區別性知識利用的遷移分類學習*
2017-03-16 07:22:52王士同杭文龍
計算機與生活 2017年3期
程 旸,王士同,杭文龍
江南大學 數字媒體學院,江蘇 無錫 214122
區別性知識利用的遷移分類學習*
程 旸+,王士同,杭文龍
江南大學 數字媒體學院,江蘇 無錫 214122
目前的遷移學習模型旨在利用事先準備好的源域數據為目標域學習提供輔助知識,即從源域抽象出與目標域共享的知識結構時,使用所有的源域數據。然而,由于人力資源的限制,收集真實場景下整體與目標域相關的源域數據并不現實。提出了一種泛化的經驗風險最小化選擇性知識利用模型,并給出了該模型的理論風險上界。所提模型能夠自動篩選出與目標域相關的源域數據子集,解決了源域只有部分知識可用的問題,進而避免了在真實場景下使用整個源域數據集帶來的負遷移效應。在模擬數據集和真實數據集上進行了仿真實驗,結果顯示所提算法較之傳統遷移學習算法性能更佳。
遷移學習;經驗風險最小化(ERM);泛化的經驗風險最小化(GERM);區別性知識利用;負遷移
1 引言
美國心理學家Anderson提出了自適應思維控制理論(adaptive control of thought,ACT)[1],把人類認知分為過程性認知和陳述性認知,并把認知過程分為兩個階段:首先是過程性認知上升為陳述性認知,然后陳述性認知在任務間遷移,并在新任務中產生新的過程性認知。由于過程性認知的不足,對于某些新任務,即使人們只學習到其某些特征,陳述性認知會選擇性地利用大腦中的舊任務知識對該新任務進行識別、學習并轉化為過程性認知的新任務。在陳述性認知過程中,大腦會根據新任務的某些特征檢索與其相關的舊任務,以便推理得到更多、更具體的認知[1]。如圖1所示的例子,若在過程性認知中已掌握了源域中的任務,當接觸到識別雞的新任務時,會根據雞的外形等特征迅速檢索到同屬鳥綱類的鳥類動物。同樣的情形也適用于貓科類動物的識別。
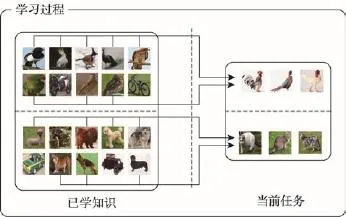
Fig.1 Two examples of using related knowledge on birds and dogs while learning target objects chicken and cats圖1 使用相關鳥類和狗類知識幫助目標域雞類和貓類對象學習示例
機器學習自從誕生起,一直在模仿人類的認知學習過程。毫無疑問,認知心理學的發展促進了機器學習的發展。然而,區別性知識利用是人類所特有的,傳統的機器學習并無此認知能力,即傳統的機器學習算法在輔助學習時沒有考慮如何檢索僅與當前任務相關的經驗知識。目前,模仿人類的學習方式,利用先前知識輔助當前任務學習的遷移學習[2-3]吸引了越來越多人的關注,但絕大多數遷移學習算法都是在事先準備好的源域數據上獲得較高的識別度。考慮到人工成本的攀升,在現實場景中篩選出同一分布的源域數據并不現實。并且由于常規遷移學習模型并沒有考慮如何從源域中抽選出與目標域相關的源域子集,使得在常規場景下的遷移學習知識利用并不可靠,極有可能出現負遷移的情況。本文給出一種泛化的經驗風險最小化模型,在此基礎上提出了區別性遷移學習框架,并給出了風險上界。與當前遷移學習算法相比,本文所提算法具有以下特性:
(1)提出了一種基于泛化的經驗風險最小化區別性知識利用遷移學習模型,更有效地利用了源域知識,其中心思想是利用與目標域相關的源域子集數據輔助目標域學習。
(2)提出了一種源域相關數據選擇算法,通過保持源域與目標域數據分布一致的原則,篩選出部分相關數據,進而避免了負遷移。
2 相關工作
