Hadoop云計算平臺的參數優化算法
2016-11-29 02:56:02王春梅胡玉平易葉青
華中師范大學學報(自然科學版) 2016年2期
王春梅, 胡玉平, 易葉青
(1.廣東金融學院 互聯網金融與信息工程系, 廣州 510521; 2.廣東財經大學 信息學院, 廣州 510320; 3.湖南人文科技學院 信息科學與工程系, 湖南 婁底 417000)
?
Hadoop云計算平臺的參數優化算法
王春梅1*, 胡玉平2, 易葉青3
(1.廣東金融學院 互聯網金融與信息工程系, 廣州 510521; 2.廣東財經大學 信息學院, 廣州 510320; 3.湖南人文科技學院 信息科學與工程系, 湖南 婁底 417000)
為提高Hadoop云計算平臺的性能,該文提出了一種跨層的參數優化模型.首先分析了云計算平臺的工作流程,將系統參數與流程對應,并加入基礎設施即服務與平臺即服務層的參數,找出對Hadoop集群效率作用顯著的參數,并把這些參數值作為性能參數,構建成性能參數模型,再用啟發式蟻群算法搜尋性能較優的可行參數,并不斷修正,找出最佳參數組合,最后整合跨層的參數來提高Hadoop云計算平臺的性能.實驗表明,該算法可行,性能優良.
Hadoop云計算; 參數最優化; 蟻群優化算法; 虛擬機
Hadoop是Apache基金組織下的一個開源的可運行于大規模集群上的分布式并行編程框架,搭建Hadoop云計算平臺進行海量數據存儲是目前最為廣泛應用的開源云計算軟件平臺[1-2].Hadoop云計算平臺的系統參數配置,直接關系到系統資源的利用情況,性能參數值的合理設定對Hadoop云計算平臺的工作性能具有重要的作用[3].但現在多數Hadoop集群系統對參數的設置都過于簡單,通常在集群安裝配置時,采用默認配置或手動修改部分配置的方式.由于Hadoop集群工作系統提供200多個可調的參數,這些參數直接影響集群的工作效率,但并不是所有的參數對Hadoop集群效率作用顯著[3-5].調整對效率有顯著作用的參數,可縮短作業執行時間,提高吞吐量,減少I/O或網絡傳輸成本,因此合理配置這些參數是集群工作性能提升的重要保障.
Hadoop集群系統的參數影響是復雜且聯動,改變某個參數的值可減少某部分的成本,但也可能增加其它部分的成本.因此很多學者一直不斷研究.代棟等[6]利用模糊邏輯規則對集群參數進行自動配置,該方法主要考慮集群中節點的異構,并沒有對集群任務做出明確的分析.Herodotou等[7]先建立一個參數空間,然后使用搜尋算法來找出最佳化參數配置來滿足目標函數,由于挑選出整體最佳化參數配置是相當消耗時間,而且沒有明確目標函數來尋找參數空間,導致搜尋效果不佳.Lin等[8]結合參數調整的經驗和登山算法來配置,但效果不是非常理想.
本文提出一種跨基礎設施即服務(Infrastructure as a Service,IaaS)層、平臺即服務(Platform as a Service,PaaS)層和軟件即服務(Software as a Service,SaaS)層的跨層式參數優化模型,并使用蟻群算法串接IaaS層、PaaS層、SaaS層的優化方法,來提高Hadoop云計算的系統性能.實驗表明本算法可行,性能優越.
1 跨層式參數優化模型
跨層式參數優化模型的結構如圖1.先通過收集到的性能參數建立性能模型,再利用模型所產生的值,通過蟻群優化(Ant Colony Optimization,ACO)算法[9]搜尋最佳參數組合,最后使用跨層蟻群算法(C-ACS)整合跨層的參數,來改善Hadoop云計算平臺的性能.

圖1 跨層參數優化模型流程圖
Fig.1 Flow chart of cross-layer parameter optimization mode
1.1 跨層效率參數
本文主要是搜尋那些參數會直接或間接對工作效率有影響,因Hadoop集群工作系統有200多種可調的配置參數,經過一些學者研究,其中大約有20多個對Hadoop集群效率作用顯著[1],以這些參數為依據建立性能模型,并加入跨層的性能參數,讓啟發式蟻群算法(ACS)在搜尋參數最佳組合時,可以有更好的參數選擇來提升云計算平臺的性能.Hadoop集群工作系統的運行架構如圖2.
