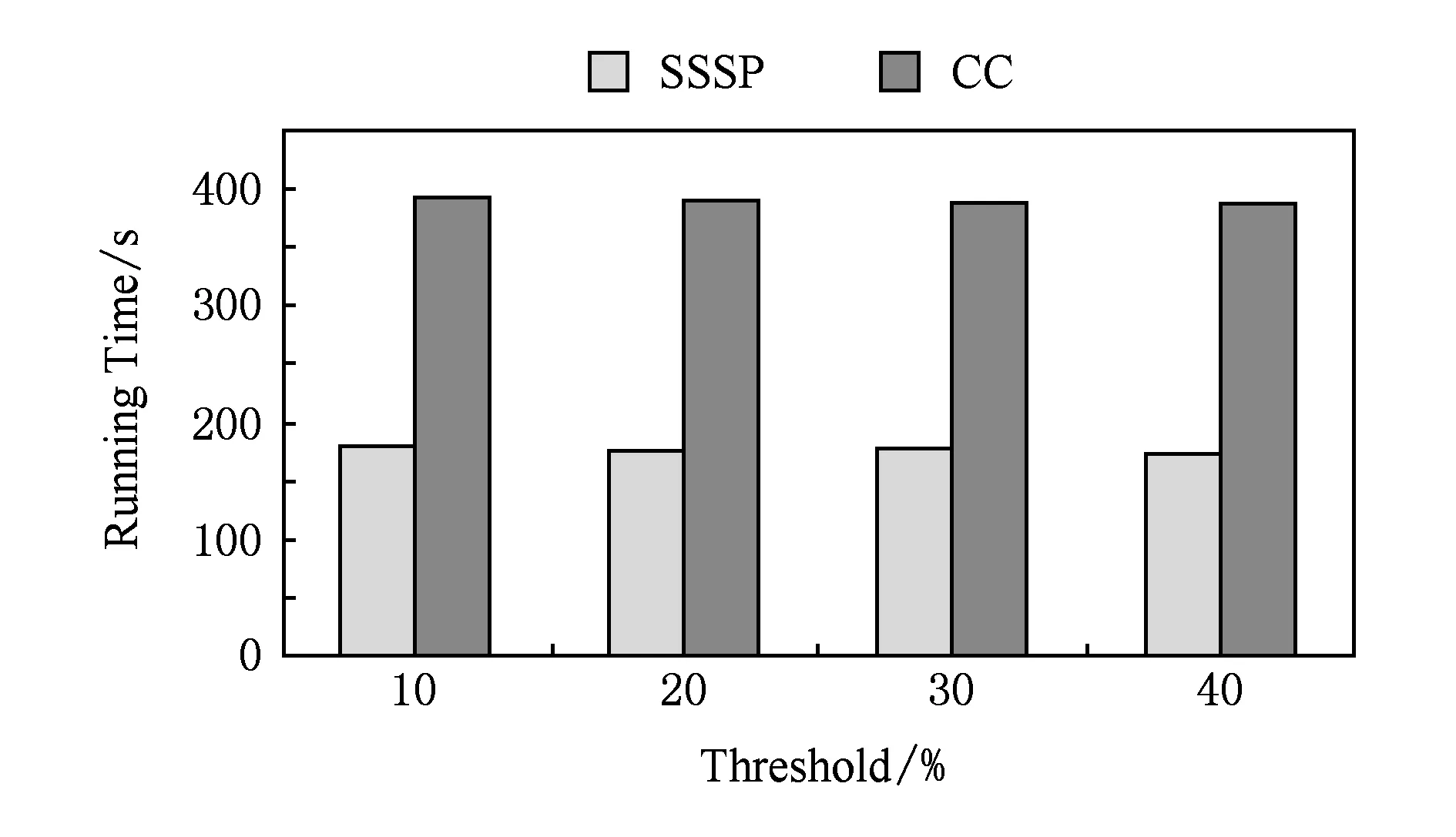
Fig. 10 Running time of job against the threshold of starting the log mechanism.圖10 不同log機制啟動閾值下作業運行時間
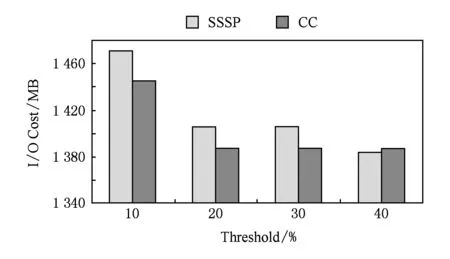
Fig. 11 IO cost of backup against the threshold of starting the log mechanism.圖11 不同log機制啟動閾值下備份的IO開銷
6 結 論
本文提出了多級容錯處理機制,通過在2個真實數據集上大量的對比實驗證明了多級容錯機制的高效性與正確性.第1級容錯處理機制直接利用本地保存的動態數據、靜態數據及HDFS上的消息進行恢復,避免了加載HDFS上動態數據、靜態數據從而加快了其恢復過程.第3級容錯處理機制對于頂點值變化比例較低的應用,例如SSSP和CC,通過log記錄變化的頂點信息而極大減少了傳統檢查點機制所記錄的數據量和存儲開銷(實驗中也發現,對于每個超步頂點變化比例較高的應用,例如PageRank,意義不大).系統在所有任務都啟用log機制后,整個作業的運行時間明顯減少.通過log信息進行節點故障的恢復,在節點恢復過程中雖然引入了合并log的過程,但由于作業運行過程中開啟了log機制,作業的整體運行時間在一定程度上仍有所降低.
下一步的工作將探索日志合并頻率對log機制的影響,即它的改變對于節點故障恢復時間的影響.通過大量實驗找出一個最合適節點故障恢復的日志合并頻率.
[1]The Apache Software Foundation. Introduction to Giraph[EB/OL]. [2015-05-25]. http://giraph.apache.org/intro.html
[2]Bao Yubin, Wang Zhigang, Yu Gu, et al. BC-BSP: A BSP-based parallel iterative processing system for big data on cloud architecture[C] //Proc of the 1st Int DASFAA Workshop on Big Data Management and Analytics. Berlin: Springer, 2013: 31-45
[3]Malewicz G, Austern M H, Bik A J C, et al. Pregel: A system for large-scale graph processing[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 135-146
[4]Shen Y, Chen G, Jagadish H V, et al. Fast failure recovery in distributed graph processing systems[J]. Proceedings of the VLDB Endowment, 2014, 8(4): 437-448
[5]Low Y, Gonzalez J E, Kyrola A, et al. GraphLab: A new framework for parallel machine learning[J/OL]. 2014[2015-05-25]. http://arxiv.org/abs/1408.2041
