基于改進(jìn)仿射傳播聚類的圖像分割算法研究
2017-04-13 01:34:38趙淑娟王江晴孫陽光
軟件導(dǎo)刊 2017年3期
趙淑娟,王江晴,孫陽光
(中南民族大學(xué) 計(jì)算機(jī)科學(xué)學(xué)院,湖北 武漢 430074)
基于改進(jìn)仿射傳播聚類的圖像分割算法研究
趙淑娟,王江晴,孫陽光
(中南民族大學(xué) 計(jì)算機(jī)科學(xué)學(xué)院,湖北 武漢 430074)
仿射傳播聚類算法是一種比較新的基于質(zhì)心的聚類算法,在圖像分割領(lǐng)域得到了廣泛應(yīng)用。仿射傳播聚類算法最終聚類數(shù)目會(huì)受到偏向參數(shù)P(Preference)的影響,得到的聚類數(shù)目往往偏多,影響分割質(zhì)量。鑒于此,提出一種改進(jìn)的仿射傳播聚類的圖像分割算法,該算法將仿射傳播聚類算法與CURE層次聚類算法相結(jié)合,CURE算法能夠?qū)Ψ律鋫鞑ゾ垲愃惴ǖ姆指罱Y(jié)果進(jìn)行優(yōu)化。實(shí)驗(yàn)驗(yàn)證表明,改進(jìn)后的算法圖像分割效果更好。
圖像分割;仿射傳播聚類;聚類數(shù)目;偏向參數(shù);CURE算法
0 引言
在計(jì)算機(jī)高速發(fā)展的時(shí)代,人們?cè)絹碓蕉嗟亟柚?jì)算機(jī)獲取與處理自己所需的圖像信息。然而,在對(duì)圖像進(jìn)行研究和處理時(shí),人們不一定對(duì)所有的圖像信息感興趣,而有時(shí)只對(duì)圖像中某些特定的、具有獨(dú)特性質(zhì)的部分感興趣,這就需要將這些區(qū)域從圖像中分割出來。圖像分割就是將圖像劃分為幾個(gè)不同的區(qū)域,在相同的區(qū)域內(nèi),圖像的特征相近;而在不同的區(qū)域,圖像特征差異性較大。圖像特征可以是圖像自身的特征,如像素的灰度、邊緣輪廓和紋理等[1]。圖像分割技術(shù)應(yīng)用領(lǐng)域廣泛,已在生物醫(yī)學(xué)圖像分析、工業(yè)自動(dòng)化、在線產(chǎn)品檢驗(yàn)、生產(chǎn)程控、文件圖像處理、遙感圖像、保安監(jiān)視及軍事等方面得到了廣泛應(yīng)用。然而由于圖像自身的復(fù)雜性,其發(fā)展至今仍沒有一個(gè)通用的、絕對(duì)好的方法,因此對(duì)圖像分割方法的進(jìn)一步研究具有十分重要的意義。聚類算法一經(jīng)提出就憑借其在圖像分割上的良好效果,在圖像分割領(lǐng)域受到了廣泛關(guān)注。聚類分析是根據(jù)圖像在某些屬性上的相似性,將圖像劃分為不同類的過程。聚類算法能夠保證一幅圖像上同一類內(nèi)的對(duì)象有較高的相似性,類間對(duì)象有較高的差異性,這就有利于人們特定地去分析自己感興趣的內(nèi)容。根據(jù)聚類方法的不同,聚類算法可以分為多種,文獻(xiàn)[2]中將聚類算法大致分為層次算法、劃分算法、基于密度和網(wǎng)格的方法以及其它聚類算法。K-means聚類算法作為一種比較經(jīng)典的圖像分割算法,在圖像分割中得到了很好的應(yīng)用。然而,K-means聚類算法必須預(yù)先給定聚類數(shù)目,對(duì)初始聚類中心的選擇比較敏感,如果給定的數(shù)值不合適則容易陷入局部最優(yōu)狀態(tài)。
