華語流行音樂的歌詞情緒分析
——基于新媒體音樂終端的大數(shù)據(jù)分析方法
2017-02-10 02:25:14黃美帆
音樂傳播 2017年4期
■薛 亮 黃美帆
(中國社會科學(xué)院大學(xué),北京,102488;南加州大學(xué),美國洛杉磯,CA 90089-0851)
無論流行音樂產(chǎn)業(yè)以何種方式獲利,最根本的問題依然是如何真正理解受眾,抓住受眾的喜好。過去流行音樂業(yè)者主要透過唱片銷售量了解歌曲暢銷程度,但近年來數(shù)字音樂興起,受眾并非只能透過購買唱片聆聽音樂,在線流媒體服務(wù)與社交媒體均是可以輕易接觸到流行音樂的方式。在線流媒體播放平臺(如網(wǎng)易云音樂、QQ音樂、KKBOX、Spotify、Apple Music)興起,使得收聽不同種類的流行音樂成本大幅下降,受眾更能夠輕易選擇喜愛的曲目;同時,判斷流行音樂是否為暢銷曲目,不再能僅憑唱片銷售的數(shù)字,因此,音樂產(chǎn)業(yè)必須開始重視并且分析應(yīng)用這些數(shù)字流媒體平臺及社群間不斷產(chǎn)生的大量數(shù)據(jù)。
流行音樂的相關(guān)研究可大致分為流行音樂內(nèi)容(文本)分析、流行音樂制作分析、流行音樂受眾分析等等。其中,音樂內(nèi)容可分為兩個部分,分別是:以音樂特征為主體的歌曲結(jié)構(gòu)分析,如音樂本身的旋律、節(jié)奏、音色、和弦等等;以流行音樂演唱的歌詞內(nèi)文作為主體的分析。本研究則是屬于以流行音樂演唱的歌詞文本作為主體的音樂內(nèi)容文本分析。
一、研究目的與研究對象
本研究期望基于大數(shù)據(jù)的分析,利用文字挖掘以及情緒分析的技術(shù),了解受眾對流行音樂之喜好,協(xié)助流行音樂制作出版相關(guān)產(chǎn)業(yè),提供制作出版與營銷之參考。研究將針對華語流行音樂,以歌詞的面向了解聽眾對音樂情感之喜好,提供流行音樂制作出版之音樂類型建議,幫助流行音樂產(chǎn)業(yè)在進行音樂出版銷售時能夠更精準地運作。
本研究欲了解2011年至2016年華語熱門流行歌曲歌詞情感趨勢,因此,選取了“MusicRadio中國TOP排行榜”、“QQ音樂內(nèi)地/港臺巔峰榜”和“網(wǎng)易云音樂熱歌榜”等三個較有代表性的與新媒體平臺相關(guān)的榜單作為研究對象的來源,經(jīng)交叉比對后,選出同一時間內(nèi)三個榜的共同作品作為文本分析對象。需要說明的是,由于“網(wǎng)易云音樂”這款終端是2013年才發(fā)布的,因此2013年之前的榜單主要從另外兩個排行榜中選取。
二、技術(shù)背景
大數(shù)據(jù)(Big Data)是指以現(xiàn)有科技的水平難以處理的大量數(shù)據(jù),數(shù)據(jù)的大小并沒有被定義,而是依照當時的科技能力而定;大數(shù)據(jù)的數(shù)據(jù)類型可分為結(jié)構(gòu)化數(shù)據(jù)(即關(guān)系數(shù)據(jù)庫能夠容易處理之數(shù)據(jù)類型,如數(shù)值、字符字串、布爾值等)與非結(jié)構(gòu)化數(shù)據(jù)(即關(guān)系數(shù)據(jù)庫難以直接處理之數(shù)據(jù)形態(tài),如網(wǎng)頁、文件、多媒體等)。大數(shù)據(jù)具有“4V”的特征:
Volume(大體量)——指數(shù)據(jù)的數(shù)量龐大,而大數(shù)據(jù)的數(shù)據(jù)量通常是以現(xiàn)有的科技能力難以處理的數(shù)量,會隨著科技的演進不斷地增加;
Velocity(高速度)——指數(shù)據(jù)產(chǎn)生與更新的速度是極快的,例如云音樂歌單不斷快速產(chǎn)生的用戶的活動記錄(收藏、評論)等數(shù)據(jù),它們每分每秒都在快速地增加與更新;
Variety(多樣性)——指數(shù)據(jù)的內(nèi)容與結(jié)構(gòu)有豐富的多樣性,除了結(jié)構(gòu)化的數(shù)據(jù),也存在著非結(jié)構(gòu)化的圖像、聲音、影片及社交網(wǎng)站上的推廣性質(zhì)文章內(nèi)容等;
Veracity(真實性)——指數(shù)據(jù)本身可靠、可信,由于所有數(shù)據(jù)的存儲和采集,均由系統(tǒng)后臺無差別記錄、保存而成,因此能夠客觀、真實地反應(yīng)用戶狀態(tài)、需求、行為以及判斷。
由于大數(shù)據(jù)有以上特性,配合數(shù)據(jù)分析的技術(shù),能夠從海量的數(shù)據(jù)中分析得出有效信息,進而轉(zhuǎn)換成商業(yè)信息,協(xié)助企業(yè)科學(xué)地找出現(xiàn)象背后的本質(zhì)、了解目前的狀況,進而分析未來的趨勢。大數(shù)據(jù)的應(yīng)用范圍很廣泛,對于音樂產(chǎn)業(yè)而言更是意義重大,例如美國流媒體音樂服務(wù)商潘多拉(Pandora)靠用戶數(shù)據(jù)預(yù)測格萊美獎(Grammy Awards),靠用戶數(shù)據(jù)精準投放廣告,并為了讓優(yōu)秀的樂隊和歌手能被大眾聽到,為音樂人提供受眾數(shù)據(jù)分析工具AMP(Artist Marketing Platform),以幫助音樂人了解關(guān)于他們的受眾的數(shù)據(jù)(如收聽習(xí)慣等),以方便創(chuàng)作。
三、分析方法
本研究所用的分析方法主要涉及文字數(shù)據(jù)挖掘與情緒分析兩大方面。
文字數(shù)據(jù)挖掘文字數(shù)據(jù)挖掘(Text Mining)是針對文字數(shù)據(jù)進行分析的技術(shù),透過各種不同的量化技巧,試圖找出隱含且有助于決策之信息或知識。相較于傳統(tǒng)的數(shù)據(jù)挖掘主要是針對結(jié)構(gòu)化的數(shù)據(jù)進行挖掘,其主要針對半結(jié)構(gòu)化(semi-structured)或非結(jié)構(gòu)(unstructured)格式儲存之文字數(shù)據(jù)進行處理。文字數(shù)據(jù)挖掘是一種編輯、組織及分析大量文件的過程,以為特定的決策者提供特定的信息,以及發(fā)現(xiàn)隱藏的特征及其關(guān)聯(lián)。文字不像數(shù)值具有單位統(tǒng)一性質(zhì),其使用以及表達方式也是因人而異,因此,文字挖掘的技術(shù)最重要的就是將非結(jié)構(gòu)化或半結(jié)構(gòu)化文字或文件進行量化,再利用其屬性尋找出各文件之間的相關(guān)性或關(guān)鍵詞語——而如何將其進行結(jié)構(gòu)性量化,是文件挖掘最首要的目標。
