面向制造領域文本的多標簽分類方法
2016-11-29 13:54:10王慶文
制造業自動化 2016年2期
楊 瑩,王慶文
(北京航空航天大學,北京 100191)
面向制造領域文本的多標簽分類方法
楊 瑩,王慶文
(北京航空航天大學,北京 100191)
機械制造領域存在大量的領域知識,這些領域知識將特征項與文本類別關聯起來,有助于區分文本的類別。基于此,本文提出一種融合領域知識的多標簽分類方法旨在提高機械制造領域文本的分類性能,該方法首先采用融合領域知識的x2統計特征選擇方法得到文本表示特征項集合和對應的相關度矩陣R,R反映了各特征項與類別的相關度;然后將文本是否包含某類別標簽這一事件和文本與該類別的相關度關聯起來,文本與該類別相關度視作特征項與該類別相關度的集聚,其相關度越大,文本包含該類別標簽的概率也越大,統計文本各類別相關度的貢獻率,根據最大后驗概率準則推理文本類別標簽集合。在3個多標簽分類常用評測指標下的實驗結果表明:與MLKNN方法進行對比,對于機械制造領域文本,融合領域知識的多標簽分類方法具有更好的分類性能。
機械制造領域;領域知識;相關度;多標簽;文本分類
0 引言
隨著互聯網和信息技術的快速發展,互聯網數據量劇增,有研究表明,文本信息這一類非結構化數據占了互聯網數據的50%以上,因此,對文本信息的處理顯得尤為重要。文本分類是對文本進行有效管理的一種方式,方便用戶進行查詢、定位信息等,同時文本分類也是信息檢索,信息過濾,數據挖掘等相關領域的技術基礎[1]。機械制造領域研究的內容非常廣泛,包括材料分析,制造加工,車間管理調度,機構設計應用,檢測監控等,各研究內容不完全獨立,存在著交叉研究,因此對機械制造領域的文本進行分類時,文本可能包含多個類別標簽。基于此,本文將對面向機械制造領域文本的多標簽分類問題展開研究。
目前多標簽文本分類問題的解決方法主要有兩種:問題轉換法和算法適應法[2]。問題轉化法的思想是首先根據一定的規則將多標簽問題轉化為一個或多個單標簽問題,然后利用單標簽學習算法進行處理。算法適應法則是通過擴展單標簽學習算法來適用于多標簽學習問題,無需將多標簽文本轉化為單標簽問題。張敏靈提出了一種基于K近鄰的多標簽文本分類方法:MLKNN,該方法是一種典型的算法適應法,使用K近鄰方法統計近鄰樣本的類別標簽信息,通過最大化后驗概率的方法推理待分類文本的標簽集合[3]。與其他多標簽分類方法相比,MLKNN方法具有無需學習,實現簡單,分類性能好的特點,為此,許多學者在其基礎上展開了進一步研究。張敏靈后來針對MLKNN未考慮標簽間的相關性的不足提出一種新型多標記懶惰學習算法IMLLA,這種方法在對文本每個類別進行預測時利用了蘊含于其他類別中的信息,充分考察了多個標簽的相關性[4]。Ruben Nicolas提出了一種基于案例推理學習的多標簽分類方法MLCBR,MLCBR基于案例推理學習近鄰樣本標簽重用概率的閾值,使用近鄰樣本標簽的分布概率推理文本的類別標簽集合,與MLKNN相比,其算法復雜度低且分類性能相當[5]。Everton AlvaresCherman采用MLKNN方法進行多標簽分類時,不僅考慮樣本的K近鄰標簽集合還考慮近鄰樣本的K近鄰標簽集合用于推理樣本的標簽,與原始的MLKNN方法相比,其方法的準確率有進一步的提高[6]。
目前采用的多標簽分類方法基本都是基于機器學習的思想。根據經驗,有些專業詞匯具有明顯的類別傾向性,是判斷文本類別的重要依據,如:當文本中大量出現“云制造”、“制造服務”這些詞語時,我們很容易將文本聯想到制造工程這一類別。我們稱“云制造”和“制造服務”包含的行業內流通度高、眾所周知、與具體類別相關的語義知識為領域知識[7],顯然領域知識有助于文本分類。在實際應用中,往往由于樣本集的有限性,機器學習不能將特征項的領域知識都學習出來用于分類,在機械制造領域,存在著大量的領域知識。基于此,本文提出一種融合領域知識的多標簽分類方法旨在進一步提高機械制造領域文本的分類性能。