仿射傳播聚類算法(Affinity Propagation Clustering, AP)是2007年由Frey等[3-4]在《Science》上提出的同屬于K-means算法的一種新的聚類算法,AP算法克服了K-means算法的缺點(diǎn),不需要預(yù)先指定聚類中心,初始時(shí)將全部的數(shù)據(jù)點(diǎn)都作為候選聚類中心點(diǎn),通過數(shù)據(jù)點(diǎn)之間的消息傳遞過程不停地循環(huán)迭代,最終獲得高質(zhì)量的聚類中心[5],避免了局部最優(yōu)的狀態(tài),同時(shí) AP算法對(duì)數(shù)據(jù)點(diǎn)之間生成的相似度矩陣的對(duì)稱性沒有要求,多次獨(dú)立運(yùn)行的結(jié)果都非常穩(wěn)定。目前也有一些學(xué)者對(duì)AP算法進(jìn)行了改進(jìn)[6-9],有的是與其它算法結(jié)合來縮短運(yùn)行時(shí)間,有的是對(duì)自身結(jié)構(gòu)作了改進(jìn),然而并沒有從根本上解決問題。AP聚類算法雖然運(yùn)行結(jié)果比較穩(wěn)定,但是在處理結(jié)構(gòu)較松散的數(shù)據(jù)時(shí)產(chǎn)生的類數(shù)往往會(huì)偏多[10],在處理具有復(fù)雜結(jié)構(gòu)的數(shù)據(jù)集時(shí),不能夠產(chǎn)生合理的聚類效果,因此會(huì)影響圖像分割質(zhì)量。同時(shí)AP算法最終的聚類數(shù)目在很大程度上會(huì)受到偏向參數(shù)ρ的影響,這就使得AP算法對(duì)ρ值的選擇較為敏感[11-12]。CURE算法是一種凝聚型層次聚類算法,它是基于質(zhì)心和代表點(diǎn)的策略,能夠有效地處理非球形數(shù)據(jù),且該算法能夠很好地控制孤立點(diǎn)對(duì)聚類結(jié)果的影響[13-14]。因此,本文將AP聚類算法和CURE算法相結(jié)合,利用CURE算法的優(yōu)點(diǎn)對(duì)AP聚類算法的結(jié)果進(jìn)行優(yōu)化,從而提高聚類質(zhì)量。
1 相關(guān)算法
1.1 傳統(tǒng)AP聚類算法
AP聚類算法不需要事先指定聚類數(shù)目,而是在初始時(shí)把全部的數(shù)據(jù)點(diǎn)都作為候選聚類中心,通過計(jì)算數(shù)據(jù)點(diǎn)間的相似度矩陣S,確定偏向參數(shù)p(preference),經(jīng)過循環(huán)迭代過程,判斷決策矩陣E從而找到聚類中心。
設(shè)任意兩個(gè)數(shù)據(jù)點(diǎn)xi和xk,它們之間的相似度s(i,k)是通過計(jì)算它們的負(fù)的歐氏距離來得到,最終得到的相似度矩陣S是一個(gè)N×N的矩陣,s(i.k)的計(jì)算公式如下:
(1)
式(1)中,當(dāng)i=k時(shí),s(i,k)本應(yīng)該是零,但為了確保每個(gè)點(diǎn)成為聚類中心的可能性相同,這里全部設(shè)置為偏向參數(shù)ρ的值。
AP算法在消息傳遞過程中涉及兩個(gè)重要參數(shù):吸引度矩陣R和歸屬度矩陣A。吸引度矩陣R:吸引度r(i,k)是由點(diǎn)xi發(fā)送到候選聚類中心點(diǎn)xk的消息,表示點(diǎn)x可以成為點(diǎn)xi的類中心點(diǎn)的程度。歸屬度矩陣A:歸屬度a(i,k)是由候選聚類中心點(diǎn)xk發(fā)送到點(diǎn)xi的消息,表示點(diǎn)xi是否選擇點(diǎn)xk作為其類中心點(diǎn)的程度。
r(i,k)與a(i,k)的大小直接決定著xk能否成為聚類中心,值越大,xk成為聚類中心的可能性越大。它們之間的消息傳遞過程如圖1所示。
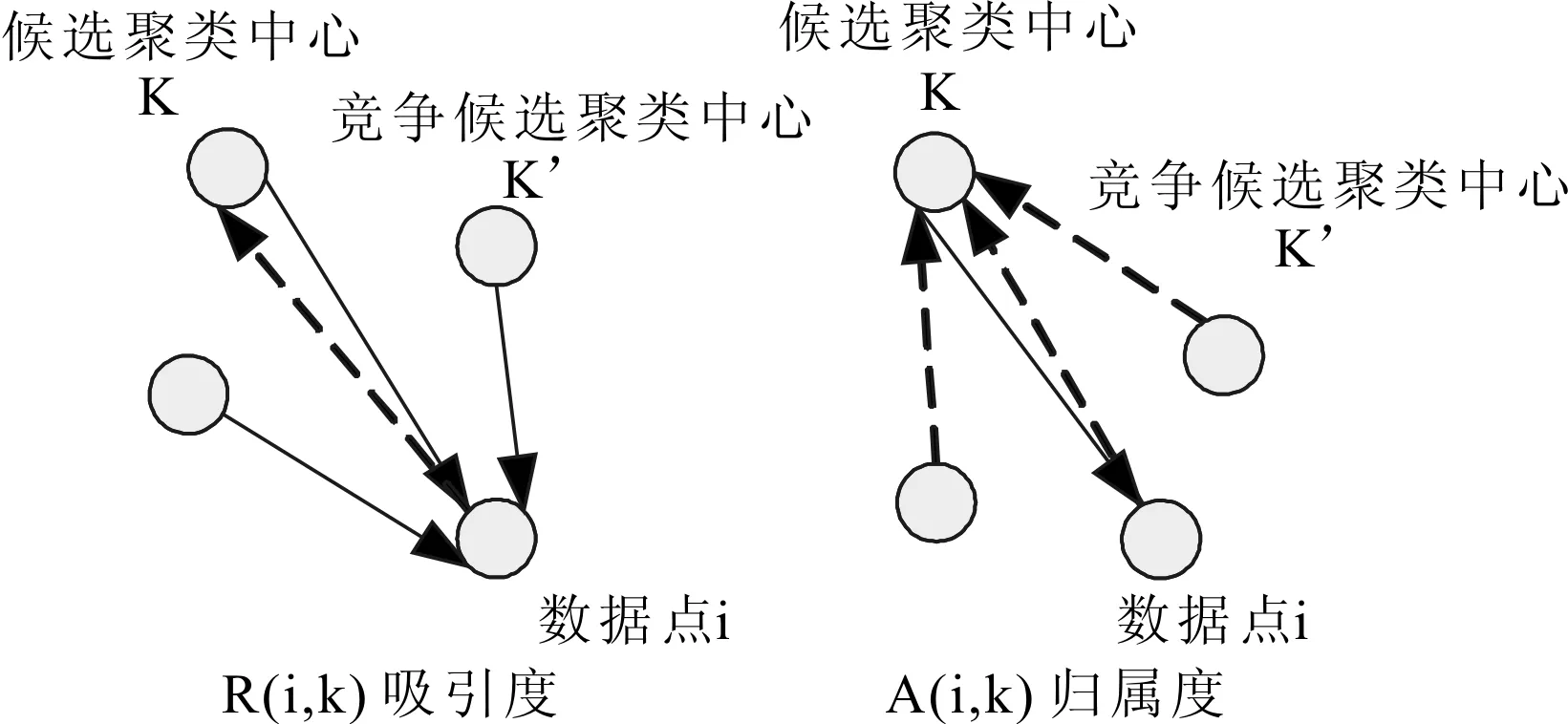
圖1 消息傳遞過程
根據(jù)文獻(xiàn)[3]用相似度矩陣S來計(jì)算吸引度矩陣R和歸屬度矩陣A:
(2)
(3)
(4)
(5)
AP算法還引入了兩個(gè)重要的信息參數(shù):阻尼振蕩因子lam和偏向參數(shù)p(preference)。在每一次的更新迭代過程中,R和A的值利用lam來進(jìn)行迭代更新,更新過程如下:
(6)
(7)
其中,當(dāng)?shù)^程中獲得的聚類個(gè)數(shù)不停地發(fā)生震蕩而無法收斂時(shí),適當(dāng)增大lam的值可消除震蕩,使算法更快收斂。通常情況下,lam設(shè)置在0.85左右可以直接避免震蕩。對(duì)于偏向參數(shù)p,在很大程度上影響最終的聚類數(shù)目,通常會(huì)把p值設(shè)置成相似度矩陣的中值,但即使設(shè)置成相似度矩陣的中值也并非就能夠獲得最好的聚類效果,因此很難直接知道p取何值時(shí)能夠獲得最好的聚類效果。
AP算法不停地更新吸引度矩陣R和歸屬度矩陣A的值,當(dāng)超過預(yù)先設(shè)置的最大迭代次數(shù)maxits或聚類中心連續(xù)convits次穩(wěn)定不變時(shí),算法將停止迭代。通過終止時(shí)r(i,k)+a(i,k)的值來確定最終的聚類結(jié)果。數(shù)據(jù)點(diǎn)k確定為i的類中心點(diǎn),k的值為:
k=argkmax(r(i,k)+a(i,k))
(8)
對(duì)式(2)兩邊同時(shí)加上a(i,k)得:
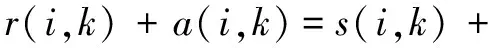
(9)
1.2 AP算法步驟
對(duì)于由N個(gè)數(shù)據(jù)點(diǎn)組成的數(shù)據(jù)集T,AP算法的運(yùn)算步驟可以用圖2所示的流程圖來表示。