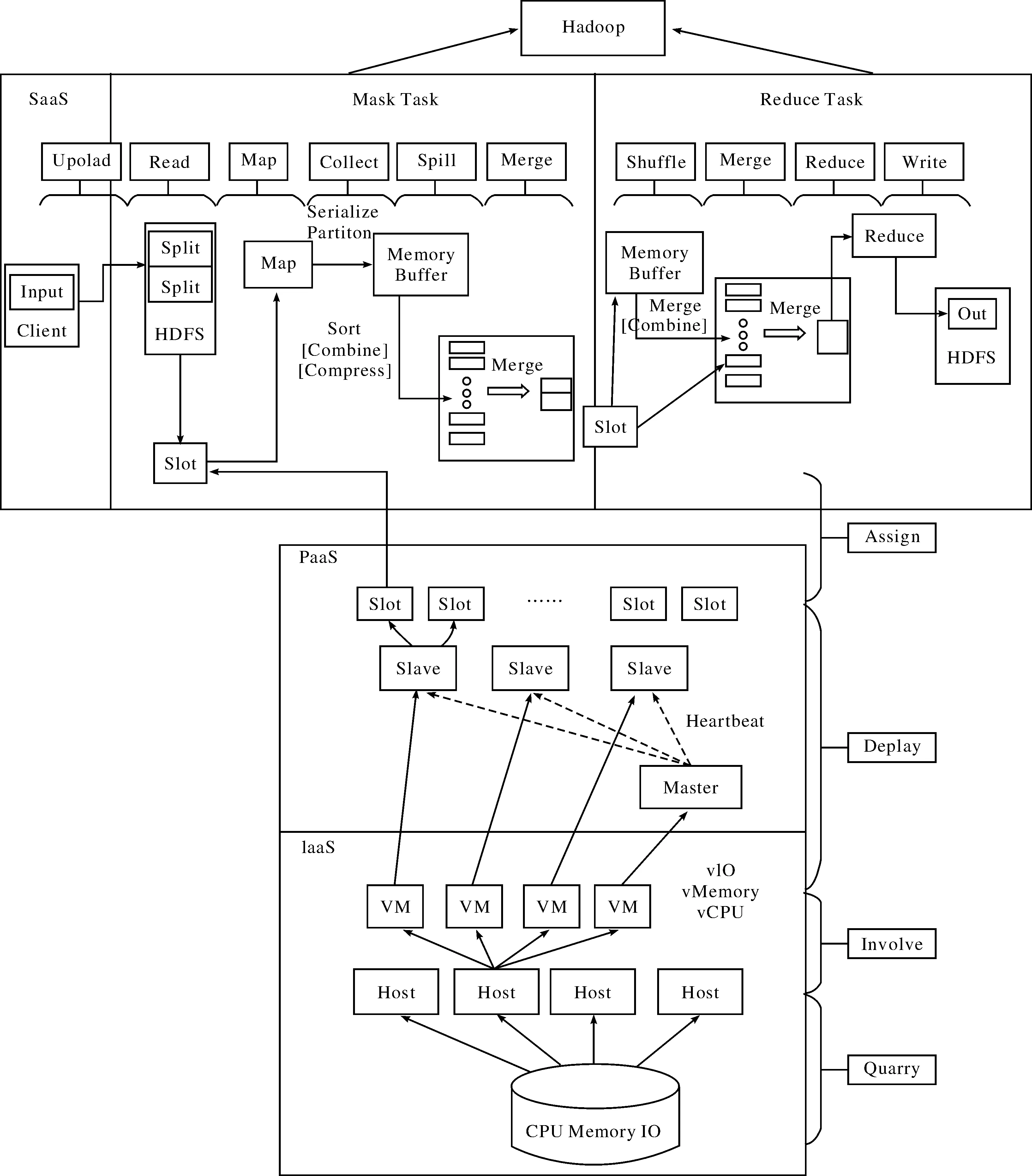
圖2 Hadoop集群工作系統運行架構示意圖Fig.2 Diagram of Hadoop cluster operating system
(I) SaaS層
Hadoop云計算平臺的SaaS層運行MapReduce的應用程序,一開始從Client端將需要運算的輸入數據上傳到HDFS分布式文件系統,HDFS將上傳的數據分割成Block.然后Block按照鍵值對存儲在HDFS上,并將鍵值對的映射存到內存中.MapReduce框架主要包括Map和Reduce兩個階段,每個階段都會有各自的任務(MapTask、ReduceTask),在Map階段,每個MapTask讀取一個block,并調用map()函數進行處理,將結果寫到本地磁盤上;在Reduce階段,每個ReduceTask從MapTask所在節點上讀取數據,調用reduce()函數進行數據處理,并將最終結果寫到HDFS.
