面向Java程序包的代碼概要自動(dòng)生成技術(shù)研究*
2017-02-20 10:48:10孫小兵
計(jì)算機(jī)與生活 2017年2期
柳 郁,孫小兵,2+,李 斌,2
1.揚(yáng)州大學(xué) 信息工程學(xué)院,江蘇 揚(yáng)州 225127
2.南京大學(xué) 計(jì)算機(jī)軟件新技術(shù)國家重點(diǎn)實(shí)驗(yàn)室,南京 210023
面向Java程序包的代碼概要自動(dòng)生成技術(shù)研究*
柳 郁1,孫小兵1,2+,李 斌1,2
1.揚(yáng)州大學(xué) 信息工程學(xué)院,江蘇 揚(yáng)州 225127
2.南京大學(xué) 計(jì)算機(jī)軟件新技術(shù)國家重點(diǎn)實(shí)驗(yàn)室,南京 210023
程序理解是從軟件程序中獲得抽象在程序中的功能和知識(shí)的過程,對(duì)軟件維護(hù)有著重要的意義。研究表明,軟件維護(hù)消耗了軟件預(yù)算的50%到80%,而其中大概47%到62%的維護(hù)時(shí)間用于對(duì)軟件系統(tǒng)的理解上。提出了一種面向Java程序的包概要方法,嘗試從軟件的語義層次出發(fā),利用信息索引領(lǐng)域的潛在語義分析和數(shù)據(jù)挖掘領(lǐng)域的聚類算法對(duì)軟件程序中的語義信息進(jìn)行提取分析。對(duì)相似詞匯的代碼文件進(jìn)行聚類,并從中提取話題對(duì)Java程序中的包進(jìn)行刻畫;對(duì)這些話題進(jìn)行語義恢復(fù),并利用MiniPar,一個(gè)英文詞法分析器,來輔助生成程序中包的概要信息。實(shí)驗(yàn)結(jié)果表明該方法能夠改進(jìn)程序理解的效率。
程序理解;潛在語義分析;聚類;話題;概要化
1 引言
軟件系統(tǒng)生存期往往長(zhǎng)達(dá)數(shù)十年,長(zhǎng)時(shí)間的軟件維護(hù)與演化使得遺留軟件系統(tǒng)中包含了眾多知識(shí),包括源代碼、文檔等。這些遺留軟件有兩大特征:海量的代碼文件和過時(shí)的說明文檔。長(zhǎng)時(shí)間的運(yùn)行和升級(jí),使得遺留軟件系統(tǒng)中的程序代碼和說明文檔不一致,導(dǎo)致所維護(hù)的代碼變得復(fù)雜和難以理解。據(jù)統(tǒng)計(jì),在軟件維護(hù)過程中,高達(dá)60%的時(shí)間花費(fèi)在軟件理解上,特別是對(duì)程序代碼的理解[1-2]。在軟件理解過程中,源程序成為程序理解的主要信息來源。程序理解是從軟件系統(tǒng)程序中獲得抽象在程序中的功能和知識(shí)的過程[3]。程序代碼中包含兩方面的信息:一方面是基于程序組成部分間的依賴關(guān)系形成的結(jié)構(gòu)信息[4-5];另一方面是凝結(jié)著開發(fā)員知識(shí)的語義信息[6]。正是這些程序代碼中包含著自然語言信息的標(biāo)識(shí)符和注釋內(nèi)容,可以方便開發(fā)人員對(duì)程序語義功能方面的理解。
以往的程序理解技術(shù)注重對(duì)程序結(jié)構(gòu)的分析[5],通過對(duì)源程序的剖析,檢查每個(gè)程序文件的程序設(shè)計(jì)結(jié)構(gòu),追蹤對(duì)象的繼承、依賴關(guān)系,分析程序的數(shù)據(jù)結(jié)構(gòu)、標(biāo)準(zhǔn)算法和控制流程。通過圖形方式將這些信息反饋給開發(fā)維護(hù)人員,如程序的抽象語法樹、類繼承視圖、函數(shù)調(diào)用圖等。相比較而言,近來基于語義信息的程序理解方法更注重于理解程序語義功能,特別是能自動(dòng)生成與代碼對(duì)應(yīng)的概要,這樣有助于開發(fā)人員直接根據(jù)這些概要來理解程序代碼,特別是對(duì)于那些無文檔或者文檔較少的程序代碼,這些概要能夠輔助理解這些代碼。
基于語義信息的方法通常是利用程序代碼中所包含的語義信息進(jìn)行分析,根據(jù)最終提取的話題來幫助理解程序。例如,Maletic等人利用潛在語義分析技術(shù)對(duì)一款Moisc軟件的代碼與文檔進(jìn)行語義分析輔助對(duì)程序的理解[7]。Kuhn等人利用語義聚類的方法對(duì)幾個(gè)開源項(xiàng)目(如JEdit、JBoss等)的程序代碼進(jìn)行分析理解[8]。然而這些方法所提取的話題由多個(gè)獨(dú)立的單詞組成,在語義上缺乏連貫性,需要程序開發(fā)、維護(hù)人員事先對(duì)軟件系統(tǒng)有一定的理解。本文嘗試?yán)谜Z義恢復(fù)的方法解決這一問題。以軟件程序中的語義信息作為分析材料,通過信息檢索等技術(shù)提取能夠表征系統(tǒng)的話題,并利用語義恢復(fù)方法對(duì)話題的語義進(jìn)行恢復(fù),利用MiniPar[9]輔助生成對(duì)軟件程序的概要信息。本文目的在于:
(1)分析包結(jié)構(gòu)的語義成分。不同功能模塊間的詞匯存在差異,通過分析包結(jié)構(gòu)的語義成分,可以得到包的功能組成。
(2)生成包層次的概要信息。可以在包層次生成概要信息,這些概要信息反映了程序包的統(tǒng)計(jì)信息和語義信息兩部分,有助于開發(fā)人員迅速理解程序。