AP聚類算法雖然多次獨(dú)立運(yùn)行的結(jié)果比較穩(wěn)定,但其仍然存在兩個(gè)缺點(diǎn):①AP算法對(duì)偏向參數(shù)P的選擇較敏感,P值偏小獲得的聚類個(gè)數(shù)偏少,P值越大獲得的聚類個(gè)數(shù)越多。如果逐個(gè)去試就會(huì)增加算法的復(fù)雜度,因此P值的選擇不容忽視;②AP算法在處理較松散的數(shù)據(jù)時(shí)容易產(chǎn)生較多的聚類數(shù),影響聚類效果,即在消息傳遞過程中有可能多個(gè)數(shù)據(jù)點(diǎn)成為聚類中心的優(yōu)先級(jí)相同,從而導(dǎo)致聚類數(shù)目偏多,影響圖像分割質(zhì)量。
1.3 CURE算法
CURE算法是針對(duì)大多數(shù)數(shù)據(jù)集而提出的一種基于質(zhì)心的聚結(jié)型層次聚類算法。CURE算法最開始是將每個(gè)數(shù)據(jù)點(diǎn)都看成一個(gè)類(即每個(gè)類中只有這個(gè)數(shù)據(jù)點(diǎn)本身),然后計(jì)算各個(gè)數(shù)據(jù)點(diǎn)間的相似性,將最相似的兩個(gè)數(shù)據(jù)點(diǎn)進(jìn)行合并。CURE聚類算法可以適用任意形狀的簇,通過收縮因子來控制孤立點(diǎn)的影響。因此在遇到較松散的數(shù)據(jù)集時(shí)CURE算法能夠更好地處理孤立點(diǎn),而且能夠識(shí)別非球形和大小并改變較大的類。
設(shè)任意一個(gè)數(shù)據(jù)集W,CURE算法最初聚類時(shí)每個(gè)數(shù)據(jù)點(diǎn)都是一類,通過計(jì)算兩兩之間的距離,然后融合距離最近的兩個(gè)類,直到達(dá)到預(yù)先設(shè)定的聚類個(gè)數(shù)。對(duì)于任意一個(gè)類u,u.mean和u.rep分別表示類u的聚類中心點(diǎn)和屬于類u的數(shù)據(jù)點(diǎn),類與類之間的距離是采用歐式距離,兩個(gè)聚類u、v之間的距離計(jì)算公式定義為:
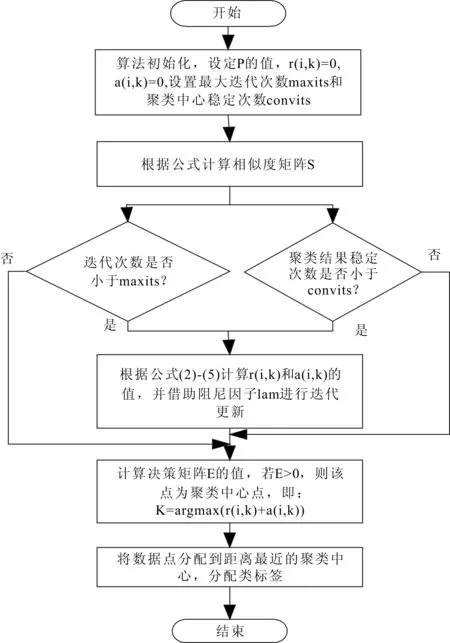
圖2 AP算法運(yùn)算步驟流程
dist(u,v)=min(dist(u.rep,v.rep))
(10)
當(dāng)確定距離最小的兩個(gè)類后,將這兩個(gè)類融合,融合后形成新的聚類中心點(diǎn),計(jì)算公式為:
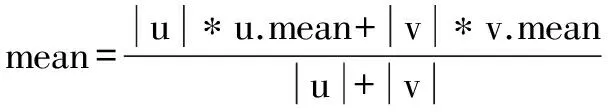
(11)
其中|u|為類u的數(shù)據(jù)點(diǎn)個(gè)數(shù)。
2 改進(jìn)的AP聚類算法
針對(duì)AP聚類算法存在的一些缺點(diǎn),以及CURE算法能夠處理任意形狀數(shù)據(jù)集的優(yōu)點(diǎn),本文是將兩種聚類算法進(jìn)行結(jié)合形成一種新的算法,即C-AP算法,以克服AP算法的不足,經(jīng)驗(yàn)證C-AP算法的圖像分割效果明顯優(yōu)于AP算法的聚類結(jié)果。
2.1 算法原理