SaaS層的性能參數主要是改善MapReduce執行Job時的參數,可分為三大類:Job整體性能參數、MapTask性能參數、ReduceTask性能參數.這三大類參數可能直接影響系統的效率,可以通過修改/etc/Hadoop/conf文檔來調整系統性能.SaaS層Job整體性能參數如表1.
SaaS層中MapReduce的參數歸納為兩部分,一個是Map端的性能參數,另一個是Reduce端的性能參數.由于這兩部分沒明確的定義,所以需通過搜尋參數的方式,來找出最佳參數的組合.

表1 SaaS層Job整體性能參數
(II) PaaS層
除考慮SaaS層的性能參數外,還得考慮到PaaS層的參數,Hadoop云計算平臺的PaaS層有Master節點和Slave節點,Master節點是主要控制節點,用來指派工作任務給工作節點Slave,Slave節點通過不斷的心跳匯報(HeartBeat)來和Master通信,可以讓Master節點知道那些Slave節點可以使用,那些已經失效,這樣可以避免將工作任務指派給失效的節點上,導致任務失敗.PaaS層性能參數如表2.

表2 PaaS層性能參數
(III) Iaas層
Hadoop云計算平臺的基礎設在Iaas層上,將硬件資源分配給虛擬機(VM),每一臺VM就會得到虛擬的硬件資源(vCPU、vIO、vMemory).IaaS層性能參數(Host參數)有:nHostr(Host的數量)、hCPU(Host的CPU能力)、hMemory(Host的內存大小)、hIO(Host的IO能力),IaaS層性能參數(VM參數)有nVM(VM的數量)、vCPU(VM的CPU能力)、vmemory(VM的內存大小)、vIO(VM的IO能力).
有了這些性能參數之后,就可以將這些參數建立性能參數模型,找出相對應的關系.
1.2 性能參數模型
通過找出的性能參數與Hadoop的流程作結合,得出性能模型如公式(1).
T=TSetup+TMap+TReduce+TCleanup,
(1)
其中,TSetup為程序啟動基本作業時間,TMap為Map階段作業執行時間,TReduce為Reduce階段作業執行時間,TCleanup為結束程序的基本作業執行時間.
性能模型找出性能參數之間的關系,通過這樣的關系,找出3層參數對CPU、Memory、IO之間的性能模型:
1) 運算能力CPU
每個VM的運算能力vCPUN不一定會一樣,將這些vCPUN加總,就得到Host的運算能力hCPU,如公式(2).
(2)
其中,k為VM的個數.vCPU為VM的CPU能力.
而Slot的運算能力sCPUN是由VM的運算能力vCPUN除以Slot的數量nSlot,如公式(3).
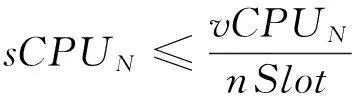
(3)
2) 內存大小Memory
Host的內存大小計算如公式(4).
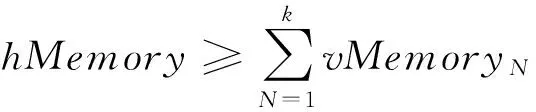
(4)
VM的內存大小vMemoryN如公式(5).
vMemoryN≥mapred.child.java.opts*
(nMapSlot+nReduceSlot)+io.sort.mb+
mDataNode+mTracker+mOS,
(5)
其中,mapred.child.java.opts為JVM的大小,nMapSlot和nReduceSlot分別是Map和Reduce所使用的Slot數量,io.sort.mb為緩沖區的大小,mDataNode為啟動DataNode的基本內存開銷,mTracker為啟動TaskTracker的基本內存開銷,mOS為操作系統的基本開銷.
3) 磁盤IO
磁盤IO的計算如公式(6).

