基于文本挖掘技術的高血壓用藥規律研究*
2017-02-22 09:02:55李艷紅沈瑞琪歐敬民
網絡安全與數據管理 2017年3期
李艷紅,沈瑞琪,歐敬民
(1.上海財經大學 信息管理與工程學院,上海 200433;2.上海交通大學醫學院附屬新華醫院 普外科,上海 200092)
基于文本挖掘技術的高血壓用藥規律研究*
李艷紅1,沈瑞琪1,歐敬民2
(1.上海財經大學 信息管理與工程學院,上海 200433;2.上海交通大學醫學院附屬新華醫院 普外科,上海 200092)
大數據時代的來臨日益凸顯數據挖掘技術的價值。文本挖掘作為數據挖掘的研究分支,對非結構化數據的知識發現有重要意義。高血壓患病人群廣,發病率高,治療藥物種類繁雜,尋找其中的用藥規律,是臨床醫學的一個重要方向。基于文本挖掘技術,從在線醫療網站獲取醫患互動論壇數據,進行文本預處理,基于TF-IDF算法發現高血壓常用中西藥、非藥物治療、并發癥用藥特點等,結合關聯規則算法挖掘“癥-藥”關系,有益于高血壓的臨床判斷及用藥研究。另外,驗證了在線醫療網站醫患互動數據用于疾病研究的可用性和效果。
高血壓;文本挖掘;用藥規律;TF-IDF;關聯規則
0 引言
文本挖掘能抽取分散在文本數據中未被發現的、有價值的、能被用戶理解的知識,從而更好地組織信息,是數據挖掘的一個研究分支。大數據時代的數據量龐大,類型繁多,價值密度低。利用傳統的信息檢索技術處理如此大量瑣碎的文本數據顯然力不從心,文本挖掘漸漸受到重視。大量醫學信息以非結構化文本的形式充斥互聯網,如醫療新聞、生物醫學文獻、在線醫療網站上的醫患互動論壇等,應用文本挖掘知識以及技術從中發現隱含潛在的規律,已成為醫學研究的一個重要方向。
高血壓是目前最常見的疾病,據統計,全國高血壓患者接近2.7億,15歲及以上高血壓發病率達四分之一,并有逐漸增多的趨勢。治療使用的中西藥種類繁多,而且不斷有研發出的新藥用于臨床。尋找高血壓的用藥規律,是臨床醫學的一個重要任務。
本文基于文本挖掘技術,抓取國內知名在線醫療網站上關于高血壓的醫患問答文本,獲取高血壓的相關知識,所得結論供醫生和病人參考,有益于高血壓臨床判斷及用藥研究。
1 文獻綜述
文本挖掘在生物信息和生物制藥領域的應用取得成功,為其在中醫藥領域的應用建立了案例。參考文獻[1]指出文本挖掘技術對中醫藥文獻分析是一種很有前景的方法。目前,文本挖掘技術也確實在我國的中醫藥領域被廣泛運用,越來越多的學者基于中醫藥文獻使用文本挖掘技術研究某疾病用藥規律,僅針對高血壓疾病,文獻[2-3]基于中國生物醫學文獻數據庫中檢索的高血壓診療相關文獻,進行必要的數據清洗后,參考文獻[2]對每一篇文獻共同出現的關鍵詞對構建關鍵詞對程序算法,合并相同的關鍵詞對,根據出現的頻數找出常用的中西藥;參考文獻[3]采用基于敏感關鍵詞頻數統計的數據分層算法,挖掘高血壓中醫癥狀、證候以及用藥規律。目前國內尚未見到網絡數據用于醫學研究,在國外,有相應的工作發布,如參考文獻[4]認為網絡和社會媒體數據是重要的疾病監測資源,基于其上的文本挖掘研究不僅能預測流感趨勢,還能通過社交網絡的異常進行生物事件的探測;參考文獻[5]試圖建立一個機器學習方法,從社交媒體中高度非正式的描述性文本中提取藥物不良反應信息;參考文獻[6]發現網絡和社會化媒體的謾罵相關信息可用于監控濫用處方藥;參考文獻[7]調查了是否在線醫療社區的社交支持交換有利于患者的心理健康,如憂郁癥;參考文獻[8]針對twitter用戶使用樸素和日常的語言來描述他們的疾病,經常報告綜合癥狀,而不是一個疑似或確診等特點,發現twitter有潛力成為一個內容豐富和低成本的數據源,可用于癥狀監測。
