面向對象的多版本傳感器觀測服務模式匹配方法
2016-12-22 08:06:18侯景偉
華中師范大學學報(自然科學版) 2016年6期
何 杰, 侯景偉
(寧夏大學 資源環境學院, 銀川 750021 )
?
面向對象的多版本傳感器觀測服務模式匹配方法
何 杰*, 侯景偉
(寧夏大學 資源環境學院, 銀川 750021 )
以多版本傳感器觀測服務(Sensor Observation Service,簡稱SOS)模式為研究對象,從SOS實現規范數據類型UML圖中解析出SOS服務模式組成對象,提出一種面向對象的模式匹配方法,把服務模式匹配問題轉換為模式對象的匹配問題.重點闡述了模式對象的分解、關聯子對象識別、及子對象匹配等相關技術.最后,以兩種版本的SOS模式匹配試驗驗證了方法的有效性.
傳感器觀測服務; UML; 面向對象; 對象匹配
模式匹配[1-5]是當前研究的一個熱點和重點問題,也是眾多應用,如基于web的服務查詢和集成、電子商務、數據同化等不可缺少的關鍵步驟.然而,在當前,不管是語法模式匹配[1,5-6]方法還是語義(本體)[2-4,7]模式匹配方法,它們都從微觀上,以每個模式元素為單位參與匹配,而且通常需要對兩個待匹配的模式文件中所有元素進行比較,由于參與匹配元素的增多,特別是大尺度的模式匹配問題,造成匹配性能較差;同時,隨著參與匹配元素的增多,匹配復雜度提高,誤匹配率也會增多,從而影響匹配精度.針對這些問題,國際上有人提出基于模式片段匹配的方法來提高模式匹配性能和質量,如在H.Do和Rahm設計的COMA++[8]系統中,首先對模式進行分塊,然后對這些模式分塊進行匹配,但由于COMA++采用啟發式分塊規則,造成模式分塊要么太多,要么太少,且在識別相似分塊時,通常只考慮分塊的根節點信息,造成匹配質量不高.在國內,東南大學的胡偉等人提出的Falco[9]系統則根據輸入的本體實體在結構和語言學上的相似性把兩個本體中所有相似的實體單元,通過聚類算法形成一個個大的本體塊,由于其算法中涉及的本體信息多且復雜,從而影響了系統的性能.
在地理信息網絡服務中,傳感器觀測服務(SOS)[10]內容最復雜、應用最廣,它提供了一個標準的接口來管理和提取各種不同傳感器系統的元數據和觀測.在本文中,以SOS服務模式為例,研究不同版本服務模式的差異,及差異造成了諸如類在命名上的變化、屬性上的變化(如新增屬性)、繼承關系上的變化等.從本質上講,這些服務模式具有面向對象特征.為此,本文提出了一種面向對象的模式匹配方法(Object-Oriented Schema Matching,簡稱OOSM),試圖把待匹配模式文件當作一個對象類,在綜合考慮Falco[9]系統通過聚類算法形成本體塊,及COMA++[8]系統采用的啟發式分塊方法的基礎上,采用直接利用類的繼承層次關系把類分解成一個個子類或子對象.然后通過計算子類名稱字符、詞義及注釋相似度來找出待匹配的兩個模式類的所有相似或關聯子對象.最后設計一種匹配算法對所有相似子類進行匹配,最終達到通過匹配規模的減少和匹配算法的改進來提高匹配性能和質量.
1系統體系結構及部件
圖1是系統體系結構.
