基于Hadoop平臺的個性化新聞推薦系統的設計*
2016-12-21 07:13:59黎偉強
網絡安全與數據管理 2016年23期
韋 靈,黎偉強
(廣西科技大學鹿山學院 電氣與計算機工程系,廣西 柳州 545616)
?
基于Hadoop平臺的個性化新聞推薦系統的設計*
韋 靈,黎偉強
(廣西科技大學鹿山學院 電氣與計算機工程系,廣西 柳州 545616)
為使互聯網用戶快捷地查找所需信息,個性化推薦系統的優勢得到了體現和運用。該系統設計的目的是為廣大網民在瀏覽新聞時提供一個個性化的新聞推薦系統,實現對新聞數據的協同過濾推薦處理。系統利用 Hadoop的MapReduce模型實現并行快速地聚類海量新聞數據,大大提高了數據處理的速度,聚類使得新聞之間的相似度得以體現,再利用不同的協同過濾算法實現個性化的新聞推薦。
Hadoop;MapReduce;聚類;個性化;Mahout
0 引言
隨著互聯網的發展,大量新聞快速涌現,信息嚴重過載,令用戶無從選擇。新聞推薦系統被廣泛應用于解決信息過載問題[1],解決不同人之間關注新聞熱點不一致的問題。新聞是人們生活中必不可少的一部分,如何使人們快速地在每天眾多新聞中找出自己感興趣、想要了解并查看的新聞成為了各大新聞門戶網站的一大難題。快速準確的新聞推薦能節省用戶大量查找自己感興趣的新聞的時間,這能讓用戶得到一個非常好的用戶體驗。大數據的出現標志著人們生活品質的進步,這是社會進化的副產品,它能利用許多常規機器進行海量數據處理。將一個海量數據任務分成需要的小任務,分別發給許多常規機器進行并行處理,然后得出結果,這個過程就像許多常規機器匯聚成為一個超級機器,整個處理過程就像一個機器在處理一樣,這大大降低了數據挖掘的成本,并且在數據量很大時大大減少了計算的時間。在當今時代,無論是新聞門戶網站還是購物網站,無論是醫療方面的還是金融方面的,大數據平臺下的數據挖掘都是現在主流的發展方向。從另一個角度看,大數據的出現不僅幫助人們篩選出了有用的信息,同時還幫人們過濾掉了無用的信息。混合方法彌補了基于內容推薦在多樣性上的不足,但卻帶來了冷啟動問題,在推薦熱點新聞或用戶具有潛在興趣的新聞時,沒有得到足夠點擊的新聞依然無法推薦給目標用戶[2]。目前,國內外學者在新聞推薦領域已展開了一系列研究。參考文獻[3-6]使用了協同過濾的新聞推薦方法,本文提出了基于用戶和物品的協同過濾算法來實現面向不同用戶的個性化新聞內容推薦。
1 協同過濾算法介紹
