網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
2017-03-23 21:19:09趙悅品
現(xiàn)代電子技術(shù) 2017年4期
關(guān)鍵詞:數(shù)據(jù)挖掘
趙悅品
摘 要: 傳統(tǒng)的信息挖掘方法挖掘面窄,擴(kuò)展性差,無(wú)法有效挖掘出網(wǎng)絡(luò)中的不安全信息。因此,設(shè)計(jì)并實(shí)現(xiàn)了網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng),其由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。Web文本采集模塊從網(wǎng)絡(luò)Web網(wǎng)頁(yè)中采集文本信息,并將信息反饋給文本分類模塊。文本分類模塊由訓(xùn)練模塊、分類模塊和分類器構(gòu)成。訓(xùn)練模塊采用完成分類的文本對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞間的關(guān)聯(lián)性,塑造向量空間模型。分類模塊對(duì)將要進(jìn)行分類的Web文本進(jìn)行分詞處理,通過向量描述文本特征詞。分類器運(yùn)算待分類文本特征向量同各類中心向量間的相似度,確保Web文本被劃分到具有最高相似度的文本類型中。類別判斷模塊辨識(shí)待分析的網(wǎng)絡(luò)文本信息是否屬于不安全信息類,并通過報(bào)警模塊對(duì)不安全信息進(jìn)行報(bào)警。軟件部分給出了系統(tǒng)的功能結(jié)構(gòu)以及文本分類模塊的程序?qū)崿F(xiàn)代碼。實(shí)驗(yàn)結(jié)果表明,所設(shè)計(jì)系統(tǒng)具有較高的查全率、查準(zhǔn)率和較高的檢測(cè)性能。
關(guān)鍵詞: 網(wǎng)絡(luò)信息; 安全防范; Web數(shù)據(jù); 數(shù)據(jù)挖掘
中圖分類號(hào): TN711?34; TP309 文獻(xiàn)標(biāo)識(shí)碼: A 文章編號(hào): 1004?373X(2017)04?0061?05
Design and implementation of network information security protection and
Web data mining system
ZHAO Yuepin
(Hebei Jiaotong Vocational and Technical college, Shijiazhuang 050091, China )
Abstract: The traditional information mining method has narrow mining face and poor scalability, so it cannot effectively dig out the unsafety information in the network. Therefore, the network information security protection and Web data mining system was designed and realized. It is composed of Web text acquisition module, text classification module and category judgment module. The Web text acquisition module is used to collect text information from the Internet Web pages, and feeds the information back to text classification module. The text classification module is made up of training module, classification module and classifier. The training module adopts the text completing classification to train text classification model to obtain the correlation among different category feature words and establish vector space model. The classification module is used to conduct the segmentation processing of words in Web text under classification and diescribe the text feature words through vector. The classifier is used to operate the similarity between the character vector of the text under classification and all kinds of central vector to ensure that the Web text is divided into the text type with the highest similarity. The category judgment module identifies whether the network text information under analysis belongs to the unsafety information, and gives an alarm for the unsafety information through the alarm module. The system function structure and program implementation code of the text categorization module are given in the software section. The experimental results indicate that the designed system has a high recall ratio, high precision ratio and high detection performance.
