群體計算中基于博弈論的任務分配策略*
2016-12-13 06:58:16滿君豐劉美博
計算機與數字工程 2016年11期
劉 鳴 彭 成 滿君豐 劉美博 杜 坤
(湖南工業大學計算機與通信學院 株洲 412007)
?
群體計算中基于博弈論的任務分配策略*
劉 鳴 彭 成 滿君豐 劉美博 杜 坤
(湖南工業大學計算機與通信學院 株洲 412007)
大數據的快速發展,推動了社會經濟和科技的發展,但大數據的價值密度低等特點為其發展帶來了挑戰。大數據的這些特點使得大數據迫切需要復雜認知的推理技術,而人機協作的群體計算成為了復雜認知推理技術的有效途徑,但其任務分配策略還尚未完善。盡管已經有學者提出了基于用戶主題感知的任務分配策略,解決了涉及不同專業背景及不同知識水平的任務分配,但并未解決處于同層次知識水平和專業背景的用戶如何分配任務,使得計算效率更高。針對此問題,提出了基于博弈論的任務分配算法,檢測相同專業背景和知識水平的人群完成任務的準確率,與任務隨機分配相比較,突出博弈論算法的準確性。
群體計算; 博弈論; 大數據; 任務分配
Class Number TP301.6
1 引言
隨著大數據的發展與應用,越來越多的研究和應用領域需要用到大數據處理技術,大數據已經逐步滲透到人民生活和社會經濟的方方面面中,在社會發展中起著越來越重要的作用。當前大數據技術的發展已經取得一定的發展,如大數據的大規模性和高速增長性,使得大數據計算任務需要海量的存儲計算技術,近幾年集群如Hadoop集群等的發展很好解決了海量數據的存儲,降低了海量數據的存儲成本,而MapReduce也較好地適應了大數據計算技術。盡管如此,大數據還存在著很多嚴峻的挑戰,如單純的計算技術難以處理形式多樣、價值密度低等的大數據,這就需要研究新的大數據計算任務高度依賴復雜認知推理技術,我們認為基于人機協作的群體計算是解決復雜認知推理的有效途徑。
群體計算[1]在學術界并沒有明確的定義,維基百科給出一種闡述:“群體計算是人群和集群合作的一種模型,以此來處理計算技術難以解決的復雜任務”,即群體計算是以互聯網為平臺,通過合理的體制機制來整合網絡資源和用戶群體資源,協同完成大數據計算任務[2]。群體計算任務往往涉及到不同專業領域的子任務,需要這些子任務進行協同處理,其中一部分子任務涉及到先進的算法和強大的推理能力,并且很多子任務之間存在著復雜的關聯關系[3~4]。這些子任務需要分配給用戶群體協作完成,而由于用戶群體知識水平和專業背景不同,所完成任務的水平也會不同,再加上任務設置者與任務完成者的利益訴求不一樣,所以任務最終的完成質量并不能取得滿意的效果,這就需要一個合理的任務分配策略,將不同領域的任務分配給相應領域的用戶群體處理,從而提高任務完成質量,這就是本文要闡述的基于博弈論的任務分配策略。
博弈論是研究決策主體的行為發生直接相互作用時侯的決策以及這種決策的均衡問題的理論[5]。最初的博弈論應用于經濟學領域[6~7],只是經濟學的分支學科,后來博弈論在有理性行為和非對稱信息的分析發揮了強大作用,迅速成為經濟學的重要組成部分,廣泛應用于政治、經濟等諸多領域,如今在計算機和通信領域也得到了廣泛的應用。在博弈過程中參與者之間能否達成具有約束力的協議可以將博弈分為合作博弈與非合作博弈,而本文主要闡述基于合作博弈的任務分配策略。
2 相關工作
目前,群體計算發展還處于發展的階段,遠沒有達到成熟的地步。現有的群體計算的任務分配結構還比較單一,甚至還存在隨機任務分配,對于任務所屬領域、任務之間的關聯度和任務完成者的網絡使用習慣、教育水平與知識背景等,隨機的任務分配策略并不給予考慮,只是將任務隨機的分配給用戶群體,因而任務難以得到具有專業知識的用戶處理,致使任務完成的質量不能令人滿意,人機協作的群體計算優勢并不能很好地發揮出來。
