科學大數據管理:概念、技術與系統
2017-02-22 04:31:38黎建輝沈志宏孟小峰
計算機研究與發展 2017年2期
黎建輝 沈志宏 孟小峰
1(中國科學院計算機網絡信息中心 北京 100190)2 (中國人民大學信息學院 北京 100872) (lijh@cnic.cn)
科學大數據管理:概念、技術與系統
黎建輝1沈志宏1孟小峰2
1(中國科學院計算機網絡信息中心 北京 100190)2(中國人民大學信息學院 北京 100872) (lijh@cnic.cn)
近年來,隨著越來越多的大科學裝置的建設和重大科學實驗的開展,科學研究進入到一個前所未有的大數據時代.大數據時代科學研究是一個大科學、大需求、大數據、大計算、大發現的過程,研發一個支持科學大數據全生命周期的數據管理系統具有重要的意義.分析了研發科學大數據管理系統的背景,闡述了科學大數據的概念和三大特征,通過對科學數據資源發展和科學數據管理系統的研究進展進行綜述分析,提出了滿足科學數據管理全生命周期的科學大數據管理框架,并從數據融合、數據實時分析、長期存儲、云服務體系以及數據開放共享機制5個方面分析了科學大數據管理系統中的關鍵技術.最后,結合科學研究領域展望了科學大數據管理系統的應用前景.
科學數據;大數據;數據流水線;數據全生命周期
大規模巡天望遠鏡、大型粒子加速器、高通量基因測序儀等源源不斷產生巨量科學數據,使得全球科技創新進入一個前所未有的科學大數據時代.科學大數據已成為科學發現的新型戰略資源,一個國家的科學研究水平將直接取決于其在科學大數據的優勢以及將數據轉換為知識的能力.
面向大規模的科學數據管理,以及科學大數據應用,往往需要突破當今所有數據管理系統的極限,才能實現高效的科學知識發現,這也成為當下科學界和數據管理領域攜手攻堅的“難題”.概括起來,科學大數據管理面臨的主要問題和挑戰包括:1)超大規模關系數據管理.如天文領域多個數據中心千億乃至萬億行天文星表數據的管理.2)多源數據關聯和知識發現.如全球開放生物資源、文獻、序列和疾病等萬種數據源100億級關聯數據的知識發現,需6步以上關聯挖掘.3)實時的高效數據處理.如引力波科學發現中,16 MHz 采樣頻率10 000信道數據需要近似零延遲數據處理.
1 科學大數據概念與特性
1.1 科學大數據概念
科學數據是科研活動的輸入、輸出和資產.但究竟“什么是科學數據?”,如何給“科學數據”一個確切的定義?迄今為止,還在困擾著學術界.Greenberg在其最近出版的著作《大數據,小數據,沒數據》[1]中,列舉了學術界對數據各種不同的認識和理解,“在自然科學、社會科學和人文科學領域,學者們創造、使用、分析和解釋數據,但往往不知道這些數據的真正含義.”
科學數據是對所研究的客觀對象的某些現象的描述.這種描述,一般是指在領域或學科知識指導下,對客觀對象進行科學抽象和概念化后,就其中的某些現象進行系統地、有目的地觀測、調查、實驗所形成的實體.因此,數據不是客觀事物,數據不是帶有自身特征的自然對象,數據只是對學術研究的客觀對象中某些可觀測到的現象的描述.這些描述會因人而異、因地而異和因時而異.把一些事物概念化為數據,本身就是一種學術研究活動.
科學數據是以科學證據形式存在的事實,它至少應該包括科學觀測與監測的數據、實驗數據、計算與模型模擬輸出的數據、對情景或現象的描述數據、對行為的觀測或定性描述數據、用于管理或者商業目的統計數據等,以及描述數據的元數據.它們通常是科研活動的輸入,是證實、證偽科學發現、科學觀點的事實與證據,或者是論證推理的基礎.
科學數據從歷史上非自動化的“手工采集”的方式,逐漸地過度到自動化的“機器采集”.非自動“手工采集”的數據,其產生的速度較慢,數據量與復雜度不高,但數據的價值密度高.而通過大型儀器設備、大科學裝置、大規模傳感器網絡等自動化采集的數字化數據,其產生的速度快,數據量和復雜性高,存在著不確定性和噪聲.對這些數據進行存儲、分析和應用需要新技術與更強的基礎設施環境支持.科學大數據主要是指這種通過“機器”自動化快速采集、規模化存儲與分析處理、具有較高維度和復雜關聯的數據及其衍生產品.
隨著越來越多的諸如500 m口徑球面射電望遠鏡(five-hundred-meter aperture spherical radio telescope, FAST)、中國散裂中子源(China spallation neutron source, CSNS)等大科學裝置的建設和重大科學實驗的開展,以及無所不在的科學傳感器和傳感器網絡廣泛應用于天空、陸地和海洋,對自然環境進行全方位的探測、監測,源源不斷產生的科學數據將科學研究快速推進到一個前所未有的大數據時代.科學大數據將改變人類幾個世紀以來科學研究主要在于理解相對簡單、未耦合或弱耦合系統這一局面,增強我們詳細表征和描述復雜性的能力,以及分析高度耦合復雜系統的動態行為的能力,催生如希格斯粒子和引力波等重大科學發現.可以這樣比喻,科學大數據為科學發現提供了一種新型的“望遠鏡”和“顯微鏡”,在宏觀上大大擴展了我們對復雜系統整體性進行研究的能力,在微觀上,讓我們的視線可以深入到復雜系統內部細微的行為和動態變化.
1.2 科學大數據的特征
相較于其他類型的大數據,科學大數據除了具有明顯的“4V”特征[2-4]之外,還具有多層次逐級演化、全生命周期以及流水線處理和應用等特征.
1.2.1 多層次演化特征
科學大數據具有多層次逐級演化的顯著特征.如圖1所示,由大型儀器設備、大科學裝置和計算模擬等產生的海量原始數據,經過校對、刻度、特征提取等處理形成具有科學意義的實例對象數據,并與相關的數據關聯融合,形成知識網絡.典型例子如美國航空航天局(NASA)地球觀測系統(earth observing system, EOS)[5]衛星獲取的數據按照其不斷加工和演化過程,區分為0級、1A級、1B級、2級、3級、4級6個不同的級別.根據科學應用和目標的不同,科學家可以直接使用精加工的4級數據,也可以使用1A級,甚至0級數據.
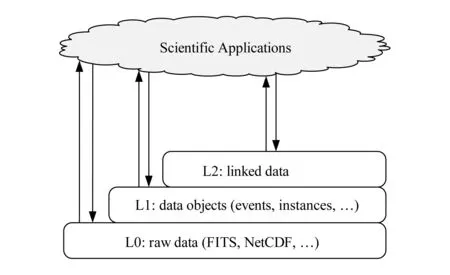
Fig. 1 Characteristics of multi-level progressive evolution of scientific big data圖1 科學大數據具有多層次逐級演化的顯著特性
1.2.2 全生命周期特征
科學大數據具有明顯的涉及“采集與實時分析—存儲與處理—發布與共享—再分析與重用—歸檔與長期保存”全過程的全生命周期特征.其中,采集與實時分析階段主要完成科學實驗裝置、儀器設備、觀測臺站等數據的采集,并實現數據的實時篩選、處理和分析;存儲與處理階段主要完成對采集篩選的數據的持久化存儲,同時通過批量分析任務,完成初步的科學分析和科學發現;發布與共享階段主要按照特定的主題,對科學數據進行組織管理,形成系列的數據集產品,通過Web等方式對科研界發布,提供數據共享與交換服務;再分析與重用階段主要支持用戶對發布的數據集進行二次整合分析,實現進一步的科學發現;歸檔與長期保存階段主要完成歷史數據的歸檔,通過采用持久的存儲設備,實現海量歷史數據的長期保存.整個流程如圖2所示.
在如上不同階段中,對科學數據的操作方式具有不同的特征,如表1所示.