(6)
IO的模型主要是減輕IO的壓力,計算如公式(7).
vION=MapOutput+Intermediate+
ReduceOutput.
(7)
通過定義出來的參數性能模型,讓蟻群算法搜尋滿足上述各層的性能需求的參數解.
1.3 參數優化模型的ACS
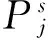

(8)
其中,Tj為調整參數后的執行時間成本,Tj-1為調整參數前的執行時間成本.
然后確定Hadoop參數配置,假設給定n個候選參數值i∈I,要選m個最佳參數值j∈J,可使用一個變量xij(變量xij表示最佳參數j是否選取候選參數值i),目標是使執行時間最小化,如公式(9).

(9)

期望值ηi,j的計算如公式(10),如果F的值越大,期望值就越小,反之F值越小,就會對蟻群的吸引力越大,也就是說當執行時間越少,蟻群越容易找到這個參數組合.
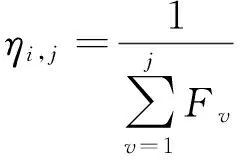
(10)
依照公式(11)和公式(12)可以判斷蟻群是否要選取這個參數.
i=
(11)

(12)
AS在進行整體信息素更新時,是以每只螞蟻的表現進行更新的,ACS的更新方式如下:
整體信息素計算公式如公式(13).
τi,j(t)=(1-ρg)τi,j(t-1)+ρΔτi,j,
(13)
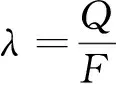
ACS在每一只螞蟻尋找一個可行解(可能參數值)的過程中,每經過一個邊(i,j),即對該邊做一次信息素更新,以避免其它螞蟻收斂在局部解,并增加路徑尋找的多樣性,其更新方式如公式(14).
τi,j(t)=(1-ρl)τi,j(t-1)+ρl·τ0.
(14)
1.4 參數優化模型的C-ACS
在跨層的參數優化模型中將PaaS與IaaS的影響也考慮進來,SaaS層采用ACS的方法,而Paas層的影響則采用跨層的方法C-ACS.跨層參數優化模型的架構圖如圖3.
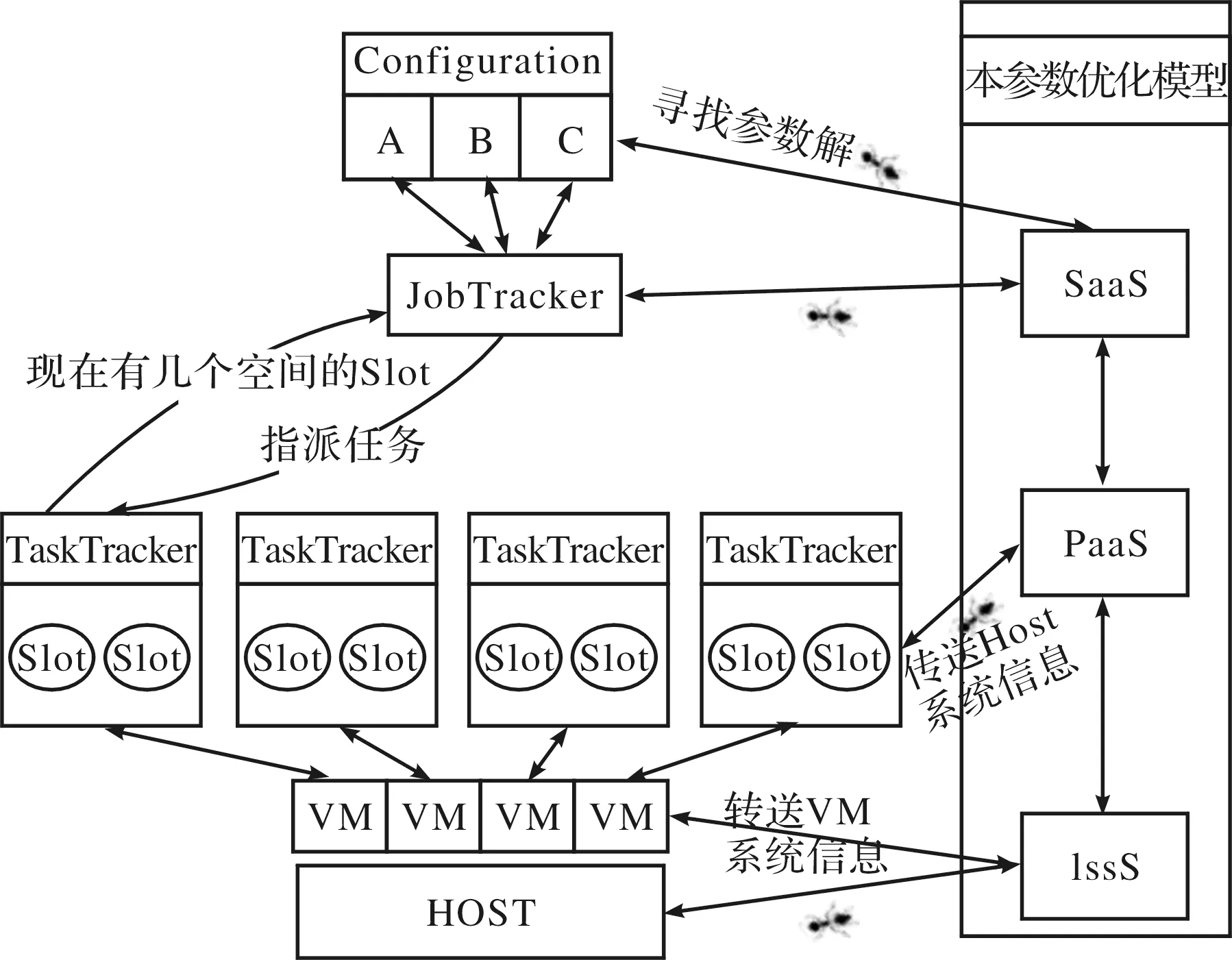
圖3 跨層參數優化模型的架構圖Fig.3 Structure diagram of cross-layer parameter optimization model