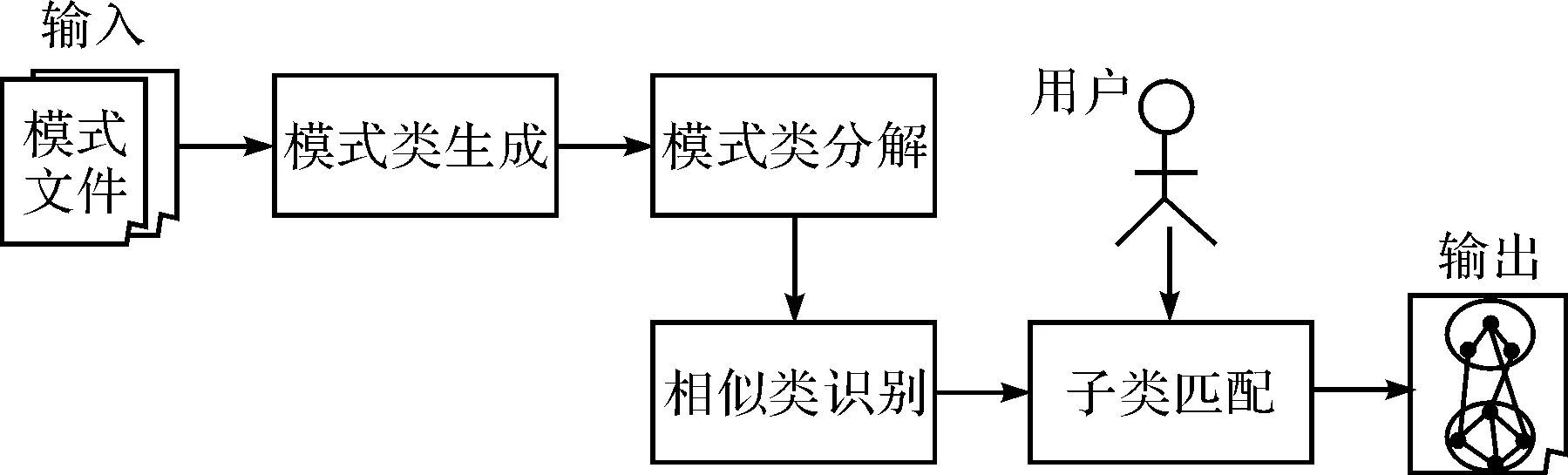
圖1 系統體系結構Fig.1 Architecture of the schema matching system
系統由模式類生成,模式類分解,相似類識別及模式子類匹配四個部件組成.模式類生成部件主要實現把輸入的模式文件生成對應的模式類,并用對應的類圖表示;模式類分解部件則根據模式類包含的子類或對象間的層次關系,把模式類分解成一個個獨立的子類;相似類識別部件則從分解的所有源和目的子類中識別出相似或關聯的子類;最后子類匹配部件對這些相似子類進行匹配,并對所有子類匹配結果進行組合,得到最終匹配結果.同時,在子類匹配過程中,可以人工從匹配器庫中選擇合適的匹配器及匹配器組合方法.
2系統實現
2.1模式類生成
OGC(Open Geospatial Consortium)為不同類型的網絡服務間的互操作定義了技術和實現規范,它們使用標準的XML 模式定義語言(XSD)定義了網絡服務實例文檔應該遵循的結構和使用的數據類型.從本質上講,XML模式定義是面向對象的,所以把XML模式文件轉換為一種面向對象的模式類表示是合適的.
一個XML模式文檔中定義了4種類型的數據結構:復雜類型(complexType),簡單類型(simpleType),元素(element),屬性(attribute).此外,XML模式定義語言還定義了19種內置的原子數據類型,如string類型,及25種派生數據類型(由原子數據類型派生),如normalizedString派生于string.下面來定義各種規則把不同數據類型轉換為面向對象的類型.
規則1:所有的復雜類型(complexType)都映射為一個類類型,復雜類型名字為對應的類名,復雜類型內部定義的變量,如果類型為內置原子類型,則映射為類的屬性,如果是派生類類型則映射為復雜類的一個嵌套子類.
規則2:所有的簡單的數據類(simpleType)型映射為類的屬性,其定義的枚舉值為屬性的默認值.
規則3:所有的元素(element)及屬性,如果其類型為原子數據類型,則映射為類的屬性,否則映射為類的一個嵌套子類.
以SOS GetCapabilities響應文件為例,其模式文件包括ows∶CapabilitiesBaseType,sos∶Fileter_Capabilities,sos∶Contents等3個模式片段,在XMLSpy軟件中,其模式結構圖如圖2所示.根據本節定義的轉換規則,很容易把其轉換為模式類表示,其類名為Capabilities,下面包含3個子類,每個子類又包含其它子類或屬性,圖3顯示了模式片段轉換后的UML靜態圖表示.