傳統的眾包平臺便是將任務簡單的隨機分配下去,這種分配方式有其本身的優點,但缺點也是顯而易見,例如填寫病人的病例,如果將這種任務交給不具備醫學背景的人來完成,很難將數千份的病例無誤地輸入到計算機中;2004年天津大學的楊冬等將螞蟻算法進行改進,使得該算法具有正反饋和分布式計算以及全局搜索的能力等特點,但是該算法容易陷入局部極小點的陷阱,而得不到任務分配的最優解[8];2009年沈陽自動化研究所聶明鴻等提出了總體極小任務分配算法,討論將任務如何分配,使完成n個任務所需的代價最小,但其計算量較大,不適合大規模的任務分配[9]。基于以上問題,張曉航和李國良[10]等提出了基于用戶主題感知的任務分配模型。李國良等人對用戶的行為進行了分析和研究,認為用戶的行為具有同質性,即不同用戶的行為被認為提供了同等質量水平的隱式或顯式反饋信息[11~13],設計了一種針對用戶主題的任務分配算法,很好地解決了任務隨機分配的盲從性,并通過分析用戶的歷史任務數據以及明測、暗測任務了解用戶真實的主題分布,很大程度上提高了任務整體的完成質量[14~19]。但針對具有相同教育水平和知識背景的人,如何分配任務使得任務的完成質量較高就是本文需要闡述的基于博弈論的任務分配策略。
3 基于博弈論的任務分配策略
經過第2節了解到博弈論之后,將在本節詳細敘述基于博弈論的任務分配策略。
3.1 合作博弈定義
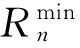
3.2 合作博弈
合作是在合作之后根據收益情況分為本質性合作和非本質性合作,如果合作比非合作的收益多,則此合作博弈是本質性的,若是未增加甚至下降,則此合作博弈是非本質性合作。例如,我國存在一些效率低、收益低的一些商業合作組織可看作是非本質性合作,因為其收益遠低于不合作時的收益。
本章研究了一個復雜任務和用戶群體的聯合分配問題。在群體用戶知識水平和專業背景一致的約束下,同時考慮系統效率和群體用戶間的公平性。基于合作博弈理論,將復雜任務分解成的小任務資源分配問題建模為群體用戶的任務分配議價博弈(Tasks Allocation of Group User Bargaining Game,TAGUBG),提出了一種動態協作的任務分配方案。首先,引入用戶完成該任務之后期望獲得的信息增益以決定分解后的小任務對于不同可信度用戶的分配模式。進而,將同背景、同領域的小任務在不同可信度用戶間動態分配。然后,基于動態任務分配的結果,通過自適應任務分配算法在每個用戶分得的任務上調整任務量和難易程度。在任務分配過程中,TAGUBG實現了效率和公平性的折衷。借助計算機仿真,從復雜任務的切分機制和小任務的選擇以及不同用戶可信度的角度分析了相互作用的理性用戶的決策過程,理論分析與仿真結果證實,與任務隨機分配方案相比較,所提出的TAGUBG方案在任務完成質量、群體用戶間的公平性等方面都得到了改善。其總體思路圖如圖1所示。
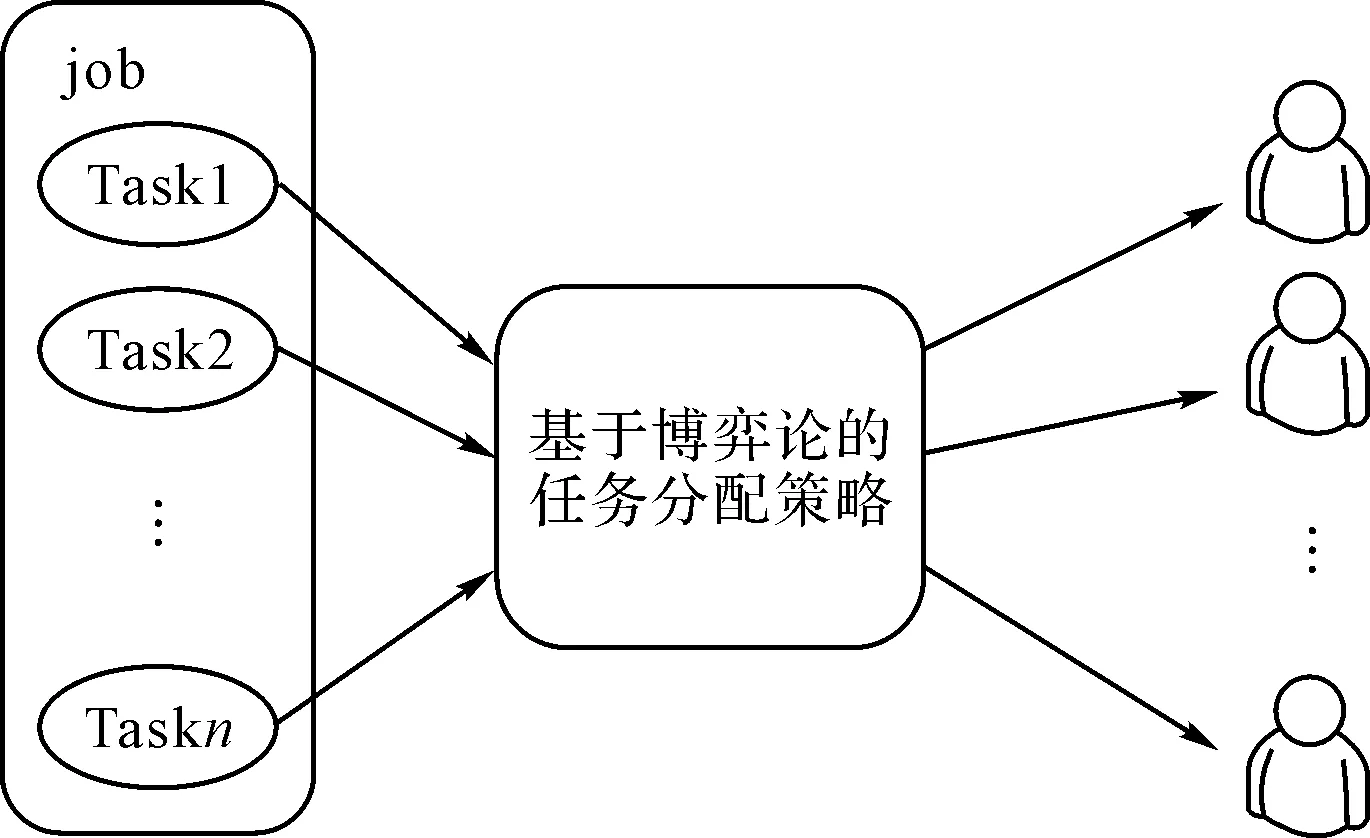
圖1 總體思路圖
為了簡化任務與群體用戶之間的分配,引入等效信息增益G,同時為了在效率和公平性之間取得更好的折衷,對單任務多用戶分配問題建模為
(1)
其中
(2)

(3)
其中,pr(x|θ)表示用戶給出正確答案的概率,pr(x)則表示問題本身得到某一個答案的概率,T表示具有不同合作能力的參與人期望效用的對比。
3.3 博弈論任務分配過程
將自動切分獲得的小任務劃分為相關任務子集和獨立的任務子集,并將它們按照最優利用率進行排序,采用博弈論算法將關聯的小任務分配到同一組中,不關聯的任務則不進行分配。其任務分配算法如下:
輸入:X={x1,x2,…,xn}