用藥規律研究方面,包括參考文獻[1]在內的已有文獻都只挖掘出常用中藥及西藥的用藥規律,鮮有研究“癥-藥”關聯。另外,數據源都是直接從生物醫學文獻數據庫檢索的文獻。雖然文獻的數據更具權威性,但已被人為處理過。根據國外的研究成果,已知網絡數據在醫學某方面應用的有效性,直接從網上抓取的數據更具客觀性、先進性以及臨床價值。所以,本文在研究方法和數據源選擇方面進行新的嘗試。
2 研究設計
本文的研究工作路徑設計如下:數據爬取→文本預處理(分詞和過濾)→抽取關鍵詞→文本向量化→知識獲取。
數據獲取是研究的第一步,使用Python設計兩層網絡爬蟲,使用Scrapy架構,采用Spider作為爬蟲設計的基類來獲取網絡數據源。中文文本預處理最基礎的一個工作就是分詞。非結構化的文本數據會摻雜大量對結果沒有影響的無意義的單詞,處理文本時需要過濾掉。在哈工大擴展停用詞表的基礎上手工添加了若干如“疾病”、“醫生”這些對研究沒有幫助的高頻詞,導入到結巴分詞中,完成文本預處理。由于文本包含的信息和詞條繁雜,直接進行文本向量化維數過大,因此需要先進行特征提取降維。使用詞頻-反詞頻(Term Frequency-Inverse Document Frequency, TF-IDF)方法更客觀地權衡某詞語的重要程度,實現關鍵詞的自動抽取。文本向量化是把文本數據從非結構化轉到結構化的重要一步,使用Python機器學習包scikit-learn完成文本向量化的過程。最后,基于詞頻統計信息和關聯規則的經典算法Apriori完成高血壓用藥相關知識獲取。
3 實證分析過程
3.1 獲取數據
爬取到2013~2016年尋醫問藥在線醫療網站上高血壓相關醫患互動文本數據57 000條。
3.2 文本預處理
導入自定義詞典,自定義詞典為高血壓相關的醫學專有名詞以及藥名。導入哈工大停用詞典。進行分詞。
3.3 獲取關鍵字
首先使用基于詞頻統計的方法抓取關鍵詞,得出病人提問部分主要集中在患者對血壓(“高壓”、“低壓”)、病史(如“心臟病”、“糖尿病”、“冠心病”等),以及癥狀(“頭暈”、“頭疼”)的描述。醫生回答部分主要為藥名。設置參數輸出指定詞性的關鍵詞,抓取名詞關鍵詞作為特征提取能更高效地挖掘用藥規律。選用同時兼顧詞頻和詞重要性的TF-IDF方法自動抽取關鍵詞。
3.4 文本向量化
將TF-IDF結果轉換成對應稀疏矩陣。每行對應一個文件,共有57 000行,列由關鍵詞表組成。然后進行高血壓用藥相關知識獲取。
4 高血壓用藥知識獲取
4.1 基于詞頻獲取高血壓常用中西藥及非藥物治療