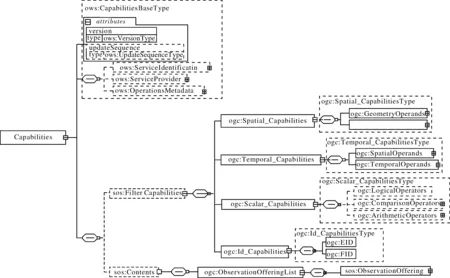
圖2 GetCapabilities響應文件結構Fig.2 Structure of GetCapabilities response file
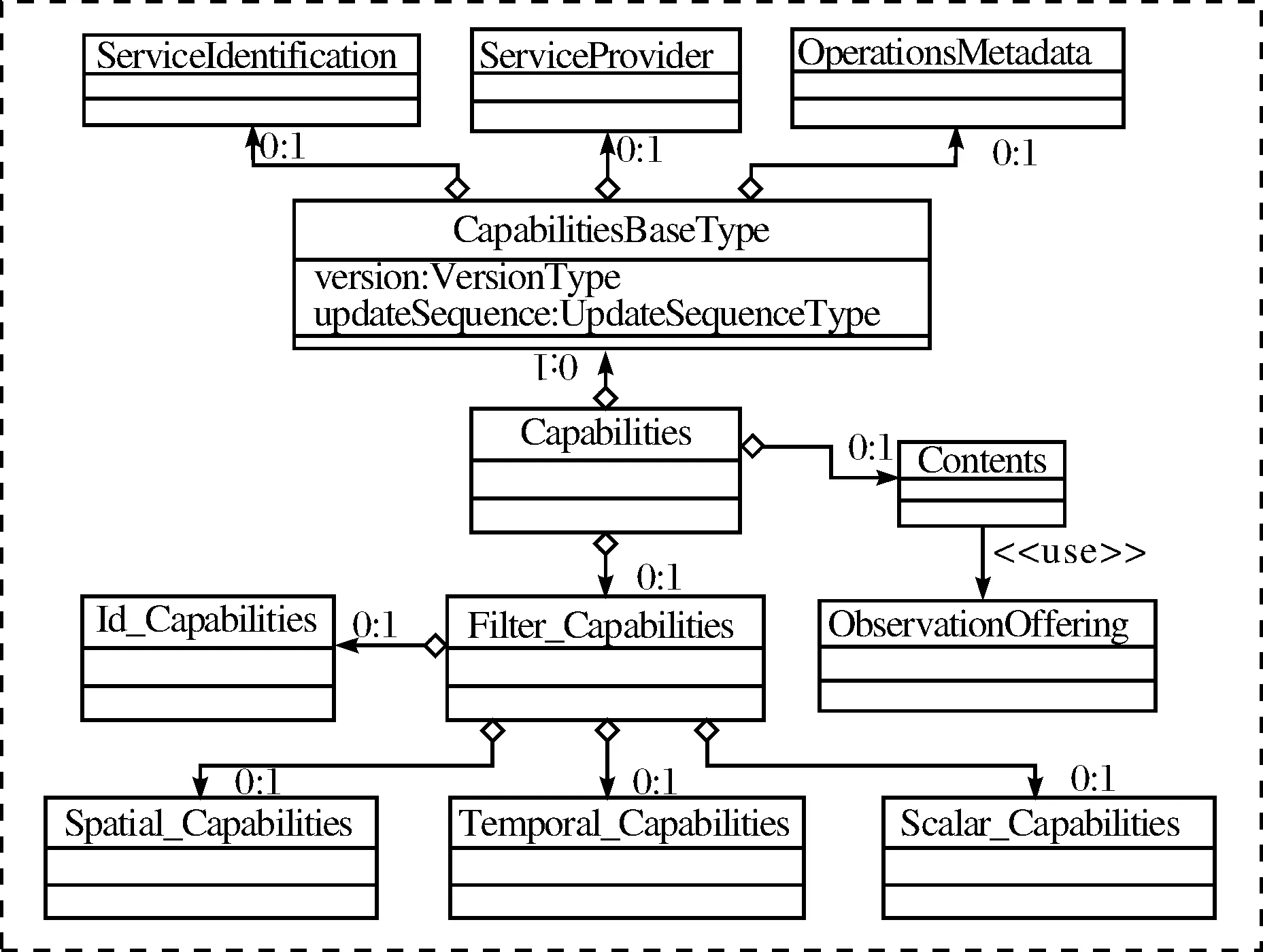
圖3 GetCapabilities響應文件UML表示Fig.3 UML diagram of GetCapabilities response file
2.2模式類分解
為了操作方便,把模式類的UML靜態表示圖轉換為一個面向對象系統的有向圖,圖中每個類或子類用一個節點表示,節點的標簽用類名表示,節點間的有向邊表示類間的關系(如繼承,關聯,聚合等).下面對有向圖及相關操作進行定義.
定義1在OOSM對象模型圖中,每個對象用一個五元組
在定義1中,編號根據圖的廣度優先遍歷方法獲得.節點類型包括簡單基本數據類型(如integer,char,string等)及復雜數據類型,如類類型.在OOSM有向圖中,直接的前驅節點最多一個,沒有前驅節點的節點為圖的根節點,而直接的后繼節點可以有多個,沒有后繼節點的節點稱為葉子節點.
定義2在OOSM對象模型圖中,每個有向圖用一個三元組〈R,V,E〉表示,其中R表示有向圖的根節點,V表示頂點或節點集合,E是邊集合.
在定義2中,R是有向圖中唯一一個沒有前驅的節點,且經過R可以到達有向圖中任意節點.
模式類的分解是基于模式類的有向圖進行的,分解規則定義如下.
模式類分解規則:給定任何一個待分解的模式類圖,首先判斷模式類中是否包含嵌套的子類或對象,如果模式類為空,或者包含的全是原子屬性,沒有子類,則分解結束;否則,我們對模式類進行分解,分解方法為:把所有與模式類(父類)有直接關系的各種子類或對象提取出來,成為一個個獨立的子類.算法的偽代碼表示如下:
算法1:圖分解算法PartitionGraph(G).
