基于Hadoop平臺的圖像識別
2017-03-23 23:35:40趙禎
現代電子技術 2017年4期
趙禎

摘 要: 基于Hadoop平臺以字符識別為例建立圖像識別系統。所設計的系統在借鑒云平臺高擴展性以及高效性等優勢的基礎上,有效地解決了傳統字符識別系統在計算效率以及數據處理方面所存在的不足。通過實例驗證了基于Hadoop平臺進行圖像識別相比單機圖像識別系統具有更高的效率:在僅具有2個節點的Hadoop圖像識別平臺上進行字符圖像的識別時,由于節點數較少,在2臺計算機中消耗的數據交換時間使得Hadoop圖像識別平臺進行圖像識別的總時間甚至超過了單臺計算機所使用的時間,而在具有4個節點、6個節點和8個節點的Hadoop圖像識別平臺上,處理相同圖像所使用的時間隨著節點數量增多而降低。
關鍵詞: 字符識別; Hadoop平臺; 圖像識別; 數據交換時間
中圖分類號: TN911?34; U495 文獻標識碼: A 文章編號: 1004?373X(2017)04?0128?04
Image recognition based on Hadoop platform
ZHAO Zhen
(Department of Software Engineering, Inner Mongolia Electronic Information Vocational Technical College, Hohhot 010000, China)
Abstract: The image recognition system was established based on Hadoop platform, which takes the character recognition as an example. The system based on the advantages of good scalability and high efficiency of the cloud platform can effectively eliminate the shortcomings of the traditional character recognition system in the aspects of computing efficiency and data processing. The fact that the efficiency of the image recognition system based on Hadoop platform is higher than that of the stand?alone image recognition system is verified with an instance. The data exchange time consumed in two computers makes the total time of the image recognition based on Hadoop image recognition platform with only two nodes longer than the use time of the image recognition based on single computer due to the less node quantity, when the character image is recognized on Hadoop image recognition platform with two nodes. The use time for processing the same image on Hadoop image recognition platform with four nodes, six nodes or eight nodes is deduced with the increase of the node quantity.