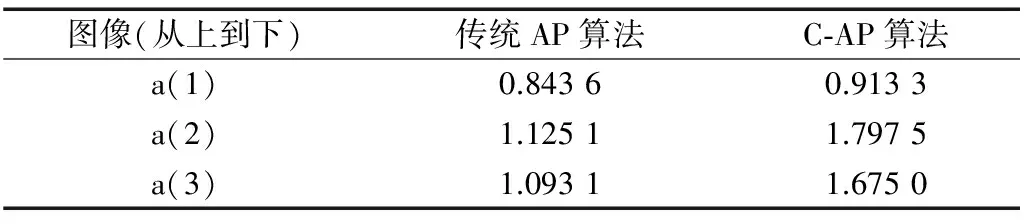
C-AP算法進(jìn)行聚類分為3個(gè)過程:首先運(yùn)用AP算法對(duì)數(shù)據(jù)集進(jìn)行預(yù)分割,會(huì)獲得n個(gè)聚類中心;其次對(duì)于獲得的這n個(gè)聚類中心進(jìn)行去異常值處理,獲得n個(gè)質(zhì)量較好的聚類中心;最后階段是將這個(gè)質(zhì)量較好的聚類中心作為CURE算法的輸入數(shù)據(jù),經(jīng)過CURE算法聚類后將獲得最終的聚類中心,也是質(zhì)量最高的聚類中心Cbest,再將其余的數(shù)據(jù)點(diǎn)分配到所屬的類。C-AP算法為了得到更好的聚類效果,偏向參數(shù)p的值不能設(shè)置得太小,這樣才能保證在進(jìn)行CURE聚類的階段輸入數(shù)據(jù)點(diǎn)個(gè)數(shù)不會(huì)太少。若值設(shè)置得太大,一些噪聲點(diǎn)就會(huì)被分割出來,這就必須進(jìn)行去噪聲處理。C-AP算法引入了去噪聲率α,若centeri為中心的簇中樣本點(diǎn)個(gè)數(shù)ni<α 由于CURE算法需要初始設(shè)定聚類數(shù)目,為了能夠得到最好的聚類個(gè)數(shù),本文加入了聚類有效性指標(biāo)Silhouette指標(biāo),能夠通過Silhouette指標(biāo)值來判斷出最優(yōu)的聚類個(gè) 數(shù)[15]。設(shè)一個(gè)有N個(gè)樣本的數(shù)據(jù)集被劃分為k個(gè)類Ci(i=1,2,l,k),其中,ni表示Ci類中的樣本點(diǎn)個(gè)數(shù)。t為類別Ci中的樣本點(diǎn),則設(shè)a(t)表示為Ci中t與其類內(nèi)其它樣本的平均距離(此處為歐氏距離),d(t,Ci)表示t到另一類別中所有樣本平均聚類,得到bt=min{d(t,Ci},j=1,23,…,k,且j≠i,得到樣本t的Silhouette指標(biāo)為: (12) 一個(gè)聚類中所有樣本點(diǎn)的平均值能夠反映該類的緊密性和可分性,那么整個(gè)數(shù)據(jù)集內(nèi)所有樣本的Sil平均值就可以反映整個(gè)聚類結(jié)果的質(zhì)量,平均Silhouette指標(biāo)越大表明聚類質(zhì)量越好,其最大值對(duì)應(yīng)的類數(shù)即為最優(yōu)聚類個(gè)數(shù)。本文是通過比較不同的分割類數(shù)得到不同的Silhouette指標(biāo)值,選擇Silhouette指標(biāo)值較大的類數(shù)輸出。 2.2 C-AP算法進(jìn)行圖像分割步驟 Step1:輸入待分割圖像,提取圖像的灰度值作為數(shù)據(jù)點(diǎn)輸入。 Step2:初始化聚類算法參數(shù):計(jì)算數(shù)據(jù)點(diǎn)間的相似度矩陣S,偏向參數(shù)P,去噪聲率α。 