基于N-Gram算法的數據清洗技術*
2017-02-10 03:12:10馬平全紀建偉
沈陽工業大學學報 2017年1期
關鍵詞:數據庫
馬平全, 宋 凱, 紀建偉
(1. 沈陽農業大學 信息與電氣工程學院, 沈陽 110866; 2. 沈陽理工大學 自動化與電氣工程學院, 沈陽 110159)
基于N-Gram算法的數據清洗技術*
馬平全1,2, 宋 凱1,2, 紀建偉1
(1. 沈陽農業大學 信息與電氣工程學院, 沈陽 110866; 2. 沈陽理工大學 自動化與電氣工程學院, 沈陽 110159)
針對數據庫中存在的大量相似重復數據,對相似重復記錄的屬性結構以及產生原因進行了分析,采用N-Gram算法對數據記錄進行計算,得到代表每條記錄屬性的鍵值,即N-Gram值.依據該鍵值將數據庫中的數據記錄進行排序處理,建立有序的數據庫,并對其中的數據記錄進行相似度計算.運用排列合并的清洗思想對識別出來的相似重復數據記錄進行清洗,實驗結果表明,N-Gram算法有效提高了相似重復數據記錄的查全率和查準率.
相似度; 相似重復記錄; 屬性; 排序; 合并; 數據清洗; 查全率; 查準率
在第二次世界大戰期間,信息傳遞給戰爭雙方帶來了極大的便利,在戰爭進行過程中,人們漸漸地發現信息的重要性,各方都在不斷地更新自己的信息處理機制,加速信息的獲取.這種形式促進了電子計算機的產生,并在戰爭中起到了舉足輕重的作用.戰爭結束以后,電子計算機作為一種新的技術被保留下來,并且不斷地被開發,漸漸走進了人們的生活,人類逐漸進入了信息化時代,信息技術成為每一位新時代人所必備的技術.
但隨著信息技術的不斷發展,數據量不斷增加,大量的錯誤數據充斥其中,相似數據、重復數據和字段缺失數據等,這些垃圾數據的出現給人們帶來了很大的不便,甚至會給一些企業機關單位帶來嚴重的后果[1-3].因此,針對這些數據進行數據清洗變得迫在眉睫.
1 相似重復數據產生的原因
相似重復記錄是指在合并數據集的過程中,同一目標實體往往有著多條記錄,這些記錄之間雖然在形式上有所不同,但其所描述的目標卻是相同的一個.通常造成這種結果的原因是由于數據錄入時錯誤的拼寫、對名詞的縮寫以及不同的存儲類型,導致同一記錄實體有著多種不同表現形式,但這些記錄往往本意上都是表現同一條數據記錄[4-5].由于這種特殊原因,造成了其數據特征并不明顯,這對相似重復記錄的識別以及對其進行數據清洗造成了很大的困難.因此,清除數據庫中的相似重復記錄是提高數據庫使用率、降低消耗、提高數據質量的一個重要途徑[6-7].
本文將相似重復記錄大致分為以下兩大類:
1) 完全重復記錄.這類記錄在數據庫中無論是字符還是數值,在屬性和表現形式上都是完全相同的.
2) 相似重復記錄.這類記錄是指在數據庫中部分屬性字段相同或者相似,但卻是同一記錄實體的不同表現形式[8-9].
2 數據清洗
數據清洗是指通過某種方式來清除數據集中“臟數據”的技術,經常作為提高數據使用率的一種途徑.到目前為止,數據清洗仍是一個模糊的概念,研究人員對數據清洗沒有給出一個標準定義,對數據清洗技術的理解仍是從字面意思上解釋的,比較通用的說法是數據清洗就是把數據庫中“臟”的數據記錄清洗掉,保留下“干凈”的數據記錄[10-11].
數據清洗的步驟與一般數據處理過程類似,主要內容包括如下幾個方面.
1) 數據分析.數據分析基本上是所有數據處理過程的首要步驟,通過詳細分析源數據庫,檢測源數據庫中的錯誤數據和不一致數據的情況,從而來判定數據質量上的問題.然而,如何準確了解數據集中的質量問題是個難點,而這個問題僅依靠既有的元數據并不能達到預期目的.這便需要對具體的數據實例進行數據分析,從中提取出能夠代表整條記錄的元數據,這些元數據能夠自動改變數據之間的屬性,本文稱之為依附性,然后重點對這些實例的屬性進行分析,才能發現其中的數據質量問題[12].