本文組織結(jié)構(gòu)如下:第2章介紹研究方法所使用到的信息檢索和數(shù)據(jù)挖掘技術(shù);第3章詳細(xì)地介紹本文方法;第4章進(jìn)行案例分析和實(shí)驗(yàn)評(píng)估;最后對(duì)方法進(jìn)行總結(jié)和展望。
2 技術(shù)簡(jiǎn)介
2.1 潛在語義分析
潛在語義分析(latent semantic indexing,LSI)是信息檢索技術(shù)中常用的技術(shù)[10-11],利用數(shù)學(xué)上的奇異值分解(sigular value decomposition,SVD)來分析術(shù)語和概念間的關(guān)系模式,并以良好的降維、降噪著稱[10]。潛在語義分析被廣泛運(yùn)用到信息檢索和文本處理中,如論文審核、文檔分類等應(yīng)用中[12]。
在潛在語義分析技術(shù)中,文檔集合被表示為術(shù)語和文檔矩陣(term-document matrix),矩陣的每一列表示一個(gè)文檔,矩陣的每一行表示一個(gè)術(shù)語。對(duì)于矩陣的每一個(gè)單元ai,j,表示術(shù)語ti出現(xiàn)在文檔dj中的頻率。對(duì)于一個(gè)m行n列的文本空間,奇異值分解將其分解為3個(gè)矩陣:一個(gè)m行r列的術(shù)語矩陣、一個(gè)r行r列的奇異值矩陣和一個(gè)r行n列的文檔矩陣[11]。奇異值分解將奇異值矩陣截取為k階,k遠(yuǎn)遠(yuǎn)小于r。類似地將術(shù)語矩陣截取到m行k列,將文檔矩陣截取到k行n列,于是可以得到原始矩陣的一個(gè)只有k階近似的矩陣,這個(gè)矩陣保留了原始矩陣中盡可能多的信息,但將它們拆分到了更小維度。人們不僅可以得到近似矩陣,還可以得到術(shù)語與術(shù)語的關(guān)系矩陣以及文檔與文檔的關(guān)系矩陣,因此利用LSI可以實(shí)現(xiàn)對(duì)術(shù)語與文檔、術(shù)語與術(shù)語以及文檔與文檔的相似度計(jì)算。文檔的相似度通常采用余弦相似度來表示,對(duì)于兩個(gè)文檔向量A和B,它們之間的相似度可以表示為:
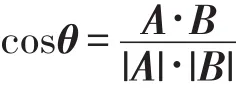
總的來說,潛在語義分析以一個(gè)術(shù)語文檔矩陣作為輸入,出于對(duì)術(shù)語出現(xiàn)頻率的考慮,需要對(duì)文本空間進(jìn)行加權(quán),常用的加權(quán)算法為TF-IDF[13-14]。TFIDF加權(quán)算法由兩部分組成,術(shù)語頻率(tf)和逆文件頻率(idf),權(quán)重由這兩部分相乘得到,即w=tf*idf。SVD對(duì)原始文本空間進(jìn)行分解,并將其截取到較低的維度,同時(shí)保存了原始文本空間盡可能多的信息。
2.2 聚類算法
聚類是將對(duì)象集合分成由類似的對(duì)象組成的多個(gè)類的過程。聚類算法有多種,傳統(tǒng)的算法有:劃分方法如K-means算法,層次方法如AHC(agglomerative hierarchical clustering)算法,基于密度的方法如DBSCAN(density-based spatial clustering of application with noise)算法等[15-16]。本文使用自下向上的層次聚類算法(AHC算法)[15,17]。
層次聚類算法又叫樹聚類算法,它根據(jù)數(shù)據(jù)的聯(lián)接規(guī)則,通過層次架構(gòu)方式,反復(fù)將數(shù)據(jù)進(jìn)行分割或者聚合,來解決層次序列的聚類問題。AHC算法是一種自下向上的層次聚類方法,實(shí)質(zhì)是自下向上合并為一棵層次樹的過程[17]。初始每個(gè)對(duì)象對(duì)當(dāng)作一個(gè)聚類,兩個(gè)聚類根據(jù)其相似度或者距離合并成一個(gè)聚類。這里利用余弦距離來表示兩個(gè)聚類間的距離或者相似性。
3 程序概要化技術(shù)
隨著程序的不斷修改,程序文檔會(huì)過時(shí)或者有些文檔會(huì)丟失,這給開發(fā)人員理解程序帶來了困難,如果能自動(dòng)生成程序代碼的概要,可有效幫助開發(fā)人員理解程序。
而在軟件開發(fā)過程中,相同類型的文件如功能往往被歸檔在一個(gè)包文件中,即包往往是某一功能的集合。另外,包文件通常包含足夠多的代碼文件,也就是說包含一定的語義信息。本文主要以Java程序中包層次作為語料庫進(jìn)行分析,本部分將對(duì)技術(shù)細(xì)節(jié)進(jìn)行詳細(xì)介紹。
3.1 技術(shù)流程
本文的技術(shù)方法分為4部分,如圖1所示。首先從軟件程序中提取語義信息;接下來是對(duì)這些語料信息進(jìn)行預(yù)處理,包括組合詞分割、去除停用詞等;然后利用潛在語義分析技術(shù)和聚類技術(shù)提取軟件程序中的話題并恢復(fù)這些話題的語義信息;最后生成相應(yīng)的概要信息。
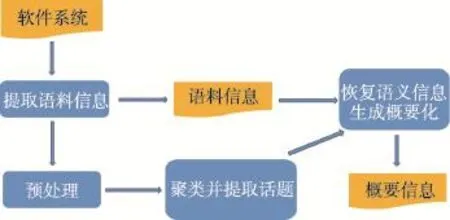
Fig.1 Process of this paper approach圖1 方法流程