輸入:面向對象系統的有向圖G.
輸出:子圖集合subGraphs.
subGraphs=Φ
if(hasSubClass(G))
subGraphs=getSubGraph(G)
End if
上述算法中,hasSubClass(G)用來判斷圖是否包含可分解的子類,判斷方法即根據圖G的根節點的類型來判斷,如果根節點是簡單數據類型,則圖G是不可再分的,否則可以再分.getSubGraph(G)則從圖G中分解出直接的子類(子圖).分解的過程為:依次處理圖G的每個直接后繼節點,將這些節點的Pre(前驅)設置為空,則每個后繼節點及其所有后繼節點構成了一個以該后繼節點為根節點的新子圖.最小的子圖是一個只包含一個葉子節點的節點,節點的前驅及后繼均為空.
如給定圖3的Capabilities類經過一次分解后得到Filter_Capabilites,Contents,CapabilitiesBaseType 3個子類,其中,Filter_Capabilites又可分解為Spatial_Capabilities,Temporal_Capabilities,Scalar_Capabiities,Id_Capabilities 4個子類,對于Contents子類,它又是由很多的ObserationOffering類組成,CapabilitiesBaseType子類分解成4個屬性元素及3個可選子類ServiceIdentification,ServiceProvider,OperationsMetadata.
2.3相似類識別
相似類識別主要是發現源和目的模式類中所有相似子類對,以便對這些相似子類對作進一步匹配.為了提高相似類識別的效率,只考慮所有子類的名稱相似值及類的注釋文本相似值,而不考慮類的內部結構相似性;同時,只計算相似類間1∶1的關聯關系.下面定義2個子類相似值sim(o1,o2).
sim(o1,o2)=α×simstr(o1.Name,o2.Name)+
β×simsyn(o1.Name,o2.Name)+
γ×simglos(o1.gloss,o2.gloss).
(1)
在公式(1)中,simstr(o1.Name,o2.Name)計算的是兩個類名字符相似值,在本文中,采用編輯距離算法來計算兩個類的名稱相似值,即有:
simstr(o1.Name,o2.Name)=
1-editNums/maxLength(o1.Name,o2.Name)
(2)
其中,editNums為把一個字符轉換為另一個字符需要的編輯次數,maxLength()返回字符串最大長度.如給定兩個類名:”feature”,”fofeature”,根據公式(2)可計算出它們間的字符相似值simstr("feature","fofeature")=1-2/9=0.78.
simsyn(o1.Name,o2.Name)計算的是兩個類名的標簽概念相似值[11],其具體計算方法如下.
定義3(類名標簽詞義相似值)設有類名標簽A、B,其在WordNet[12]中的同義詞集合表示為A=(α1,α2,α3,…,αn),B=(β1,β2,β3,…,βm),其中α1,α2,α3,…,αn,β1,β2,β3,…,βm分別為類名標簽A、B的原子義詞,則類名標簽A、B的內積為:
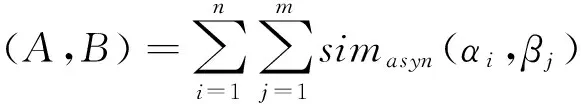
(3)
其中,simasyn(αi,βj)根據兩個原子義詞在WordNet中的詞義距離的倒數計算出的義詞相似值.有了內積,我們就能導出類名標簽的范數和原始類名標簽的相似值定義.
定義4(類名標簽范數和相似值)設有類名標簽Α,其范數定義如下:
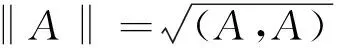
(4)
則兩個原始類名標簽Α、B間的相似值定義如下:

(5)
simglos(o1.gloss,o2.gloss)用來計算兩個類的注釋文本相似值,我們采用的是基于向量空間模型的余弦算法,定義如下.
定義5(文本相似度)設有源模式類的注釋文檔di={ti1,wi1;ti2,wi2;…; tin,win},目的模式類的注釋文檔dj={tj1,wj1;tj2,wj2;…; tjn,wjn},其中ti1,ti2,…, tin;tj1,tj2,…, tjn為源和目的注釋文檔的特征項,wi1,wi2,…, win;wj1,wj2,…, wjn為對應的文檔特征項的權重,則文檔di、dj的文本相似值用公式表示為:
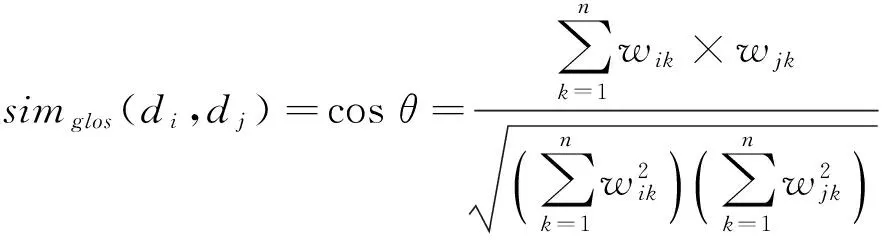
(6)
其中,θ為兩個文檔向量的空間夾角.