Keywords: network information; security protection; Web data; data mining
0 引 言
隨著網(wǎng)絡(luò)信息技術(shù)的快速發(fā)展,其在人們的生產(chǎn)和生活中發(fā)揮著越來越重要的作用。網(wǎng)絡(luò)信息技術(shù)的發(fā)展促使網(wǎng)絡(luò)經(jīng)濟(jì)發(fā)展速度提升,網(wǎng)絡(luò)信息安全問題限制了網(wǎng)絡(luò)經(jīng)濟(jì)的發(fā)展。因此,尋求有效的方法,確保網(wǎng)絡(luò)信息安全,成為相關(guān)人員分析的熱點(diǎn)問題[1?3]。傳統(tǒng)的信息挖掘方法,挖掘面窄,擴(kuò)展性差,無(wú)法有效挖掘出網(wǎng)絡(luò)中的不安全信息。而在網(wǎng)絡(luò)中充分運(yùn)用Web 數(shù)據(jù)挖掘技術(shù),可大大增強(qiáng)網(wǎng)絡(luò)信息安全的監(jiān)測(cè)質(zhì)量,具有重要應(yīng)用意義[4?6]。
當(dāng)前針對(duì)網(wǎng)絡(luò)不安全信息的挖掘方法大都存在一定的問題,如文獻(xiàn)[7]分析依據(jù)規(guī)則的網(wǎng)絡(luò)不安全信息檢測(cè)方法,其采用人工事先設(shè)置好的推理規(guī)則,對(duì)Web資料進(jìn)行推理分析,檢測(cè)出不安全信息。但是該方法對(duì)待檢測(cè)資料的可理解性要求較高,存在一定的局限性。文獻(xiàn)[8]分析了基于回歸模型檢測(cè)網(wǎng)絡(luò)不安全信息,其統(tǒng)計(jì)不安全信息發(fā)生的概率,塑造概率的回歸模型,完成不安全信息的歸類。該方法可在實(shí)際運(yùn)用中獲取滿意的結(jié)果,但是需要大量的數(shù)據(jù)為分析依據(jù),且檢測(cè)效率較低。文獻(xiàn)[9]通過基于連接的形式,實(shí)現(xiàn)網(wǎng)絡(luò)不安全信息的檢測(cè)。其通過一定的算法模擬人的思維,完成網(wǎng)絡(luò)信息的有效分類。但是該方法檢測(cè)到的結(jié)果較為粗糙,存在較高的誤差。文獻(xiàn)[10]提出了基于向量的網(wǎng)絡(luò)不安全信息挖掘方法,塑造網(wǎng)絡(luò)信息的向量空間,通過分析網(wǎng)絡(luò)信息向量空間的相似度,挖掘出不安全信息。但其檢測(cè)精度較低,無(wú)法獲取令人滿意的檢測(cè)效果。
針對(duì)上述問題,設(shè)計(jì)并實(shí)現(xiàn)了網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng),其由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。實(shí)驗(yàn)結(jié)果表明,所設(shè)計(jì)系統(tǒng)具有較高的查全率、查準(zhǔn)率和較高的檢測(cè)性能。
1 網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)
1.1 系統(tǒng)的體系結(jié)構(gòu)
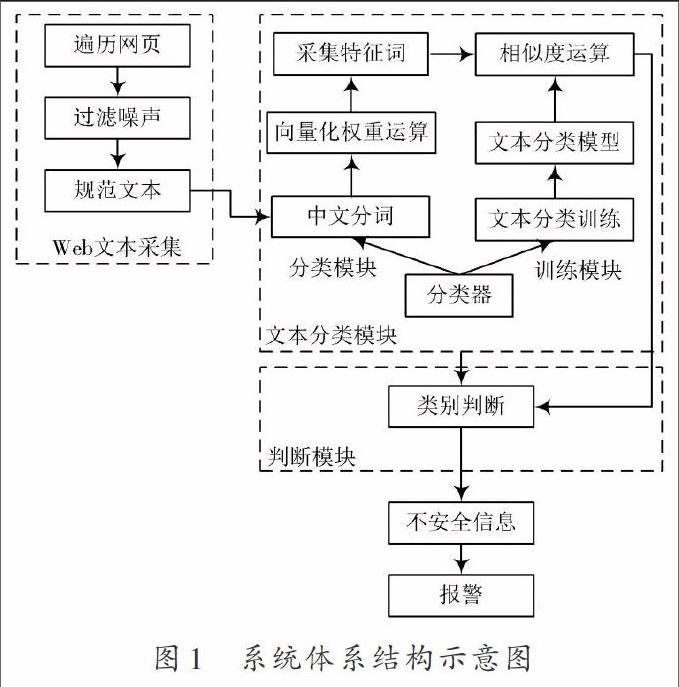
塑造的網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)的體系結(jié)構(gòu)如圖1所示。