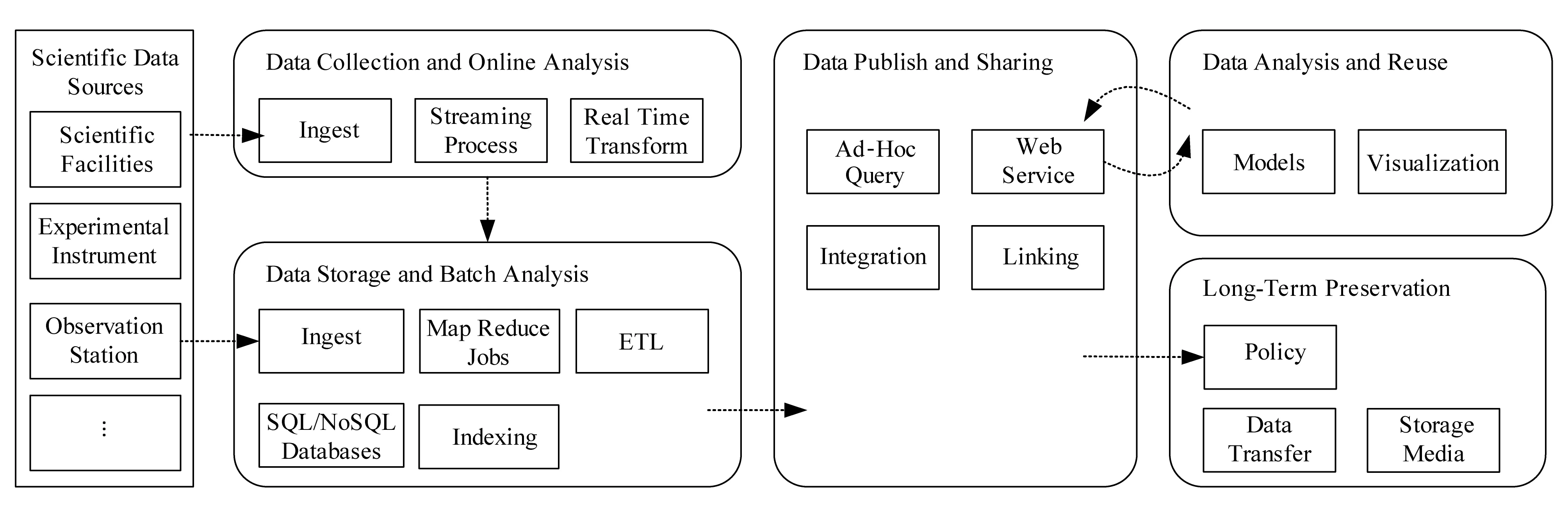
Fig. 2 Full life cycle of scientific big data圖2 科學大數據全生命周期
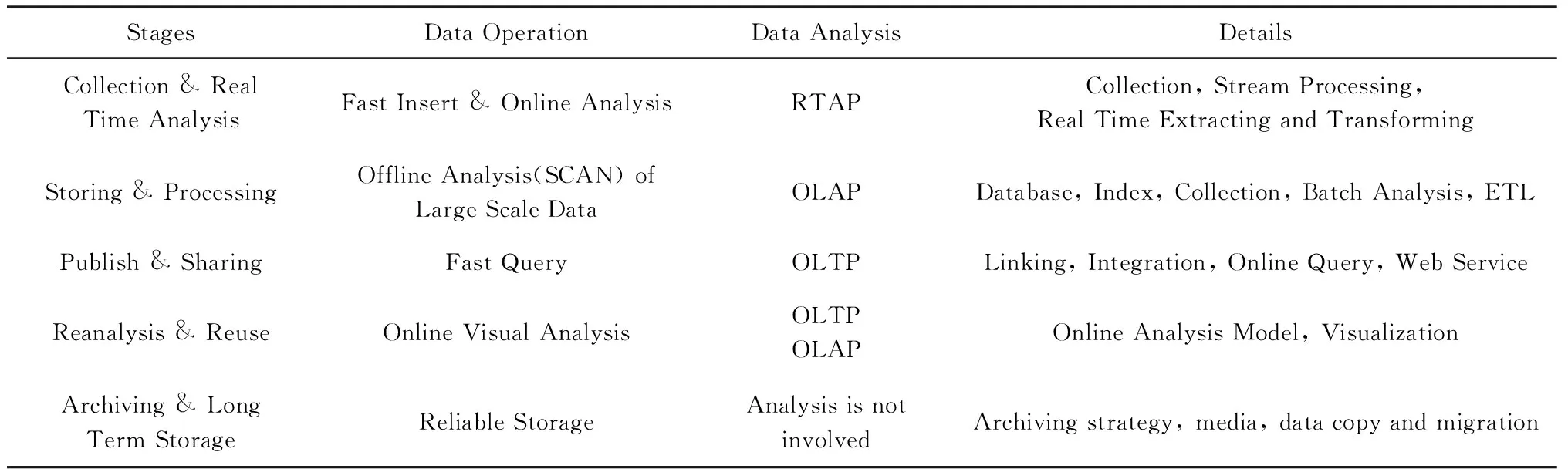
StagesDataOperationDataAnalysisDetailsCollection&RealTimeAnalysisFastInsert&OnlineAnalysisRTAPCollection,StreamProcessing,RealTimeExtractingandTransformingStoring&ProcessingOfflineAnalysis(SCAN)ofLargeScaleDataOLAPDatabase,Index,Collection,BatchAnalysis,ETLPublish&SharingFastQueryOLTPLinking,Integration,OnlineQuery,WebServiceReanalysis&ReuseOnlineVisualAnalysisOLTPOLAPOnlineAnalysisModel,VisualizationArchiving&LongTermStorageReliableStorageAnalysisisnotinvolvedArchivingstrategy,media,datacopyandmigration
1.2.3 流水線處理特征
科學大數據具有“流水線處理和應用”的特征.以GWAC(The ground-based wide-angle camera array)為例,GWAC是中法合作伽瑪暴探測天文衛星SVOM的關鍵地面設備,一個GWAC相機每15 s產生一個大小為32 MB的天區圖,圖像的點源提取和接下來的光變曲線處理流程應該在一幀的15 s內快速處理完.這個實時處理約束是由于很多短時標的光變,例如微引力透鏡事件,需要通過對光變曲線數據實時分析才能得以發現.這個過程就是一個典型的數據流水線,包括天區圖采集、圖像處理、點源提取、交叉證認、光變曲線處理等步驟[6],如圖3所示.為了滿足特定的科學目標,科學數據流水線一般對數據處理的精度或者對數據處理的速度等方面會有明確而苛刻的要求,從而為預期的科學目標或者科學發現提供保證.

Fig. 3 Collecting and analyzing pipeline of astronomic data圖3 天文數據采集分析流水線
科學數據流水線具有如下特點:
1) 一條流水線通常會涉及到科學數據采集、存儲、分析等不同環節.如:從GWAC望遠鏡獲取到天區圖,就是一個海量數據采集步驟,圖像處理則是一個數據分析的過程.因此,除了需要提供數據分析的支持,還需要考慮到數據的采集等管理功能的支持.
2) 一條流水線會涉及到多元的大數據管理與處理系統.為了達到高效的科學發現目標,往往需要組合不同的數據管理系統,如高吞吐的消息隊列系統、高效交互式查詢的SQL數據庫系統、高可靠的HDFS管理系統等.同時,根據任務的不同特征,也會組合用到不同時效性要求的計算框架,如流計算框架、實時計算框架、離線計算框架等.
3) 完整的科學發現過程往往需要多個流水線并行執行,因此需要考慮CPUGPU、內存、存儲等資源的共享和分配問題.
2 發展現狀
科學大數據已成為科學發現的新型戰略資源,為了搶占科技競爭的至高點,世界各國已紛紛把科學大數據納入國家戰略,并開始重點部署.美國國立衛生研究院2013年啟動了“從大數據到知識” (BD2K)計劃[7],總投資達到6.56億美元.歐盟“地平線2020”計劃[8]將科學大數據關鍵技術和基礎設施列為了重點支持領域.歐盟宣布,將投資65億歐元用于建設“歐洲開放科學云”(Europe Open Science Cloud)[9],重點支持大數據驅動的科學發現.在我國發布的《促進大數據發展行動綱要》中,首次將科學大數據上升到國家戰略層面,明確提出“發展科學大數據”的戰略目標.中國科學院在“十三五”信息化發展規劃中,也明確提出將實施科學大數據工程,全面提升大數據驅動的科技創新能力.
