醫療衛生行業互聯網輿情監測預警系統設計及實現
2017-03-21 10:49:50,,,,,
中華醫學圖書情報雜志 2017年3期
,,,,,
醫療衛生行業是關乎家庭幸福的重大民生工程,醫療問題是網民最為關注的熱點之一。在我國醫療衛生改革與發展的過程中,體制性矛盾、醫療糾紛和突發公共衛生事件都會引發大小不一、影響各異的輿情事件;同時,互聯網技術的蓬勃發展以及網民數量劇增所致的信息快速、廣泛傳播,進一步加劇了醫療衛生事件在全國范圍內的影響力和爆發力,使醫療衛生互聯網輿情總體呈現觸點多、燃點低、熱度高的特點,更加多發易發[1]。尤其是一些負面輿情的持續發酵,激化了醫患矛盾,引發了醫藥衛生行業的形象危機,進而屢陷輿論漩渦[2-3]。
在全國醫療衛生行業互聯網輿情井噴、相關部門對互聯網輿情管控難度劇增的態勢下,除了需要在制度、管理等方面逐步完善以外,也需要充分利用現有的信息技術,及時地發現和處理這些輿情事件。做好互聯網輿情信息的監測,及時、科學應對,已成為相關醫療機構和政府部門的工作重點[4-5]。基于此我們設計并開發了醫療衛生行業的互聯網輿情監測預警信息系統,結合具有衛生行業背景的專業輿情分析師的人工處理分析和研判,開展行業輿情監測分析工作,為行政管理機構及醫療計生單位對互聯網輿情的全面掌控和有效應對提供專業可信的依據。系統的架構和功能實現介紹如下。
1 系統需求
本項目開發的醫療衛生網絡輿情監測系統主要實現互聯網信息獲取、互聯網信息處理、輿情分析、輔助決策支持4個方面功能。其中互聯網輿情信息獲取的快與準、內容分析的確定性、輿情研判的準確性、輿情響應的及時性、信息跟蹤的及時性等目標的實現,是本系統開發技術的關鍵點和輿情分析研究的主要著力點[6]。
1.1 網絡信息獲取
互聯網輿情的來源十分復雜,包括新聞網站、論壇、博客等,主要表現形式為動態網頁,具有主題發散、形式多樣、時效性強等特點。互聯網信息獲取的目的就是要采集和提取這些動態網頁中的非結構化信息。
1.2 網絡信息處理
新聞、論壇帖子、博文等頁面包含有效信息,同時也包含垃圾信息,因此在輿情分析前必須去偽存真。網絡信息的處理目的是對頁面內容進行過濾,并提煉成概要信息,便于查詢和檢索。再經過人工的二次審核,確保保留信息的準確性,以提升輿情分析的準確性和科學性。
1.3 輿情監測分析及預警
網民討論的話題極為發散,如何從海量信息中找到熱點、敏感話題,并對其趨勢變化進行追蹤,成為公共衛生網絡輿情監測系統的重點。系統需要從實時采集到的數據中篩選出重要的敏感信息,及時推送給有關部門以達到預警的目的。對于持續追蹤的輿情,系統可自動生成相應圖表,并進行人工分析,最終形成準確、專業、全面的輿情分析報告。
1.4 輔助決策支持
醫療衛生互聯網輿情監測系統需為相關部門的決策服務,因此需要將各種輿情分析結果接入個人工作平臺,服務于實際工作。
2 系統架構
系統架構遵循先進性、可靠性、安全性、標準化、成熟性、適用性、可擴展性原則,按層次架構進行設計,每層之間通過松散藕合的方式相互通信,從下而上分別由采集模塊、過濾模塊、分析模塊、應用系統組成(圖1)。
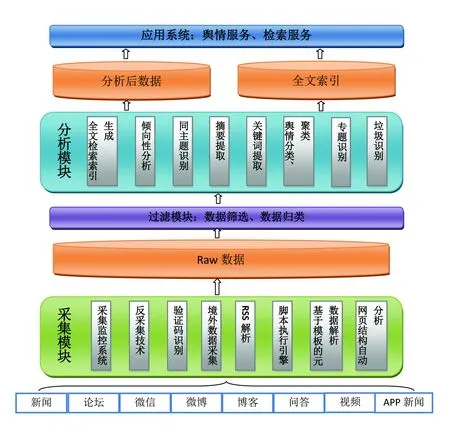
圖1 醫療衛生網絡輿情監測系統架構
2.1 信息采集模塊
網絡輿情散布于網絡的各個部分,如新聞、論壇、微信、微博、博客等。這些信息實時更新,動態變化。信息獲取的目標是對相關信息進行采集,對已有數據進行周期性的更新以獲取其最新的轉發和評論狀態。采集的信息源以及采集頻率都可以根據用戶需要,進行定制化配置,靈活性強。用戶還可自定義特定主題或事件,如“莆田系”,從而對特定主題或事件進行專題監測和追蹤,并由系統生成專題報道。由于不同數據源的格式千差萬別,在獲取信息前要對每個站點進行采集配置,以確保能夠及時準確從網頁中采集標題、內容、作者、發文時間等內容,并格式化存儲以方便之后的量化統計分析。