文字數(shù)據(jù)不像數(shù)字或者運算公式是全球通用的,文字挖掘中文字數(shù)據(jù)的分析處理方法會因地區(qū)文化及語言使用習(xí)慣不同而有所異。例如:英文的“Together”這個詞,對計算機來說可以清楚地理解是一個單一的詞“在一起”,而不會認為是一句話“得到她”(to get her),這是因為英文語言由空格判斷字詞的位置;但是對于中文來說,并沒有可以進行字詞判斷的標準,如“你好不好”這句話可以斷詞為“你|好|不好”、“你|好不好”、“你好不|好”,而它們所產(chǎn)生的意思完全不同。
文字挖掘技術(shù)經(jīng)常應(yīng)用于處理分類議題,透過分類相關(guān)算法與技術(shù),將大量文件分門別類,以滿足檢索與分析的需求。文字挖掘分類技術(shù)可分成以下兩種方向,分別為“群集”(clustering)與“分類”(categorization)——群集法是將集合切割成不同的未知主題或特性的小群集,并在切割后找出屬于該群集的主題和特性;分類法則是依照已知的主題或特性進行分類,必須事先定義好集合。而由于分類法中類別集合為事先定義,因此可透過改善范本訓(xùn)練數(shù)據(jù)的精確程度及特征值,提升分類結(jié)果之準確率。
情緒分析情緒分析(Sentiment Analysis,或可稱“情感分析”)是指通過一些主題或文件的整體脈絡(luò)判斷或預(yù)測文本的情緒或者意見態(tài)度。情緒分析常用的分析方法是通過找出文字內(nèi)容和經(jīng)由人工標記的情緒類別,尋找文字跟情緒之間的關(guān)聯(lián)性。因此,當我們所搜集的關(guān)聯(lián)樣本足夠多,使得尋找出來文字與情緒之間的關(guān)聯(lián)性具有顯著相關(guān)性時,即可預(yù)測出未知情緒類別的文字內(nèi)容可能帶有的情緒。
情緒分析可區(qū)分為三種層級來討論,分別為字詞、語句、文章。大多數(shù)的相關(guān)研究在文章層級,根據(jù)文章中的圖釋預(yù)測作者表達的情感,并將圖釋作情緒分類,如喜、怒、哀、樂。最后發(fā)現(xiàn),若將情緒區(qū)分為正反兩面來做,SVM(Support Vector Machine,支持向量機)上的情緒分類效率是最高的。在情緒分類方面,Thayer二維情緒分類模型,將情緒分為四種,分別為滿足(contentment)、憂郁(depression)、熱情(exuberance)、焦慮/煩躁(anxious/frantic)。