3.2 實(shí)現(xiàn)方法
3.2.1 預(yù)處理
由于目標(biāo)對(duì)象是軟件程序代碼,其中存在著許多影響信息檢索技術(shù)有效性的元素,如程序代碼中包含大量無語義的邏輯代碼,一個(gè)單詞的多種詞形,注釋中包含常見無意義單詞,文本長(zhǎng)度和單詞出現(xiàn)頻率不一致問題等。
在預(yù)處理階段,從提取源碼中的類名、方法名、屬性和注釋入手,按照J(rèn)ava的編程風(fēng)格規(guī)范,標(biāo)識(shí)符必須有一定的含義,開發(fā)人員在編寫代碼時(shí)將具體的對(duì)象、業(yè)務(wù)流程轉(zhuǎn)化為具有一定含義的代碼。類名、方法名、屬性和注釋最集中反映了這些語義信息。為了解決以上的各種問題,按照如下的流程進(jìn)行預(yù)處理操作。
(1)組合詞分割。Java代碼通常遵從一定的編碼風(fēng)格,如駝峰風(fēng)格,在標(biāo)識(shí)符命名上也往往由多個(gè)有具體含義的單詞組成。在類名命名上,往往由多個(gè)大寫字母開頭的單詞組成,如FileFilter、IOException等。在屬性命名上和方法名類似,第一個(gè)單詞小寫,如果其后又有單詞,則其后的單詞首字母大寫,如getTime、arrayCopy等。本文按照這些命名規(guī)則,將提取的類名、方法名、屬性名和注釋進(jìn)行分割得到獨(dú)立的單詞。
(2)去除停用詞。在提取的詞匯中,會(huì)包含一些沒意義的詞,如do、doing、of、in、everything等,這些沒用的信息需要排除,本文利用自定義的停用詞表來去除停用詞。
(3)截取詞干[18]。在文本中,相同含義的單詞會(huì)有不同的形式,以remove為例,有removing、removed、removes等形式,可以將單詞截取到remove詞根。這樣做的好處是可以降低文本空間,避免話題中出現(xiàn)同詞根的情況。
(4)加權(quán)。原始的術(shù)語文檔矩陣中,每一個(gè)單元表示相應(yīng)術(shù)語在文檔中出現(xiàn)的次數(shù)。這種表示方法在文檔長(zhǎng)度不同以及部分詞匯在文檔集中大量或較少出現(xiàn)的情況下存在著較大的不合理性。本文采用TF-IDF算法進(jìn)行加權(quán)。
3.2.2 聚類和話題提取
在該步驟中,通過對(duì)包含相似詞匯的文檔進(jìn)行聚類,并根據(jù)單詞和聚類的相似度提取前n個(gè)單詞作為對(duì)應(yīng)聚類功能的描述。在使用層次聚類過程中,為了降低空間維度以及去除原始空間的噪音,首先利用潛在語義分析獲得原始文本空間的近似空間[6,9,11]。由于每個(gè)文檔由組成它的詞組向量表示,文檔間的相似度可以通過兩個(gè)文檔向量的余弦距離表示,兩個(gè)文檔向量間夾角越小,兩個(gè)文檔越相似,余弦距離的絕對(duì)值越接近1,否則余弦距離接近0。在層次聚類中根據(jù)對(duì)象間的距離進(jìn)行聚類,需要將相似關(guān)系轉(zhuǎn)化為距離關(guān)系,可以采用如下公式:
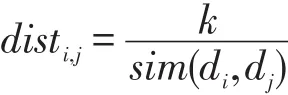
通過層次聚類,可以獲得文本空間聚類的基本分布情況,由此可以劃定聚類個(gè)數(shù)。不同的功能使用不同的詞匯,聚類的結(jié)果反映了包中所包含的功能。根據(jù)單詞和聚類的相似度對(duì)包的聚類進(jìn)行話題提取,取前5個(gè)單詞組成對(duì)聚類描述的話題。
3.2.3 生成概要信息
在這一階段,將已經(jīng)提取的話題去匹配標(biāo)識(shí)符中的組合詞。這樣做的目的是因?yàn)樵谠~匯的提取過程中,需要對(duì)組合詞進(jìn)行分割。比如方法名getTime被分解為get和time兩個(gè)單詞,getTime所反映的信息是獲取時(shí)間,當(dāng)話題提取到這兩個(gè)單詞的任何一個(gè)時(shí)都無法完整表示其本來的語義信息。本文嘗試通過利用已提取的話題,去查找匹配頻率較高的組合詞,獲取該話題可能代表的語義信息。
Java的代碼風(fēng)格使得人們可以根據(jù)標(biāo)識(shí)符來獲得更多的信息。Java的類名往往由一個(gè)或多個(gè)名詞組成,屬性也類似,方法名通常由動(dòng)詞開頭接上名詞或者由名詞組成。本文將這些組合詞再次分割,并將分割后的多個(gè)單詞作為輸入,利用MiniPar來進(jìn)行詞性分析。這樣根據(jù)話題匹配的結(jié)果可以定義概要的生成規(guī)則如表1所示。
對(duì)于最終包的概要內(nèi)容,本文主要提供兩個(gè)統(tǒng)計(jì)信息和兩個(gè)分析信息。這兩個(gè)統(tǒng)計(jì)信息是包中所含類的個(gè)數(shù)和包的聚類個(gè)數(shù)以及聚類分布情況;另外,提供包總聚類的話題以及根據(jù)這些話題分析生成的概要信息。預(yù)設(shè)生成的概要模式如下:

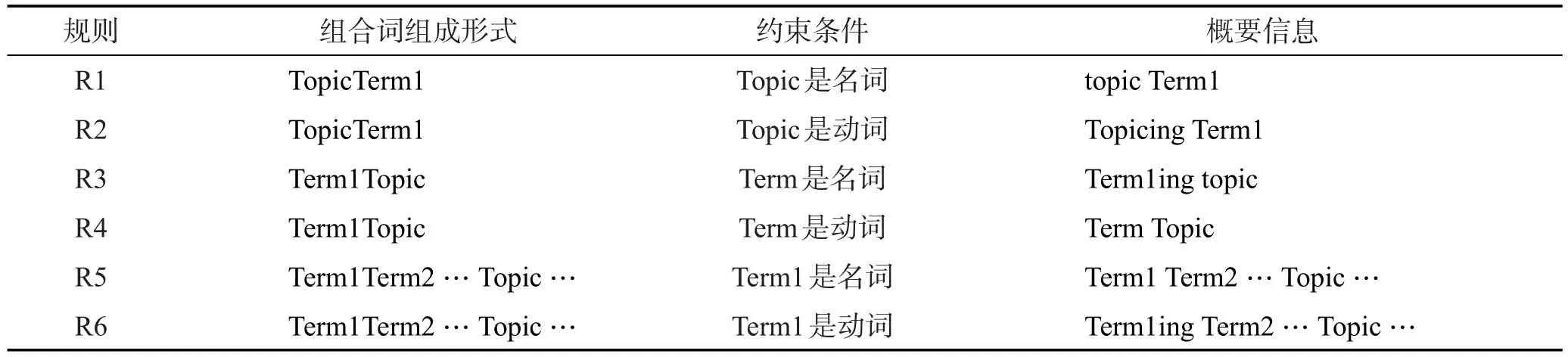
Table 1 Rules to generate summarization表1 概要信息生成規(guī)則
3.3 一個(gè)實(shí)際系統(tǒng)案例分析