跨層參數優化模型的運作流程:1)SaaS層優化:執行Hadoop的Job的調教,一開始執行能被調整的參數,取得每個參數對應的執行時間,將需要調整的參數的執行時間作為路徑,執行時間越短的幾率越高,越會被蟻群尋找到,從而搜尋到該時刻最佳的參數組合.2)Paas層優化:在運行中遇到VM繁忙時,本優化模型會依照那個VM具有空閑的能力,將他暫時加入;遇到Host都很忙碌時,可以將VM從別的Host取得.3)IaaS層優化:一開始本模型會去建立一個VM,并跑一個Job,得到執行時間,通過這個執行時間,評估出在一臺Host上需建立多少個VM.4)通過一開始IaaS層優化,到PaaS層優化,以及最后的SaaS層優化,來構建本參數優化模型.
1.4.1 跨層優化的目標函數
1) SaaS層優化的目標函數
SaaS層優化的目標函數如公式(15).
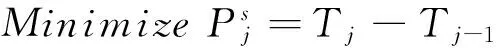
(15)
2) PaaS層優化的目標函數
執行過程中當遇到節點突然壞死的情況,如果節點心跳一直沒有回傳回來,就會被加到這一次的Job的黑名單,這時需動態啟動一個節點來支援運算,對于實體機可能無法那么快的新增節點,但對于虛擬機可以快速啟動節點,并加入到集群中.本模型利用跨層的ACS執行搜尋實體機上是否還有空閑的資源可以利用,能利用的資源越多,對跨層的ACS吸引力就越大,如果要啟動節點的話,會在信息素最多的實體機上建立虛擬機,來加入到集群中.
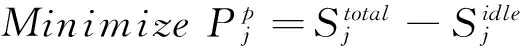
(16)
3) IaaS層優化的目標函數
現在的研究大部分注重在應用層的參數調整上,所以一開始建立集群環境時,就沒特別最優化.本優化模型通過跨層ACS來進行搜尋最佳的虛擬機搭配實體機的方式.一開始通過建立虛擬機并執行Job得到執行效率,建立蟻群初始值,讓蟻群尋找出最佳的實體機與虛擬機的搭配方式,最后產生出環境最佳組合,來組成虛擬機集群.
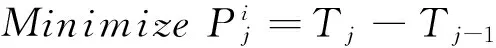
(17)
其中,Tj為調整虛擬機數量后的執行時間成本,Tj-1為調整虛擬機數量前的執行時間成本.
1.4.2 跨層目標函數F(x) 跨層的目標函數如公式(18).