在兩個子類的相似值計算中,由于不同類型相似值的作用程度不同,如對于類名的字符相似值,由于同名異義、同義異名現象使得在很多情況下,類名的字符相似值并不能準確表示兩個子類的相似程度,所以各個類型相似值權重不同,對公式(1)中的α、β、γ取值滿足α<β≤γ,且α+β+γ=1.
對于源類的每個子類,當計算出其與目的類的所有子類的相似值后,我們選擇相似值最大者(maxSim)、且相似值大于門限值(threshold)的子類對作為候選相似子類對(subGPairs).如果某個最大相似值的值小于規定的門限值,此時,把這種子類對作為次候選相似子類對(secondSubGPairs).當源和目的類的所有子類初次識別完成后,判斷是否有次候選相似對產生,如果沒有,子類識別結束,輸出最終相似子類對,否則,進行二次子類識別,即,處理所有的次候選相似對.處理過程為:如果源子類可以分解(包含有子類),分解源子類,然后把目的子類與源子類的所有子類比較(見算法2中的函數getMaxSim),如果沒有候選相似子類對,則逆向比較,即如果目的子類可以分解,則把源子類和目的子類的所有子類比較,如果仍然不滿足候選相似子類條件,則處理結束,否則輸出對應的候選相似子類.算法2是子類(子圖)識別算法的偽代碼.
算法2:子類識別算法SimilarClassIdentity(subGraphs1,subGraphs2).
輸入:源和目的子圖subGraphs1,subGraphs2.
輸出:候選相似子圖對subGPairs.
subGPairs=Φ, secondSubGPairs=Φ;
foreach(class o1 in subGraphs1){
maxSim=0.0;
foreach(class o2 in subGraphs2){
if(sim(o1,o2)>=maxSim)
maxSim=sim(o1,o2);
}
if(maxSim>threshold)
subGPairs+=new Pair
else
secondSubGPairs+=new Pair
}
if(secondSubGPairs==Φ)
return subGPairs;
else{
foreach(Pair p in secondSubGPairs){
class oo=p.getFirstClass();
class oo2=p.getSecondClass();
if(oo.canPaitition()){
class tmpClass=getMaxSim(PartitionGraph(oo),oo2);
subGPairs+=new Pair
}else if(oo2.canPaitition()){
class tmpClass=getMaxSim(PartitionGraph(oo2),oo);
subGPairs+=new Pair
}
}
return subGPairs;
}//算法結束.
識別后的候選相似子類對被分成兩種類型,一種為簡單的原子子類對,即不可再分解,一種為復雜的子類對,可以繼續被分解.下節將對這兩種相似子類進行匹配.
2.4子類匹配
針對識別后的兩種類型的子類對:簡單子類對和復雜子類對,分別設計了簡單子類匹配算法和復雜子類匹配算法.
對于簡單子類匹配,由于每個子類內部只包含屬性成員,沒有嵌套子類,所以根據公式(1)計算所有屬性成員兩兩間的名稱、標簽概念和注釋文本組合相似值,同時每組相似值中的最大者、且大于門限值的屬性對為匹配的候選映射.
對于復雜子類匹配問題,我們思想是通過類分解,把復雜子類匹配轉化為簡單子類匹配,即首先使用本文的類分解方法對復雜類進行分解,然后識別分解后的相似子類,最后對子類進行匹配.具體算法描述如下.
算法3:子類匹配算法ObjectMatching(Os,Ot).
輸入:候選子類對(Os,Ot).
輸出:候選映射Mappings.
1)從對象管理器中選擇未匹配子類對(osi,otj).
2)判斷子類類型.如果是簡單子類,利用公式(1)進行簡單子類匹配;如果是復雜子類,則首先把復雜子類轉換為簡單子類,再利用簡單子類算法進行匹配.
3)匹配中間結果處理.即把每輪得到的候選映射路徑擴充到模式類的根節點,候選映射轉化為匹配的最終映射.
4)如果子類對匹配完,轉步驟5),否則返回到步驟1),重新執行上述步驟.
5)輸出子類匹配結果,算法結束.