這里選取了Eclipse環(huán)境中的IO包作為分析對(duì)象。首先載入需要分析的包文件,預(yù)處理程序?qū)?huì)從程序文件提取出含有語義信息的類名、方法名、屬性和注釋內(nèi)容,并對(duì)其中的組合詞進(jìn)行分割。本文利用潛在語義分析建立術(shù)語文檔矩陣。
IO包中含有85個(gè)類文件,31 335行代碼,3 388個(gè)方法和1 341個(gè)屬性。原始空間包含85個(gè)源碼文檔,文檔詞匯數(shù)主要分布在100~200間,其中4個(gè)文檔包含詞匯在300以上。文檔長(zhǎng)度集中在500左右,而部分文檔則達(dá)到了4 000以上,從這一點(diǎn)可以看出對(duì)原始空間加權(quán)的必要性,不同文檔長(zhǎng)度會(huì)導(dǎo)致不同文檔中部分詞匯出現(xiàn)頻率過高。TF-IDF算法一方面考慮單詞在文檔中的作用,采用該單詞頻數(shù)在文檔長(zhǎng)度中的比重作為局部權(quán)重,而逆向文件頻數(shù)則對(duì)出現(xiàn)該單詞文檔數(shù)目在文檔集中的比重取對(duì)數(shù),則該單詞權(quán)重由局部權(quán)重乘以逆向文件頻數(shù)得到。
本文對(duì)原始文本空間進(jìn)行潛在語義分析,獲得原始空間的近似空間。文檔被表示為詞匯頻率的向量,文檔間的相似度通過余弦距離表示,取值范圍在[-1,1]之間,數(shù)值的絕對(duì)值越接近于1,則兩個(gè)文檔越相似,距離越近;反之越不相似,距離越遠(yuǎn)。在利用層次聚類時(shí),需要將相似度轉(zhuǎn)化為距離。層次聚類的結(jié)果展示為一棵層次樹,文檔對(duì)象根據(jù)相互間的距離聚合成一個(gè)聚類。
觀察表2中提取的話題,聚類1中話題內(nèi)容為exception onversion get put invalid,由此可以推斷出聚類1的功能為打印流、寫打印和緩沖相關(guān)。聚類5中話題為serializable object file read input,由此可以推斷出這部分功能為讀與文件和目錄相關(guān)。

Table 2 Topics of IO package表2 IO包話題
對(duì)于該IO包,可以生成兩方面信息:統(tǒng)計(jì)信息關(guān)于文件數(shù)目和聚類結(jié)果,語義信息主要是提取的話題和生成的概要信息,如下:


4 實(shí)驗(yàn)及評(píng)估
本部分將利用具體的軟件系統(tǒng)來對(duì)本文技術(shù)進(jìn)行實(shí)驗(yàn)評(píng)估。實(shí)驗(yàn)將對(duì)Java源碼rt.jar中java目錄中的幾個(gè)包文件進(jìn)行分析。實(shí)驗(yàn)評(píng)估主要關(guān)注如下三方面:
(1)聚類效果。聚類效果采用經(jīng)驗(yàn)分析,通過實(shí)驗(yàn)小組成員對(duì)源碼進(jìn)行閱讀,人工劃定文本聚類,并和工具的聚類結(jié)果進(jìn)行比較。
(2)話題提取。話題同樣采用人工閱讀源碼的方法給出話題,并與本文的工具進(jìn)行比較。
(3)概要有效性。概要的有效性通過分組比較,一組成員閱讀程序進(jìn)行理解,另一組通過閱讀概要信息,再和經(jīng)驗(yàn)概要信息比較,以此判定概要信息的有效性。
4.1 參數(shù)設(shè)置
以下將對(duì)實(shí)驗(yàn)過程中本文技術(shù)所涉參數(shù)進(jìn)行設(shè)定,并給出合理的參數(shù)經(jīng)驗(yàn)值。
(1)術(shù)語文檔矩陣的加權(quán)。考慮到文檔長(zhǎng)度對(duì)詞頻的影響以及權(quán)衡出現(xiàn)頻率較高和頻率較低的單詞,對(duì)術(shù)語文檔矩陣進(jìn)行加權(quán)操作是信息檢索中常見的處理方法。本文采用的TF-IDF加權(quán)算法是常見的一種加權(quán)算法。
(2)LSA-space維度。在利用LSI對(duì)原始的文本空間進(jìn)行降維和降噪操作時(shí),利用一個(gè)近似空間來代替原始文本空間。在對(duì)奇異值向量進(jìn)行截取的過程中,截取的數(shù)值k越接近奇異值向量的長(zhǎng)度,則近似矩陣越接近原始矩陣。考慮到本文分析的對(duì)象為近百篇文檔近千個(gè)詞匯的包文件,建議將k設(shè)置在原始規(guī)模的20%,即在10到20范圍內(nèi)。
(3)聚類數(shù)。在使用層次聚類的過程中,由于聚類規(guī)模的劃定是通過觀測(cè)聚類樹得到的,在聚類數(shù)目劃定時(shí),不宜將數(shù)目劃定得過大,這樣不利于話題的提取。這里根據(jù)文獻(xiàn)[7-8]來進(jìn)行聚類數(shù)的設(shè)置,設(shè)置在5個(gè)。
(4)話題數(shù)。本文的概要信息基于提取的話題,由于需要將話題用來匹配包含這些話題的組合詞,話題的設(shè)置會(huì)影響提取的組合詞個(gè)數(shù)。這里同樣根據(jù)文獻(xiàn)[7-8]將話題數(shù)控制在5個(gè)左右。
4.2 實(shí)驗(yàn)結(jié)果與分析