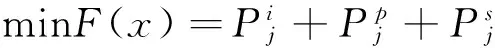
(18)
讓ACS通過搜尋方式,可以找到最小的目標函數F(x),從而達到跨層優化目標,相對單一層的目標函數,跨層的目標函數給定更多的參數選擇.
2 仿真實驗結果與分析
建立一個虛擬Hadoop集群,服務器配置:CPU為Intel Xeon E5-2690W,內存32GB,硬盤2TB 7.2K RPM;軟件配置是:OS為Linux CentOS6.5-64bit,Hadoop版本為Hadoop2.2.0,Java版本為Sun JDK 6u45.6個虛擬節點的參數如表3.

表3 6個虛擬節點的參數情況
選一臺虛擬機同時作為Namenode和JobTracker,稱為主節點,其余虛擬機同時充當DataNode和TaskTracker,稱為從屬節點.本文使用WordCount和Terasort來模擬實際的負載情況,WordCount主要測試CPU,Terasort主要測試IO.使用TeraGen這個測試工具,產生1G的文本文件,作為輸入的數據集.
2.1 參數最佳化組合結果
在執行蟻群算法時,使用劉彥鵬[10]的方法先初始化,把初始值τ0設為0.006 944,信息素衰落參數(ρ)設為0.9,蟻群數量(S)設為3,α=1,β=2,執行時間T=3,Q=100.實驗得到的最優化參數如表4.
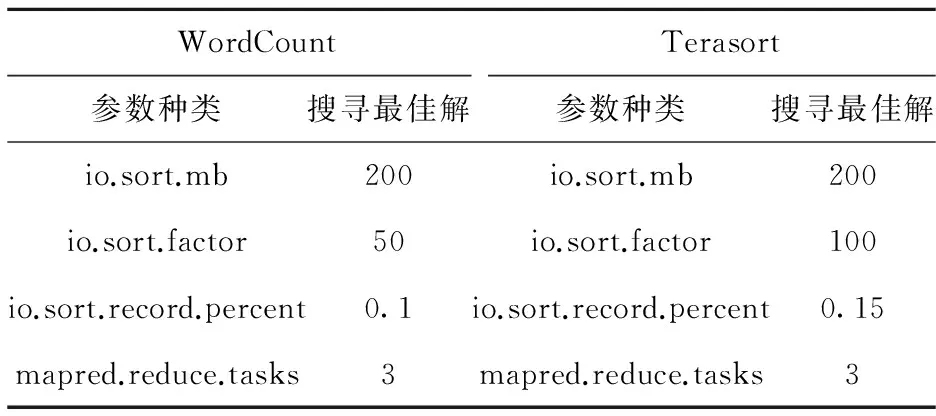
表4 實驗得到算法的最優化參數
執行效率比較如圖4.從圖中可看出,其模型比登山算法和系統默認的都要好,這是由于登山算法被限制在所設定的范圍內進行搜索,所以當范圍設置不當時,只能找到設定范圍內較佳參數解.而本文的方法通過探索的方式,找到設定范圍外的可用解.
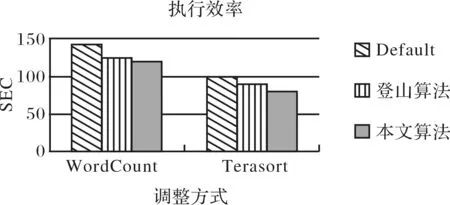
圖4 執行時間比較Fig.4 Comparison of executive time
2.2 節點失效情況
節點突然失效時的實驗結果如圖5.從實驗結果可看出,Default在節點失效時時間花費較多,這是由于節點失效時,Default的狀態是用剩余的節點去完成運算,但它還會嘗試失效的節點,這時將去做加入一個節點動作,當新的節點進入Hadoop集群時,會遇到要將數據傳輸到這個節點上做運算,所以會多花費一些傳輸的時間.
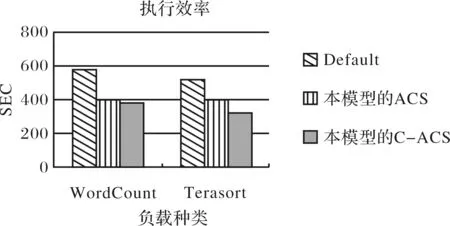
圖5 節點失效情況下執行的效率對比Fig.5 Efficiency comparison of the execution in the case of node failure
2.3 與Starfish方法比較
本實驗使用Herodotou[7]的方法進行比較,兩種方法最佳化參數組合比較如表5.