美國國防部DARPA機器人大賽文檔系列在2005年給出了遷移學習的基本定義:利用事先學習的知識和技能來識別新任務的學習能力。根據此定義,遷移學習旨在抽取有用的歷史知識,并用此類知識來幫助新任務的學習。根據所抽取的知識,遷移學習方法所使用的技術大概可分為三大類:
(1)實例遷移方法。實例遷移的主要思想是假設源域中有部分數據可以直接用來輔助目標域的學習[3-4],通過諸如聚類等方法,挑選出一些最具代表性的源域數據用于幫助目標域建模。其中,比較著名的是Liao等人在文獻[4]中展示了一種利用自主學習推斷出目標域數據標簽的方法;Dai等人提出了基于Adaptive Boosting(AdaBoost)[5]算法的遷移學習算法;Wu等人在文獻[6]中提出了一種基于支持向量機的框架,通過整合源域數據提高分類精度。
(2)特征遷移方法。特征遷移學習方法旨在獲得一個理想的特征表示,并通過將該特征表示嵌入到某個知識共享框架中來降低源域和目標域的差異,以此提高目標域的學習效果[7-8]。典型的有Bart和Ullman[8]提出用新類別中的單個實例特征來自適應目標域的特征,以達到提高精度的效果。
(3)參數模型遷移方法。大部分基于參數模型遷移的方法都基于一個假設,即源域和目標域共享某些參數或者先驗分布[9-11]。Tommasi等人在文獻[9]中提出了一種基于最小二乘支持向量機的有區別的遷移學習策略,通過留一法自適應源域和目標域的學習程度。Li等人在文獻[10]中提出了一種基于貝葉斯先驗模型的參數遷移方法,使用源域獲得的參數模型知識輔助目標域的學習。
從以上分析可以看出,目前大多數遷移學習建模方法旨在一系列事先準備好的源域數據集上取得最優的知識遷移效果。但實際情況下,篩選出來自同一領域的數據涉及大量的人力物力,已不現實。在這種情況下,如何高效地選出僅和目標域相關的源域數據來輔助目標域學習是關系遷移學習成敗的關鍵。目前,這方面的相關工作較少,較著名的有ASVM(adaptive support vector machine)[12]和CD-SVM(cross-domain support vector machine)[13]。在文獻[12]中,提出了自適應支持向量機A-SVM,即在SVM(support vector machine)的目標函數中引入一個新的規則化項,旨在同時最小化源域數據和目標域有標簽數據的分類誤差以及目標和原始分類器之間差異。但是由于其樣本選擇策略是基于最小化期望誤差,這需要在上一次迭代更新得到的樣本集上重新訓練并更新,這種策略某種程度上會導致A-SVM效率較低且精度受限。文獻[13]中提出了一種基于源域支撐向量的方法,其旨在約束目標域數據與源域數據支撐向量保持流型一致,即目標域數據落在源域支撐向量近鄰范圍內的應當保持標簽一致。CDSVM的缺點在于其在選擇源域支撐向量時,沒有充分考慮領域間的差異性。其選擇的源域支撐向量對源域數據具有較低的實際風險,卻不能夠較好地自適應目標域數據學習,極端情況下,甚至會降低目標域的學習效率和精度。
不同于A-SVM和CD-SVM的樣本選擇策略,本文提出了一種新的方法,通過一般化的經驗風險最小化驗證了僅僅和目標域相關的源域數據才能保證知識遷移的風險上界,并提出了一種選擇方法,用于篩選出源域與目標域分布一致的數據。
3 基于一般化經驗風險最小化模型的區別性知識利用遷移學習方法框架
3.1 經驗風險最小化
在傳統的半監督學習框架中,經驗風險最小化(empirical risk minization,ERM)準則被成功地應用于解決許多機器學習和數據挖掘問題[14]。給定一個數據集H服從分布p(z),從中隨機選取n個獨立同分布的數據。若使用Rademacher復雜度指標測量目標函數的復雜性,真實風險和經驗風險之間滿足如下不等式:

3.2 一般化經驗風險最小化
ERM準則的主要問題在于其要求H中的數據獨立同分布且符合同一分布p(z),也就是說測試數據必須與訓練數據分布一致,這極大限制了在真實環境中的應用。在遷移學習中,如何選出與目標域分布最接近的源域數據,即去除干擾數據是保證正遷移的首要條件。
在遷移學習中,源域數據分布q(z)通常與目標域不同,即p(z)≠q(z)。則一般化的經驗風險最小化(generalized empirical risk minimization,GERM)準則上界可以表示為:

在遷移學習中,若源域和目標域數據分布不一致,但有著相同的條件分布[2],即p(x,y)=p(x)p(y|x),q(x,y)=q(x)p(y|x),可以得到:
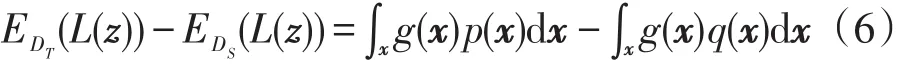
式(6)中,g(x)=∫yL(f(x),y)p(y|x)dy。函數g有界并且可測,可以得到一個實際的有界且連續的函數。最終,通過函數和不等式的性質,可以得到:

這里是關于變量x且屬于有界連續函數類?(x)。
3.3 基于一般化經驗風險最小化模型的區別性知識利用遷移學習方法
由于真實場景下收集的歷史數據不可能完全和目標域相關,僅篩選出部分相關的數據來輔助目標域的學習是關系知識遷移成功的關鍵。因此如何篩選出這些數據,最小化源域和目標域之間的分布差異是保證正遷移的關鍵。首先定義區別性最大均值差異(discriminativemaximum meandiscrepancy,DMMD)。
定義1(區別性最大均值差異)用NS個變量ρ=表示源域的每一個數據指示器。ρi=1表示該數據可以被用來輔助目標域學習,則DMMD可以定義如下:
定理1考慮一組確定的變量ρ={ρi},指示相關的源域數據,則僅對于相關的源域數據和目標域數據而言,式(8)等價于最大均值差異(maximum mean discrepancy,MMD)[16]。
證明假設表示源域中與目標域相關的數據的個數,則這些相關源域數據構成的子集和目標域DT之間的MMD可以表示為:

用Kij=K(xi,xj)=?(xi)T?(xj)表示核矩陣,可以把DMMD拓展到再生核希爾伯特空間(reproducing kernel Hilbert space,RKHS)。則基于GERM的遷移學習的風險上界可以用下面的定理描述,即式(12)同樣至少以概率1-δ成立。由于在絕大多數實際情況中,源域數據較充足,本文僅僅考慮源域數據量大于目標域數據的情況。 □定理2令zi=(xi,yi),這里xi∈?d并且yi∈{- 1,+1}。假設核函數有上界C,即0≤Kij≤C,?xi,xj。在遷移學習的框架內,如下的GERM不等式至少以概率1-δ成立。

這里DMMD和函數復雜度項表示如下:

這里,τ為一個常量;為相關的源域數據子集。
證明文獻[17]給出了真實MMD和經驗MMD間的關系,由定理1可知,真實DMMD和經驗DMMD之間同樣滿足:


3.4 區別性源域樣本選擇
本文用NS個指示器表示源域中的每個數據點。如果ρi=1,對應的源域數據點被認為是可以安全使用的。通過最小化如下DMMD可以得到ρ:


這里1為|DN|維單位向量。上述最優化問題是一個凸二次規劃問題,有全局最有解。得到的不為0的α所對應的源域數據即為源域和目標域相關的源域數據子集。
3.5 問題求解
根據上一節源域相關數據求解,可以得到和目標域分布最接近的數據,此部分數據可以被用來進行知識遷移。此節,結合最小二次支持向量機和源域相關數據,提出區別性知識利用的遷移學習目標表達式:

在核理論的基礎上,通過表示定理,可以得到最終的決策函數如下:
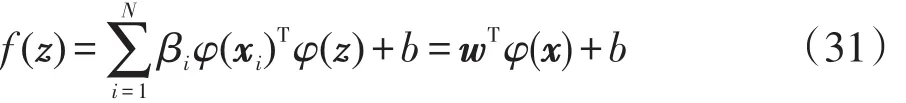
算法的時間復雜度分析如下:式(29)和式(31)的時間復雜度均為n3,因此總的時間復雜度為2n3。此外本文算法僅僅選出與目標域相關的源域數據,因此其在目標域的決策函數中可能會包含更少的支持向量。實驗表明本文算法的實際時間對比傳統的遷移學習算法具有明顯優勢。
4 實驗與分析
此部分,在人造數據集和真實圖像、文本數據集上驗證所提算法的有效性。
在人造數據集部分,使用雙月數據集,其中目標域由300個數據樣本構成(正、負類各150個)。源域數據集構造如下:將目標域數據集逆時針旋轉10°、20°、30°和40°,并對每個數據點增加均值為0,方差為2的高斯噪聲。由于旋轉和噪聲,目標域數據已和源域數據產生了分布差異,且一些隨機噪聲導致了源域部分數據無法用來輔助目標域學習。表1給出了人工數據集更詳細的說明。

Table 1 Synthetic dataset表1 人造數據集
在真實數據集部分,使用了圖像公共數據集Caltech-256[18]。Caltech-256包含了30 607張圖片,共有256類。使用其中的車輛數據集,包含5個子類:fire-truck、school-bus、car-side、moto-bike和snow-mobile。本文使用了PHOG(pyramid histogram of oriented gradients)特征描述方法對圖片進行特征提取,并構造moto-bike和snow-mobile為負類,其他均為正類。表2給出了數據集設置的更多細節。
在文本數據集方面,使用了公共垃圾郵件數據集email spam filtering[19],包括一個公共郵件集(Public)和3個用戶郵件集(User1、User2和User3)。其中,每個用戶郵件集有2 500份郵件,公共郵件集有4 000份郵件。每一份郵件都是一個字符集合,共有206 908維。按文獻[20]中所提方法對所有郵件進行降維。具體關于源域和目標域的設置如表3。
本文采用如下對比算法:
(1)最小二乘SVM(LS-SVM)。
(2)歸納式最小二乘SVM(ILS-SVM)。
(3)自適應SVM(A-SVM)[12]。
(4)交叉SVM(CD-SVM)[13]。

Table 2 Image dataset表2 圖像數據集
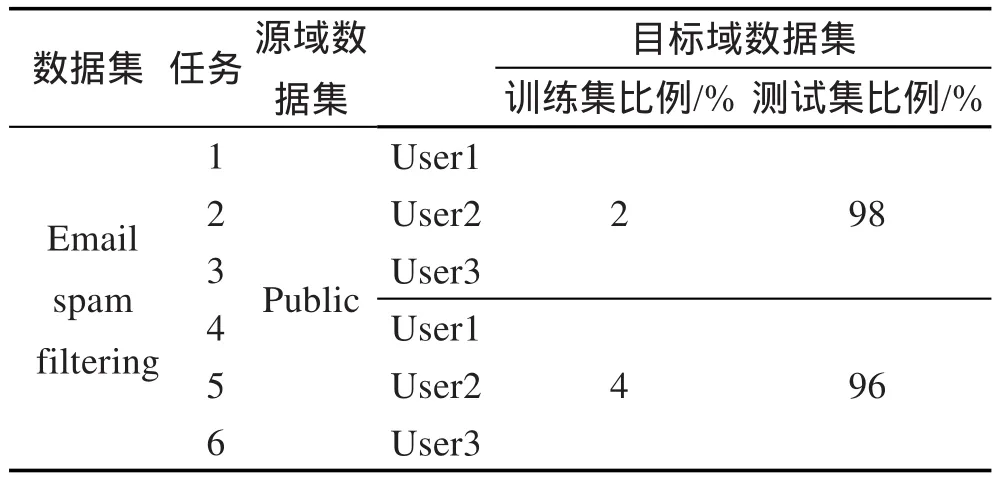
Table 3 Text dataset表3 文本數據集