在實(shí)驗(yàn)階段,將實(shí)驗(yàn)人員進(jìn)行分組,一部分小組閱讀人工提取信息,一部分小組閱讀工具提取信息,通過比較評(píng)分來對(duì)方法進(jìn)行評(píng)估。對(duì)于評(píng)估結(jié)果,采用差、中、好3個(gè)等級(jí),并給出問題的評(píng)注。在聚類效果評(píng)估中,關(guān)注聚類數(shù)目和文檔歸類情況兩部分。在概要信息部分,關(guān)注概要的可理解性。
經(jīng)過對(duì)多個(gè)軟件程序的處理分析,得到如下實(shí)驗(yàn)結(jié)果。
(1)聚類效果。由于聚類算法種類多樣,聚類效果也有不同。考慮到這一現(xiàn)實(shí),很難對(duì)聚類算法的優(yōu)劣給出一個(gè)評(píng)估標(biāo)準(zhǔn)。本文在這一階段通過人工閱讀程序文件,分析工具聚類結(jié)果是否合理。同樣將人員分成5個(gè)小組進(jìn)行評(píng)估,評(píng)估結(jié)果如表3所示。
從表3中可以看到,有3組聚類效果還是得到了實(shí)驗(yàn)人員的認(rèn)可,但是還有兩組聚類效果不是很滿意。詳細(xì)分析原因,主要是源碼語義信息進(jìn)行聚類存在的明顯問題就是歸檔不合理和聚類數(shù)目不合理。而表中結(jié)果也反映了幾乎所有的組別均出現(xiàn)了歸檔不合理的情況。對(duì)于這種問題,如異常處理類可能會(huì)與相應(yīng)的類使用近似的詞匯,即使在功能上不同,但由于存在較多相似的詞匯,相似度較高,有可能被劃分到一個(gè)聚類中。而出現(xiàn)這些結(jié)果主要是由于采用層次聚類,聚類數(shù)目的設(shè)定是通過觀察聚類樹得到的,具有一定的不穩(wěn)定性。

Table 3 Evaluation of clustering results表3 聚類評(píng)估結(jié)果
(2)話題提取。話題是基于單詞和聚類的相似度提取前n個(gè)。在實(shí)驗(yàn)過程中,將實(shí)驗(yàn)人員分為5組,每一組先閱讀工具提取的話題,再閱讀程序源碼,通過人工判斷工具提取話題的效果,評(píng)估結(jié)果如表4所示。

Table 4 Evaluation of topics表4 話題評(píng)估結(jié)果
從表4結(jié)果中可以看到,實(shí)驗(yàn)人員對(duì)話題整體還是認(rèn)可的,基本可以通過這些話題對(duì)程序進(jìn)行一定的理解。但是在通過閱讀代碼來評(píng)估話題的過程中存在著兩個(gè)主要問題,即看不懂的縮寫和不具有代表性的話題。造成這種差距的原因是多方面的:第一,在人工閱讀的過程中,對(duì)程序的理解并不是單純的基于詞頻,而工具分析的基礎(chǔ)是考慮詞頻。第二,在工具過濾停用詞的時(shí)候沒法達(dá)到人類那樣效果顯著,所有的停用詞都是預(yù)設(shè)的,不能滿足所有的情況。第三,在開發(fā)過程中會(huì)有大量開發(fā)人員約定的縮寫,如果這些縮寫包含對(duì)功能的描述,往往會(huì)占有較高的頻率,然而這些縮寫對(duì)于新接觸的人來說是看不懂的。
(3)概要信息。在分組測(cè)試的過程中,將人員分成6組。第1、2、3小組采用直接閱讀源碼的方法,第4、5、6小組利用工具進(jìn)行程序理解。主要對(duì)兩組實(shí)驗(yàn)人員在理解不同程序時(shí)所需的時(shí)間進(jìn)行評(píng)估。實(shí)驗(yàn)過程中,1、4,2、5和3、6小組分別閱讀對(duì)應(yīng)源程序和概要信息,實(shí)驗(yàn)結(jié)果如表5所示。

Table 5 Time to understand program表5 程序理解時(shí)間
從表5結(jié)果中可以看到,第1、2、3小組在理解時(shí)間上遠(yuǎn)遠(yuǎn)大于利用工具的小組,這說明了利用本文的工具所生產(chǎn)的程序概要能夠有助于程序員對(duì)程序的理解,改進(jìn)他們理解軟件程序的效率。
綜合來看,本文方法能夠在語義上給開發(fā)和維護(hù)人員提供一定的幫助,可以改進(jìn)開發(fā)人員理解程序的效率。當(dāng)然,該技術(shù)還存在一些缺陷,例如在聚類數(shù)目、文檔歸類以及話題提取上仍然有一定的不足,這也是今后工作將要著重研究的地方。
4.3 實(shí)驗(yàn)威脅
在實(shí)驗(yàn)過程中,許多限制因素對(duì)實(shí)驗(yàn)的效果造成了影響。首先,聚類方法對(duì)程序代碼理解時(shí)僅僅考慮代碼中詞匯出現(xiàn)的次數(shù),而忽略了一些結(jié)構(gòu)性語法,如循環(huán)語句,對(duì)詞頻的影響。其次,由于程序代碼并不完全符合編碼規(guī)范,導(dǎo)致預(yù)處理過程結(jié)果中包含噪音。另外,實(shí)驗(yàn)中聚類和層次等參數(shù),主要依據(jù)文獻(xiàn)[7-8]進(jìn)行設(shè)定,不同的參數(shù)值可能會(huì)取得不同效果。最后,實(shí)驗(yàn)的對(duì)象類型較少,僅僅對(duì)Java項(xiàng)目源碼中的幾個(gè)包進(jìn)行了實(shí)驗(yàn)。對(duì)更多類型的軟件系統(tǒng)的實(shí)驗(yàn)分析將是后期工作的一部分。