由于中藥種類繁多,量效關系復雜,用藥配比規定嚴格,在線醫療網站上醫生答復以西藥為主,故所得中藥成分相關數據頻數普遍較小。選取部分頻數相對比較高的,可見治療高血壓常用中藥以丹參、山楂、牛黃、決明子、菊花、天麻、葛根為主,多有祛風解毒、清肝補腎之藥效,如圖1所示。文獻[2][3]得出治療高血壓病最常用的中藥是天麻、鉤藤、丹參、地黃,最常用的中成藥是丹參注射液和珍菊降壓片。本研究未細致區分中藥和中成藥,導致丹參兼具中藥成分和注射液的雙重身份,故頻數最多,所以本文結論與文獻[2][3]類似。
治療高血壓的常用西藥頻數統計如圖2。可見鈣通道拮抗劑類藥物使用較多,繼續對其進行分析。根據圖3可知,硝苯地平頻數最多,是鈣通道拮抗劑中使用最廣的藥物。
表1為ACEI類各藥物的目前使用頻數表,顯示ACEI類藥物中卡托普利及依那普利應用最廣泛,占ACEI藥物的60%和35%。

圖3 鈣通道拮抗劑類藥物頻數圖
ARB類各藥物的使用頻數如表2,可見替米沙坦、纈沙坦使用較多,分別占比34%和30%。
利尿劑使用氫氯噻嗪、吲達帕胺兩種最多,氨苯蝶啶和螺內酯也起利尿作用,但頻數較低,如圖4。

表1 ACEI類各藥物的使用頻數表

表2 ARB類各藥物的使用頻數表

圖4 利尿劑類藥物使用頻數圖
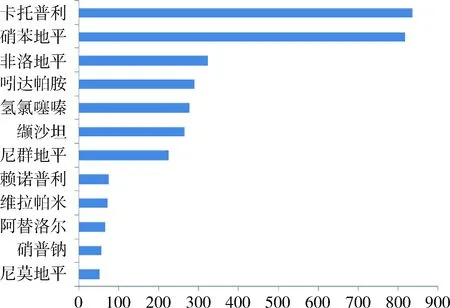
圖5 文獻[2]高血壓病常用西藥使用文獻頻數圖
如圖5所示為文獻[2]對高血壓病常用西藥使用情況的研究結果。本文研究對目前高血壓西藥的用藥情況結論與文獻[2]類似,排名前三的藥物是一樣的。本文在高血壓西藥大的分類框架下做了更細致的分析,提供了更詳細的信息。硝苯地平是臨床常用的降壓藥,也是一種不可多得的急救藥,特別是舌下含化,療效迅速。根據資料和專家求證發現硝苯地平能否作為長期降壓藥,理論和實踐中存在分歧。從本文研究數據中看,它的使用位居榜首,從圖5可見它的使用基本持平卡托普利。圖5結論基于中國生物醫學文獻數據庫數據,更反映臨床研究。本文研究基于互聯網醫患互動論壇數據,涉及面更廣,反映廣大患者的實際使用。二者近似相同,證實了本文研究一定程度的可信性。同時也提出了疑問,目前硝苯地平如此多的使用,是否存在誤用問題,有待于引發思考,進一步求證。
由圖6可見,除了藥物治療以外,改變生活習慣,食療和鍛煉也是治療高血壓的常用療法。高血壓患者要注意:低脂低鹽,保持情緒穩定,戒煙忌酒,飲食清淡,注意睡眠,多吃蔬菜,補充維生素,多參加體育鍛煉,多喝水等。

圖6 高血壓其他治療方法
4.2 基于關聯規則獲取“癥-藥”關系
基于詞頻統計獲得的高血壓癥狀信息如圖7,可見高血壓常見癥狀為頭暈、頭痛、惡心嘔吐、水腫等。頭暈、頭痛為最主要的兩大癥狀,此結論與文獻[3]一致。根據圖7,可把高血壓癥狀主要分為3類:影響患者腦部血管引起患者頭痛、頭暈、耳鳴;影響患者心血管機能造成患者心悸、心絞痛;造成患者四肢乏力、麻木、水腫。

圖7 高血壓癥狀頻數統計圖
本文數據源并非權威的文獻,患者癥狀描述或醫生答復并不詳盡,數據集的稀疏度決定最小支持度不能太高。同時再次對數據進行清洗去噪,把矩陣中不包含關鍵詞和只包含一個關鍵詞的評論刪除以增加數據的密集度。經過多次嘗試,降低最小支持度至5%,計算出滿足置信度50%的強規則有:
規則1:頭痛→頭暈,最小置信度為53.1%;
規則2:頭痛→鈣通道拮抗劑,最小置信度為53.3%;