個性化推薦主要分為協同過濾推薦、基于內容推薦、混合推薦。個性化推薦本質上是把用戶與物品進行聯系,使得用戶能夠發現自己所喜愛的物品,使得物品能夠被所喜歡的用戶所了解[7]。關于協同過濾的一個最典型的例子就是看電影,有時候不知道哪一部電影是我們喜歡的或者評分比較高的,那么通常的做法就是問問周圍的朋友,看看最近有什么好的電影推薦。在詢問時,都習慣于問與自己愛好相似的朋友,這就是協同過濾的核心思想。協同過濾推薦與傳統的基于內容過濾推薦不同,協同過濾分析用戶興趣,在用戶群中找到指定用戶的相似(興趣)用戶,綜合這些相似用戶對某一信息的評價,形成對該指定用戶對此信息的喜好程度預測。協同過濾主要分為基于用戶的協同過濾和基于物品的協同過濾。
1.1 基于用戶的協同過濾算法
俗話說“物以類聚、人以群分”,拿看電影這個例子來說,如果你喜歡《蝙蝠俠》、《碟中諜》、《星際穿越》、《源代碼》等電影,另外有個人也喜歡這類電影,而且他還喜歡《鋼鐵俠》,則很有可能你也喜歡《鋼鐵俠》這部電影。所以說,當一個用戶 A 需要個性化推薦時,可以先找到與他興趣相似的用戶群體 G,然后把 G 喜歡的、并且 A 沒有聽說過的物品推薦給 A,這就是基于用戶的協同過濾算法。
1.2 基于物品的協同過濾算法
基于物品的協同過濾算法(ItemCF)是業界應用最多的算法,主要思想是利用用戶之前有過的行為,給用戶推薦和之前物品類似的物品。依然以電影為例,如果喜歡《蝙蝠俠》的用戶有A、B、C和D,喜歡《碟中諜》的用戶有A、C、D。那么可以認為《蝙蝠俠》和《碟中諜》擁有相似的用戶群體,則很可能B用戶也會喜歡《碟中諜》這部電影,于是推薦《碟中諜》給B用戶。這就是基于物品的協同過濾算法。

圖1 基于用戶的協同過濾算法推薦流程圖
2 協同過濾算法用戶的模型構建
協同過濾算法所需要的數據結構是用戶id+新聞id+評分,為了將數據庫中的數據形成這樣的數據結構,通過查詢新聞表的用戶表來確定所查詢的用戶是否在其中,然后得到該用戶瀏覽過的所有新聞id,最后對該新聞的喜愛程度進行預測。根據式(1)計算出Preference喜好值,其中Preference為預測的結果,ct為新聞聚類結果簇的個數,cn為當前新聞所在簇的新聞個數,unt為當前用戶瀏覽過的新聞總數,nct為該新聞的瀏覽數。
(1)