圖1描述的系統(tǒng)體系結(jié)構(gòu)由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。Web文本采集模塊從網(wǎng)絡(luò)Web網(wǎng)頁(yè)中采集文本信息,同時(shí)將獲取的Web文本信息傳輸給文本分類模塊。文本分類模塊包括訓(xùn)練模塊、分類模塊以及分類器,訓(xùn)練模塊采用完成分類的文本對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞間的關(guān)聯(lián)性,塑造向量空間模型。分類模塊對(duì)將要進(jìn)行分類的文本進(jìn)行分詞處理,過濾其中的停用詞,采集其中的特征詞,并通過向量描述獲取特征詞。分類器對(duì)比待分類文本特征向量同各類中心向量間的相似度,將Web文本劃分到最高相似度的文本種類內(nèi)。類別判斷模塊分析待分析的網(wǎng)絡(luò)文本信息是否屬于不安全信息類,并通過報(bào)警模塊對(duì)網(wǎng)絡(luò)不安全信息進(jìn)行報(bào)警,同時(shí)通知管理人員對(duì)不安全信息進(jìn)行相關(guān)的處理。
1.2 Web文本采集模塊設(shè)計(jì)
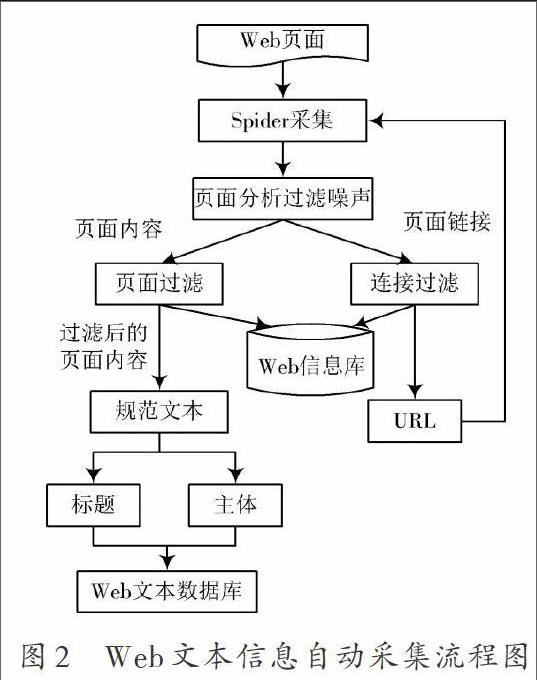
Web文本數(shù)據(jù)采集流程如圖2所示。
圖2 Web文本信息自動(dòng)采集流程圖
其中的Spider采集模塊位于Web 信息采集中底層,其通過不同Web協(xié)議自主采集互聯(lián)網(wǎng)網(wǎng)頁(yè)中的信息。Web 頁(yè)面的采集,應(yīng)先過濾Web頁(yè)面的圖像、聲音等非結(jié)構(gòu)數(shù)據(jù),再?gòu)捻?yè)面采集鏈接、文本的標(biāo)題以及正文,確保在Web網(wǎng)頁(yè)中僅存在文本信息。
超鏈接采集獲取URL,按照超鏈接分析算法,分析Web頁(yè)面種類,刪除無(wú)價(jià)值的分析鏈接頁(yè)面,保留頁(yè)面種類為“tex/html”的分析連接頁(yè)面。按照應(yīng)答頭以及URL的文件擴(kuò)展名分析頁(yè)面的種類。
規(guī)范文本將Web文本信息劃分成文章的標(biāo)題和主體,確保分類模塊可基于不同的標(biāo)題和主體,設(shè)置相應(yīng)的參數(shù)。具體的過程如下:
(1) 分析正文開始位置,順次檢索文章的段落,直至某段長(zhǎng)高于設(shè)置的正文最小長(zhǎng)度,則說明該段文字為正文中的某段。
(2) 在正文位置向文章開始處檢索,按照字體大小,是否居中等特征,獲取最滿意的一段文字,將其當(dāng)成標(biāo)題。
(3) 檢索文章直至獲取非文字字符,將對(duì)應(yīng)的內(nèi)容當(dāng)成文本的主體。
(4) 將獲取的標(biāo)題和主體存儲(chǔ)到數(shù)據(jù)庫(kù)或格式文件內(nèi)。
1.3 文本分類模塊設(shè)計(jì)
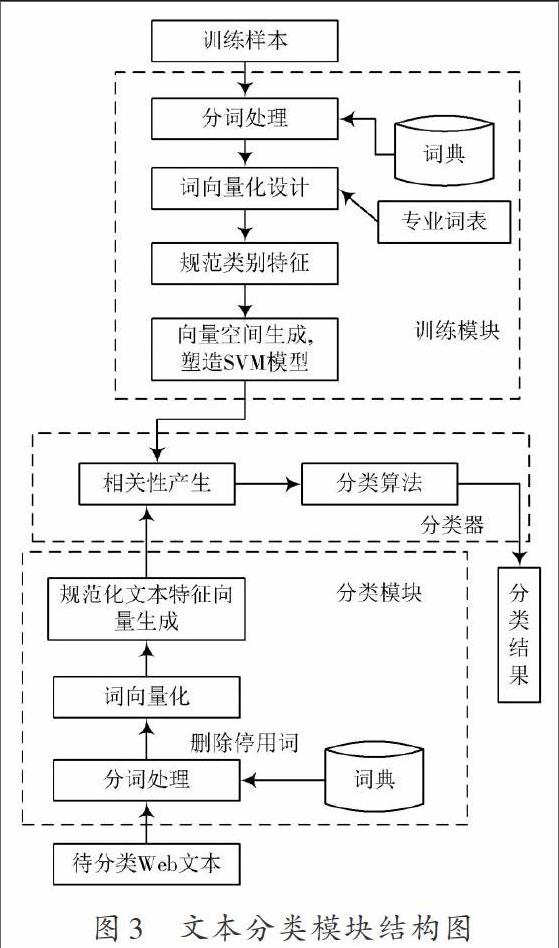
文本分類模型由訓(xùn)練模塊、分類模塊和分類器構(gòu)成。訓(xùn)練模塊通過大量完成分類的文本進(jìn)行訓(xùn)練,獲取文本分類模型,獲取不同類型特征詞間的關(guān)聯(lián)性,塑造向量空間模型SVM。分類模塊將待分類的Web文本進(jìn)行分詞處理,過濾其中的停用詞,獲取其中的特征詞,同時(shí)通過向量描述文本特征詞。分類器可運(yùn)算待分類文本特征向量同各類中心向量間的相似度,將Web文本劃分到具有最高相似度的文本類型中。塑造的文本自動(dòng)分類模塊的結(jié)構(gòu)圖如圖3所示。