Keywords: character recognition; Hadoop platform; image recognition; data exchange time
在對互聯網圖片進行匹配和分類的過程中,單臺計算機已經無法滿足相應的需求,而分布式計算框架能夠穩定和高效地匹配和分配大量的互聯網圖片,具有顯著的優勢[1?2]。本文基于Hadoop平臺,以字符識別為例建立圖像識別系統。本文所設計的系統在借鑒云平臺高擴展性以及高效性等優勢的基礎上有效的解決在計算效率以及數據處理方面傳統字符識別系統所存在的不足。主要體現在以下兩個方面:利用Hadoop能夠在平臺各個節點中分配字符識別任務,對于任務執行時間的縮短有非常積極的作用,還能夠提升系統處理大型數據集的效率;能夠在普通的PC機上搭建Hadoop平臺,同時節點數可以根據數據量大小以及任務需求來靈活的減小,相比于一些昂貴的服務器,其具有非常顯著的成本優勢。另外,在互聯網技術逐漸發展和完善的過程中傳統的單機離線識別系統已經不能滿足現代化的需求,所以以云平臺為基礎對字符識別系統進行研究具有顯著的現實意義和實用價值[3?4]。
1 基于Hadoop平臺圖像識別系統框架
1.1 傳統圖像識別框架
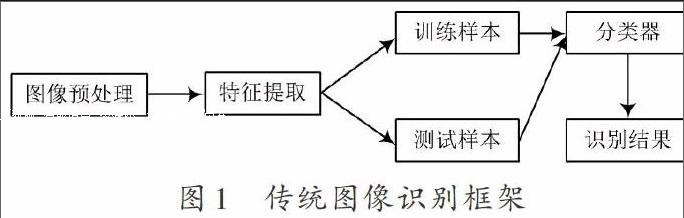
傳統圖像識別框架如圖1所示。
傳統圖像識別框架主要由圖像預處理模塊、相關特征提取模塊和分類器訓練分類模塊組成[5]。
(1) 圖像預處理模塊。通過圖像預處理模塊能夠轉換用戶所選擇的彩色圖片,并將轉換得到的灰度圖像在內存中進行讀入,為下一步的計算做好準備工作。
(2) 相關特征提取模塊。通過相關特征提取模塊能夠運算讀入到內存中的圖像數據,進而保證所獲取的圖像特征能夠滿足用戶需求。通過該模塊能夠向量化用戶提供所需要的特征。
(3) 分類器訓練分類模塊。通過對神經網絡以及支持向量機等機器學習算法的應用,該模塊能夠訓練所提取的樣本數據,同時根據實際的需求用戶可以對相關的算法訓練分類器進行選擇。能夠在本地文件系統中以文件的形式將這些訓練得到的分類器儲存起來。在實現前兩個模塊的功能以后就可以使用分類器判決特征向量,進而對輸入圖像的類別進行識別。
在利用傳統圖像分類系統進行圖像分類的過程中,圖像特性提取過程需要耗費非常長的時間,另外在對較大數據量的特征矩陣進行計算時需要讀寫系統硬盤與內存,這就直接增加了程序的出錯率,降低了系統的穩定性和可靠性。
在訓練分類模型的過程中用戶可以利用傳統圖像分類系統對不同類型的分類器模型進行選擇。但是不同的分類器采用了不同的訓練算法,使得所選取的參數以及模型存在著一定的差距,如果不能保證所選取分類器模型的適用性,沒有充分地優化模型參數,就會降低分類器的正確率。
1.2 基于hadoop平臺圖像識別系統框架
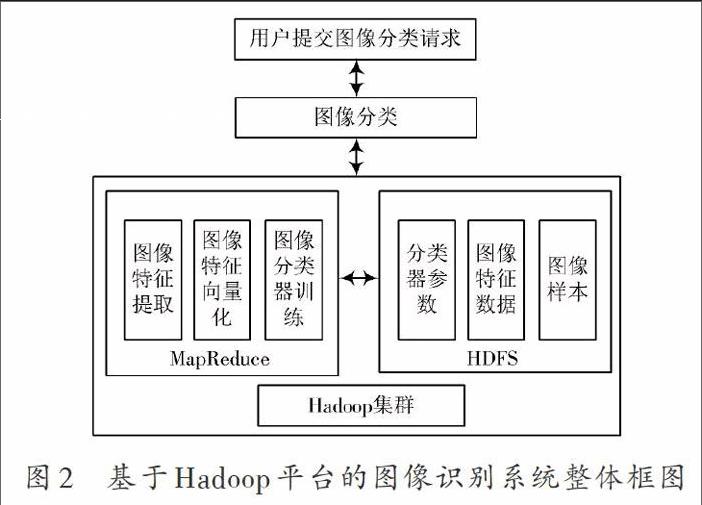
基于Hadoop平臺的圖像識別系統整體框圖如圖2所示[6]。在Hadoop平臺上進行圖像識別主要分為以下5個過程[7]:
(1) 用戶提交圖像分類請求。通過Job Client就可以從Hadoop的Job Tracker中獲取新的圖像分類作業ID。然后工程JAR包可以由圖像分類作業運行,通過Job Client能夠將程序依賴的圖像特征分類數據以及配置文件復制到HDFS中。完成以上過程以后,Job Client就可以將作業提交到Job Tracker中,Job Tracker首先對作業的相關信息進行檢查,然后輸入數據的劃分情況就可以從HDFS中獲取,做好作業執行的準備工作。