基于用戶的協同過濾推薦流程圖如圖1所示。當啟動基于用戶的協同過濾算法引擎后,指定一個用戶為其推薦,系統將查詢數據庫中該用戶瀏覽過的所有新聞,根據新聞中用戶表查詢瀏覽過的該新聞的相關用戶,然后構建協同過濾算法用戶的模型。整個過程封裝在MyRecommender類的UserRecommender方法中,而在UserRecommender中封裝了數據庫的一系列查詢方法與協同過濾算法的調用,通過基于用戶的協同過濾算法計算出應該為其推薦的新聞。
3 協同過濾算法物品的模型構建
首先,以具有相同標題的新聞作為查詢語句的分組條件,查詢出每一個新聞標題下都有哪些用戶訪問過,根據查詢到的結果形成該新聞未訪問過的推薦用戶列表。另外系統將會查詢出瀏覽過該新聞的用戶并構建瀏覽用戶列表,并直觀顯示在分析后的推薦列表中,同時根據用戶瀏覽的新聞分類的不同比重,推薦結果顯示時,根據比重做相關的排序,把用戶最關注的那類新聞排在最前面,以此來做推薦排序。基于物品的協同過濾利用式(2)計算:
(2)
其算法流程圖如圖2所示。

圖2 基于物品的協同過濾算法推薦流程圖
基于物品的協同過濾推薦,當啟動基于物品的協同過濾算法引擎后,指定一個用戶為其推薦,系統將查詢數據庫中該用戶瀏覽過的所有新聞,根據新聞中用戶表查詢瀏覽過該新聞的相關用戶,然后構建協同過濾算法用戶的模型。整個過程封裝在MyRecommender類的ItemRecommender方法中,而在ItemRecommender中封裝了數據庫的一些查詢方法和協同過濾算法的調用,通過基于物品的協同過濾算法計算出應該推薦的新聞。
4 個性化新聞推薦系統實現
基于Hadoop平臺聚類算法的個性化新聞推薦系統,其目的是為讓廣大網民在瀏覽新聞時,為其提供一個個性化的新聞推薦系統。大量的信息使得用戶找到自己需要的信息變得很困難。為了使互聯網用戶快捷地查找所需信息,個性化推薦系統的優勢得到了體現,本文利用 Hadoop的MapReduce模型實現并行快速地聚類海量新聞數據,大大提高了數據處理的速度,聚類使得新聞之間的相似度得以體現,再利用不同的協同過濾算法實現個性化的新聞推薦。系統使用了JSP、Servlet技術及Mahout開源項目編寫程序,首先利用Java將新聞數據按約定格式處理并將其傳到Hadoop的HDFS上,在安裝好Hadoop的Linux端定時調用shell腳本聚類處理新聞,然后使用MySQL數據庫存儲數據,實現對新聞數據的協同過濾推薦處理。新聞推薦系統主要功能包括前臺與后臺的設計,圖3所示為系統整體功能結構圖,前臺主要負責展示推薦的新聞信息結果和供用戶瀏覽新聞;后臺處理新聞數據,并將處理好的數據插入數據庫供前臺使用。