2.1 國際科學大數據資源發展趨勢
大規模巡天望遠鏡、大型粒子加速器、高通量基因測序儀等大科學裝置,使得科學大數據呈幾何級數增長態勢.在天文學領域,人類正在設計和制造各種大型巡天望遠鏡,試圖實現對宇宙多波段、多時域等數字化全覆蓋,實現其“虛擬天文臺”的偉大構想.如斯隆數字巡天(SDSS)、“泛星計劃”(Pan-STARRS)、大型巡天望遠鏡LSST(Large Synoptic Survey Telescope)等[10].LSST[11]將每3天完成對南半球的天空巡天1次,每15 s記錄3幅10億像素圖像(每幅圖像包含百萬個天體),每晚需對30 TB原始數據準實時的分析,同時對轉瞬即逝的千萬級突發天體事件,需在60 s之內完成數據分析、插入和分發,并向全世界發出預警[12-13].
在生命科學領域,第二代測序技術使得基因組數據發生了爆炸式的增長.相比于2000年,2010年的基因組數據產量增大了8個數量級.僅華大基因這一個基因組研究機構每天就產生約15 TB數據[14].世界著名的三大基因序列數據庫GenBank,EMBL,DDBJ收錄了70 000多種生物的核苷酸序列[15-16],其數據量以指數形式增長,核酸堿基數目大概每14個月就翻一倍.再以腦科學為例,用電子顯微鏡重建大腦中的突觸網絡,1 mm3大腦的圖像數據就超過了1 PB[17].
在高能物理領域,位于歐洲核子研究組織CERN的大型強子對撞器LHC每年將產生有15 PB左右的原始數據,利用原始數據進行事例重建以及物理分析所產生的數據規模更大.以其中的ATLAS實驗[18]為例,僅2011年產生的總數據就達40 PB.
在對地觀測領域,剛剛退役的Landsat 5[19]衛星保持在每天67 GB的觀測數據獲取量,而2012年發射的ZY3衛星,每天的觀測數據獲取量可以達到10 TB以上,類似能力的傳感器現已大量部署在衛星、飛機等飛行平臺上,未來10年全球部署的對地觀測平臺的數據獲取能力將超過10 PB/d.
各個不同的領域都在講述著一個類似的故事,那就是爆炸式增長的數據.這種增長超出了我們創造機器和軟件工具的速度,甚至超出了我們的想象.
2.2 我國科學大數據資源現狀
我國從20世紀80年代就持續進行數據資源的積累.1982年,中國科學院正式提出科學數據庫及其應用系統建設項目.經過30余年的持續發展,截止十二五“科技數據資源整合與共享工程”項目驗收[20],該項目系統地整合了58家單位的1 340個科學數據庫,數據下載量累計達175 TB.國家科技基礎條件平臺持續資助了林業科學數據平臺、地球系統科學數據共享平臺、人口與健康科學數據共享平臺、農業科學數據共享中心、地震科學數據共享中心、氣象科學數據共享中心等.
以中國科學院為例,中國科學院在生命與健康領域、地球與空間領域、基礎與前沿領域積累了豐富的數據資源.其中生物多樣性與生物資源數據比較完善,已建成3類資源體系:生物多樣性與生物資源、組學、醫藥與健康.在地球與空間領域已建成的數據資源體系包括:固體地球、陸地表層和空間天文等.其中陸地表層又分為地形地貌、氣象、水文、生態、自然資源、海洋等內容.此外,在基礎與前沿領域已建成的數據資源體系包括物理、化學、能源、材料、腦科學、信息科學等.各領域積累的數據資源如表2所示:
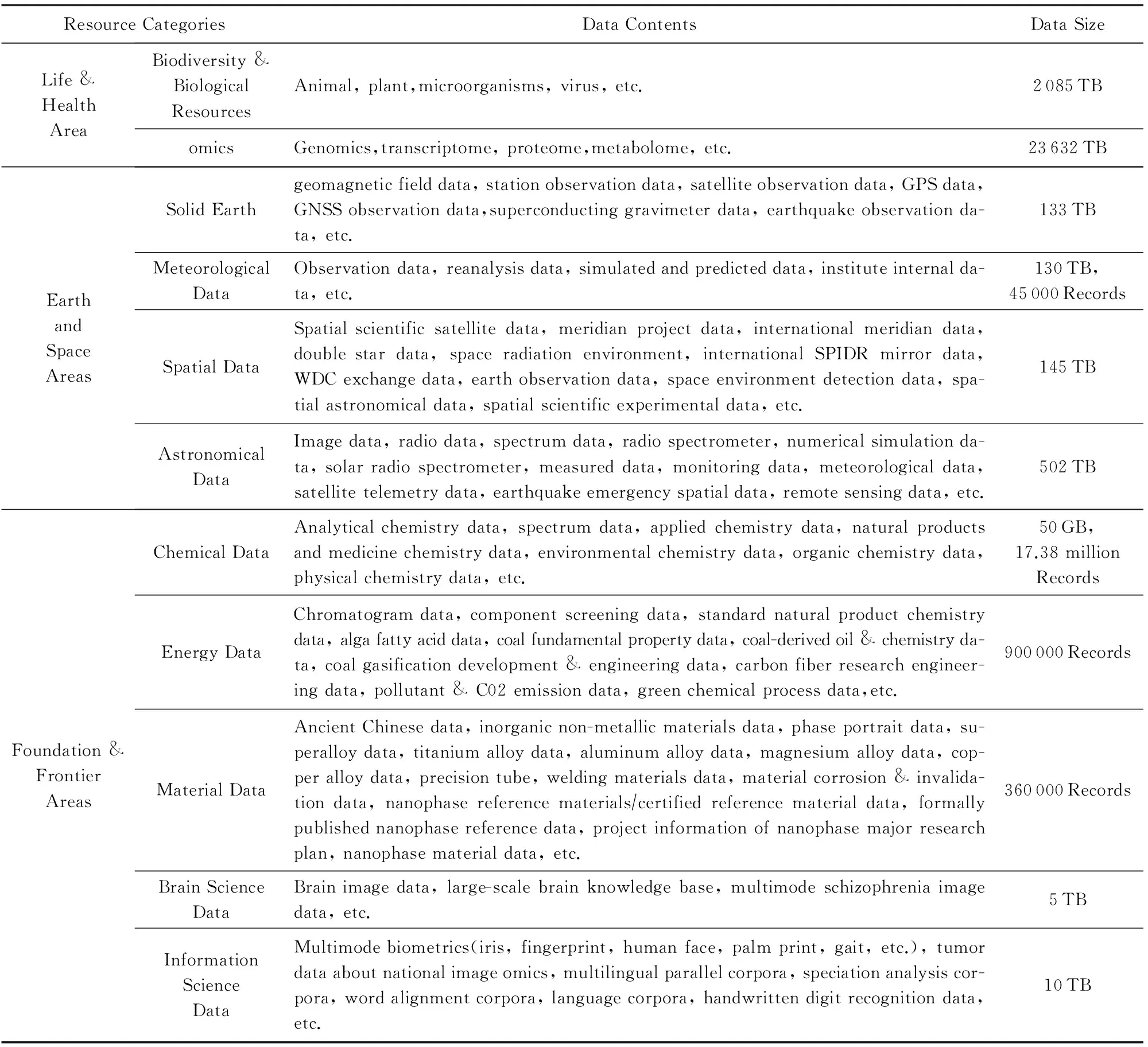
Table 2 Typical Scientific Data Resources
2.3 科學大數據管理系統
針對科學數據,不同科研機構相繼研發了科學數據管理系統,包括SRB[21-22],iRODS[23-25],SciDB[26-35],Hama[36-39],SkyServer[40-41]等.美國圣地亞哥超算中心(San Diego Supercomputer Center, SDSC)為了解決復雜海量科學數據的方便、高效、透明、統一的數據管理和訪問,研發了融合資源保存代理(storage resource broker, SRB)系統,在數據網格、數字圖書館、永久保存和實時數據系統中得到了較好的應用,并繼而推出了開源分布式數據管理系統iRODS(Integrated Rule-Oriented Data System).結合科學研究所產生的數據特征,Stonebraker等人在列存儲的基礎上,研發了一套開源的數據管理系統SciDB.SciDB不同于傳統的關系數據庫管理系統,它是一個數據管理和分析軟件系統,側重于科學數據的分析操作,設計目標是與R,MATLAB以及IDL等科學分析軟件結合來分析管理科學數據.Hama作為Hadoop項目的大規模計算子項目,利用Hadoop強大的分布式存儲與處理性能,針對部分科學問題的計算提供基于整體同步并行計算(bulk synchronous parallel, BSP)模型及graph模型的計算框架.針對SDSS的數據,Gray主導研發了SkyServer天文數據管理系統,實現TB量級天文數據的管理與探索.由于現有數據庫管理在處理像LSST 這樣100~200 PB量級的數據時依然顯得力不從心,因此LSST啟動研發了可管理百億級天文對象的數據庫Qserv[42],借助多數據中心、大規模分布式并行數據庫等技術,實現更加強大的數據管理、訪問和共享的能力.