就音樂的研究而言,以往的研究多借由音樂特征(旋律、節(jié)奏等)來區(qū)分能量(Energy)的程度,而壓力(Stress)的程度則多以歌詞內(nèi)容來區(qū)分。本研究的研究目標為歌詞,以壓力程度為情緒的分類目標,將熱門歌曲的歌詞分為“快樂”(正向)以及“焦慮”(負向)兩類情緒;另外,本研究并未搜集音樂特征數(shù)據(jù),因此情緒的能量(Energy)程度將不在探討范圍。在詞匯的情感傾向?qū)用妫狙芯繉⒃~語分為正面情感詞(如“開心”、“幸福”、“溫暖”等)和負面情感詞(如“墮落”、“放手”、“絕望”等)。另外特別標明了“程度詞”,即形容情感詞程度的詞匯,如“好幸福”中的“好”這類程度副詞,并且為其做了加權(quán)處理——“極其”、“最”的加權(quán)值為2,“超”、“非常”為 1.5,“很”為 1.25,“較”為1.2,“稍”為0.8,“缺”、“欠”等這類為0.5;而否定詞,例如“不”、“沒”、“無”、“非”、“莫”等標示為相反情感,如“不開心”則被標示為負面情感詞。
四、分析路徑
為利用SVM分類算法進行歌詞情感分類,歌詞數(shù)據(jù)須先經(jīng)過斷詞處理,并比對情感詞庫中詞的情感,最后選取出歌詞情感的特征值。按以下步驟操作:
(一)中文斷詞
詞為中文文章意義的最小單位,相較于英文文章中對于詞的處理,中文無法利用詞與詞之間的空格分辨出哪幾個字可組合成詞,因此若要對中文的文章運用詞進行分析,需要先經(jīng)過斷詞處理,將文章中的每個詞分隔出來才能運用。本研究采用開源的中文斷詞系統(tǒng)Jieba,進行歌詞的斷詞。例如:
如果|感情|會|掙扎,沒有|說的|儒雅;把|挽回的手|放下,鏡子里的|人|說|假話,違心的|樣子|你決定了嗎?……我們的|距離|到這|剛剛好,不夠|我們|擁抱|就|挽回不了,用力|愛過的|人|不該計較,是否|要逼人|棄了|甲,亮出|一條|傷疤,不堪的|根源|在哪,可是|感情|會掙扎,沒有|別的辦法|……再|(zhì)不爭|也|不吵,不必|再|(zhì)煎熬……天空|有些|暗了|暗的|剛剛好,我難過的|樣子|就|沒人看到,你|別|太在意|我身上的|記號。(選自薛之謙《剛剛好》)
(二)情感詞庫及比對
本研究整合HowNet(知網(wǎng))和“搜狗”中文情感詞庫作為比對范本。綜合詞庫可以表示概念之間以及其所帶有的屬性之間的關(guān)系。對于中文詞匯,“詞”是語句中的最基本概念,最小語義單位。由于中文中“詞”的含義非常復(fù)雜,往往在不同的情境中會表達不同的意義,因此在綜合對比詞庫中,將“詞”分為若干詞義的集合,包含2 812個正面情緒詞(如“開心”、“幸福”、“溫暖”等)與4 276個負面情緒詞(如“墮落”、“放手”、“絕望”等)。為分辨詞匯的情感,本研究整合情感詞匯、程度詞匯以及否定詞匯,比對歌詞,尋找歌詞中的情感特征值。如前文所述,程度詞指的是形容情感詞程度之詞匯,如“好幸福”中的“好”。要找出歌詞中帶有情感色彩的詞匯,須先將斷詞處理后的詞匯與情感詞庫中之情感詞匯進行比對,然后將比對結(jié)果標記于歌詞數(shù)據(jù)中。
例如對《剛剛好》的歌詞,系統(tǒng)會做出如下劃分:
正面情感——好、愛過、在意、儒雅……
程度詞——剛剛(好)、太(在意)、沒(+儒雅)、不夠、有些……
負面情感——掙扎、沒+儒雅、假話、違心、挽回不了、傷疤、不堪、煎熬、暗、難過……
可以初步得出一個結(jié)論,整首歌詞情緒非常負面,本就不多的正面情感詞匯前幾乎都加了否定詞,或者程度詞,而在本就很多的負面情感詞匯前還添加了程度詞,由此越顯得負面。
(三)SVM模型