[6]Gonzalez J E, Low Y, Gu H, et al. PowerGraph: Distributed graph-parallel computation on natural graphs[C] //Proc of the 10th USENIX Conf on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 17-30
[7]Salihoglu S, Widom J. GPS: A graph processing system[C] //Proc of the 25th Int Conf on Scientific and Statistical Database Management. New York: ACM, 2013: 22
[8]Khayyat Z, Awara K, Alonazi A, et al. Mizan: A system for dynamic load balancing in large-scale graph processing [C] //Proc of the 8th ACM European Conf on Computer Systems. New York: ACM, 2013: 169-182
[9]Xin R S, Gonzalez J E, Franklin M J, et al. GraphX: A resilient distributed graph system on spark[C] //Proc of the 1st Int Workshop on Graph Data Management Experiences and Systems. New York: ACM, 2013: 1-6
[10]Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C] //Proc of the 9th USENIX Conf on Networked Systems Design and Implementation. Berkeley, CA: USENIX Association, 2012: 141-146
[11]Yi Huizhan, Wang Feng, Zuo Ke, et al. Asynchronous checkpoint/restart based on memory buffer[J]. Journal of Computer Research and Development, 2015, 52(6): 1229-1239 (in Chinese)
(易會戰, 王鋒, 左克, 等. 基于內存緩存的異步檢查點容錯技術[J]. 計算機研究與發展, 2015, 52(6): 1229-1239)
[12]Wikipedia. Using the Wikipedia Link[EB/OL]. [2015-05-25]. http://haselgrove.id.au/wikipedia.htm[13]Sapienza University of Rome. Using the USA-Road Link[EB/OL]. [2015-05-25]. http://www.dis. uniroma1.it/challenge9/download.shtml