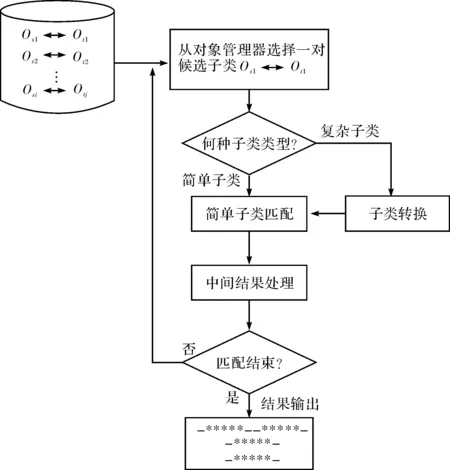
圖4 候選子類對匹配流程圖Fig.4 Process of the candidate subclass pairs matching
3實驗及討論
本文試驗使用的計算機配置為:windows XP 操作系統, 2.5 GHz Intel Core2 Quad處理器,2.0 GB RAM,且安裝Sun Java 1.6.0運行庫.實驗數據我們選取的是SOS 1.0.0版本和2.0.0版本的三種模式文件,分別是:sosGetCapabilities.xsd,文件大小為4 KB;sos GetObservation.xsd,其大小為6 KB;sosGetResult.xsd,大小為5 KB.
3.1模式匹配質量實驗
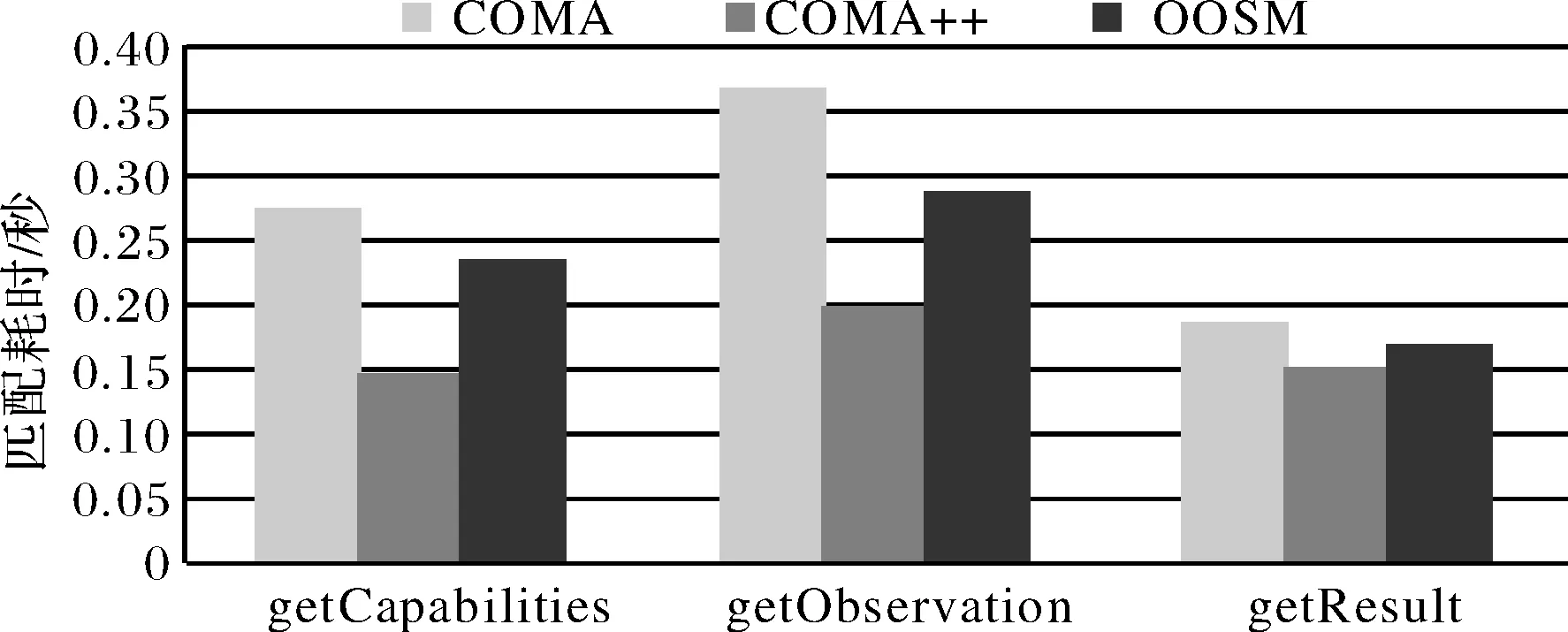
應用①COMA;②COMA++;③OOSM分別進行匹配試驗.對于COMA我們選擇的配置策略為:平均值法進行相似值聚合和組合,MaxDelta法選擇匹配候選者,匹配方法選擇AllContext(完全上下文),包含匹配器組合為:NAME(名稱),PATH(路徑),LEAVES(葉子),PAR ENTS(父親),SIBLINGS(兄弟).對于COMA++,選擇的匹配策略是Fragment-based(基于片段),使用的Node Matcher(節點匹配器)和Context Matcher(上下文匹配器)均為COMA.對于OOSM,相似子類識別選定的門限值為0.7.