圖3中,本文訓(xùn)練模塊通過分類文本訓(xùn)練對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞的關(guān)聯(lián)性,塑造向量空間模型。新文本分類模塊過濾將要進(jìn)行類型劃分的文本中的分詞,獲取文本中的特征詞,并通過向量描述該特征詞。對(duì)比將要分類的文本特征向量同各類中心向量的相似度,確保文本被分類到具有最高相似度的種類中。文本訓(xùn)練模塊持續(xù)進(jìn)行自我學(xué)習(xí),并接收新文本分類模塊反饋的訓(xùn)練文本,提高文本分類精度。
其中的語(yǔ)料搜集是從積累的大規(guī)模不安全網(wǎng)絡(luò)信息資料中,采集代表性的文本資料,將其當(dāng)成訓(xùn)練分類模型的語(yǔ)料。按照不同的文本類別塑造各類專業(yè)詞表,其中含有文本的專業(yè)詞編號(hào)、所屬類別以及專業(yè)詞等內(nèi)容。采用逆向最大匹配法采集Web文本中的最大符號(hào)串,并將其同詞典中的單詞條目進(jìn)行匹配,若匹配不成功,則過濾一個(gè)漢字,再次進(jìn)行匹配,直至在詞典中獲取相關(guān)的單詞,最終獲取Web文本的中文分詞。
將新文本劃分到分類體系中的某一類時(shí),因?yàn)榉诸愺w系中的各類別間具有一定相似性,因此需要對(duì)各類別確定合理的閾值,若Web文本在該類的閾值之上,則將文本歸類到該類中,設(shè)置的分類類別閾值為65%。
2 軟件設(shè)計(jì)
0 引 言
隨著網(wǎng)絡(luò)信息技術(shù)的快速發(fā)展,其在人們的生產(chǎn)和生活中發(fā)揮著越來越重要的作用。網(wǎng)絡(luò)信息技術(shù)的發(fā)展促使網(wǎng)絡(luò)經(jīng)濟(jì)發(fā)展速度提升,網(wǎng)絡(luò)信息安全問題限制了網(wǎng)絡(luò)經(jīng)濟(jì)的發(fā)展。因此,尋求有效的方法,確保網(wǎng)絡(luò)信息安全,成為相關(guān)人員分析的熱點(diǎn)問題[1?3]。傳統(tǒng)的信息挖掘方法,挖掘面窄,擴(kuò)展性差,無(wú)法有效挖掘出網(wǎng)絡(luò)中的不安全信息。而在網(wǎng)絡(luò)中充分運(yùn)用Web 數(shù)據(jù)挖掘技術(shù),可大大增強(qiáng)網(wǎng)絡(luò)信息安全的監(jiān)測(cè)質(zhì)量,具有重要應(yīng)用意義[4?6]。
當(dāng)前針對(duì)網(wǎng)絡(luò)不安全信息的挖掘方法大都存在一定的問題,如文獻(xiàn)[7]分析依據(jù)規(guī)則的網(wǎng)絡(luò)不安全信息檢測(cè)方法,其采用人工事先設(shè)置好的推理規(guī)則,對(duì)Web資料進(jìn)行推理分析,檢測(cè)出不安全信息。但是該方法對(duì)待檢測(cè)資料的可理解性要求較高,存在一定的局限性。文獻(xiàn)[8]分析了基于回歸模型檢測(cè)網(wǎng)絡(luò)不安全信息,其統(tǒng)計(jì)不安全信息發(fā)生的概率,塑造概率的回歸模型,完成不安全信息的歸類。該方法可在實(shí)際運(yùn)用中獲取滿意的結(jié)果,但是需要大量的數(shù)據(jù)為分析依據(jù),且檢測(cè)效率較低。文獻(xiàn)[9]通過基于連接的形式,實(shí)現(xiàn)網(wǎng)絡(luò)不安全信息的檢測(cè)。其通過一定的算法模擬人的思維,完成網(wǎng)絡(luò)信息的有效分類。但是該方法檢測(cè)到的結(jié)果較為粗糙,存在較高的誤差。文獻(xiàn)[10]提出了基于向量的網(wǎng)絡(luò)不安全信息挖掘方法,塑造網(wǎng)絡(luò)信息的向量空間,通過分析網(wǎng)絡(luò)信息向量空間的相似度,挖掘出不安全信息。但其檢測(cè)精度較低,無(wú)法獲取令人滿意的檢測(cè)效果。