Table 4 Classification accuracy obtained by different inductive transfer learning algorithms on synthetic dataset表4 不同的歸納式遷移學習算法在人造數據集上的分類精度對比
(5)本文算法DLS-SVM。
從目標域中隨機抽出一些數據點,用作目標域的標注數據。所有實驗均運行10次,給出均值和方差。表4給出了在人造數據集上5種方法的運行效果。由表4中可以看出,DLS-SVM明顯優于直接利用源域數據集的對比算法,進一步說明了所提算法的有效性。接下來將進一步對比所提算法與傳統算法在真實圖像和文本數據集上的效果。圖2給出了各個對比算法在圖像數據集上的對比效果,表5和表6給出了在文本數據集上的分類效果。隨著已標注目標域數據的增加,各個分類算法的效果趨于平穩。可以看出,相對于其他對比算法,所提算法具有明顯的優勢。另外,還能得到如下觀察結論:
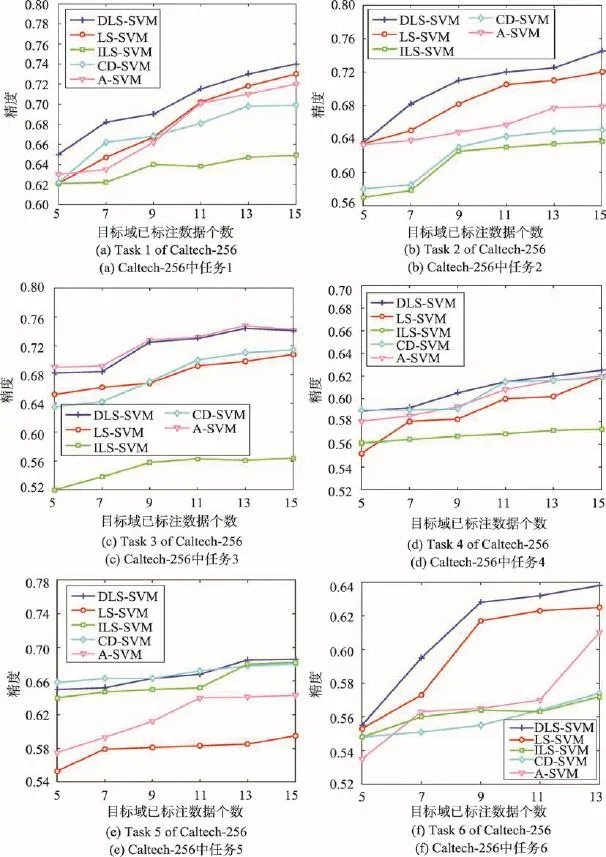
Fig.2 Classification accuracy obtained by 5 algorithms on image dataset圖2 5種對比算法在圖片數據集上的分類精度
(1)根據數據集Caltech-256[18]中源域和目標域數據集的產生方式以及表2中的設置,并非所有的源域圖片都適合用于知識遷移。因此,本文算法理論上比其他歸納式遷移學習算法更適用于此類真實場景。從圖2(a)~(f)可以看出,DLS-SVM算法可以有效地檢索出和目標域相關的源域數據子集來提高目標域的分類效果。
(2)在人造數據集上對本文實驗的中間過程做了進一步的觀察,得到如下結論:表4中,對源域1、源域2、源域3和源域4進行分布一致性求解時,分別得到了152、128、89和52個源域數據子集,進一步驗證了本文所提分布一致性策略的有效性。僅僅參考部分相關源域數據子集,對目標域數據的學習,無論在精度還是時間上都將得到提升。
(3)從表4和圖2可以看出,本文算法在人造數據集和圖片數據集中的大多數情況下都取得了顯著的結果。由于CD-SVM和ILS-SVM算法最主要的局限性在于它們雖然考慮了所有源域數據,但是并沒有考慮與目標域不相關的數據對目標分類器造成的干擾,因此這些算法所生成的目標模型并不完善。對于A-SVM而言,在部分情況下取得了較好的結果,如圖2(c),但是其樣本選擇策略是基于最小化期望誤差,這需要在上一次迭代更新得到的樣本集上重新訓練并更新,這種策略導致了大部分情況下ASVM的精度受到影響。
(4)表5和表6展示了各種對比算法在文本數據集上的分類對比效果。隨機抽取了目標域2%和4%的數據作為目標域有標注數據。與傳統歸納式遷移學習算法對比可以發現,本文算法在目標域已標注數據匱乏的情況下明顯優于傳統方法。隨著目標域已標注數據的增多,傳統半監督方法LS-SVM同樣得到了很好的分類效果,這與實際相吻合。
(5)圖3顯示的是5種對比算法在圖片數據集中的平均總運行時間,即訓練時間與測試時間之和。從圖3中可以看出,LS-SVM算法的運行時間相對于其他算法較短,這是因為其訓練樣本較少。相對于ILS-SVM、A-SVM和CD-SVM,本文算法的運行時間具有明顯優勢。由于A-SVM需要不斷迭代選擇與目標域數據分布一致的源域數據子集,且在迭代過程中得到目標域分類精度,花費較多時間在迭代計算過程且不能保證收斂于全局最優值。對于CD-SVM而言,其增加流型約束項增加了核函數計算成本,導致目標域分類器的學習效率降低。且流型約束項中的近鄰個數的選擇對目標域分類器的學習影響較大。也就是說,盡管DLS-SVM需要使用額外的時間計算源域的相關數據,但是僅有部分源域相關數據被用于知識的遷移,因此通常決策函數包含了較少的支撐向量,從而使得本文算法具有更短的測試時間,總運行時間具有優勢,如圖3所示。