這些科學數據管理系統在功能、原理以及特色上的差異如表3所示,可以看出,目前的科學數據管理系統僅關注科學數據全生命周期的某個環節,還缺乏面向大數據的、涉及全生命周期的、與分析系統緊密集成的科學數據管理系統.
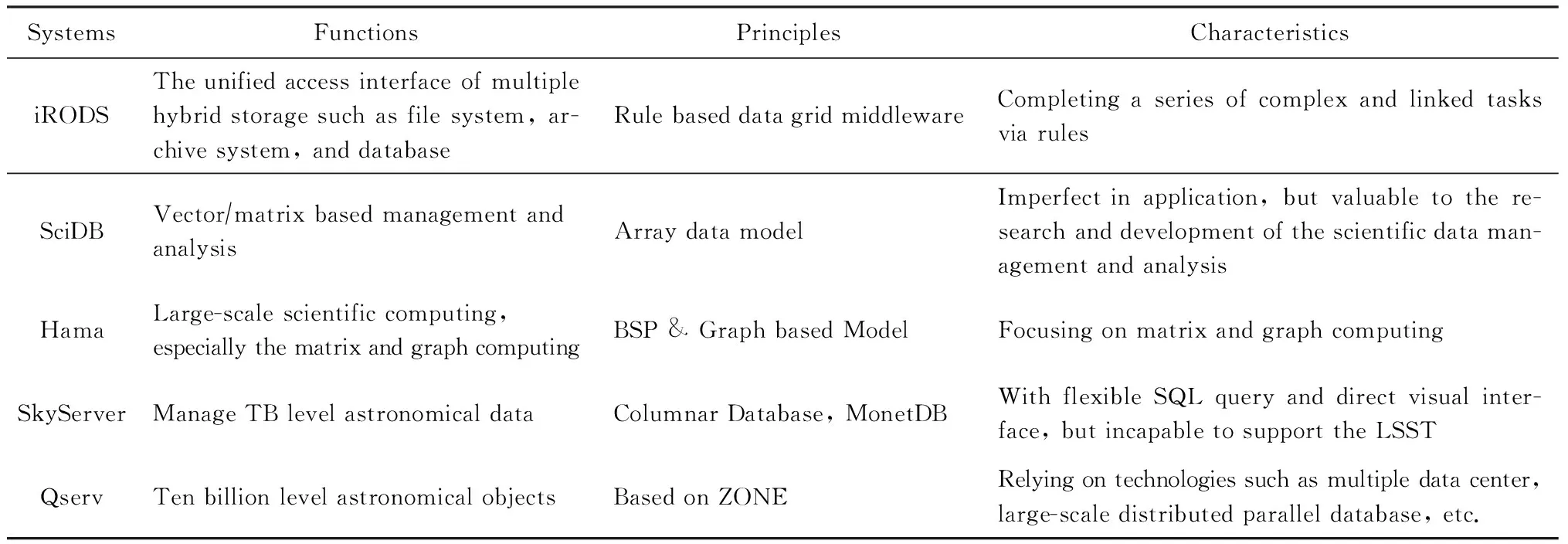
表3 現有科學數據管理系統對比分析
我國在科學數據管理技術與平臺軟件方面也有一些工作在展開,典型的如中國科學院通過信息化專項項目在“十二五”期間率先建成了“科學數據云”,形成了52 PB云存儲和上萬個虛擬機的云計算環境,研發部署了科學數據管理軟件TeamDR、數據發布與集成軟件VisualDB/VDBCloud[43-44]、數據服務注冊系統RSR、可視化服務平臺DVIZ[45]等20余項軟件工具.
面對源源不斷快速產生的大量數據文件以及從中分析生成的千億級科學對象的管理,我們還面臨著一系列的挑戰,包括EB級文件和萬億行關系數據的高效率、低成本、一體化存儲和管理,科學大數據快速索引,以支持大規模、交互式的查詢和處理;海量多源、多學科數據的自動關聯與融合;瞬時產生的海量數據實時或準實時的高效分析;以流水線的方式實現海量數據資源與科學模型的快速融合與并行處理等.
3 全域科學大數據管理系統框架
科學大數據數據管理的目的是最大限度提高科學發現的速度和能力,因此管理必須與科學發現的過程有機融合,要實現科學數據的采集、存儲、分析處理、發布與關聯融合、歸檔等全域管理,支持數據按需快速流動,支持各種類型的科學數據流水線的動態集成與調度.此外,要充分考慮到科學數據類型多樣性,應用需求多樣性和計算框架的多樣性,能以開放架構實現系統的按需擴展和動態演進.
為此,本文提出全域科學大數據管理框架,具體如圖4所示:
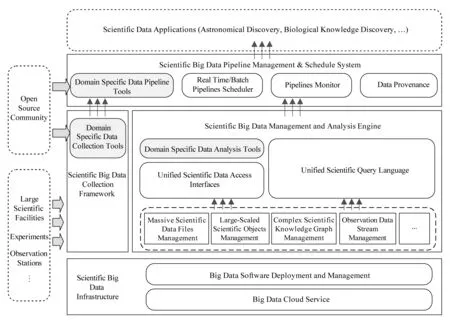
Fig. 4 Scientific big data management system圖4 科學大數據管理系統
主要組成部件包括科學大數據基礎平臺、科學大數據統一采集與匯聚框架、科學大數據管理與分析引擎、科學大數據流水線管理與調度系統,以及科學大數據應用環境.
科學大數據基礎平臺旨在構建大數據存儲與計算的云服務平臺,對存儲和計算資源進行管理及優化,提供基礎的大數據存儲和并行計算能力.同時配置大數據軟件部署與管理工具,實現Impala[46],HBase[47],Solr[48],TITAN[49],Cassandra[50]等大數據集群的按需部署與配置化管理,實現集群的橫向擴展,并通過提供運行監控界面,實現資源狀態可視化和及時告警.
科學大數據統一采集與匯聚框架是一個可擴展的、高容錯的、高吞吐量的科學大數據采集框架,實現科學大裝置、實驗觀測、臺站網絡等各類科學數據的統一接入,同時提供包括morphine轉換、正則轉換、模板轉換等靈活的數據轉換能力.針對各領域科學數據的采集的不同需求,提供個性化的學科領域大數據采集軟件,如天文巡天圖像數據采集、實驗觀測數據采集、臺站網絡觀測數據采集等.