針對(duì)上述問題,設(shè)計(jì)并實(shí)現(xiàn)了網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng),其由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。實(shí)驗(yàn)結(jié)果表明,所設(shè)計(jì)系統(tǒng)具有較高的查全率、查準(zhǔn)率和較高的檢測(cè)性能。
1 網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)
1.1 系統(tǒng)的體系結(jié)構(gòu)
塑造的網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)的體系結(jié)構(gòu)如圖1所示。
圖1描述的系統(tǒng)體系結(jié)構(gòu)由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。Web文本采集模塊從網(wǎng)絡(luò)Web網(wǎng)頁(yè)中采集文本信息,同時(shí)將獲取的Web文本信息傳輸給文本分類模塊。文本分類模塊包括訓(xùn)練模塊、分類模塊以及分類器,訓(xùn)練模塊采用完成分類的文本對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞間的關(guān)聯(lián)性,塑造向量空間模型。分類模塊對(duì)將要進(jìn)行分類的文本進(jìn)行分詞處理,過濾其中的停用詞,采集其中的特征詞,并通過向量描述獲取特征詞。分類器對(duì)比待分類文本特征向量同各類中心向量間的相似度,將Web文本劃分到最高相似度的文本種類內(nèi)。類別判斷模塊分析待分析的網(wǎng)絡(luò)文本信息是否屬于不安全信息類,并通過報(bào)警模塊對(duì)網(wǎng)絡(luò)不安全信息進(jìn)行報(bào)警,同時(shí)通知管理人員對(duì)不安全信息進(jìn)行相關(guān)的處理。
1.2 Web文本采集模塊設(shè)計(jì)
Web文本數(shù)據(jù)采集流程如圖2所示。
圖2 Web文本信息自動(dòng)采集流程圖
其中的Spider采集模塊位于Web 信息采集中底層,其通過不同Web協(xié)議自主采集互聯(lián)網(wǎng)網(wǎng)頁(yè)中的信息。Web 頁(yè)面的采集,應(yīng)先過濾Web頁(yè)面的圖像、聲音等非結(jié)構(gòu)數(shù)據(jù),再?gòu)捻?yè)面采集鏈接、文本的標(biāo)題以及正文,確保在Web網(wǎng)頁(yè)中僅存在文本信息。
超鏈接采集獲取URL,按照超鏈接分析算法,分析Web頁(yè)面種類,刪除無(wú)價(jià)值的分析鏈接頁(yè)面,保留頁(yè)面種類為“tex/html”的分析連接頁(yè)面。按照應(yīng)答頭以及URL的文件擴(kuò)展名分析頁(yè)面的種類。
規(guī)范文本將Web文本信息劃分成文章的標(biāo)題和主體,確保分類模塊可基于不同的標(biāo)題和主體,設(shè)置相應(yīng)的參數(shù)。具體的過程如下:
(1) 分析正文開始位置,順次檢索文章的段落,直至某段長(zhǎng)高于設(shè)置的正文最小長(zhǎng)度,則說明該段文字為正文中的某段。
(2) 在正文位置向文章開始處檢索,按照字體大小,是否居中等特征,獲取最滿意的一段文字,將其當(dāng)成標(biāo)題。
(3) 檢索文章直至獲取非文字字符,將對(duì)應(yīng)的內(nèi)容當(dāng)成文本的主體。