1 融合領域知識的多標簽文本分類方法
1.1特征選擇
特征選擇一般采用機器學習的方法,其步驟是構造特征項的評估函數,依據評估函數計算每個特征項的權重,權重越大表示特征項區分文本類別的能力越強,特征項被選擇的可能性也越大,按照權重降序排列,確定閾值,選取排名滿足條件的特征項表示文本,常用的特征選擇方法有:文檔頻率,信息熵,互信息和X2統計等。本文采取的特征選擇方法將領域知識和機器學習結合起來。
有研究結果指出X2統計方法的降維效果比較好[8],本文首先選擇X2統計作為特征選擇的方法,其計算方法如下所示:
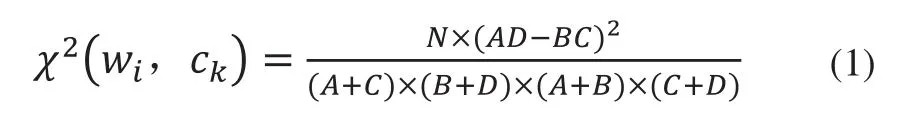
其中,N表示文本總數,A表示包含類別標簽ck和特征項wi的文本數量,B表示不包含類別標簽ck但包含特征項wi的文本數量,C表示包含類別標簽ck但不包含特征項wi的文本數量,D表示不包含類別標簽ck和特征項wi的文本數量。考慮到B=C=0時,式(1)取得最大值N,將式(1)進行歸一化處理,χ2統計值的計算公式變換為如下所示:

特征項wi與類別ck的相關程度包含正相關和負相關兩種情況,由原始公式(1)的數學意義可知,當ADBC>0時,特征項wi與類別ck呈正相關,此時wi的出現使得文本傾向于包含類別ck,x2(wi,ck)值越大,這種傾向性越明顯;當時AD-BC≤0,特征項wi與類別ck呈負相關,此時wi的出現使得文本傾向于包含類別ck以外的標簽,包含類別ck的傾向性則為最小值0。因此,將特征項wi與類別ck的正負相關性考慮進去,將式(2)變換為如下所示:
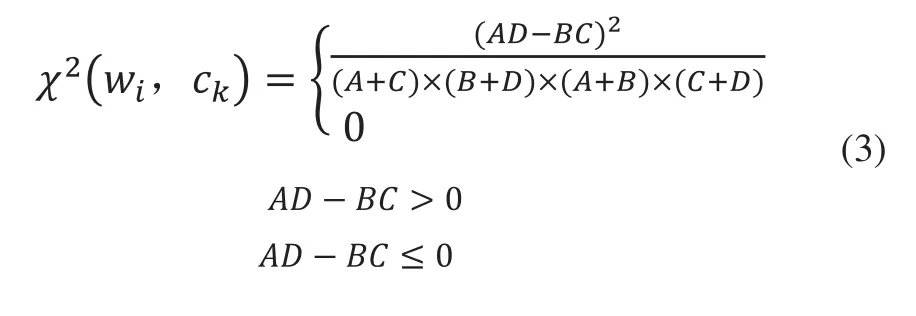
式(3)中,x2(wi,ck)取值范圍為[0,1],對于多類問題,通常首先計算特征項wi對于每個類別的x2統計值,將其表示為x2統計列向量x2(wi)=(x2(wi,c1),…,x2(wi,ck),…,x2(wi,cm)),m為數據集的類別標簽總數,然后取列向量x2(wi)中值最大的元素作為特征項wi的x2統計值x2(wi)value,即:
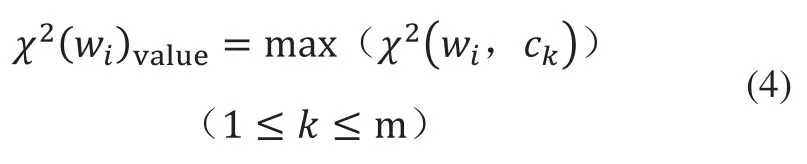
確定排名閾值α,將所有特征項的x2統計值x2(wi)value按降序排列,選擇排名為α和α之前的特征項用于表示文本,則文本表示特征項集合為W'=(w1',w2',…,wi',…,wα')。
對于機械制造領域文本,由于數據集樣本數量有限,有些詞匯只是集中出現在某一類別的少量文本中,根據式(3)可知,這些詞匯的x2統計值較小,與文本類別的相關度較小。然而根據經驗,這類詞匯很可能包含領域知識,與某類別相關度較大,有助于文本分類。除此之外,還有一些專業詞匯未出現在數據集中,一般這些詞匯不會作為文本表示特征項,然而當待分類文本包含這些特征項并且這些特征項包含領域知識時,這些詞匯能夠有效地的區分文本類別。基于此,本文提出一種融合領域知識的特征選擇方法,在x2統計方法的基礎上融合領域知識選擇出有助于文本分類的特征項,領域知識的融合主要體現在以下兩個方面:
1)修改出現在數據集中的特征項的x2統計值列向量x2(wi)。對于那些出現在數據集中,并且包含領域知識的特征項,根據經驗修改該特征項的x2統計值列向量x2(wi),向量中每個元素的取值范圍為[0,1],值越大表示特征項與某類別的相關程度越大;
2)增加未出現在數據集中,但是包含領域知識的特征項。根據經驗構造這些特征項的x2統計值列向量x2(wi),向量中每個元素的取值范圍為[0,1],值越大表示特征項與某類別的相關程度越大;