Table 5 Classification accuracy obtained by different inductive transfer learning algorithms on email dataset with 2%training samples and 98%testing samples表5 不同的歸納式遷移學習算法在已標注2%的垃圾郵件數據集上的分類精度對比

Table 6 Classification accuracy obtained by different inductive transfer learning algorithms on email dataset with 4%training samples and 96%testing samples表6 不同的歸納式遷移學習算法在已標注4%的垃圾郵件數據集上的分類精度對比

Fig.3 Total running time obtained by 5 algorithms on image dataset圖3 5種對比算法在圖片數據集上的總運行時間對比
(6)綜合在圖片數據集和文本數據集上的實驗結果可以發現,本文算法明顯優于傳統的歸納式遷移學習算法,即本文算法是一種有效的數據選擇、合理利用歷史數據的方法。這表明應該篩選出僅和目標域相關的源域數據子集并加以利用,可以更好地避免負遷移。
5 結束語
本文針對現實情況中源域存在干擾樣本導致傳統數據分析任務失效的問題,拓展了經典的ERM,使其適用于遷移學習機制,利用部分相關源域知識輔助目標域學習,提出了一種新的基于泛化的經驗風險最小化區別性知識利用遷移學習算法。本文算法是一種基于數據分布一致性的知識遷移聚類算法,其只利用了源域數據的部分相關數據子集,得到了更具指導意義的有效知識,進而確保了利用的源域知識不會對源域造成負遷移。最后,結合最小二乘支持向量機,進一步提出了DLS-SVM算法。在人工數據集和真實數據集上的實驗結果反映了DLSSVM算法對于領域間知識遷移學習的有效性。
[1]Anderson J R.Cognitive psychology and its applications [M].7th ed.New York:Freeman,2010.
[2]Mao Fagui,Li Biwen,Shen Beijun.Cross-project software defect prediction based on instance transfer[J].Journal of Frontiers of Computer Science and Technology,2016,10 (1):43-55.
[3]Hang Wenlong,Jiang Yizhang,Qian Pengjiang,et al.Transfer affinity propagation clustering algorithm[J/OL].Journal of Software(2015-11-26)[2015-12-05].doi:10.13328/j. cnki.jos.004921.
[4]Liao Xuejun,Xue Ya,Carin L.Logistic regression with an auxiliary data source[C]//Proceedings of the 22nd International Conference on Machine Learning,Bonn,Germany, Aug 7-11,2005.New York:ACM,2005:505-512.
[5]Dai Wenyuan,Xue Guirong,Yang Qiang,et al.Transferring naive Bayes classifiers for text classification[C]//Proceedings of the 22nd National Conference on Artificial Intelligence, Vancouver,Canada,Jul 22-26,2007.Menlo Park,USA: AAAI Press,2007:540-545.
[6]Wu Pengcheng,Dietterich T G.Improving SVM accuracy by training on auxiliary data sources[C]//Proceedings of the 21st International Conference on Machine Learning,Banff, Canada,2004.New York:ACM,2004:110.
[7]Daume III H,Marcu D.Domain adaptation for statistical classifiers[J].Journal of Artificial Intelligence Research, 2006,26(1):101-126.
[8]Bart E,Ullman S.Cross-generalization:learning novel classes from a single example by feature replacement[C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,San Diego,USA, Jun 20-25,2005.Washington:IEEE Computer Society,2005: 672-679.