(4) 將獲取的標(biāo)題和主體存儲(chǔ)到數(shù)據(jù)庫(kù)或格式文件內(nèi)。
1.3 文本分類模塊設(shè)計(jì)
文本分類模型由訓(xùn)練模塊、分類模塊和分類器構(gòu)成。訓(xùn)練模塊通過大量完成分類的文本進(jìn)行訓(xùn)練,獲取文本分類模型,獲取不同類型特征詞間的關(guān)聯(lián)性,塑造向量空間模型SVM。分類模塊將待分類的Web文本進(jìn)行分詞處理,過濾其中的停用詞,獲取其中的特征詞,同時(shí)通過向量描述文本特征詞。分類器可運(yùn)算待分類文本特征向量同各類中心向量間的相似度,將Web文本劃分到具有最高相似度的文本類型中。塑造的文本自動(dòng)分類模塊的結(jié)構(gòu)圖如圖3所示。
圖3中,本文訓(xùn)練模塊通過分類文本訓(xùn)練對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞的關(guān)聯(lián)性,塑造向量空間模型。新文本分類模塊過濾將要進(jìn)行類型劃分的文本中的分詞,獲取文本中的特征詞,并通過向量描述該特征詞。對(duì)比將要分類的文本特征向量同各類中心向量的相似度,確保文本被分類到具有最高相似度的種類中。文本訓(xùn)練模塊持續(xù)進(jìn)行自我學(xué)習(xí),并接收新文本分類模塊反饋的訓(xùn)練文本,提高文本分類精度。
其中的語(yǔ)料搜集是從積累的大規(guī)模不安全網(wǎng)絡(luò)信息資料中,采集代表性的文本資料,將其當(dāng)成訓(xùn)練分類模型的語(yǔ)料。按照不同的文本類別塑造各類專業(yè)詞表,其中含有文本的專業(yè)詞編號(hào)、所屬類別以及專業(yè)詞等內(nèi)容。采用逆向最大匹配法采集Web文本中的最大符號(hào)串,并將其同詞典中的單詞條目進(jìn)行匹配,若匹配不成功,則過濾一個(gè)漢字,再次進(jìn)行匹配,直至在詞典中獲取相關(guān)的單詞,最終獲取Web文本的中文分詞。
將新文本劃分到分類體系中的某一類時(shí),因?yàn)榉诸愺w系中的各類別間具有一定相似性,因此需要對(duì)各類別確定合理的閾值,若Web文本在該類的閾值之上,則將文本歸類到該類中,設(shè)置的分類類別閾值為65%。
2 軟件設(shè)計(jì)
0 引 言
隨著網(wǎng)絡(luò)信息技術(shù)的快速發(fā)展,其在人們的生產(chǎn)和生活中發(fā)揮著越來越重要的作用。網(wǎng)絡(luò)信息技術(shù)的發(fā)展促使網(wǎng)絡(luò)經(jīng)濟(jì)發(fā)展速度提升,網(wǎng)絡(luò)信息安全問題限制了網(wǎng)絡(luò)經(jīng)濟(jì)的發(fā)展。因此,尋求有效的方法,確保網(wǎng)絡(luò)信息安全,成為相關(guān)人員分析的熱點(diǎn)問題[1?3]。傳統(tǒng)的信息挖掘方法,挖掘面窄,擴(kuò)展性差,無(wú)法有效挖掘出網(wǎng)絡(luò)中的不安全信息。而在網(wǎng)絡(luò)中充分運(yùn)用Web 數(shù)據(jù)挖掘技術(shù),可大大增強(qiáng)網(wǎng)絡(luò)信息安全的監(jiān)測(cè)質(zhì)量,具有重要應(yīng)用意義[4?6]。