最后,根據閾值α得到表示文本的特征項集合W=(w1,w2,…,wi,…,wα),集合W中的每一個特征項對應一個x2統計列向量x2(wi),這些列向量形成了一個相關度矩陣R=(x2(w1),x2(w2),…,x2(wi),…,x2(wα)),R反映了各特征項與類別的相關度。與x2統計方法相比,融合領域知識的特征選擇方法增加和修正了特征項的x2統計向量,從而更加準確的反映了特征項與各類別的相關度,有助于區分文本的類別。
1.2多標簽分類方法
領域知識一般將特征項與文本的類別關聯起來,因此本文提出融合領域知識的多標簽分類方法基本思想是將文本是否包含類別標簽ck這一事件和文本與類別ck的相關度關聯起來,根據最大化后驗概率推理文本是否包含類別標簽ck。
首先引入相關符號和定義:給定文本X及對應的類別向量C(X)。文本X表示為向量X=(x1,x2,…,xi,…,xα),xi對應特征項集合W中的一個特征項wi,表示wi在文本X中出現的頻率;C={c1,c2,…,ci,…,cm}表示數據集的類別標簽集合;C(X)=(C(X,c1),C(X,c2),…,C(X,ci),…C(X,cm))表示文本X的類別向量,類別標簽ci對應C(X,ci),如果文本包含標簽ci則C(X,ci)=1,否則C(X,ci)=0;ξ(X,ck)表示文本X與類別ck的相關度。
1.2.1相關度計算
本文將文本X與類別ck的相關度看作是各特征項與類別ck的相關度的集聚,那么ξ(X,ck)的計算方法可由式(5)表示:
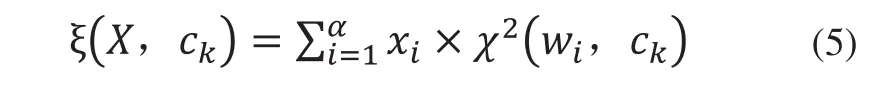
其中xi表示特征項wi在文本X中出現的頻率,x2(wi,ck)表示特征項wi與類別ck的相關度。由上文可知,x2(wi,ck)是相關度矩陣R中的一個元素,根據式(3)計算或經驗知識確定。
對于不同的文本,由于其篇幅的不同,文本中各特征項的頻率具有較大的差異,由式(5)可知,包含類別標簽ck的不同文本與類別ck的相關度差異較大。本文引入類別相關度貢獻率δ(X,ck)這一定義,將文本與類別ck的相關度歸一化處理,用來衡量不同的文本與各類別相關度的大小,其計算方法如下:
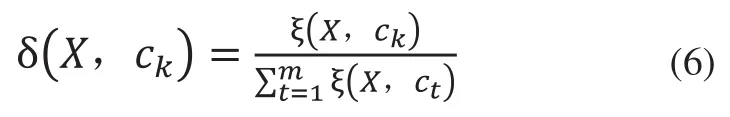
其中ξ(X,ck)表示文本X與類別ck的相關度,表示文本X與各類別標簽的相關度之和。δ(X,ck)的取值范圍是[0,1],δ(X,ck)越大,文本包含類別標簽ck的概率越大,否則文本包含類別標簽ck的概率越小。
1.2.2多標簽分類

根據貝葉斯法則可得:
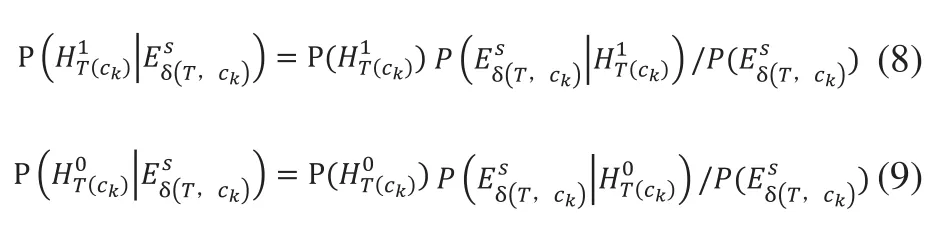

其中N表示訓練集文本數量總和,N(ck)表示包含標簽ck的文本數量,N'(ck)表示不包含標簽ck的文本數量,N(ck,s)表示包含類別標簽ck且類別ck相關度貢獻率小于s的文本數量,N'(ck,s)表示不包含類別標簽ck且與類別ck相關度貢獻率大于或等于s的文本數量。
根據上述分析,融合領域知識的多標簽文本分類方法的具體實現步驟可由圖1表示。
2 實驗結果與分析
為了驗證分類方法的有效性,實驗中建立制造領域數據集作為實驗庫,該數據集包含六個類別:材料工程,動力學,機構,機器人,儀器科學與技術和制造科學與技術。語料庫中總共有970個樣本,其中約10%的樣本包含多個類別標簽。
本文將MLKNN作為對比算法,采用多標簽文本分類中常用的3個評測指標[9](漢明損失,準確率,召回率)比較兩種分類方法在制造領域文本數據集上的性能。漢明損失考察的是文本預測分類結果與實際分類結果的差異,評估了預測標簽錯誤的次數;準確率考察的是文本預測標簽屬于文本實際標簽的情況,評估了預測標簽的平均準確度;召回率考察的是文本預測分類結果與實際分類結果相符的情況,評估了預測標簽的平均查全率。