科學大數據管理與分析引擎旨在支持海量分布式科學數據文件的索引和管理、萬億級事例數據的在線查詢與提取、高吞吐的觀測實驗流數據的在線分析與管理,以及大規模關聯圖的管理與分析計算.該引擎通過統一的查詢語言,實現對多元數據管理模型的統一訪問和查詢,包括對關系型數據、圖數據、KeyValue數據、列數據,以及文件系統的查詢.同時通過統一的編程式查詢分析一體化操作語言,實現對科學數據的大批量寫入與分析,通過函數式編程語言的特性,支持用戶在操作語句中自定義數據的轉換和分析算法.
科學大數據流水線管理與調度系統通過對數據的采集、存儲、查詢和分析過程的封裝,形成科學大數據流水線的軟件表達模型.通過流水線管理模塊,實現各領域數據流水線的統一集成管理.同時,基于大數據計算環境,實現數據流水線任務的轉換和運行調度,支持數據流水線任務的啟停、再放與回溯.針對各領域科學數據的分析處理的不同特征,集成個性化的學科領域大數據流水線處理軟件,如天體交叉證認流水線、生物信息關聯發現流水線、高能物理事件抽取流水線等.
4 關鍵技術
針對科學大數據的管理需求與特點,我們可將其涉及到的關鍵技術歸納為:科學大數據的融合、實時分析、長期存儲、云服務技術、開放共享機制等.
4.1 科學大數據融合
大數據時代人們面臨的最根本挑戰是從數據中凝練可領悟的知識[51-52].大數據融合的概念[53]是指聚合數據間、信息間、知識片斷間多維度、多粒度的關聯關系實現更多層面的知識交互,已廣泛應用于各個領域.比如商業領域中IBM Watson[54]利用大數據融合的關鍵技術輔助認知商業發展;生命科學利用Bio2RDF[55],Neurocommons[56]等知識圖譜做問答和決策等.
大數據融合不同于傳統數據庫領域的數據集成技術[57-59],也不同于傳統人工智能與認知科學中的知識融合技術[60-61].數據融合需要用動態的方式統一不同的數據源,將離散的數據轉化為統一的知識資源.知識融合是將數據融合階段獲得的籠統的知識轉化為可領悟知識,面向需求提供知識服務.它需要挖掘隱含知識,尋找潛在知識關聯,進而實現知識的深層次理解,以便更好地解釋數據.
以微生物領域為例,比如后基因組時代的系統生物學把生物系統內不同性質的構成要素以及系統內各個不同層次整合在一起進行研究[62].那么首先勢必要將基因、mRNA、蛋白質、生物小分子,以及從基因到細胞、到組織、再到每個水平的有機體等不同來源的數據進行融合.這個過程分4步完成:
1) 需要從不同數據源(如Taxonomy,Genbank,Gene,UniProt,PDB,KEGG,Pfam,GO等)抽取相關的實體和關系,或者從現存知識庫(如Neuroco-mmons,Bio2RDF)中直接轉化數據,這一過程中,隨著數據體量、種類、來源等動態變化,需要對構建的知識庫進行動態更新;
2) 識別出相同實體,并進行實體鏈接,比如識別出Bt蛋白與蘇云金桿菌蛋白是同一個蛋白,并且它們與知識庫中的實體Bt蛋白進行鏈接;
3) 在進行實體關聯時可能會存在歧義、沖突的情況,比如BT既可以表示蘇云金桿菌,也可以表示螞蟻磁力鏈接搜索引擎,這就需要沖突解決技術消除歧義;
4) Bt蛋白屬于晶體蛋白,如果我們為Bt蛋白構建了本體——晶體蛋白,那么也可以加速融合的效率,比如中國科學院微生物研究所構建Speices taxonomy,Protein(uniprot),Gene,Pathway(Kegg),Genome,Enzyme Reaction Data(Kegg)六個本體用于促進生物大數據的融合.
經過上述數據融合,我們僅僅使碎片化的數據相聯系、將分散的數據相集中,形成表層知識,即微生物知識資源;但是為了更好地探究生物數據之間繁雜的邏輯關系和特征,就要使隱性知識顯性化,使表層知識上升為普適機理.這個過程分4步完成:
1) 根據數據的分布規律歸納出數據的結構規則進而抽象出數據之間的關聯模式來表示知識,即要對微生物知識進行抽象與建模,比如把“蘇云金桿菌是產生Bt蛋白質的土壤細菌”這一知識用RDF三元組〈蘇云金桿菌,產生,Bt蛋白質〉和〈蘇云金桿菌,屬于,土壤細菌〉表示或者用低維向量的形式表示.
2) 通過關系推演技術顯性化隱性知識,比如中科院微生物研究所融合了36個不同的數據源約830萬個數據,從約4 000萬個顯示關聯關系中推演得到約1.4億個隱式關聯關系.
3) 除了隱性知識,還有更重要的深度知識,包括高階多元關系和隱含語義關系,比如魚類中的掠食者在食物富集時運動軌跡呈布朗運動,微生物菌群共生體系中可能存在基因共振現象,而單個培養的微生物中沒有共振現象[63].這種知識一般需要通過領域理論,運用數學、物理等工具,進行理論建模、解析、邏輯演繹、公式推演和證明獲得,如采用統計分析和深度學習的方法.
4) 人的智力能透過現象看到本質,只有發現大數據所呈現出的普遍現象背后的普適原理才能對客觀世界產生更大的影響.比如,社會網絡中社群的消失現象,他們背后的普適原理是生物進化論[64];增長和擇優機制在復雜網絡自組織演化中具有普遍性,它們使網絡在宏觀上具有冪律度分布的普適現象[65].這就搭建起了龐大復雜的人類社會與渺小精細的微生物群落之間的關聯.
從上述案例我們也可以看出,微生物大數據融合的數據融合用于“喂飽”人類對微生物知識的需求,而知識融合“反哺”生態系統的和諧發展.二者相互協調啟發才能最大限度地提升微生物大數據的價值.
4.2 科學大數據實時分析
科學領域已進入一個信息豐富的大數據時代,數據量正以TB級甚至PB級的速度增長.科學大數據的分析正在從傳統的批量處理向實時分析快速發展.
以天文領域GWAC全天短時標觀測系統為例,整個天區由40個GWAC相機陣同時監控,一個GWAC相機每15 s產生一個大約32 MB的天區圖,通過點源提取該天區圖將生成1.7×106條星表記錄.每副圖片的點源提取和星表記錄與模板表的交叉證認時間之和需小于15 s的延遲,這是一個典型的實時分析的應用場景.
天文大數據具有產生速度快、數據量大、周期時間長等特點,需要設計可快速入庫的緩存機制或消息隊列,提高數據的存儲能力和消息隊列的吞吐率.并采用分布式多級緩存機制或可擴展的消息隊列實現科學數據的快速存儲和傳輸.
為滿足高速數據采集下的實時分析,一般分為針對批量外存數據的大規模并行處理(massively parallel processing, MPP)技術和基于流式內存數據的數據流查詢處理技術.為便于快速查詢和實時分析內外存數據,可設計同時進行批量處理和流式處理的查詢適配器,通過統一的查詢接口實現不同數據類型的全量查詢結果.
此外,隨著數據量的累積和維度的增加,以及查詢和分析復雜度的不斷增長,實時返回用戶查詢結果越來越成為科學大數據系統的一個重要挑戰.目前,學術界和工業界的一個研究重點就是如何在科學大數據系統中支持交互式的數據查詢.這里的交互性體現在處理用戶查詢過程中系統及時不斷地提供反饋,這樣使得用戶能夠快速地做出反應和根據反饋結果更改或優化下一步的查詢條件,以找到最相關和最有意義的查詢結果.因此,交互性查詢分析也是實時分析的一個重要研究方向.
4.3 科學大數據長期存儲
現代科學大數據需要花費成百上千萬美元產生數據,通常會積累幾年到十幾年的數據,這些數據該如何有效地保存和利用一致是科學數據面臨的重大問題.大數據時代數據產生的速度更快,產生的量更大,如何長期存儲這些數據并提供高效的處理,或者說如何決定保存哪些數據淘汰哪些數據成為了當務之急.