輸出:任務分配結果
1.從任務自動切分中獲得g個相關任務子集:X1…Xg
2.FORi=1;g
3.Xk←Highest_UT()//未分配的最大相關子集
4.pk←lowest_Ld(P)//當前負載最小的核pk
5.IFSched(Xk,pk)isTRUE//Xk在pk上可調度
6.Alloc(Xk,pk)//將Xk分配到pk上
7.WHILE?Xi∈(X1…Xg)//存在未分配的任務
8.Xk←Highest_UT()//未分配任務的最大相關子集
9.pk←lowest_Ld(P)//當前負載最小的核pk
10.IF任務自動分配算法返回FAILURE
11.Roll_Back()//取消本次任務分配
12.Taskset_Broken()//將任務分散
13.WHILE?Xi未分配
14.Xλ←Highest_UT()//最大的未分配獨立任務
15.pk←lowest_Load(P)//當前負載最小的核pk
16.IFSched(Xk,pk)isTRUE//分配后可調度17.Alloc(Xk,pk)//將Xk分配到pk上
4 實驗分析
首先通過模擬實驗,在Matlab平臺上驗證基于合作博弈的任務分配算法的效果。模擬實驗過程中,以螞蟻分配算法作為對照實驗,從而體現合作博弈的任務分配算法的優越性。試驗中總的小任務數n=200,這n個任務的主題是一樣的或相似的,選擇的群體用戶的專業水平和背景知識相同或相似,和任務主題相一致,將自動切分的小任務分別按照隨機分配方法和合作博弈的方法分配給用戶群體,用戶群體完成任務的有效性服從gauss(0.8,0.2)分布,假定有20個用戶符合上述條件。
在實驗中,每次分發20個任務,即m=20,因此任務分配一共進行R=10輪。設定三個參數α、β和γ,使α和β的值都為1,γ的初始值為10,在之后的每一輪任務分配中γ的值都減半,使任務的困難程度服從伽瑪函數分布,從beta(x,y)中獲取任務完成的正確率。(x,y)的值分別取(2,1),(6,1)和(10,1),表示任務從易到難的難易程度,(x,y)所取得每一對值都是通過重復200次算法得到的平均值。如圖2所示。

圖2 實驗模擬圖
從圖2中可以看出,兩種分配算法不同,其所對應的用戶完成的任務準確率也不同,縱觀整體,通過博弈論算法將小任務分配給群體用戶所反饋結果的有效性明顯比隨機分配算法要好,隨著x的值越高,其有效性對比越明顯。我們從beta(10,1)中進行采樣,觀察兩種算法所對應任務準確率的變化情況,其結果如圖3所示。
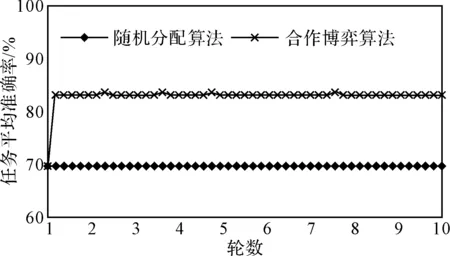
圖3 任務完成的有效性對比
從圖3中可以看出,選擇合作博弈的任務分配算法所得的準確率明顯要比選擇隨機分配算法所得的準確率要高,兩種算法所得的結果都比較平穩,沒有較大的波動性,隨機分配所得的平均準確率基本保持在70%,而合作博弈算法準確率基本穩定在83%左右。由于剛開始并沒有用戶的歷史數據,所以第一輪的平均準確率相同。針對不同的用戶會根據用戶的可信度和歷史完成任務的質量來分配難易度合適的任務,從而提高用戶回答任務的效率和準確率。
5 結語
研究基于博弈論的任務分配策略,對提高群體計算效率與質量有著重要的作用。通過模擬仿真實驗,驗證了博弈論中合作博弈算法的有效性,為群體計算的高效任務分配做出了重要的貢獻。未來群體計算將采用更加靈活的任務分配策略,其中博弈論將在任務分配中發揮更大的作用。如何更好地運用博弈論在任務分配中任務優化分配,還有很多的工作值得研究和探索。