表5 最佳化參數組合比較
與Herodotou[7]的方法進行比較,Wordcount與Terasort執行的效率差異如圖6.從圖可以看出本文的算法效果明顯.這主要是Herodotou的方法主要根據經驗來配置部分參數.
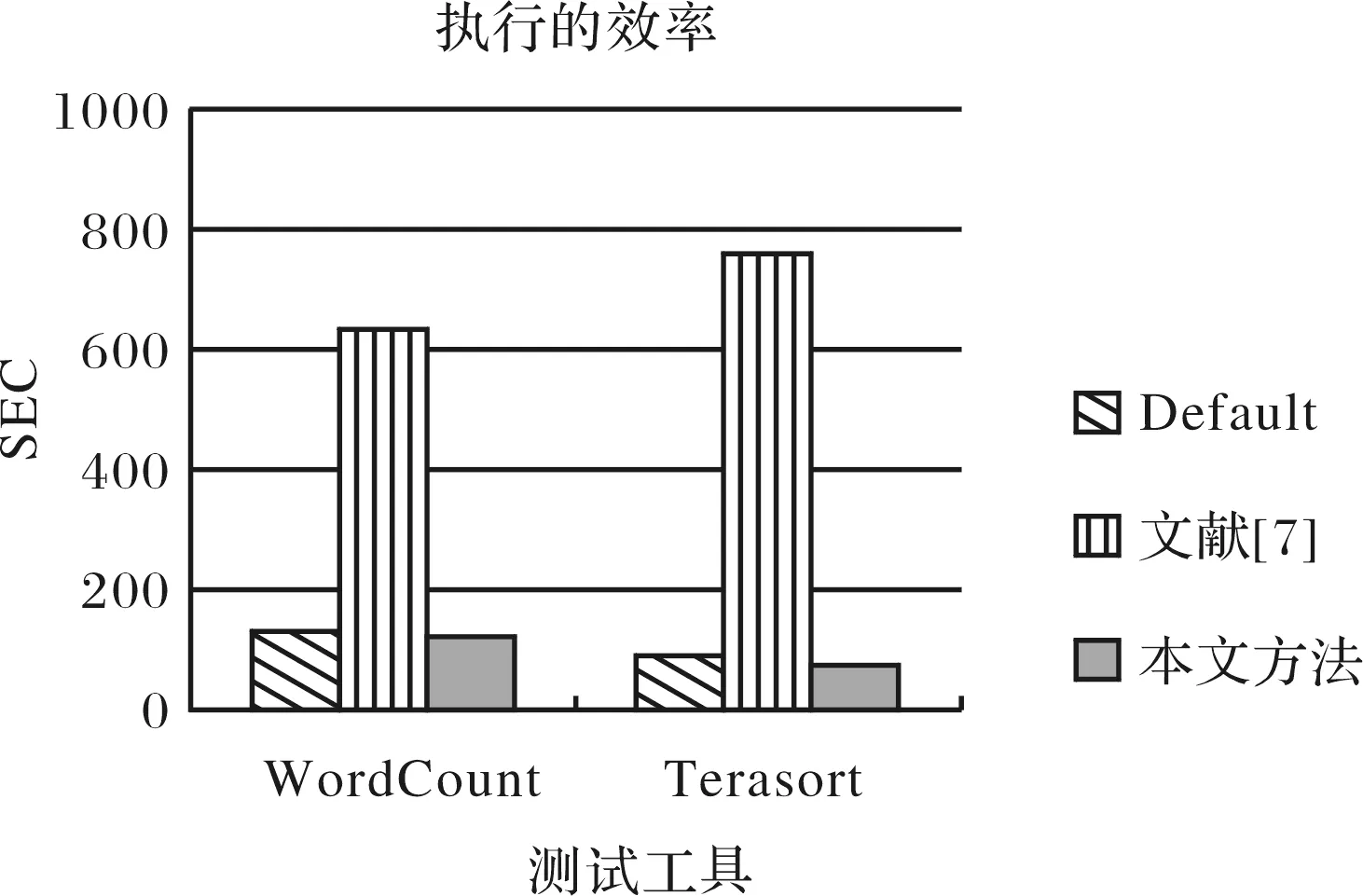
圖6 執行的效率差異Fig.6 Difference of the execution efficiency
3 結束語
本文研究目標是希望提高Hadoop云計算平臺的性能,首先將Hadoop集群系統中使用到的參數歸納出來,分析云計算的工作流程中的參數,將參數與流程一一對應,并加入IaaS層和PaaS層參數,來找出那些參數值可以作為性能參數,并把性能參數建立性能模型,用啟發式蟻群算法搜尋出執行時間中最佳可行參數,并不斷修正,找出最佳參數組合.仿真實驗表明跨層改善的方式比單一Hadoop層的改善,更具有彈性,性能的改善更好.未來的研究希望可以通過自動化的過程讓虛擬機通過跨層優化的方式,建立虛擬集群,讓蟻群找到最佳參數組合,來改善Hadoop集群性能,同時還可以使用數據挖掘的算法來分析Job的特征,建立分類模型,當Job要最佳化時,可以有特征值來進行比對,這樣能使整個系統性能更優越.