數據派生和數據挖掘都能夠較好地完成數據分析的任務,但兩者主要應用在不同的數據庫中.首先兩者最大的不同是作用范圍,數據派生主要是作用在單獨的屬性上,通過對單獨的屬性實例進行分析,從而得到大量的屬性信息,包括數據類型、數據單位、屬性沖突的次數和缺失信息的頻率等.而數據挖掘恰好與其相反,其主要應用在大型數據中心,通過對大型數據中心的海量信息進行分析,挖掘出屬性之間依賴關系和約束關系,這些關系往往是后期對多數據源中相似重復記錄進行數據清洗的一個重要依據,根據這些關系能夠較為完善地解決存在的問題[13-14].
2) 確定數據轉換規則和工作流.通過數據分析可得到一些信息,包括數據源的個數、錯誤數據的多少以及“臟數據”的主要類型等,通過這些信息建立合適的清洗步驟、轉換算法、查詢語句以及檢測算法等,從而確定主句轉換規則和工作流.
3) 數據驗證.在確定數據轉換規則和工作流之后,需要對其進行驗證,避免出現效率低下等問題.從數據源中抽出一部分數據當作樣本數據,然后利用上一步確定的數據轉換規則和工作流對抽出來的樣本進行驗證,并對驗證結果進行分析,對工作流和轉換規則進行相應的調整和改進[15-16].數據驗證這一過程往往需要進行多次,以達到盡可能高的效率以及高精度地進行數據清洗.
4) 數據清洗.在數據驗證過程中,對選擇的清洗策略進行了驗證,確定其可行性,并利用該策略進行數據清洗操作,數據清洗的流程如圖1所示.
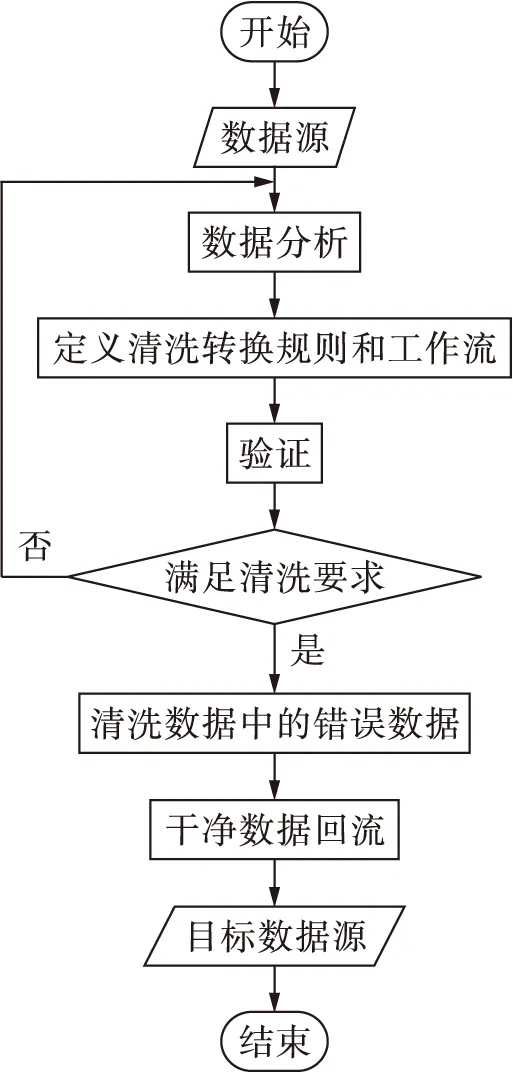
圖1 數據清洗流程Fig.1 Flow chart of data cleaning
3 N-Gram算法
N-Gram算法是一種大詞匯連續語音識別中常用的語言模型,它遵循的思想是每一條數據的出現都有一定的概率,通過假設數據中所有詞的出現都會影響其之后的詞,但對已出現的詞并沒有任何影響.通過這種思想可以認為整條記錄的出現都有一定的概率,與記錄中的每一個詞均有關系.因此,本文根據每個詞出現的概率,給每條記錄計算出一個鍵值,即N-Gram值,該值在一定程度上代表了該條記錄的屬性,屬性越相近,相似程度越高,該值在數值上就越接近.根據這種特性對數據源中所有的數據進行排序能夠將相似重復數據放到一起.