圖1 融合領域知識的多標簽文本分類算法
【】【】
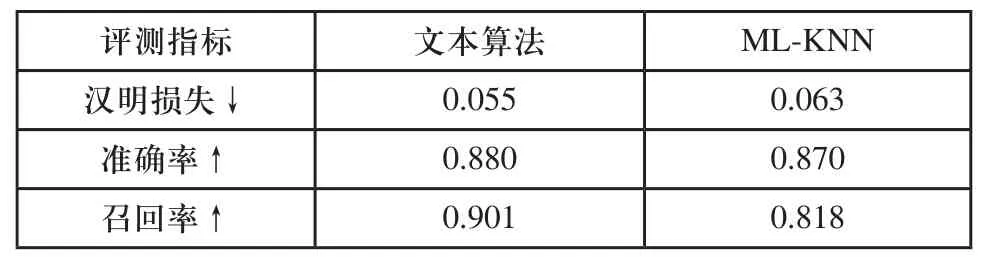
表1 本文方法與MLKNN性能比較
由表1可以看出,對于評測指標漢明損失、準確率和召回率,與MLKNN相比,本文方法具有較明顯的優勢。因此,本文提出的融合領域知識的多標簽文本分類方法對于制造領域文本具有較好的分類性能。
3 結論
機械制造領域存在大量的領域知識,這些領域知識將特征項與文本類別關聯起來,有助于區分文本的類別,基于此,本文提出了一種融合領域知識的多標簽文本分類方法。該方法將文本是否包含某類別標簽這一事件和文本與該類別的相關度關聯起來,在進行特征選擇時,充分利用已有的領域知識增加和修正衡量特征項與類別相關程度的x2統計向量,從而選擇出更為準確,具有代表性的特征項表示文本。實驗結果表明,與MLKNN多標簽文本分類方法比較,對于機械制造領域文本,本文方法的總體分類性能更優。
[1] 周浩.中文多標簽文本分類算法研究[D].上海交通大學,2014.
[2] Tsoumakas G,Katakis I,VlahavasI.Mining Multi-label Data. Data Mining and Knowledge Discovery Handbook[M]. Maimon O, RokachL.2nd ed.Springer,2010:667-685.
[3] Zhang Minling, Zhou Zhihua. ML-kNN:A lazy learning approach to multi-label learning[J].Pattern Recognition,2007(7):2038-2048.
[4] 張敏靈.一種新型多標記懶惰學習算法[J].計算機研究與發展,2012,11:2271-2282.
[5] Ruben Nicolas,Andreu Sancho-Asensio, ElisabetGolobardes, Albert Fornells, Albert Orriols-Puig, Multi-label classification based on analog reasoning[J].Expert Systems with Applications, 2013(40):5924-5931.
[6] Everton AlvaresCherman.Lazy Multi-label Learning Algorithms Based on Mutuality Strategies[J].Intell Robot Syst,2014(10):1007-1022.
[7] 朱靖波,陳文亮.基于領域知識的文本分類[J].東北大學學報,2005,08:733-735.
[8] 龐觀松,蔣盛益.文本自動分類技術研究綜述[J].情報理論與實踐,2012,02:123-128.
[9] Tsoumakas G.Multi-label classification[J].International Journal of Data Warehousing&Mining ,2007(3):1-13.
A multi-label classification method for manufacturing-text
YANG Ying, WANG Qing-wen
TP391.1
A
1009-0134(2016)02-0010-05
2015-10-14
國家科技重大專項:漢川機床采用國產數控系統加工大型機床零件應用示范工程(2012ZX04011-011)
楊瑩(1992 -),女,江西樟樹人,碩士研究生,研究方向為企業信息化。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