Step3:應(yīng)用AP算法對(duì)圖像進(jìn)行預(yù)分割,會(huì)得到M個(gè)聚類中心點(diǎn){center1,center2,…,centerm}。 Step4:對(duì)m個(gè)聚類中心進(jìn)行去噪聲點(diǎn)處理。即基于該聚類中心的簇中樣本個(gè)數(shù)是否小于α×N,若小于a×N的值,則將該聚類中心刪除;反之將該聚類中心進(jìn)行下一步聚類,這樣就得到n個(gè)質(zhì)量較好的聚類中心{goodcenter1,goodcenter2,…,goodcentern}。 Step5:對(duì)獲得的這n個(gè)聚類中心進(jìn)行CURE算法聚類,通過比較不同類數(shù)對(duì)應(yīng)不同的Silhouette指標(biāo)值選出最好的聚類個(gè)數(shù),對(duì)剩余的數(shù)據(jù)點(diǎn)進(jìn)行類標(biāo)簽分配。 Step6:根據(jù)聚類結(jié)果輸出分割后的圖像。 本文的實(shí)驗(yàn)運(yùn)行環(huán)境是在MATLAB 7.10.0(R2010a)版本上運(yùn)行。圖像均來源于Berkeley的標(biāo)準(zhǔn)灰度圖像分割數(shù)據(jù)庫BSDS300中的圖像。本文是對(duì)AP算法和C-AP算法的聚類性能進(jìn)行比較,實(shí)驗(yàn)中AP算法初始時(shí)偏向參數(shù)P設(shè)置為相似度矩陣的中值,算法最大迭代次數(shù)設(shè)置為1 000,迭代過程聚類結(jié)果連續(xù)不發(fā)生改變的次數(shù)設(shè)置為100,阻尼系數(shù)lam設(shè)置為0.9,去噪聲率α取值為0.02。本文選取了其中的3幅圖像進(jìn)行分割,分割效果如圖3所示。 圖3 AP算法和C-AP算法分割結(jié)果 從圖2可以看出,本文的C-AP算法分割效果要優(yōu)于傳統(tǒng)的AP算法分割效果。其中傳統(tǒng)AP算法將第一幅圖像分割成了6類,本文算法是分割成了3類,傳統(tǒng)AP算法分割數(shù)目多于本文算法,天空背景區(qū)域出現(xiàn)了錯(cuò)分割現(xiàn)象,本文算法分割后的圖像更加干凈,相對(duì)準(zhǔn)確。第二幅圖像,傳統(tǒng)AP算法對(duì)草地分割得比較粗糙,本文C-AP算法則比較細(xì)膩,將背景和山羊明顯的區(qū)分開來。第三幅圖像中,本文C-AP算法對(duì)背景光暈處的分割效果明顯優(yōu)于傳統(tǒng)AP算法的分割效果。直觀上看,實(shí)驗(yàn)結(jié)果驗(yàn)證了本文改進(jìn)后的算法在分割效果上更加精確,但有時(shí)通過肉眼觀察會(huì)存在主觀性,缺乏定量分析,因此本文引入了區(qū)域間對(duì)比度來客觀評(píng)價(jià)算法的性能。圖像分割就是將圖像分割成若干類,類與類之間的差異越大表明分割效果越好,因此選擇區(qū)域間對(duì)比度能很好地反應(yīng)分割的好壞。區(qū)域間對(duì)比度(GC)用于衡量分割后圖像各區(qū)域之間的差異度,GC值越大表明分割效果越好[16]。