(2) 圖像分類作業的任務分配與初始化。在接收到Job Client提交的作業之后,Job Tracker就會對作業進行初始化操作,并在一個內部的任務隊列中放置該作業。利用Hadoop的作業調度器可以調度這個隊列中的任務。根據Task Tracker的心跳情況Job Tracker就可以在相應的集群節點上分配相關的作業任務,由于部分特征數據是存放在DataNode上的,因此在進行MapTask的過程中Job Tracker能夠從本次直接獲取輸入數據,這樣能夠有效地減少數據傳輸過程中所產生的網絡損耗。
(3) 圖像分類任務的Map階段。在獲取到Job Tracker所分配的任務以后,程序的相關數據以及JAR文件就可以自動地從HDFS中獲取,并在本地的文件磁盤中進行儲存,通過對本地的Java虛擬機進行執行就可以對JAR文件和數據進行加載,這樣運行任務實例的Task Tracker中就可以接收到數據塊。在對Map任務進行執行的過程中,應當對特征庫中的圖像特征與對應類下輸入圖像的特征之間的距離進行計算,并將特征圖像庫中的圖像類別以及計算得到的距離作為輸出結果的鍵值對,并在本地文件磁盤中存儲得到的結果。
(4) 圖像分類任務的Reduce階段。在獲取Map任務計算得到的圖像特征向量的中間臨時鍵值對之后,就可以進行圖像的分類。MapReduce框架按照其對應的鍵值對這些特征向量進行分類,當中間結果的鍵值一致時就會整理和合并鍵值對的特征向量,并由ReduceTask來處理合并之后的結果。利用ReduceTask可以排序MapTask的輸出,并獲取圖像分類的結果,同時將結果寫入到HDFS中。
(5) 圖像分類任務的完成:完成Reduce階段以后,JobTracker就會識別到任務已經完成,并進行相應的表示,另外用戶利用JobTracker可以獲取作業運行的相關參數。最后,利用JobTracker清空所有作業狀態,利用TaskTracker刪除Map階段產生的中間結果,這樣用戶就可以在HDFS上對結果文件進行查看。
2 字符圖像識別方法
通常情況下,對字符進行識別,會使用神經網絡和字符識別兩種方法。神經網絡的識別效率很低,但是擁有較好的容錯性能;字符識別形式簡單,運行速度快,應用比較廣泛。在文中對字符進行識別,使用文獻[8]提到的模板匹配和字符圖像特征統計相結合的方法。通過確定分析樣本和輸入形式之間的相似度,將相似程度最高的確定為輸入模型類型。在特征的提取過程中,會使用字符的最直接形象,在識別過程中會用到內容匹配原理。也就是說,在完成匹配的時候,要將標準形式的字符和需要輸入的字符放到相同的分類器中。相關匹配方法表示如下:
假設以輸入函數表示輸入字符,函數表示標準模板,為通過相關器比較得到的輸出。相關器的輸出表示為:
3 Hadoop平臺圖像識別過程實現
為了保證Hadoop平臺能夠并行地識別字符圖像,應當以MapReduce框架為基礎進行Reduce()和Map()函數的編寫,其中輸入和數據鍵值對的設計對于Map()和Reduce()函數的編寫非常關鍵[9]。
將Keyin設定為Text 類型來對字符圖像的文件名進行儲存;將Valuein設置為Image 類型來對字符圖像數據進行儲存。在將圖像數據從HDFS中批量讀入以后,Map()函數就可以將其解析為相應的鍵值對,通過Exif信息提取的執行就可以識別字符,同時在中間結果Keyj中存儲所識別的字符,在中間結果Valuej中存儲圖像文件名以及拍攝時間,經過Collect,Spill,Combine過程Reduce()函數就可以接收到最終的結果。在執行Map Tasks的過程中,輸入圖像的數量控制著所產生的Map 任務個數,同時這些Map 任務具有相互獨立的特點。Map任務數據流處理過程如圖3所示[10?11]。