2.2 信息過濾模塊
由于互聯網數據質量參差不齊,各種垃圾信息(如廣告)充斥其中,智能的垃圾文識別算法可有效過濾廣告等無用信息。然后,可根據每個角色自身業務需求,進一步將這些數據分門別類,最終實現根據不同的需求呈現不同的數據。
2.3 信息分析模塊
信息分析模塊能實現輿情信息自動提取摘要,自動識別與主題相關的內容并自動聚類,對信息內容進行正負面情感傾向性分析。除了及時篩選出重要的輿情信息之外,還要能識別出熱點話題,并根據該話題事件輿情信息的各個維度,包括人群分布、媒體分布、時間趨勢、地域分布、觀點分類等的統計及對數據的有效組織、分類,從多方面分析輿情信息的具體分布情況,從而分析事件的整體發展趨勢和現狀,以及網民對事件的觀點傾向。
3 模塊功能實現
系統采用跨平臺的JAVA技術,使采集系統可以在各種操作系統上運行。同時,為了解決數據量大引發的擴展性問題,底層數據的存儲和分發采用hadoop的相關技術實現,機器學習相關的算法采用weka實現。
3.1 信息采集模塊
采集器構架(圖1)不但可以采集普通采集器所能實現的簡單的網頁采集,還可以執行網頁上的動態腳本(如javascript,ajax等),以得到普通采集方式通過抓取靜態頁面無法獲取的信息。
3.1.1 動態網頁的采集
越來越多的網站采用了動態頁面技術(即javascript、ajax等),典型的如博客、微博等網站,通過普通的靜態頁面只能采集到部分信息,甚至采集不到真正的頁面內容。本系統的采集器內采用了頁面動態構建技術,可以使采集到的頁面執行頁面動態腳本得到與普通瀏覽器完全一致的頁面內容。
3.1.2 采集范圍廣泛
目前采集器的采集目標包括微信公眾號、新聞、論壇、博客、微博、RSS等各種類型的站點。除了采集系統所設的目標網站外,還能獲取各大搜索引擎的內容,以獲取采集目標站點外的信息作為重要補充。由于系統包含各目標站點類型的配置信息,除了普通網絡采集器能夠采集到的網頁標題、網頁更新時間、網頁內容外,最大特點是可以根據此配置信息自動解析出普通網頁中輿情處理的結構化信息,如標題、內容、發表時間、閱讀數、回復量、最新回復時間等。系統有定時的網站格式分析及監測,在網站結構改變時,能夠及時調整系統針對站點的配置設定以及時獲取正確的信息。采集系統除了采用常規的關鍵詞采集外,還能夠對指定的站點實現全采集,即地毯式搜索,不遺漏任何輿情信息。另外,系統也能夠采集某些需要登錄才能看到內容的網站,如某些論壇和微博站點,并且能夠采取各種措施有效繞過網站的反爬蟲技術實現輿情采集。
3.2 信息過濾模塊
信息過濾模塊主要包括文章去重,垃圾文過濾和輿情預警3個部分。
3.2.1 文章去重
互聯網中存在大量的重復頁面,統計表明系統所采集的數據中有超過50%的重復。檢測重復頁面對于減少重復工作量,提高數據質量至關重要。同時,由于每天采集的文章量巨大,要實時計算每篇文章是否是近似重復文章對算法的計算速度具有很高的要求。因此系統采用了TF-IDF,I-match[7-8],Shingling[9-10]和Jaccard Index相結合的方式計算,對每篇文檔進行分詞,找出所有的停用詞,停用詞后面的連續兩個非停用詞詞串作為代表這篇文檔的詞串;計算所有這些詞串的IDF,去掉IDF太大和太小的詞串;利用I-match算法[7-8]計算和已經有的文檔是否相似,如果相似則該篇文檔的計算結束,如果不相似則對每篇文檔計算其選取詞串的TFIDF,然后根據LSH計算是否和已經有的文檔相似;對每篇文檔利用Shingling方法[9-10]計算其是否和已有文檔相似;對于任何可能相似的情況進一步計算所有詞串的Jaccard Index來過濾掉假陽性。
3.2.2 垃圾文過濾
網絡所采集的大量文章中,很多都和醫療衛生不相關。本系統采用weka文本分類技術對每篇采集的文本進行分類,可以將和醫療相關的文章篩選出來,過濾掉垃圾文。這一步篩選至關重要,其準確性直接影響到后續數據分析中統計的正確性。