以GWAC為例,根據天文數據的獨特要求,為了滿足對短期數據的快速實時查詢以及對數據的長期存儲,設計使用了正三角和倒三角模型對數據進行處理分析(如圖5所示).在數據的底層存儲中,通過使用HDFS對數據按照文件的方式進行存儲.將每一個星的數據保存成一個文件.單個星的文件隨著時間的積累不斷增加,而文件總數卻始終保持在百萬級.而HDFS面對海量小文件時的處理應對能力較弱,因此我們使用三角模型對數據進行處理.隨著時間的增加,將海量小文件逐步合并,越久遠的數據合并率越高,而近期的數據則保持不變,不進行合并.同時,隨著文件的合并,文件大小也會有所變化,當久遠的數據合并后,單一文件大小會不斷增大.通過這樣的方法,在文件個數和文件大小之間尋找平衡以滿足對數據的有效管理.
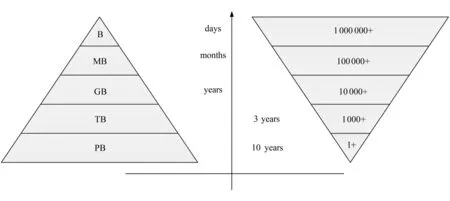
Fig. 5 Counts and sizes of long term stored scientific data圖5 科學大數據長期存儲文件數目與大小
總之,長期存儲系統的目標可以歸為3個:1)設計一個簡單一致的解決方案,計算與存儲資源混合在同一節點上,使其具備獨立運行能力;2)完成可擴張的和輕便的設計,以便能夠將所有設計布置到位于全球任何地方的合作單位;3)集安全性和適應性于一體,對于磁盤或結點丟失應具有健壯性,所有后備成員具備完全獨立性.
4.4 科學大數據云服務技術
隨著云服務提供給大數據管理和分析的質量得到不斷提高,云服務的多樣性也在穩步增長.科學大數據的管理與分析正好可以借助云服務的進步來更好地為科學研究提供助力,將計算資源和數據資源合理高效地整合到云端,更好地為科技工作者提供服務和幫助.
科學大數據云存儲服務不同于普通云存儲,其主要是面向大數據分析的超大規模存儲庫,一般要求能存儲非結構化和結構化數據且能提高分析性能的大吞吐量.由于受到傳統分析體系結構(例如架構的預定義)的限制,需要事先定義數據模式.為應對這一挑戰,引入數據湖概念,將它作為存儲在單一位置收集的各種類型數據的企業級存儲庫.出于科學探索分析目的,可在定義架構之前,所有類型的數據都可以存儲在數據湖中.因此當面對某種分析時,動態的創建數據模式是未來的主要挑戰.
科學領域的數據分析往往需要深度定制自身分析流程.科研人員需要調用基本API編程,但不同系統的API差異很大(如Spark和Hadoop的編程接口差異),導致程序移植性差.因此云分析服務面臨的基本挑戰是解耦底層數據分析系統和分析API直接的聯系,從而實現同樣的分析程序可在不同的大數據系統之間輕松移植,從而減輕科研人員的工作壓力.
4.5 科學大數據開放共享
數據只有在不斷的使用中才能產生價值,而且,數據資源天然具有可重復使用的特征.開放科學數據可確保科學研究結論的真實性和可重現性,可確保公共財政投入獲取的公共資源,能最大限度地產生價值,可支持數據跨領域、跨學科的融合和重復使用,從而加快科學發現的進程.世界經濟合作與發展組織OECD提出了科學數據開放的基本原則[66],Force11明確了有效開放的“FAIR”(findable,accessible,interoperable,reusable)標準[67-68],國際科學聯合會ICSU發布了“大數據時代開放數據公約”,明確了在數據開放過程中各利益相關方的責任.
科學大數據開放共享一個基本的共識是,研究項目及其相關數據收集完成時,公共財政支持產生的數據應可公開訪問及最大限度地再利用.如生命科學領域的基因序列數據庫GenBank,通過和國際著名學術期刊合作,強制要求學術論文作者在提交論文時,必須先將數據提交到GenBank數據庫中,為全人類積累了一個龐大的基因序列數據庫.再如,Sloan數字巡天項目SDSS,已經先后向全世界發布了13版的巡天數據.
概括起來,科學大數據開放共享方式主要包括:
1) 通過國際合作項目或合作網絡驅動的開放共享,典型的如GEOSS[69],GBIF[70], WDCM[71]等.這種方式要求所有參與者按照大家共同認可的規則開放數據和使用數據.
2) 通過學術期刊驅動的開放共享,典型的如基因序列數據庫EMBL/GenbankDDBJ.
3) 通過公共存儲庫和公共服務驅動的開放共享,典型的如SDSS,Dryad[72],Fig share[73]等.這種方式通過建立一個領域內或者跨領域的公共數據庫或公共數據存儲平臺,以服務的方式來匯聚和開放數據資源.
4) 數據出版和引用機制,典型的如Nature旗下的Scientific Data[74]、ESSD[75]、《中國科學數據》[76]等,通過數據論文的發表和引用來激勵科研人員開放數據,并提高數據的可理解性和可重用性.此外,以數據交易的形式提供服務的數據集市機制,也開始有一些嘗試,但是其是否適合于科學數據,還有待進一步觀察.
在科學數據的開放共享中,不同的學科、不同的數據、不同的組織乃至國家,其采用的機制、模式等可能均不同,不能一概而論,也不存在“One size fits all”的解決方案.但在任何一種機制的設計中,必須首先明確參與數據開放共享的各相關方的利益和訴求,要通過建立有效的激勵機制、利益分配機制和評估評價機制等來有序推進,而且其中數據權屬的問題、隱私問題、安全問題,也不可忽視.
5 總結和展望
大數據時代科學研究是一個大科學、大需求、大數據、大計算、大發現的過程.數據密集型科學發現已經成為繼實驗科學、理論推演、計算機仿真這3種科研范式相輔相成的科學研究第四范式.先進的科學大數據管理和處理可以為各學科領域的新發現提供堅實的技術基礎,能夠加速具有國際影響力的科技成果的產出過程,具有重要的科學價值.
然而,為了更好地促進科學研究,科學大數據的管理還存在著較大的技術挑戰,包括EB級文件和千億行關系數據的高效率、低成本、一體化存儲和管理,科學大數據快速索引,以支持大規模、交互式的查詢和處理;海量多源、多學科數據的自動關聯與融合;瞬時產生的海量數據實時或準實時的高效分析;以流水線的方式實現海量數據資源與科學模型的快速融合與并行處理等.
為此,我們需突破科學大數據管理與分析的關鍵問題,研發一體化全流程科學大數據管理系統,成為大數據時代重大科技創新活動必要的“使能利器”,也成為廣大科研人員“軍械庫”中的“殺手锏”,幫助他們從大數據中高效、快速地發現新知識,取得新的突破.