規則3:水腫→利尿劑,最小置信度為67.2%。
由規則1可知,出現頭痛癥狀的高血壓患者通常伴有頭暈,這兩種癥狀都與腦部血管有關。規則2和規則3都是“癥-藥”的強規則。規則2說明如高血壓患者出現頭疼,醫生通常都會使用鈣通道拮抗劑類的藥。規則3的置信度接近70%,“癥-藥”關系比較強,可推斷高血壓患者若出現水腫的癥狀,醫生通常會開利尿劑配合降壓藥使用。挖掘出的“癥-藥”規則較少,可能是由于沒有經過面診的文本數據質量不高,還因為高血壓病理復雜,并發疾病多,用藥需要結合患者年齡、病史、并發疾病以及進一步的儀器檢查方能確定,因此單一的“癥-藥”關聯較弱。
4.3 基于詞頻獲得高血壓并發癥用藥特點
高血壓病人常伴有糖尿病、動脈硬化、冠心病、腦梗塞、血栓、中風或腎臟病等,如圖8。這幾種疾病或者病因是相通的,疾病的危害互相影響。根據并發癥的不同,癥狀與治療方法也有所不同。探究高血壓并發癥用藥特點,以高血壓合并“冠心病”、“糖尿病”、“腎病”為例進行研究。篩出包含如上某個并發癥的數據,比較篩選前后關鍵詞頻率變化較大的項,可知:高血壓合并冠心病的患者出現“心悸”、“胸悶氣短”、“心絞痛”癥狀更頻繁。與之對比,單單高血壓的患者出現以上3種癥狀的頻率則低得多,并發“腦梗塞”、“動脈硬化”的頻率也只有并發冠心病患者的1/2。用藥方面,并發冠心病的高血壓患者使用鈣通道拮抗劑的頻率為48.3%,接近篩選前的兩倍多,可見并發冠心病的高血壓患者更傾向于使用鈣通道拮抗劑作為首選降壓藥。由整體數據可知,高血壓并發糖尿病關鍵字詞頻總體上比高血壓低,說明癥狀與高血壓基本相同。四肢的癥狀如“四肢乏力”、“水腫”、“麻木”頻率稍微比單純高血壓患者高一點,說明高血壓并發糖尿病后容易出現這些癥狀,可多吃利尿的食物。肥胖的患者更容易出現高血壓并發糖尿病,高血壓并發糖尿病患者也更容易出現昏厥,所以高血壓患者要多運動減肥,防止低糖。對于高血壓合并腎臟病,“低鹽”、“低脂肪”詞頻高達70%以上,說明高血壓腎病患者要尤其注重低鹽、低脂肪的飲食,同時保持情緒穩定。在用藥方面,鈣通道拮抗劑是高血壓腎病患者的首選。多喝水、多補充維生素這些對于單純高血壓需要提倡的非藥物治療方法,對于高血壓腎病患者不強調,意圖減輕腎臟負擔。
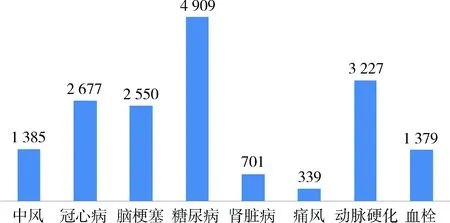
圖8 高血壓相關疾病頻數圖
5 結論
本文基于文本挖掘正規流程,基于在線醫療網站醫患互動論壇數據,使用TF-IDF算法和關聯規則算法,發現高血壓常用中西藥、非藥物治療、并發癥用藥特點、“癥-藥”
關系等知識,并與當前文獻交互驗證,發現待思考求證的問題,驗證了互聯網數據用于疾病研究的可用性和效果。
本文的不足之處及后繼工作是:受當前自然語言處理發展的影響,分詞處理還有提升空間;由于病理復雜,單一的“癥-藥”關聯規則分析可能無法應用于實際臨床中,需要進一步對“多癥狀-多藥”進行聯合挖掘。
隨著醫療管理的移動化和智能化,數據會更多更好,各種源頭的數據聯合使用,文本挖掘技術在醫療領域的應用會展現出蓬勃的生命力。
[1] 楊進,羅漫,張啟蕊.文本挖掘在中醫藥文獻分析中的應用[J].廣東藥學院學報,2010,26(2):216-220.