用傳統的查全率(Recall),精度(Precision)來評估匹配結果,試驗結果如圖5、圖6所示.從圖5看出,對于SOS兩種不同版本的3種操作模式文件匹配,使用本文面向對象方法得到的查全率最高,平均查全率值達到82%以上,這主要由于面向對象匹配方法中不僅考慮到了元素標簽名稱組成,還考慮到了標簽的節點語義和注釋,所以能發現更多那些使用COMA/COMA++沒有發現的語義異質性問題.從圖5還可以看出,對于操作getCapabilities,getObservation來說,COMA++查全率稍稍高于COMA,對于getResult匹配結果,二者幾乎相同,這主要由于getResult兩種版本結果差異巨大,模式片段及相似片段少,COMA++作用不明顯.從圖6可以看出,3種匹配方法精度值滿足COMA 圖5 匹配查全率比較Fig.5 The Recall of 3 match methods 圖6 匹配精度比較Fig.6 The Precision of 3 match methods 3.2模式匹配性能實驗 同樣,應用上節使用的3種匹配器來進行匹配性能實驗,實驗數據也同3.1節,實驗結果如圖7所示.從圖7比較看出,不同的類型的模式文件間的匹配,及不同匹配方法性能各不相同.對于同種匹配任務,匹配性能COMA++最好,OOSM次之,COMA最差.這主要由于COMA++在局部上雖然使用的與COMA相同的匹配器,但在整體上采用的是分塊策略,匹配規模大大減少,所以性能優于COMA,同時由于COMA++在元素級上的匹配仍然為語法匹配方法,而OOSM在匹配時考慮了節點的語義信息及注釋文本信息,所以整體匹配性能稍遜于COMA++.對于結構組成清晰,模式類繼承關系簡單,容易分塊或子類化的模式文件,如對于操作getCapabilities,getObservation模式文件由于易于對象化表達和分塊,所以使用COMA++和OOSM都能使性能大幅提高. 圖7 3種匹配方法性能比較Fig.7 Performance comparison of three matching methods 異構網絡服務模式間特別是不同質的模式文件間結構差異巨大,同時元素語義表達差異明顯,造成了模式匹配精度和性能的下降.為了改善性能,提高精度,本文在分析不同版本模式文件結構特征基礎上,提出了一種面向對象的模式匹配方法,把模式匹配問題轉化為模式子對象間的匹配問題,從整體上減少了模式匹配規模,同時在局部匹配過程中充分考慮模式元素的標簽語義信息和注釋文本向量信息.實驗結果表明,文中提出的方法在匹配性能上比傳統模式匹配方法,如COMA,有較大提高,同時在精度上又優于COMA++. 下一步將把面向對象方法用于異質不同類型模式文件間,如SOS與WCS,SOS與WFS間的匹配,同時改善匹配算法,進一步提高匹配性能. [1] SHVAIKO P, EUZENAT J. A survey of schema-based matching approaches[J]. Journal on Data Semantics IV, 2006, 3730:146-171. [2] GIUNCHIGLIA F, SHVAIKO P. Semantic matching[J]. KER Journal, 2003, 18(3):265-280. [3] GIUNCHIGLIA F,SHVAIKO P,YATSKEVICH M.S-Match[J]:An Algorithm and an Implementation of SemanticMatching[C].In:Proceedings of the European Sema-ntic WebSymposium(ESWS),Springer, Heidelberg,2004:61-75. [4] GIUNCHIGLIA F, YATSKEVICH M, GIUNCHIGLIA E. Efficient semantic matching[C]//In Proceedings of ESWC,Heraklion,Greece, 2005: 272-289. [5] 王育紅, 陳 軍. 