當(dāng)前針對(duì)網(wǎng)絡(luò)不安全信息的挖掘方法大都存在一定的問題,如文獻(xiàn)[7]分析依據(jù)規(guī)則的網(wǎng)絡(luò)不安全信息檢測(cè)方法,其采用人工事先設(shè)置好的推理規(guī)則,對(duì)Web資料進(jìn)行推理分析,檢測(cè)出不安全信息。但是該方法對(duì)待檢測(cè)資料的可理解性要求較高,存在一定的局限性。文獻(xiàn)[8]分析了基于回歸模型檢測(cè)網(wǎng)絡(luò)不安全信息,其統(tǒng)計(jì)不安全信息發(fā)生的概率,塑造概率的回歸模型,完成不安全信息的歸類。該方法可在實(shí)際運(yùn)用中獲取滿意的結(jié)果,但是需要大量的數(shù)據(jù)為分析依據(jù),且檢測(cè)效率較低。文獻(xiàn)[9]通過基于連接的形式,實(shí)現(xiàn)網(wǎng)絡(luò)不安全信息的檢測(cè)。其通過一定的算法模擬人的思維,完成網(wǎng)絡(luò)信息的有效分類。但是該方法檢測(cè)到的結(jié)果較為粗糙,存在較高的誤差。文獻(xiàn)[10]提出了基于向量的網(wǎng)絡(luò)不安全信息挖掘方法,塑造網(wǎng)絡(luò)信息的向量空間,通過分析網(wǎng)絡(luò)信息向量空間的相似度,挖掘出不安全信息。但其檢測(cè)精度較低,無(wú)法獲取令人滿意的檢測(cè)效果。
針對(duì)上述問題,設(shè)計(jì)并實(shí)現(xiàn)了網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng),其由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。實(shí)驗(yàn)結(jié)果表明,所設(shè)計(jì)系統(tǒng)具有較高的查全率、查準(zhǔn)率和較高的檢測(cè)性能。
1 網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)
1.1 系統(tǒng)的體系結(jié)構(gòu)
塑造的網(wǎng)絡(luò)信息安全防范與Web數(shù)據(jù)挖掘系統(tǒng)的體系結(jié)構(gòu)如圖1所示。
圖1描述的系統(tǒng)體系結(jié)構(gòu)由Web文本采集模塊、文本分類模塊和類別判斷模塊構(gòu)成。Web文本采集模塊從網(wǎng)絡(luò)Web網(wǎng)頁(yè)中采集文本信息,同時(shí)將獲取的Web文本信息傳輸給文本分類模塊。文本分類模塊包括訓(xùn)練模塊、分類模塊以及分類器,訓(xùn)練模塊采用完成分類的文本對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞間的關(guān)聯(lián)性,塑造向量空間模型。分類模塊對(duì)將要進(jìn)行分類的文本進(jìn)行分詞處理,過濾其中的停用詞,采集其中的特征詞,并通過向量描述獲取特征詞。分類器對(duì)比待分類文本特征向量同各類中心向量間的相似度,將Web文本劃分到最高相似度的文本種類內(nèi)。類別判斷模塊分析待分析的網(wǎng)絡(luò)文本信息是否屬于不安全信息類,并通過報(bào)警模塊對(duì)網(wǎng)絡(luò)不安全信息進(jìn)行報(bào)警,同時(shí)通知管理人員對(duì)不安全信息進(jìn)行相關(guān)的處理。
1.2 Web文本采集模塊設(shè)計(jì)
Web文本數(shù)據(jù)采集流程如圖2所示。
圖2 Web文本信息自動(dòng)采集流程圖
其中的Spider采集模塊位于Web 信息采集中底層,其通過不同Web協(xié)議自主采集互聯(lián)網(wǎng)網(wǎng)頁(yè)中的信息。Web 頁(yè)面的采集,應(yīng)先過濾Web頁(yè)面的圖像、聲音等非結(jié)構(gòu)數(shù)據(jù),再?gòu)捻?yè)面采集鏈接、文本的標(biāo)題以及正文,確保在Web網(wǎng)頁(yè)中僅存在文本信息。