[1] 李國良.人機協作的群體計算[J].中國計算機學會通訊,2015,11(7):20-26. LI Guoliang. Crowd computing of human-machine collaboration[J]. Communications of the China Computer Federation,2015,11(7):20-26.
[2] 劉蔚.協作和感知網絡中基于博弈論的資源分配研究[D].北京:北京郵電大學,2011:101-112. LIU Wei. Research on resource allocation based on Game Theory in the network of cooperation and perception[D]. Beijing: Beijing University of Posts and Telecommunications,2011:101-112.
[3] 李國杰,程學旗.大數據研究:未來科技及經濟社會發展的重大戰略領域-大數據的研究現狀與科學思考[J].中國科學院院刊,2012,27(6):647-657. LI Guojie, CHENG Xueqi. Research status and scientific thinking of big data[J]. Bulletin of Sciences,2012,27(6):647-657.
[4] Wang J. Kraska T, Franklin M J. et al. Crowder:Crowdsourcing entity resolution [J]. Proceedings of the VLDB Endowment, 2012,5(11):1483-1494.
[5] Franklin M J, Kossmann D, Draska T, et al. CrowdDB:Answering queries with crowdsourcing [C]//Proc of the 2011 ACM SIGMOD Int Conf on Management of Data. New York:ACM,2011,8(11):61-72.
[6] Park H, Garcia-Molina H, Pang R, et al. Deco: A system for declarative crowdsourcing [J].Proceedings of the VLDB Endowment,2012,5(12):1900-1993.
[7] 張維迎.博弈淪與信息經濟學[M].上海:上海格致出版社,上海三聯出版社,上海人民出版社,2012:363-380. ZHANG Weiying. Game Theory and Information Economics [M]. Shanghai:Shanghai Gezhi press, Shanghai Sanlian Publishing House, Shanghai people’s Publishing House,2012:363-380.[8] 約翰·F·納什,勞埃德·S·沙普利,約翰·C·海薩尼,萊因哈德·澤爾騰. 諾貝爾經濟學獎獲得者叢書·博弈論經典[M]. 韓松,譯.北京:中國人民大學出版社,2013,12(6):545-559. John F Nash, Lloyd S Shapley, John - C - Harder Selten Harsanyi, Rhine. Nobel Economics Prize Winner Series: Classic Game Theory [M]. Han Song, translation. Beijing: Chinese People’s University Press,2013,12(6):545-559.