5 相關(guān)工作
程序理解是軟件維護(hù)與演化過程中的一個(gè)重要活動(dòng),近來程序概要化是程序理解的一個(gè)有效手段,開發(fā)人員直接根據(jù)這些概要來理解程序代碼。
Sridhara等人提出了能直接生成面向?qū)ο蟪绦蛑蓄惡头椒ǖ某绦蚋乓椒╗19-20]。該方法針對(duì)不同的結(jié)構(gòu),通過細(xì)化分析程序結(jié)構(gòu)中的代碼變量和執(zhí)行方法等信息來確定方法和類的意圖;最后,通過組織代碼中變量名或者是方法本身與調(diào)用方法的簽名生成描述語言來概括整個(gè)方法。Dragan等人通過識(shí)別程序中的一些方法模式,并利用方法模式作為軟件系統(tǒng)的概要化描述來分析系統(tǒng)[21]。如上這些方法主要考慮了程序的語法結(jié)構(gòu),根據(jù)語法結(jié)構(gòu)來生成程序的概要,但是忽略了程序的語義信息。而本文則主要分析程序代碼中的語義信息,能直接生成可讀性更好的系統(tǒng)包層次的概要化信息。
Alhindawi等人也通過分析程序中的語義信息進(jìn)行類的理解[22],他們主要使用了文本詞的分割和辨別技術(shù)生成類文件的自然語言的注釋,這些注釋包含了類的一些相關(guān)信息供開發(fā)人員理解。而本文則針對(duì)Java程序中的包進(jìn)行分析,利用LSI技術(shù)分析程序包中的主題,然后將這些主題整合成包的概要信息供開發(fā)人員理解。
6 總結(jié)與展望
本文提出了語義恢復(fù)和概要的方法來進(jìn)行包層次的程序理解,利用語義恢復(fù)的方法對(duì)由多個(gè)獨(dú)立單詞組成的話題進(jìn)行語義恢復(fù),并利用MiniPar生成對(duì)包層次的概要信息。通過多次實(shí)驗(yàn)表明,本文方法可以生成程序的基本語義信息,提供可讀性較強(qiáng)的概要信息,有助于開發(fā)人員快速理解程序。因此,對(duì)于那些缺少文檔或者文檔較少的軟件代碼,本文提出的包層次的概要化方法可有效地幫助開發(fā)人員理解整個(gè)軟件。但本文方法依然存在著一些不足之處,具體如下:
(1)停用詞表需要針對(duì)軟件工程領(lǐng)域做出調(diào)整。軟件程序中的語義信息和自然語言文本信息有一定的差異,停用詞表并不通用,需要根據(jù)軟件工程領(lǐng)域制定合適的停用詞表。
(2)權(quán)衡注釋和標(biāo)識(shí)符比重。在提取過程中,文檔中的標(biāo)識(shí)符數(shù)量遠(yuǎn)遠(yuǎn)少于注釋中的內(nèi)容,注釋中的對(duì)功能描述影響不大的詞匯可能因頻率而影響標(biāo)識(shí)符的作用,需要進(jìn)行一定的權(quán)衡。
(3)拓展工具使用范圍。目前工具僅支持Java程序,可進(jìn)一步拓展到其他語言程序中。
本文后期的工作會(huì)針對(duì)這些不足進(jìn)行改進(jìn),進(jìn)一步提高方法的有效性和適用范圍。
[1]Abran A,Bourque P,Dupuis R,et al.Guide to the software engineering body of knowledge(ironman version)[R].IEEE Computer Society,2004.
[2]Rajlich V.Software evolution and maintenance[C]//Proceedings of the 2014 Conference on Future of Software Engineering,Hyderabad,India,May 31-Jun 7,2014.New York: ACM,2014:133-144.
[3]Rugaber S.Program understanding[M]//Kent A,Williams J G.[S.l.]:Encyclopedia of Computer Science and Technology, 1996:341-368.
[4]Ducasse S,Lanza M.The class blueprint:visually supporting the understanding of glasses[J].IEEE Transactions on Software Engineering,2005,31(1):75-90.
[5]Binkley D,Beszédes á,Islam S,et al.Uncovering dependence clusters and linchpin functions[C]//Proceedings of the 2015 IEEE International Conference on Software Maintenance and Evolution,Bremen,Germany,Sep 29-Oct 1, 2015.Piscataway,USA:IEEE,2015:141-150.
[6]Binkley D,Lawrie D J.The impact of vocabulary normalization[J].Journal of Software Evolution and Process,2015, 27(4):255-273.