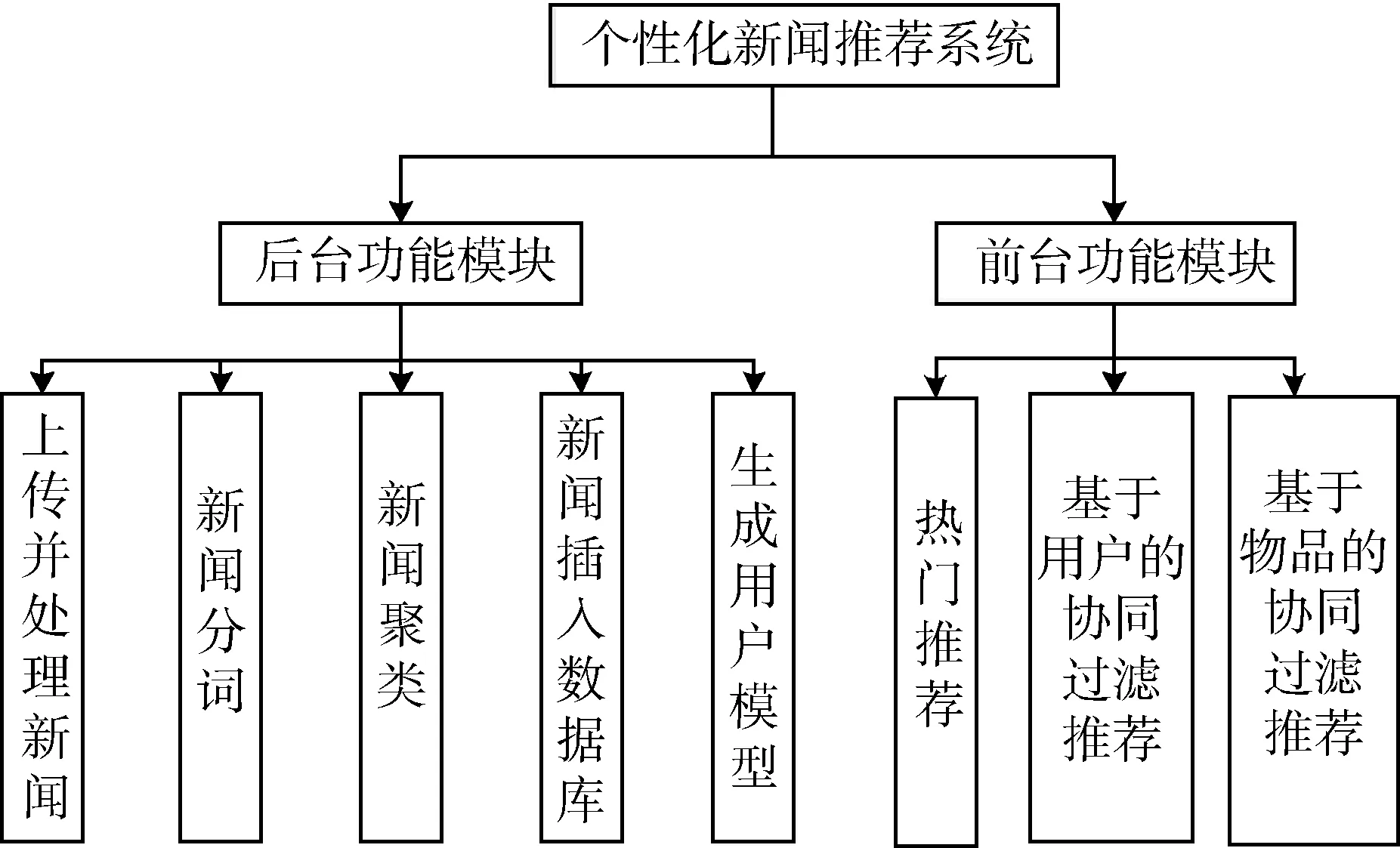
圖3 系統整體功能結構圖
圖4為新聞推薦流程圖。選擇基于用戶的協同過濾推薦,系統將自動啟動基于用戶的協同過濾算法引擎進行數據的計算并將數據推送到頁面中。同理基于物品的協同過濾算法相同。這個過程中查詢所有人的瀏覽記錄是通過多次的數據庫查詢得到的。
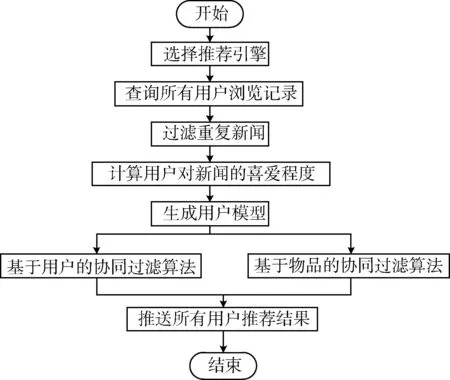
圖4 新聞推薦流程圖
新聞普遍存在的問題就是冷啟動問題,當用戶第一次使用時該如何進行推薦,用戶新加入時沒有任何的歷史行為及其興趣,因此無法對其進行推薦。本文使用熱門推薦來解決這種極端的情況。當剛打開該系統時,為模擬處理冷啟動問題,系統將查詢出瀏覽數前十的新聞進行推薦。
(1)當用戶進行基于用戶的協同過濾推薦算法操作時,將觸發baseOnUserSer這個Servlet基類,該Servlet基類將查詢出系統中的所有用戶,并對所有的用戶進行基于用戶的協同過濾算法推薦。首先,提交所有用戶的相關數據(格式為:用戶id,新聞id,評分),格式表示某用戶id瀏覽過某條新聞id,并且把喜歡程度表示為評分,利用每個用戶的新聞評分,根據皮爾遜相關系數公式計算出需要推薦的用戶與其他用戶之間的皮爾遜相似度,最后利用式(2)計算出需要推薦的用戶與用戶之間的皮爾遜相似度per。假設某用戶瀏覽過的某條新聞的評分為p,那么通過公式可以計算出該條新聞的推薦分值point=per×p,如果該條新聞被多個用戶閱讀過則需求出Σpoint=per1×p1+per2×p2…+pern×pn。得到所有新聞的推薦分后,選取被推薦用戶沒有瀏覽過的新聞中最高分的新聞作為推薦。
基于用戶的協同過濾推薦系統效果如圖5所示。
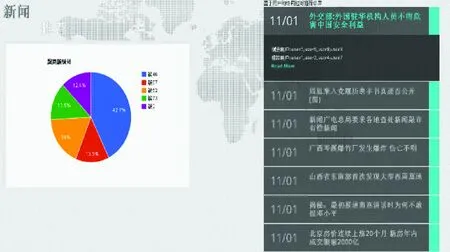
圖5 基于用戶的協同過濾推薦結果
(2)當用戶進行基于物品的協同過濾推薦操作時,將觸發baseOnItemSert類,該類將查詢出系統中的所有用戶,并過濾掉admin這個測試用戶,將所有的用戶進行基于物品的協同過濾算法推薦,所有推薦結果存儲在一個專門設計的newsModeBean類中 ,其他的操作基本與基于用戶的協同過濾推薦一樣。基于物品的協同過濾算法,提交數據的格式與基于用戶的協同過濾算法一樣。首先提取出所有的新聞,計算并建立新聞的共軛矩陣。然后使用用戶向量點乘共軛矩陣可以得到推薦分數。
基于物品的協同過濾推薦系統如圖6所示。