其中,字符識別功能可以通過Map()函數來實現,每個Map 任務由單獨的鍵值對來啟動,采用下面兩個步驟處理解析出的圖像。首先通過調用metadata?extractor就可以將拍攝文件名和時間提取出來。然后通過算法的執行來對圖像中的字符進行識別。最后在鍵值對中寫入結果,并將其作為Reduce()函數的輸入[12]。
在完成Map()函數的執行以后就需要將輸出的中間值Valuej以及keyj傳遞到Reduce Task,不同的Keyj下的Valuej由不同的Reduce Task來負責,在執行完所有的Map()函數以后就可以在Reduce()函數中合并和排序處理收集到的鍵值對。Reduce任務數據流處理過程如圖4所示。
其中,通過應用冒泡法Reduce()函數可以排序Value 值中的時間參數,并將拍攝時間與文件名以及字符以文本的形式進行輸出[13]。
4 基于Hadoop平臺圖像識別效率分析
本文通過實例對比分析基于Hadoop平臺以及單機圖像識別平臺的識別效率。
單機圖像識別平臺和Hadoop圖像識別平臺中主從機均使用相同配置的計算機。在Hadoop平臺中節點計算機上安裝Hadoop 1.0.0版本平臺系統,并對Hadoop平臺系統進行配置。
將采集到的字符圖像分為四組,各組中分別包含了200,500,1 000和2 000張字符圖像,分別使用單機圖像識別平臺以及配置有2,4,6和8個節點的Hadoop圖像識別平臺進行圖像識別,分別得到各種識別平臺下的識別時間如圖5所示。
從各識別平臺的識別效率對比曲線可以看出,在僅具有2個節點的Hadoop圖像識別平臺上進行字符圖像的識別時,由于節點數較少,在兩臺計算機中消耗的數據交換時間使得Hadoop圖像識別平臺進行圖像識別的總時間甚至超過了單臺計算機所使用的時間,而在具有4個節點、6個節點和8個節點的Hadoop圖像識別平臺上,處理相同圖像所使用的時間隨著節點數量增多而降低。
5 結 論
在對互聯網圖片進行匹配和分類的過程中,單臺計算機已經無法滿足相應的需求,而分布式計算框架能夠穩定和高效地匹配和分配大量的互聯網圖片,具有顯著的優勢。本文基于Hadoop平臺,以字符識別為例建立圖像識別系統。本文所設計的系統在借鑒云平臺高擴展性以及高效性等優勢的基礎上有效地解決在計算效率以及數據處理方面傳統字符識別系統所存在的不足。通過實例驗證了基于Hadoop平臺進行圖像識別相比單機圖像識別系統具有更高的效率。
參考文獻
[1] 王自昊.基于Hadoop的圖像分類與匹配研究[D].北京:北京郵電大學,2015.
[2] 梁世磊.基于Hadoop平臺的隨機森林算法研究及圖像分類系統實現[D].廈門:廈門大學,2014.
[3] 呂聯盟.基于云計算的人臉識別系統研究與設計[D].西安:長安大學,2014.
[4] 李潔.基于Hadoop的海量視頻的分布式存儲與檢索研究[D].南京:南京郵電大學,2015.
[5] 陳永權.基于Hadoop的圖像檢索算法研究與實現[D].廣州:華南理工大學,2013.
[6] 李彬.嵌入式車牌識別系統的設計與實現[D].西安:西安工業大學,2013.
[7] 陳洪.基于云計算的大規模圖像檢索后臺處理系統實現[D].成都:西南交通大學,2013.
[8] 陳聰,姚大志.高靈敏度CCD和圖像特征在車牌識別中的應用[J].計算機仿真,2015,32(11):164?168.
[9] 潘天工.汽車牌照自動識別系統的研究[D].哈爾濱:哈爾濱理工大學,2006.
[10] 李科.基于FPGA和DSP的車牌識別系統的硬件設計與實現[D].成都:電子科技大學,2007.
[11] 王彤.車牌識別系統設計與實現[D].蘇州:蘇州大學,2009.
[12] 李顏.基于云平臺的車牌識別系統設計與實現[D].桂林:桂林電子科技大學,2015.
[13] 章為川.基于神經網絡的車牌識別系統的研究與設計[D].成都:西南交通大學,2006.