SVM(Support Vector Machine)是在分類問題上經(jīng)常使用的數(shù)學(xué)模型,其主要的概念是將欲分類用的特征值建構(gòu)成一個多維度的超平面來分類數(shù)據(jù),利用訓(xùn)練用的范例數(shù)據(jù)向量分成相應(yīng)的類別,并尋找這個平面的邊界最大化。例如下頁圖1所示的原理:欲將圖中的黑點與白點利用SVM分類,SVM會尋找黑點所在的平面與白點所在的平面之間的界線——如圖中的深色線,兩條淺色線則用來示意兩平面上的點與黑線之間的距離w,而SVM的目標為尋找到擁有最大距離的黑線Max(w)。本研究將使用臺灣大學(xué)林智仁教授所開發(fā)的SVM工具套件 LIBSVM(Chang et al.,2011),利用R語言進行訓(xùn)練分類。
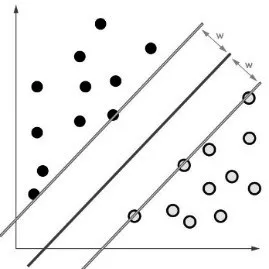
圖1 SVM分類原理示意圖
利用SVM分類算法進行歌詞自動分類,要先列出可能成為分類特征之特征值(見表格)。例如,將每首歌的歌詞先經(jīng)過Jieba斷詞系統(tǒng)將歌詞分為個別詞匯,接著將每個詞匯對照情感詞庫,找出每個詞匯的屬性,計算出正面情感與負面情感數(shù)量為特征值。

圖2 SVM訓(xùn)練模型運算參數(shù)格式
(四)比對分析
當利用SVM分類算法而建立的分類模型將所有歌曲歌詞情感分類完畢后,由統(tǒng)計出來的具有正負向歌詞的歌曲情況,可大略知道受眾對華語流行音樂歌詞情感喜好的畫像,例如大部分受眾喜好有正面情感歌詞的歌曲還是有負面情感歌詞的歌曲,同一年度中具有何種情感傾向的歌曲數(shù)量較多等等。當然,這里要說明的是,歌詞體現(xiàn)出來的負面情感,對于聽眾而言,并不一定都是負面影響,因為傷感的、消極的負面情感也是聽眾排遣自己傷感情緒的一種重要方式,因此,負面情感也有積極作用。
五、結(jié)論:歌詞情感公式及五年來呈現(xiàn)的規(guī)律
本研究最后利用數(shù)據(jù)可視化軟件Tableau將排行榜數(shù)據(jù)及依照時間序列分析后的結(jié)果進行可視化呈現(xiàn),以探討隱藏于其中之信息,如每年上榜的歌曲之歌詞情感是否會依照季節(jié)而變化等等。本研究將觀察統(tǒng)計時間切割為每月一次,查看每月中具有各類情感歌詞之歌曲的數(shù)量變化;將歌曲數(shù)量化為可公平比較的情感數(shù)值,讓每月都從相同的基準點出發(fā),以利于更精確地觀察熱門歌詞情感的變化。情感分數(shù)計算公式見下頁,其中Score(m)為某月的情感分數(shù),m(d)為該月份總天數(shù),d則為該月份的某個日期,SPd為該日期具有正面情感歌詞的歌曲總數(shù),SNd為該日期具有負面情感歌詞歌曲的總數(shù),最后會得到一個1與-1之間的分數(shù)Score(m)——若Score(m)>0,代表當月的歌詞情感以正面的為主,Score(m)<0則表示當月的歌詞情感以負面的為主。
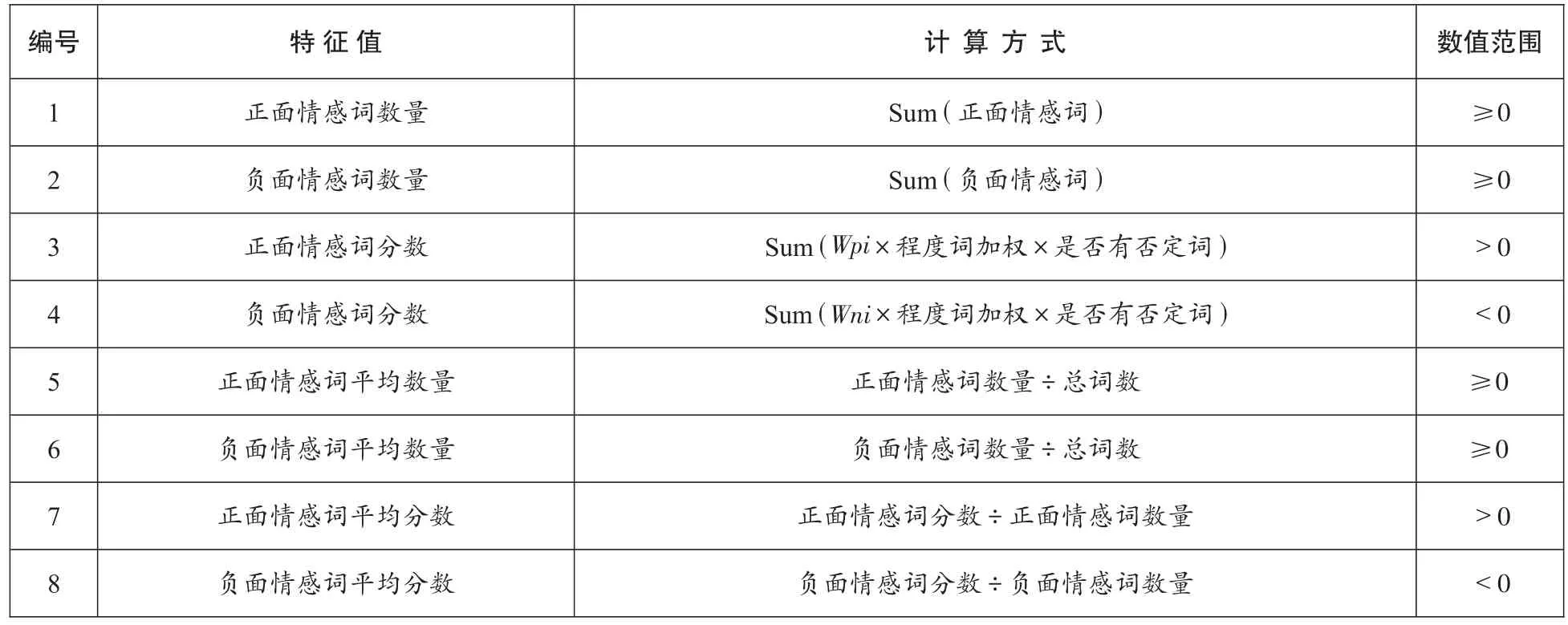
表格 可能成為歌詞分類特征的各個特征值

圖3 2011至2016年的每月情感分數(shù)變化