Bi Yahui, born in 1990. Master candidate at the College of Computer Science and Engineering, Northeastern University. His main research interests include cloud computing and graph management, etc.

Jiang Suyang, born in 1991. Master candidate at the College of Computer Science and Engineering, Northeastern University. Her main research interests include cloud computing and graph management, etc.

Wang Zhigang, born in 1987. PhD candidate at the College of Computer Science and Engineering, Northeastern University. His main research interests include cloud computing and graph data mining, etc.

Leng Fangling, born in 1978. Received her PhD degree in computer software and theory from Northeastern University in 2008. Lecturer at Northeastern University. Member of China Computer Federation. Her main research interests include data warehouse and online analytical processing (OLAP), etc.

Bao Yubin, born in 1968. Received his PhD degree in computer software and theory from Northeastern University in 2003. Professor at Northeastern University. Senior member of China Computer Federation. His main research interests include data warehouse, online analytical processing (OLAP), cloud computing and data intensive computing, etc.

Yu Ge, born in 1962. Received his PhD degree in computer science from Kyushu University of Japan in 1996. Professor and PhD supervisor at Northeastern University. His main research interests include database theory and technology, distributed system, parallel computing and cloud computing, etc.

Qian Ling, born in 1972. Received his PhD degree of engineering at the Department of Computer Science and Technology, Tsinghua University, in 2001. He joined Bell Labs Research China in 2001. He worked on IPv6 edge router, voice messaging, voip, instant messaging, LBS, mobile application and other related projects. In 2008, he joined China Mobile Research Institute and worked on mobiles ads, big data and cloud computing projects.
A Multi-Level Fault Tolerance Mechanism for Disk-Resident Pregel-Like Systems
Bi Yahui1, Jiang Suyang1, Wang Zhigang1, Leng Fangling1, Bao Yubin1, Yu Ge1, and Qian Ling2
1(CollegeofComputerScienceandEngineering,NortheasternUniversity,Shenyang110819)2(ChinaMobile(Suzhou)SoftwareTechnologyCo,Ltd,Suzhou,Jiangsu215163)
The BSP-based distributed frameworks, such as Pregel, are becoming a powerful tool for handling large-scale graphs, especially for applications with iterative computing frequently. Distributed systems can guarantee a flexible processing capacity by adding computing nodes, however, they also increase the probability of failures. Therefore, an efficient fault-tolerance mechanism is essential. Existing work mainly focuses on the checkpoint policy, including backup and recovery. The former usually backups all graph data, which leads to the cost of writing redundant data since some data are static during iterations. The latter always loads backup data from remote machines to recovery iterations, ignoring the usage of data in the local disk in special scenarios, which incurs network costs. It proposes a multi-level fault tolerant mechanism, which distinguishes failures into computing task failures and node failures, and then designs different strategies for backup and recovery. For the latter, considering that the volume of data involved in computation varies with iterations, a complete backup policy and an adaptive log-based policy are presented to reduce the cost of writing redundant data. After that, at the stages of recovery, we utilize the local graph data and the remote message data to handle the recovery for task failures, but the remote data are used for node failures. Finally, extensive experiments on real datasets validate the efficiency of our solutions.
fault tolerance;large-scale graph; iterative computing; BSP model; checkpoint
2015-06-30;
2015-10-29
國家自然科學基金重點項目(61433008);國家自然科學基金項目(61173028,61272179);中央高校基本科研業務費專項基金項目(N100704001);教育部-中國移動科研基金項目(MCM20125021)
TP311. 13
This work was supported by the Key Program of the National Natural Science Foundation of China (61433008), the National Natural Science Foundation of China (61173028,61272179), the Fundamental Research Funds for the Central Universities (N100704001), and Chinese Ministry of Education-China Mobile Communications Corporation Research Funds (MCM20125021).
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
汽車維修與保養(2019年7期)2020-01-06 03:30:42
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
汽車維護與修理(2016年10期)2016-07-10 08:17:41
中國衛生(2015年9期)2015-11-10 03:11:12
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
汽車維護與修理(2015年2期)2015-02-28 12:15:39