[9] 范如國,韓民春.博弈論[M].武漢:武漢大學出版社,2013:360-480. FAN Ruguo, HAN Minchun. Game Theory[M]. Wuhan: WuHan University Press,2013:360-480.
[10] 張曉航,李國良,馮建華.大數據群體計算中用戶主題感知的任務分配[J].計算機研究與發展,2015,52(2):309-317. ZHANG Xiaohang, LI Guoliang, FENG Jianhua. Theme-Aware Task Assignment in Crowd Computing on Big Data[J]. Journal of Computer Research and Development,2015,52(2):309-317.
[11] Karger D R,Oh S, Shah D. Iterative learning for reliable crowdsourcing systems [C]// Advances in Neural Information Processing Systems. La Jolla: NIPS, 2011:1953-1961.
[12] 劉云浩.群智感知計算[J].中國計算機學會通訊,2012,8(10):38-41. LIU Yunhao. Crowd sensing computing[J].Communications of the China Computer Federation,2012,8(10):38-41.
[13] Feng Jianhong, Li Guoliang, Wang Henan et al. Incremental Quality Inference in Crowdsourcing [M]. Database Systems for Advanced Applications. Berlin: Springer,2014:435-467.
[14] Wei Wei,Qi Yong. Information potential fields navigation in wireless Ad-Hoc sensor networks[J]. Sensors,2011,11(5):4794-4807.
[15] Wei W, Xu Q, Wang L, et al. GI/Geom/1 queue based on communication model for mesh networks[J]. International Journal of Communication Systems,2014,27(11):3013-3029.
[16] Wei W, Yang X L, Shen P Y, et al. Holes detection in anisotropic sensornets: Topological methods[J]. International Journal of Distributed Sensor Networks,2012,23(5):233-256.
[17] Song, Houbing, and Maté Brandt-Pearce. “A 2-D discrete-time model of physical impairments in wavelength-division multiplexing systems.” Journal of Lightwave Technology 30.5 ,2012:713-726.
[18] Song, Houbing, and Maté Brandt-Pearce. “Range of influence and impact of physical impairments in long-haul DWDM systems.” Lightwave Technology, Journal of 31.6,2013:846-854.
[19] Song, Houbing, Maite Brandt-Pearce. Model-centric nonlinear equalizer for coherent long-haul fiber-optic communication systems[C]//Global Communications Conference (GLOBECOM),2013,24(8):233-235.
Task Allocation Strategy Based on Game Theory in Group Computing
LIU Ming PENG Cheng MAN Junfeng LIU Meibo DU Kun
(College of Computer and Communication, Hunan University of Technology, Zhuzhou 412007)
The rapid development of big data promotes the progress of economy and technology, but the features, low value density, bring challenges to the big data. These features make that it need urgently complex cognitive reasoning,which is effectively solved by human-machine collaboration based crowd computing.However, crowd computing’s task allocation strategy is not maturity completely.some scholars have come up with a theme-aware task assignment framework, which solves task allocation to different professional background and knowledge level, but it does not deal with task allocation involving same knowledge level and professional background, which makes higher computational efficiency. To deal with this problem, it propose a task allocation algorithm based on game theory, which detects the accuracy with same professional and knowledge level. The task allocation algorithm based on game theory, compared with randomly task allocation, shows the accuracy of game theory algorithm.
crowd computing, game theory, big data, task allocation
2016年5月12日,
2016年6月22日
國家自然科學基金項目(編號:61350011,61379058);湖南省自然科學基金項目(編號:14JJ2115,12JJ2036); 湖南工業大學研究生校級創新基金項目(編號:CX1605);互聯網+環境下協同云制造業務流程監管方法研究(編號:16A059);基于多源大數據融合的裝備健康評估與預測(編號:16B071)資助。
劉鳴,男,碩士研究生,研究方向:大數據和群體。彭成,男,博士,研究方向:軟件工程,大數據分析。滿君豐,男,博士,教授, 碩士生導師,研究方向:可信軟件、軟件工程。劉美博,男,碩士研究生,研究方向:大數據和群體計算。杜坤,男,碩士研究生,研究方向:大數據和群體計算。
TP301.6
10.3969/j.issn.1672-9722.2016.11.010
猜你喜歡
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
