
Linux下自適應網絡數據捕獲系統設計
2017-04-10 19:42:29周瑩
中國新通信 2017年4期
周瑩
【摘要】 本文在對零拷貝技術改進的基礎上提出了一種適應不同網絡負載環境下的自適應的數據捕獲方法,重點介紹了其實現的關鍵技術、數據捕獲整體結構,自適應數據捕獲方法使用范圍更廣、在同等條件下有效的減輕了CPU的負荷,提高了數據捕獲的效率。
【關鍵詞】 自適應 數據捕獲 Linux系統
一、引言
網絡數據捕獲是網絡安全性分析過程中一種常用的方法,一般采用NAPI中斷輪詢機制、零拷貝技術和TOE等關鍵方法來提升數據捕獲的性能,但是這些方案在實際應用中存在適用范圍小性能提升有限等問題。本文提出了自適應網絡數據捕獲方法,實現一種應用范圍更廣的數據捕獲方案。
二、自適應數據捕獲及其關鍵技術
為了提高數據捕獲的效率,適應不同的網絡環境,本文在零拷貝的基礎上提出一種自適應的網絡數據捕獲機制。
2.1 自適應網絡數據捕獲整體結構
與零拷貝技術相比,將接口程序中隊列中的去寫數據的方式從硬件中斷方式改為輪詢方式,設定自適應的輪詢定時器,采用自適應的方式根據流量大小對定時器的工作時間進行調整,如果網絡中數據流量較大時則增大定時器的定時時間間隔,如果流量較小時則減小定時器定時時間。通過這種方式可以減小中斷帶來的系統開銷,同時能夠根據不同的網絡環境適時調整輪詢頻率,及時高效的處理網絡數據。
2.2 自適應定時器
自適應網絡數據捕獲方法減少中斷次數的關鍵就是根據網絡流量大小修正輪詢時定時器計時的時間間隔。其核心是根據已經采集的數據流量大小預測定下一次定時器啟動的時間。在預測時間時首先按照一定的時間間隔采集當前網絡流量大小得到一個連續的時間序列,網絡流量數據可以用如下數據形式描述:
X={x1,x2,x3,…xt,t=1,2,3…}
其中xt表示網絡中t到t+1時刻網絡中數據流量大小,X表示為連續的網絡流量時間序列。網絡流量預測根據過去的現在已知的或者非確定的網絡流量狀態建立一個網絡流量預測模型從而預測未來的流量,可以用如下函數表示: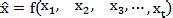
其中為其與預測值。為了不增加額外的開銷,在流量預測時使用計算相對簡單預測也較準確的基于數理統計的泊松過程模型。
2.3 內存地址映射
為了避免數據在內存之間的拷貝,在用戶和內核中設置了一塊共享的緩沖區,但是用戶程序所使用的地址和硬件使用的物理地址是不相同的。Linux操作系統中每個應用程序維護一個多級頁表來實現地址之間的轉換。
內存地址轉換時首先將用戶緩沖區UserBuff經過頁對齊之后的首地址傳入內核中并以此為首地址逐級映射到物理地址表phy_addr_table。物理地址表phy_addr_table一旦初始化后就鎖定不可更改。具體過程如下:
For(i=0;i<(BUFF_BLK_NUM)>>1);i++,addr+=PAGE_SIZE)
經過映射之后,用戶就可以直接訪問送入Phy_addr_ table中的網絡數據包。
三、測試
為了對自適應網絡數據數據捕獲方法進行進一步分析,對整個系統進行了測試。測試是使用linux2.6.21操作系統,realtek rtl8168 8111網卡,CPU為Intel(R) i3-2100 CPU。為了測試自適應數據捕獲系統的性能,測試了64字節小包發送不同速率的數據包對CPU資源的占用情況,測試結果如表1所示:
測試結果表明,自適應的網絡數據捕獲方法在不同的數據流量大小情況下占用CPU的資源均比使用libpcap庫和零拷貝技術時要小,尤其是在發包數量大道150萬個/s的情況下采用libpcap庫和零拷貝機制的CPU使用率達到將近100%,自適應數據捕獲CPU使用率仍然相對較低。
四、結束語
本文在對零拷貝技術的改進的基礎上提出了一種適應不同網絡負載環境下的自適應的數據捕獲方法,相比較與其他數據捕獲機制,自適應數據捕獲方法使用范圍更廣、在同等條件下有效的減輕了CPU的負荷,提高了數據捕獲的效率。
參 考 文 獻
[1]馬博.Linux下的高流量數據包監聽技術[J].計算機應用,2009,29(5):1244-1250
[2]劉文濤.網絡安全開發包詳解[M].北京:電子工業出版社,2011