[7]Maletic J I,Marcus A.Using latent semantic analysis to identify similarities in source code to support program understanding[C]//Proceedings of the 12th IEEE International Conference on Tools with Artificial Intelligence,Vietrisul Mare,Italy,Nov 15,2000.Piscataway,USA:IEEE,2000: 46-53.
[8]Kuhn A,Ducasse S,G?rba T.Semantic clustering:identifying topics in source code[J].Information and Software Technology,2007,49(3):230-243.
[9]Nakov P,Popova A,Mateev P.Weight functions impact on LSA performance[C]//Proceedings of the EuroConference on Recent Advances in Natural Language Processing,Tzigov Chark,Bulgaria,2001:187-193.
[10]Foltz P W,Kintsch W,Landauer T K.The measurement of textual coherence with latent semantic analysis[J].Discourse Processes,2009,25(2):285-307.
[11]Deeester S,Dumais S T,Fumas G W,et al.Indexing by la-tent semantic analysis[J].Journal of the American Society of Information Science,1990,41(6):391-404.
[12]Binkley D,Heinz D,Lawrie D J,et al.Understanding LDA in source code analysis[C]//Proceedings of the 22nd International Conference on Program Comprehension,Hyderabad,India,Jun 2-3,2014.New York:ACM,2014:26-36.
[13]Dumais S T.Improving the retrieval of information from external sources[J].Behavior Research Methods:Instruments and Computers,1991,23(2):229-236.
[14]Manning C D,Raghavan P,Schutze H.Introduction to information retrieval[M].Cambridge,UK:Cambridge University Press,2008.
[15]Jain A K,Murty M N,Flynn P J.Data clustering:a review[J]. ACM Computing Surveys,1999,31(3):264-323.
[16]Steinbach M,Karypis G,Kumar V.A comparison of document clustering techniques[C]//Proceedings of the 2000 KDD Workshop on Text Mining,Boston,USA,Aug 20, 2000.New York:ACM,2000:1-2.
[17]Anquetil N,Lethbridge T.Experiments with clustering as a software remodularization method[C]//Proceedings of the 6th Working Conference on Reverse Engineering,Atlanta, USA,Oct 6-8,1999.Washington:IEEE Computer Society, 1999:235-255.
[18]Porter M F.An algorithm for suffix stripping[J].Program: Electronic Library and Information Systems,1980,14(3): 130-137.
[19]Sridhara G,Hill E,Muppaneni D,et al.Towards automatically generating summary comments for Java methods[C]// Proceedings of the 25th IEEE/ACM International Conference on Automated Software Engineering,Antwerp,Belgium,Sep 20-24,2010.New York:ACM,2010:43-52.