3.2.3 輿情預警
系統通過關鍵詞匹配的方式從醫療衛生相關的信息中過濾出敏感的輿情事件。為此,我們收集整理了和醫療衛生相關的負面詞庫,其中包括諸如“醫鬧”“醫患”“單獨兩孩”等詞。然后在系統過濾的基礎上,通過人工研判識別的方式篩選出重要信息,并根據信息的重要性和緊急程度,分成一般、重要、緊急3個級別,通過WEB端、PC端和手機客戶端等方式推送預警,以確保用戶能隨時隨地及時掌握最新重要輿情。
3.3 信息分析模塊
圍繞過濾之后的數據,系統會進行多方位的分析。其中分析技術包括熱點識別、熱詞發現、傾向性分析、地域識別、趨勢分析和媒體分析等。基于這些分析結果,系統可通過圖形化的方式展示,具有較好的可視化效果。
3.3.1 熱點事件
系統根據新聞熱點、關鍵詞、專題等信息進行熱度分析,考慮了信息來源、所處網頁位置、轉載、點擊、評論、回復和報道率等關鍵因素,對這些因素進行綜合排名,并支持以半小時為間隔的任意時間段進行統計分析,同時提供1天、3天、7天等時間序列的符合用戶精確度要求的分類熱點排行。此外,系統還可以對熱點信息進行持續追蹤,并通過趨勢分析圖和傳播鏈分析圖等技術幫助用戶了解熱點事件的報道趨勢以及來龍去脈,幫助用戶更好地對輿情進行研判。
3.3.2 熱詞發現
系統在不斷更新的信息中尋找一定時期熱度較高的短語,如人名、地名、機構名和其他常見短語。很多網絡熱詞是詞典中未收錄的新詞語,因此計算熱詞的時候,系統主要考慮兩個方面,一是出現的頻率信息越多,熱度越高;二是歷史波動信息曲線越陡,熱度越高。
3.3.3 傾向性分析
情感傾向性分析具有極強的行業領域依賴性[11]。本系統通過建立面向衛生行業領域的情感詞典,對輿情進行觀點傾向性分析,自動分析文章的傾向性為正面、負面還是中性,從而為輿情處理提供重要的分析依據。在實現上,本系統同樣采用weka技術實現文本的傾向性分類。
3.3.4 地域識別
系統采用了實體名識別技術,對其中的地域名詞進行識別,并且將每一個地域名詞歸類到全國的地域層級上,從而實現全國范圍內的地域識別。
4 結論
我們設計開發的輿情監測系統可實現7×24小時不間斷采集互聯網信息,通過系統智能過濾、強大的分析功能配合人工精細化服務的研判分析,及時有效地從互聯網上篩選出醫療衛生行業相關的輿情事件并進行預警、專題追蹤和趨勢分析,同時通過Web端、PC輿情助手和手機客戶端,確保用戶隨時隨地都能準確有效地掌握最新輿情動態并做出有效應對。和其他輿情分析系統相比,本系統采集的數據源更廣,數據分類更智能,數據分析更完備,結合人工分析服務,使輿情研判和預警更加精準。但實際運行過程中尚存在一些需要完善的地方,主要包括以下3個方面。
一是輿情事件的分析。一件輿情事件可能涉及到幾百至上百萬的文章,如何將每篇文章自動準確地歸類于某一事件尚需進一步探索。雖然通過關鍵詞等方式可以解決大部分問題,但是有很多長尾文章不能簡單地通過關鍵詞的方式過濾。
二是傾向性分析。由于自然語言處理的復雜性,對于一個事件的正負面評價以及網民評論傾向性分析并不是一件容易的事情,需要不斷完善系統中傾向性分類器的精度。
三是境外外語輿情監測功能欠缺[12]。主要存在聯通不暢、語言不支持、抓取不及時等短板,需加強境外站點的配置、語種語料庫等設置。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
山東工業技術(2016年15期)2016-12-01 05:31:22
中外會展(2014年4期)2014-11-27 07:46:46
電腦愛好者(2011年11期)2011-06-22 08:20:18
河北軟件職業技術學院學報(2010年3期)2010-06-06 07:18:42
祝您健康(1987年3期)1987-12-30 09:52:32