設(shè)一幅圖像被分割成fi和fj個(gè)區(qū)域,i和j分別表示圖像中的任意兩個(gè)區(qū)域,fi和fj分別表示第i個(gè)區(qū)域和第j個(gè)區(qū)域的平均灰度,則GC可表示為: (13) 傳統(tǒng)AP算法和本文算法的區(qū)間對(duì)比度如表1所示。 表1 兩種算法GC值對(duì)比 從表1中的數(shù)據(jù)可以看出,改進(jìn)后的仿射傳播聚類算法(C-AP算法)與傳統(tǒng)的AP聚類算法相比,3幅圖像的區(qū)域間對(duì)比度都得到了提高,說明改進(jìn)后的算法分割效果更好。 本文針對(duì)傳統(tǒng)的仿射傳播聚類算法在圖像分割上存在的不足,對(duì)傳統(tǒng)的仿射傳播聚類算法作了改進(jìn),通過與CURE層次聚類算法結(jié)合使得算法克服了對(duì)偏向參數(shù)選擇的敏感性,對(duì)于一些孤立點(diǎn)的處理更加健壯,經(jīng)驗(yàn)證改進(jìn)后的算法在圖像分割效果和性能上都得到了一定的提高。由于本文算法是在傳統(tǒng)放射傳播聚類算法分割之后再利用CURE算法作進(jìn)一步分割,在運(yùn)行時(shí)間上會(huì)略長,因此如何進(jìn)一步縮短運(yùn)行時(shí)間是下一步研究的重點(diǎn)。 [1] 章毓晉.圖像分割[M].北京:科學(xué)出版社,2001. [2] 孫吉貴,劉杰,趙連宇.聚類算法研究[J].軟件學(xué)報(bào),2008,19(1):48-61. [3] FREY B J,DUECK D.Clustering by passing messages between data points[J].Science,2007,315(5814):972-976. [4] MéZARD M.Where are the exemplars[J].Science,2007,315(5814):949-951. [5] SHANG FAN-HUA,JIAO L C,SHI JIA-RONG,et al.Fast affinity propagation clustering:a multil- evel approach[J].Pattern Recognition,2012,45(1). [6] 肖宇,于劍.基于近鄰傳播算法的半監(jiān)督聚類[J].軟件學(xué)報(bào),2008,19(11):2803-2813. [7] 許曉麗,盧志茂,張格森,等.改進(jìn)近鄰傳播聚類的彩色圖像分割[J].計(jì)算機(jī)輔助設(shè)計(jì)與圖形學(xué)學(xué)報(bào),2012,24(4):514-519. [8] 董俊,王鎖萍,熊范綸.可變相似性度量的近鄰傳播聚類[J].電子與信息學(xué)報(bào),2010,32(3):509-514. [9] 劉曉楠,尹美娟,李明濤,等.面向大規(guī)模數(shù)據(jù)的分層近鄰傳播聚類算法[J].