當某條記錄中第N個詞的出現概率并不是隨機出現時,而是與這條記錄的前N-1個詞息息相關,并且僅與這N-1個詞有關,與第N個詞后面的詞都沒有關系,每個詞出現的概率相乘,便得到整條數據記錄出現的概率,而每個詞出現的概率都可以直接從所有數據記錄的語料庫和重復矩陣中計算得到,這便是N-Gram算法模型.
統計語言模型的數學模型表達式為
(1)
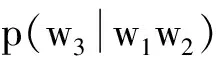
(2)
式(2)即為“馬爾可夫假設”.二元的Bigram認為,每條語句中的所有詞僅和其前面最相近的那個詞有關,與其他任何詞都無關,則其概率表達式為
P(S)=P(w1w2…wn)=
(3)
三元的Trigram假設下一個詞的出現僅依賴于其前面的兩個詞,則其概率表達式為
(4)
算法過程描述如下.
1) 數據預處理.在進行數據清洗之前,首先對待清洗的數據進行數據預處理,將其中無法識別的字符串或者帶有標識性含義的標點進行處理,例如銀行系統中常用的“¥”和“$”符號,以及處于對數據保密的原因所進行的加密處理符號“*”,這些字符串在后期進行數據清洗的時候,由于其具有相似性,會對清洗結果的準確性產生很大的影響.
例如,待清洗的數據庫中有如下5條數據:
①Johnny·Depp,California,PrincetonUniversity,Computer
②Tom·Hanks,Districtofcolumbia,HarvardUniversity,philosophy
③Tom·Hanks,Districtcolumbia,HarvardUniversity,philosophy
④Adam·Sandler,Alabamas,UniversityofCaliforniaBerkeley,PhysicalScience
⑤Leonardo·Dicaprio,Connecticut,UniversityofSou-thernCalifornia,Biology
對它們進行預處理之后的結果如下:
① s1=johnnydeppcaliforniaprincetonuniversityco-mputer
② s2=tomhanksdistrictofcolumbiaharvardunivers-ityphilosophy
③ s3=tomhanksdistrictcolumbiaharvarduniversit-yphilosophy
④ s4=adamsandleralabamasuniversityofcaliforni-aberkeleyphysicalscience
⑤ s5=leonardodicaprioconnecticutuniversityofs-outherncaliforniabiology
2) 建立語料庫.掃描整個待清洗數據庫,根據N-Gram算法精度建立語料庫.當N值為2時,語料庫中每一個元素字符串的長度則為1,建立上述5條待清洗記錄的語料庫,如表1所示.
3) 分 割數據記錄,計算重復矩陣.按照N-Gram算法將這5條字符串分割成元字符串,例如,當N值為2時,這5條字符串經過N-Gram算法分割后得到的字符串數組如下:
S1={“jo”,“oh”,“hn”,“nn”,…,“ut”,“te”,“er”}
S2={“to”,“om”,“mh”,“ha”,…,“op”,“ph”,“hy”}
S3={“to”,“om”,“mh”,“ha”,…,“op”,“ph”,“hy”}
S4={“ad”,“da”,“am”,“ms”,…,“en”,“nc”,“ce”}
表1 待清洗記錄語料庫
Tab.1 Corpus of records to be cleaned

名稱數量a24b5c16d9名稱數量e17f6g1h11名稱數量i31j1k3l13名稱數量m7n20o24p10名稱數量q0r21s16t16名稱數量u10v7w0x0名稱數量y11z0
S5={“le”,“eo”,“on”,“na”,…,“lo”,“og”,“gy”}
對這些字符串數組建立重復矩陣M.在重復矩陣中,M(a,b)代表“ab”在整個數據庫中的數量,則有

4) 計算N-Gram值.根據式(4)及語料庫和重復矩陣,對這5條待清洗數據記錄進行計算,得到它們的N-Gram值,即
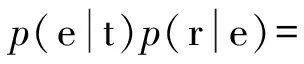
(p(jo)/p(o))(p(oh)/p(h))(p(hn)/p(n))…(p(er)/p(r))=
4.9×10-37
(5)
P(S2)=7.411×10-36
(6)
P(S3)=4.447×10-35
(7)
P(S4)=1.9e×10-51
(8)
P(S5)=3.7×10-50
(9)
5) 對數據進行清洗.根據步驟4)所得到的N-Gram值對待清洗數據記錄進行排序,對所得到的排序結果采用基本的字段匹配算法計算數據記錄之間的相似度,當相似度低于規定的閾值時,則判定兩者為相似重復記錄.