[20]Moreno L,Aponte J,Sridhara G,et al.Automatic generation of natural language summaries for Java classes[C]//Proceedings of the 2013 IEEE 21st International Conference on Program Comprehension,San Francisco,USA,May 20-21,2013.Piscataway,USA:IEEE,2013:23-32.
[21]Dragan N,Collard M L,Maletic J I.Using method stereotype distribution as a signature descriptor for software systems[C]//Proceedings of the 2009 IEEE International Conference on Software Maintenance,Edmonton,Canada,Sep 20-26,2009.Piscataway,USA:IEEE,2009:567-570.
[22]Alhindawi N,Dragan N,Collard M L,et al.Improving feature location by enhancing source code with stereotypes[C]// Proceedings of the 2013 IEEE International Conference on Software Maintenance,Eindhoven,The Netherlands,Sep 22-28,2013.Piscataway,USA:IEEE,2013:300-309.

LIU Yu was born in 1993.He is an M.S.candidate at Southeast University.His research interests include data mining and machine learning,etc.
柳郁(1993—),男,江蘇徐州人,東南大學(xué)-蒙納士蘇州研究生院計(jì)算機(jī)專業(yè)碩士研究生,主要研究領(lǐng)域?yàn)閿?shù)據(jù)挖掘,機(jī)器學(xué)習(xí)等。

SUN Xiaobing was born in 1985.He received the Ph.D.degree in computer science from Southeast University in 2012.Now he is an associate professor at Yangzhou University,and the senior member of CCF.His research interests include software maintenance and evolution and software data analytics,etc.
孫小兵(1985—),男,江蘇姜堰人,2012年于東南大學(xué)獲得博士學(xué)位,現(xiàn)為揚(yáng)州大學(xué)副教授,CCF高級(jí)會(huì)員,主要研究領(lǐng)域?yàn)檐浖S護(hù)與演化,軟件數(shù)據(jù)分析學(xué)等。發(fā)表學(xué)術(shù)論文40余篇,主持國家自然科學(xué)基金項(xiàng)目、江蘇省教育廳自然科學(xué)基金項(xiàng)目等。

LI Bin was born in 1965.He received the Ph.D.degree in computer science from Nanjing University of Aeronautics and Astronautics in 2001.Now he is a professor and Ph.D.supervisor at Yangzhou University,and the senior member of CCF.His research interests include software systems and machine learning,etc.
李斌(1965—),男,江蘇靖江人,2001年于南京航空航天大學(xué)獲得博士學(xué)位,現(xiàn)為揚(yáng)州大學(xué)教授、博士生導(dǎo)師,CCF高級(jí)會(huì)員,主要研究領(lǐng)域?yàn)檐浖到y(tǒng),機(jī)器學(xué)習(xí)等。發(fā)表學(xué)術(shù)論文100余篇,主持國家自然科學(xué)基金項(xiàng)目等。
Research onAutomatic Summarization for Java Packages*
LIU Yu1,SUN Xiaobing1,2+,LI Bin1,2
1.School of Information Engineering,Yangzhou University,Yangzhou,Jiangsu 225127,China
2.State Key Laboratory for Novel Software Technology,Nanjing University,Nanjing 210023,China
+Corresponding author:E-mail:xbsun@yzu.edu.cn
Program comprehension is a process of acquiring knowledge from software systems and is important to software maintenance.It is estimated that about 50%to 80%software budget is spent on software maintenance,and about 47%to 62%software maintenance is spent on program comprehension.This paper proposes a novel approach to summarize the packages in a software system based on Java,which employs latent semantic indexing,a typical information retrieve technique,and hierarchical clustering to derive artifacts from source code and group source files sharing similar vocabulary.Then,topics are retrieved from these clusters and linguistic information is recovered from the generated vocabulary.Finally,this paper employs MiniPar,a parser for English language,to generate the package summarization.The experimental results show that the proposed approach can improve the efficiency of program comprehension process.
10.3778/j.issn.1673-9418.1512105
A
TP311
*The National Natural Science Foundation of China under Grant Nos.61402396,61472344(國家自然科學(xué)基金);the Postdoctoral Science Foundation of China under Grant No.2015M571489(中國博士后面上項(xiàng)目);the Open Funds of State Key Laboratory for Novel Software Technology of Nanjing University under Grant No.KFKT2016B21(軟件新技術(shù)國家重點(diǎn)實(shí)驗(yàn)室開放課題項(xiàng)目); the Natural Science Foundation of the Jiangsu Higher Education Institutions under Grant No.13KJB520027(江蘇省教育廳自然科學(xué)基金面上項(xiàng)目).
Received 2015-12,Accepted 2016-03.
CNKI網(wǎng)絡(luò)優(yōu)先出版:2016-03-07,http://www.cnki.net/kcms/detail/11.5602.TP.20160307.1710.012.html
LIU Yu,SUN Xiaobing,LI Bin.Research on automatic summarization of Java packages.Journal of Frontiers of Computer Science and Technology,2017,11(2):212-220.
Key words:program comprehension;latent semantic indexing;clustering;topic;summarization
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級(jí))(2020年8期)2020-01-08 02:21:16
人大建設(shè)(2019年12期)2019-05-21 02:55:44
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時(shí)報(bào)(2017-03-30)2017-03-30 06:44:45
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
七彩語文·低年級(jí)(2011年19期)2011-04-12 00:00:00