[1] 林 利, 石文昌. 構建云計算平臺的開源軟件綜述[J].計算機科學, 2012, 39(11):1-7.
[2] DEAN J,GHEMAWAT S. Map reduce:a flexible data processingtool[J].Communications of the ACM, 2010, 53(1): 72-77.
[3] 項 明. Hadoop集群系統性能優化的研究[D].大連:遼寧師范大學,2013.
[4] LEE G,CHUNB G, KATZ R H. Embracing heterogeneity in scheduling mapReduce [EB/OL].[2012-03-26].http://www.cs.berkeley.edu/~agearh/cs267.sp10/files/cs267-gunho.pdf.
[5] MURTHY A C. Speeding up Hadoop[EB/OL]. [2012-03-26].http://developer.yahoo.com/blogs/ydn/posts/2009/09/hadoop-summit-speeding-up-hadoop/.
[6] 代 棟, 周學海, 楊 峰. 一種基于模糊推理的Hadoop異構機群自動配置工具[J].中國科學院研究生院學報, 2011, 28(6):793-798.
[7] HERODOTOU H, HAROLD L, GANG L, et al. Starfish: a self-tuning system for big data analytic[C]//Proc. 5th Biennial Conference on Innovative Data Systems Research. USA:CIDR, 2011: 261-272.
[8] LIN X, TANG W, WANG K. Predator—an experience guided configuration optimizer for HadoopMapReduce[C]//In Proceedings of the 2012IEEE 4th International Conference on Cloud Computing Technology and Science. Taiwan: IEEE Press, 2012:419-426.
[9] DORIGO M, GAMBARDELLA L M. Ant colony system: a cooperative learning approach to the traveling salesman problem[J]. IEEE Transactions on Evolutionary Computation, 1997, 1(1):53-66.
[10] 劉彥鵬. 蟻群優化算法的理論研究及其應用[D].杭州:浙江大學,2007.
Cross-layer parameter optimization algorithm for Hadoop cloud computing platform
WANG Chunmei1, HU Yuping2, YI Yeqing3
(1.Department of Internet Finance & Information Engineering, Guangdong University of Finance, Guangzhou 510521; 2.School of Information, Guangdong University of Finance & Economics Guangdong, Guangzhou 510320; 3.Department of Information Science and Engineer, Hunan University of Humanities Science and Technology, Loudi, Hunan 417000)
In order to improve the performance of the Hadoop cloud computing platform, a parameter optimization model is presented for across layer of IaaS, PaaS and SaaS. Firstly, the work flow of cloud computing platform is analyzed, to make the system parameters correspond to the flow. The parameters of IaaS and PaaS layer are added and parameters which significant impact on Hadoop execution time are found. Performance parameter model is formed based on the above parameters and optimized by Heuristic ant colony algorithm. Finally, cross layer parameters are integrated to improve the performance of Hadoop cloud computing platform. Experiments show that the algorithm is feasible and perform well.
Hadoop cloud computing; parameter optimization; ant colony system; virtual machine
2015-12-30.
國家自然科學基金項目(61472135));廣東省科技計劃項目(2014B010102007).
1000-1190(2016)02-0183-07
TP393
A
*E-mail: mei_wangchun@163.com.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