[9]Tommasi T,Orabona F,Caputo B.Learning categories from few examples with multi model knowledge transfer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(5):928-941.
[10]Li Feifei,Fergus R,Perona P.One-shot learning of object categories[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28(4):594-611.
[11]Yang Changjiang,Deng Zhaohong,Jiang Yizhang,et al. Adaptive recognition of epileptic EEG signals based on transfer learning[J].Journal of Frontiers of Computer Science and Technology,2014,8(3):329-337.
[12]Jun Yang,Rong Yan,Hauptmann A G.Adapting SVM classifiers to data with shifted distributions[C]//Proceedings of the 7th IEEE International Conference on Data Mining Workshops,Omaha,USA,Oct 28-31,2007.Washington: IEEE Computer Society,2007:69-76.
[13]Jiang Wei,Zavesky E,Chang S F,et al.Cross-domain learning methods for high-level visual concept classification[C]// Proceedings of the 15th IEEE International Conference on Image Processing,San Diego,USA.Oct 12-15,2008.Piscataway,USA:IEEE,2008:161-164.
[14]Burges C J C.A tutorial on support vector machines for pattern recognition[J].Data Mining and Knowledge Discovery, 1998,2(2):121-167.
[15]Dudley R M.Real analysis and probability[M].Cambridge, UK:Cambridge University Press,2002.
[16]Borgwardt K M,Gretton A,Rasch M J,et al.Integrating structured biological data by kernel maximum mean discrepancy[J].Bioinformatics,2006,22(14):e49-e57.
[17]Gretton A,Borgwardt K M,Rasch M J,et al.A kernel twosample test[J].The Journal of Machine Learning Research, 2012,13(1):723-773.
[18]Gehler P,Nowozin S.On feature combination for multiclass object classification[C]//Proceedings of the 2009 IEEE 12th International Conference on Computer Vision,Kyoto, Sep 29-Oct 2,2009.Piscataway,USA:IEEE,2009:221-228.
[19]Bickel S.ECML-PKDD discovery challenge 2006 overview [C]//ECML-PKDD Discovery Challenge Workshop,Antwerp,Belgium.Piscataway,USA:IEEE,2006:1-9.
[20]Deng Zhaohong,Choi K S,Jiang Yizhang,et al.Generalized hidden-mapping ridge regression,knowledge-leveraged inductive transfer learning for neural networks,fuzzy systems and kernel methods[J].IEEE Transactions on Cybernetics, 2014,44(12):2585-2599.
附中文參考文獻:
[2]毛發貴,李碧雯,沈備軍.基于實例遷移的跨項目軟件缺陷預測[J].計算機科學與探索,2016,10(1):43-55.
[3]杭文龍,蔣亦樟,劉解放,等.遷移近鄰傳播聚類算法[J/OL].軟件學報(2015-11-26)[2015-12-05].doi:10.13328/j. cnki.jos.004921.
[11]楊昌健,鄧趙紅,蔣亦樟,等.基于遷移學習的癲癇EEG信號自適應識別[J].計算機科學與探索,2014,8(3):329-337.