超鏈接采集獲取URL,按照超鏈接分析算法,分析Web頁(yè)面種類,刪除無(wú)價(jià)值的分析鏈接頁(yè)面,保留頁(yè)面種類為“tex/html”的分析連接頁(yè)面。按照應(yīng)答頭以及URL的文件擴(kuò)展名分析頁(yè)面的種類。
規(guī)范文本將Web文本信息劃分成文章的標(biāo)題和主體,確保分類模塊可基于不同的標(biāo)題和主體,設(shè)置相應(yīng)的參數(shù)。具體的過程如下:
(1) 分析正文開始位置,順次檢索文章的段落,直至某段長(zhǎng)高于設(shè)置的正文最小長(zhǎng)度,則說明該段文字為正文中的某段。
(2) 在正文位置向文章開始處檢索,按照字體大小,是否居中等特征,獲取最滿意的一段文字,將其當(dāng)成標(biāo)題。
(3) 檢索文章直至獲取非文字字符,將對(duì)應(yīng)的內(nèi)容當(dāng)成文本的主體。
(4) 將獲取的標(biāo)題和主體存儲(chǔ)到數(shù)據(jù)庫(kù)或格式文件內(nèi)。
1.3 文本分類模塊設(shè)計(jì)
文本分類模型由訓(xùn)練模塊、分類模塊和分類器構(gòu)成。訓(xùn)練模塊通過大量完成分類的文本進(jìn)行訓(xùn)練,獲取文本分類模型,獲取不同類型特征詞間的關(guān)聯(lián)性,塑造向量空間模型SVM。分類模塊將待分類的Web文本進(jìn)行分詞處理,過濾其中的停用詞,獲取其中的特征詞,同時(shí)通過向量描述文本特征詞。分類器可運(yùn)算待分類文本特征向量同各類中心向量間的相似度,將Web文本劃分到具有最高相似度的文本類型中。塑造的文本自動(dòng)分類模塊的結(jié)構(gòu)圖如圖3所示。
圖3中,本文訓(xùn)練模塊通過分類文本訓(xùn)練對(duì)文本分類模型進(jìn)行訓(xùn)練,獲取不同類別特征詞的關(guān)聯(lián)性,塑造向量空間模型。新文本分類模塊過濾將要進(jìn)行類型劃分的文本中的分詞,獲取文本中的特征詞,并通過向量描述該特征詞。對(duì)比將要分類的文本特征向量同各類中心向量的相似度,確保文本被分類到具有最高相似度的種類中。文本訓(xùn)練模塊持續(xù)進(jìn)行自我學(xué)習(xí),并接收新文本分類模塊反饋的訓(xùn)練文本,提高文本分類精度。
其中的語(yǔ)料搜集是從積累的大規(guī)模不安全網(wǎng)絡(luò)信息資料中,采集代表性的文本資料,將其當(dāng)成訓(xùn)練分類模型的語(yǔ)料。按照不同的文本類別塑造各類專業(yè)詞表,其中含有文本的專業(yè)詞編號(hào)、所屬類別以及專業(yè)詞等內(nèi)容。采用逆向最大匹配法采集Web文本中的最大符號(hào)串,并將其同詞典中的單詞條目進(jìn)行匹配,若匹配不成功,則過濾一個(gè)漢字,再次進(jìn)行匹配,直至在詞典中獲取相關(guān)的單詞,最終獲取Web文本的中文分詞。
將新文本劃分到分類體系中的某一類時(shí),因?yàn)榉诸愺w系中的各類別間具有一定相似性,因此需要對(duì)各類別確定合理的閾值,若Web文本在該類的閾值之上,則將文本歸類到該類中,設(shè)置的分類類別閾值為65%。
2 軟件設(shè)計(jì)
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國(guó)交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國(guó)中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學(xué)學(xué)報(bào)(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:12