4 實驗結果及分析
本文根據上述算法設計了一個基于N-Gram算法的相似重復記錄數據清洗流程,通過查全率、查準率和運行速度3個因素對數據清洗過程和基于S-W算法的數據清洗技術進行對比.
查全率是評判數據清洗技術好壞的一個重要指標,查全率越高,代表所檢查出來的相似重復記錄越多,在一定程度上能夠代表數據清洗技術的性能.圖2為查全率曲線圖.從圖2中可以看出,在查全率方面,本文提出的算法較S-W算法有較大的優勢,且隨著數據量的不斷增加,兩種算法的查全率都在不斷遞增.
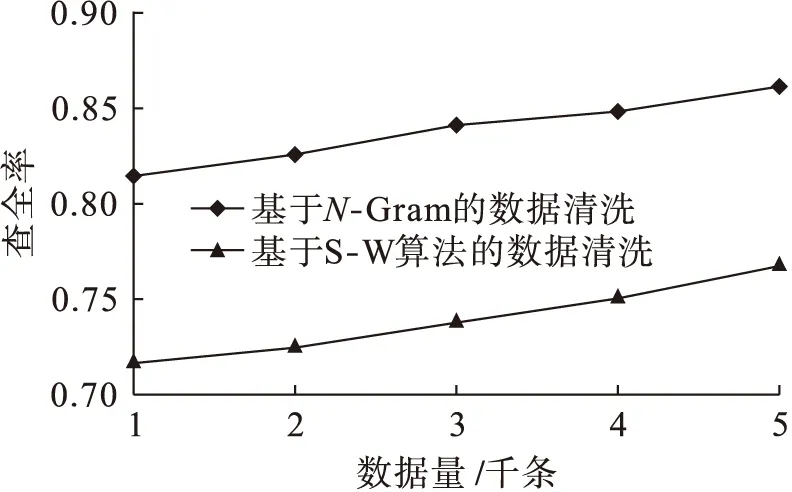
圖2 查全率Fig.2 Recall ratio
查準率是評判數據清洗技術好壞的重要指標,是指所檢測出來的相似重復記錄中確實為相似重復記錄的比例,能夠真實地反映出一個算法的好壞.圖3為查準率曲線圖.從圖3中可以看出,本文提出的算法較S-W算法有較大優勢,雖然隨著數據量的不斷增加,該優勢有所減緩,但結合查全率的優勢可以看出本文算法的優點.
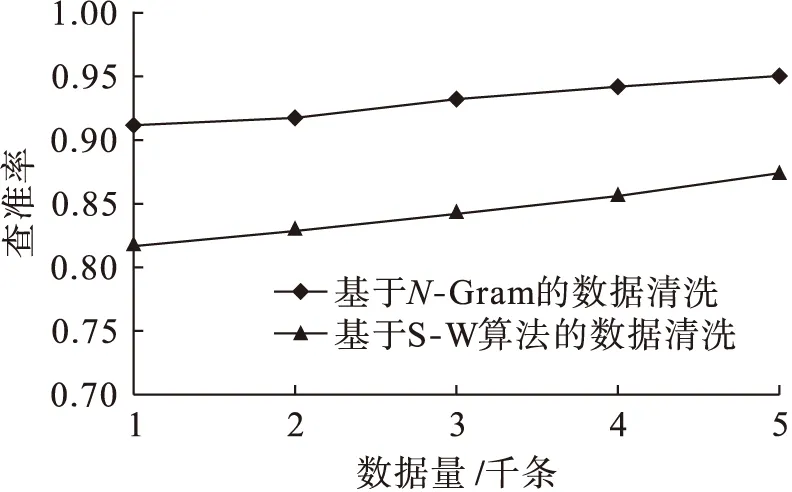
圖3 查準率Fig.3 Precision ratio
隨著信息的不斷發展,數據記錄的不斷增多,運行時間也作為評判一個算法好壞的標準,本文對兩種算法的運行時間進行了對比,結果如圖4所示.從圖4中可以看出,數量級較低時,S-W算法較本文算法具有較大優勢,隨著數量級的不斷增多,S-W算法的運行時間增長迅速,超過本文算法所提出的數據清洗算法運行時間.