[2] 王麗穎,鄭光,郭洪濤,等.基于文本挖掘技術的高血壓病中成藥與西藥用藥規律分析[J].中華中醫藥雜志,2013,28(1):60-63.
[3] 賀丹,姜淼,鄭光,等.利用文本挖掘技術探索高血壓病癥狀、證候以及用藥規律[J].中國實驗方劑學雜志, 2014,20(19):214-216.
[4] CORLEY C D,COOK D J, MIKLER A R, et al. Text and structural data mining of influenza mentions in Web and social media[J]. International Journal of Environmental Research & Public Health, 2010, 7(2):596-615.
[5] NIKFARJAM A, SARKER A, O’CONNOR K, et al. Pharmacovigilance from social media: mining adverse drug reaction mentions using sequence labeling with word embedding cluster features[J]. Journal of the American Medical Informatics Association, 2015,22(3):671-681.
[6] SARKER A, O’CONNOR K,GINN R, et al. Social media mining for toxicovigilance: automatic monitoring of prescription medication abuse from twitter[J]. Drug Safety, 2016,39(3):231-240.
[7] YAN L, TAN Y. Feeling blue? go online: an empirical study of social support among patients[J]. Information Systems Research, 2014,25(4): 690-709.
[8] GESUALDO F,STILO G,AGRICOLA E,et al. Influenza-like illness surveillance on twitter through automated learning of naive language[J]. PLoS One, 2013, 8(12): 182.
Medication rules research on hypertension based on text mining
Li Yanhong1, Shen Ruiqi1,Ou Jingmin2
(1. School of Information Management and Engineering, Shanghai University of Finance and Economics,Shanghai 200433,China; 2. Department of General Surgery, Xinhua Hospital Affiliated to Medical Colledge of Shanghai Jiaotong University,Shanghai 200092,China)
The era of big data is coming which increasingly emphasizes the value of data mining technology. As a research branch of data mining, text mining is so important to the discovery of data-unstructured knowledge.Hypertension with the character of high incidence is one of the main diseases which damage human health. Many different kinds of drugs exist and the discovery of medication rules is one of the most important research directions. Based on text mining technology, this paper obtained data from doctor-patient interactive forum on online medical websites and preprocessed the text. Then, found common used Chinese and western medicine, non drug therapy,characteristics of drug use for complication and so on by using TF-IDF method, mined the relationship between symptoms and drugs with association rules algorithm. All the studies will be beneficial to the clinical judgment of hypertension and drug research. In addition, the paper verifies the availability and effectiveness of data from doctor-patient interactive forum used in the medical research.
hypertension; text mining; medication rule; TF-IDF(term frequency-inverse document frequency); association rule
國家自然科學基金資助項目(71401096,81572673)
TP399
A
10.19358/j.issn.1674- 7720.2017.03.030
李艷紅,沈瑞琪,歐敬民.基于文本挖掘技術的高血壓用藥規律研究[J].微型機與應用,2017,36(3):103-106.
2016-10-02)
李艷紅(1974-),女,博士,副教授,主要研究方向:文本挖掘、醫療大數據分析。
沈瑞琪(1993-),女,碩士研究生,主要研究方向:數據挖掘。
歐敬民(1972-),通信作者,男,博士,教授,主要研究方向:血管外科疾病的微創治療。E-mail:jingminou@163.com。
猜你喜歡
初中生學習指導·提升版(2023年8期)2023-09-12 10:26:19
保健醫苑(2022年1期)2022-08-30 08:39:40
西部醫學(2021年10期)2021-10-28 08:25:50
基層中醫藥(2020年10期)2020-02-13 15:45:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
基層中醫藥(2018年4期)2018-08-29 01:25:58
基層中醫藥(2018年6期)2018-08-29 01:20:14
獸醫導刊(2016年6期)2016-05-17 03:50:35
小學教學參考(2015年20期)2016-01-15 08:44:38