計(jì)算機(jī)科學(xué),2014,41(3):185-188. [10] 王開軍,李健,張軍英,等.半監(jiān)督的仿射傳播聚類[J].計(jì)算機(jī)工程,2007,33(23):197-199. [11] KAREN K.Affinity program slashes computing times [EB/OL].http://www.news. utoronto. ca/bin6/ 070215-2952.Asp,2007-10-25. [12] BODENHOFER U,KOTHMEIER A,HOCHREITER S.APcluster:an R package for affinity propagation clustering[J].Bioinformatics,2011,27(17):2463-2464. [13] GUHA S,RASTOGI R,SHIM K.CURE:an efficient clustering algorithm for large databases[J].ACM SIGMOD Record,ACM,1998,27(2):73-84. [14] 沈潔,趙雷,楊季文,等.一種基于劃分的層次聚類算法[J].計(jì)算機(jī)工程與應(yīng)用,2007,43(31):175-177. [15] DUDOIT S,FRIDLYAND J.A prediction-based resampling method for estimating the number of clusters in a dataset[EB/OL].http://www.edlab.cs.umass.edu/cs69 1k/conlon/readings/Dudoit Fridlyand2002GB.pdf,2002. [16] LEVINC M D,NAZIF A M.Dynamic measurement of computer generated image segmentations[J].IEEE Trans.PAMI-7,1985,7(2):155-164. (責(zé)任編輯:孫 娟) 國家自然科學(xué)基金項(xiàng)目(60975021);中南民族大學(xué)中央高校基本科研業(yè)務(wù)費(fèi)專項(xiàng)資金項(xiàng)目(CZZ15003) 趙淑娟(1990-),女,山東菏澤人,中南民族大學(xué)計(jì)算機(jī)科學(xué)學(xué)院碩士研究生,研究方向?yàn)閳D像處理、人工智能;王江晴(1964-),女,湖北武漢人,博士,中南民族大學(xué)計(jì)算機(jī)科學(xué)學(xué)院教授,研究方向?yàn)槿斯ぶ悄堋?shù)字圖像處理;孫陽光(1978-),男,湖北武漢人,博士,中南民族大學(xué)計(jì)算機(jī)科學(xué)學(xué)院副教授,研究方向?yàn)閿?shù)字圖像處理。 10.11907/rjdk.162273 TP312 A 1672-7800(2017)003-0018-043 實(shí)驗(yàn)結(jié)果及分析

4 結(jié)語