CHENG Yang was born in 1991.He is an M.S.candidate at Jiangnan University,and the student member of CCF. His research interests include artificial intelligence and pattern recognition,etc.
程旸(1991—),男,江蘇蘇州人,江南大學碩士研究生,CCF學生會員,主要研究領域為人工智能,模式識別等。

WANG Shitong was born in 1964.He received the M.S.degree in computer science from Nanjing University of Aeronautics and Astronautics in 1987.Now he is a professor and Ph.D.supervisor at School of Digital Media,Jiangnan University.His research interests include artificial intelligence,pattern recognition and image processing,etc.
王士同(1964—),男,江蘇揚州人,1987年于南京航空航天大學獲得碩士學位,現為江南大學數字媒體學院教授、博士生導師,主要研究領域為人工智能,模式識別,圖像處理等。在國內外重要核心期刊上發表論文近百篇,其中SCI、EI收錄50余篇,主持或參加過6項國家自然科學基金項目,1項國家教委優秀青年教師基金項目,其他省部級科研項目10多項,先后獲國家教委、中船總公司和江蘇省省部級科技進步獎5項。

HANG Wenlong was born in 1988.He is a Ph.D.candidate at Jiangnan University,and the student member of CCF.His research interests include artificial intelligence and pattern recognition,etc.
杭文龍(1988—),男,江蘇南通人,江南大學博士研究生,CCF學生會員,主要研究領域為人工智能,模式識別等。
Discriminative Knowledge-Leverage-Based Transfer Classification Learning*
CHENG Yang+,WANG Shitong,HANG Wenlong
School of Digital Media,Jiangnan University,Wuxi,Jiangsu 214122,China
+Corresponding author:E-mail:szhchengyang@163.com
Current transfer learning model studies the source data for future target inferences within a major view that the whole source data should be used to explore the shared knowledge structure.However,due to the limited availability of human ranked source domain,this assumption may not hold due to the fact that not all prior knowledge in the source domain is correlative to the target domain in most real-world applications.This paper proposes a general framework referred to discriminative knowledge-leverage(KL)based on generalized empirical risk minimization(GERM) transfer learning,where the empirical risk minimization(ERM)principle is generalized to the transfer learning setting. Additionally,this paper theoretically shows the upper bound of generalized ERM(GERM)for the practical discriminative transfer learning.The proposed method can alleviate negative transfer by automatically discovering useful objects from source domain.Extensive experiments verify that the proposed method can significantly outperform the state-ofthe-art transfer learning methods on several artificial/public datasets.
transfer learning;empirical risk minimization(ERM);generalized empirical risk minimization(GERM); discriminative knowledge-leverage;negative transfer
10.3778/j.issn.1673-9418.1512014
A
:TP181
*The National Natural Science Foundation of China under Grant No.61272210(國家自然科學基金).
Received 2015-12,Accepted 2016-04.
CNKI網絡優先出版:2016-04-08,http://www.cnki.net/kcms/detail/11.5602.TP.20160408.1642.002.html
CHENG Yang,WANG Shitong,HANG Wenlong.Discriminative knowledge-leverage-based transfer classification learning.Journal of Frontiers of Computer Science and Technology,2017,11(3):427-437.