[1]Greenberg J. Big data, little data, no data: Scholarship in the networked world[J]. Leonardo, 2016, 49(1): 91-92
[2]Barwick H. The “four Vs” of Big Data, Implementing Information Infrastructure Symposium[EB/OL]. North Sydney NSW: IDG Communications Pty Ltd. (2012-10-02) [2016-10-10]. http://www.computerworld.com.au/article/396198/iiis_four_vs_big_data/
[3]IBM. What is big data? [EB/OL].Armonk, NY: IBM Corporation. (2012-10-02) [2016-10-12]. http://www-01.ibm.com/software/data/bigdata/
[4]Wikimedia. Big data[EB/OL]. 2016 [2016-10-02]. http://en.wikipedia.org/wiki/Big_data
[5]Kaufman Y J, Justice C, Flynn L, et al. Monitoring global fires from EOS-MODIS[J]. Journal of Geo-Physical Research, 1998, 103(D24): 32215-32238
[6]Wan Meng, Wu Chao, Wang Jing, et al. Column store for GWAC: A high-cadence, high-density, large-scale astronomical light curve pipeline and distributed shared-nothing database[J]. Publications of the Astronomical Society of the Pacific, 2016, 128(969): 114501-114516
[7]Bourne P E, Bonazzi V, Dunn M, et al. The NIH big data to knowledge (BD2K) initiative[J]. Journal of the American Medical Informatics Association, 2015, 22(6): 1114-1114
[8]Chen Guangren, Zhu Yu, Su Qing. Science programs lead to the future[J]. Science Technology Review, 2014, 32(31): 15-28 (in Chinese)(陳廣仁, 朱宇, 蘇青. 引領未來的科學計劃[J]. 科技導報, 2014, 32(31): 15-28)
[9]Jones B. Towards the open European science cloud[C] // Digital Era Forum. Zenodo, 2015: 1-21
[11]LSST. LSST Public Website Sitemap[OL]. Tucson, AZ. LSST Corporation. [2016-10-02]. http://www.lsst.org/lsst/science/scientist_transient
[12]Ivezic Z, Tyson J A, Abel B, et al. LSST: From science drivers to reference design and anticipated data products[J]. American Astronomical Society, 2008, 41: 366
[13]Becla J, Szalay A, Gray J. Designing a multi-petabyte database for LSST[C] //Proc of SPIE Astronomical Telescopes+ Instrumentatio. Bellingham: WASPIE Publica-tions, 2006: 62700R-62700R
[14]Mao Daowei, Su Xia. The initial progress of the model reforming, the characteristics of the cultivating talents-Students fromthe Beijing Genomics Institute (BGI) frequently publish works in Science and Nature[J]. Guangdong Science & Technology, 2010, 19(11): 15-18 (in Chinese)(毛道偉, 孫俠. 模式改革初顯成效人才培養漸成特色——華工-華大基因組科學創新班學生《Science》、《Nature》頻亮相引關注[J]. 廣東科技, 2010, 19(11): 15-18)
[15]Brooksbank C, Cameron G, Thornton J. The European Bioinformatics Institute’s data resources: Towards systems biology[J]. Nucleic Acids Research, 2005, 33(Suppl 1): 46-53
[16]Rao Dongmei. NCBI data base and its resource access[J]. Science & Technology Vision, 2013 (7): 53-54 (in Chinese)(饒冬梅. NCBI數據庫及其資源的獲取[J]. 科技視界, 2013 (7): 53-54)
[17] Li Guojie. The recognition of big data[J]. Big Data, 2015, 1(1): 1-9 (in Chinese)(李國杰. 對大數據的再認識[J]. 大數據, 2015, 1(1): 1-9)
[18]Andreeva J, Campana S, Fanzago F, et al. High-energy physics on the grid: The ATLAS and CMS experience[J]. Journal of Grid Computing, 2008, 6(1): 3-13
[19]Chen J, Wang W, Li Z Y, et al. Landsat 5 satellite overview[J]. Remote Sensing Information, 2007, 43(3): 85-89
[20]The results summary of the information special project “integration and share of data resources” in Chinese Academy of Science. Science and Technology Daily[N]. Beijing: Science and Technology Daily Press, 2016-04-05 (in Chinese)(中科院“十二五”信息化專項科技數據資源整合與共享工程成果概述. 科技日報[N]. 北京: 科技日報社, 2016-04-05)
[21]Moore R, Chen S Y, Schroeder W, et al. Production storage resource broker data grids[C] //Proc of IEEE Int Conf on E-Science & Grid Computing. Los Alamitos, CA: IEEE Computer Society, 2006: 147
[22]Manandhar A, Dam K K V, Berrisford P, et al. Deploying a distributed data storage system for grid applications on the National Grid Service using federated SRB[C] //Proc of the UK e-Science All Hands Meeting. Edinburgh. UK: National e-Science Centre, 2004
[23]Hedges M, Hasan A, Blanke T. Management and preser-vation of research data with iRODS.[C] //Proc of the 16th ACM Conf on Information and Knowledge Management, Workshop on Cyberinfrastructure: Information Management in Escience (CIMS 2007, CIKM 2007). New York: ACM, 2007: 17-22
[24]Conway M, Moore R, Rajasekar A, et al. Demonstration of policy-guided data preservation using iRODS[C] //Proc of IEEE Int Symp on Policies for Distributed Systems and Networks. Los Alamitos, CA: IEEE Computer Society, 2011: 173-174
[25]Antunes G, Barateiro J. Securing the iRODS metadata catalog for digital preservation[M] //Research and Advanced Technology for Digital Libraries. Berlin: Springer, 2009: 412-415
[26]Cudre-Mauroux P, Kimura H, Lim K T, et al. A demons-tration of SciDB: A science-oriented DBMS[J]. VLDB, 2009, 2(2): 1534-1537
[27]Stonebraker M. SciDB: An open-source DBMS for scientific data[J]. ERCIM News, 2012, 89: 13
[28]Stonebraker M, Becla J, Dewitt D J, et al. Requirements for science data bases and SciDB[C] //Proc of the Conf of CIDR. New York: ACM, 2009: 173-184
[29]Hammami R, Zouhir A, Naghmouchi K, et al. SciDBMaker: New software for computer-aided design of specialized biological databases[J]. BMC Bioinformatics, 2008, 9(1): 1-6
[30]Stonebraker M, Brown P, Becla J, et al. SciDB: A database management system for applications with complex analytics[J]. Computing in Science & Engineering, 2013, 15(3): 54-62
[31]Cudré-Mauroux P, Kimura H, Lim K T, et al. A demonstration of SciDB: A science-oriented DBMS[J]. VLDB Endowment, 2009, 2(2): 1534-1537
[32]Stonebraker M, Duggan J, Battle L, et al. SciDB DBMS research at MIT[J]. IEEE Data Engineering Bulletin, 2013, 36(4): 21-30
[33]Paul G Brown. Overview of SciDB: Large scale array storage, processing and analysis[C] //Proc of Conf of SIGMOD. New York: ACM, 2010: 963-968
[34]Stonebraker M, Brown P, Poliakov A, et al. The architecture of SciDB[C] // Proc of Scientific and Statistical Data Management Conf. Berlin: Springer, 2011: 1-16
[35]Becla J, Lim K T. Report from the SciDB workshop[J]. Data Science Journal, 2008, 7: 88-95
[36]Seo S, Yoon E J, Kim J, et al. HAMA: An efficient matrix computation with the MapReduce framework[C] //Proc of Cloud Computing Technology and Science (CloudCom). Piscataway, NJ: IEEE, 2010: 721-726
[37]Luo S, Liu L, Wang H, et al. Implementation of a parallel graph partition algorithm to speed up BSP computing[C] //Proc of Fuzzy Systems and Knowledge Discovery (FSKD). Piscataway, NJ: IEEE, 2014: 740-744
[38]Suchanek F M, Weikum G. Knowledge bases in the age of big data analytics[J]. VLDB Endowment, 2014, 7(13): 1713-1714
[39]Suchanek F, Weikum G. Knowledge harvesting in the big-data era[C] //Proc of ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2013: 933-938
[40]Szalay A S, Gray J, Thakar A R, et al. The SDSS SkyServer, public access to the sloan digital sky server data[C] //Proc of SIGMOD. New York: ACM, 2002: 570-581
[41]Raddick M J, Szalay A S, Gray J N, et al. Two years of SkyServer: Education and outreach with sloan digital sky survey data[J]. Bulletin of the American Astronomical Society, 2003, 35(3): 718
[42]Wang D L, Monkewitz S M, Lim K T, et al. Qserv: A distributed shared-nothing database for the LSST catalog[C] //Proc of High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2011: 1-11
[43]Shen Z, Li J, Li C, et al. VisualDB: Managing and publishing scientific data on the Web[C] //Proc of Int Conf on Cyber-Enabled Distributed Computing and Knowledge Discovery, Cyberc. Piscataway, NJ: IEEE, 2011: 399-404
[44]Huo D M, Li S, Xu C. Service system of the South China Sea science data products based on VisualDB[J]. Journal of Tropical Oceanography, 2012, 31(2): 118-122