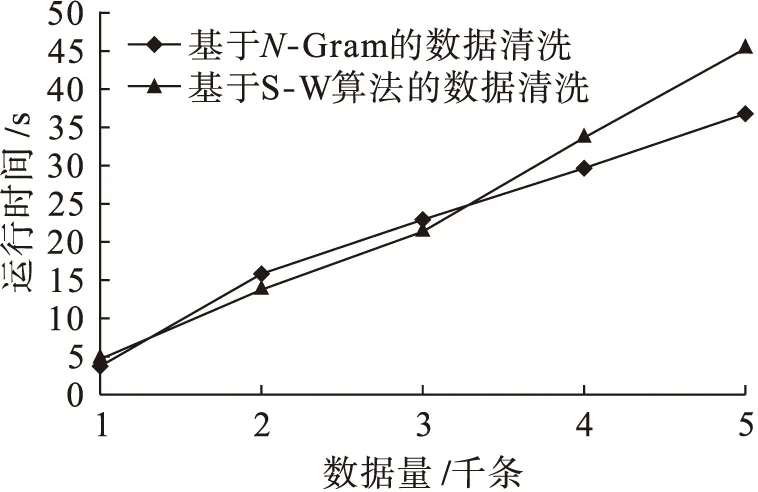
圖4 運行時間對比Fig.4 Runtime comparison
5 結 論
通過對相似重復數據記錄的結構及產生原因進行分析,提出了一種基于N-Gram算法的相似重復記錄的數據清洗技術.該方法通過計算數據記錄之間的N-Gram值,將待清洗記錄進行排序,并對排序后的結果進行相似度檢測,從而提高了相似重復記錄的查全率和查準率,且隨著數量級的不斷增加,本文算法的運行時間優于其他算法.
[1]楊東華,李寧寧,王宏志,等.基于任務合并的并行大數據清洗過程優化 [J].計算機學報,2016,39(1):97-108.
(YANG Dong-hua,LI Ning-ning,WANG Hong-zhi,et al.The optimization of the big data cleaning based on task merging [J].Chinese Journal of Computers,2016,39(1):97-108.)
[2]羅景峰,劉艷秋,許開立.基于均勻設計與灰局勢決策的智能算法參數設定 [J].沈陽工業大學學報,2010,32(1):84-89.
(LUO Jing-feng,LIU Yan-qiu,XU Kai-li.Parameter establishment of intelligent algorithm based on uniform design and grey situation decision [J].Journal of Shenyang University of Technology,2010,32(1):84-89.)
[3]陳明.大數據分析 [J].計算機教育,2014(5):122-126.
(CHEN Ming.Big data analysis [J].Computer Education,2014(5):122-126.)
[4]吳斐,唐雁,補嘉.基于N-Gram的VB源代碼抄襲檢測算法 [J].重慶理工大學學報(自然科學),2012,26(2):86-91.
(WU Fei,TANG Yan,BU Jia.A VB source code plagiarism detection method based onN-Gram [J].Journal of Chongqing University of Technology (Natural Science),2012,26(2):86-91.)
[5]邵林,黃芝平,唐貴林,等.并行緩存結構在高速海量數據記錄系統中的應用 [J].計算機測量與控制,2008,16(4):527-529.
(SHAO Lin,HUANG Zhi-ping,TANG Gui-lin,et al.Application of parallel cache structure in high-speed mass data recording system [J].Computer Measurement and Control,2008,16(4):527-529.)
[6]周典瑞,周蓮英.海量數據的相似重復記錄檢測算法 [J].計算機應用,2013,33(8):2208-2211.