基于實例的GIS數據庫模式匹配方法[J]; 武漢大學學報(信息科學版), 2008, 33(1):46-50. [6] AUMULLER D, DO H H, MABMANN S, et al. Schema and ontology matching with COMA++[C]//In Proc of the 2005 ACM SIGMOD Int Conference on Management of Data. New York: ACM Press, 2005: 906-908. [7] NOY N, MUSEN M. The prompt suite: interactive tools for ontology merging and mapping[J]. International Journal of Human-Computer Studies, 2003, 59(6):983-1024. [8] DO H H, RAHM E. Matching large schemas:Approaches and evaluation[J]. Information Systems, 2007, 32(6):857-885. [9] HU W,QU Y,CHENG G. Matching large ontologies:A divide-and-conquer approach[J]. DKE, 2008, 67:140-160. [10] OGC. OpenGIS? Sensor Observation Service Implementation Specification [M]. 2006. [11] 何 杰, 陳能成, 鄭 重, 等. 利用語義的多版本網絡覆蓋服務模式匹配方法[J]. 武漢大學學報(信息科學版), 2012, 37(2):210-214. [12] MILLER A G. WordNet:A lexical database for English[J]. Communications of the ACM, 1995, 38(11):39-41. [13] DO H H, RAHM E.COMA-A System for FlexibleCombination of Match Algorithms[C]//In Proceedings of the 28th International Conference on VeryLarge Data Bases, Hongkong,China, 2002. An object-oriented multi-versions sensor observation services schema matching method HE Jie, HOU Jinwei (School of Resource and Environment, Ningxia University, Yinchuan 750021) An Object-Oriented schema matching method is proposed and the schema match is converted into object match using multi-version sensor observation service(SOS) schemas as study objects and SOS service schema objects parsed out from SOS implementation specification presented by Unified Modeling Language (UML) static class diagram. Key problems, such as object decomposition, similar sub-object identification and sub-object match, are focused on. Finally, different version schemas of SOS are utilized to test the effectiveness of the proposed method. sensor observation service; UML; Object-Oriented; object match 2016-09-11. 寧夏自然科學基金資助項目(NZ12110);國家自然基金資助項目(41201393);武漢大學測繪遙感信息工程國家重點實驗室開放基金項目(14I03). 1000-1190(2016)06-0805-07 P205 A *E-mail: whujiejie@163.com.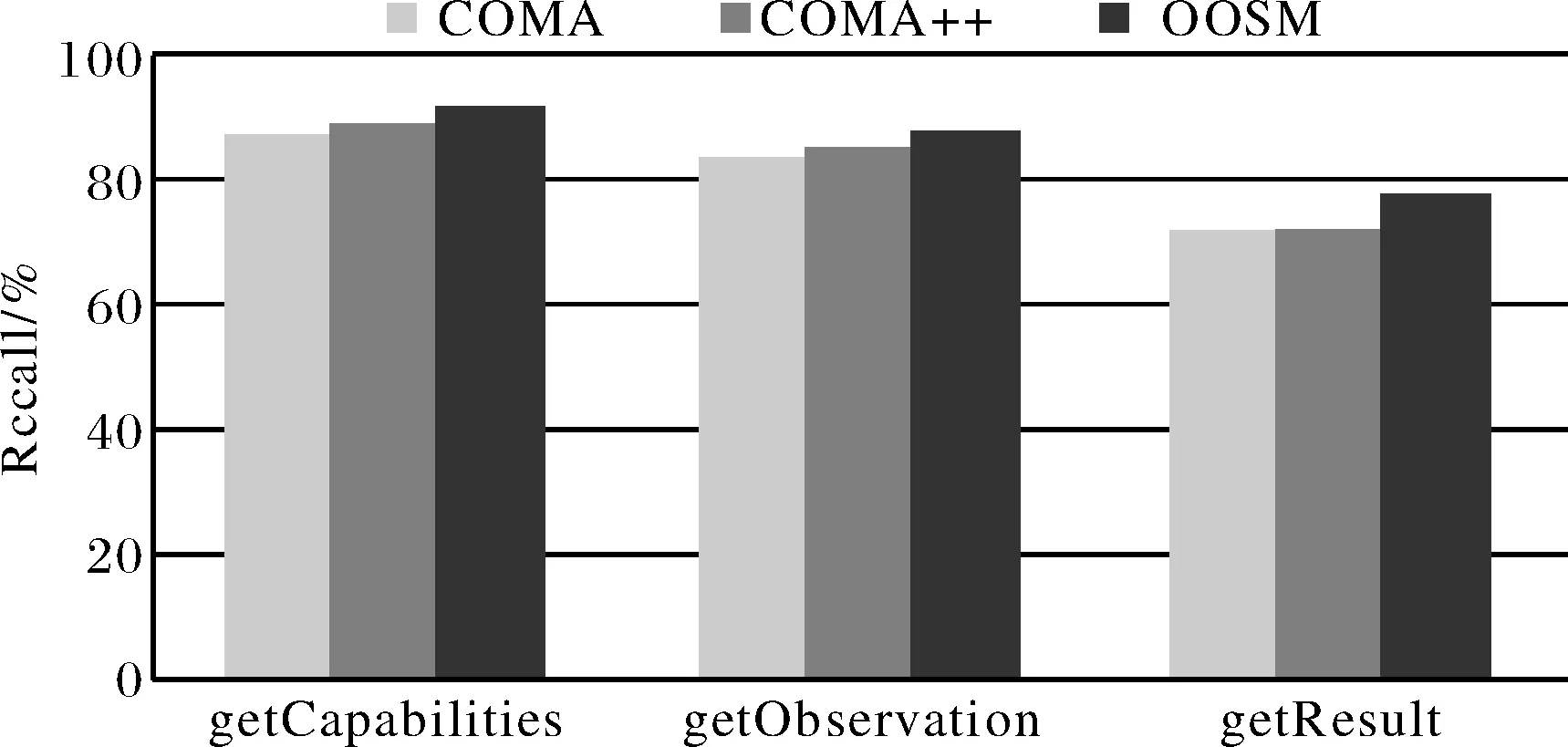

4結論與展望
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