[45]Du Yi, Guo Danhuai, Chen Xi, et al. Model-driven visualization generation system[J].Journal of Software, 2016, 27(5): 1199-1211 (in Chinese)(杜一, 郭旦懷, 陳昕, 等. 一種模型驅動的可視化生成系統[J]. 軟件學報, 2016, 27(5): 1199-1211)
[46]Taft D K. Cloudera Impala 1.0 Brings SQL to Hadoop for Real-Time Queries[EB/OL]. Foster City, CA: Eweek, (2013-05-12) [2016-10-10]. http://www.eweek.com/database/cloudera-impala-1.0-brings-sql-to-hadoop-for-real-time-queries
[47]Vora M N. Hadoop-HBase for large-scale data[C] //Proc of Int Conf on Computer Science and Network Technology. Piscataway, NJ: IEEE, 2011: 601-605
[48]Abdelouarit K A, Sbihi B, Aknin N. Solr, lucene and Hadoop: Towards a complete solution to improve research in big data environment (Case of the UAE)[C] //Proc of the Mediterranean Congress of Telecommunications. Los Alamitos, CA: IEEE Computer Society, 2016: 363-367
[49]Jouili S, Vansteenberghe V. An empirical comparison of graph databases[C] //Proc of Int Conf on Social Computing. Piscataway, NJ: IEEE, 2013: 708-715
[50]Lakshman A, Malik P. Cassandra: A decentralized structured storage system[J]. AcmSigops Operating Systems Review, 2010, 44(2): 35-40
[51]Suchanek F M, Weikum G. Knowledge bases in the age of big data analytics[J]. Proceedings of the VLDB Endowment, 2014, 7(13): 1713-1714
[52]Suchanek F, Weikum G. Knowledge harvesting in the big-data era[C] //Proc of the 2013 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2013: 933-938
[53]Meng Xiaofeng, Du Zhijuan. Research on the big data fusion: Issues and challenges[J]. Journal of Computer Research and Development, 2016, 53(2): 231-246 (in Chinese)(孟小峰, 杜治娟. 大數據融合研究: 問題與挑戰[J]. 計算機研究與發展, 2016, 53(2): 231-246)
[54]IBM. Shop hardware, software and services from IBM and our partners[OL]. IBM Watson. 2016[2016-10-13]. http://www-31.ibm.com/ibm/cn/cognitive/outthink/
[55]Belleau F, Nolin M A, Tourigny N, et al. Bio2RDF: Towards a mashup to build bioinformatics knowledge systems[J]. Journal of Biomedical Informatics, 2008, 41(5): 706-716
[56]Lenzerini M. Data integration: A theoretical perspective[C] //Proc of the 21st ACM SIGMOD-SIGACT-SIGART Symp on Principles of Database Systems. New York: ACM, 2002: 233-246
[57] Meng Xiaofeng, Liu Wei, Jiang Fangjiao, et al. Web Data Management Principle and Technology[M]. Beijing: Tsinghua University Press, 2014 (in Chinese)(孟小峰, 劉偉, 姜芳艽, 等. Web數據管理:概念與技術[M].北京: 清華大學出版社, 2014)
[58]Dong X L, Srivastava D. Big data integration[C] //Proc of Int Conf on Data Engineering (ICDE). Piscataway, NJ: IEEE, 2013: 1245-1248
[59]Dong X, Gabrilovich E, Heitz G, et al. Knowledge vault: A Web-scale approach to probabilistic knowledge fusion[C] //Proc of SIGKDD. New York: ACM, 2014: 601-610
[60]Jan M. Linked data integration[D]. Progue: Charles University in Prague, 2013
[61]Samarati P, Sweeney L. Generalizing data to provide anonymity when disclosing information (abstract)[C] //Proc of PODS. New York: ACM, 1998: 188
[62]Zieglg?nsberger W, Toile T R. The pharmacology of pain signalling[J]. Current Opinion in Neurobiology, 1993, 3(4): 611-618
[63]Chen Y, Kim J K, Hirning A J, et al. Emergent genetic oscillations in a synthetic microbial consortium[J]. Science, 2015, 349(6251): 986-989
[64] Givan M, Newman M E J. Community structure in social and biological networks[C] //Proc of the National Academy of Sciences of the United States of America. Los Gatos, CA: HighWire Press, 2001: 7821-7826
[65]Barabási A L, Albert R. Emergence of scaling in random networks[J]. Science, 1999, 286(5439): 509-512
[66]Pilat D, Fukasaku Y. OECD principles and guidelines for access to research data from public funding[J]. Data Science Journal, 2007, 6: OD4-OD11
[67]Wilkinson M D, Dumontier M, Aalbersberg I J J, et al. The FAIR guiding principles for scientific data management and stewardship[J]. Scientific Data, 2016, 3: 1-9
[68]Force11. Guiding principles for findable, accessible, interoperable and re-usable data publishing version b1.0 [EB/OL]. [2016-09-10]. https://www.force11.org/fairprinciples
[69]Wikimedia. GEO.GEOSS: The Global Earth Observation System of Systems. [EB/OL]. [2016-09-10]. http://www.earthobser vations.org/geoss.shtml
[70] GBIF(Global biodiversity information facility). Free and Open Access to Biodiversity Data|GBIF.org[EB/OL]. [2016-09-10]. http://www.gbif.org/
[71]Sun Q, Li L, Wu L, et al. Web resources for microbial data[J]. Genomics Proteomics Bioinformatics, 2015, 42(1): 69-72
[72]Dryad. Submission integration[EB/OL]. [2016-09-10]. http://datadryad.org/
[73] Hahnel M. Exclusive: Figshare a new open data project that wants to change the future of scholarly publishing[EB/OL]. 2012 [2016-09-10]. https://core.ac.uk/download/pdf/16380431.pdf
[74]Nature. Scientific Data[EB/OL]. [2016-09-10]. http://www.nature.com/sdata/
[75]ESSD. Earth System Science Data[EB/OL]. [2016-09-10]. http://www.earth-system-science-data.net/
[76] CSData. Chinese Science Data[EB/OL]. [2016-09-10]. http://www.csdata.org/ (in Chinese)(CSData.中國科學數據(中英文網絡版)[EB/OL]. [2016-09-10]. http://www.csdata.org/)

Li Jianhui, born in 1973. PhD, professor. His main research interests include open data policy and practice, large scale distributed data integration and data cloud service, big data management, big data computing and analysis for science discovery.

Shen Zhihong, born in 1977. PhD, professor. His main research interests include scientific data management and integration, linked data and big data management.

Meng Xiaofeng, born in 1964. PhD, professor at Renmin University of China. CCF fellow. His main research interests include data fusion and knowledge fusion, big data management for new hardware, big data real time and interactive analysis, and big data privacy management.
Scientific Big Data Management: Concepts, Technologies and System
Li Jianhui1, Shen Zhihong1, and Meng Xiaofeng2
1(ComputerNetworkInformationCenter,ChineseAcademyofSciences,Beijing100190)2(SchoolofInformation,ReminUniversityofChina,Beijing100872)
In recent years, as more and more large-scale scientific facilities have been built and significant scientific experiments have been carried out, scientific research has entered an unprecedented big data era. Scientific research in big data era is a process of big science, big demand, big data, big computing, and big discovery. It is of important significance to develop a full life cycle data management system for scientific big data. In this paper, we first introduce the background of the development of scientific big data management system. Then we specify the concepts and three key characteristics of scientific big data. After an review of scientific data resource development projects and scientific data management systems, a framework is proposed aiming at the full life cycle management of scientific big data. Further, we introduce the key technologies of the management framework including data fusion, real-time analysis, long termstorage, cloud service, and data opening and sharing. Finally, we summarize the research progress in this field, and look into the application prospects of scientific big data management system.
scientific data; big data; data pipeline; full life cycle of data
2016-11-15;
2017-01-14
國家重點研發計劃項目(2016YFB1000600) This work was supported by the National Key Research Program of China (2016YFB1000600).
TP391
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國科技教育(2019年11期)2019-09-26 10:49:15
中國科技教育(2019年12期)2019-09-23 08:02:08
小小藝術家(2019年6期)2019-06-24 17:39:44
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
今古傳奇·故事版(2016年15期)2016-09-07 06:57:32
小雪花·成長指南(2015年3期)2015-05-04 00:04:37
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