(ZHOU Dian-rui,ZHOU Lian-ying.Algorithm for detecting approximate duplicate records in massive data [J].Journal of Computer Applications,2013,33(8):2208-2211.)
[7]付印金,肖儂,劉芳.重復數據刪除關鍵技術研究進展 [J].計算機研究與發展,2012,49(1):12-20.
(FU Yin-jin,XIAO Nong,LIU Fang.Research and development on key techniques of data deduplication [J].Journal of Computer Research and Development,2012,49(1):12-20.)
[8]Lillibridge M,Eshghi K,Bhagwat D.Improving restore speed for backup systems that use inline chunk-based deduplication [C]//Proceedings of the 11th USENIX Conference on File and Storage Technologies.New York,USA,2013:183-197.
[9]朱燦,曹健.實體解析技術綜述與展望 [J].計算機科學,2015,42(3):8-12.
(ZHU Can,CAO Jian.Summary and prospect on entity resolution [J].Computer Science,2015,42(3):8-12.)
[10]王琛.Web數據清洗及其系統框架研究 [J].計算機時代,2014(12):42-44.
(WANG Chen.Research on Webdata cleaning and its system framework [J].Computer Era,2014(12):42-44.)
[11]Geerts F,Mecca G,Papotti P,et al.The LLUNATIC data-cleaning framework [J].VLDB Endowment,2013,6(9):625-636.
[12]Tan Y J,Jiang H,Sha H M,et al.SAFE:a source deduplication framework for efficient cloud backup ser-vices [J].Journal of Signal Processing Systems,2013,72(3):209-228.
[13]殷秀葉.大數據環境下的相似重復記錄檢測方法 [J].武漢工程大學學報,2014,36(3):66-69.
(YIN Xiu-ye.Method for detecting approximately duplicate database records in big data environment [J].Journal of Wuhan Institute of Technology,2014,36(3):66-69.)
[14]Nguyen T T,Hui S C,Chang K.A lattice-based approach for mathematical search using formal concept analysis [J].Expert Systems with Applications,2012,39(5):5820-5828.
[15]黨小超,高琪,郝占軍.基于小波變換的分布式WSN數據融合模型研究 [J].計算機工程與應用,2014,50(22):97-101.
(DANG Xiao-chao,GAO Qi,HAO Zhan-jun.Research on model of distributed date aggregation in WSN based on wavelet transform [J].Computer Engineering and Applications,2014,50(22):97-101.)
[16]譚霜,何力,陳志坤,等.云存儲中一致基于格的數據完整性驗證方法 [J].計算機研究與發展,2015,52(8):1862-1872.
(TAN Shuang,HE Li,CHEN Zhi-kun,et al.A method of provable data integrity based on lattice in cloud storage [J].Journal of Computer Research and Deve-lopment,2015,52(8):1862-1872.)
(責任編輯:鐘 媛 英文審校:尹淑英)
Data cleaning technology based onN-Gram algorithm
MA Ping-quan1,2, SONG Kai1,2, JI Jian-wei1
(1. College of Information and Electrical Engineering, Shenyang Agricultural University, Shenyang 110866, China; 2. School of Automation and Electrical Engineering, Shenyang Ligong University, Shenyang 110159, China)
Aiming at the plentiful approximately duplicate data in the database, the attribute structure of approximately duplicate records and the causing reason were analyzed. The data records were calculated with theN-Gram algorithm to get the key values, namelyN-Gram values, which represented the attribute of every record. According to the key values, the data records in the database were ordered so as to form a well-organized database. In addition, the similarity of data records in the database was calculated. The identified approximately duplicate records were cleaned by applying the arranged combination cleaning idea. The experimental results show that theN-Gram algorithm effectively increases the recall ratio and precision ratio of approximately duplicate data records.
similarity; approximately duplicate record; attribute; ordering; combination; data cleaning; recall ratio; precision ratio
2016-06-28.
遼寧省教育廳科學研究項目(LG201610).
馬平全(1975-),男,遼寧丹東人,講師,博士生,主要從事信號檢測與處理等方面的研究.
17∶40在中國知網優先數字出版.
http:∥www.cnki.net/kcms/detail/21.1189.T.20161222.1740.040.html
10.7688/j.issn.1000-1646.2017.01.13
TP 311.11
A
1000-1646(2017)01-0067-06
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