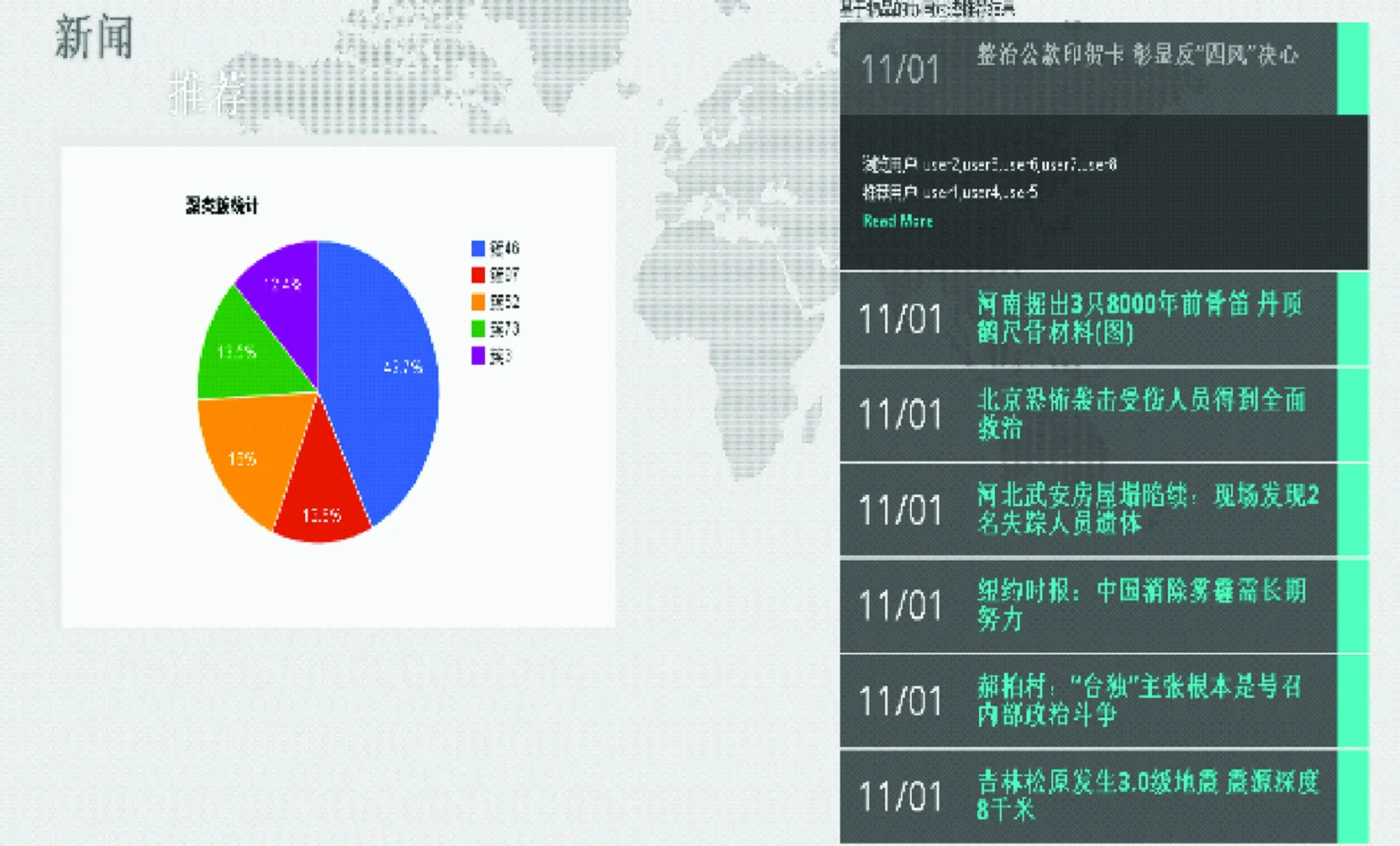
圖6 基于物品的協同過濾推薦結果
5 結論
隨著互聯網的迅速發展,用戶面對海量互聯網信息的時候,有時覺得很迷茫,不知道從何閱讀,甚至有時面對無關的廣告產生煩躁的心情。為了提高有效閱讀率,本文提出了利用基于用戶或者物品的協同過濾算法來實現新聞的個性化推薦,從測試的效果看,基本上達到用戶信息個性化新聞推薦的各項功能要求,表明該算法是有效的。因為測試數據較少,在Hadoop平臺上運行,沒有體現出并行計算的效果,下一步將利用更多的用戶數據來驗證系統。同時,算法目前的實現主要依靠相似性來做推薦,后續將引進其他算法來改進個性化推薦的新聞內容和分類,從而提高推薦的準確性。
[1] JIANG S,HONG W X.A vertical news recommendation system:CCNS—an example from Chinese campus news reading system[C].ICCSE 2014: Proceedings of the 2014 9th International Conference on Computer Science & Education.Piscataway,NJ: IEEE,2014: 1105-1114.
[2] 楊武,唐瑞,盧玲.基于內容的推薦與協同過濾融合的新聞推薦方法[J].計算機應用, 2016, 36(2):414-418.
[3] 劉金亮.基于主題模型的個性化新聞推薦系統的研究與實現[D].北京: 北京郵電大學,2013.
[4] 彭菲菲,錢旭.基于用戶關注度的個性化新聞推薦系統[J].計算機應用研究,2012,29(3) : 1005-1007.
[5] 文鵬,蔡瑞,吳黎兵.一種基于潛在類別模型的新聞推薦方法[J].情報雜志,2014,33(1):161-166.
[6] 項亮.推薦系統實踐[M].北京: 人民郵電出版社,2012.
[7] 曹一鳴. 基于協同過濾的個性化新聞推薦系統的研究與實現[D]. 北京:北京郵電大學, 2013.
Design of personalized news recommendation system based on Hadoop platform
Wei Ling,Li Weiqiang
(Department of Electrical and Computer Engineering,Lushan College of Guangxi University of Science and Technology , Liuzhou 545616, China)
For Internet users to quickly find the required information, personalized recommendation system has been reflected and applied. The design of this system is to allow the majority of Internet users to browse the news, it can provide a personalized news recommendation system, to achieve collaborative filtering recommended treatment of news data. The system uses Hadoop MapReduce model to realize the parallel fast clustering massive news data, can greatly improve the speed of data processing. Clustering makes the similarity between news to reflect, and using different collaborative filtering algorithm to achieve personalized news recommendation.
Hadoop;MapReduce;clustering;personalized;Mahout
廣西科技大學鹿山學院2015年科學基金項目(2015LSKY17)
TP301.6
A
10.19358/j.issn.1674- 7720.2016.23.006
韋靈,黎偉強. 基于Hadoop平臺的個性化新聞推薦系統的設計[J].微型機與應用,2016,35(23):21-23,27.
2016-08-12)
韋靈(1979-),男,碩士,講師,主要研究方向:人工智能、機器學習。
黎偉強(1981-),男,碩士,講師,主要研究方向:人工智能、數據并行化處理。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