本研究將每月的歌詞情感數(shù)量標準化后得到每月情感分數(shù),并按時間序列畫出2011年至2016年每月情感分數(shù)變化的折線圖(如圖3)。由圖可見,上榜歌曲的情感分數(shù)皆為正數(shù),可認為受眾對具有“正面情緒”歌詞之歌曲有較高的偏好。另外,這五年間,歌曲的情感分數(shù)從原本的0.5分緩慢地減少至2016年的0.1分,由此可發(fā)現(xiàn),榜單雖以歌詞具有正面情感的歌曲為主,但卻有逐漸轉(zhuǎn)向具負面情感的趨勢,到2016年已經(jīng)表現(xiàn)出正面情感歌曲與負面情感歌曲接近持平的狀態(tài)。
此外,從圖中可以發(fā)現(xiàn),每年12月至來年3月之間,每月情感分數(shù)會出現(xiàn)一個高峰,7月和8月則呈現(xiàn)低點,可以觀察到歌曲情感偏向也有依季節(jié)(暑期、“畢業(yè)季”、“分手季”等)變化的趨勢。另外,從折線起伏變化中還能發(fā)現(xiàn)一些規(guī)律,例如當一部現(xiàn)象級的電影或者電視劇熱播之際,其主打歌或主題曲會帶來局部情感趨勢的波動,例如《平凡之路》、《匆匆那年》①《平凡之路》為電影《后會無期》插曲,該片上映時間為2014年7月;《匆匆那年》為同名電影主題曲,該片于2014年12月上映。——但由于是單首作品帶來的波動,不會對整體長期趨勢有實質(zhì)性影響。
大數(shù)據(jù)分析方法被越來越多地用于音樂等藝術(shù)的分析和使用上,隨著各大音樂流媒體終端和平臺逐漸成熟,該方法的影響力也將逐漸增大。本研究暫未將其他平臺的排行榜數(shù)據(jù)及用戶反饋采納入樣本,且只探討華語流行音樂,并未涉及其他語言或風(fēng)格的音樂如歐美、日韓歌曲甚至獨立制作之歌曲等。另外,本研究只針對音樂歌詞進行分析,探討其情感趨勢,其他音樂特征并未涉及。
今后的研究會著重從以下幾方面改善:首先,修正情感特征值,增加訓(xùn)練數(shù)據(jù)集,提升分類準確度;第二,加入其他在線音樂流媒體終端的排行榜數(shù)據(jù),增加熱門曲目判斷的依據(jù);第三,加入對其他音樂類型的考察,增加了解受眾喜好的途徑,尋找各音樂類型之間的關(guān)聯(lián);第四,結(jié)合歌曲的音樂特征,如節(jié)奏、旋律等,增加情感類別并提升分類的準確度;第五,結(jié)合不同的事件或新聞,探討華語流行音樂受眾對歌詞情感的喜好變化的原因。
[1]夏云慶、楊瑩、張鵬洲、劉宇飛《基于情感向量空間模型的歌詞情感分析》,載《中文信息學(xué)報》2010年第1期。
[2]V.N.Vapnik,The Nature of Statistical Learning Theory,New York:Springer,2000.
[3]“知網(wǎng)”信息庫。http://www.keenage.com/html/c_index.html
猜你喜歡
新世紀智能(高一語文)(2021年4期)2021-07-28 02:12:54
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
北方音樂(2017年4期)2017-05-04 03:40:39
人民音樂(2016年3期)2016-11-07 10:03:19
